在数据分析和建模工作中,列的相关操作是最基础也是最高频的数据预处理任务之一,例如删除不需要的列、或者一些复杂的条件筛选等。
所以本文以模拟生成的用户数据集为示例,总结Pandas中关于DataFrame列常用的基本操作,包括列的新增、删除、修改、重命名以及条件筛选。
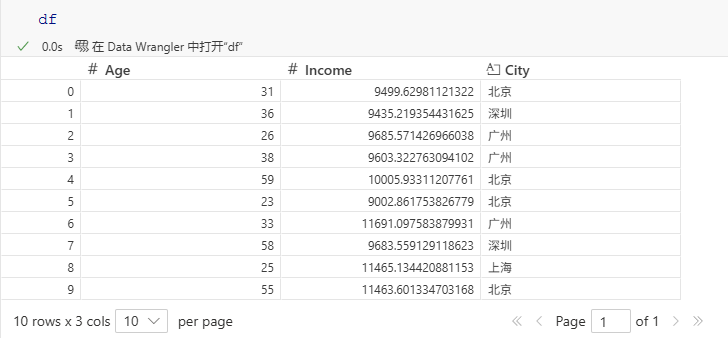
首先生成一份数据集用于演示:
python
import numpy as np
import pandas as pd
# 生成一个10行3列的数据集
# 分别代表: 10个用户,3个字段分别是用户的年龄、收入、城市
df = pd.DataFrame(
{'Age': np.random.randint(22,60,10)
,'Income':np.random.normal(10000,1000,10)
,'City': np.random.choice(['北京','上海','广州','深圳'],10)}
)生成结果如下:
1-列的新增
比如现在这份数据集中有用户的年龄、收入与城市。如果用户的性别单独存放在user_gender中,需要将其添加到df中,只需要将其对DataFrame 的列索引直接赋值即可:
python
# 用户性别信息存储在 user_gender中
user_gender = np.random.choice(['男','女'],10)
# 添加用户性别字段: 将 user_gender 直接赋值到 df的新列名 'Gender' 中即可
df['Gender'] = user_gender
df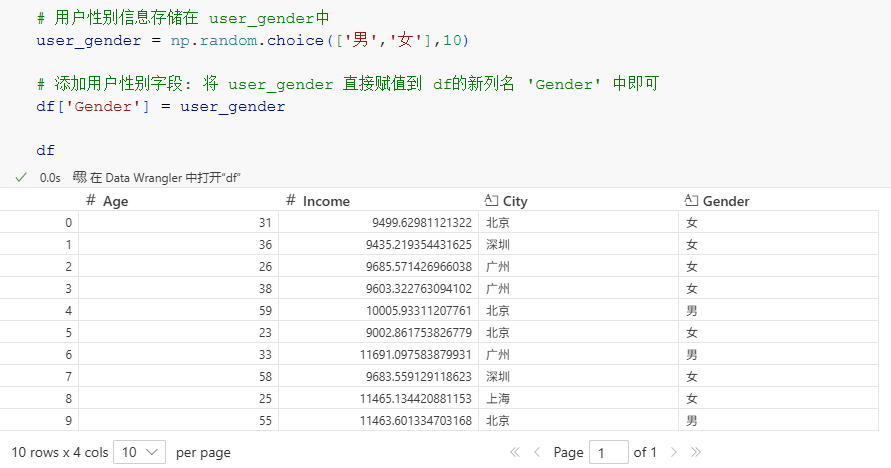
2-列的删除
如果不需要用户的性别信息/Gender列,可以通过drop()方法删除该列.
drop()方法的主要参数:
python
df.drop(
# 需要删除的列名是col_name / 可以是单个列名字符串或列名列表
columns=[col_name]
# 0/1 分别对应 删行还是删列
# 当指定 columns 参数时, axis 默认为 1(删除列)
,axis=0/1
# inplace=False(默认), 将删除后的结果返回为一个新的DataFrame
# inplace=True,会修改原始数据,返回 df原地删除后的结果
,inplace=True/False
)下面就以删除'gender'列为例,演示drop()方法的使用:
python
# 通过drop()方法删除 'Gender'
# 指定 columns=['Gender']后,无需设置axis=1
# 且默认inplace=False,不会修改原始数据df
# 所以将删除后的结果赋值为df2
df2 = df.drop(columns=['Gender'])
df2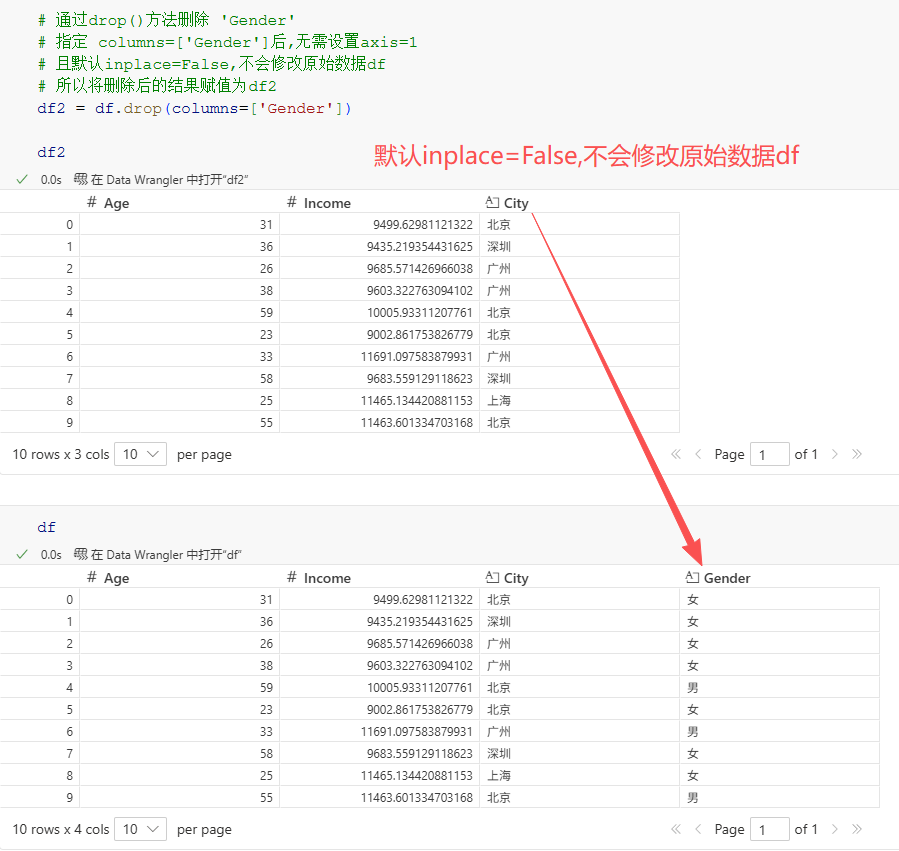
3-列值的修改
直接对列重新赋值即可完成对该列的修改,例如假设要将'Income'列的单位由美元更改为人民币:
python
# 假设美元兑人民币汇率为7
# 将收入 原地修改为 人民币单位
df['Income'] = df['Income']*7
df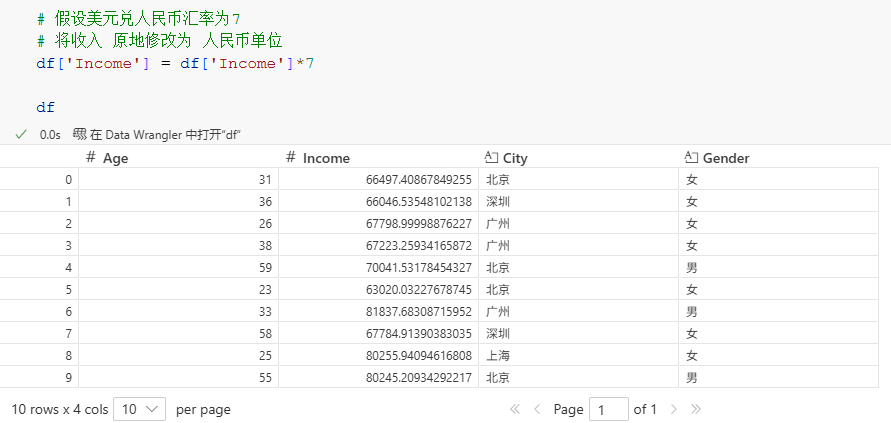
4-列名的修改
(1) 所有列名的修改
通过columns属性,将新列名对其重新赋值即可:
python
# 新列名直接重新赋值给 df.columns
df.columns = ['年龄','收入','城市','性别']
df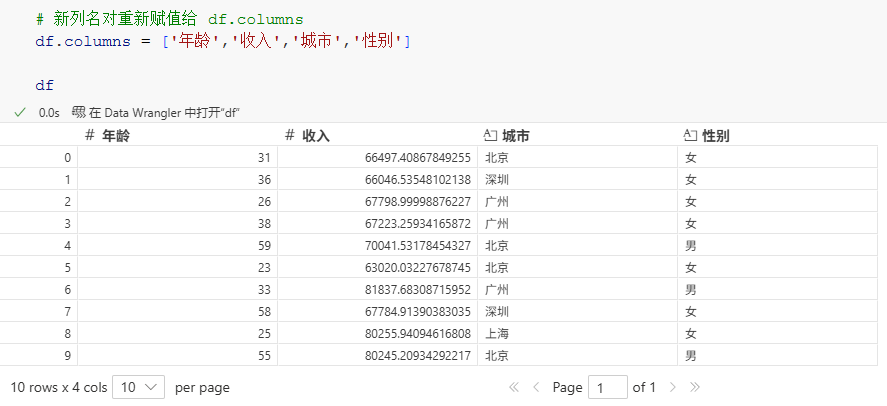
(2) 部分列名的修改
如果原始数据的字段数/列数过多,但实际只需修改部分列名时,则可以通过rename()方法更改:
python
# 此处只对原始数据df的 '年龄'与'性别'列重新赋值
# 构建一个字典传入rename()方法的columns中:
# 字典的键 -- 被修改的列名
# 字典的值 -- 修改后的新名
df = df.rename(columns={'年龄':'用户年龄','性别':'用户性别'})
df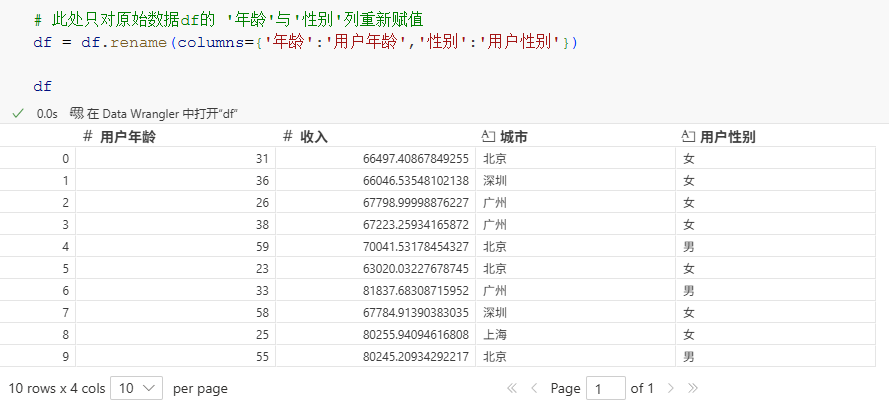
5-列的条件筛选
条件筛选在各种场景下都是高频操作,对于列的筛选,Pandas提供了下面两种高效方式查询:
(1) 布尔表达式
例如要查询出 所有小于40岁的用户,将 df'用户年龄'<40 作为布尔表达式传入 df 中即可:
python
df[ df['用户年龄']<40 ]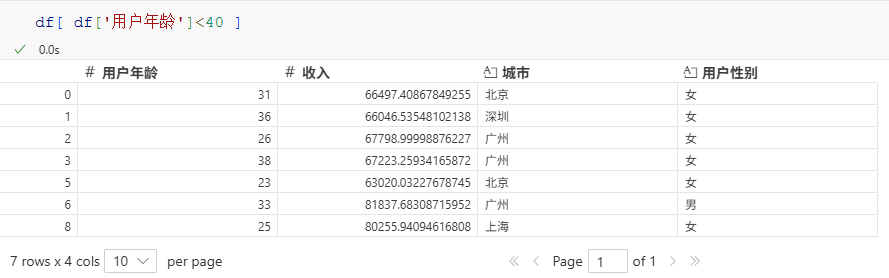
对于更复杂的条件,可以配合逻辑运算符(&、|、~)构造布尔表达式查询
例如要查询出 所有小于40岁的女性用户,可以将
(df'用户年龄'<40) 与 (df'用户性别'=='女') 两个查询条件通过 与运算符'&' 连接,构造布尔表达式:
python
# 注: 不同条件之间最好用 () 区分,保证逻辑正确性
df[ (df['用户年龄']<40) & (df['用户性别']=='女')]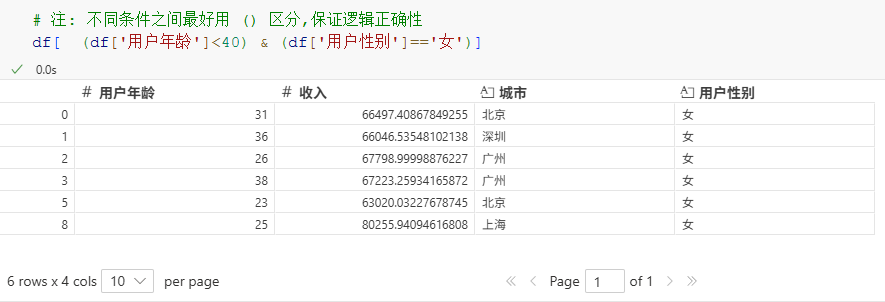
布尔表达式可以满足基本的条件查询,但当查询条件较为复杂时,布尔表达式会变得冗长,导致可读性低。
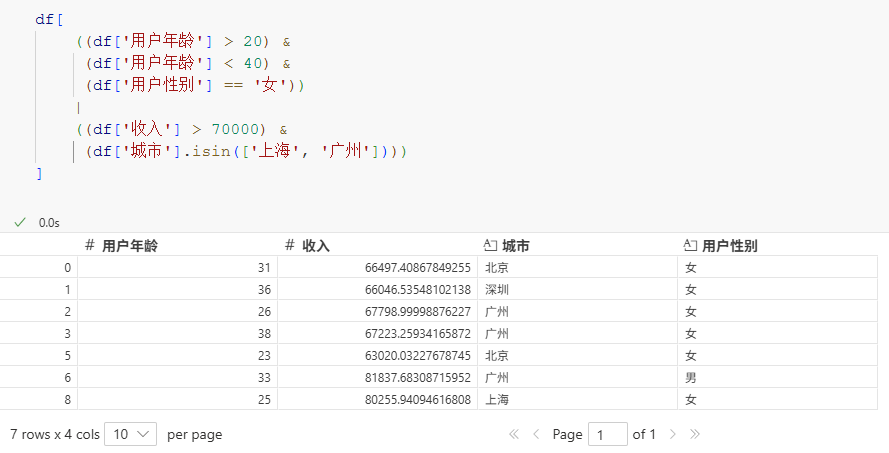
例如要查询出:20-40岁之间的女性用户 或者 收入大于70000且居住在上海或广州的用户,
用布尔表达式的查询代码是:
python
df[
((df['用户年龄'] > 20) &
(df['用户年龄'] < 40) &
(df['用户性别'] == '女'))
|
((df['收入'] > 70000) &
(df['城市'].isin(['上海', '广州'])))
]
因此对于复杂的条件查询,Pandas提供了 query()方法。
(2) query()方法
与布尔表达式相比,query()方法具有更简洁的语法和更好的可读性,允许使用字符串表达式 来筛选数据。
语法简洁是因为query()使用类似SQL的表达式替代多重括号
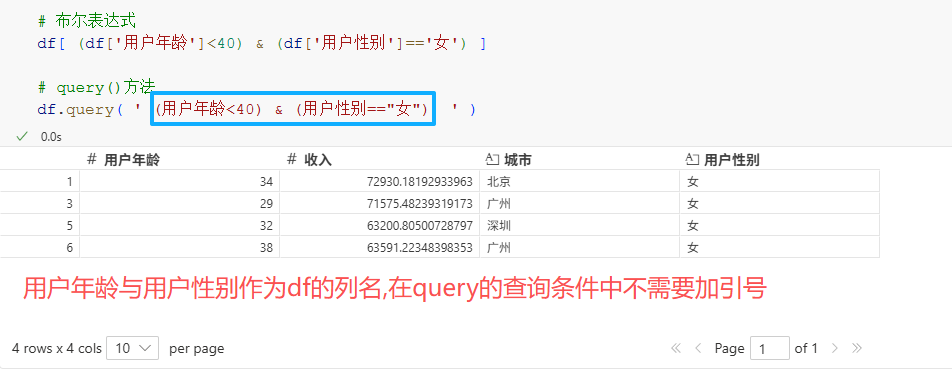
例如下面以对于 "所有小于40岁的女性用户"的查询,对比布尔表达式与query()方法的查询表达式
python
# 布尔表达式
df[ (df['用户年龄']<40) & (df['用户性别']=='女') ]
# query()方法
df.query( ' (用户年龄<40) & (用户性别=="女") ' )显然 query()方法的查询表达式更简洁
所以对于"20-40岁之间的女性用户 或者 收入大于70000且居住城市在上海或者广州的用户",使用query()可以这样查询:
python
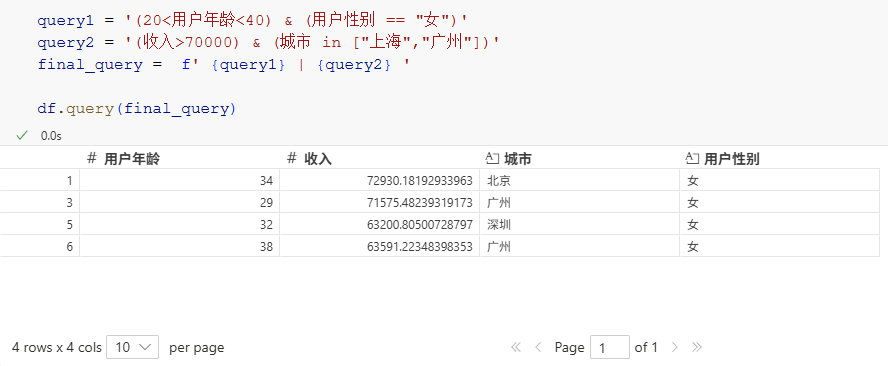
query_how = '(20<用户年龄<40) & (用户性别 == "女") | (收入>70000) & (城市 in ["上海","广州"])'
df.query(query_how)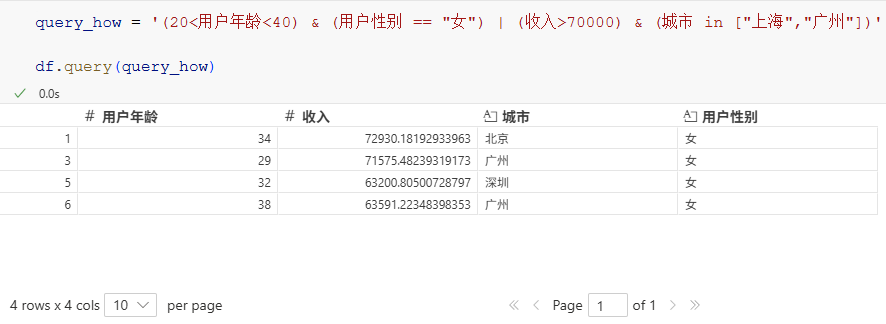
如果需要进一步提高可读性,也可以按下面的方式查询:
python
query1 = '(20<用户年龄<40) & (用户性别 == "女")'
query2 = '(收入>70000) & (城市 in ["上海","广州"])'
final_query = f' {query1} | {query2} '
df.query(final_query)