目录
[2.1、 常用元字符](#2.1、 常用元字符)
[2.3、字符集 \[\] 详解](#2.3、字符集 [] 详解)
[3.4、常用标志(flags 参数)](#3.4、常用标志(flags 参数))
[3、URL 验证(HTTP/HTTPS)](#3、URL 验证(HTTP/HTTPS))
[1、提取 HTML 标签内容](#1、提取 HTML 标签内容)
1、正则表达式概述
1.1、正则表达式的作用
在实际开发过程中经常会有查找符合某些规则的字符串。
比如:邮箱、图片地址、手机号码等。想匹配或者查找符合某些规则的字符串 就可以使用正则表达式了。
1.2、正则表达式概念
正则表达式(regular expression)描述了一种字符串匹配的模式
- 检索一个串 是否含有某种 子串**(检索)**。
- 匹配的子串做替换**(替换)**。
- 从一个串 中取出符合某个条件的子串(提取)。
**模式:**一种特定的字符串模式,这个模式是通过一些特殊的符号组成的。
正则表达式并不是Python所特有的 ,在Java、PHP、Go以及JavaScript等语言中都是支持正则表达式的。Python 内置 re 模块提供了对正则表达式的完整支持,本文将从基础到进阶,全面讲解正则表达式语法、re 模块用法及实际应用场景。
1.3、正则表达式的功能
- 数据验证(表单验证、如手机、邮箱、IP地址)
- 数据检索(数据检索、数据抓取) => 爬虫功能
- 数据隐藏(135****6235 王先生)
- 数据过滤(论坛敏感关键词过滤)
2、正则表达式基础语法
正则语法由「普通字符」和「元字符」组成:
- **普通字符:**直接匹配自身(如 a、1、中文);
- 元字符: 具有特殊含义的字符(如**.** 、* 、 ),是正则的核心。
2.1、 常用元字符
|---------|---------------------------------------------------|
| 元字符 | 含义说明 |
|.| 匹配任意单个字符 (除换行符**\n**,指定 re.DOTALL标志可匹配换行) |
|^| 匹配字符串开头 (多行模式 re.MULTILINE下匹配每行开头) |
|$| 匹配字符串结尾 (多行模式 re.MULTILINE下匹配每行结尾) |
|*| 匹配前面的字符 / 子模式 0 次或多次(贪婪匹配) |
|+| 匹配前面的字符 / 子模式 1 次或多次(贪婪匹配) |
|?| 匹配前面的字符 / 子模式 0 次或 1 次 ;或用于非贪婪匹配(加在 *+?后) |
|{n}| 匹配前面的字符 / 子模式 恰好 n 次 |
|{n,}| 匹配前面的字符 / 子模式 至少 n 次(n到无穷大) |
|{n,m}| 匹配前面的字符 / 子模式 n 到 m 次(含 n 和 m) |
|[]| 字符集:匹配括号内任意单个字符 (支持范围 a-z、排除 [^...]) |
||| 逻辑或:匹配 **|**左侧或右侧的模式(优先级最低,需用括号分组) |
|()| 分组:将子模式视为整体,可捕获匹配结果(用于引用或取) |
|\| 转义字符:将元字符转为普通字符(如 **.**匹配 .),或触发预定义字符类 |
2.2、预定义字符类(简化字符集)
|----------|-----------------|---------------------------------|
| 预定义类 | 等价字符集 | 含义说明 |
| \d |[0-9]| 匹配任意数字 |
| \D |[^0-9]| 匹配非数字 |
| \w |[a-zA-Z0-9_]| 匹配字母、数字、下划线(Python3 支持 Unicode) |
| \W |[^a-zA-Z0-9_]| 匹配非单词字符 |
| \s |[ \t\n\r\f]| 匹配任意空白字符(空格、制表符、换行等) |
| \S |[^ \t\n\r\f]| 匹配非空白字符 |
2.3、字符集 [] 详解
- 匹配括号内任意单个字符:
[abc]匹配a、b或c;- 范围简写:
[a-z](小写字母)、[A-Z](大写字母)、[0-9a-f](十六进制数字);- 排除规则:
[^abc]匹配除a、b、c外的任意字符;- 特殊字符在 **[]**内失效 :无需转义
$、*、+等(如[a*.]匹配a、*或.);- 匹配中文:[\u4e00-\u9fa5](Unicode 中文范围)。
2.4、贪婪与非贪婪匹配
正则默认是贪婪匹配 (尽可能匹配最长的字符串 ),在量词(
*、+、?、{n,m})后加?可切换为非贪婪匹配 (尽可能匹配最短的字符串)。|----------|-----------|-----------------------------|
| 贪婪模式 | 非贪婪模式 | 示例(匹配 b****) |
|.*|.*?| 贪婪:<a>b</a>(整个字符串) |
|+|+?| 非贪婪:<a>和</a>(两个片段) |
|{n,m}|{n,m}?|a{2,5}?匹配最少 2 个a|示例对比 :
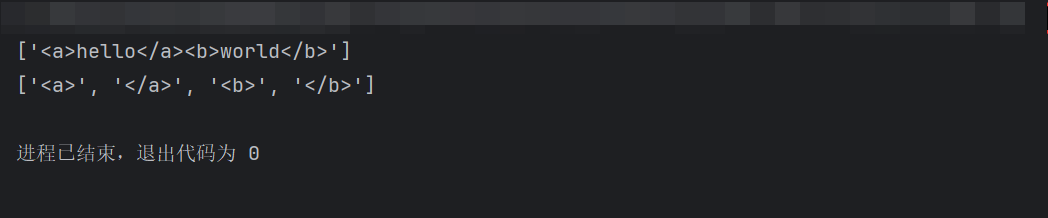
pythonimport re text = "<a>hello</a><b>world</b>" # 贪婪匹配(默认) print(re.findall(r'<.*>', text)) # 非贪婪匹配(加 ?) print(re.findall(r'<.*?>', text))
3、re模块
Regular Expression , 正则表达式, 简称: re**,re模块**是Python操作正则的核心,提供了一系列函数实现正则功能。
3.1、匹配与查找类函数
1、re.match()
语法:
python# pattern:正则规则, # string:要被效验的字符串, # flags:可选,表示匹配模式,比如忽略大小写,多行模式等 re.match(pattern, string, flags=0)
- 功能: 从字符串开头 匹配模式,仅返回第一个匹配结果;
- 返回值: 匹配成功返回 Match****对象 ,失败返回 None;
- **关键:**仅匹配开头,即使后面有符合模式的内容也不匹配。
示例:
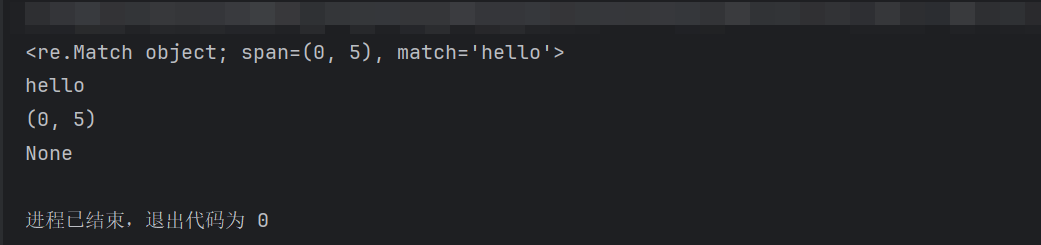
python# 导入re模块 import re # 使用match方法进行匹配操作 result = re.match(r'hello', 'hello world') # 匹配成功输出Math对象,失败输出None print(result) # <re.Match object; span=(0,5), match='hello'> # 如果数据匹配成功,使用group方法提取数据 print(result.group()) # 获取匹配结果:hello # 使用span方法可以获取匹配的位置 print(result.span()) # 获取匹配位置(起始索引,结束索引):(0,5) # 匹配失败(字符串开头不是 'hi') result2 = re.match(r'hi', 'hello world') print(result2)
2、re.search()
语法:
python# pattern:正则规则, # string:要被效验的字符串, # flags:可选,表示匹配模式,比如忽略大小写,多行模式等 re.search(pattern, string, flags=0)
- 功能: 在整个字符串中查找第一个符合模式的内容(不局限于开头);
- 返回值: 同
re.match(Match对象或None);- 区别于
match:search****扫描整个字符串 ,match仅匹配开头。示例:
pythonimport re result = re.search(r'world', 'hello world') print(result.group()) print(result.span())

3、re.findall()
语法:
python# pattern:正则规则, # string:要被效验的字符串, # flags:可选,表示匹配模式,比如忽略大小写,多行模式等 re.findall(pattern, string, flags=0)
- 功能: 查找字符串中所有符合模式的内容;
- 返回值:列表(元素为匹配字符串,无匹配则返回空列表);
- 若模式中有分组 ()****,则返回分组匹配的结果(而非整个模式匹配结果)。
示例:
pythonimport re # 提取所有数字 text = "年龄:25,身高:180,体重:75" nums = re.findall(r'\d+', text) print(nums) # 带分组:提取键值对(返回分组结果) pairs = re.findall(r'(\w+):(\d+)', text) print(pairs)

4、re.finditer()
语法:
python# pattern:正则规则, # string:要被效验的字符串, # flags:可选,表示匹配模式,比如忽略大小写,多行模式等 re.finditer(pattern, string, flags=0)
- 功能: 同
findall,但返回迭代器(而非列表);- 优势: 处理大量匹配结果时,迭代器更节省内存;
- 迭代器元素为 Match****对象,需通过 **group()**获取结果。
示例:
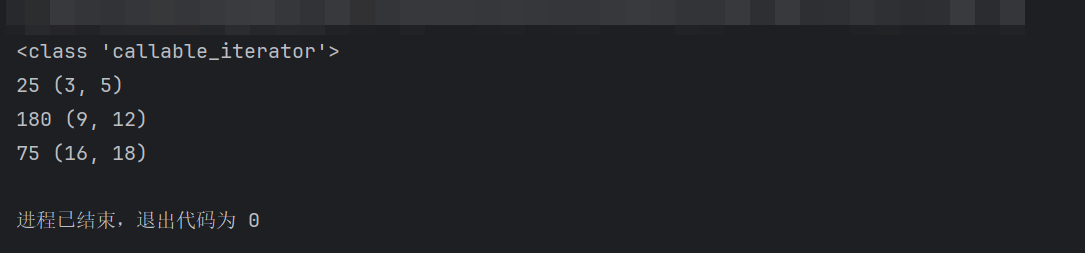
pythonimport re text = "年龄:25,身高:180,体重:75" iter_result = re.finditer(r'\d+', text) print(type(iter_result)) for match in iter_result: print(match.group(), match.span())
3.2、替换与分割类函数
1、re.sub()
语法:
python# pattern:正则规则, # repl:替换后的字符串(可是普通字符串或函数), # string:要被替换的字符串, # count:替换次数(默认 0 表示全部替换), # flags:可选,表示匹配模式,比如忽略大小写,多行模式等 re.sub(pattern, repl, string, count=0, flags=0)
- 功能:替换字符串中符合模式的内容;
- 返回值: 替换后的新字符串。
示例 1:普通替换(敏感词过滤)
pythonimport re text = "你是笨蛋,他是傻瓜" # 将敏感词替换为 * new_text = re.sub(r'笨蛋|傻瓜', '**', text) print(new_text)示例 2:函数替换(动态处理匹配结果)
pythonimport re text = "价格:100 元,折扣:80 元" # 将数字乘以 2 def double_num(match): num = int(match.group()) return str(num * 2) new_text = re.sub(r'\d+', double_num, text) print(new_text)


2、re.split()
语法:
python# pattern:正则规则, # string:要被分割的字符串, # maxsplit:最大分割次数(默认 0 表示全部分割), # flags:可选,表示匹配模式,比如忽略大小写,多行模式等 re.split(pattern, string, maxsplit=0, flags=0)
- 功能: 按符合模式的内容分割字符串;
- 返回值: 分割后的字符串列表。
示例:
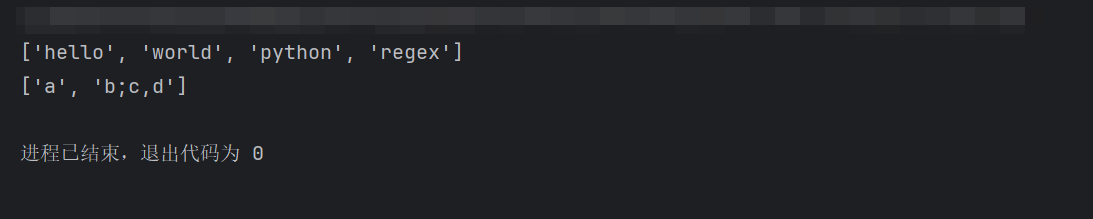
pythonimport re # 按任意空白字符(空格、制表符、换行)分割 text = "hello world\tpython\nregex" result = re.split(r'\s+', text) print(result) # ['hello', 'world', 'python', 'regex'] # 按逗号或分号分割,最多分割 1 次 text = "a,b;c,d" result = re.split(r'[,;]', text, maxsplit=1) print(result)
3.3、编译正则表达式:re.compile()
语法:
pythonre.compile(pattern, flags=0)
- 功能: 将正则模式编译为
Pattern对象,重复使用时提升效率;- **场景:**同一正则模式需多次调用(如循环中匹配)时,编译后可避免重复解析模式;
- Pattern****对象拥有与 re****模块同名的方法( match**、** search**、** findall****等)。
示例:
pythonimport re # 编译正则模式(提取数字) pattern = re.compile(r'\d+') # 重复使用 Pattern 对象 text1 = "身高 180" text2 = "体重 75" print(pattern.findall(text1)) print(pattern.findall(text2))

3.4、常用标志(flags 参数)
标志用于修改正则匹配规则,可通过
|组合使用:|-----------------|--------|----------------------------------|
| 标志 | 简写 | 功能说明 |
|re.IGNORECASE|re.I| 忽略大小写匹配(如a匹配A) |
|re.DOTALL|re.S| 让.匹配换行符(默认不匹配) |
|re.MULTILINE|re.M| 让^/$匹配每行开头 / 结尾(默认仅匹配整个字符串) |
|re.VERBOSE|re.X| 允许正则模式换行和注释(增强可读性) |示例:
pythonimport re # 忽略大小写匹配 text = "Hello WORLD" result = re.findall(r'hello', text, flags=re.I) print(result) # 允许正则注释(re.VERBOSE) pattern = re.compile(r''' \d+ # 匹配数字 [a-z]+ # 匹配字母 ''', flags=re.X) print(pattern.findall("123abc456def"))

4、正则表达式进阶用法
4.1、分组与引用
1、普通分组 ()
- 作用: 将子模式视为整体(如
(ab)+匹配abab);- 捕获匹配结果: 通过
Match.group(n)提取第 n 个分组**(n=0 表示整个匹配结果,n≥1 表示第 n 个分组)**。示例:
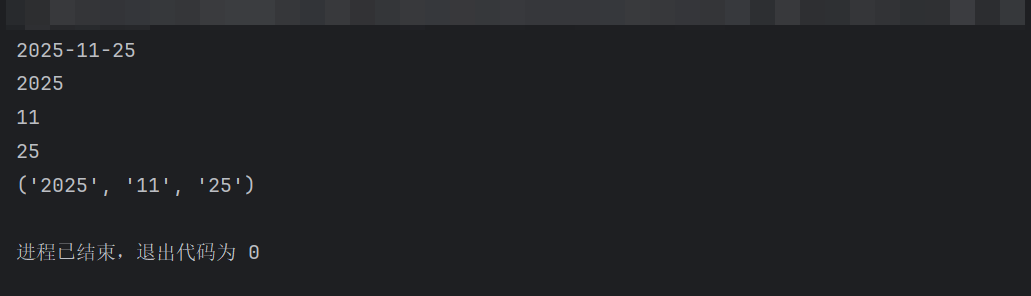
pythonimport re text = "2025-11-25" # 分组匹配年、月、日(3 个分组) pattern = re.compile(r'(\d{4})-(\d{2})-(\d{2})') match = pattern.search(text) print(match.group(0)) # 整个匹配结果:2025-11-25 print(match.group(1)) # 第 1 组(年):2025 print(match.group(2)) # 第 2 组(月):11 print(match.group(3)) # 第 3 组(日):25 print(match.groups()) # 所有分组结果:('2025', '11', '25')
2、非捕获分组 (?:pattern)
- 作用: 仅分组(视为整体),不捕获匹配结果 (节省内存,不影响
group()提取)。示例:
pythonimport re text = "abab123" # 非捕获分组:(?:ab)+ 仅作为整体匹配,不单独捕获 pattern = re.compile(r'(?:ab)+(\d+)') match = pattern.search(text) print(match.group(0)) print(match.group(1))

3、分组引用
- 反向引用: 在正则模式中用
\n引用第 n 个分组的匹配结果(如匹配重复单词);- 正向引用: 在替换字符串中用
\n或\g<n>引用分组(\g<n>避免歧义)。示例 1:反向引用(匹配重复单词)
pythonimport re text = "the the cat cat" # \1 引用第 1 个分组的匹配结果(即 \w+ 匹配的内容) pattern = re.compile(r'(\w+) \1') print(pattern.findall(text))示例 2:正向引用(替换时保留分组内容)
pythonimport re text = "2025-11-25" # 将 年-月-日 改为 月/日/年(用 \g<2> 引用第 2 组) new_text = re.sub(r'(\d{4})-(\d{2})-(\d{2})', r'\g<2>/\g<3>/\g<1>', text) print(new_text)


4、命名分组 (?P<name>pattern)
- **作用:**给分组命名,通过名称提取结果(更易读,避免分组索引混乱);
- 提取方式:
Match.group('name')或Match.group(name);- 引用方式: 模式中用
(?P=name),替换中用\g<name>。示例:
pythonimport re text = "2025-11-25" # 命名分组:年、月、日 pattern = re.compile(r'(?P<year>\d{4})-(?P<month>\d{2})-(?P<day>\d{2})') match = pattern.search(text) print(match.group('year')) print(match.group('month')) # 替换时引用命名分组 new_text = re.sub(pattern, r'\g<month>/\g<day>/\g<year>', text) print(new_text)

4.2、零宽断言(环视)
零宽断言 (Lookaround)用于匹配位置 而非字符(匹配结果长度为 0),常用于匹配某个字符前后满足特定条件 的场景。零宽断言就像是一个"侦察兵",它不会(消耗)字符,只是在字符串里查看某个位置前后的字符是否符合特定条件。可以把字符串想象成一条街道,每个字符是街道上的房子,零宽断言就是站在某个房子前查看前后房子情况的人,它只做观察,不改变街道本身。
|----------|----------------|-------------------------|
| 断言类型 | 语法 | 功能说明 |
| 正向先行断言 |(?=pattern)| 匹配后面紧跟 pattern 的位置 |
| 负向先行断言 |(?!pattern)| 匹配后面不紧跟 pattern 的位置 |
| 正向后行断言 |(?<=pattern)| 匹配前面紧跟 pattern 的位置 |
| 负向后行断言 |(?<!pattern)| 匹配前面不紧跟 pattern 的位置 |示例 1:正向先行断言(匹配后面是 @gmail.com****的用户名)
pythonimport re text = "user1@gmail.com user2@qq.com user3@gmail.com" # 匹配 @gmail.com 前的用户名 pattern = re.compile(r'\w+(?=@gmail\.com)') print(pattern.findall(text)) # ['user1', 'user3']示例 2:负向后行断言(匹配前面不是 http****的 www**)**
pythonimport re text = "www.baidu.com http://www.google.com" # 匹配前面不是 http:// 的 www pattern = re.compile(r'(?<!http://)www\.\w+\.com') print(pattern.findall(text))


4.3、边界匹配
- \b**:** 单词边界(如
\bcat\b匹配独立的cat,不匹配category中的cat);- \B**:** 非单词边界(如
\Bcat\B匹配category中的cat,不匹配独立的cat);- \A**/** \Z**:** 严格匹配整个字符串开头 / 结尾(不受多行模式影响,区别于
^/$)。示例:
pythonimport re text = "cat 1category cat123" print(re.findall(r'\bcat\b', text)) # ['cat'](仅独立的 cat) print(re.findall(r'\Bcat\B', text)) # ['cat'](1category 中的 cat)

5、常见应用场景实例
5.1、数据验证
1、手机号验证(中国大陆)
规则:以 1 开头,第 2 位为 3-9,后 9 位为数字(共 11 位)。
pythonimport re pattern = re.compile(r'^1[3-9]\d{9}$') print(pattern.match("13812345678")) # 匹配成功 print(pattern.match("12345678901")) # 匹配失败(第 2 位是 2)

2、邮箱验证
规则:用户名由字母、数字、下划线、中划线组成,域名含 1 个或多个
.。
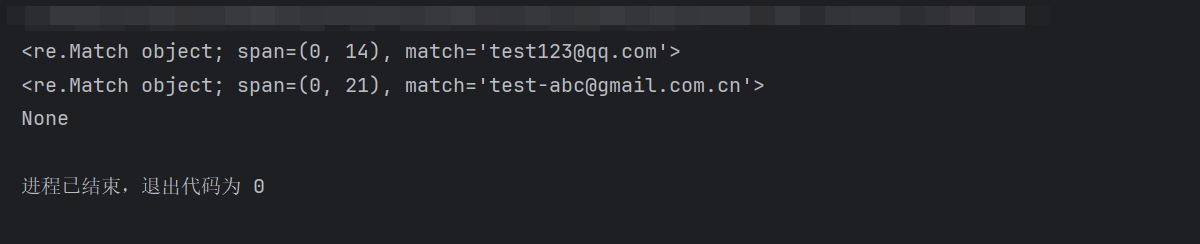
pythonimport re pattern = re.compile(r'^[a-zA-Z0-9_-]+@[a-zA-Z0-9_-]+\.[a-zA-Z0-9_-]+(\.[a-zA-Z0-9_-]+)*$') print(pattern.match("test123@qq.com")) # 匹配成功 print(pattern.match("test-abc@gmail.com.cn")) # 匹配成功 print(pattern.match("test@.com")) # 匹配失败(域名格式错误)
3、URL 验证(HTTP/HTTPS)
pythonimport re pattern = re.compile(r'^https?://[a-zA-Z0-9_-]+(\.[a-zA-Z0-9_-]+)*(:\d+)?(/[a-zA-Z0-9_.-]*)*(\?[a-zA-Z0-9_=&%-]*)?$') print(pattern.match("https://www.baidu.com/s?wd=python")) # 匹配成功 print(pattern.match("http://localhost:8080")) # 匹配成功

5.2、数据提取
1、提取 HTML 标签内容
pythonimport re html = "<h1>Python 正则</h1><p>正则表达式详解</p>" # 提取 <h1> 和 <p> 标签内的文本(非贪婪匹配) pattern = re.compile(r'<(h1|p)>(.*?)</\1>') # \1 引用标签名(避免匹配 <h1>...</p>) print(pattern.findall(html))

2、提取字符串中的日期
(格式:年 - 月 - 日)
pythonimport re text = "今天是 2025-11-25,明天是 2025-11-26,昨天是 2025/11/24" pattern = re.compile(r'(\d{4})-(\d{2})-(\d{2})') print(pattern.findall(text)) # [('2025', '11', '25'), ('2025', '11', '26')]

5.3、字符串替换
1、格式化日期
(将 年 / 月 / 日 改为 年 - 月 - 日)
pythonimport re text = "2025/11/25 2024/05/10" new_text = re.sub(r'(\d{4})/(\d{2})/(\d{2})', r'\1-\2-\3', text) print(new_text)

2、去除字符串中的所有空格
pythonimport re text = " Python 正则表达式 详解 " new_text = re.sub(r'\s+', '', text) print(new_text)

6、注意事项
- 正则中的元字符(如
.、*、()需用\转义(如\.匹配.);- Python 字符串中
\本身是转义字符,因此正则模式建议用r''(raw 字符串),避免双重转义(如r'\d'无需写成'\\d')。
- 当匹配包含嵌套结构的字符串(如 HTML 标签、括号)时,贪婪匹配可能导致匹配范围过大,需用非贪婪匹配
.*?。