😀嗨嗨嗨, 这里是一乐,今天又来折腾豆瓣书影音同步Notion啦,在这之前,先跟老朋友们同步下进度:之前写的虚拟货币 Chrome 插件,已经更到 0.0.4 版本啦!新增了 "点击直接打开 CoinGecko 官网" 的功能,还修复了一堆 AI 生成的小 BUG(关于怎么调教 AI 写代码,最近有新心得,你们感兴趣我单独开一篇讲~).没看过的小伙伴可以戳这里补补课[大龄程序员的失业自救之路------Chrome 插件从注册到审核全程踩坑总结](https://juejin.cn/post/7544388006721355830 "https://juejin.cn/post/7544388006721355830"),还是很有价值的.
言归正传!今天要分享的是我新折腾的「豆瓣→Notion 同步工具」
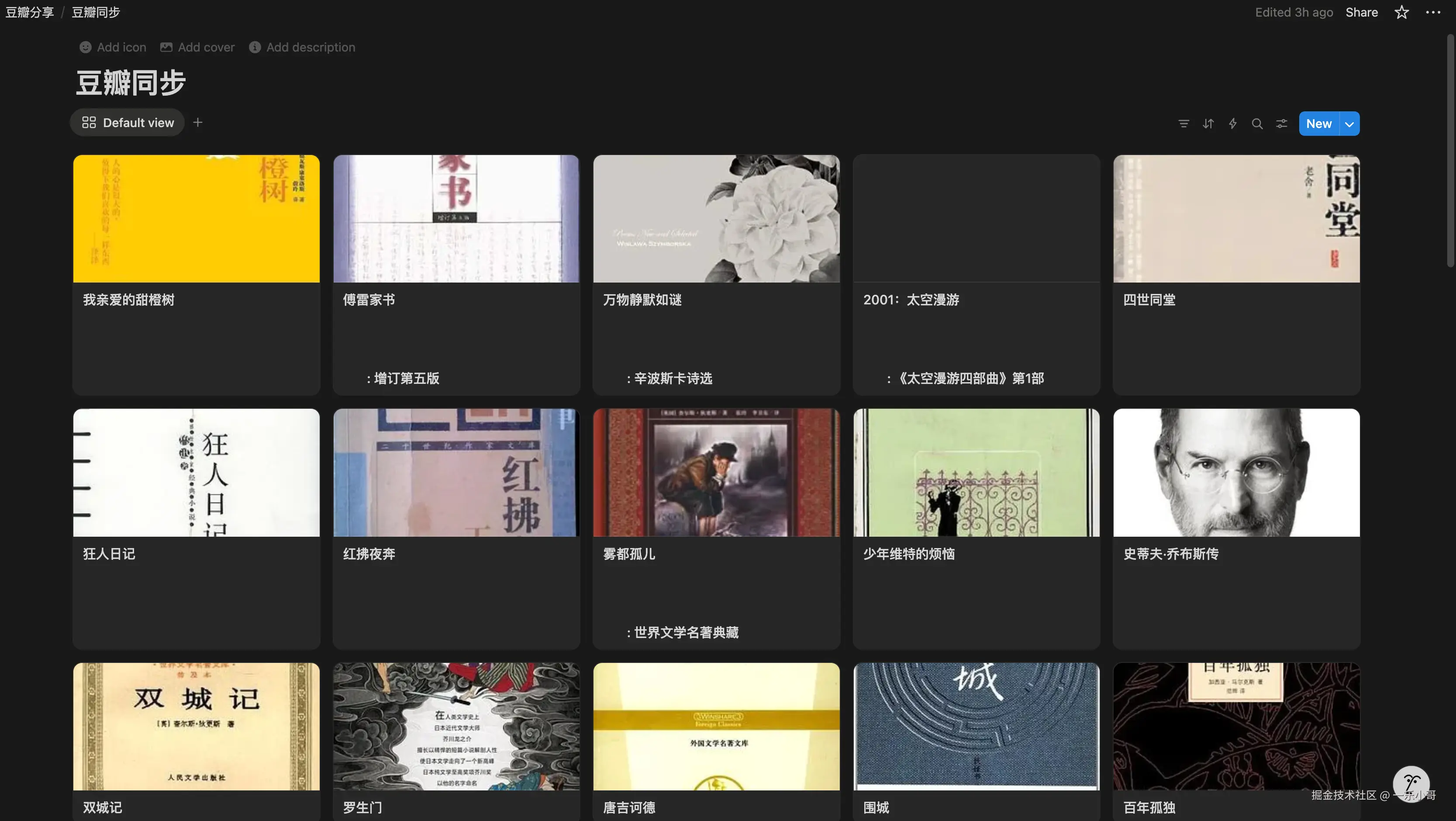
先上效果:同步后的 Notion 长这样!✅
我同步了我 "想看" 的书,每一条都带着豆瓣原链接,点进去就能跳转到豆瓣详情页,后续在 Notion 里做读书计划、加笔记都超方便~
一、先说明:为什么要搞这个同步工具?
- 手动同步太折磨:之前想把豆瓣 "已看" 影单整理到 Notion,复制标题、粘贴链接,10 条就花了 20 分钟,还容易漏;
- 怕数据丢:豆瓣这些年收益不稳定,打开 APP 全是广告,真担心哪天我的收藏记录突然没了,提前同步到 Notion 才放心;
- 找的工具不趁手:GitHub 上搜了几个同步脚本,要么配置文档写得模糊("填数据库 ID" 却不说在哪找),要么是chrome插件,还是得一个个点,干脆自己写一个。
二、准备工作:3 步搭好环境
1. 必备工具
- Python 3.9+(我用的 3.9,其他 3.x 版本应该也兼容);
- 豆瓣账号(需要登录,获取 Cookie);
- Notion 账号(需要创建 "集成",拿 Token)。
2. 项目结构
没那么复杂,核心就 4 个文件:
| 文件名 | 作用 |
|---|---|
douban.py |
抓取豆瓣数据(带节流、重试、增量早停) |
notion_sync.py |
Notion 交互(创建数据库、写入、去重) |
sync.py |
命令行入口(调同步逻辑) |
config.json |
配置文件(填 Cookie、Token、ID) |
3. 核心实现
我把核心功能拆成了 3 部分代码,每部分都加了详细注释,看不懂的地方可以私聊我哦~
1. 第一步:爬取豆瓣数据(douban.py关键代码)
主要负责从豆瓣抓 "标题、详情链接",还加了去重和防反爬(比如 User-Agent、超时控制):
python
import requests
from bs4 import BeautifulSoup
# 防反爬用的请求头,别改!改了可能被豆瓣封
HEADERS = {
"User-Agent": (
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/119.0.0.0 Safari/537.36"
)
}
# 豆瓣书/影/音的基础链接,按类型匹配
HOSTS = {
"book": "<https://book.douban.com>",
"movie": "<https://movie.douban.com>",
"music": "<https://music.douban.com>",
}
# 豆瓣状态对应:done=已看/已读,wish=想看/想读,doing=在看/在读
STATUS = {"done": "collect", "wish": "wish", "doing": "do"}
def fetch_douban_minimal(user_id: str, cookie: str, content_type: str = "movie", status: str = "done"):
"""
抓指定用户的豆瓣数据(一页)
:param user_id: 豆瓣数字ID(不是昵称!)
:param cookie: 豆瓣登录Cookie
:param content_type: 类型:book/movie/music
:param status: 状态:done/wish/doing
:return: 去重后的条目列表(含title和url)
"""
# 拼接请求链接
host = HOSTS.get(content_type, HOSTS["movie"]) # 默认抓电影
seg = STATUS.get(status, "collect") # 默认抓"已看"
url = f"{host}/people/{user_id}/{seg}?mode=grid" # grid模式页面更规整,好爬
# 加Cookie(必须登录才能抓个人收藏)
headers = dict(HEADERS)
headers["Cookie"] = cookie.strip() # 别漏了strip(),避免多余空格
# 发请求(超时15秒,防止卡着)
try:
r = requests.get(url, headers=headers, timeout=15)
r.raise_for_status() # 404/500会直接报错,方便排查
except Exception as e:
print(f"抓豆瓣数据报错:{e},先检查Cookie对不对!")
return []
# 解析页面,提取标题和链接
soup = BeautifulSoup(r.text, "html.parser")
items = []
for a_tag in soup.select("a"):
href = a_tag.get("href", "")
if "/subject/" in href: # 豆瓣条目链接都带/subject/
title = (a_tag.get("title") or a_tag.text).strip()
if title: # 过滤空标题
# 清理链接(去掉?后面的参数,只留基础链接)
clean_href = href.split("?")[0]
items.append({"title": title, "url": clean_href})
# 去重(按豆瓣链接去重,避免重复抓)
unique_items = {}
for item in items:
unique_items[item["url"]] = item
return list(unique_items.values())2. 第二步:同步到 Notion(notion_sync.py关键代码)
用Notion官方SDK写的,只需要传Token和数据库ID,就能自动创建条目:
python
from notion_client import Client
from typing import Dict, List
def create_notion_page_minimal(
token: str,
database_id: str,
douban_item: Dict[str, str]
) -> bool:
"""
往Notion数据库写一条豆瓣条目
:param token: Notion的Internal Integration Token
:param database_id: Notion数据库ID
:param douban_item: 豆瓣条目(含title和url)
:return: 成功返回True,失败返回False
"""
# 初始化Notion客户端
try:
notion = Client(auth=token)
except Exception as e:
print(f"Notion客户端初始化失败:{e},检查Token是不是secret_开头!")
return False
# 创建页面(注意:Notion数据库字段要和这里的"Name""URL"对应!)
try:
notion.pages.create(
parent={"database_id": database_id},
properties={
"Name": { # 这个"Name"是Notion数据库的"标题字段名",要和你的数据库对应
"title": [{"text": {"content": douban_item["title"]}}]
},
"豆瓣链接": { # 这个"豆瓣链接"是我在Notion里建的"URL字段名",你们可以改
"url": douban_item["url"]
}
}
)
print(f"成功同步:{douban_item['title']}")
return True
except Exception as e:
print(f"同步到Notion失败:{e},可能是数据库没共享给集成!")
return False
# 批量同步的函数(一次同步多个条目)
def batch_sync_to_notion(
token: str,
database_id: str,
douban_items: List[Dict[str, str]]
) -> None:
for item in douban_items:
create_notion_page_minimal(token, database_id, item)3.第三步:整合调度(sync.py关键代码)
python
import json
from douban import fetch_douban_minimal
from notion_sync import batch_sync_to_notion
def main():
# 读配置文件(config.json要自己填哦~)
try:
with open("config.json", "r", encoding="utf-8") as f:
config = json.load(f)
except Exception as e:
print(f"读配置文件报错:{e},先检查config.json在不在项目文件夹里!")
return
# 从配置里拿参数
douban_user = config.get("douban_user", "") # 豆瓣数字ID
douban_cookie = config.get("douban_cookie", "") # 豆瓣Cookie
notion_token = config.get("notion_token", "") # Notion Token
notion_database_id = config.get("notion_database_id", "") # Notion数据库ID
# 检查必填配置(少一个都不行)
if not all([douban_user, douban_cookie, notion_token, notion_database_id]):
print("⚠️ 配置没填全!douban_user、douban_cookie、notion_token、notion_database_id都要填!")
return
# 这里改同步类型和状态(比如想同步电影"已看",就把content_type改成movie,status改成done)
douban_items = fetch_douban_minimal(
user_id=douban_user,
cookie=douban_cookie,
content_type="book", # 可选:book/movie/music
status="wish" # 可选:wish(想看/想听)、done(已看/已听)、doing(在看/在听)
)
if not douban_items:
print("没抓到豆瓣数据,先检查Cookie和用户ID对不对!")
return
# 批量同步到Notion
print(f"共抓到{len(douban_items)}条数据,开始同步到Notion...")
batch_sync_to_notion(notion_token, notion_database_id, douban_items)
print("同步完成!去Notion看看吧~")
if __name__ == "__main__":
main()四、最关键的配置:2 个核心信息怎么拿?避坑指南来了!⚠️
config.json是唯一要改的文件,里面的 4 个参数,我一步步教你们怎么拿
1. 豆瓣ID和Cookie
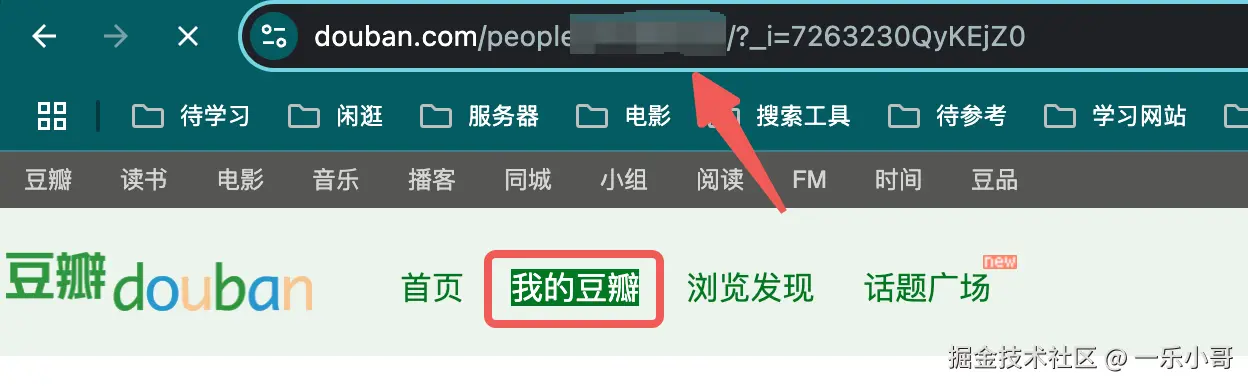 进入豆瓣,点击我的豆瓣,图中我打码部分就是你的豆瓣ID啦~
进入豆瓣,点击我的豆瓣,图中我打码部分就是你的豆瓣ID啦~ 
cookie的话,大家都是程序员,就不用我教了吧😈(豆瓣的控制台还有招聘信息呢~
2. Notion集成
NotionPageId
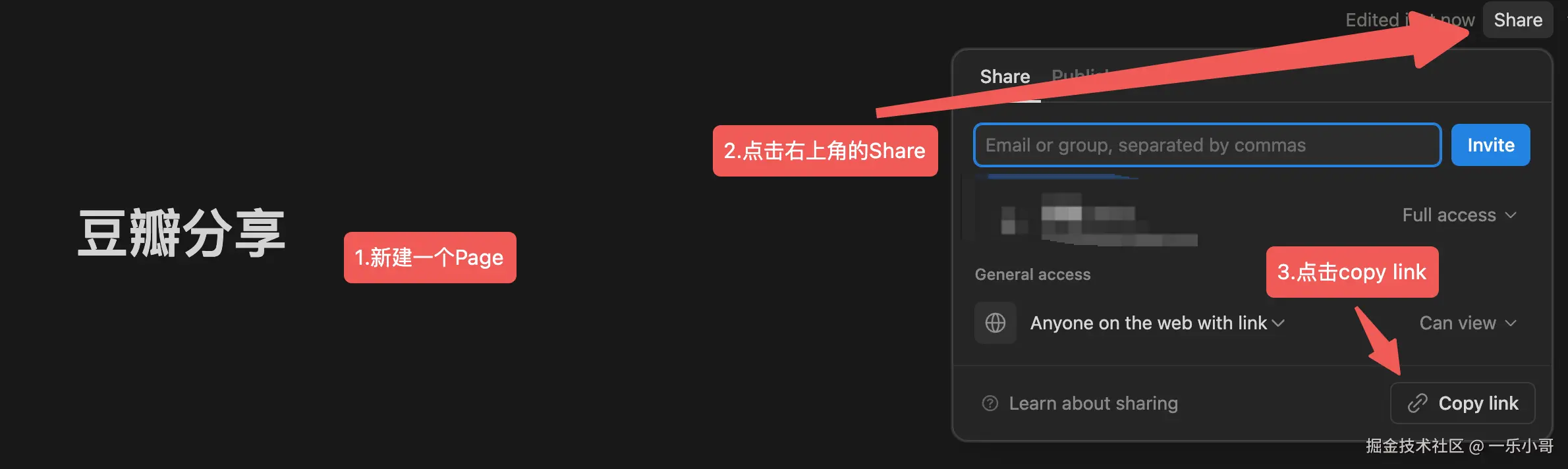 把上面copy的link粘贴下来,链接里的
把上面copy的link粘贴下来,链接里的https://www.notion.so/xxxxxx?v=xxx,中间的 xxxxxx 就是 ID(32/36 位字符);
Notion Token
点击进入notionAPI后台
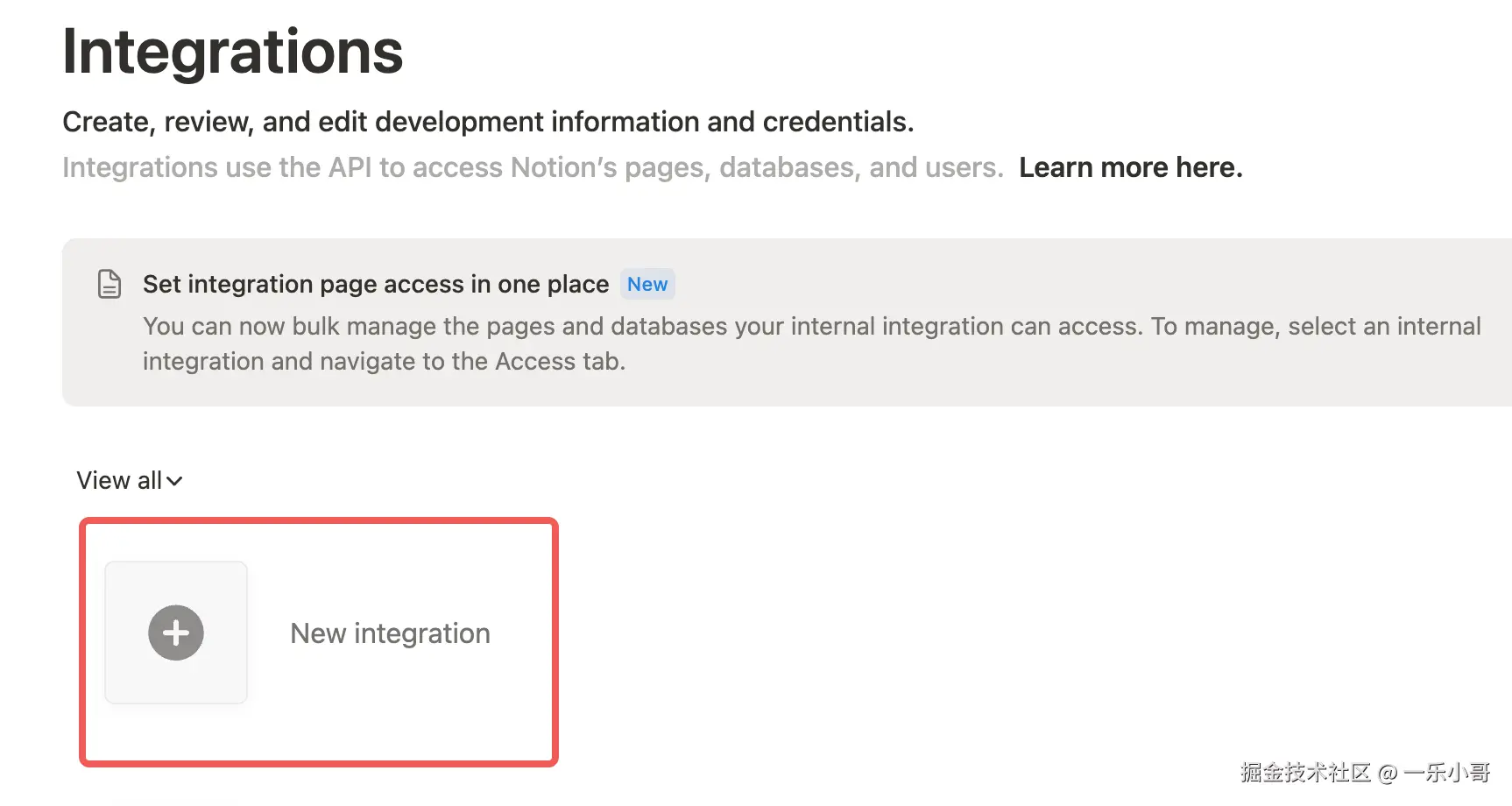 点击新建集成
点击新建集成
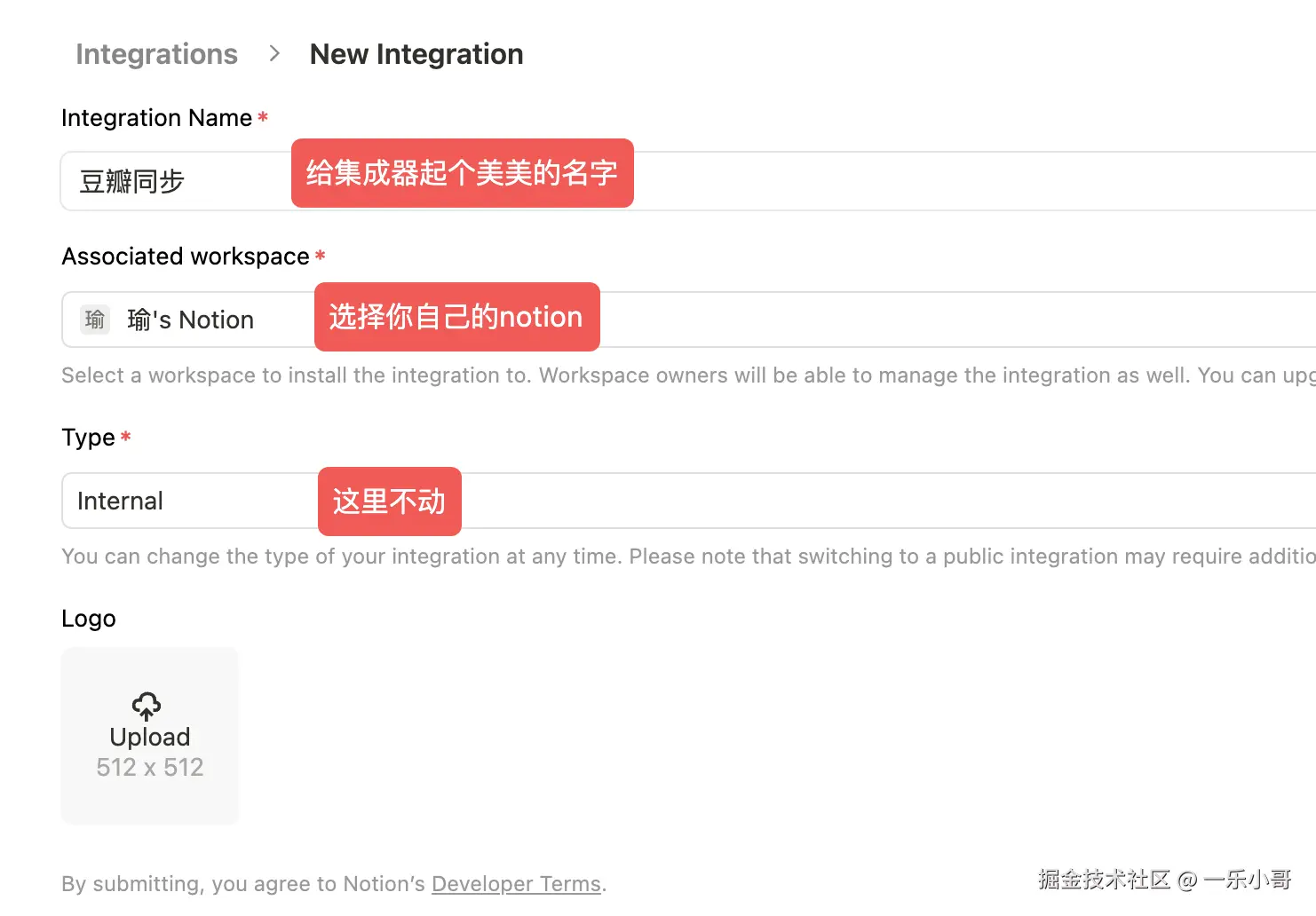
如图创建你的集成器
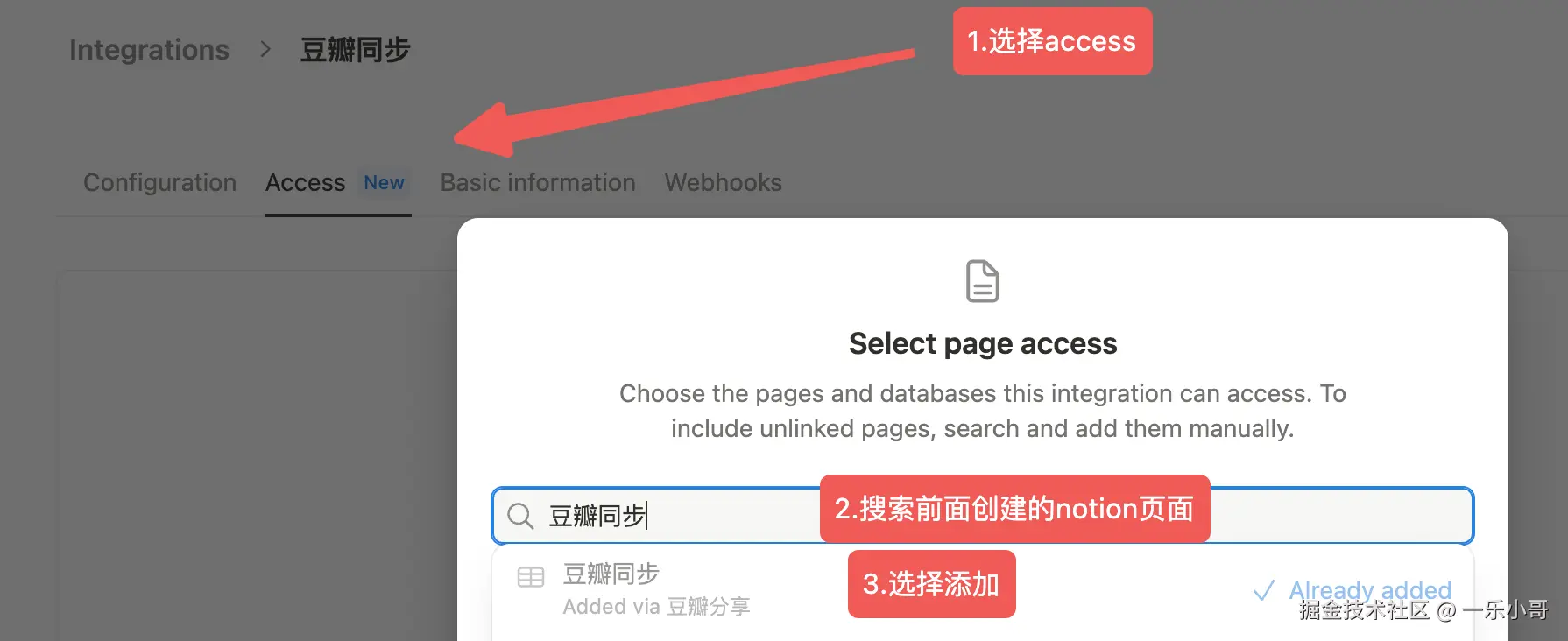
如图给你的集成器添加前面新建的notion页面的访问权限(记得一定要点击保存哦
五、后续
这个小工具我个人还是挺满意的,就是现在个性化太强,没能达到通用的工具效果,不知道小伙伴们有没有相关需求,如果有的话我就加班加点搞出来,我能想到的优化的地方有:
- 优化Notion页面,提供notion的模版;
- 增量同步:只同步 "上次同步后新增的条目",不用每次都全量抓;
- 定时同步:每周自动同步一次;
- 简单 GUI:不用改代码,填配置点按钮就能跑(适合不熟悉命令行的小伙伴)。
你们最想要哪个功能?或者有其他需求,评论区告诉我~需求多的话,我这周搞出来,到时候再分享一次!
最后再提醒 2 个小细节:
- 敏感信息别泄露 :
config.json里的 Cookie 和 Token,千万别提交到 GitHub,也别发给别人(Cookie 能登录你的豆瓣,Token 能操作你的 Notion); - 别爬太快:我在代码里加了节流,抓豆瓣数据时间隔会控制在 1 秒以上,别自己改快了,容易被豆瓣封 IP。
💡 有任何配置或运行问题,都可以在评论区或私信留言,我看到会回复~咱们一起把这个小工具越搞越好!