目录
[1. 导入必要的库](#1. 导入必要的库)
[2. 数据准备部分](#2. 数据准备部分)
[3. 设备配置](#3. 设备配置)
[5. 模型训练配置](#5. 模型训练配置)
[6. 模型训练过程](#6. 模型训练过程)
[7. 模型测试与词向量提取](#7. 模型测试与词向量提取)
[8. 保存和加载词向量](#8. 保存和加载词向量)
简介
在自然语言处理(NLP)的广阔领域中,语言转换方法是连接不同语言、打破沟通壁垒的关键桥梁,也是初学者开启 NLP 学习之旅的重要入门知识点。无论是日常使用的翻译软件,还是跨语言信息检索、多语言文本分析等专业场景,都离不开高效的语言转换技术。
为了让大家轻松迈入 NLP 语言转换的大门,本博客将以 "第一课" 的视角,用通俗易懂的语言拆解语言转换的核心逻辑。我们会从最基础的规则式转换讲起,带大家了解基于词典和语法规则实现简单语言转换的原理,感受早期技术的朴实思路;随后深入当下主流的统计机器翻译与神经机器翻译,对比不同技术路径的优势与局限,比如统计方法对数据依赖性、神经方法在语义理解上的突破等。
一、语言模型
之前说过在机器学习中使用统计的方法转换词向量。自然语言处理(NLP)中的语言转换方法主要涉及将一种形式的语言数据转换为另一种形式,这种转换可以是不同语言之间的翻译,也可以是语言到其他形式数据(如向量、标签等)的转换。
1.统计语言模型
统计语言模型存在的问题:
1、由于参数空间的爆炸式增长,它无法处理(N>3)的数据。
2、没有考虑词与词之间内在的联系性。例如,考虑"the cat is walking in the bedroom"这句话。如果我们在训练语料中看到了很多类似"the dog is walking in the bedroom"或是"the cat is running in the bedroom"这样的句子;那么,哪怕我们此前没有见过这句话"the cat is walking in the bedroom",也可以从"cat"和"dog"("walking"和"running")之间的相似性,推测出这句话的概率。
2.神经语言模型
2.1.含义与方法
神经语言模型(Neural Language Model, NLM)是一种基于神经网络技术的语言模型,它利用深度学习来模拟自然语言的分布特性,捕捉词汇之间的关系,以更精确地估计自然语言中词序列出现的概率。
词向量化:在处理自然语言时,通常将词语或字做向量化处理。这可以通过one-hot编码、词嵌入(如Word2Vec、GloVe等)等技术实现。其中,词嵌入技术能够捕捉词汇之间的语义关系,使得相似的词汇在向量空间中具有相近的表示。
维度灾难:在处理大规模文本数据时,one-hot编码会导致维度灾难问题。为了解决这个问题,神经语言模型通常使用词嵌入技术将高维的词表示转换为低维的词表示。
训练过程:神经语言模型通过训练大量文本数据来学习词汇和句子的概率分布。在训练过程中,模型会不断调整其参数以最小化预测误差。常见的神经语言模型包括循环神经网络(RNN)、长短时记忆网络(LSTM)、Transformer等。
2.2.one-hot编码
One-hot编码,又称一位有效编码或独热编码,是一种将分类变量(如类别或标签)转换为数值表示的方法。在机器学习和数据处理中,分类变量通常需要被转换为数值形式,以便可以输入到算法中进行训练或预测。
例如我们有一句话为:"我爱北京天安门",我们分词后对其进行one-hot编码,结果可以是:
- "我": 1,0,0,0
- "爱": 0,1,0,0
- "北京": 0,0,1,0
- "天安门": 0,0,0,1
如果需要对语料库中的每个字进行one-hot编码如何实
1、统计语料库中所有的词的个数,例如4960个词。
2、按顺序依次给每个词进行one-hot编码,例如第1个词为:1,0,0,0,0,0,0,....,0,最后1个词为: 0,0,0,0,0,0,0,....,1
存在的问题?
矩阵为非常稀疏,出现维度灾难。
如何解决维度灾难问题 ?
通过神经网络训练,将每个词都映射到一个较短的词向量上来。这个较短的词向量维度是多大呢? 一般需要在训练时自己来指定。现在很常见的例如300维。
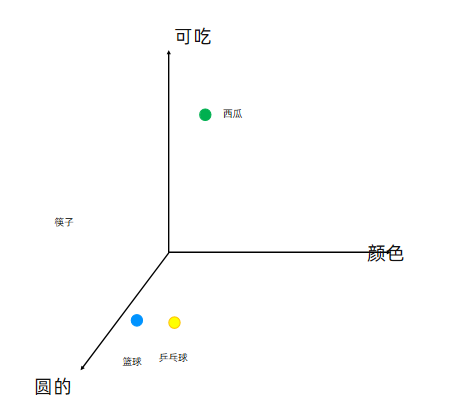
2.3.词嵌入word2vec
这种将高维度的词表示转换为低维度的词表示的方法,我们称之为词嵌入(word embedding)。

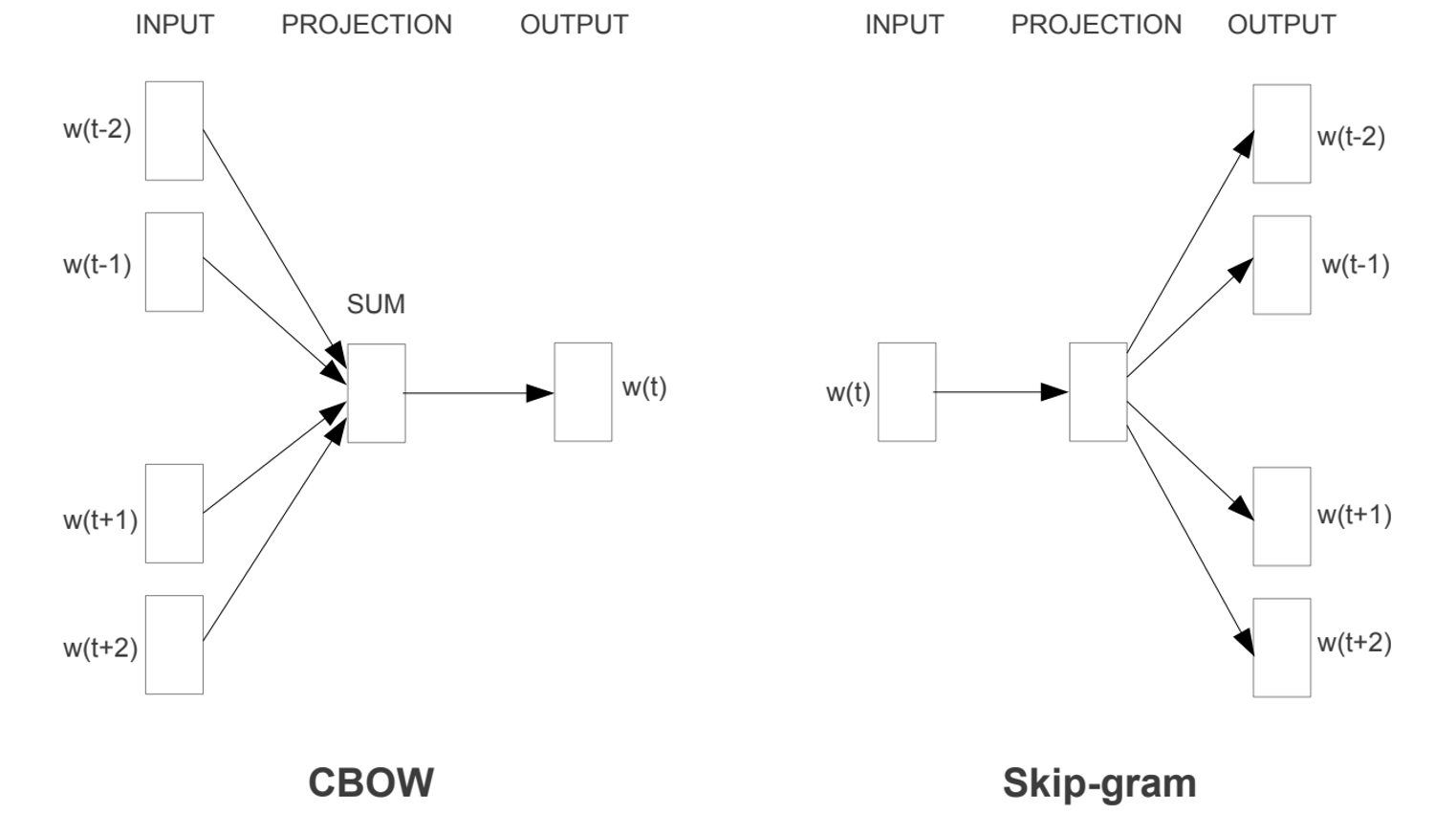
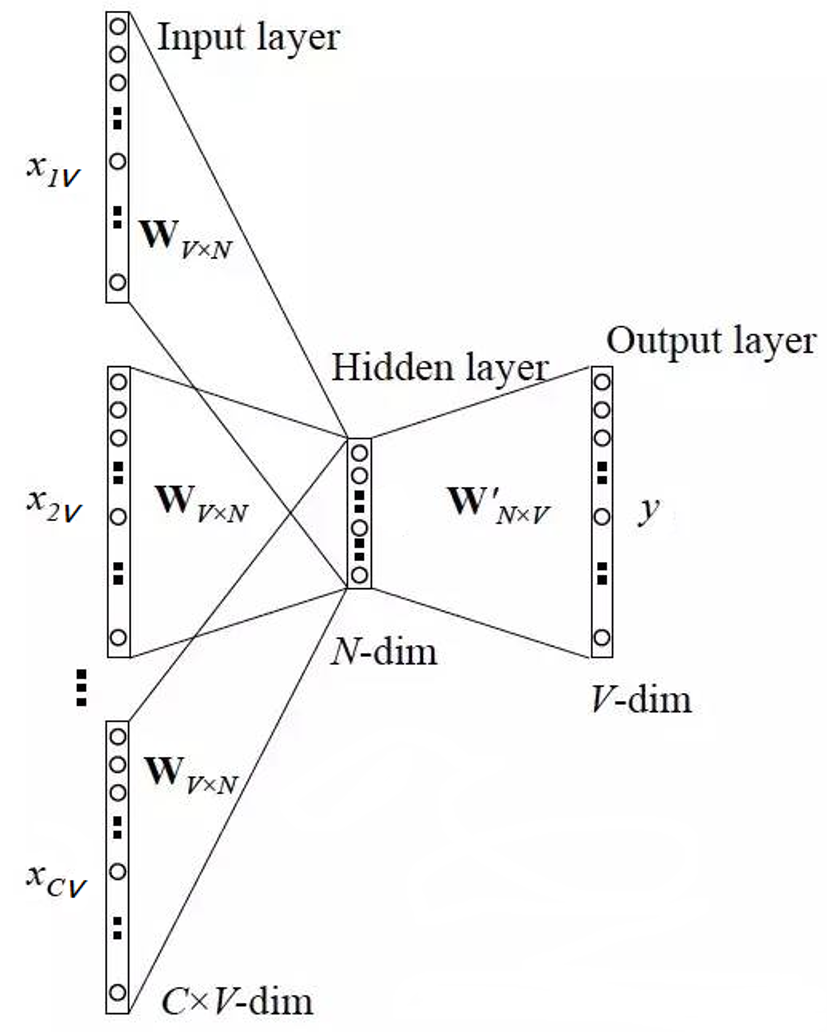
模型的训练过程:
- 1、当前词的上下文词语的one-hot编码输入到输入层。
- 2、这些词分别乘以同一个矩阵WV*N后分别得到各自的1*N 向量。
- 3、将多个这些1*N 向量取平均为一个1*N 向量。
- 4、将这个1*N 向量乘矩阵 W'V*N ,变成一个1*V 向量。
- 5、将1*V 向量softmax归一化后输出取每个词的概率向量1*V
- 6、将概率值最大的数对应的词作为预测词。
- 7、将预测的结果1*V 向量和真实标签1*V 向量(真实标签中的V个值中有一个是1,其他是0)计算误差
- 8、在每次前向传播之后反向传播误差,不断调整 WV*N和 W'V*N矩阵的值。
假定语料库中一共有4960个词,则词编码为4960个01组合 现在压缩为300维

二、代码分析
1. 导入必要的库
python
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from tqdm import tqdm
import numpy as np2. 数据准备部分
python
raw_text = """called a program. People create programs to direct processes. In effect, we conjure the spirits of the computer with our spells."""
raw_text = raw_text.split() # 将文本按空格分割成单词列表首先定义了一段原始文本,并将其分割成单词列表。
python
# 创建词汇表
vocab = set(raw_text) # 去除重复词
vocab_size = len(vocab) # 词汇表大小
# 创建词到索引和索引到词的映射
word_to_idx = {word: i for i, word in enumerate(vocab)}
idx_to_word = {i: word for i, word in enumerate(vocab)}这部分构建了词汇表,将每个唯一的单词映射到一个整数索引,方便后续处理。
python
# 准备训练数据
data = []
CONTEXT_SIZE = 2 # 上下文窗口大小,左右各2个词
for i in range(CONTEXT_SIZE, len(raw_text) - CONTEXT_SIZE):
# 获取左右各CONTEXT_SIZE个词作为上下文
context = (
[raw_text[i - (CONTEXT_SIZE - j)] for j in range(CONTEXT_SIZE)]
+ [raw_text[i + j + 1] for j in range(CONTEXT_SIZE)]
)
target = raw_text[i]
data.append((context, target))这里构建了训练样本,每个样本由上下文(目标词前后各 2 个词)和目标词组成。例如 "People create programs to direct" 中,上下文是 "People", "create", "to", "direct",目标词是 "programs"。
python
def make_context_vector(context, word_to_idx):
idxs = [word_to_idx[w] for w in context]
return torch.tensor(idxs, dtype=torch.long)这个函数将上下文词转换为对应的索引张量,便于输入模型。
3. 设备配置
python
device = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"
print(f"使用设备: {device}")自动选择可用的计算设备(GPU 优先,没有则用 CPU)
python
class CBOW(nn.Module):
def __init__(self, vocab_size, embedding_dim, context_size):
super(CBOW, self).__init__()
self.embeddings = nn.Embedding(vocab_size, embedding_dim) # 词嵌入层
# 投影层,输入维度为上下文词嵌入拼接后的维度
self.proj = nn.Linear(embedding_dim * 2 * context_size, 128)
self.output = nn.Linear(128, vocab_size) # 输出层,预测目标词
def forward(self, inputs):
# 获取嵌入向量,形状: (context_size*2, embedding_dim)
embeds = self.embeddings(inputs)
# 将所有上下文词的嵌入向量拼接起来,形状: (1, context_size*2*embedding_dim)
embeds = embeds.view(1, -1)
out = F.relu(self.proj(embeds)) # 经过投影层和激活函数
out = self.output(out) # 输出层
nll_prob = F.log_softmax(out, dim=-1) # 计算对数softmax概率
return nll_probCBOW 模型的原理是:给定上下文词,预测中间的目标词。模型包含三个主要部分:
- 词嵌入层:将每个词的索引转换为低维向量表示
- 投影层:将上下文词的嵌入向量进行处理
- 输出层:预测目标词的概率分布
5. 模型训练配置
python
# 模型参数
EMBEDDING_DIM = 10 # 词向量维度
model = CBOW(vocab_size, EMBEDDING_DIM, CONTEXT_SIZE).to(device) # 初始化模型并移动到指定设备
optimizer = optim.Adam(model.parameters(), lr=0.001) # 优化器
loss_function = nn.NLLLoss() # 损失函数,负对数似然损失配置了模型的超参数、优化器和损失函数。
6. 模型训练过程
python
losses = []
model.train() # 进入训练模式
for epoch in tqdm(range(200), desc="训练进度"): # 训练200轮
total_loss = 0
for context, target in data:
# 准备数据
context_vector = make_context_vector(context, word_to_idx).to(device)
target = torch.tensor([word_to_idx[target]]).to(device)
# 前向传播
model.zero_grad() # 清零梯度
train_predict = model(context_vector)
# 计算损失
loss = loss_function(train_predict, target)
# 反向传播和优化
loss.backward() # 反向传播计算梯度
optimizer.step() # 更新参数
total_loss += loss.item()
losses.append(total_loss) # 记录每轮的总损失
print("损失变化:", losses)训练过程包括:
- 准备输入数据和目标值
- 前向传播得到预测结果
- 计算损失
- 反向传播更新模型参数
- 记录每轮的损失,用于观察训练效果
7. 模型测试与词向量提取
python
# 测试模型预测
context = ['People', 'create', 'to', 'direct']
context_vector = make_context_vector(context,word_to_idx).to(device)
model.eval() # 进入测试模式
predict = model(context_vector)
max_idx = predict.argmax(1) # 获取预测概率最大的词的索引
print(max_idx) # 输出预测结果的索引使用训练好的模型进行预测,对于上下文 "People", "create", "to", "direct",模型应该能预测出 "programs"。
python
# 获取词向量
print("CBOW embedding'weight=", model.embeddings.weight) # 输出嵌入层权重
W = model.embeddings.weight.cpu().detach().numpy() # 将权重转换为numpy数组
# 生成词嵌入字典
word_2_vec = {}
for word in word_to_idx.keys():
# 词向量矩阵中某个词的索引所对应的行即为该词的词向量
word_2_vec[word] = W[word_to_idx[word], :]
print('结束')训练完成后,嵌入层的权重就是我们需要的词向量。这里将其提取出来,构建一个 {单词:词向量} 的字典。
8. 保存和加载词向量
python
# 保存训练后的词向量为npz文件
np.savez('word2vec实现.npz', file_1 = W)
data = np.load('word2vec实现.npz')
print(data.files) # 输出保存的文件内容最后将词向量保存到文件中,以便后续使用。
总结来说,这段代码实现了一个简单的 CBOW 模型,通过给定的上下文预测目标词,在训练过程中学习到的词嵌入(embedding)就是我们需要的词向量,这些词向量能够捕捉词语之间的语义关系。