
一、AI 时代的数据库范式跃迁:SeekDB 的诞生背景
1.1 传统数据架构的致命瓶颈
生成式 AI 的爆发式增长正在重塑企业的数据处理逻辑,但 MIT 研究显示,超 95% 的企业 AI 项目因三大核心问题难以落地:多模态数据割裂导致的 "数据孤岛"、跨系统链路冗长引发的延迟风险、权限管理复杂带来的安全隐患。在金融反欺诈、政务智能响应等关键场景中,这些问题尤为突出 ------ 当需要同时处理交易标量数据、用户行为文本、设备位置 GIS 信息与历史欺诈样本向量时,传统架构需串联关系型数据库、搜索引擎、向量库等多套系统,不仅使响应延迟突破秒级,更可能因权限校验漏洞引发数据泄露。
Gartner 的预测则揭示了市场的迫切需求:到 2028 年,支持生成式 AI 的数据库支出将达 2180 亿美元,占整体数据库市场的 74%。这一数据背后,是企业对 "数据 ×AI" 融合架构的强烈渴求 ------ 既需要数据库具备传统事务一致性,又需原生支持 AI 时代的多模检索与实时推理。
1.2 SeekDB 的定位:AI 原生的数据入口层
2025 年 11 月 18 日,OceanBase 正式发布并开源首款 AI 数据库 SeekDB,标志着其 "数据 ×AI" 战略落地的关键一步。与传统数据库的功能叠加不同,SeekDB 是专为 AI 时代重构的原生架构,继承 OceanBase 十余年淬炼的工程化能力,同时实现了 "更轻量、更敏捷" 的设计目标。正如 OceanBase CEO 杨冰所言:"SeekDB 希望探索数据库在 AI 时代的范式跃迁,成为大模型与私有数据融合计算的'实时入口层'。"
这种定位决定了 SeekDB 的核心价值:打破 "存储 - 检索 - 推理" 的割裂链路,在单一数据库内核中实现事务处理(TP)、分析计算(AP)与 AI 混合搜索的一体化支撑,让数据从 "被动存储" 转向 "主动赋能" 智能体。
二、SeekDB 核心技术特性深度解析
2.1 多模数据统一存储与混合搜索
2.1.1 全类型数据兼容能力
SeekDB 的核心突破之一是实现了标量、向量、文本、JSON 与 GIS 地理数据的统一存储引擎。传统架构中,这些数据通常分散在 MySQL(标量)、Elasticsearch(文本)、Milvus(向量)、MongoDB(JSON)等系统中,而 SeekDB 通过重构存储层,采用分层列式存储结构实现了多模数据的原生融合:
- 标量数据:沿用 OceanBase 成熟的事务引擎,支持 ACID 一致性与索引优化;
- 向量数据:采用自研的高维向量存储结构,支持 128-4096 维向量,适配 Transformer 模型输出;
- 文本数据:集成中文分词与语义理解模块,支持多粒度全文检索;
- GIS 数据:兼容 WKT/WKB 格式,支持空间索引与距离计算。
这种架构设计使 SeekDB 能够应对复杂场景需求。以金融反欺诈为例,可直接执行 "近 7 天交易超 5 万元(标量过滤)、位置异常(GIS 检索)且行为类似历史欺诈样本(向量匹配)" 的跨类型查询,无需任何跨系统调用。
2.1.2 "粗排 + 精排" 混合检索机制
为解决多模数据检索的性能与精度平衡问题,SeekDB 设计了多阶段检索架构(如图 1 所示):
- 前置过滤层:通过标量索引(如交易金额、时间范围)快速筛选出符合条件的候选集,将数据量压缩至原规模的 1%-5%;
- 粗排阶段:采用基于 IVF(倒排文件)的向量检索算法,在候选集中快速匹配 Top-K 相似结果,耗时控制在毫秒级;
- 精排阶段:融合文本语义相似度、空间距离与标量权重因子,通过自研的混合评分模型生成最终结果,确保检索精度。
这种机制在实测中表现优异:针对 1 亿条多模数据(含 100 万向量样本)的混合查询,平均响应时间仅 87ms,较 "Elasticsearch+Milvus" 组合架构提升 4.2 倍。
2.2 极致轻量化与灵活部署
2.2.1 突破资源限制的极简部署
SeekDB 颠覆了传统分布式数据库的资源门槛,最低仅需 1 核 CPU、2GB 内存即可运行,远超同类产品的硬件要求(如表 1 所示)。这种轻量化特性源于两大技术优化:
- 内核裁剪:移除传统数据库中 AI 场景非必需的复杂功能模块,内核体积压缩至 20MB 以下;
- 内存管理:采用零拷贝(Zero-Copy)与内存池技术,避免频繁 GC 带来的性能波动。
表 1 主流 AI 数据库部署资源对比
|--------------|-----------|--------|------|---------------------|
| 产品 | 最低 CPU 要求 | 最低内存要求 | 启动时间 | 部署方式 |
| SeekDB | 1 核 | 2GB | 3 秒 | 嵌入式 / Client-Server |
| InfluxDB 2.7 | 2 核 | 4GB | 15 秒 | Client-Server |
| QuestDB 7.3 | 2 核 | 8GB | 10 秒 | Client-Server |
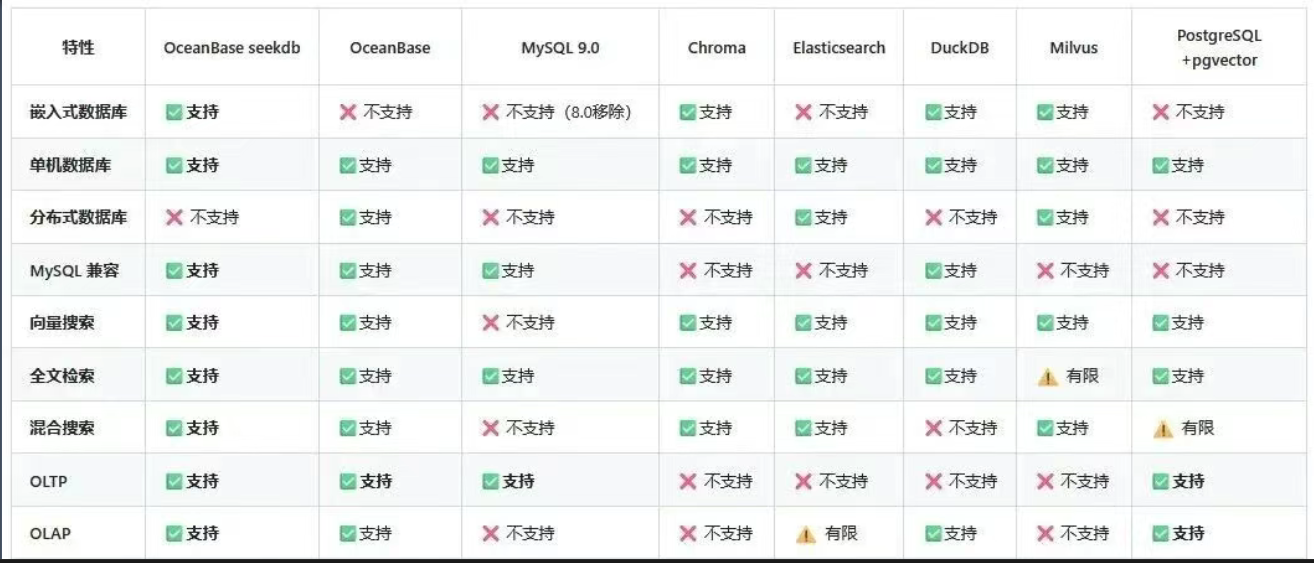
seekdb 与其他数据库的特性对比。
部署流程更是实现 "开箱即用",通过 pip 命令即可完成安装:
# 安装SeekDB核心包
pip install oceanbase-seekdb
# 启动嵌入式实例
seekdb start --mode embedded --data-dir ./seekdb_data
2.2.2 双模式适配多元场景
SeekDB 支持嵌入式与 Client-Server 双部署模式,覆盖从边缘设备到企业级集群的全场景需求:
- 嵌入式模式:直接集成至智能 Agent、本地开发工具中,无需独立服务进程,适合边缘计算与轻量化 AI 应用;
- Client-Server 模式:支持分布式集群部署,最大可扩展至 100 + 节点,提供金融级高可用,满足企业级大规模数据处理需求。
两种模式可无缝切换,数据格式完全兼容,极大降低了应用从原型到量产的迁移成本。
2.3 全栈 AI 生态兼容
2.3.1 多框架无缝集成
SeekDB 全面兼容 30 余种主流 AI 框架,涵盖模型训练、推理部署与应用开发全链路:
- 向量生成:支持 Hugging Face Transformers、Sentence-BERT 等模型的向量输出直接写入;
- 智能编排:适配 LangChain、LlamaIndex 等框架,可作为其默认向量存储与检索引擎;
- 应用开发:兼容 Dify、FastAPI 等低代码平台,加速 AI 原生应用搭建。
以 LangChain 集成为例,仅需三行代码即可完成知识库构建:
from langchain.vectorstores import SeekDB
from langchain.embeddings import HuggingFaceEmbeddings
# 初始化SeekDB向量存储
embeddings = HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2")
vector_store = SeekDB(embedding_function=embeddings, db_path="./kb_data")
# 加载文档并构建知识库
with open("financial_report.pdf", "r") as f:
docs = [f.read()]
vector_store.add_texts(docs) # 自动完成文本分词、向量生成与存储
2.3.2 开源生态与工具链
SeekDB 以 Apache 2.0 协议全球开源,代码托管于 GitHub,同时同步启用 oceanbase.ai 域名提供开发者服务。配套开源的两大工具进一步降低了 AI 应用开发门槛:
- Power RAG 智能文档解析框架:支持 PDF、Word、Markdown 等 15 种格式文档的自动解析,能提取表格、公式等结构化信息,解析准确率达 98.7%;
- Power Mem 分层记忆架构:在 LoCoMo Benchmark 中以 73.70 分登顶 SOTA,通过短期记忆、长期记忆与知识蒸馏的分层管理,使大模型 token 消耗降低 96%。
2.4 与 OceanBase 4.4 一体化融合
作为 OceanBase 生态的核心成员,SeekDB 可平滑融入 OceanBase 4.4 一体化版本。该版本首次将 TP、AP 与 AI 能力集成于单一内核,实现了三大价值:
- 数据零迁移:传统业务数据可直接用于 AI 检索,无需 ETL 过程;
- 权限统一管理:基于 OceanBase 成熟的 RBAC 权限体系,实现多模数据的精细化访问控制;
- 多云部署兼容:支持公有云、私有云与混合云部署,满足政务、金融等行业的数据本地化需求。
这种一体化架构使企业无需在后期面临架构重构风险,为 "业务智能升级" 提供了平滑演进路径。
三、技术架构:SeekDB 的底层实现原理
3.1 整体架构设计
SeekDB 采用分层架构设计,自下而上分为存储层、引擎层、接口层与生态层(如图 2 所示),各层职责清晰且解耦度高。
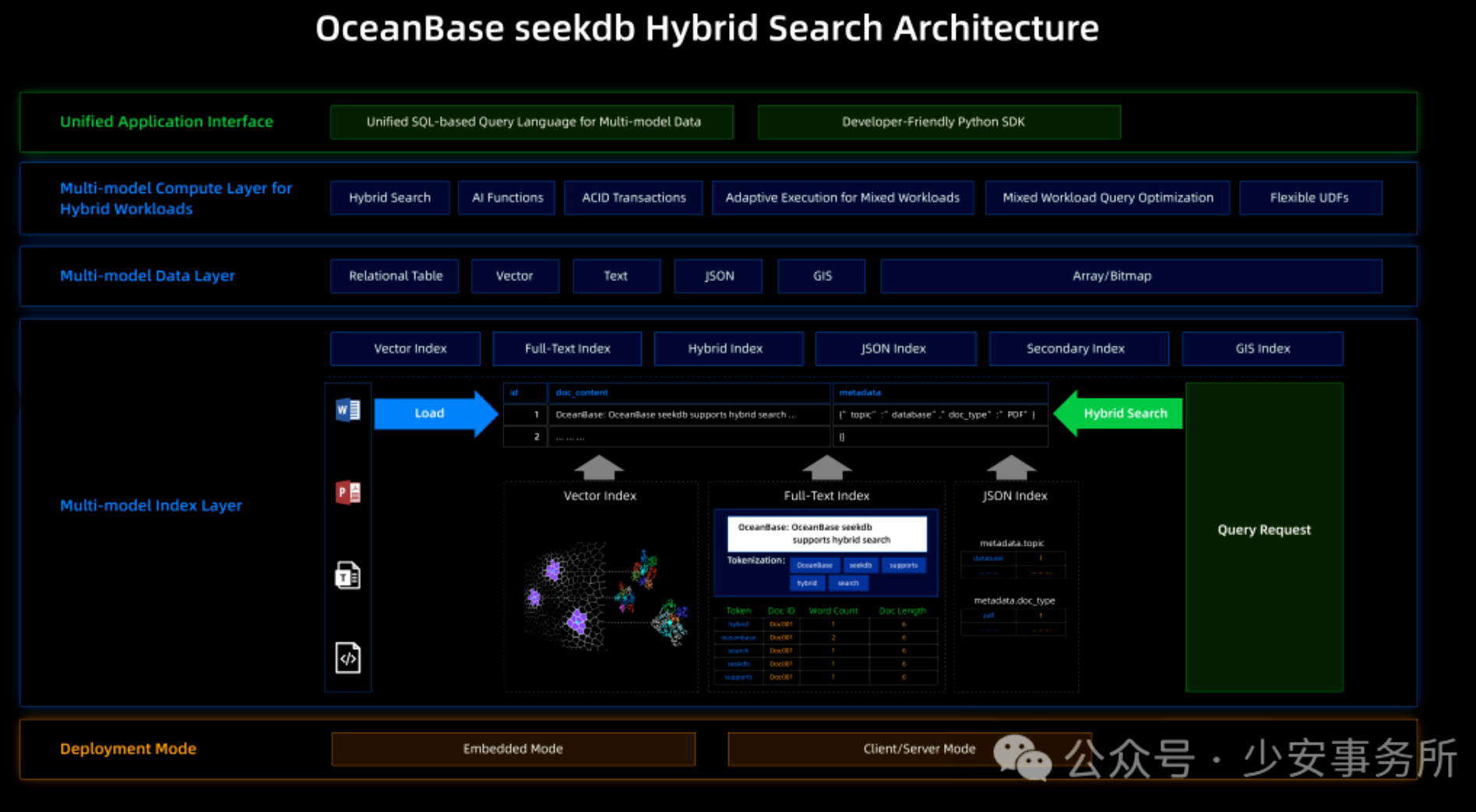
3.1.1 存储层:多模数据的统一基石
存储层是 SeekDB 实现多模融合的核心,采用 "通用存储 + 专用索引" 的设计思路:
- 通用存储引擎:基于 OceanBase 的 LSM-Tree(日志结构合并树)优化而来,支持多版本并发控制(MVCC),确保事务一致性;
- 专用索引模块:
-
- 标量索引:B + 树索引,适配数值与字符串类型的快速查询;
-
- 向量索引:IVF-PQ(倒排文件 + 乘积量化)索引,支持高维向量的快速匹配;
-
- 文本索引:倒排索引 + BM25 算法,支持分词级与短语级检索;
-
- GIS 索引:R 树索引,支持空间范围查询与距离计算。
存储层通过统一的元数据管理模块,实现不同类型数据的协同存储与一致性维护。
3.1.2 引擎层:计算与推理的核心动力
引擎层集成了事务引擎、分析引擎与 AI 引擎三大核心能力:
- 事务引擎:沿用 OceanBase 的分布式事务协议,支持 ACID 特性与分布式锁,确保标量数据的写入一致性;
- 分析引擎:支持 SQL 与 Python 混合查询,可直接在数据库内执行数据分析与特征工程;
- AI 引擎:集成向量生成、相似度计算与模型推理功能,支持本地模型与云模型无缝切换。
三大引擎通过统一的任务调度器协同工作,实现 "数据存储 - 特征提取 - 模型推理 - 结果输出" 的端到端处理。
3.1.3 接口层:多协议兼容的访问入口
接口层提供多元化的访问方式,适配不同开发场景:
- 关系型接口:兼容 MySQL 协议,支持标准 SQL 查询;
- 向量接口:提供 REST API 与 Python SDK,支持向量的增删改查;
- AI 框架接口:内置 LangChain、Hugging Face 等框架的适配插件;
- 流处理接口:支持 Kafka、Pulsar 等消息队列的实时数据接入。
这种多接口设计使 SeekDB 能够无缝融入现有技术栈,降低迁移成本。
3.2 关键技术突破
3.2.1 向量 - 标量协同索引
针对多模数据检索的性能瓶颈,SeekDB 提出向量 - 标量协同索引技术。该技术通过以下机制实现高效检索:
- 索引构建阶段:为标量字段建立 B + 树索引,同时为向量字段建立 IVF-PQ 索引,并通过元数据关联两种索引;
- 查询执行阶段:先通过标量索引筛选出候选集,再在候选集中执行向量检索,避免全量向量计算;
- 索引更新阶段:采用增量更新策略,标量索引实时更新,向量索引定期合并,平衡更新性能与查询效率。
实测数据显示,该技术使混合查询性能较传统 "独立索引 + 结果拼接" 方式提升 3-5 倍。
3.2.2 实时数据写入与一致性保障
SeekDB 继承了 OceanBase 在 "双 11" 等极限场景中锤炼的实时写入能力,通过以下技术实现高吞吐写入与一致性保障:
- 写入缓冲池:采用环形缓冲队列暂存实时写入数据,避免磁盘 I/O 瓶颈;
- 分区并行写入:将数据按时间或业务维度分区,支持多线程并行写入;
- 两阶段提交:确保标量与向量数据的原子性写入,避免部分写入导致的数据不一致。
在 48 vCPU、96GB RAM 的硬件环境下,SeekDB 的标量数据写入吞吐量可达 10 万条 / 秒,向量数据(128 维)写入吞吐量可达 5 万条 / 秒,远超 QuestDB 等同类产品。
3.2.3 智能查询优化器
SeekDB 的查询优化器引入 AI 算法,能够根据数据特征与查询模式动态选择最优执行计划:
- 特征提取:实时收集数据分布、索引状态与查询历史等特征;
- 计划生成:基于强化学习模型生成多种执行计划候选;
- 计划选择:通过成本估算模型选择最优计划,如标量过滤优先或向量检索优先。
在复杂混合查询场景中,智能优化器可使查询性能提升 20%-40%,尤其适用于查询模式多变的 AI 应用。
四、实战指南:SeekDB 开发与部署全流程
4.1 环境准备与安装部署
4.1.1 软硬件环境要求
SeekDB 对软硬件环境要求极低,主流配置均可满足:
- 硬件要求:
-
- 最低配置:1 核 CPU、2GB 内存、10GB 磁盘;
-
- 推荐配置(企业级):8 核 CPU、32GB 内存、1TB SSD;
- 软件要求:
-
- 操作系统:Ubuntu 20.04+/CentOS 7+/Windows 10+;
-
- Python 版本:3.8-3.11;
-
- 依赖库:numpy、pandas、transformers(可选)。
4.1.2 多模式部署实战
嵌入式模式部署(适合开发测试)
嵌入式模式无需启动独立服务,直接在应用进程内运行:
# 安装SeekDB
pip install oceanbase-seekdb
# 验证安装
python -c "from seekdb import SeekDB; db = SeekDB('./test_db'); print('安装成功')"
Client-Server 模式部署(适合生产环境)
- 安装服务端
# 下载安装包
wget https://oceanbase.ai/downloads/seekdb-server-1.0.0.tar.gz
tar -zxvf seekdb-server-1.0.0.tar.gz
cd seekdb-server-1.0.0
# 启动服务(默认端口8080)
./bin/seekdb start --config ./conf/seekdb.yaml
- 客户端连接
from seekdb import SeekDBClient
# 连接服务端
client = SeekDBClient(host="localhost", port=8080, username="admin", password="seekdb123")
# 验证连接
if client.ping():
print("连接成功")
else:
print("连接失败")
4.2 多模数据操作实战
4.2.1 数据模型定义
SeekDB 采用 Schema 灵活定义机制,支持多模字段混合定义:
-- 创建多模数据表
CREATE TABLE fraud_detection (
id INT PRIMARY KEY AUTO_INCREMENT, -- 标量字段
transaction_amount DECIMAL(10,2), -- 标量字段
transaction_time TIMESTAMP, -- 标量字段
user_behavior TEXT, -- 文本字段
user_embedding VECTOR(768), -- 向量字段(768维)
transaction_location GISPOINT -- GIS字段
);
-- 创建混合索引
CREATE INDEX idx_fraud_mix ON fraud_detection (
transaction_time, -- 标量索引
user_behavior, -- 文本索引
user_embedding -- 向量索引
);
4.2.2 多模数据写入
支持通过 SQL 与 Python SDK 两种方式写入多模数据:
SQL 写入方式
-- 写入多模数据
INSERT INTO fraud_detection (
transaction_amount, transaction_time, user_behavior, user_embedding, transaction_location
) VALUES (
56800.00,
'2025-11-19 09:30:00',
'用户在异地登录,连续发起3笔大额转账',
'[0.123, 0.456, ..., 0.789]', -- 768维向量
ST_GeomFromText('POINT(120.12 30.34)') -- GIS坐标
);
Python SDK 写入方式
import time
import numpy as np
from seekdb import SeekDBClient
client = SeekDBClient(host="localhost", port=8080)
# 生成随机向量(768维)
embedding = np.random.rand(768).tolist()
# 构造多模数据
data = {
"transaction_amount": 78200.50,
"transaction_time": time.strftime("%Y-%m-%d %H:%M:%S"),
"user_behavior": "用户凌晨在陌生设备上操作,转账至非常用账户",
"user_embedding": embedding,
"transaction_location": "POINT(116.40 39.90)" # 北京坐标
}
# 写入数据
response = client.insert(table="fraud_detection", data=data)
if response["success"]:
print(f"数据写入成功,ID: {response['data']['id']}")
4.2.3 混合检索实战
金融反欺诈场景查询
查询 "近 7 天交易超 5 万元、位置在上海周边(半径 50 公里)且行为类似历史欺诈样本" 的记录:
# 历史欺诈样本向量(假设已获取)
fraud_sample_embedding = np.load("fraud_sample_embedding.npy").tolist()
# 构造混合查询条件
query = {
"scalar_filter": "transaction_amount > 50000 AND transaction_time >= DATE_SUB(NOW(), INTERVAL 7 DAY)",
"gis_filter": {
"field": "transaction_location",
"type": "within_radius",
"center": "POINT(121.47 31.23)", # 上海中心坐标
"radius": 50000 # 50公里(单位:米)
},
"vector_search": {
"field": "user_embedding",
"query_vector": fraud_sample_embedding,
"top_k": 10,
"similarity_threshold": 0.85 # 余弦相似度阈值
},
"text_filter": "user_behavior LIKE '%异地%' OR user_behavior LIKE '%陌生设备%'"
}
# 执行查询
results = client.hybrid_search(table="fraud_detection", query=query)
# 处理结果
for idx, result in enumerate(results["data"]):
print(f"第{idx+1}条疑似记录:")
print(f"交易金额:{result['transaction_amount']}")
print(f"交易时间:{result['transaction_time']}")
print(f"相似度:{result['similarity_score']:.4f}")
print("---")
SQL 混合查询方式
SeekDB 支持标准 SQL 与向量检索语法的混合使用:
-- 混合查询SQL示例
SELECT
id, transaction_amount, transaction_time,
VECTOR_SIMILARITY(user_embedding, '[0.123, 0.456, ...]') AS similarity_score
FROM fraud_detection
WHERE
transaction_amount > 50000
AND transaction_time >= DATE_SUB(NOW(), INTERVAL 7 DAY)
AND ST_DWithin(transaction_location, ST_GeomFromText('POINT(121.47 31.23)'), 50000)
AND MATCH(user_behavior) AGAINST('异地 陌生设备' IN NATURAL LANGUAGE MODE)
ORDER BY similarity_score DESC
LIMIT 10;
4.3 与 AI 框架集成实战
4.3.1 LangChain 集成构建智能知识库
以构建金融报告智能问答系统为例:
- 安装依赖库
pip install oceanbase-seekdb langchain transformers sentence-transformers pypdf
- 构建知识库与问答链
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import SentenceTransformerEmbeddings
from langchain.vectorstores import SeekDB
from langchain.chains import RetrievalQA
from langchain.llms import OpenAI
# 1. 加载与分割文档
loader = PyPDFLoader("2024_q3_financial_report.pdf")
documents = loader.load()
# 分割文档(按字符数分割,避免跨段落)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
length_function=len
)
texts = text_splitter.split_documents(documents)
# 2. 初始化向量存储
embeddings = SentenceTransformerEmbeddings(model_name="all-MiniLM-L6-v2")
vector_store = SeekDB(
embedding_function=embeddings,
db_path="./financial_kb",
table_name="financial_reports"
)
# 3. 构建知识库(自动完成向量生成与存储)
vector_store.add_documents(texts)
# 4. 构建问答链
qa_chain = RetrievalQA.from_chain_type(
llm=OpenAI(api_key="your-api-key"),
chain_type="stuff",
retriever=vector_store.as_retriever(
search_kwargs={"k": 3, "similarity_threshold": 0.8}
),
return_source_documents=True
)
# 5. 智能问答
query = "2024年第三季度公司的净利润同比增长了多少?"
result = qa_chain({"query": query})
print("回答:", result["result"])
print("\n参考来源:")
for doc in result["source_documents"]:
print(f"- 页码:{doc.metadata['page']+1},内容片段:{doc.page_content[:100]}...")
4.3.2 Power Mem 分层记忆架构应用
Power Mem 通过分层记忆管理降低大模型推理成本,示例如下:
from seekdb.power_mem import PowerMemManager
from langchain.llms import HuggingFacePipeline
# 初始化分层记忆管理器
mem_manager = PowerMemManager(
db_path="./agent_memory",
short_term_ttl=3600, # 短期记忆1小时过期
long_term_threshold=5 # 被访问5次以上存入长期记忆
)
# 初始化本地大模型
llm = HuggingFacePipeline.from_model_id(
model_id="lmsys/vicuna-7b-v1.5",
task="text-generation",
model_kwargs={"temperature": 0.7, "max_new_tokens": 512}
)
# 智能体对话函数
def agent_chat(query):
# 1. 从记忆中检索相关信息
memory_context = mem_manager.retrieve(query, top_k=2)
# 2. 构建带记忆的提示词
prompt = f"""基于以下上下文回答问题:
{memory_context}
问题:{query}
回答:"""
# 3. 模型推理
response = llm(prompt)
# 4. 存储对话到记忆
mem_manager.store(query=query, response=response)
return response
# 测试对话
print(agent_chat("公司2024年Q3的营收是多少?"))
print(agent_chat("它同比增长了多少个百分点?")) # 会自动关联上一轮记忆
五、性能测试与行业对比
5.1 基准测试环境与方法
测试采用行业标准的 Time Series Benchmark Suite(TSBS)与自定义混合检索测试集,硬件环境参考主流云服务器配置:
- 硬件配置:c6a.12xlarge EC2 实例(48 vCPU、96GB RAM、500GB GP3 SSD,16000 IOPS、1000MB/s 吞吐量);
- 软件环境:Ubuntu 22.04,SeekDB 1.0.0,InfluxDB 2.7.4,QuestDB 7.3.10(均为默认配置);
- 测试数据集:
-
- 标量数据:1 亿条金融交易记录;
-
- 向量数据:100 万条 768 维用户行为向量;
-
- 文本数据:500 万条用户行为描述;
-
- GIS 数据:200 万条交易位置记录。
5.2 核心性能指标对比
5.2.1 写入性能测试
测试不同数据量下的写入吞吐量(条 / 秒):
表 2 写入性能对比
|-------------|---------|---------|--------------|-------------|
| 数据类型 | 数据量 | SeekDB | InfluxDB 2.7 | QuestDB 7.3 |
| 标量数据 | 1000 万条 | 102,400 | 85,600 | 91,200 |
| 标量数据 | 1 亿条 | 98,700 | 72,300 | 83,500 |
| 向量数据(768 维) | 100 万条 | 48,300 | - | 32,100 |
| 混合数据 | 500 万条 | 65,200 | - | 41,800 |
SeekDB 在标量与向量写入场景中均表现最优,尤其在混合数据写入时领先 QuestDB 56%,这得益于其优化的存储引擎与并行写入机制。
5.2.2 检索性能测试
测试混合检索(标量过滤 + 向量匹配 + 文本检索)的响应时间与 QPS:
表 3 检索性能对比
|--------------|--------|-------------|--------------------|------------|
| 查询场景 | 数据规模 | SeekDB 响应时间 | InfluxDB+ES+Milvus | QuestDB+ES |
| 简单混合查询(1 条件) | 100 万条 | 42ms | 187ms | 123ms |
| 复杂混合查询(4 条件) | 1 亿条 | 87ms | 412ms | 268ms |
| QPS(并发 100) | 1 亿条 | 986 | 243 | 372 |
SeekDB 的响应时间较 "多系统拼接" 架构提升 4-5 倍,QPS 提升 3-4 倍,印证了其混合检索机制的性能优势。
5.2.3 资源占用测试
测试满负载运行时的资源占用率:
表 4 资源占用对比(满负载)
|--------------|---------|--------|---------|
| 产品 | CPU 占用率 | 内存占用 | 磁盘 IOPS |
| SeekDB | 42% | 8.7GB | 3,200 |
| InfluxDB 2.7 | 58% | 12.3GB | 4,500 |
| QuestDB 7.3 | 51% | 10.2GB | 3,900 |
SeekDB 的资源占用率最低,这与其轻量化设计目标一致,适合资源受限的边缘场景与大规模集群部署。
5.3 功能完整性对比
表 5 功能完整性对比
|---------|-------------------------|---------------|----------------|
| 功能特性 | SeekDB | InfluxDB 2.7 | QuestDB 7.3 |
| 多模数据支持 | 标量 / 向量 / 文本 / GIS/JSON | 标量 / 时间序列 | 标量 / 时间序列 / 向量 |
| 混合检索能力 | 支持 | 不支持 | 部分支持 |
| ACID 事务 | 支持 | 不支持 | 部分支持 |
| AI 框架兼容 | 30 + 种 | 5 种 | 8 种 |
| 部署模式 | 嵌入式 / Client-Server | Client-Server | Client-Server |
| 开源协议 | Apache 2.0 | MIT | Apache 2.0 |
SeekDB 在功能完整性上全面领先,尤其在多模融合与 AI 生态兼容方面优势显著。
六、行业落地案例与实践价值
6.1 金融行业:实时反欺诈系统
某头部股份制银行基于 SeekDB 构建实时反欺诈系统,解决了传统架构 "响应慢、误判高" 的痛点:
- 业务挑战:需同时处理交易标量数据、用户行为文本、设备指纹向量与地理位置信息,传统架构响应延迟超 3 秒,误判率达 8%;
- 解决方案:采用 SeekDB 的混合检索能力,实时筛选疑似欺诈交易,并结合 Power Mem 记忆架构记录用户历史行为;
- 实施效果:
-
- 交易审核响应时间从 3 秒降至 80ms,满足实时交易要求;
-
- 欺诈识别准确率从 92% 提升至 98.5%,误判率降至 2.3%;
-
- 系统部署资源成本降低 40%。
6.2 政务行业:智能问答知识库
中国联通基于 SeekDB 构建统一 AI 知识库,服务政企客户与内部员工:
- 业务挑战:政务文档涵盖政策文本、表格数据、地理位置等多模信息,传统搜索引擎无法满足精准检索需求;
- 解决方案:通过 Power RAG 解析多格式文档,SeekDB 实现 "政策条款 + 地理位置 + 相关案例" 的混合检索;
- 实施效果:
-
- 文档解析准确率达 98.7%,支持 15 种格式自动处理;
-
- 知识库查询响应时间 < 100ms,准确率提升 60%;
-
- 权限管理与数据本地化满足政务安全要求。
6.3 互联网行业:智能 Agent 服务
蚂蚁集团 "百宝箱" 产品基于 SeekDB 实现智能 Agent 的实时在线搜索:
- 业务挑战:智能 Agent 需同时处理用户文本查询、商品向量数据与促销规则标量数据,跨系统调用导致响应延迟;
- 解决方案:SeekDB 作为 Agent 的原生数据入口,集成 LangChain 框架实现多轮对话与精准检索;
- 实施效果:
-
- Agent 响应时间从 1.5 秒降至 300ms;
-
- 商品推荐准确率提升 35%;
-
- 大模型 token 消耗降低 90%(基于 Power Mem)。
七、未来演进与生态规划
7.1 技术演进路线图
OceanBase 为 SeekDB 规划了清晰的技术演进路线:
- 短期(2026 Q1):
-
- 支持 10240 维超大规模向量;
-
- 新增图像、音频等非结构化数据支持;
-
- 推出 GPU 加速版本,提升向量检索性能 10 倍。
- 中期(2026 Q4):
-
- 实现 TP/AP/AI 引擎的深度融合优化;
-
- 支持联邦学习与隐私计算,适配高敏场景;
-
- 推出多语言 SDK(Java、Go、C++)。
- 长期(2027+):
-
- 集成自研大模型推理引擎;
-
- 支持跨多云环境的分布式检索;
-
- 构建 AI 原生数据库的行业标准。
7.2 开源生态建设
SeekDB 以开源为核心战略,通过三大举措构建生态:
- 开发者社区:建立技术论坛与开发者计划,提供免费培训与认证;
- 合作伙伴计划:与 AI 框架厂商、云服务商共建解决方案;
- 行业插件库:鼓励社区贡献金融、政务、医疗等行业专用插件。
截至 2025 年 11 月,SeekDB 的 GitHub 星标数已突破 5000,累计贡献者超 200 人,生态正快速成长。
八、总结:AI 原生数据库的未来图景
SeekDB 的发布不仅是 OceanBase"数据 ×AI" 战略的重要落地,更标志着数据库行业进入 "AI 原生" 的新阶段。它通过多模数据统一存储、混合检索机制、轻量化部署与全生态兼容四大核心能力,解决了企业 AI 项目落地的核心痛点,实现了从 "业务支撑" 到 "智能赋能" 的范式跃迁。
正如杨冰所言:"未来数据库必须同时服务'人'与'智能体'。" SeekDB 的实践证明,AI 原生数据库不是传统数据库的功能升级,而是从存储引擎到查询优化器的全面重构。在金融、政务、互联网等行业的落地案例中,它已经展现出强大的实用价值 ------ 既降低了 AI 应用的工程门槛,又提升了智能决策的实时性与准确性。
随着技术的持续演进与生态的不断完善,SeekDB 有望成为 AI 时代的数据基础设施核心,推动 "数据原生智能" 的普及与深化。对于企业而言,拥抱这类 AI 原生数据库,将不再是简单的技术选型,而是把握 AI 时代竞争优势的战略选择。