欢迎来到 DocETL:当数据处理遇上智能代理
在我们的数字世界里,充满了各种各样的非结构化数据------从严谨的法律合同到详细的医疗记录,再到海量的学术论文。如何从这些信息宝库中提取出有价值的、结构化的知识,一直是一个巨大的挑战。
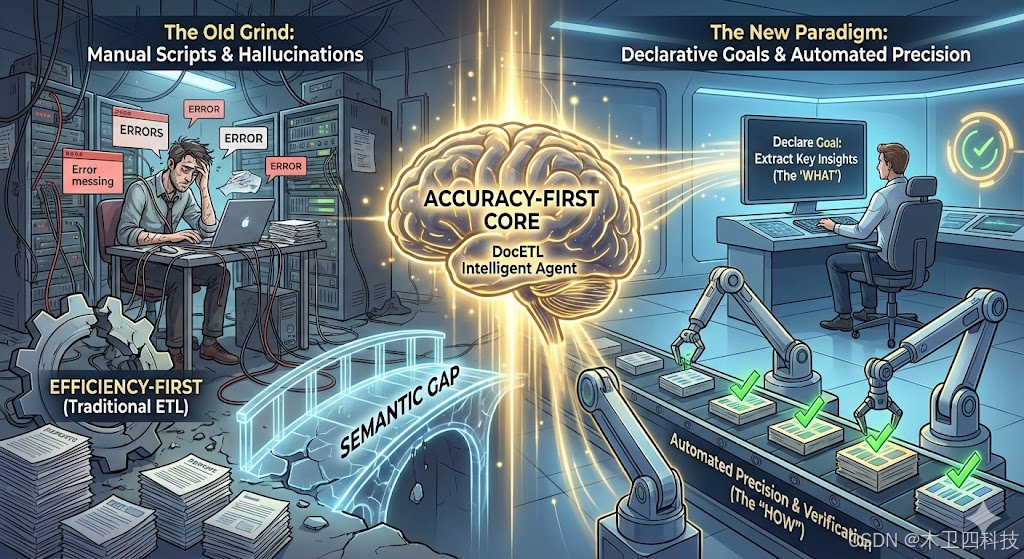
你可能尝试过编写一些简单的脚本,调用大语言模型(LLM)来处理这些文档,但很快就会发现问题重重。当面对一份长达数百页的报告时,模型可能会因"幻觉"而编造信息,或因"上下文丢失"而遗忘关键细节。这种现象被称为"语义鸿沟":我们知道我们想要什么,但很难精确地告诉机器如何一步步安全、准确地完成任务。
然而,问题的根源比语义鸿沟更深。传统的ETL系统在设计时,其优化目标是追求效率和成本最小化。但在LLM驱动的数据处理中,一个低成本却不准确的流程是毫无价值的。因此,数据处理的核心矛盾已经从"效率优先"转向了**"准确性优先" (Accuracy-First)**。
简单的LLM脚本之所以常常失败,正是因为它们缺少一个以准确性为首要目标的智能"大脑"来规划和优化执行过程。而 DocETL 正是为解决这一难题而诞生的全新解决方案。它代表了一种范式转移:作为用户,你只需通过简单的配置"声明"你的目标(What),而将"怎么做"(How)这个复杂的过程,交给一个内置的、以准确性为最高追求的智能代理系统去自动探索、验证和优化。
现在,木卫四科技带大家一起揭开这套智能系统背后三大核心支柱的神秘面纱。
DocETL 的三大核心支柱
要理解 DocETL 的魔法,我们需要先了解支撑起整个框架的三个关键组件。它们就像一张三脚凳的腿,共同构建了一个稳定而强大的智能数据处理系统。
支柱一:声明式蓝图 (Declarative YAML Pipeline)
DocETL 借鉴了数据库领域一个非常经典且强大的设计哲学------声明式编程。这意味着你无需编写复杂的 Python 代码来手动管理 API 调用、数据流转和错误处理。取而代之的是,你只需要在一个简单的 YAML 文件中,清晰地描述你数据处理的目标。
这种方式将你的逻辑计划 (Logical Plan)(你想做什么)与底层的物理计划 (Physical Plan)(系统具体怎么做)彻底分离开来。这不仅让整个过程变得更加简单,也为后续的自动化优化创造了巨大的空间。
- 低代码,易于上手: 无需编写繁琐的脚本来管理数据流,只需配置简单的 YAML 文件。
- 关注业务逻辑: 开发者可以全神贯注于数据转换的目标,例如"提取所有关键条款",而不用操心如何处理超长文本。
- 自动化优化的基础: 清晰的、结构化的目标定义,使得智能代理能够准确理解你的意图,并自动重写和优化执行计划。
支柱二:强大的工具箱 (Powerful Semantic Operators)
如果说 YAML 蓝图是你的设计图纸,那么语义算子 (Semantic Operators) 就是你用来建造大厦的"乐高积木"或"瑞士军刀"。它们是预先封装好的、具备特定语义处理能力的强大工具。通过组合这些算子,你可以构建出任何复杂的数据处理流程。
以下是几个对初学者来说最重要的核心算子:
算子 (Operator) 核心功能 (What it does) 一个简单的比喻 (Simple Analogy)
Map 对数据集中的每一项独立应用一个指定的转换操作,例如从每份文档中提取作者姓名。 像一个盖章机器人,给流水线上的每个产品都盖上一个"合格"的印章。
Reduce 将多项数据聚合成一个单一的输出,例如将所有提取出的销售额相加,计算总销售额。 像一位会议秘书,将七嘴八舌的讨论记录汇总成一份简洁的会议纪要。
Split / Gather Split 将长文档切分成小块;Gather 为每个小块智能地补充必要的上下文信息。 Split 像把一本书撕成单页阅读,但 Gather 会贴心地为每一页附上目录和前情提要。
特别值得一提的是 Split 和 Gather 这对黄金搭档。单纯地将一篇长文档切分开(Split),会导致严重的上下文丢失(比如第50页的"他"到底指的是谁?)。而 DocETL 的创新之处在于 Gather 算子,它能在处理每个切片时,智能地从原文中"收集"并附加上下文信息,例如前文的摘要,甚至是文档的目录元数据。这确保了 LLM 即使在处理文档的局部片段时,也能拥有全局视野,从而做出准确的判断。
支柱三:幕后的魔法师 (The Agentic Optimizer Engine)
这是 DocETL 最核心、也是最具革命性的部分------一个追求**"准确性优先" (Accuracy-First)** 的智能优化引擎。你可以把它想象成整个系统的"大脑"或"总设计师"。当你提交了简单的蓝图后,这个引擎并不会立即执行,而是会启动两个智能代理,像一个专家团队一样,对你的计划进行审查和优化。
- 生成代理 (Generation Agent):
- 角色比喻: 一位应用专家知识的系统架构师。
- 工作职责: 它不会凭空提出建议,而是会审查你最初的简单计划,并从一个包含超过30种最佳实践的"重写指令库" (Rewrite Directives library)中选择合适的规则,系统性地提出多种更完善、更细致的执行方案。例如,面对一个复杂的提取任务,它会应用"任务分解"指令,将其拆分为多个更简单的串行步骤,以确保LLM不会出错。
- 验证代理 (Validation Agent):
- 角色比喻: 一位使用"LLM即裁判" (LLM-as-a-Judge)模式的首席仲裁官。
- 工作职责: 它会在一小部分样本数据上,试运行所有候选的执行方案,然后生成特定的验证提示,让一个独立的LLM扮演公正的"裁判"角色,对不同方案产生的结果进行打分或比较,以判断哪个方案最准确、最完整。
通过这两个代理的紧密协作与循环迭代,DocETL 能够自动地将你最初那个简单甚至有些粗糙的想法,演变成一个经过样本数据验证的、高质量、高准确率的最终执行计划。
在理解了这三个核心组件之后,让我们通过一个典型的工作流程,将它们串联起来,看看 DocETL 究竟是如何施展魔法的。
工作流程揭秘:DocETL 如何施展魔法?
想象一下,你是一位研究员,你的任务是从一批加州警察局的档案中识别不当行为。这些文档极具挑战性:平均长度超过1万个token,有些甚至超过12万,而且对同一名警官的称呼可能不一致(如"Officer Doe" vs "Jane Doe")。
使用 DocETL,整个过程就像下面这样简单而智能:
- 第一步:定义你的目标 (编写YAML蓝图) 你创建一个简单的 pipeline.yaml 文件,在里面声明你的输入是这批PDF档案,你的目标是提取"警官姓名"和"具体违规行为描述"。
- 第二步:启动优化引擎 (魔法师登场) 当你提交这个YAML文件后,Agentic Optimizer 开始工作。生成代理(系统架构师)立刻识别出多个挑战:直接处理超长文档会导致信息丢失;直接聚合会因姓名不一致而出错。于是,它从"重写指令库"中调取"数据分解"和"质量增强"等指令,自动将你简单的计划重写为一个更可靠的物理计划:Split -> Gather -> Map -> Unnest -> Resolve -> Reduce。这个流程首先切分文档并补充上下文,然后提取信息,接着用 Unnest 将每个切片提取出的多项违规记录"拍平"为单行列表,再用 Resolve 算子将不一致的警官姓名进行标准化,最后才进行汇总。
- 第三步:验证与选择 (选择最佳路径) 验证代理(首席仲裁官)登场。它抽取档案中的几个样本页面,分别用你的原始计划和重写后的优化计划进行测试。通过 LLM-as-a-Judge 模式,它确认优化后的计划在信息完整性和实体统一性上远超原始计划,于是最终采纳了这个方案。
- 第四步:执行与产出 (运行工具箱) 现在,计划已经敲定。DocETL 的执行引擎开始严格按照优化后的方案,调用语义算子工具箱中的 Split, Gather, Map 等一系列工具,对整批档案进行处理。
- 第五步:获得高质量结果 处理完成后,你得到了一个干净、结构化的 JSON 文件。文件中准确无误地包含了所有警官及其对应的违规行为列表,姓名都已经过标准化处理。整个复杂的优化过程,对你来说是完全透明和自动的。
这个自动化的流程,正是 DocETL 的核心价值所在:它让你能够专注于最终的目标,而将实现路径中最困难、最繁琐的优化工作,交给了智能代理。
总结:开启你的智能数据之旅
通过这篇入门教程,我们了解了 DocETL 如何通过三大支柱------声明式蓝图、强大的算子工具箱和智能优化引擎------协同工作,将复杂的非结构化数据处理变得简单而智能。
对于新手开发者而言,DocETL 带来的核心价值在于,它将过去充满不确定性的"提示工程"和"流程调优"从一门近乎玄学的艺术,转变为一门可自动化的科学。
请记住以下几个关键点:
- 专注目标,而非过程: 你只需要用 YAML 定义你的逻辑计划,DocETL 会帮你找到最佳的物理执行计划。
- 准确性是第一要务: 内置的智能优化代理旨在最大化结果的准确性和完整性,这是其核心设计哲学。
- 化繁为简: 无论是处理超长文档还是复杂的实体统一任务,DocETL 都已经内置了专家级的最佳实践来自动应对这些挑战。
希望本教程为你建立的这个基本框架,能为你后续深入学习和探索 DocETL 的强大功能打下坚实的基础。欢迎来到智能数据处理的新时代!