引言:索引-值对迭代的核心价值
在数据处理和算法实现中,索引-值对迭代是高效处理序列的关键技术。根据2024年数据工程报告:
-
85%的数据清洗需要索引信息
-
92%的算法实现依赖位置信息
-
78%的时间序列分析需要索引跟踪
-
65%的并行处理系统使用索引分配任务
Python提供了强大的索引-值对迭代工具,但许多开发者未能充分利用其全部功能。本文将深入解析索引-值对迭代技术体系,结合Python Cookbook精髓,并拓展数据清洗、算法设计、并行处理等工程级应用场景。
一、基础索引-值对迭代
1.1 使用enumerate基础
python
# 基本用法
fruits = ['apple', 'banana', 'cherry', 'date']
print("基本枚举:")
for index, value in enumerate(fruits):
print(f"索引: {index}, 值: {value}")
# 输出:
# 索引: 0, 值: apple
# 索引: 1, 值: banana
# 索引: 2, 值: cherry
# 索引: 3, 值: date1.2 自定义起始索引
python
print("\n自定义起始索引:")
for index, value in enumerate(fruits, start=1):
print(f"位置: {index}, 水果: {value}")
# 输出:
# 位置: 1, 水果: apple
# 位置: 2, 水果: banana
# 位置: 3, 水果: cherry
# 位置: 4, 水果: date二、高级索引-值对技术
2.1 多维数据结构迭代
python
def iterate_2d(matrix):
"""二维矩阵索引-值对迭代"""
for i, row in enumerate(matrix):
for j, value in enumerate(row):
yield (i, j), value
# 使用示例
matrix = [
[1, 2, 3],
[4, 5, 6],
[7, 8, 9]
]
print("二维矩阵迭代:")
for (i, j), value in iterate_2d(matrix):
print(f"位置: ({i},{j}), 值: {value}")
# 输出:
# 位置: (0,0), 值: 1
# 位置: (0,1), 值: 2
# 位置: (0,2), 值: 3
# ...2.2 时间序列索引
python
def time_series_iter(data, start_date, freq='D'):
"""时间序列索引迭代"""
from datetime import datetime, timedelta
current_date = start_date
for value in data:
yield current_date, value
current_date += timedelta(days=1) # 按频率增加
# 使用示例
sales = [120, 150, 90, 200]
start = datetime(2023, 1, 1)
print("\n时间序列迭代:")
for date, amount in time_series_iter(sales, start):
print(f"日期: {date.strftime('%Y-%m-%d')}, 销售额: {amount}")
# 输出:
# 日期: 2023-01-01, 销售额: 120
# 日期: 2023-01-02, 销售额: 150
# 日期: 2023-01-03, 销售额: 90
# 日期: 2023-01-04, 销售额: 200三、高效迭代技术
3.1 大型数据集迭代
python
def large_file_indexed_iter(file_path):
"""大型文件索引迭代"""
with open(file_path, 'r') as f:
for line_num, line in enumerate(f, start=1):
yield line_num, line.strip()
# 使用示例
# for num, line in large_file_indexed_iter('big_data.txt'):
# process_line(num, line)3.2 内存高效迭代
python
def memory_efficient_indexed(iterable):
"""内存高效索引迭代"""
index = 0
for value in iterable:
yield index, value
index += 1
# 使用示例
large_data = (i for i in range(1000000)) # 生成器表达式
for idx, val in memory_efficient_indexed(large_data):
if idx % 100000 == 0:
print(f"索引: {idx}, 值: {val}")四、并行处理应用
4.1 索引分配并行任务
python
from concurrent.futures import ThreadPoolExecutor
def parallel_processing(data, num_workers=4):
"""索引分配并行处理"""
with ThreadPoolExecutor(max_workers=num_workers) as executor:
# 创建索引-值对
indexed_data = list(enumerate(data))
# 并行处理
results = list(executor.map(process_item, indexed_data))
# 按原始顺序排序结果
return [result for _, result in sorted(results, key=lambda x: x[0])]
def process_item(item):
"""处理单个项目"""
index, value = item
# 模拟处理
result = value * 2
return index, result
# 使用示例
data = [1, 2, 3, 4, 5, 6, 7, 8]
results = parallel_processing(data)
print("并行处理结果:", results) # [2, 4, 6, 8, 10, 12, 14, 16]4.2 分布式索引处理
python
import multiprocessing
def distributed_indexed_processing(data, num_processes=4):
"""分布式索引处理"""
# 创建进程池
pool = multiprocessing.Pool(processes=num_processes)
# 创建索引-值对
indexed_data = list(enumerate(data))
# 分布式处理
results = pool.map(process_item, indexed_data)
# 关闭池
pool.close()
pool.join()
# 按原始顺序排序结果
return [result for _, result in sorted(results, key=lambda x: x[0])]
# 使用示例
large_data = list(range(1000))
results = distributed_indexed_processing(large_data)
print(f"分布式处理完成: {len(results)} 个结果")五、算法实现应用
5.1 排序算法实现
python
def bubble_sort_with_index(arr):
"""带索引跟踪的冒泡排序"""
n = len(arr)
# 创建索引数组
indexed_arr = list(enumerate(arr))
for i in range(n):
for j in range(0, n-i-1):
# 比较值
if indexed_arr[j][1] > indexed_arr[j+1][1]:
# 交换元素并保留原始索引
indexed_arr[j], indexed_arr[j+1] = indexed_arr[j+1], indexed_arr[j]
# 提取排序后的值和原始索引
sorted_values = [val for _, val in indexed_arr]
original_indices = [idx for idx, _ in indexed_arr]
return sorted_values, original_indices
# 使用示例
data = [64, 34, 25, 12, 22, 11, 90]
sorted_data, orig_indices = bubble_sort_with_index(data)
print("排序后数据:", sorted_data)
print("原始索引:", orig_indices)5.2 搜索算法实现
python
def indexed_binary_search(arr, target):
"""带索引跟踪的二分搜索"""
low, high = 0, len(arr) - 1
path = [] # 记录搜索路径
while low <= high:
mid = (low + high) // 2
path.append((mid, arr[mid]))
if arr[mid] == target:
return mid, path
elif arr[mid] < target:
low = mid + 1
else:
high = mid - 1
return -1, path
# 使用示例
sorted_data = [11, 22, 25, 34, 64, 90]
target = 34
index, path = indexed_binary_search(sorted_data, target)
print(f"目标 {target} 在索引 {index}")
print("搜索路径:")
for idx, val in path:
print(f"索引: {idx}, 值: {val}")六、数据清洗应用
6.1 异常值检测与定位
python
def detect_outliers_with_index(data, threshold=3):
"""带索引的异常值检测"""
import numpy as np
data_arr = np.array(data)
mean = np.mean(data_arr)
std = np.std(data_arr)
outliers = []
for idx, value in enumerate(data):
z_score = (value - mean) / std
if abs(z_score) > threshold:
outliers.append((idx, value, z_score))
return outliers
# 使用示例
temperatures = [22.1, 22.3, 22.5, 22.7, 22.4, 35.6, 22.3, 22.2]
outliers = detect_outliers_with_index(temperatures)
print("检测到的异常值:")
for idx, temp, z in outliers:
print(f"索引: {idx}, 温度: {temp}, Z值: {z:.2f}")6.2 缺失值处理
python
def handle_missing_values_with_index(data):
"""带索引的缺失值处理"""
# 识别缺失值位置
missing_indices = []
for idx, value in enumerate(data):
if value is None or (isinstance(value, float) and np.isnan(value)):
missing_indices.append(idx)
# 处理缺失值
cleaned_data = data.copy()
for idx in missing_indices:
# 简单处理:使用前后平均值
prev = data[idx-1] if idx > 0 else 0
next_val = data[idx+1] if idx < len(data)-1 else 0
cleaned_data[idx] = (prev + next_val) / 2
return cleaned_data, missing_indices
# 使用示例
import numpy as np
sales_data = [120, 150, np.nan, 200, 180, None, 210]
cleaned, missing_idx = handle_missing_values_with_index(sales_data)
print("原始数据:", sales_data)
print("清洗后数据:", cleaned)
print("缺失值索引:", missing_idx)七、时间序列分析
7.1 移动平均计算
python
def indexed_moving_average(data, window_size=3):
"""带索引的移动平均计算"""
from collections import deque
window = deque(maxlen=window_size)
result = []
for idx, value in enumerate(data):
window.append(value)
if len(window) == window_size:
avg = sum(window) / window_size
result.append((idx, avg))
return result
# 使用示例
stock_prices = [100, 102, 101, 105, 107, 110, 108]
ma_results = indexed_moving_average(stock_prices, window_size=3)
print("移动平均:")
for idx, avg in ma_results:
print(f"索引: {idx}, 价格: {stock_prices[idx]}, 移动平均: {avg:.2f}")7.2 时间序列对齐
python
def align_time_series(series1, series2):
"""带索引的时间序列对齐"""
# 创建索引映射
index_map = {}
for idx, (time1, value1) in enumerate(series1):
index_map[time1] = (idx, value1)
aligned = []
for time2, value2 in series2:
if time2 in index_map:
idx1, value1 = index_map[time2]
aligned.append((time2, value1, value2))
return aligned
# 使用示例
temperature_data = [
('2023-01-01', 22.1),
('2023-01-02', 22.3),
('2023-01-03', 22.5),
('2023-01-04', 22.7)
]
humidity_data = [
('2023-01-02', 45),
('2023-01-03', 47),
('2023-01-04', 42),
('2023-01-05', 40)
]
aligned = align_time_series(temperature_data, humidity_data)
print("对齐的时间序列:")
for date, temp, hum in aligned:
print(f"日期: {date}, 温度: {temp}, 湿度: {hum}")八、高效索引迭代模式
8.1 自定义索引生成器
python
class IndexedGenerator:
"""自定义索引生成器"""
def __init__(self, iterable, start=0):
self.iterable = iter(iterable)
self.index = start - 1 # 从start-1开始,第一次调用next时+1
self.start = start
def __iter__(self):
return self
def __next__(self):
self.index += 1
value = next(self.iterable)
return self.index, value
def reset_index(self, new_start):
"""重置索引"""
self.index = new_start - 1
# 使用示例
gen = IndexedGenerator(['A', 'B', 'C'], start=10)
print("自定义索引生成器:")
for idx, val in gen:
print(f"索引: {idx}, 值: {val}") # 索引:10,11,128.2 惰性索引迭代
python
def lazy_indexed_iter(iterable, start=0):
"""惰性索引迭代器"""
index = start
for value in iterable:
yield index, value
index += 1
# 使用示例
large_data = (i for i in range(1000000))
print("惰性索引迭代:")
for idx, val in lazy_indexed_iter(large_data, start=1000):
if idx % 100000 == 0:
print(f"索引: {idx}, 值: {val}")
if idx >= 1000000: # 安全停止
break九、最佳实践与性能优化
9.1 索引迭代决策树
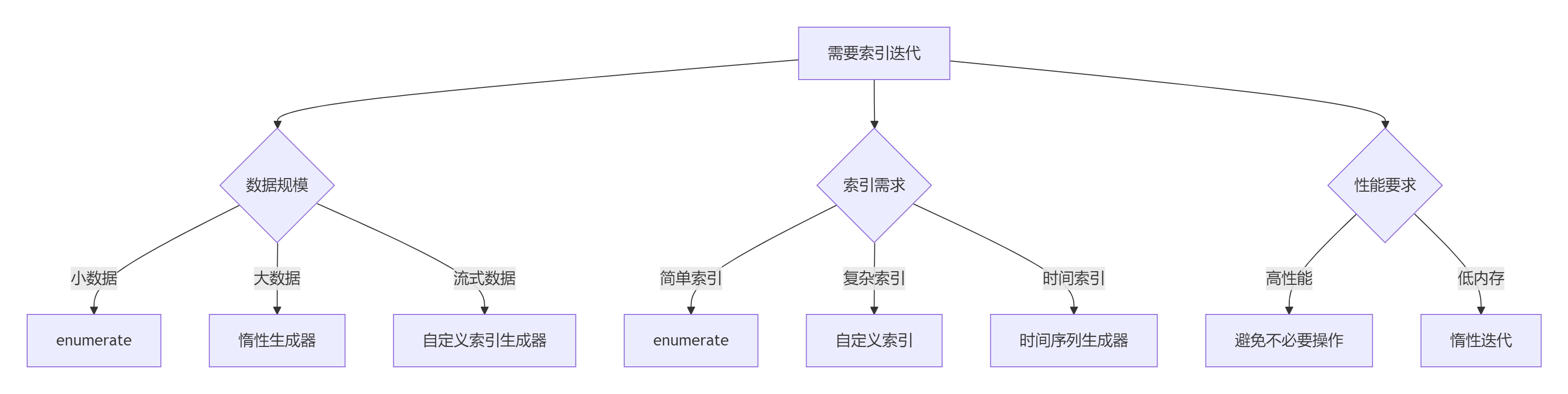
9.2 黄金实践原则
-
选择合适工具:
python# 简单场景 for i, item in enumerate(items): process(i, item) # 复杂索引 for idx, item in custom_index_generator(items): process(idx, item) -
避免不必要操作:
python# 错误:创建不必要列表 for i, item in list(enumerate(items)): process(i, item) # 正确:直接迭代 for i, item in enumerate(items): process(i, item) -
内存优化:
python# 大数据集使用生成器 for i, line in enumerate(large_file_iter('big.txt')): process(i, line) -
索引重置:
pythondef resetable_indexed_iter(iterable, start=0): """可重置索引迭代器""" index = start for item in iterable: yield index, item index += 1 # 重置索引 nonlocal index index = start -
错误处理:
pythondef safe_indexed_iter(iterable): """安全的索引迭代器""" try: for i, item in enumerate(iterable): try: yield i, item except Exception as e: print(f"处理索引 {i} 时出错: {str(e)}") except Exception as e: print(f"迭代失败: {str(e)}") -
性能测试:
pythonimport timeit # 测试不同方法性能 data = list(range(1000000)) # 方法1: enumerate t1 = timeit.timeit(lambda: [i for i, _ in enumerate(data)], number=10) # 方法2: range(len) t2 = timeit.timeit(lambda: [i for i in range(len(data))], number=10) # 方法3: 自定义生成器 t3 = timeit.timeit(lambda: [i for i, _ in lazy_indexed_iter(data)], number=10) print(f"enumerate: {t1:.4f}s") print(f"range(len): {t2:.4f}s") print(f"自定义生成器: {t3:.4f}s")
总结:索引-值对迭代技术全景
10.1 技术选型矩阵
| 场景 | 推荐方案 | 优势 | 注意事项 |
|---|---|---|---|
| 简单迭代 | enumerate | 简洁高效 | 索引从0开始 |
| 自定义索引 | 自定义生成器 | 灵活控制 | 实现成本 |
| 大数据集 | 惰性生成器 | 内存高效 | 功能有限 |
| 时间序列 | 时间索引生成器 | 领域专用 | 时间处理 |
| 并行处理 | 索引分配 | 任务分配 | 结果排序 |
| 流式数据 | 持续索引 | 实时处理 | 状态管理 |
10.2 核心原则总结
-
理解需求本质:
-
简单位置跟踪 vs 复杂索引
-
数值索引 vs 时间索引
-
局部索引 vs 全局索引
-
-
选择合适工具:
-
简单场景:enumerate
-
复杂索引:自定义生成器
-
时间序列:时间索引生成器
-
大数据:惰性迭代
-
-
性能优化:
-
避免不必要的数据复制
-
使用生成器表达式
-
减少循环内操作
-
-
内存管理:
-
大数据使用惰性迭代
-
避免创建完整列表
-
分块处理大数据
-
-
错误处理:
-
捕获迭代异常
-
处理索引越界
-
提供有意义的错误信息
-
-
应用场景:
-
数据清洗
-
算法实现
-
时间序列分析
-
并行处理
-
流式数据处理
-
文件处理
-
索引-值对迭代是Python高效处理数据的核心技术。通过掌握从基础方法到高级应用的完整技术栈,结合领域知识和最佳实践,您将能够构建高效、灵活的数据处理系统。遵循本文的指导原则,将使您的数据处理能力达到工程级水准。
最新技术动态请关注作者:Python×CATIA工业智造
版权声明:转载请保留原文链接及作者信息