这是一篇既照顾入门也能给高级工程师提供落地经验的实战笔记。
0. TL;DR(先上结论)
- 想稳:
acks=all+ 合理retries;需要"分区内不重不丢"→ 再加enable.idempotence=true且max.in.flight<=5。 - 想快:适度增大
batch.size与linger.ms,开启compression=zstd,若可丢用acks=0。 - 想一致:跨分区/主题要"要么全成要么全不成"→ 用事务(
transactional.id),消费端read_committed。 - 不确定怎么配?先跑 Demo 看数据:
lesson_three/web_demo页面支持一键预设、分区直方图、吞吐历史。
读者画像
- 初学者:只需看"工作流程概览""QoS 选型""10 分钟上手",再跑 Web Demo。
- 高级工程师:关注"参数建议表""常见坑""生产就绪清单""实战案例""调优路线"。
你将收获
- 对 acks/幂等/事务/批量/压缩的"白话"理解,知道各自代价与边界。
- 一套可直接投产的默认配置与检查清单。
- 可视化 Demo:改参数→立刻看到吞吐、分区分布、样本偏移。
0.5 10 分钟上手路线
-
启动本地 Kafka,或将
KAFKA_BOOTSTRAP指到你的集群。 -
运行 Web Demo:
uvicorn lesson_three.web_demo.main:app --reload
-
浏览器打开
http://127.0.0.1:8000:- 点顶部卡片一键预设(吞吐/可靠/同 key 同分区)
- 看右侧:JSON 结果、分区直方图、吞吐历史
通过 Demo 先把"感觉"建立起来,再回到本文查概念与参数细节。
1. 工作流程概览
- 拦截器(可选) → 统一埋点/改写消息
- 序列化器 → key/value 转字节
- 分区器 → 选择分区(同 key 同分区;无 key 用粘性分区器优化批量)
- 累加器 RecordAccumulator → 组成批(
batch.size/linger.ms/flush()触发) - Sender 线程 → 取批、发往分区 leader
- Broker → 写 leader 日志;按 acks 等待副本
- 回调/Future → 成功或异常
Producer 默认异步 :
send()立即返回 Future;同步语义通常是对 Futureget()或使用回调。
2. ACK 机制(acks)
acks=0:不等响应,最快,可能丢。acks=1:leader 写入就回,leader 掉线时可能丢。acks=all/-1:等 ISR 最小副本集合确认,最强持久性。
幂等/事务 要求
acks=all。
小贴士(为啥):
acks=0不等任何确认,延迟最低但可能丢;适合可丢日志。acks=1等 leader,leader 挂时可能丢;适合对"极偶发丢失"容忍的业务。acks=all等同步副本,可靠但更慢;配合幂等/事务才能保证语义。
3. 批量、压缩、异步
- 批量 :
batch.size(单分区批字节上限)、linger.ms(积攒时延)。常用:batch.size=32--128KB,linger.ms=5--20ms。 - 压缩 :
compression.type=zstd|lz4|snappy|gzip(推荐 zstd)。 - 异步 :默认异步;需要"业务确认" → 回调或
flush()/get()。
怎么配(经验法则):
- 低延迟接口:
linger.ms<=5,batch.size32--64KB。 - 高吞吐埋点:
linger.ms=10--20,batch.size=64--128KB,compression=zstd。 - 网络吃紧:优先开压缩;CPU 紧张则降级
gzip/none。
4. 幂等性生产者
- 开启:
enable.idempotence=true+acks=all - 建议:
max.in.flight.requests.per.connection<=5(保守有序),允许retries - 语义:分区内 Exactly-once(防重复)
为什么需要:
- 普通重试会导致同一分区重复写;幂等用序号去重,避免"多扣一次款""重复触发"。
- 注意它只保证"分区内"恰一次;跨分区一致性需要事务。
5. 事务性生产者
- 目标:跨分区/主题的一致性(要么全成要么全不成)
- 配置:
transactional.id=<稳定唯一>(自动启用幂等) - 流程:
initTransactions()→beginTransaction()→ 多次produce()→commitTransaction()/abortTransaction() - 消费端:
isolation.level=read_committed才只读到已提交数据
使用时机:跨分区/多主题的原子写入(订单主表 + 变更日志、状态转换流水)。
代价:更高延迟、更多状态管理;失败路径必须 abort_transaction()。
6. QoS(服务质量)解析
Kafka 不用 MQTT 的"QoS 0/1/2"叫法,但可用配置实现三种常见语义:最多一次 / 至少一次 / 恰一次。
6.1 语义与取舍
| 语义 | 定义 | 典型场景 | 风险/成本 |
|---|---|---|---|
| 最多一次 (At-most-once) | 可能丢,不重复 | 海量日志、低价值埋点 | 可靠性低,但延迟/吞吐最好 |
| 至少一次 (At-least-once) | 不丢,可重复 | 订单事件、账务(下游幂等) | 需去重;可能乱序 |
| 恰一次 (Exactly-once) | 不丢不重 | 强一致流水、跨主题双写 | 复杂度/开销更高 |
6.2 参数映射(Python confluent-kafka)
决策速查:
- 可丢?→ 最多一次(吞吐优先)
- 不可丢,但可重放?→ 至少一次(下游去重)
- 不丢不重?→ 分区内幂等;跨分区需要事务 + read_committed
A. 最多一次(吞吐/时延优先)
python
conf = {
"bootstrap.servers": "localhost:9092",
"acks": "0",
"enable.idempotence": False,
"retries": 0,
"compression.type": "zstd",
"linger.ms": 20,
"batch.size": 128 * 1024,
"max.in.flight.requests.per.connection": 8,
}B. 至少一次(可靠优先,允许重复)
python
conf = {
"bootstrap.servers": "localhost:9092",
"acks": "all",
"enable.idempotence": False, # 保持"至少一次"
"compression.type": "zstd",
"linger.ms": 10,
"batch.size": 64 * 1024,
"request.timeout.ms": 30000,
"delivery.timeout.ms": 120000,
"retries": 2147483647, # 近似无限重试
"max.in.flight.requests.per.connection": 6, # 吞吐高但可能乱序
}C. 恰一次(分区内)
python
conf = {
"bootstrap.servers": "localhost:9092",
"acks": "all",
"enable.idempotence": True, # 幂等
"compression.type": "zstd",
"linger.ms": 10,
"batch.size": 64 * 1024,
"max.in.flight.requests.per.connection": 5, # 保守
}D. 恰一次(事务,跨分区/主题)
python
from confluent_kafka import Producer, KafkaException
conf = {
"bootstrap.servers": "localhost:9092",
"acks": "all",
"enable.idempotence": True,
"transactional.id": "biz-tx-producer-001", # 稳定唯一
"compression.type": "zstd",
"linger.ms": 10,
}
p = Producer(conf)
p.init_transactions()
try:
p.begin_transaction()
# ... 多次 p.produce()
p.commit_transaction()
except KafkaException:
p.abort_transaction()
finally:
p.flush()快速选型
-
可丢?→ 最多一次
-
不可丢,可重?→ 至少一次
-
不可丢不可重:
- 单分区/单主题→幂等
- 跨分区/多主题→事务 (+
read_committed)
7. 参数建议表
| 参数 | 推荐/说明 |
|---|---|
acks |
all(可靠);0/1(吞吐) |
enable.idempotence |
true(防重复,分区内恰一次) |
transactional.id |
需要事务时设置稳定唯一值 |
linger.ms |
5--20ms(攒批) |
batch.size |
32--128KB |
compression.type |
zstd |
max.in.flight.requests.per.connection |
≤5(配合幂等/顺序) |
delivery.timeout.ms |
120000(端到端交付窗口) |
request.timeout.ms |
30000 |
8. Python 代码示例
8.1 幂等生产(非事务)
python
from confluent_kafka import Producer
import socket
conf = {
"bootstrap.servers": "localhost:9092",
"client.id": socket.gethostname(),
"acks": "all",
"enable.idempotence": True,
"compression.type": "zstd",
"linger.ms": 10,
"batch.size": 64 * 1024,
"max.in.flight.requests.per.connection": 5,
}
producer = Producer(conf)
def dr_cb(err, msg):
if err:
print("Delivery failed:", err)
else:
print(f"Delivered to {msg.topic()}[{msg.partition()}]@{msg.offset()}")
for i in range(100):
producer.produce("demo-topic", key=f"k-{i%10}", value=f"v-{i}", on_delivery=dr_cb)
producer.flush()8.2 事务性生产
python
from confluent_kafka import Producer, KafkaException
conf = {
"bootstrap.servers": "localhost:9092",
"acks": "all",
"enable.idempotence": True,
"transactional.id": "order-tx-producer-001",
"compression.type": "zstd",
"linger.ms": 10,
}
p = Producer(conf)
p.init_transactions()
try:
p.begin_transaction()
for i in range(10):
p.produce("orders", key=f"order-{i}", value=f"created-{i}")
p.produce("orders-changelog", key=f"order-{i}", value=f"log-{i}")
p.commit_transaction()
except KafkaException as e:
p.abort_transaction()
raise
finally:
p.flush()9. 实践建议 & 常见坑
- 可靠性 :
acks=all+min.insync.replicas>=2+replication.factor>=3;禁用unclean.leader.election。 - 顺序与吞吐 :
max.in.flight越大吞吐越高但更易乱序;幂等场景≤5更稳。 - 重试与时限 :
delivery.timeout.ms控制"最终失败"窗口;与retries/request.timeout.ms搭配。 - 监控 :
record-send-rate、request-latency-avg、record-retry-rate、record-error-rate、compression-rate-avg、批大小均值等。 - 不要混用语义 :幂等+acks=1/0 无法保证语义;事务端若消费端没开
read_committed仍会读到未提交。 - 热点分区:同一个/少量 key 写入过多导致倾斜;用"主键+盐值"或更均匀的 key;需要有序时结合复合 key 但保留可聚合性。
- 压缩依赖缺失 :
snappy/lz4/zstd未安装会触发错误;本仓库已做降级/回退,生产环境记得安装依赖。 - IPv6 坑 :macOS 上
localhost解析为::1可能连不上,用127.0.0.1或设置KAFKA_BOOTSTRAP。
10. 使用本仓库封装(kafka-python)快速上手
本仓库
lesson_three/common.py封装了稳健默认值,便于快速演示与接入。适合需要直接跑通的同学。
python
from lesson_three.common import make_producer, warmup_producer, close_safely
from datetime import datetime
topic = "demo.producer"
producer = make_producer(
acks="all", # 可靠
linger_ms=10, # 攒批
batch_size=64 * 1024,
compression_type="gzip", # 默认无需额外依赖;可换 zstd
)
try:
warmup_producer(producer, topic)
for i in range(10):
producer.send(
topic,
key=f"user-{i % 3}",
value={"ts": datetime.now().isoformat(), "i": i},
)
producer.flush()
finally:
close_safely(producer)说明:该封装基于 kafka-python,不提供"幂等/事务"语义;若需事务/幂等,请使用上文的 confluent-kafka 示例。
11. 典型业务场景 → 推荐配置映射
| 场景 | 目标 | 关键配置 | 备注 |
|---|---|---|---|
| 海量埋点/日志 | 吞吐与成本优先,可容忍少量丢失 | acks=0,compression=zstd,linger.ms=20,batch.size=128KB |
服务器端配合更高批量、异步落库 |
| 订单事件(允许重复) | 不丢但可重复 | acks=all,enable.idempotence=false,retries≈∞,delivery.timeout.ms=120s |
下游按业务键去重;max.in.flight 可放宽到 6--8 |
| 单分区强一致流水 | 分区内"恰一次" | acks=all,enable.idempotence=true,max.in.flight<=5 |
同一业务键路由到同一分区,避免跨分区一致性 |
| 跨主题双写(订单+变更日志) | 跨分区/主题一致 | transactional.id 唯一、开启事务;消费端 read_committed |
失败时必须 abort_transaction() |
| IoT 传感器高频上报 | 延迟敏感、可容忍丢失 | acks=0/1,linger.ms<=5,compression=zstd |
批量不要过大,避免尾延迟 |
12. 生产就绪检查清单(Checklist)
- 集群与主题
- 确认
replication.factor>=3、min.insync.replicas>=2 - 关闭
unclean.leader.election - 针对大消息配置
message.max.bytes与replica.fetch.max.bytes
- 确认
- Producer 端
- 可靠性:
acks=all+ 合理retries/delivery.timeout.ms - 顺序:幂等场景将
max.in.flight.requests.per.connection<=5 - 吞吐:合理设置
batch.size与linger.ms,开启compression.type=zstd - 观测:埋点回调错误率、平均批大小、压缩率、请求时延
- 可靠性:
- 事务流
transactional.id稳定唯一且可恢复- 失败路径必须
abort_transaction(),并处理补偿逻辑 - 消费侧开启
isolation.level=read_committed
- 运维监控
- 指标:
record-send-rate、record-error-rate、request-latency-avg、record-retry-rate - Lag 监控与告警;主题分区热点检查
- 指标:
13. 实战案例
案例 A:订单创建 + 变更日志双写(事务)
需求:订单主数据写 orders,同时写审计 orders-changelog,两者必须同时成功或同时失败。
关键点:使用事务性生产者;消费侧使用 read_committed;失败路径 abort_transaction()。
python
from confluent_kafka import Producer, KafkaException
conf = {
"bootstrap.servers": "localhost:9092",
"acks": "all",
"enable.idempotence": True,
"transactional.id": "order-tx-producer-001",
"compression.type": "zstd",
}
p = Producer(conf)
p.init_transactions()
try:
p.begin_transaction()
p.produce("orders", key="order-1001", value="created")
p.produce("orders-changelog", key="order-1001", value="audit-created")
p.commit_transaction()
except KafkaException:
p.abort_transaction()
raise
finally:
p.flush()案例 B:埋点日志高吞吐上报(最多一次)
目标:极致吞吐与成本,允许少量丢失。
建议:acks=0、compression=zstd、linger.ms=20、batch.size=128KB。
python
from confluent_kafka import Producer
conf = {
"bootstrap.servers": "localhost:9092",
"acks": "0",
"compression.type": "zstd",
"linger.ms": 20,
"batch.size": 128 * 1024,
}
p = Producer(conf)
for i in range(100000):
p.produce("tracking", value=f"event-{i}")
p.flush()需要的话,我可以把这篇再导成 Markdown 文件或加一页"参数对照速查卡"。
14. 在线 HTML 演示(本地运行)
为了直观理解
acks/批量/压缩/key对分区与吞吐的影响,提供了一个极简的网页 Demo(基于 FastAPI)。
目录:lesson_three/web_demo
- 安装依赖(建议虚拟环境)
bash
pip install fastapi uvicorn kafka-python pydantic- 启动 Demo(默认 http://127.0.0.1:8000)
bash
uvicorn lesson_three.web_demo.main:app --reload-
打开浏览器访问,填写参数并发送
说明:
- 后端复用本仓库
lesson_three/common.py的make_producer/warmup_producer封装。 - 该 Demo 基于
kafka-python,用于直观理解批量/压缩/QoS 的实际效果。 - 如需"幂等/事务"语义,请参考上文
confluent-kafka示例。
15. Web Demo 实验手册(一步步做)
实验前提:已按第 14 节启动 Demo,浏览器打开 http://127.0.0.1:8000/。
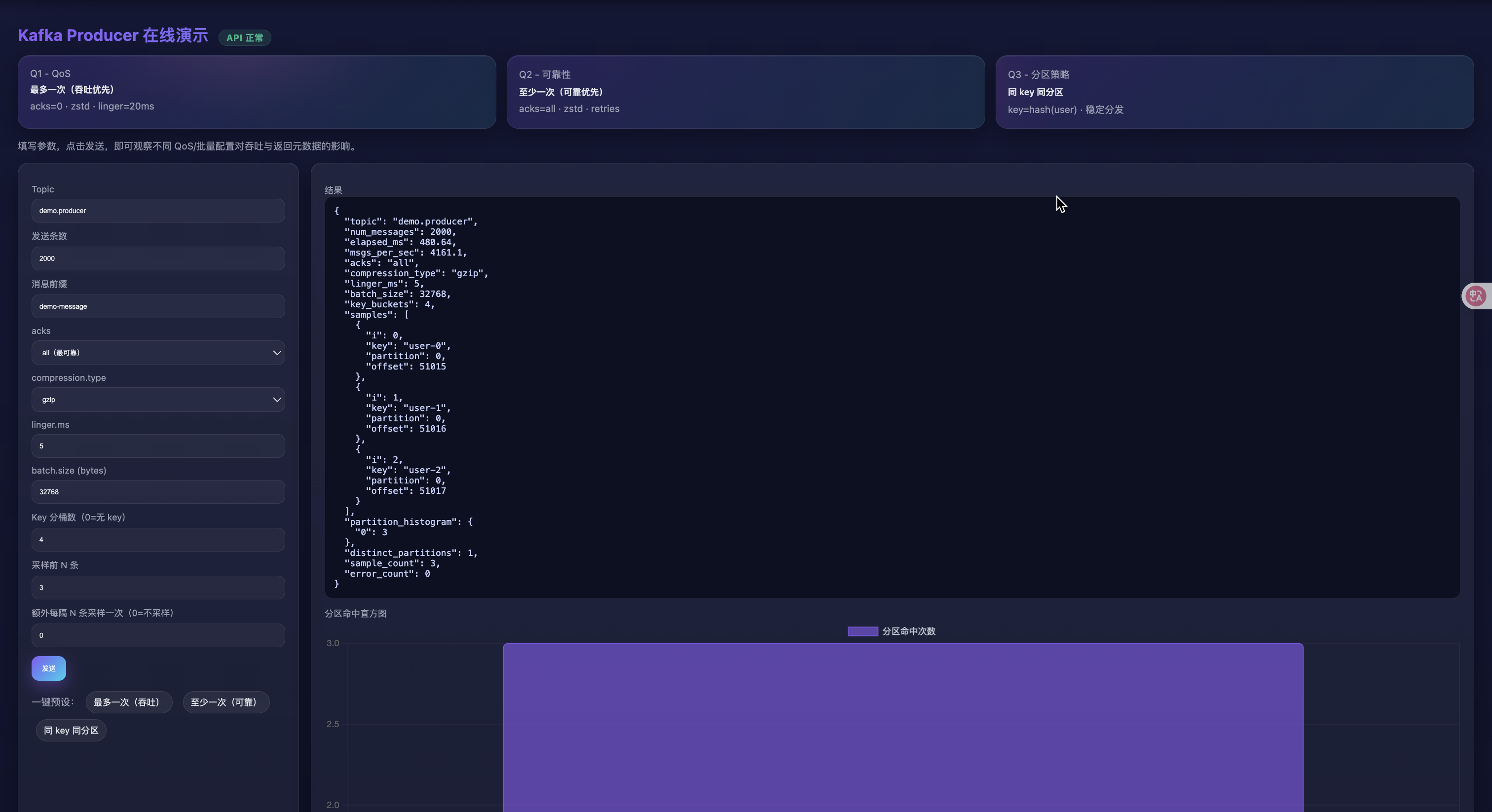
- 同 key 同分区(验证分区器)
- 设置:
acks=all、key 分桶数=4、num_messages=1000、其他默认 - 观察:返回 JSON 的
samples中相同key的partition应保持一致;partition_histogram会显示命中的分区与次数。
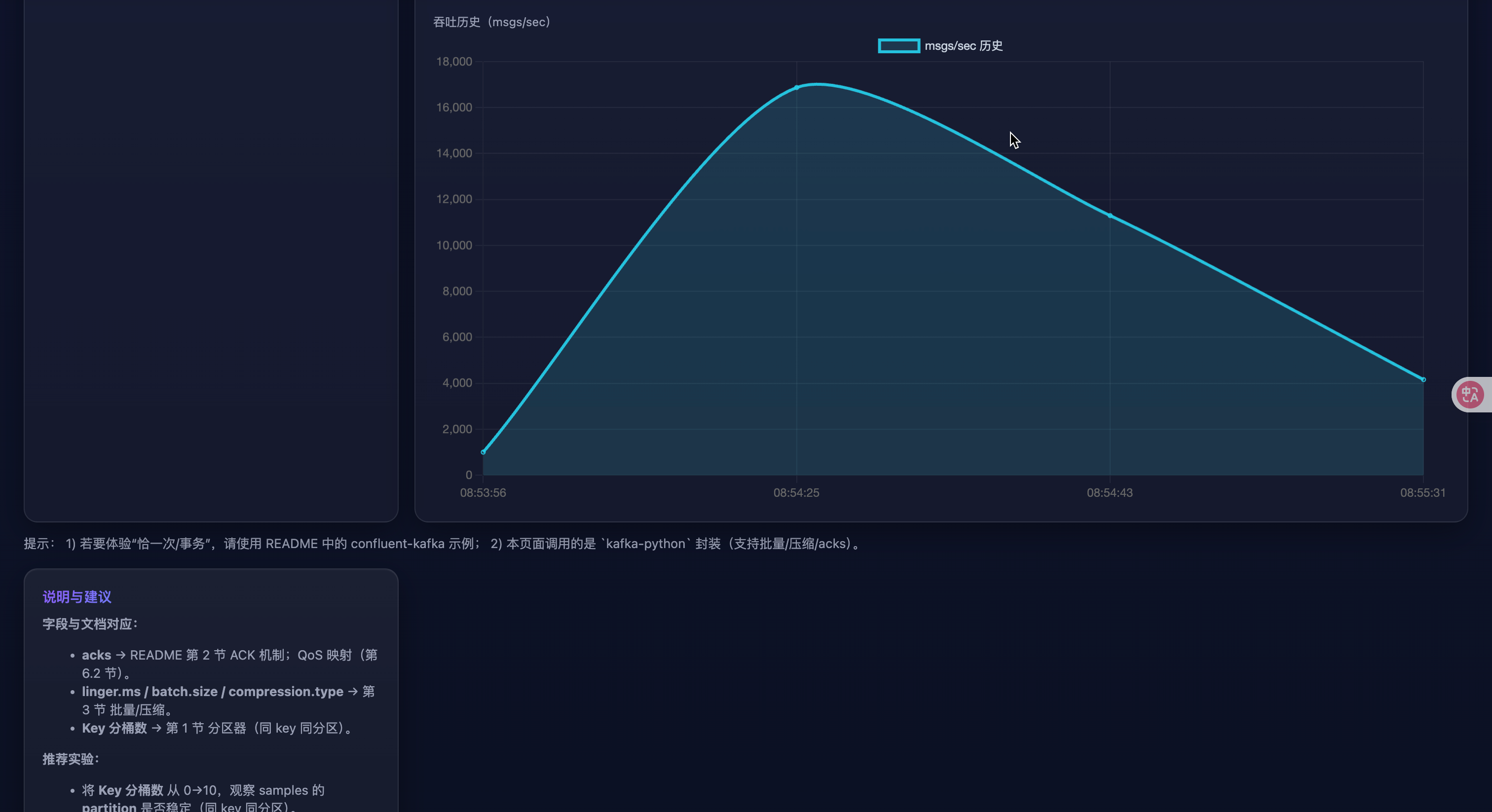
- 攒批换吞吐(验证 batch/linger)
- 对比 A:
linger.ms=0、batch.size=32768与 B:linger.ms=20、batch.size=131072 - 观察:B 的
msgs_per_sec通常更高,但elapsed_ms可能略大(延迟换吞吐)。
- 压缩算法对比(网络 vs CPU)
- 依次选择
compression.type=none/gzip/zstd(消息量 10000+ 更明显) - 观察:
zstd在网络瓶颈场景下吞吐更优;若 CPU 紧张,可能gzip/none更稳。
- 可靠性与时延取舍(acks)
- 对比:
acks=0、acks=1、acks=all - 观察:acks 越强,
elapsed_ms越大;在 broker 异常时,acks=all可能返回错误或显著变慢,acks=0"更快但有风险"。
- 分区倾斜(热点 key)
- 设置:
key 分桶数=2,num_messages=5000 - 观察:
partition_histogram若某分区远高于其他分区,说明出现热点,需优化 key 设计(见第 17 节)。
返回结果字段说明(来自 /api/send):
elapsed_ms:端到端发送耗时;msgs_per_sec:估算吞吐samples[]:采样若干条写入结果(含key/partition/offset或error)partition_histogram:采样命中分区的计数直方图distinct_partitions:命中的唯一分区数sample_count / error_count:采样条数与失败数
16. Web Demo 故障排查
-
API 返回非 JSON,页面提示
Unexpected token 'I' ...:- 原因:后端 500 错误被浏览器当作文本解析。已在 Demo 中统一返回 JSON 错误并在前端降级显示文本;若仍出现,请查看
uvicorn控制台日志。
- 原因:后端 500 错误被浏览器当作文本解析。已在 Demo 中统一返回 JSON 错误并在前端降级显示文本;若仍出现,请查看
-
Kafka 连不通或超时:
- 确认本地/远端 Kafka 已启动;必要时导出
KAFKA_BOOTSTRAP环境变量(建议127.0.0.1:9092避免 IPv6 解析)。 - 端口占用或网络策略限制时,优先用 IP 而非
localhost。
- 确认本地/远端 Kafka 已启动;必要时导出
-
压缩算法不可用:
kafka-python对snappy/lz4/zstd需要额外依赖;若未安装会抛出断言错误。Demo 将返回 500。- 解决:改用
gzip/none,或安装对应压缩库(如pip install python-snappy lz4 zstandard)。
-
分区/偏移不显示:
acks=0时无确认,不保证返回元数据;改用acks=1/all验证。
17. 生产者实践技巧(落地经验)
-
Key 设计与倾斜治理:
- 尽量使用业务主键或其哈希作为 key,保证同一实体有序且分散。
- 发现
partition_histogram倾斜时,可引入"复合 key(主键 + 盐值)"、时间片打散,或增加分区数并配合再均衡。
-
压缩选型:
- 优先
zstd(压缩率/速度折中好);CPU 紧张或未装依赖时可退回gzip。 - 关注
compression-rate-avg与端侧 CPU 使用率,动态调参。
- 优先
-
顺序与吞吐:
- 需要"分区内有序"且幂等 →
enable.idempotence=true+acks=all+max.in.flight<=5(在 confluent-kafka 中配置)。 - 追求吞吐 → 放宽
max.in.flight,增大batch.size,增加linger.ms。
- 需要"分区内有序"且幂等 →
-
超时与重试:
delivery.timeout.ms定义"最终失败"窗口;与request.timeout.ms、retries配合使用。- 监控
record-retry-rate、record-error-rate,排查网络抖动或 ISR 不足。
-
批大小与内存:
batch.size是单分区批上限;过大可能增加尾延迟与内存占用。- 搭配
linger.ms小步调优,观察平均批大小与 99 线时延。
-
监控指标(建议接入可视化):
- 发送速率、请求时延、重试/错误率、平均批大小、压缩率、每分区写入速率;结合消费端
lag与分区热点。
- 发送速率、请求时延、重试/错误率、平均批大小、压缩率、每分区写入速率;结合消费端
A. 术语小抄(Glossary)
- Producer:生产者客户端,负责写消息到 Kafka。
- RecordAccumulator:客户端侧的分区批缓冲区,受
batch.size/linger.ms影响。 - Partition:主题的分片;同一分区内写入有序。
- Key(分区键):哈希后决定分区;同 key 同分区,便于聚合与有序。
- Sticky Partitioner:无 key 时使用的"粘性分区器",提升批量效率。
- acks:写入确认级别(0/1/all);越强越可靠,延迟越大。
- ISR(In-Sync Replicas):与 leader 同步的副本集合。
- Idempotent Producer:幂等生产者;分区内 Exactly-once(不重复)。
- Transactional Producer:事务生产者;跨分区/主题的原子性(要么全成)。
- EOS(Exactly-once Semantics):恰一次语义;分区内靠幂等,跨分区靠事务+
read_committed。 batch.size:单分区批上限字节;越大吞吐越高、尾延迟越高。linger.ms:攒批等待时间;增大可提升吞吐、增加延迟。max.in.flight.requests.per.connection:同连接并行请求数;大→吞吐高但易乱序。compression.type:压缩算法(zstd/gzip/snappy/lz4/none)。delivery.timeout.ms:端到端交付窗口(超过视为失败)。request.timeout.ms:单次请求超时。replication.factor:副本数;min.insync.replicas:可写入需要的最小同步副本。unclean.leader.election:是否允许非同步副本选主;生产禁用以防数据倒退。read_committed:消费者只读已提交的事务消息。- Lag:消费者相对最新偏移的滞后量。
B. 常见问题(FAQ)
Q1:acks=all 还可能丢吗?
- 会的:当
replication.factor太小、min.insync.replicas设置不当或启用了unclean.leader.election时,发生失败切换可能导致丢失或倒退。生产建议:replication.factor>=3、min.insync.replicas>=2、禁用unclean.leader.election。
Q2:幂等就是全局恰一次吗?
- 不是。幂等仅保证"分区内"不重复。跨分区/主题要恰一次需要事务,并在消费端打开
read_committed。
Q3:事务和幂等的关系?
- 事务会自动启用幂等。幂等解决"分区内重复",事务解决"跨分区原子性"。
Q4:吞吐很低怎么办?
- 增大
batch.size与linger.ms,开启compression=zstd;检查网络/磁盘瓶颈;放宽max.in.flight(非幂等场景)。
Q5:延迟太高怎么办?
- 降低
linger.ms,适度减小batch.size;必要时用acks=1(权衡可靠性)。
Q6:为什么看到乱序?
- 重试 +
max.in.flight过大易乱序;幂等场景收敛到<=5;同 key 才能谈"有序"。
Q7:如何判断分区热点?
- 观察分区写入速率、消费者 Lag 与本文 Web Demo 的
partition_histogram。热点时优化 key(主键+盐值/复合 key)或扩分区并再均衡。
Q8:压缩用什么?
- 优先
zstd;CPU 紧张或依赖安装困难时退gzip;网络空闲时可暂不开启。
Q9:KafkaTimeoutError: Timeout after waiting for 30 secs. 怎么办?
- 多为连不通或 topic 不存在。优先使用 IPv4:
KAFKA_BOOTSTRAP=127.0.0.1:9092,确认kafka-topics.sh --create --topic <name>已创建;重启 Demo 后再试。
Q10:Demo 为什么 acks=0 时 sample 没有分区/偏移?
- 因为不等待确认,客户端未必拿到元数据。以吞吐/耗时评估即可,验证分区请改用
acks=1/all。