前言:
项目git链接 :mq/mqdemo/muduo/protobuf/protobuf_client.cpp · 耀空/项目mq - 码云 - 开源中国
使用技术简介:
开发主语言:C++
序列化框架:Protobuf 二进制序列化
网络通信:自定义应用层协议 + muduo 库(对 tcp 长连接的封装、并且使用 epoll 的事件驱动模式,实现高并发服务器与客户端)
源数据信息数据库: SQLite3
单元测试框架: Gtest
- 这一篇来了解这个项目的主要框架,在理解这个框架的基础上,后面在写代码,设计和划分模块就简单了;
首先看看核心需求是什么;
核心需求
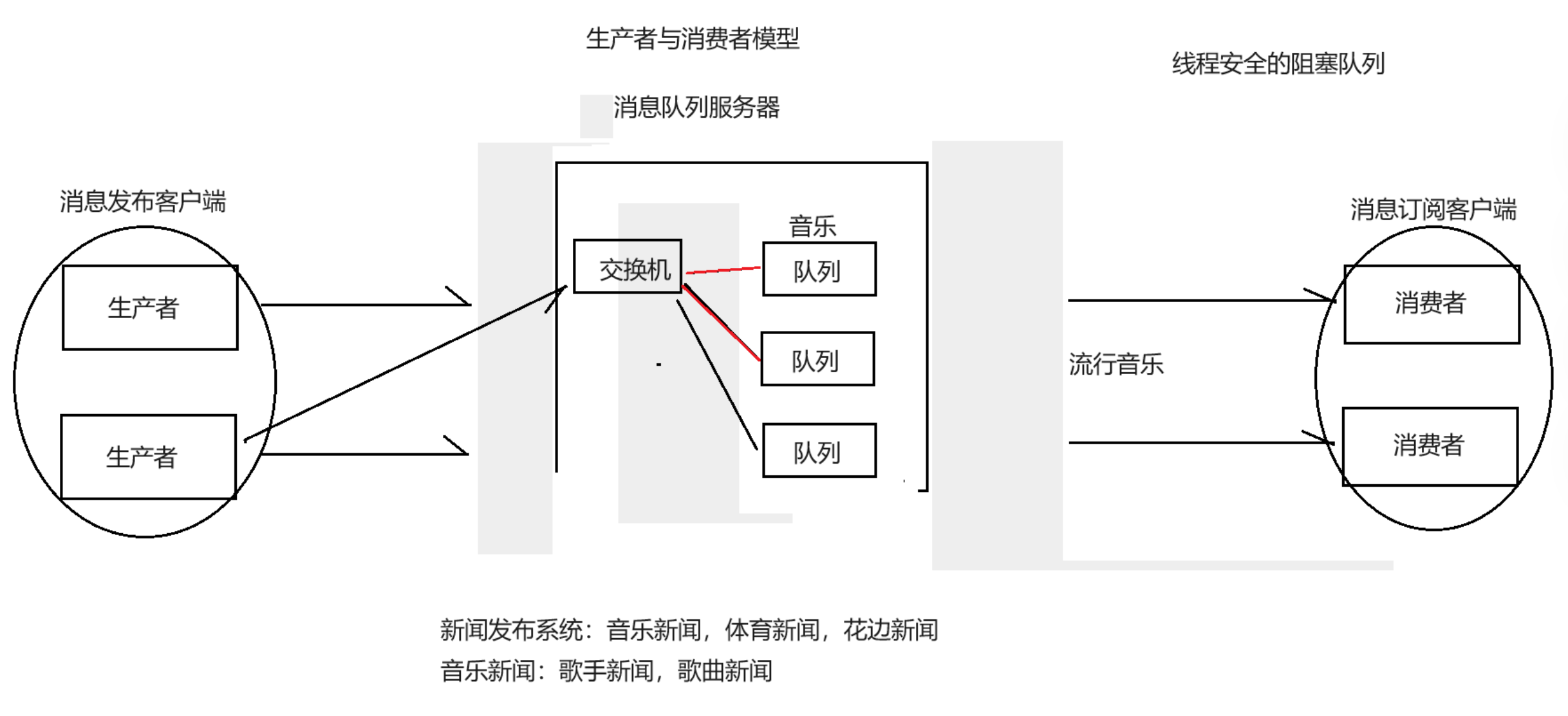
其实就类似于一个生产者消费者模型;
一个生产者一个消费者
多个生产者多个消费者
- 所以可以知道,主要成员有,生产者 (Producer) ,消费者 (Consumer) ,中间人 (Broker) ,发布 (Publish) ,订阅 (Subscribe);
而Broker又是怎么把消息进行传递的?
Broker Server
通过上图可知,Broker Server 是最核心的部分, 负责消息的存储和转发;
- 而我们是模仿了RabbitMQ这个消息队列,同时也是用和他一样的协议----AMQP(Advanced Message Queuing Protocol-高级消息队列协议)
一个提供统一消息服务的应用层标准高级消息队列协议,为面向消息的中间件设计,使得遵从该规 范的客户端应用和消息中间件服务器的全功能互操作成为可能;
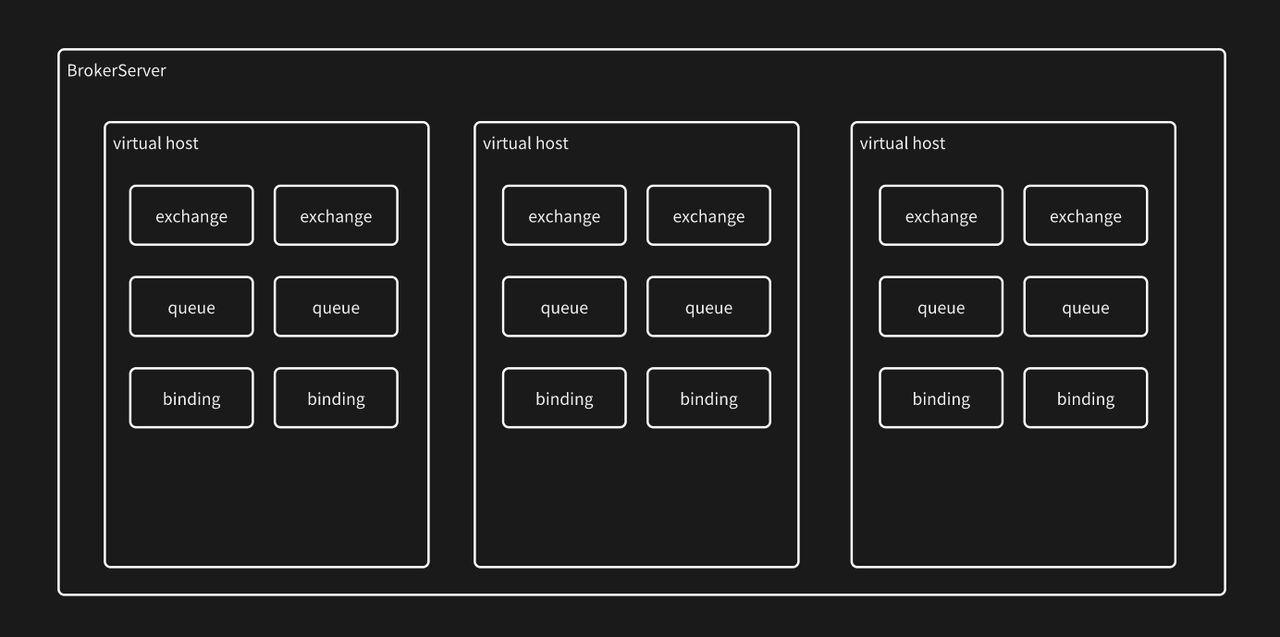
所以Broker Server存在下面成员结构 ;
- 虚拟机 (VirtualHost): 类似于 MySQL 的 "database", 是一个逻辑上的集合。一个 BrokerServer 上可以存在多个 VirtualHost
- 交换机 (Exchange): 生产者把消息先发送到 Broker 的 Exchange 上,再根据不同 的规则, 把消息转发给不同的 Queue
- 队列 (Queue): 真正用来存储消息的部分, 每个消费者决定自己从哪个 Queue 上 读取消息
- 绑定 (Binding): Exchange 和 Queue 之间的关联关系,Exchange 和 Queue 可以 理解成 "多对多" 关系,使用一个关联表就可以把这两个概念联系起来
- 消息 (Message): 传递的内容
Broker Server的成员结构
所以:
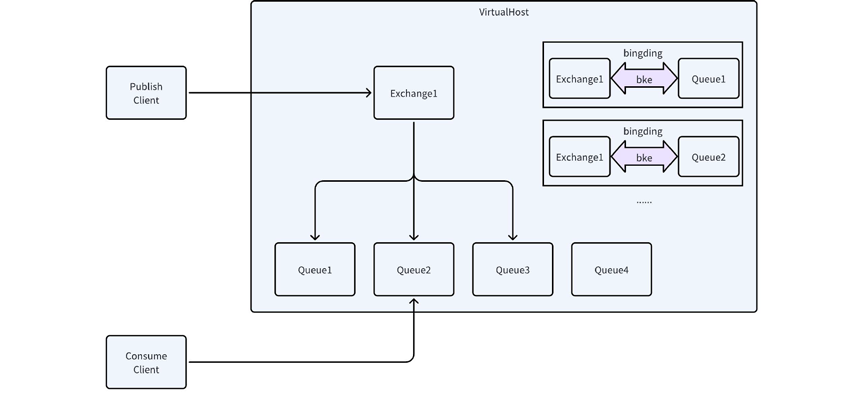
所谓的 Exchange 和 Queue 可以理解成 "多对多" 关系, 和数据库中的 "多对多" 一 样. 意思是:
- 一个 Exchange 可以绑定多个 Queue (可以向多个 Queue 中转发消息)
- 一个 Queue 也可以被多个 Exchange 绑定 (一个 Queue 中的消息可以来自于多个 Exchange)
以一个虚拟机VirtualHost为例子,Broker Server的流程图;
成员结构的储存
数据结构, 不是简单的只在内存中存储, 同时也需要在硬盘中存储
- 在内存存储是可以方便使用
- 硬盘存储是为了重启数据不丢失,提高安全性
核心 API
对于 Broker 来说, 要实现以下核心 API,通过这些 API 来实现消息队列的基本功能
通过上面Broker Server的成员结构,就可以大概怎么API有那些了
如下
- 创建虚拟机 (virtualhostDeclare),销毁虚拟机(virtualhostDelete)
- 创建交换机 (exchangeDeclare) ,销毁交换机 (exchangeDelete)
- 创建队列 (queueDeclare), 销毁队列 (queueDelete)
- 创建绑定 (queueBind) ,解除绑定 (queueUnbind)
- 发布消息 (basicPublish),确认消息 (basicAck)
- 订阅消息 (basicConsume),取消订阅 (basicCancel)
但是, Producer 和 Consumer 都是通过网络的方式, 远程调用这些 API, 实现 生产者 消费者模型
所以还需要实现网络通信
网络通信
生产者和消费者都是客户端程序, Broker 则是作为服务器,通过网络进行通信。
在网络通信的过程中, 客户端部分要提供对应的 api, 来实现对服务器的操作。
客户端,要用到的核心api
- 创建 Connection , 关闭 Connection
- 创建 Channel ,关闭 Channel
- 创建队列 (queueDeclare) ,销毁队列 (queueDelete)
- 创建交换机 (exchangeDeclare),销毁交换机 (exchangeDelete)
- 创建绑定 (queueBind),解除绑定 (queueUnbind)
- 发布消息 (basicPublish) ,确认消息 (basicAck)
- 订阅消息 (basicConsume), 取消订阅(basicCancel)
channel
网络通讯,在connection的基础还增加了channel的概念;目的就是避免频繁的创建关闭 TCP 连接;(毕竟这里与messagequeue建立链接的消费者queue很多)
在 Broker 的基础上, 客户端还要增加 Connection 操作和 Channel 操作;
- Connection 对应一个 TCP 连接
- Channel 则是 Connection 中的逻辑通道
Connection 可以理解成一根网线. Channel 则是网线里具体的线缆
所以:
**一个 Connection 中可以包含多个 Channel。**Channel 和 Channel 之间的数据是独立 的,不会相互干扰。这样做主要是为了能够更好的复用 TCP 连接, 达到长连接的效果, 避免频繁的创建关闭 TCP 连接

交换机类型
对于 RabbitMQ 来说, 主要支持四种交换机类型
Direct,Fanout,Topic,Header;
- Direct:生产者发送消息时, 直接指定被该交换机绑定的队列名
- Fanout:生产者发送的消息会被复制到该交换机的所有队列中
- Topic:绑定队列到交换机上时, 指定一个字符串为 bindingKey。发送消息指定一个 字符串为 routingKey。当 routingKey 和 bindingKey 满足一定的匹配条件的时候, 则把 消息投递到指定队列
- Header**(比较复杂, 比较少见。所以这个项目也只实现前三种)**
举个例子:

持久化
这个功能就是为了实现,硬盘存储(是为了重启数据不丢失)
Exchange, Queue, Binding, Message 等数据都有持久化需求 当程序重启 / 主机重启, 保证上述内容不丢失
消息应答
被消费的消息, 需要进行应答。应答模式分成两种:
- 自动应答: 消费者只要消费了消息, 就算应答完毕了,Broker 直接删除这个消息
- 手动应答: 消费者手动调用应答接口, Broker 收到应答请求之后, 才真正删除这个 消息
手动应答的目的, 是为了保证消息确实被消费者处理成功了. 在一些对于数据可靠性 要求高的场景, 比较常见
这两种应答都可以通过,设计一个应答函数完成;
消息队列概念性框架
要实现的有:
- broker服务器:消息队列服务器
- 消息发布客户端:从服务器发送消息;
- 消息订阅客户端:从服务器订阅消息;
AMQP协议中细化了实现规则:
- 虚拟机
- 交换机
- 队列
- 绑定
- 消息