
文章目录
[RDD-Resilient Distributed Dataset](#RDD-Resilient Distributed Dataset)
RDD-Resilient Distributed Dataset
在 Apache Spark 编程中,RDD(Resilient Distributed Dataset,弹性分布式数据集)是 Spark Core 中最基本的数据抽象,代表一个不可变、可分区、可并行计算的元素集合。RDD 允许用户在集群上以容错的方式执行计算。
一、RDD五大特性
首先回顾下Spark WordCount的核心代码流程:
Scala
sc.textFile("...").flatMap(_.split(",")).map((_,1)).reduceByKey(_+_).foreach(println)结合以上代码,我们理解RDD的五大特性,RDD理解图如下:
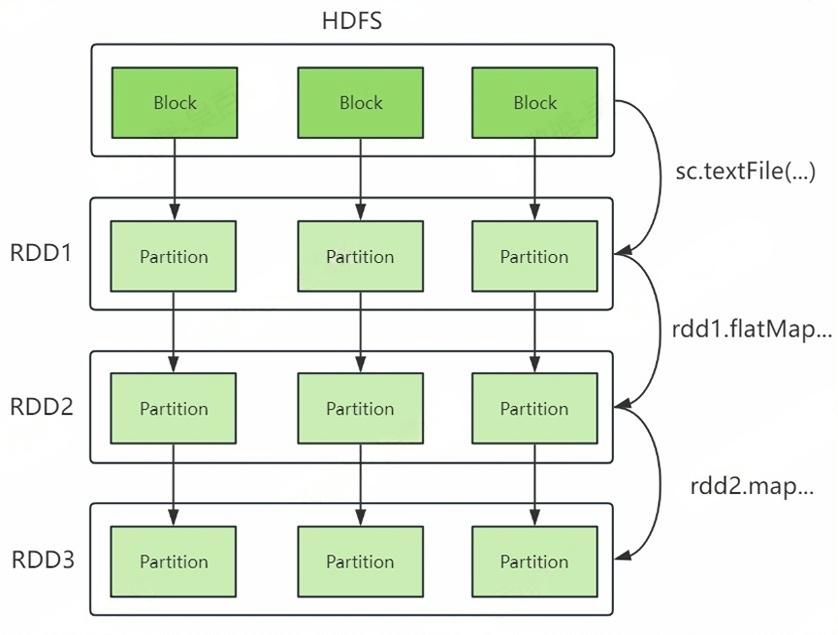
RDD五大特性:
1) RDD由一系列Partition组成(A list of partitions)
RDD由多个Partition组成,这些Partition分布在集群的不同节点上。如果读取的是HDFS中的数据,每个partition对应一个Split,每个Split大小默认与每个Block大小一样,。
2) 函数是作用在每个Partition(Split)上的(A function for computing each split)
RDD 定义了在每个分区上进行计算的函数,例如 flatMap、map 等操作,这些函数对每个分区中的数据进行处理。
3) RDD之间有依赖关系(A list of dependencies on other RDDs)
RDD之间存在依赖关系,上图中RDD2可以基于RDD1生成,RDD1叫做父RDD,RDD2叫做子RDD。
4) 分区器作用在K,V格式的RDD上(Optionally, a Partitioner for key-value RDDs)
上图中RDD3中的数据是Tuple类型,这种类型叫做K,V格式的RDD。Spark分区器作用是决定数据发往下游RDD哪个Partition中,分区器只能作用在这种K,V格式的RDD中,默认根据Key的hash值与下游RDD的Partition个数取模决定该条数据去往下游RDD的哪个Paritition中。
5) RDD提供一系列最佳的计算位置(Optionally, a list of preferred locations to compute each split on)
RDD 提供每个分区的最佳计算位置,通常是数据所在的节点,这样可以将计算task调度到数据所在的位置,减少数据传输,提高计算效率(计算移动,数据不移动原则)。
关于RDD的注意点如下:
- textFile底层读取文件方式与MR读取文件方式类似,首先对数据split,默认Split是一个block大小。
- 读取数据文件时,RDD的Paritition个数默认与Split个数相同,也可以在创建RDD的时候指定,Partition是分布在不同节点上的。
- RDD虽然叫做数据集,但实际上不存储数据,RDD类似迭代器,对象不可变,处理数据时,下游RDD会依次向上游RDD获取对应数据,这就是RDD之间为什么有依赖关系的原因。
- 如果RDD中数据类型为二元组对象,那么这种RDD我们称作K,V格式的RDD。
- RDD的弹性体现在RDD中Partition个数可以由用户设置、RDD可以根据依赖关系基于上一个RDD按照迭代器方式计算出下游RDD。
- RDD提供最佳计算位置,task发送到相应的partition节点上处理数据,体现了"计算移动,数据不移动"的理念。
二、RDD创建方式
在Spark中创建RDD可以通过读取集合、读取文件方式创建,还可以基于已有RDD转换创建,后续我们主要使用第三种方式,这里先介绍前两种方式。下面分别使用Java和Scala API演示RDD的创建。
- Java API
java
SparkConf conf = new SparkConf();
conf.setMaster("local");
conf.setAppName("generateRDD");
JavaSparkContext sc = new JavaSparkContext(conf);
//1.从集合中创建RDD,并指定并行度为3,默认并行度为1
JavaRDD<String> rdd1 = sc.parallelize(Arrays.asList("a", "b", "c", "d"),3);
System.out.println("rdd1并行度为:"+rdd1.getNumPartitions());
rdd1.foreach(new VoidFunction<String>() {
@Override
public void call(String s) throws Exception {
System.out.println(s);
}
});
//2.从集合创建K,V格式RDD
JavaPairRDD<String, Integer> rdd2 = sc.parallelizePairs(Arrays.asList(
new Tuple2<String, Integer>("a", 1),
new Tuple2<String, Integer>("b", 2),
new Tuple2<String, Integer>("c", 3),
new Tuple2<String, Integer>("d", 4)
));
rdd2.foreach(new VoidFunction<Tuple2<String, Integer>>() {
@Override
public void call(Tuple2<String, Integer> tp) throws Exception {
System.out.println(tp._1 + " " + tp._2);
}
});
//3.从文件中创建RDD,并指定并行度为3,默认并行度为1
JavaRDD<String> rdd3 = sc.textFile("./data/data.txt",3);
System.out.println("rdd3并行度为:"+rdd3.getNumPartitions());
rdd3.foreach(new VoidFunction<String>() {
@Override
public void call(String s) throws Exception {
System.out.println(s);
}
});-
Scala API
val conf = new SparkConf()
conf.setMaster("local")
conf.setAppName("GenerateRDDTest")
val sc = new SparkContext(conf)
//1.从集合创建RDD,并指定并行度为3,默认并行度为1
val rdd1 =sc.parallelize(1 to 20,3)
println(s"rdd1 并行度为:${rdd1.getNumPartitions}")
rdd1.foreach(println)//2.从集合创建K,V格式RDD
val rdd1KV:RDD[(String,Int)] = sc.parallelize(Array(("a",1),("b",2),("c",3),("d",4),("e",5)))
println(s"rdd1KV 并行度为:${rdd1KV.getNumPartitions}")
rdd1KV.foreach(println)//3.从集合创建RDD,并指定并行度为3,默认并行度为1
val rdd2 =sc.makeRDD(1 to 20,3)
println(s"rdd2 并行度为:${rdd2.getNumPartitions}")
rdd2.foreach(println)//4.从文件创建RDD,并指定并行度为3,默认并行度为1
val rdd3 = sc.textFile("./data/data.txt",3)
println(s"rdd3 并行度为:${rdd2.getNumPartitions}")
rdd3.foreach(println)
注意以下两点:
1、无论是基于集合或者文件创建RDD,默认RDD分区数为1,也可以在创建时指定RDD paritition个数;
2、Scala API中parallelize方法可以从集合中得到K,V或者非K,V格式RDD,还可以通过makeRDD方法读取集合转换成RDD。formation算子对RDD进行转换处理。
- 📢博客主页:https://lansonli.blog.csdn.net
- 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
- 📢本文由 Lansonli 原创,首发于 CSDN博客🙉
- 📢停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨