引言
在人工智能浪潮席卷全球的今天,大型语言模型(LLM)不再是遥不可及的云端技术。借助 Ollama,每一位开发者都能轻松地将强大的模型部署在自己的本地计算机上,实现无缝、私密且可定制的AI体验。本文将带领您一步步在 Ubuntu 20.04 系统上完成 Ollama 的安装与模型部署,并最终搭建美观易用的图形化界面(Open webui)。
Ollama 是什么?
Ollama 是一个开源项目,专为在本地运行、管理和部署大型语言模型(如 Llama 3、Mistral、Gemma 等)而设计。
它的核心概念与优势非常清晰:
-
简单易用 :通过简单的命令行工具,即可完成模型的下载(
pull)、运行(run)和管理。一条命令就能启动与模型的对话。 -
丰富的模型库 :它提供了官方支持的模型库(Ollama Search),包含deep-seek、qwen等数十种经过优化的大型语言模型,满足从代码生成到创意写作的各种需求。
-
"开箱即用" :它自动处理了模型运行所需的大部分复杂配置和环境依赖,用户无需关心繁琐的底层细节。
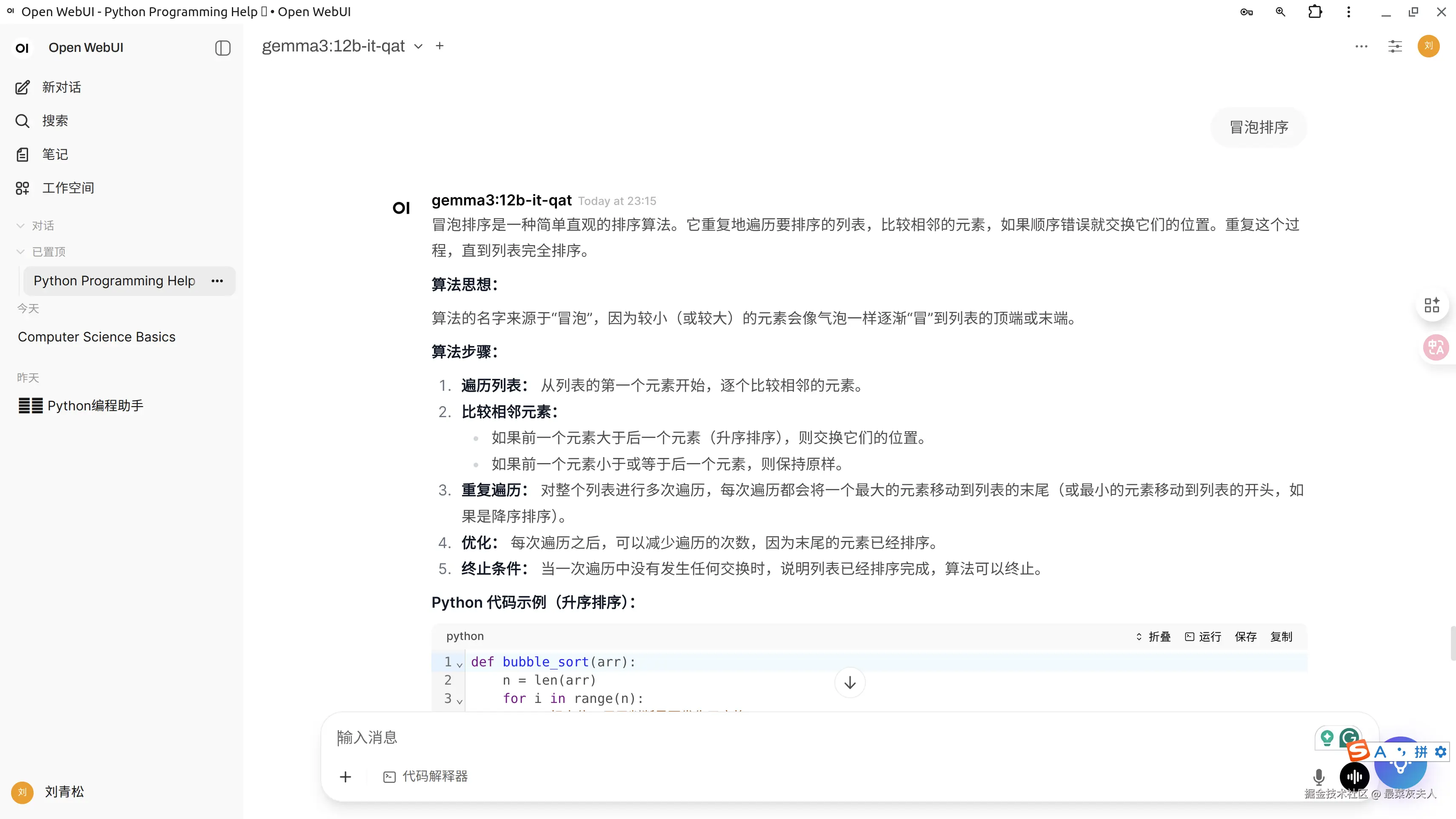
展示 Ollama 使用效果
想象一下,在您的终端中,直接与一个几十亿参数的大模型进行流畅的对话和代码编写,是一种怎样的体验?以下是在 Ubuntu 终端中运行 ollama run deepseek-coder:6.7b 后的截图:
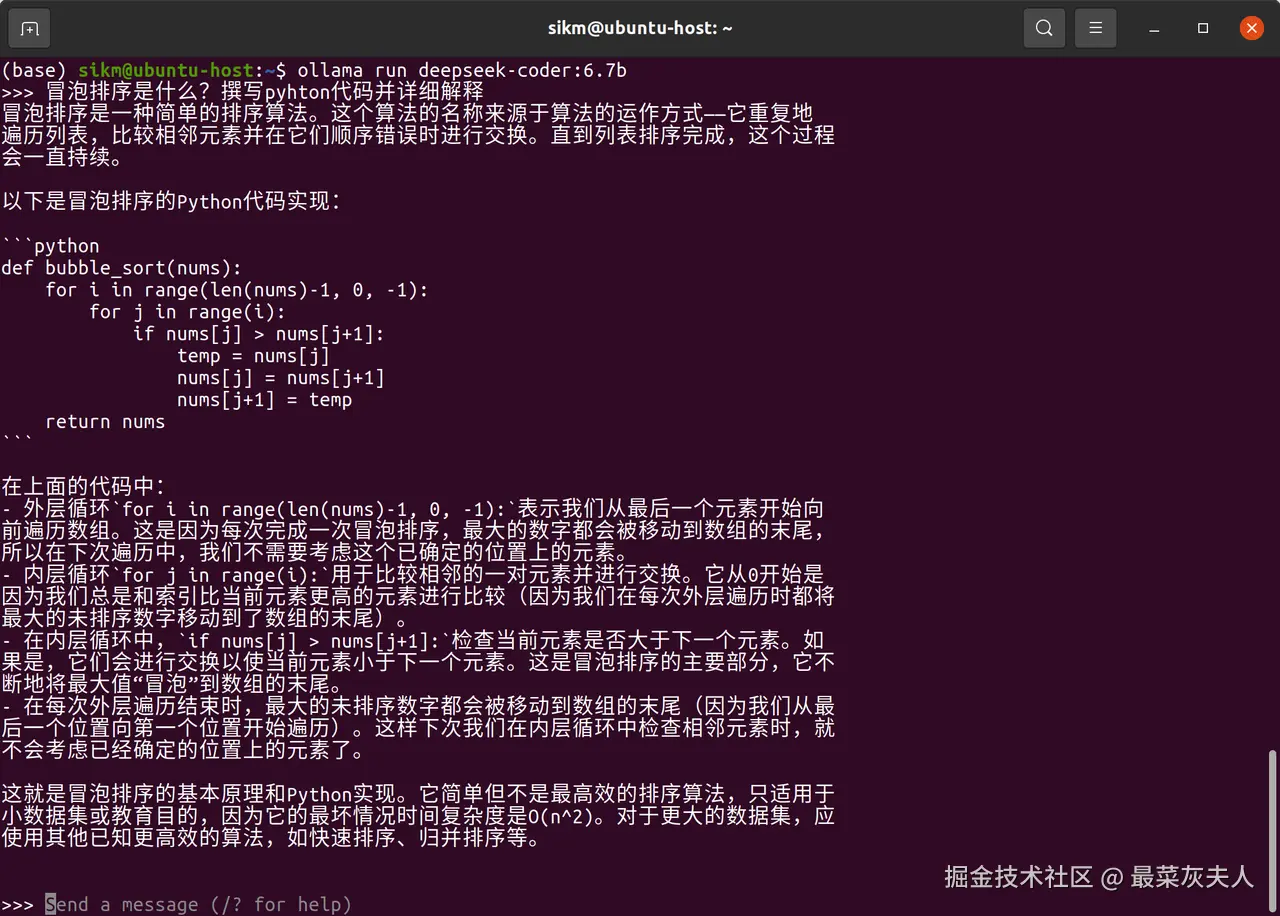 如上图所示,您可以直接在终端中提出复杂问题、寻求编程帮助或者进行头脑风暴,模型会快速给出高质量的回复,当然运行速度取决于模型参数的多少以及显卡的算力。不过在终端进行交互功能比较单一,而通过Open WebUI进行交互功能就丰富许多:
如上图所示,您可以直接在终端中提出复杂问题、寻求编程帮助或者进行头脑风暴,模型会快速给出高质量的回复,当然运行速度取决于模型参数的多少以及显卡的算力。不过在终端进行交互功能比较单一,而通过Open WebUI进行交互功能就丰富许多:
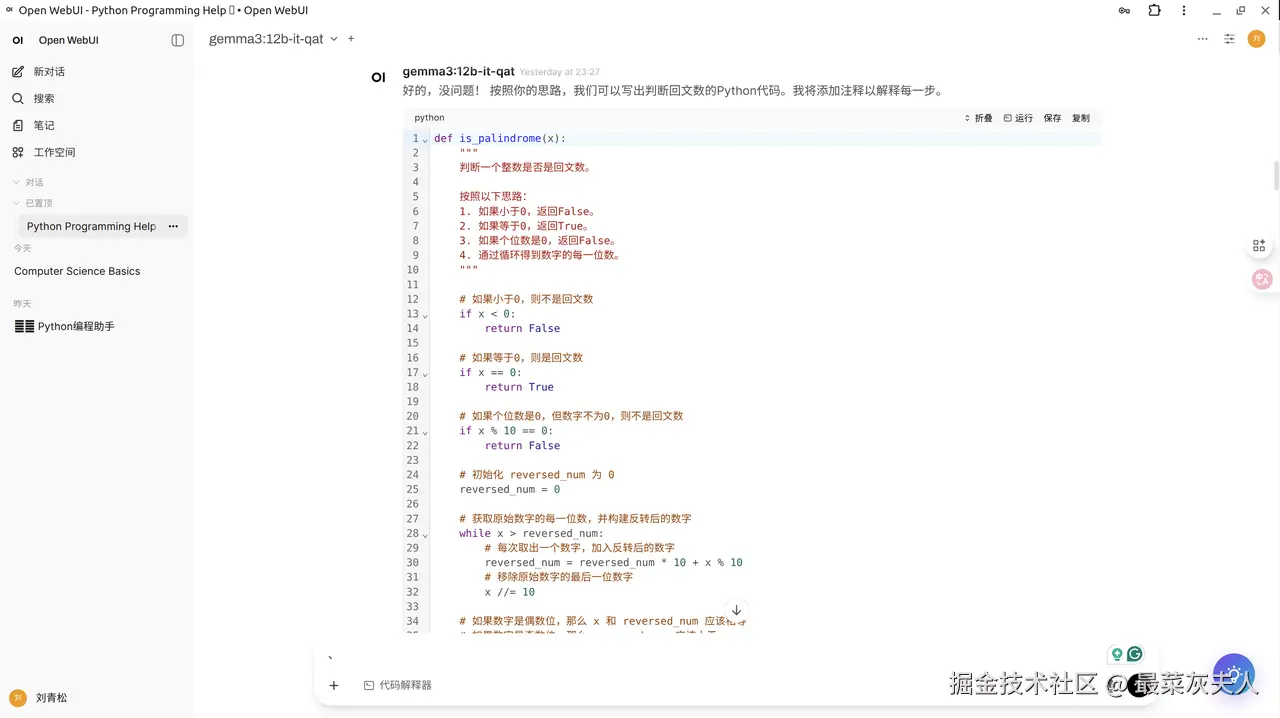
本地部署语言模型的好处与局限性
选择在本地运行 Ollama,意味着选择了一种新的 AI 交互方式,但它也并非完美无缺。
优势 (Benefits)
-
数据隐私与安全 :您的所有对话提示(Prompts)和模型生成的内容完全在本地处理,不会离开您的计算机。这对于处理敏感代码、商业数据或个人信息的用户至关重要。
-
完全离线可用:一旦模型下载完成,您就无需依赖互联网连接或担心API服务宕机,可以在任何没有网络的环境中使用。
-
可定制性:您可以尝试各种不同规模和专长的模型,甚至可以根据需要加载自定义模型(Modelfiles),灵活性远超固定的云端API。
-
无使用成本:除了电费和硬件成本外,没有按次收费或订阅费用,您可以无限次地与模型交互。
局限性 (Limitations)
-
硬件要求高 :本地部署对计算机硬件,尤其是内存(RAM)和显存(VRAM) 有较高要求。运行大型模型可能需要数十GB的资源。
-
性能差异:虽然本地推理延迟低,但模型的能力和响应速度通常无法与 OpenAI GPT-4 这类顶级付费API相提并论,尤其是在复杂推理任务上。
-
知识陈旧:本地部署的模型知识库是静态的,其知识截止日期取决于它被训练的时间点,无法像一些云端模型那样实时获取最新信息。
环境准备
设备信息
css
lsb_release -a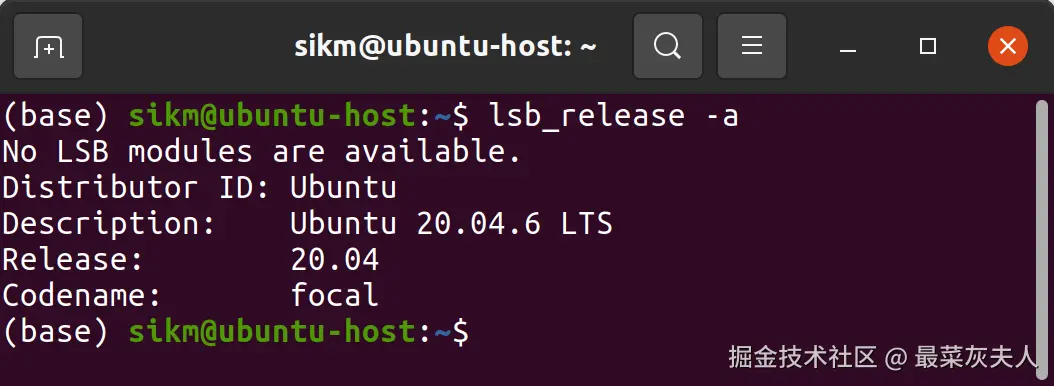
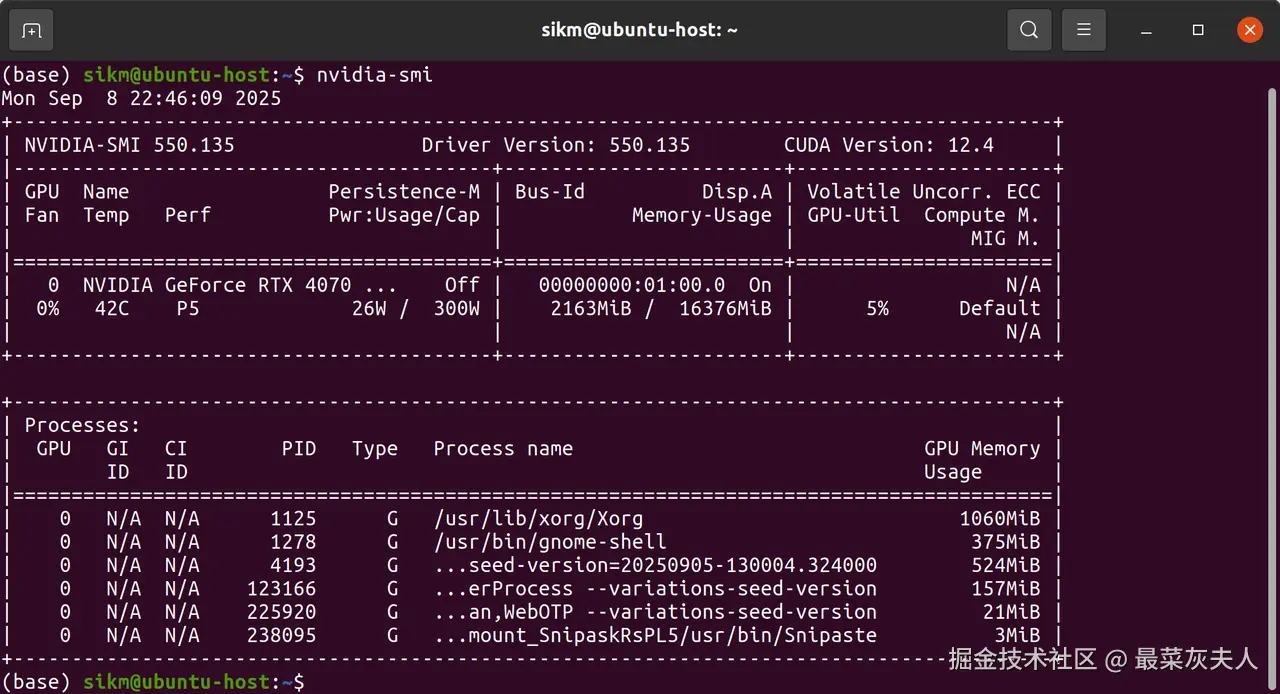
检查储存空间及显存大小
-
储存空间至少预留十几G,因为一个模型的大小都在几个G左右
-
检查显存大小,显存大小决定了能运行模型的参数量
nvidia-smi
Ollama 下载与安装
下载链接:
- 官网: ollama.com/
- GitHub: github.com/ollama/olla...
运行安装脚本:
arduino
curl -fsSL https://ollama.com/install.sh | sh-
管理Ollama服务:
bash
# 启动 Ollama 服务
sudo systemctl start ollama
# 停止 Ollama 服务
sudo systemctl stop ollama
# 重启 Ollama 服务
sudo systemctl restart ollama
# 设置开机自启
sudo systemctl enable ollama
# 查看服务日志
sudo journalctl -u ollama -f-
常用Ollama命令:
bash
# 查看所有命令帮助
ollama --help
# 运行模型(如果不存在会自动下载)
ollama run <model-name>
# 运行模型并直接提问
ollama run <model-name> "你的问题"
# 拉取(下载)模型
ollama pull <model-name>
# 列出已下载的模型
ollama list
# 删除模型
ollama rm <model-name>
# 查看已下载模型的详细信息
ollama show llama3
# 查看模型配置
ollama show llama3 --modelfileOllama 部署并运行模型
现在 Ollama 已经安装完成,让我们开始探索最令人兴奋的部分:下载和运行各种大型语言模型
查看可用模型
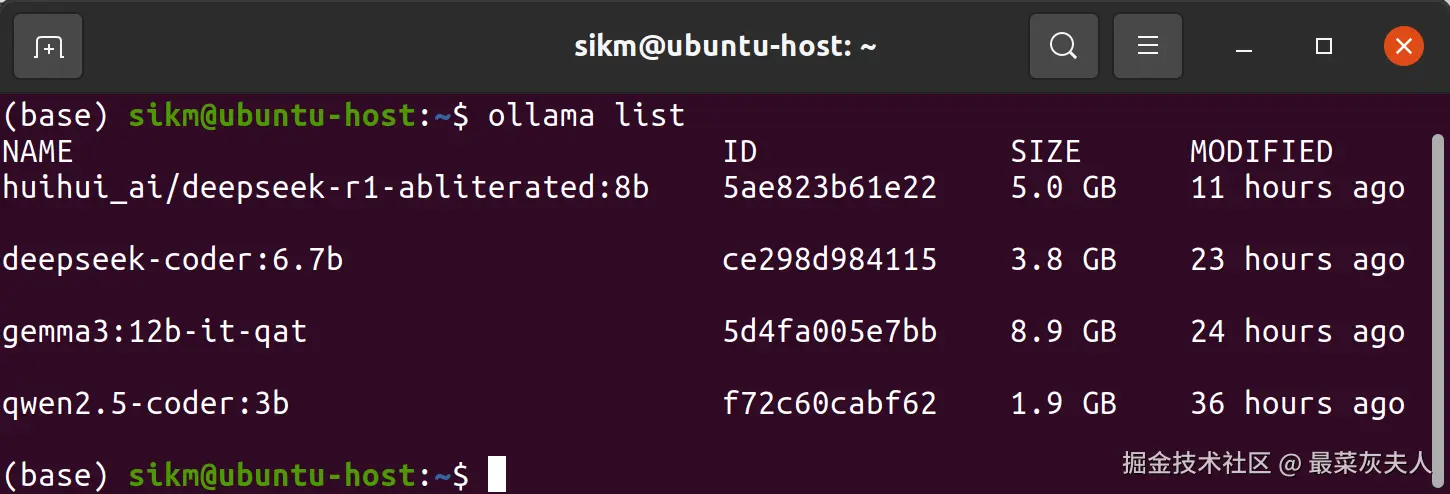
-
通过命令行查看
bash# 查看本地已下载的模型 ollama list -
通过模型库查看
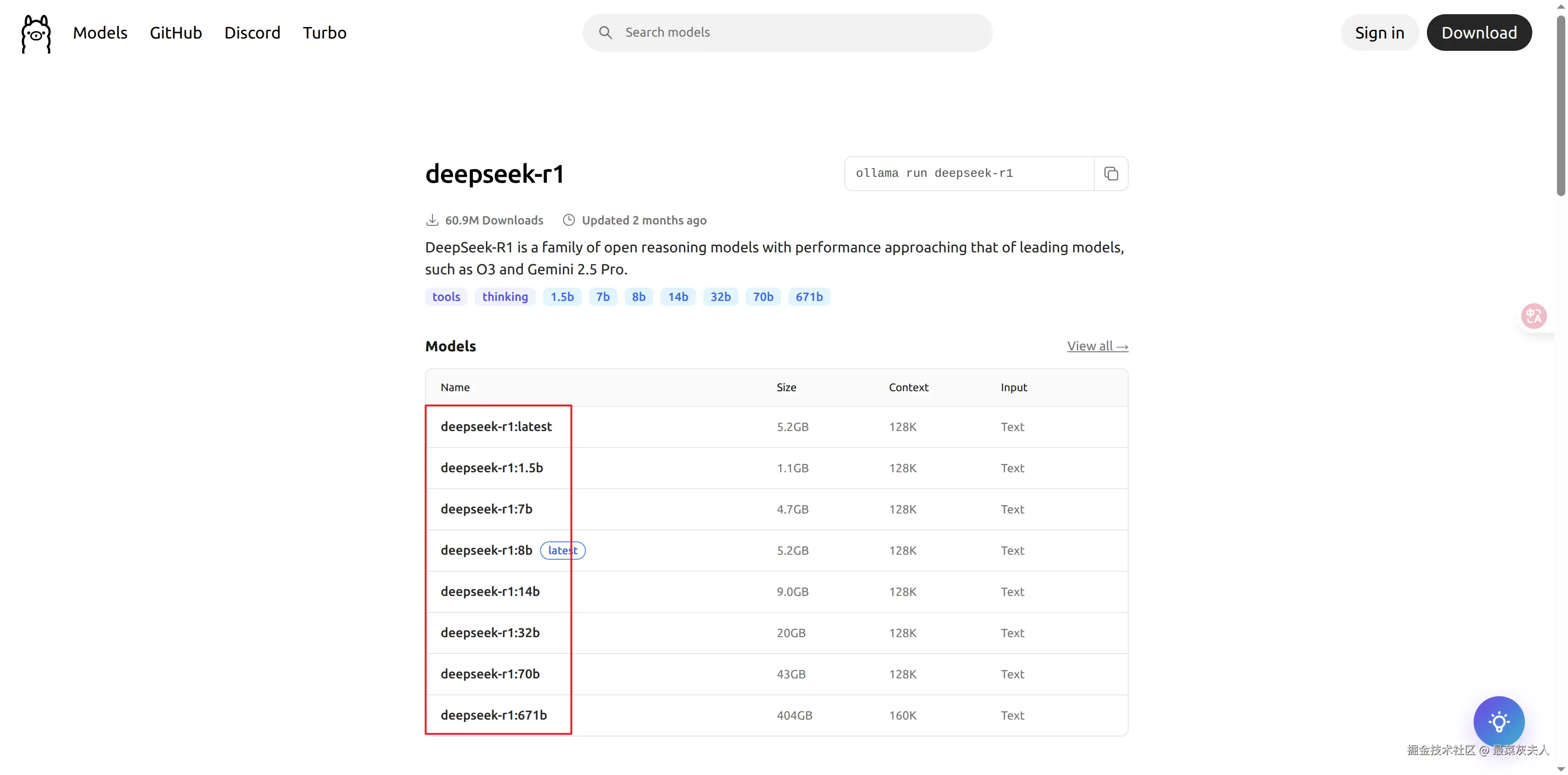
访问Ollama官方的模型库:Ollama Search,选择自己感兴趣的模型,注意参数量,一般先选择参数少一些的模型进行试验
下载模型
下载并运行deepseek-r1:7b模型
arduino
ollama run deepseek-r1:7b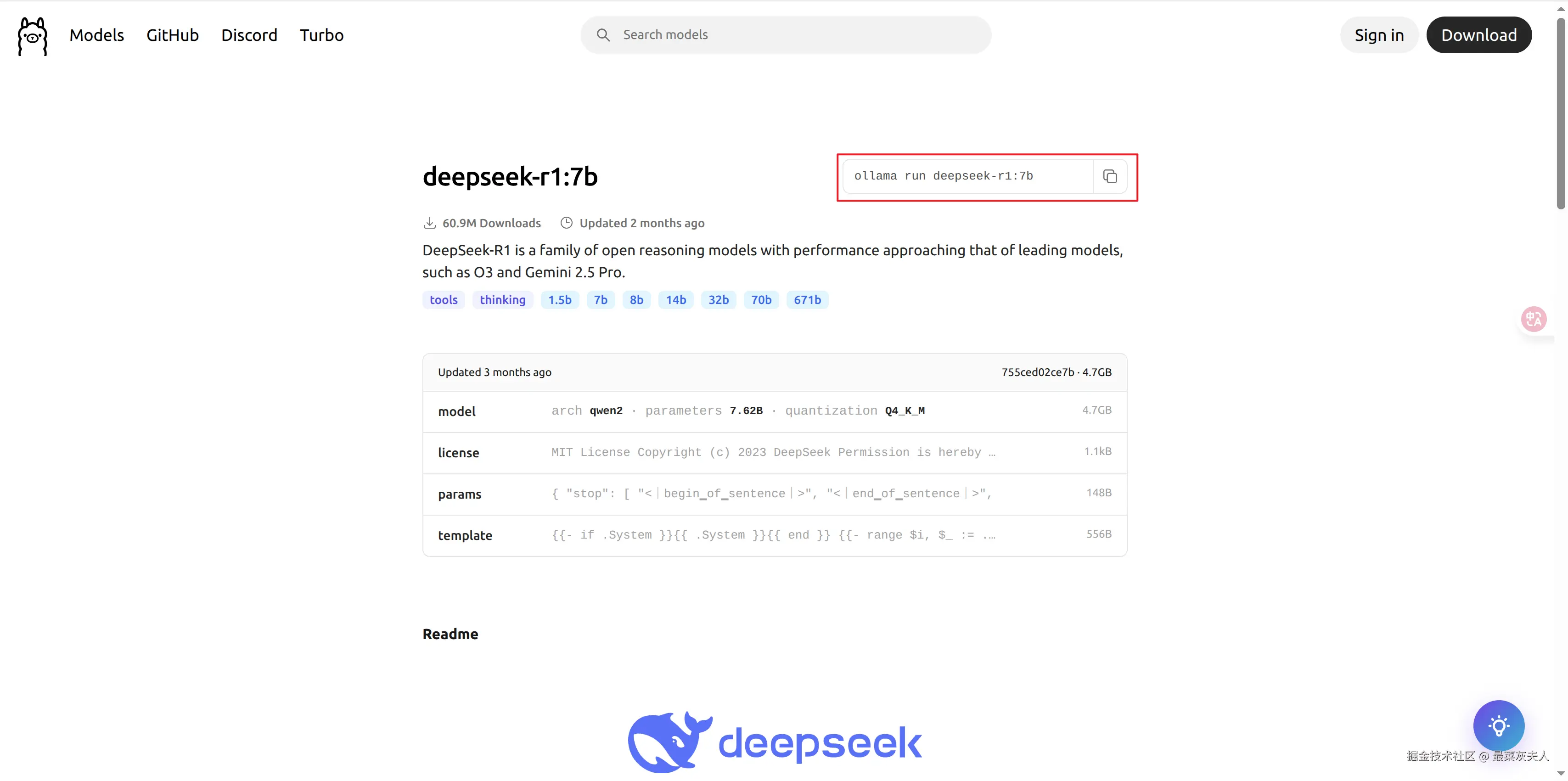
运行模型
如果已经下载了deepseek-r1:7b,就不会重复下载而是启动命令行交互对话
arduino
ollama run deepseek-r1:7b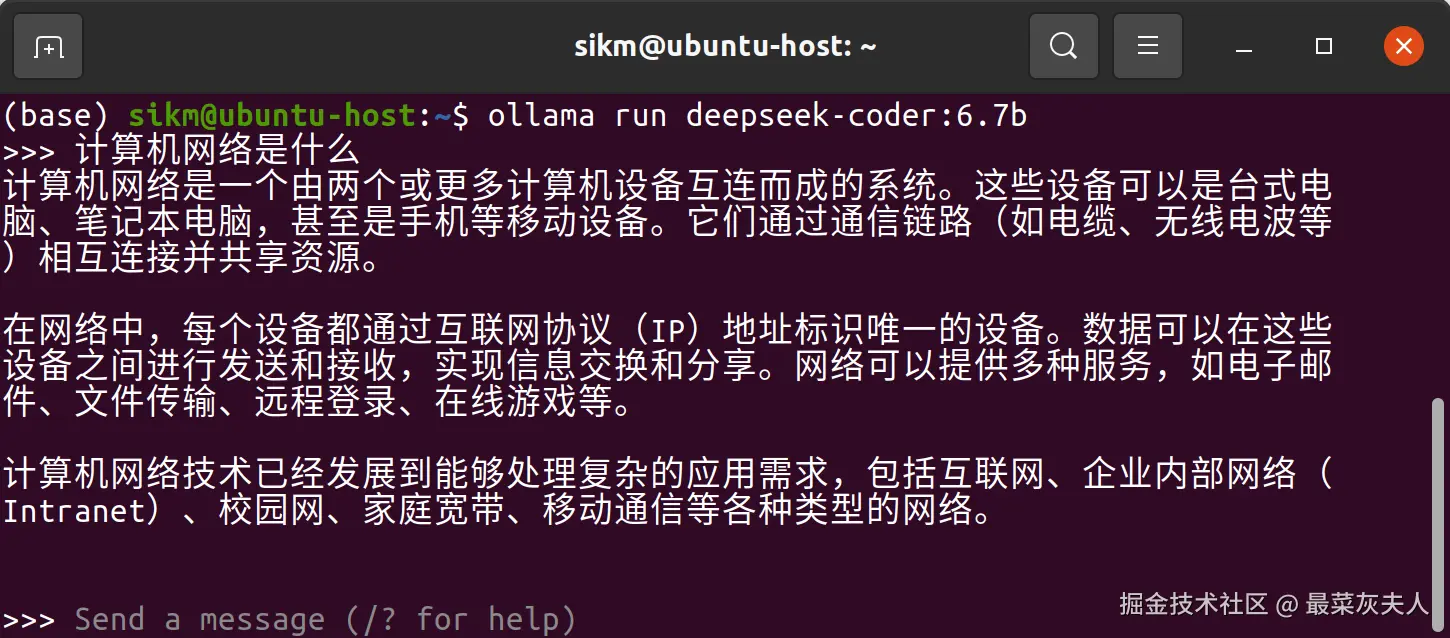
对话控制命令
在交互模式下,可以使用一些特殊命令:
bash
# 退出对话
/bye
或者按 Ctrl + D
# 清空对话上下文(开始新对话)
/clear设置参数
可以调整模型生成参数以获得不同效果:
arduino
# 设置温度(控制随机性,0-1)
ollama run deepseek-r1:7b --temperature 0.7
# 限制输出token数量
ollama run deepseek-r1:7b --num-predict 100
# 指定随机种子(确保可重复性)
ollama run deepseek-r1:7b --seed 42安装Open WebUI 图形化界面
虽然命令行交互已经很强大,但对于日常使用来说,一个美观的图形界面能极大提升体验。Open WebUI(原名 Ollama WebUI)提供了一个类似 ChatGPT 的现代化 Web 界面,让您可以通过浏览器与本地模型进行交互。
Open WebUI 是什么?
Open WebUI 是一个功能强大的开源 Web 界面,专为 Ollama 和其他本地语言模型设计。它具有以下特点:
- 类ChatGPT体验:熟悉的聊天界面,支持多轮对话、对话历史管理
- 多模型支持:轻松切换不同的语言模型
- 可视化操作:图形化的模型管理和设置界面
- 高级功能:支持 RAG(检索增强生成)、文档上传、角色预设等
- 多用户支持:可注册多个账户,每个用户有自己的对话历史
- 完全本地化:所有数据仍然保存在本地,保障隐私安全
先决条件:安装 Docker
Open WebUI 通过 Docker 容器部署,因此需要先安装 Docker。参考以下安装教程Ubuntu 20.04 安装Docker 全过程_ubuntu20.04安装docker-CSDN博客
启动Docker 服务
bash
# 确保Docker服务已启动
sudo systemctl start docker
sudo systemctl enable docker
# 检查Docker服务状态
sudo systemctl status docker使用 Docker 一键部署 Open WebUI
安装好 Docker 后,只需一条命令即可部署 Open WebUI:
arduino
docker run -d --network="host" -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main部署完成后,检查容器状态:
docker ps
访问并使用Open WebUI
容器正常运行后,即可通过浏览器访问:
-
打开浏览器,访问:
http://localhost:8080 -
首次注册:
- 点击 "Sign Up" 注册新账户
- 输入邮箱和密码(无需真实邮箱,仅用于本地识别)
- 确认密码并完成注册
-
登录系统:
- 使用刚才注册的邮箱和密码登录
- 首次登录会自动检测本地的 Ollama 服务
-
开始使用:
- 在左侧模型选择器中选择要使用的模型(如
llama3) - 在输入框中开始对话
- 右侧可以查看对话历史、切换模型、调整参数等
- 在左侧模型选择器中选择要使用的模型(如