【GPT入门】第65课 vllm指定其他卡运行的方法,解决单卡CUDA不足的问题
1.原理
要将 vllm 部署在第二张 GPU 卡上(设备编号为 1),只需在命令前添加 CUDA_VISIBLE_DEVICES=1 环境变量指定 GPU 设备:
bash
CUDA_VISIBLE_DEVICES=1 vllm serve /root/autodl-tmp/models_xxzh/Qwen/Qwen1.5-1.8B-Chat说明:
-
CUDA_VISIBLE_DEVICES=1是核心配置,强制程序仅使用编号为 1 的 GPU(第二张卡,GPU 编号从 0 开始计数) -
若需验证 GPU 编号,可先运行
nvidia-smi查看所有 GPU 设备的序号和状态 -
如需额外参数(如指定端口、并发数等),可直接追加在命令后,例如:
bashCUDA_VISIBLE_DEVICES=1 vllm serve /root/autodl-tmp/models_xxzh/Qwen/Qwen1.5-1.8B-Chat --port 8000 --max-num-seqs 32
2.实践
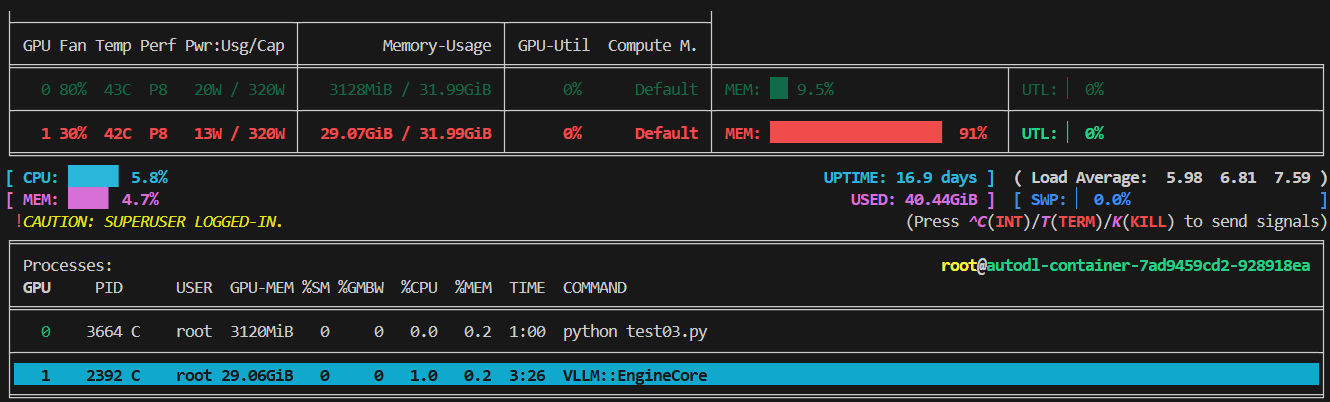
下面的图是nvitop, (通过pip install nvitop 安装) 的截图
- 运行前

- 指定第一个卡运行
命令:
c
CUDA_VISIBLE_DEVICES=1 vllm serve /root/autodl-tmp/models_xxzh/Qwen/Qwen1.5-1.8B-Chat
- 其他llm程序默认在第0个卡运行