前言
我在前文 HTTP 请求头大小写差异:一次由 Clash 代理引发的疑难杂症 提到过有些服务器可以通过指纹识别判断是否是异常爬虫,所以今日专门详细说一下浏览器指纹。因此,本文重点讨论指纹识别技术,关于广告联盟、IDFA或用户画像系统等不做深入讨论。
当你在深夜打开一个购物网站,换了IP、清了Cookie、甚至开启了无痕模式,以为自己"隐身"------
页面刚加载,弹窗却提示:"检测到异常行为,请完成验证"。
你可能会疑惑:我什么都没做,它怎么知道我是"异常"的?
真相是:你的设备在每次网络请求中都在"自报家门"。
不是靠用户名或IP,而是一系列看似无关的细节,拼凑出一个独一无二的"你"。
这,就是现代Web的设备追踪术。
设备指纹的本质:信息熵与唯一性
在信息论中,信息熵衡量一个随机事件的不确定性。熵越高,可能的取值越多,识别能力越强。
- User-Agent:常见组合几百种,信息熵低 → 容易伪造,也容易碰撞。
- 屏幕分辨率 :1920x1080较常见,
1440x900较独特,熵中等。 - Canvas渲染:GPU驱动、字体渲染、抗锯齿算法差异 → 熵极高。
- WebGL指纹:暴露GPU型号、着色器精度,熵更高。
- TLS指纹 :加密套件顺序、扩展组合 → 独特"协议口音",熵高。
- 字体枚举:已安装字体列表,熵中等偏高。
风控/防火墙通过组合中高熵信号 ,构建几乎独一无二的身份画像。EFF(电子前沿基金会)的 Cover Your Tracks(前身为 Panopticlick) 它通过分析多种信号(如 User-Agent、屏幕分辨率、字体列表、Canvas 指纹、WebGL、HTTP 头部等)来计算浏览器指纹的独特性,并与数据库中的其他用户数据对比,得出类似"1 in X" 的唯一性评分。该试验可以说明指纹的熵越高,唯一性越高。
注意: 信息熵与伪造难度的关系
误区:信息熵高并不意味着难以伪造。以下是常见指纹的熵与伪造难度对比:
| 指纹类型 | 熵值 | 伪造难度 | 原因 |
|---|---|---|---|
| Canvas指纹 | 极高 | ★★☆☆☆ | 确定性函数输出,可通过修改API返回值伪造 |
| TLS指纹 | 中高 | ★★★★★ | 需修改底层协议栈,涉及SSL库、OS内核 |
| 用户行为模式 | 中等 | ★★★★☆ | 涉及时序和统计特征,难以完美模拟 |
| 字体指纹 | 中等 | ★★★☆☆ | 可注入字体列表,但需与OS一致 |
| WebGL指纹 | 极高 | ★★★☆☆ | 可劫持API,但需与Canvas匹配 |
关键点 :指纹特征间存在一致性约束,单独伪造某一维度容易被检测到不一致。
🔧 对爬虫开发者的建议 :
仅伪造Canvas不足以绕过检测。如果TLS指纹暴露curl特征,系统会标记"设备声称是Chrome,但协议行为像脚本"。
🔧 对普通用户的建议: 高唯一性增加被追踪风险。以下工具可降低指纹独特性:
- Tor Browser:统一 User-Agent、禁用 Canvas 等,最大化降低唯一性。
- CanvasBlocker:随机化 Canvas 输出,减少指纹独特性。
- 广告拦截插件(如 uBlock Origin、Adblock Plus):通过阻止第三方跟踪脚本(如 FingerprintJS),减少网站收集指纹数据的能力,但对第一方脚本和协议层指纹(如 JA3/JA4)效果有限。
网络协议指纹:底层标识的识别原理
DNS 指纹
DNS指纹^1^(DNS Fingerprinting)是一种通过分析DNS(Domain Name System,域名系统)流量来识别用户、设备、操作系统或应用程序的技术。它利用DNS查询的模式、频率、目标域名等特征,构建出一种"指纹",用来推断用户的行为、设备类型或网络环境。例如,若你是Android设备可能频繁查询特定Google域名,而iOS设备可能查询Apple的CDN域名,这些模式可以用来区分设备类型。
工作方式
DNS指纹的生成通常包括以下步骤^2^:
- 捕获DNS查询 :通过被动监控,例如使用 DONUT^3^(Domain Oriented Network Unmasking Tool)工具^4^或主动探针,记录客户端的DNS查询流量,包括查询的域名、频率和时间戳。
- 特征提取:分析查询模式(如Google域名频繁查询提示Android设备)、域名熵(多样性)、TTL值等,构建特征向量。
- 分类识别 :传统方法通过匹配已知模式(如2013年论文 Passive OS Fingerprinting by DNS Traffic Analysis 识别OS或设备;现代方法使用机器学习(如2024数据集A user DNS fingerprint dataset 训练模型,提高精度。
传统DNS指纹依赖被动分析查询模式(如Android vs iOS的域名差异),而现代方法结合机器学习,分析更复杂的特征(如查询序列的统计规律),持续提升识别能力。
防范措施
使用加密 DNS^5^(如 DoH 或 DoT)、减少不必要的 DNS 查询,以及随机化 DNS 请求行为,可以有效提升隐私和安全性。现代浏览器大多已内置支持 DoH(DNS over HTTPS),你可以在这里查看各平台和浏览器的 DoH 配置方法。
需要注意的是,即使启用了加密 DNS(如 DoH),攻击者仍可能通过分析 DNS 查询模式推断用户行为。因此,建议进一步采用随机化查询策略(如随机选择 DNS 服务器或添加伪装查询)以增强保护。
TCP/IP层指纹:操作系统特征
TCP/IP层指纹(TCP/IP Fingerprinting) 是一种通过分析TCP/IP协议栈的独特实现特征来识别远程设备操作系统(OS)的技术。它利用TCP/IP头部中的特定字段(如TTL、DF位、窗口大小、TCP选项等)来构建"指纹",这些特征因不同OS的协议栈实现(如Windows的WinSock、Linux的内核TCP/IP栈)而异。这种方法常用于网络安全扫描、渗透测试和设备枚举,既有主动方式(发送探针包观察响应,如Nmap)也有被动方式(监控流量,如p0f工具)。
工作方式
TCP/IP指纹主要分析TCP SYN/SYN-ACK包、IP头部和相关选项的组合。这些字段的默认值和行为在不同OS间存在差异,通过比较已知指纹数据库(如 Nmap 的 osfingerprints ^6)来匹配OS7^。关键字段可能有:
- TTL (Time to Live) :IP包的生存时间,初始值因OS不同。
- DF (Don't Fragment) bit:IP头部是否设置不允许分片位。
- Window Size:TCP窗口大小,初始值反映OS的缓冲策略。
- Window Scale:TCP选项中的窗口缩放因子,用于扩展窗口大小。
防范措施
- 随机化协议字段 :使用工具如 fragroute 修改 TTL、DF 位或 TCP 窗口大小,增加指纹识别的难度,但需注意可能影响网络性能。
- 流量隐藏:通过代理(如 Tor 浏览器)或 VPN 加密隧道(如 IPsec)隐藏真实的 TCP/IP 头部信息,减少操作系统特征暴露。需注意,高级分析仍可能通过流量模式推断部分信息。
- 系统配置调整 :在操作系统层面修改默认协议行为。例如,在 Linux 上通过调整
sysctl参数(如net.ipv4.ip_default_ttl)更改 TTL 默认值,或启用 TCP 初始序列号(ISN)随机化^8^以增加协议行为的不可预测性。 - 现代操作系统的内置保护:许多现代操作系统(如 Linux 和 Windows)已增强 TCP/IP 协议栈的随机性,例如通过 ISN 随机化或动态调整窗口大小,进一步降低指纹识别的准确性。
TLS指纹:JA3、JA3S与JA4
现代浏览器普遍采用 TLS(传输层安全协议)作为标准加密协议,爬虫开发者也常通过修改 User-Agent 或 Referer 请求头来伪装成合法浏览器,以欺骗服务器。然而,云服务商的验证码系统仍能迅速识别爬虫,这通常是因为 TLS 指纹(TLS Fingerprinting)不匹配。
TLS 指纹是通过分析 TLS 握手过程中的参数(如加密套件、TLS 扩展、协议版本等)生成的一种唯一标识,用于识别客户端软件、浏览器或潜在的恶意工具(如爬虫)^9^。即使 User-Agent 被伪造,TLS 指纹仍可能暴露爬虫的真实特征。常用的 TLS 指纹技术包括 JA3(客户端指纹)、JA3S(服务器响应指纹)和 JA4(综合指纹),这些技术通过比对已知指纹数据库,能够有效检测爬虫、恶意软件或异常行为。
常见的服务器提供了这样的防火墙服务, 比如:
- 阿里云: help.aliyun.com/zh/waf/web-...
- AWS: aws.amazon.com/cn/about-aw...
- Cloudflare: developers.cloudflare.com/bots/additi...
JA3:Client Hello指纹
JA3 是一种基于 TLS Client Hello 消息生成指纹的方法,用于识别客户端的 TLS 协议栈实现(如浏览器、库或恶意软件)。由 Salesforce 开发。通过提取 Client Hello 消息中的特定字段并生成 MD5 哈希,JA3 可用于网络流量分析、客户端行为区分或恶意软件检测。
生成步骤:
- 提取字段:JA3 从 TLS Client Hello 消息中提取以下字段:
- TLS 版本:如 771(TLS 1.2)或 772(TLS 1.3)。
- Cipher Suites:客户端支持的加密套件列表,按 ID 升序排列(如 1301、1302、C02B)。
- TLS 扩展:客户端发送的扩展列表,按扩展 ID 升序排列(如 0=server_name、5=status_request、13=signature_algorithms)。仅包含非 GREASE(Generate Random Extensions And Sustain Extensibility)扩展。
- 椭圆曲线(Elliptic Curves):支持的椭圆曲线列表,按 ID 升序排列(如 29=x25519、23=secp256r1)。
- 椭圆曲线点格式(EC Point Formats):如 0=uncompressed。
- 拼接字段:将上述字段按以下格式拼接为字符串,用连字符(
-)分隔:TLS版本-Cipher Suites列表-扩展列表-椭圆曲线列表-点格式列表,每个字段内的子项以逗号(,)分隔。例如:772,1301-1302-C02B,0-5-10-13,29-23,0 - 计算MD5, 对拼接后的字符串计算 MD5 哈希,生成 32 位十六进制指纹。
现代浏览器的随机化特性
部分现代浏览器(如 Chrome)会在 TLS 握手中随机化^10^ Cipher Suites 或添加 TLS GREASE(Generate Random Extensions And Sustain Extensibility) 扩展,以防止指纹追踪。这可能导致 JA3 指纹在不同会话中发生变化。例如,Chrome 可能在每次会话中重新排序 Cipher Suites 或插入随机扩展,从而影响 JA3 指纹的一致性。
为了应对这种情况,后面还出了一个叫做JA3N的,他和JA3最大的区别就是在于他会消除上面的随机性,您可以多次访问: tls.browserleaks.com/ 观察其返回值的区别(该结果返回为JSON格式,您可能需要安装JSON扩展增加其可读性。
目前对于JA3N之中的N的概念,我没有检索到一个确定的含义,目前猜测可能是
Normalized表示规范化
一个例子
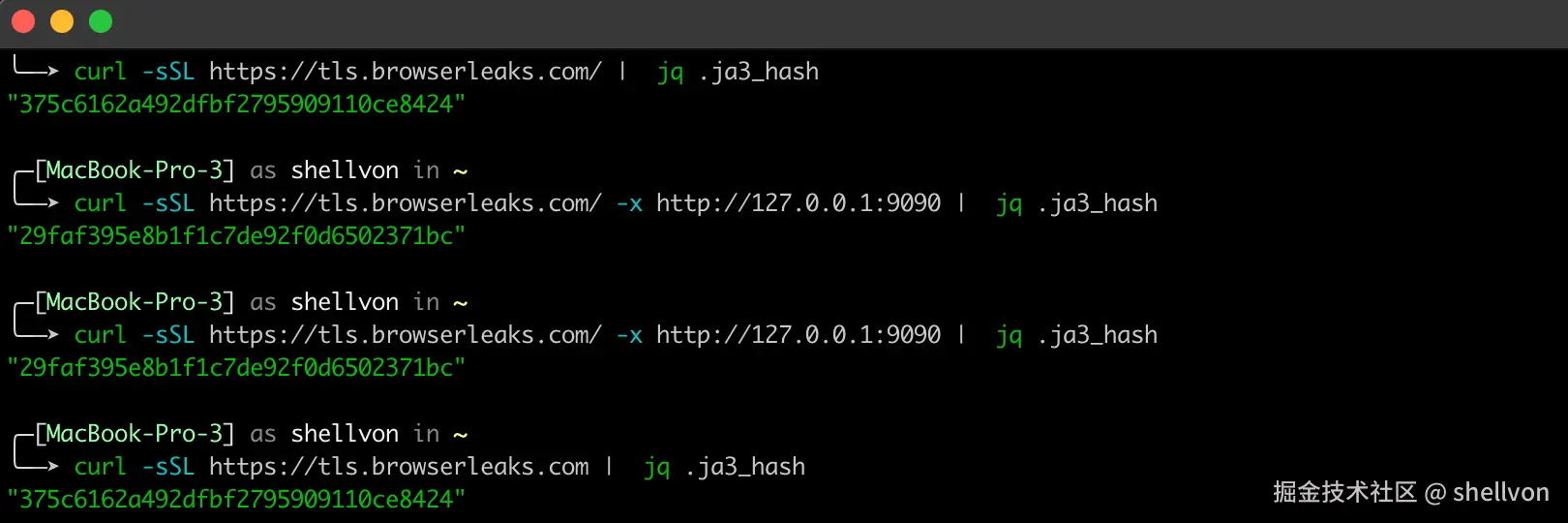
上图可以看到,当我开启了 Proxyman 代理之后,JA3指纹发生了变化,默认开启的情况下,我的 curl 的指纹应该是 375c6162a492dfbf2795909110ce8424, 但当我通过 Proxyman 代理抓包后,服务器可以发现JA3指纹的不一致,倘若这个指纹在服务器防火墙视为恶意软件,那么这次请求将会被拒绝/丢弃。
JA3S:Server Hello指纹
JA3S 是基于 TLS Server Hello 消息生成指纹的方法,用于验证客户端与服务器 TLS 握手的一致性。
JA4:下一代指纹标准
JA4是JA3的进化版,由FoxIO开发,更模块化、抗性强、可扩展,支持QUIC(HTTP/3)和更多场景。不同于JA3的MD5哈希,JA4使用SHA256的前12字符,并分为子指纹(如JA4_c for client, JA4_s for server,JA4_h for header(HTTP/2 或 HTTP/3 层,涉及头部顺序和大小写))。它处理扩展随机化(如浏览器TLS扩展顺序变化),并添加HTTP头、ALPN等字段,提高精度。而且有更多显著的优势:
- 更丰富:包括ALPN、签名算法、HTTP版本等
- 抗绕过:通过忽略 GREASE 扩展并对字段按字母顺序排序,抵御 Chrome 等客户端的随机化机制。
- 更强大:显著减少哈希碰撞风险(从JA3的MD5 -> SHA256)。
- 支持新协议:兼容 QUIC 和 HTTP/3,适应现代网络环境。(JA3 的设计相对"generic"(通用),主要基于 TLS Client Hello 消息的固定字段生成指纹, 但JA4则可以细分到比如直接分析HTTP3的头部)
防范措施
为降低 JA3/JA3N/JA4 指纹被识别的风险,可采取以下措施:
- 随机化参数 :使用库如 uTLS 随机化cipher顺序、扩展(但需避免不兼容)。
- 标准化配置 :模拟流行浏览器指纹(如Chrome的JA3),工具如 curl-impersonate。
- 代理/中间件:通过代理重写TLS握手,隐藏真实指纹,比如前文展示的Proxyman的介入就会让服务器按到代理服务器的指纹而非客户端真实指纹
3.4 HTTP/2 与 HTTP/3 指纹
HTTP/2 和 HTTP/3 指纹是通过分析 HTTP/2(基于 TCP)或 HTTP/3(基于 QUIC/UDP)的协议帧、设置参数和头部特性来识别客户端(如浏览器、爬虫)的技术。比如 Akamai Hash 是其中一种重要的 HTTP/2 指纹方法,由 Akamai 提出,通过分析 SETTINGS、WINDOW_UPDATE、PRIORITY 帧和伪头部顺序生成唯一标识,用于反爬虫、恶意流量检测等^11^。HTTP/3 指纹则扩展到 QUIC 特有参数(如连接ID、Transport Parameters)。 这些指纹常与 TLS 指纹^12^ (如 JA4)结合,以提高识别精度。
大佬 lwthiker 的文章 HTTP/2 fingerprinting: A relatively-unknown method for web fingerprinting 提到,不同的浏览器在发起请求时,他们特定的请求头顺序是固定的,这本身也会被用来区分设备:

防范措施
关于这一系列的我能知道的也就基本上是伪装参数:使用 curl-impersonate 或 uTLS 模拟浏览器(如 Chrome)的 SETTINGS、头部顺序和 QUIC 参数。
浏览器运行时指纹:高熵但可伪造
浏览器运行时指纹(Browser Runtime Fingerprinting)是通过分析浏览器在运行时暴露的特性(如渲染、音频处理、字体、硬件信息等)生成的高熵标识,用于识别用户、浏览器或设备。这些指纹利用浏览器API和硬件差异,生成几乎唯一的标识,即使在隐私模式或清空Cookie后仍可追踪用户。
隐私模式并不会阻止服务器识别用户。隐私模式仅限制浏览器在本地存储某些信息(如Cookie、浏览历史),但服务器仍可通过浏览器运行时指纹等技术生成唯一标识,从而追踪用户。值得注意的是,隐私模式本身也可以被检测。例如,detectIncognito.js 项目是一个广泛使用的JavaScript库,能够检测大多数现代浏览器(如Chrome、Safari、Firefox、Edge等)是否处于隐私模式
Canvas指纹
Canvas 指纹^13^利用 HTML5 Canvas API 的渲染差异生成唯一标识。不同设备和浏览器的 GPU 驱动、字体渲染引擎、像素对齐算法和抗锯齿处理会导致相同的 Canvas 操作(如绘制文本或图形)生成微妙不同的图像数据。然后再对数据进行哈希(如 MD5 或 SHA256)生成指纹^14^。
差异来源:GPU驱动、字体引擎、像素对齐算法。
javascript
const canvas = document.createElement('canvas');
canvas.width = 200; canvas.height = 50;
const ctx = canvas.getContext('2d');
ctx.font = '14px Arial';
ctx.fillText('Hello, World! 🎉', 2, 15);
const data = canvas.toDataURL('image/png');来自 browerLeak.com 的这张Gif图更好的解释了来自不同的35个用户相同JS代码生成出来的像素差异:

伪造方法 :劫持toDataURL,返回预设图像。
防范措施:
- 隐私浏览器 :使用 Tor Browser 或 Firefox(启用 ResistFingerprinting)。
- 扩展:安装 Canvas Blocker 或 uBlock Origin 拦截指纹脚本。
- 禁用 JavaScript: 阻止 Canvas 脚本运行,但可能影响网站功能
WebGL 指纹
WebGL 指纹^15^通过 WebGL API 暴露的 GPU 信息(如供应商、渲染器、扩展支持)生成标识。更进一步,它会执行复杂的着色器程序(Shader Program)来渲染 3D 图形。不同 GPU 驱动在处理浮点精度、纹理压缩和数学函数时存在微小差异,导致渲染出的像素数据不尽相同,提供高熵指纹。
javacript
const gl = canvas.getContext('webgl');
const vendor = gl.getParameter(gl.VENDOR); // "Intel Inc."
const renderer = gl.getParameter(gl.RENDERER); // "Intel Iris OpenGL Engine"这个技术常用于检测自动化工具,因为它们的 WebGL 配置与标准浏览器不同。尽管如此,它也并非无法伪造:
- 劫持 WebGL API:Puppeteer 修改 getParameter() 返回伪造的 GPU 信息(如 Chrome 的标准值)。
- 模拟渲染:返回预设的 WebGL 图像数据,但需要确保其与 Canvas 指纹的渲染结果一致,这是伪造中最具挑战性的一环。
更现代的浏览器还支持 WebGPU,因此也有对应的WebGPU指纹,您可以在这里查看: webbrowsertools.com/webgpu-fing...
AudioContext指纹
AudioContext 指纹利用 Web Audio API 的音频处理差异生成标识。不同设备和浏览器的音频栈(如声卡、驱动、采样率)会导致音频输出的微小差异。指纹脚本通常会生成一个特定频率的音频信号(如正弦波),然后通过一系列滤镜处理,最后获取处理后的波形数据并计算哈希值^16^。
您可以访问下面的网站演示:
字体与硬件指纹
字体和硬件指纹通过浏览器暴露的字体列表和硬件特性(如 CPU 核心数、时区)生成高熵标识。这些信息因用户设备和系统配置差异而异。
- 字体 :document.fonts 枚举字体列表。
- 硬件 :navigator.hardwareConcurrency(CPU核心数)、时区、语言设置等
移动设备指纹
移动设备指纹利用移动设备特有的硬件传感器(如陀螺仪、加速度计)、电池信息和其他物理特性生成高熵标识。这些指纹基于硬件的制造偏差和行为模式,难以伪造,因此广泛用于移动端用户追踪和安全检测。
传感器指纹
陀螺仪/加速度计:制造偏差(零偏、灵敏度误差)。
可以通过 Device Orientation Event 获取一些关键信息:
javascript
window.addEventListener('devicemotion', (e) => {
const { alpha, beta, gamma } = e.rotationRate // 旋转速率
})其他指纹
- 电池API :navigator.getBattery 暴露电量、充电时间。
- 振动/光传感器:响应时间或强度偏差。
总结一下,当你访问一个网站的时候,每一阶段的数据/行为都可能会用于产生指纹:
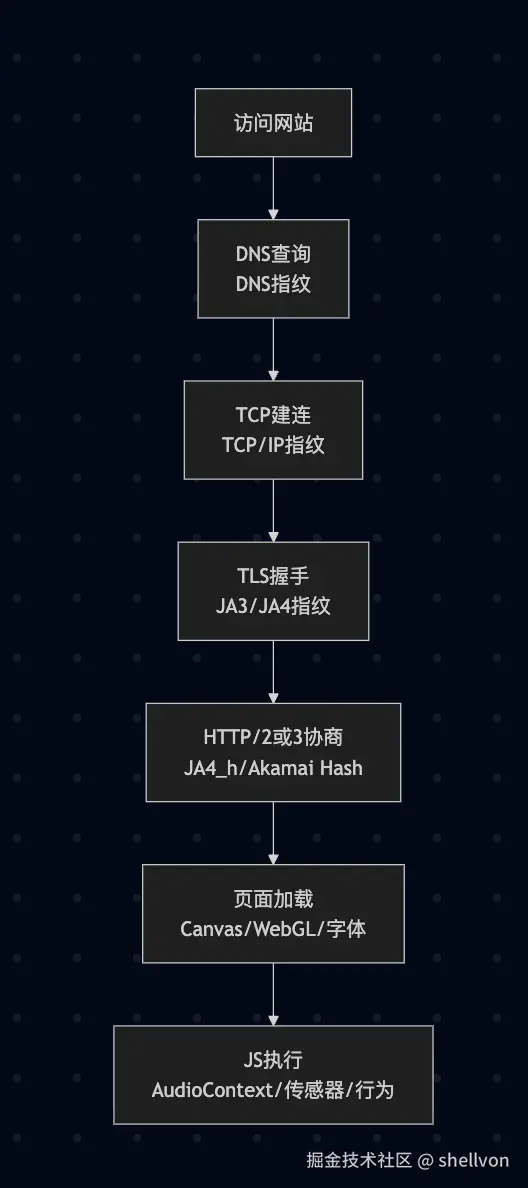
不同层级的指纹技术(如网络层:DNS/TCP/TLS;浏览器运行时层:Canvas/WebGL)它们在应用方向上也有不同的侧重点。
- 网络层指纹更倾向于安全领域的 bot 检测和异常流量识别,因为它们在协议层级直接暴露客户端行为,它们不直接提供用户兴趣或行为数据,所以营销公司(如 Google Ads)更少依赖它们,但WAF防火墙就不一定了
- 浏览器层指纹则更常用于营销追踪,因为它们提供高熵的唯一标识,易于跨站点关联用户行为。但两者都可用于双重目的(如防欺诈),且在反爬虫(bot detection)中都有作用。
这些指纹也能有效判断你是否使用了 VPN 或代理。核心在于多维度信息的不一致性。例如,如果你的 IP 地址来自一个国家,但浏览器报告的时区、语言或 DNS 请求却来自另一个国家,这就是一个明显的冲突。这种不一致性,结合 WebRTC 和 DNS 泄漏等技术,可以大大增加被标记为可疑流量的概率。
指纹生成开源项目
您可以在 Github 按照 topic:fingerprinting 搜索,比如以下就是一些专注于浏览器网页前端指纹生成的技术:
- github.com/fingerprint...
- github.com/abrahamjuli...
- github.com/thumbmarkjs...
- github.com/jackspirou/...
- github.com/jonasstrehl... 此项目区别于其他项目,因为他用的是
favicon, 也就是浏览器tab上展示那个网站的小logo,但项目很久没有更新了。
对抗工具链:如何伪装设备指纹
对抗设备指纹的关键在于模拟真实浏览器的协议栈行为(如 TLS、HTTP/2)和运行时特性(如 Canvas、WebGL),同时避免检测自动化工具(如 Headless Chrome)。比如笔者曾经借鉴(抄袭)过这个代码:
javascript
/**
* Reorders the default NodeJs ciphers so the request tries to negotiate the modern TLS version first, same as browsers do.
* @returns {string} ciphers list
*/
function ensureModernTlsFirst() {
const modernTlsCiphers = ['TLS_AES_256_GCM_SHA384', 'TLS_AES_128_GCM_SHA256', 'TLS_CHACHA20_POLY1305_SHA256'];
const defaultCiphers = new Set(crypto.constants.defaultCipherList.split(':'));
// First we will remove the modern ciphers from the set.
modernTlsCiphers.forEach((cipher) => defaultCiphers.delete(cipher));
// Then we will add the modern ciphers at the beginning
return modernTlsCiphers.concat(Array.from(defaultCiphers)).join(':');
}以下表格是我通过Google检索到的一些有用的工具或者库。包括多浏览器支持、QUIC 伪装和高级 evasion 技术:
| 工具 | 语言/平台 | 核心能力 |
|---|---|---|
| curl-impersonate | CLI | 模拟 Chrome/Firefox 的 TLS + HTTP/2 行为,支持 JA3/JA4 伪装和头部顺序随机化。 |
| curl_cffi | Python | Requests 级 TLS 伪装,内置浏览器配置文件,易集成到爬虫脚本中。 |
| CycleTLS | Go | JA3/JA4 伪装,支持 QUIC/HTTP/3,适用于高并发场景和自动化测试。 |
| puppeteer-extra-plugin-stealth | Node.js | 劫持 Canvas/WebGL/AudioContext,返回标准化渲染数据,隐藏 Headless 特征。 |
| Playwright | 多语言 | 内置 Stealth 模式,支持跨浏览器伪装和传感器模拟。 |
| undetected-chromedriver | Python | 无检测 Chromedriver,自动绕过 Cloudflare 等 WAF 的浏览器自动化检测。 |
| Multilogin | 多平台 | 浏览器指纹切换器,支持多账户隔离、Canvas 和字体伪装,适用于大规模操作。 |
| Adspower | 多平台 | 高级指纹管理工具,提供代理集成、UA 随机化和硬件模拟。 |
| Gologin | 多平台 | 免费/付费版本,支持指纹注入和跨设备伪装,易于初学者使用。 |
设备指纹与跨平台追踪的区别
设备指纹和跨平台追踪(cross-device tracking)都是隐私威胁,但目标和方法不同。设备指纹聚焦于单一设备或浏览器的识别,而跨平台追踪旨在关联多设备行为,形成用户画像。
- 设备指纹:识别"同一浏览器或设备",通过收集浏览器/硬件特征(如 Canvas、JA3、传感器)生成唯一标识,用于反欺诈或广告追踪。 例如,网站可通过 JA4 检测爬虫,即使 UA 被伪造。
- 广告ID(IDFA/AAID) :关联"同一设备",如 iOS 的 IDFA 或 Android 的 AAID,用于 app 内追踪用户行为。易重置,但受隐私法规(如 GDPR)限制。
- 设备图谱(Device Graph) :关联"多设备同一用户",使用概率匹配(如 IP 共享、登录行为、指纹相似度)构建用户跨设备画像。 例如,Google 使用指纹 + 登录数据关联手机和 PC。
绕过 WAF 靠设备指纹伪装(如修改 JA4 或 Canvas),而非 IDFA 修改(后者更针对 app 追踪)。跨平台追踪可通过 VPN + 指纹随机化缓解。
实践出真知-动手实验吧!
接下来,你通过下面这些资料、网站,你可以亲手验证和测试指纹,了解自身暴露的风险,并练习伪装。
- amiunique.org/
- demo.fingerprint.com/playground
- webbrowsertools.com/
- overpoweredjs.com/
- 仔细查看 browserleaks.com/ 或者 coveryourtracks.eff.org/
- 抓包分析:使用 Wireshark 检查 Client Hello 包,提取 Cipher Suites 和 Extensions,手动计算 JA3(参考 Salesforce 的 GitHub)
- DNS 泄露:dnsleaktest.com/ 或者 ipleak.net/ -- 运行标准/扩展测试,检查 DNS 查询是否泄露真实 IP 和位置,验证 DNS 指纹风险
- 使用 curl 模拟抓包看看如何改变了TLS指纹, 亦或者使用下面的API访问:
现在,你已经掌握了这些工具和方法。虽然你的设备正在'自报家门',但通过这些实践,你将能更好地理解这些信息是如何被收集和利用的。下一步,就是如何保护它。