论文地址:https://arxiv.org/pdf/2503.06671
代码地址:https://github.com/dslisleedh/ESC
关注UP CV缝合怪,分享最计算机视觉新即插即用模块,并提供配套的论文资料与代码。
https://space.bilibili.com/473764881
摘要
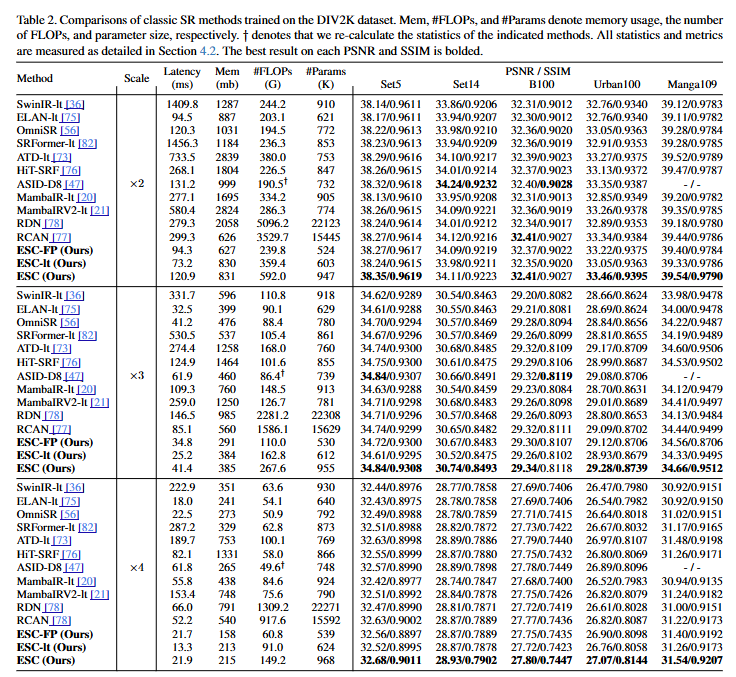
本研究解决了Transformer在高效图像超分辨率(SR)任务中的高计算开销 问题。基于对自注意力层间重复性 的观察,本研究引入了一个名为卷积注意力(ConvAttn)的卷积化自注意力模块,它利用单个共享的大卷积核和动态卷积核 来模拟自注意力的远程建模能力和实例依赖加权 。通过利用ConvAttn模块,本研究显著减少了对自注意力及其相关内存密集型操作的依赖 ,同时保持了Transformer的表示能力 。此外,本研究克服了将Flash Attention集成到轻量级SR领域的挑战 ,有效地缓解了自注意力固有的内存瓶颈 。本研究使用Flash Attention将窗口大小扩展到32×32 ,而不是提出复杂的自注意力模块,在Urban100 ×2上PSNR显著提高了0.31dB ,同时延迟和内存使用量分别降低了16倍和12.2倍 。基于这些方法,本研究提出的网络名为"用卷积模拟自注意力(ESC) ",与HiT-SRF相比,在Urban100 ×4上PSNR显著提高了0.27dB ,延迟和内存使用量分别降低了3.7倍和6.2倍 。大量实验表明,尽管大部分自注意力被ConvAttn模块取代,ESC仍保持了Transformer的远程建模能力、数据可扩展性和表示能力 。
引言
Transformer在高效图像超分辨率中的应用:用卷积模拟自注意力
本研究致力于解决Transformer在高效图像超分辨率(SR)任务中的高计算开销问题 。当前,随着多媒体内容和生成模型需求的显著增长,SR技术的重要性日益凸显,因为它能够使用户在资源受限的条件下享受高质量内容。因此,实际部署已成为SR任务中的一个关键考虑因素 ,促使许多SR研究在提高性能的同时降低计算复杂度和参数规模。Transformer在SR任务中取得了比卷积神经网络(CNN)更优越的性能 ,同时具有更低的计算量和更少的参数,因此受到了广泛关注。通过自注意力机制 捕获长距离依赖关系和执行依赖于输入的加权,Transformer展现出强大的表征能力和增强的性能,尤其是在训练数据量增加时。然而,许多研究忽略了自注意力机制造成的过度内存访问 ,这是由于需要实例化分数矩阵以及利用内存密集型操作(如张量重塑和窗口掩码)所导致的。在SR架构中,由于需要处理大特征图而没有patchify stem或下采样阶段,内存访问问题更加严重。例如,即使SwinIR-light的计算量和参数规模分别比重建×2比例高清图像的CNN少14.5倍和17倍,但其延迟却高4.7倍,内存使用量也高2倍 。因此,尽管Transformer的性能很有前景,但在资源受限的设备(如消费级GPU)上部署它们仍然具有挑战性。
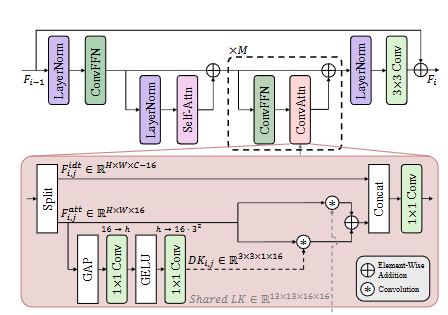
本研究的初步分析表明,自注意力机制执行的相似性建模和提取的特征在多层之间保持高度一致 。这一发现表明自注意力机制可能会提取重叠的特征 ,这意味着可以通过使用高效的替代方案来降低计算开销而不损害表征能力。基于此发现,本研究提出了一种设计策略,仅在每个块的第一层保留自注意力机制,而用本研究提出的高效替代方案------卷积注意力(ConvAttn)模块------替换其余层 。为了有效地模拟自注意力的长距离建模和依赖于实例的加权,ConvAttn模块采用双重机制运作 。首先,它通过在整个网络中应用具有共享的13×13大核的卷积 来简化自注意力的长距离交互,仅针对一部分通道进行操作。其次,生成动态核以捕获依赖于输入的加权,模仿自注意力的自适应特性 。通过结合这些组件,ConvAttn模块显著减少了对内存密集型自注意力的依赖,同时保持了Transformer的表征能力。
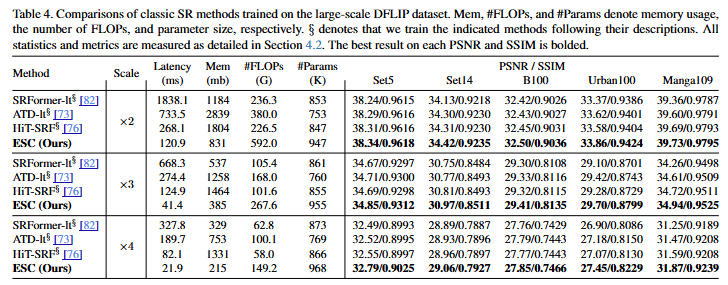
通过用ConvAttn替换大部分自注意力层,本研究利用这种效率进一步增强了剩余的自注意力层。具体而言,本研究扩大了自注意力的窗口大小 ,在仅略微增加计算量的情况下显著提高了性能。然而,增加窗口大小会导致分数矩阵扩大,从而大幅增加峰值内存使用量。为了解决这个问题,本研究将Flash Attention引入到轻量级SR任务中,以避免实例化分数矩阵 。本研究的优化实现允许将窗口大小扩展到32×32,同时将延迟和内存使用量分别减少16倍和12.2倍 。基于这些方法,本研究介绍了一种名为"用卷积模拟自注意力(ESC) "的轻量级SR网络。与ATD-light相比,所提出的ESC在Urban100 ×4上PSNR提高了0.1dB,同时速度提高了8.9倍 。此外,ESC-light在Urban100 ×2上PSNR超过ELAN-light 0.29dB,同时延迟降低了22% 。本研究通过引入ESC-FP 进一步验证了ESC在降低计算量和参数规模至关重要的场景下的有效性,ESC-FP在Manga109 ×4上的性能优于MambaIRV2-light,同时计算量和参数规模分别减少了20%和32% 。通过广泛的实验,本研究证明了即使大部分自注意力被ConvAttn模块取代,ESC仍然充分利用了Transformer的优势,包括其大的感受野、表征能力以及关于数据量的可扩展性 。本研究通过深入的实验支持了这些结果,表明所提出的ConvAttn模块提取的特征与自注意力机制相似。
论文创新点
本研究提出了一个名为ESC的高效图像超分辨率网络,旨在降低Transformer在计算和内存方面的开销。本研究的创新点主要体现在以下几个方面:
-
✨ 基于卷积的注意力模块(ConvAttn): ✨
- 本研究观察到Transformer中自注意力机制的层间特征存在高度相似性,这表明自注意力机制在不同层提取的特征存在冗余。
- 基于此,本研究设计了ConvAttn模块,它结合了共享的大核卷积和动态生成的深度卷积核,以模拟自注意力机制的长距离建模能力和实例依赖的加权能力。
- ConvAttn模块有效地替代了Transformer中除了每个块的第一层以外的其他自注意力层,从而显著降低了对内存密集型自注意力操作的依赖,同时保持了Transformer的表示能力。
-
🚀 共享大核卷积: 🚀
- ConvAttn 模块中的共享大核卷积(LK)贯穿整个网络,负责捕获全局上下文信息和长距离依赖关系。
- LK 的参数在所有层之间共享,从而减少了模型的整体参数量和计算开销,并有助于稳定训练。
-
⚙️ 动态深度卷积核: ⚙️
- 为了模拟自注意力机制的实例依赖加权,ConvAttn 模块引入了动态深度卷积核(DK)。
- DK 根据输入特征动态生成,能够捕获特定实例的局部特征。
- DK与 LK 协同工作,在降低内存开销的同时,实现了对全局和局部特征的有效建模。
-
⚡️ Flash Attention的集成: ⚡️
- 为了进一步降低自注意力机制的内存开销,本研究将Flash Attention集成到轻量级SR任务中。
- Flash Attention 通过避免显式计算和存储注意力矩阵,显著减少了自注意力操作的内存占用和延迟。
- 本研究优化了 Flash Attention 的实现,使其能够支持更大的窗口大小(32x32),从而在轻量级SR任务中实现了性能的显著提升。
-
🌐 多尺度特征融合: 🌐
- ESC 网络巧妙地融合了局部和全局特征。ConvFFN 模块提取局部特征,而 ConvAttn 模块捕获全局上下文信息。
- 通过将这两个模块的输出进行融合,ESC 网络能够有效地利用多尺度信息,从而提高了图像超分辨率的性能。
通过这些创新,本研究提出的ESC网络在多个图像超分辨率基准数据集上取得了显著的性能提升,同时显著降低了计算和内存开销。此外,本研究还证明了 ESC 网络在数据扩展性和任意尺度超分辨率任务上的有效性,进一步验证了其优越的泛化能力和实用价值。
论文实验