大模型路线大纲+学习文档,在 >gitcode ←
这一节我们来聊聊不定长的文本向量,这里我们暂不考虑有监督模型,也就是任务相关的句子表征,只看通用文本向量,根据文本长短有叫sentence2vec, paragraph2vec也有叫doc2vec的。这类通用文本embedding的应用场景有很多,比如计算文本相似度用于内容召回, 用于聚类给文章打标等等。前两章我们讨论了词向量模型word2vec和Fasttext,那最简单的一种得到文本向量的方法,就是直接用词向量做pooling来得到文本向量。这里pooling可以有很多种, 例如
- 文本所有单词,词向量 average pooling
- 文本所有单词,词向量 TF-IDF weighted average pooling
- 文本提取关键词,词向量 average pooling
- 文本提取关键词,词向量 weighted average pooling
想了解细节的可以看下REF3,5,但基于word2vec的文本向量表达最大的问题,也是词袋模型的局限, 就是向量只包含词共现信息,忽略了词序信息和文本主题信息。这个问题在短文本上问题不大,但对长文本的影响会更大些。于是在word2vec发表1年后还是Mikolov大大,给出了文本向量的另一种解决方案PV-DM/PV-DBOW。下面例子的完整代码见 github-DSXiangLi-Embedding-doc2vec
模型
PV-DM 训练
在CBOW的基础上,PV-DM加入了paragraph-id,每个ID对应训练集一个文本,可以是一句话,一个段落或者一条新闻对应。paragraph-id和词一样通过embedding矩阵得到唯一的对应向量。然后以concat或者average pooling的方式和CBOW设定窗口内的单词向量进行融合,通过softmax来预测窗口中间词。
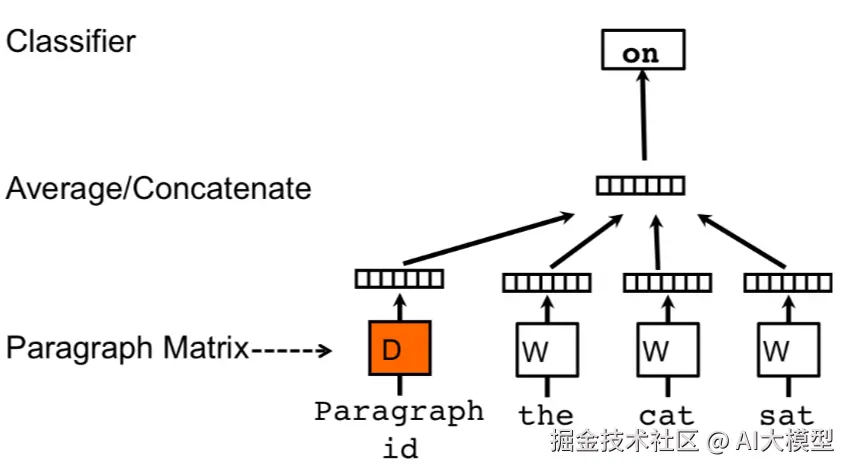
这个paragraaph-id具体做了啥嘞?这里需要回顾下word2vec的word embedding是如何通过back propogation得到的。不清楚的可以来这里回顾下哟无所不能的Embedding 1. Word2vec模型详解&代码实现
第一步hidden->output更新output embedding矩阵,在CBOW里h只是window_size内词向量的平均,而在PV-DM中,hh包含了paragraph-id映射得到的文本向量,这个向量是整个paragraph共享的,所以在窗口滑动的时候会保留部分paragraph的主题信息,这部分信息会用于output embedidng的更新。
v(new)w′j=v(old)w′j−η⋅ej⋅h(1)(1)vw′j(new)=vw′j(old)−η⋅ej⋅h
第二步input->hidden更新input embedding矩阵, 前一步学到的主题信息会反过来用于input embedding的更新,让同一个paragraph里的单词都学到部分主题信息。而paragraph-id本身对应的向量在每个滑动窗口都会被更新一次,更新用到之前paragraph的信息和窗口内的词向量信息。
v(new)wI=v(old)wI−η⋅V∑j=1ej⋅vw′j(2)(2)vwI(new)=vwI(old)−η⋅∑j=1Vej⋅vw′j
之前有看到把paragraph-id对应向量的信息说成上下文信息,但感觉会有点高估PV-DM的效果,因为这里依旧停留在词袋模型,并没有考虑真正考虑到词序信息。只是通过不同paragraph对应不同的向量,来区分相同单词在不同主题内的词共现信息的差异,更近似于从概率到条件概率的改变。而paragrah-id对应的vector,感觉更多是以比较玄妙的方式得到的加权的word embedding。
PV-DBOW训练
PV-DBOW和Skip-gram的结构近似,skip-gram是中间词预测上下文, PV-DBOW则是用paragraph对应向量来预测文本中的任意词汇。和上面的PV-DM相比,也就是进一步省略了window内的词汇,所以优点就是训练所需内存占用会更少。
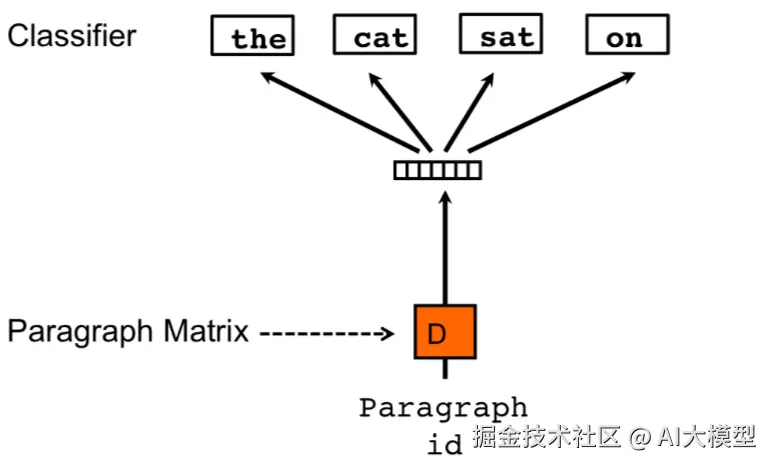
作者表示多数情况下PV-DM都要比PV-DBOW要好。不过二者一起使用,得到两个文本向量后做concat,再用于后续的监督学习效果最好。
模型预测
doc2vec和word2vec一个明显的区别,就是对样本外的文本向量是需要重新训练的。以PV-DM为例,在infer阶段,我们会把单词的input embedding,output embedding,以及bias都freeze,只对样本外的document embedding进行训练,因此doc2vec的预测部分是相对耗时的,因为也需要一定数量的epochs来保证样本外的document embedding收敛。这个特点部分降低了doc2vec在实际应用中的可用性。
Gensim实践
这里我们基于Gensim提供的word2vec和doc2vec模型,我们分别对搜狗新闻文本向量的建模,对比下二者在文本向量和词向量相似召回上的差异。
训练集测试集对比
上面提到Doc2vec用PV-DM训练会得到训练集的embedding,对样本外文本则需要重新训练得到预测值。基于doc2vec这个特点,我们来对比下同一个文本,训练的embedding和infer的 embedding是否存在差异。代码里我们默认样本内文本可以通过传入tag得到,这个和gensim的TaggedDocument逻辑一致,而样本外文本需要直接传入分词tokens。所以只需把训练样本从token传入,再按相似度召回最相似的文本即可。这里infer的epochs和训练epochs一致.

在以上的结果中,我们发现同一文本,样本内和样本外的cosine相似度高达0.98,虽然infer和训练embedding不完全一致,但显著高于和其他文本的相似度。这个测试不能用来衡量模型的准确性,但可以作为sanity check。
文本向量对比
我们对比下Doc2vec和Word2vec得到的文本向量,在召回相似文本上的表现。先看短文本,会发现word2vec和doc2vec表现相对一致,召回的相似文本一致,因为对短文本来说上下文信息的影响会小。

在长文本上(文本太长不方便展示,详见JupyterNotebook),word2vec和doc2vec差异较明显,但在随机选取的几个case上,并不能明显感知到doc2vec在长文本上的优势,当然这可能和模型参数选择有关。
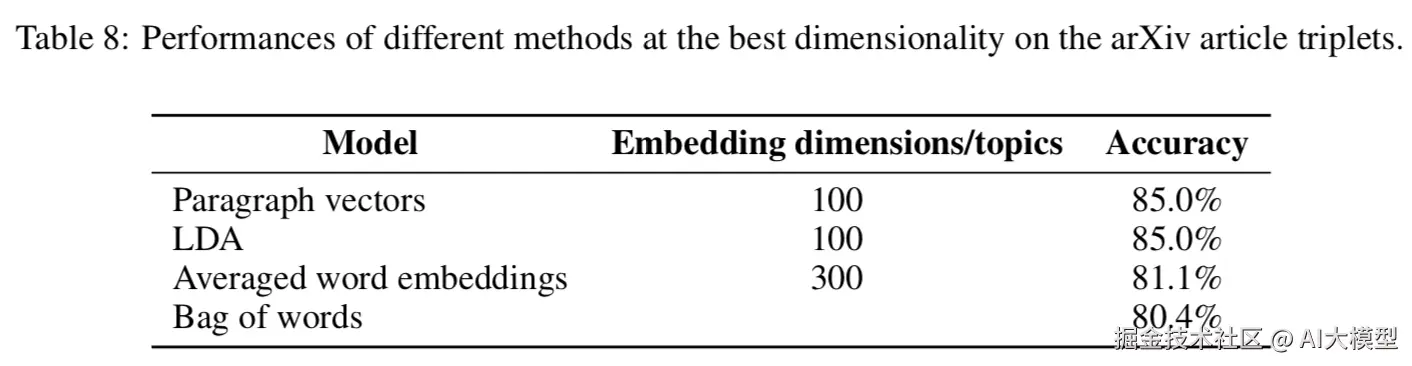
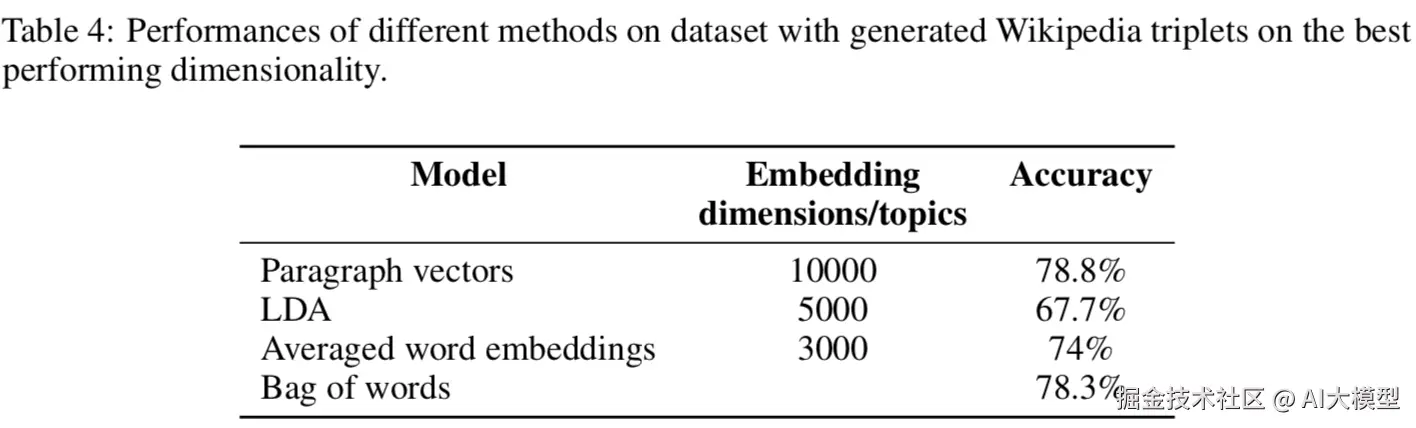
对此更有说服力的应该是Google【Ref2】对几个文本向量模型在wiki和arivx数据集的召回对比,他们分别对比了LDA,doc2vec,average word embedding和BOW。 虽然doc2vec在两个数据集的准确度都是最高的。。。算了把accuracy放上来大家自己感受下吧。。。doc2vec的优势真的并不明显。。。再一看呦呵最佳embedding size=10000,莫名有一种大力出奇迹的感觉。。。
词向量对比
考虑我们用的PV-DM建模在训练文本向量的同时也会得到词向量,这里我们对比下在相同corpus,相同参数的word2vec和doc2vec得到的词向量的差异。
考虑北京今年雨水多到的让我以为到了江南,我们来看下下雨类词汇召回的top10相似的词,由上到下按词频从高到低排序。

比较容易发现对于高频词,Doc2vec和word2vec得到的词向量相似度会更接近,也比较符合逻辑因为高频词会在更多的doc中出现,因此受到document vector的影响会更小(被平均)。而相对越低频的词,doc2vec学到的词向量表达,会带有更多的主题信息。如果说word2vec是把语料里所有的document混在一起训练得到general的词向量表达,doc2vec更类似于学到conditional的词向量表达。所以脱离当前语料,doc2vec的词向量实用价值比较玄学,因为不太说的清楚它到底是学到的了啥。
整体看来PV-DM/DBOW没有特别眼前一亮的感觉,不过毕竟是14年的论文了,这只是文本表征的冰山一角,后面还能扯出一系列的encoder-decoder,transformer框架啥的。预知后事如何,咱慢慢往后瞧着~
学习
我使用PlantUML绘制了一份技能树脑图,把大模型路线分成L1到L4四个阶段,这份大模型路线大纲已经导出整理打包了,在 >gitcode ←←←←←←
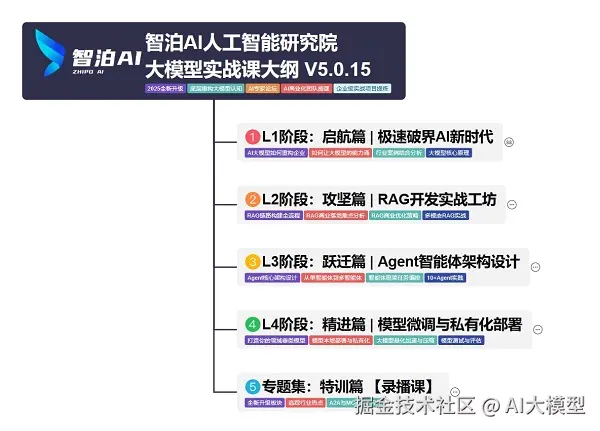
L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。
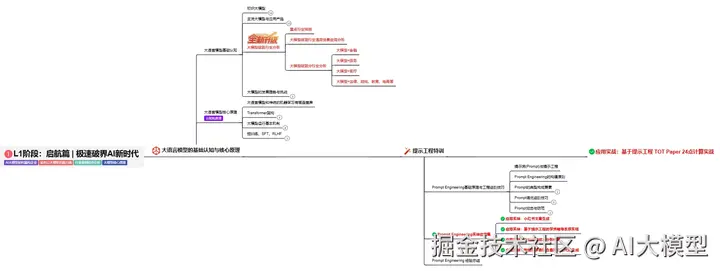
L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。
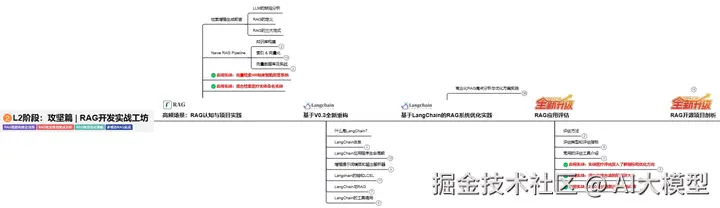
L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。
L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇