本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在这里。
在上一篇文章中,我介绍了自己使用 Obsidian 结合 PARA 方法论搭建起了自己的本地知识库,同时介绍了如何使用 Gemini CLI 让 Obsidian 有了强大的 AI 能力。
虽然 Gemini 很强,但它毕竟是云端模型,将私人的笔记数据发送到云端始终是许多人心中的一根刺。
今天来介绍下我是如何使用 本地 Ollama + Qwen 3 模型 ,结合 Obsidian 构建真正的本地隐私 RAG(检索增强生成)知识库的。我的目标很明确:打造一个完全离线、绝对隐私、且懂你的私人 AI 助理。
为什么要 "完全本地化"?
Obsidian 的核心价值观是 "Your data is yours" (你的数据属于你)。当我们把所有的思考、日记、工作计划都记录在这些 Markdown 文件中时,它们就构成了我们的"第二大脑"。
然而,传统的云端 AI 助手存在天然的悖论:
- 隐私泄露风险:要让 AI 懂你,就得把数据发给它;发给它,数据就离开了你的控制。
- 网络依赖: 非常依赖于在线网络,如果断网就完全不可用。
- 数据安全:你的个性化模型在云端服务,如果云服务停止运营,个人训练的模型也就消失了。
如果你有一台还不错的电脑,那么构建本地 RAG 知识库就完美解决了这个问题:数据不出门,推理在本地,不仅安全又高效。
我想要的是什么?
有了构建的想法,接下来就是如何实施。其实一直以来,我都渴望拥有一个能记忆个人敏感信息的智能体助理。我可以放心地将一些个人或家人的敏感数据交给它,而它也能随时准确地回答我的提问。
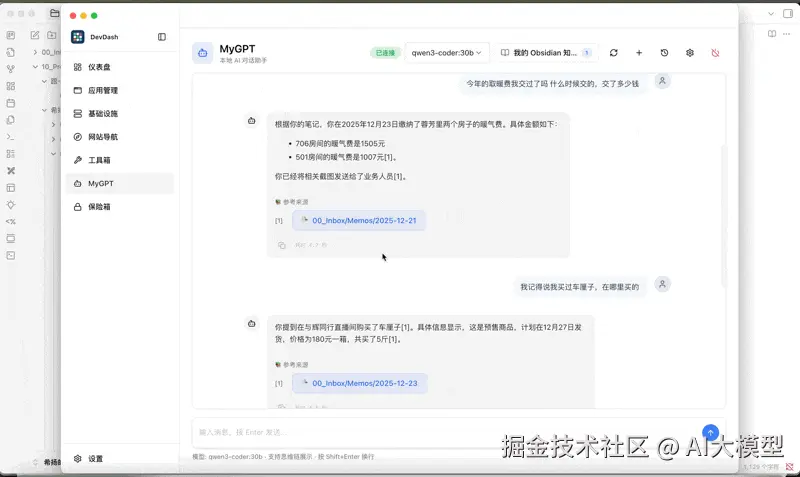
比如我可以问它:"我爸妈的身份证号是多少?""我去年过年的年夜饭都吃了什么?""今年的车险我是什么时候缴的?""六一儿童节晚上我和孩子们聊了什么?"涉及隐私的细节问题。
因为我们使用 Obsidian 作为知识库,所有的知识都存储在本地。配合 Thino 插件,可以实现类似于 Flomo 的灵感记忆存储。我便将这个插件与日记功能结合起来,专门用来记录生活中的琐事。
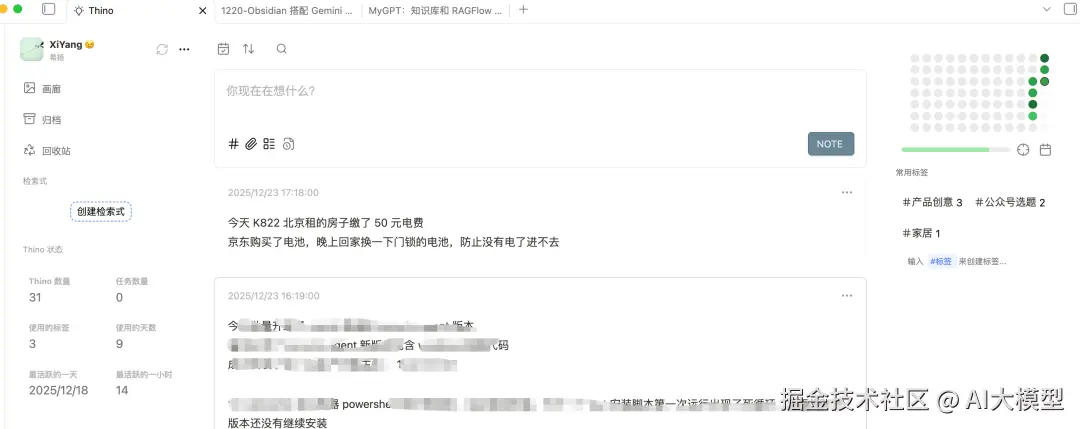
之前一直没有找到实现这个目标的有效路径,直到我使用 Obsidian 作为我的知识库,我这个想法才真正的变成了现实。
构建的底层原理:什么是 RAG?
构建个人知识库智能问答体,其实标准的做法那就是 RAG。
什么是 RAG?RAG (Retrieval-Augmented Generation,检索增强生成) 最简单理解是:它给大模型(LLM)配了一个实时查阅的"外挂数据库"或"离线手册"。
大模型虽然强大,但有两个致命伤:
- 幻觉(Hallucination):没见过的数据它会一本正经地胡说八道。
- 知识滞后:它的知识停留在训练结束的那一天(比如 2023 或 2024 年)。
RAG 的核心思想: 既然模型不能实时记住所有新知识,那就在回答问题前,先去"书架"上把相关的资料查出来,贴在 Prompt 后面发给模型:"请参考以下资料回答问题"。
所以我们只要把我们的 Obsidian 本地知识库作为外挂知识库让本地的模型参考,那他就可以基于这些知识回答我们的问题。
但是一般的模型并不能直接读取原始的文档,这中间需要一个对文档建立索引的过程,也就是将文档向量化。具体的过程如下:
- 读取:扫描 Obsidian 库中的 .md文件。
- 切片:把长文章切分成一个个小的文本块(Chunks)。
- 嵌入 (Embedding):利用 BGE-M3 模型,将这些文本块转换成高维向量。比如,"Obsidian 插件配置" 这段文字会被转化成一组代表其语义的数字。
- 存储:将这些向量存入本地的 ChromaDB 数据库。
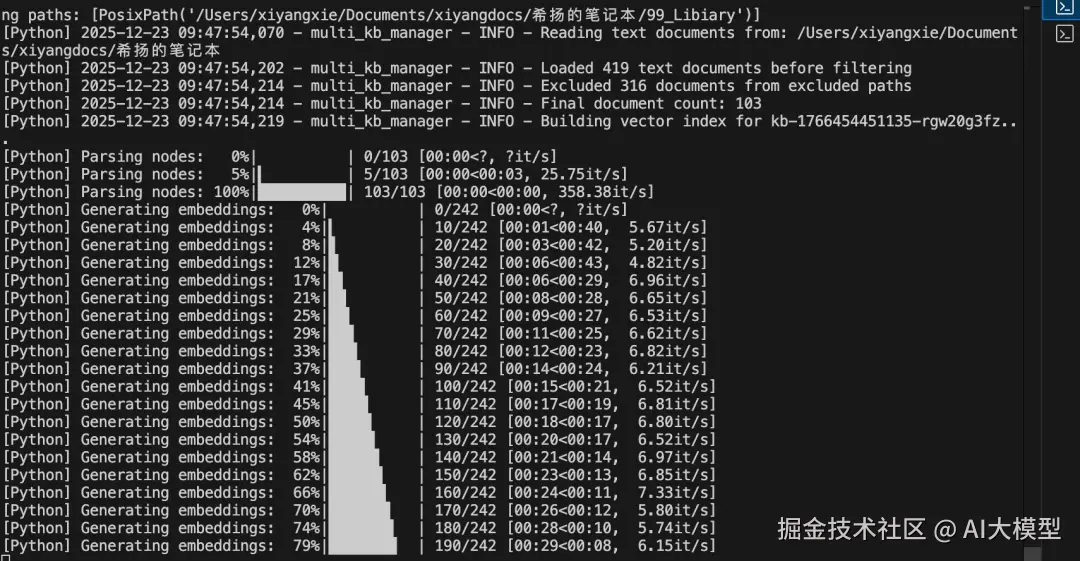
完成这一步后,我们的知识库内容就可以被大模型检索和识别了。接下来就是第二步:大模型通过 RAG 的方式回答我们的私人问题。
它首先会识别用户的问题,把用户的问题也转成向量,然后在 ChromaDB 中快速寻找与问题最相关的笔记片段(Top-K)。将找出的文档块拼接到 Prompt 中,调用本地的推理模型生成答案,我使用的本地推理模型是 qwen-corder3:30b。
构建属于自己的 MyGPT
构建本地知识库也有很多种选择,也有些开源的产品选择,比如 RAGFlow 或者 PrivateGPT。我个人是选择了自己开发,有以下几个原因:
- RAGFlow 虽然能力很强但是特别的重,它需要跑 Docker,启动一堆服务。
- PrivateGPT 虽然相对轻量,但也需要一定的研究成本,且最重要的是,我希望能够进行高度的个性化定制。
因此,我用 electron 构建了一个 mac 原生的应用,其中的核心模块之一就是 MyGPT。目前,这个 MyGPT 已经完美实现了上述的个人知识库问答功能。未来,我还计划加入工具调用功能,从而实现真正的本地 Agent。
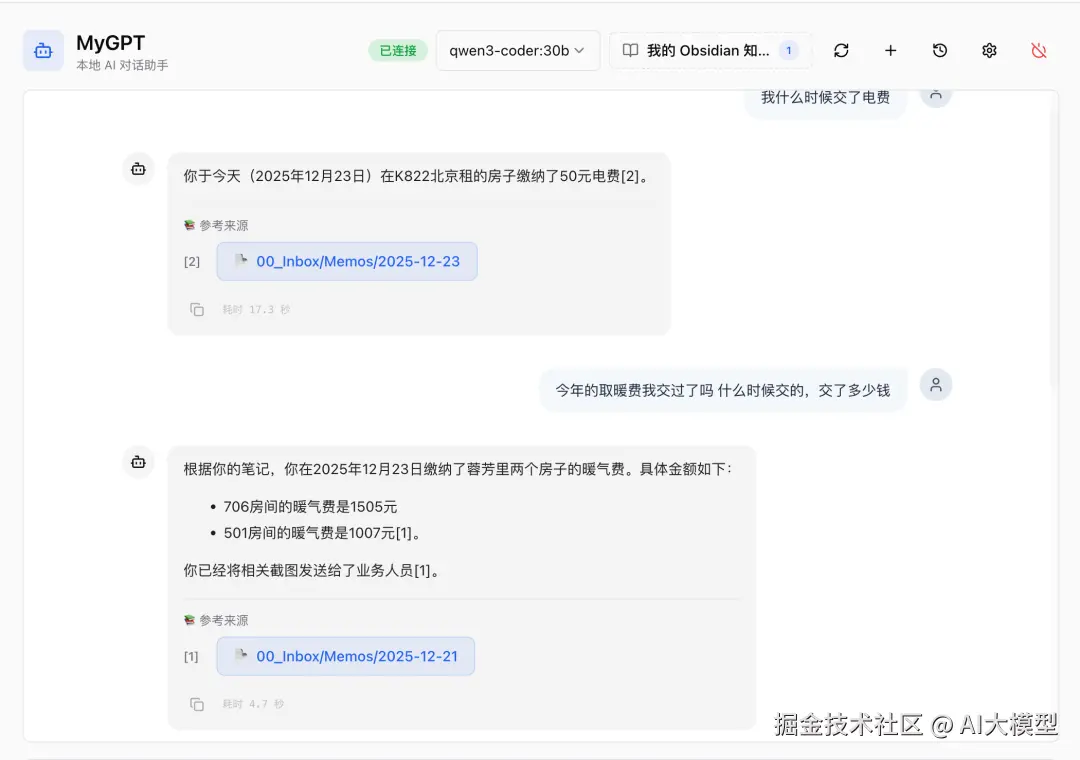
如上图所示,我可以问:"我今年的取暖费交了没,交了多少钱?"它不仅能精准地告诉我答案,还会列出原始文档的参考来源。点击这个参考来源,可以直接跳转到 Obsidian 的原始文档,这是许多其他 RAG 产品所无法做到的体验。
利用同样的方法,我也将吴军老师的一些内容制作成了知识库,作为我的第三方外部知识库加以利用。我可以在做问答的时候选择加载的知识库。

如果你也有和我类似的需求,也可以试试我现在的这种做法。
如果你想更深入地学习大模型,以下是一些非常有价值的学习资源,这些资源将帮助你从不同角度学习大模型,提升你的实践能力。
本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在这里。