Fasttext是FaceBook开源的文本分类和词向量训练库。最初看其他教程看的我十分迷惑,咋的一会ngram是字符一会ngram又变成了单词,最后发现其实是两个模型,一个是文本分类模型Ref2,表现不是最好的但胜在结构简单高效,另一个用于词向量训练Ref1,创新在于把单词分解成字符结构,可以infer训练集外的单词。这里拿quora的词分类数据集尝试了下Fasttext在文本分类的效果, 代码详见 github.com/DSXiangLi/E...
Fasttext 分类模型
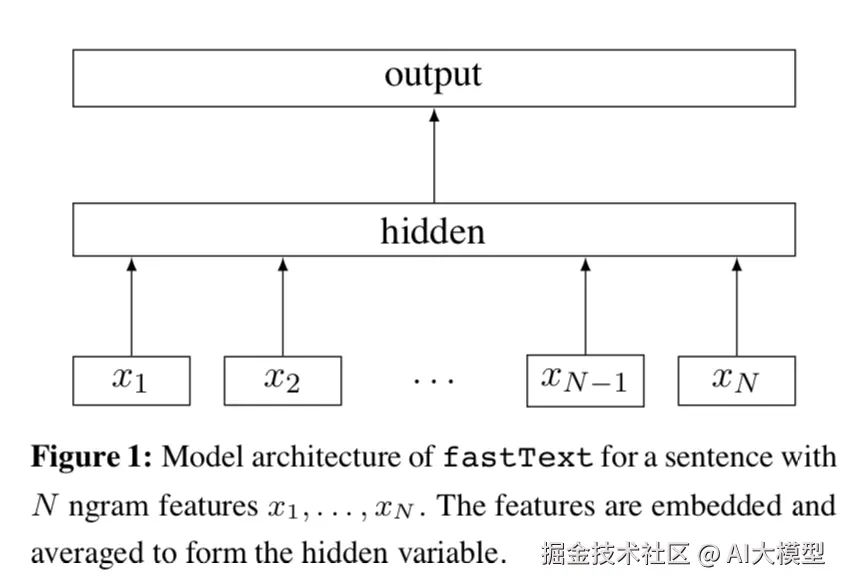
Fasttext分类模型结构很直观是一个浅层的神经网络。先对文本的每个词做embedding得到wiwi, 然后所有词的embedding做平均得到文本向量wdocwdoc,然后经过1层神经网络对label进行预测
wdoc=1nn∑i=1wip=σ(β⋅wdoc)(1)(2)(1)wdoc=1n∑i=1nwi(2)p=σ(β⋅wdoc)
只说到这里,其实会发现和之前word2vec的CBOW基本是一样的,区别在于CBOW预测的是center word, 而Fasttext预测的是label,例如新闻分类,情感分类等,同时CBOW只考虑window_size内的单词,而Fasttext会使用变长文本内的所有单词。
看到Fasttext对全文本的词向量求平均, 第一反应是会丢失很多信息,对于短文本可能还好,但对于长文本效果应该不咋地。毕竟不能考虑到词序信息,是词袋模型的通病。Fasttext对此的解决办法是加入n-gram特征。这里的n-gram是单词级别的n-gram, 把相连的n个单词当作1个单词来做embedding,这样就可以考虑到局部的词序信息。当然副作用就是需要学习的embedding规模会大幅上升,只是2-gram就会比word要多得多。
Fasttext对此的解决方法是使用hashing把n-gram映射到bucket, 相同bucket的n-gram共享一个词向量。
在Quora的文本数据集上我自己实现了一版fasttext分类模型, LeaderBoard的F1在0.71左右,因为要用Kernel提交太麻烦只在训练集上跑了下在0.68左右,所以fasttext的分类模型确实是胜在一个快字。
Fasttext 词向量模型
Fasttext另一个模型就是词向量模型,是在Skip-gram的基础上,创新加入了subword信息。也就是把单词分解成字符串,模型学习的是字符串embedding
,单词的embedding由字符embedding求平均得到,这也是Fasttext词向量可以infer样本外单词的原因。
关于模型和训练细节,和前一章讲到的word2vec是一样的,感兴趣的可以来这里搂一眼
这里我们只细讨论下和subword相关的源代码。这里n-gram不再指单词而是字符,模型参数maxn,minn会设定n-gram的上界和下界。当设定minn = 2, maxn=3的时候,'where'单词对应的subwords是<'wh','her','ere',re'>,还有<'where'>本身。
当时paper看到这里第一个反应是英文可以这么搞,因为英文可以分解成字符,且一些前缀后缀是有特殊含义的,中文咋整,拆偏旁部首么?!来看代码答疑解惑
ini
void Dictionary::initNgrams() {
for (size_t i = 0; i < size_; i++) {
std::string word = BOW + words_[i].word + EOW; // 词前后加入<>用来区分单词和字符
words_[i].subwords.clear();
words_[i].subwords.push_back(i); //先把单词本身加入subword
if (words_[i].word != EOS) {
computeSubwords(word, words_[i].subwords);
}
}
}
void Dictionary::computeSubwords(
const std::string& word,
std::vector<int32_t>& ngrams,
std::vector<std::string>* substrings) const {
for (size_t i = 0; i < word.size(); i++) {
std::string ngram;
if ((word[i] & 0xC0) == 0x80) {
continue; // 遇到10开头字节跳过,保证中文从第一个字节开始读
}
for (size_t j = i, n = 1; j < word.size() && n <= args_->maxn; n++) {
ngram.push_back(word[j++]);
while (j < word.size() && (word[j] & 0xC0) == 0x80) {
ngram.push_back(word[j++]); // 如果是中文,读取该字符的所有字节
}
if (n >= args_->minn && !(n == 1 && (i == 0 || j == word.size()))) {// subword满足长度,得到hash值加入到ngrams里面
int32_t h = hash(ngram) % args_->bucket;
pushHash(ngrams, h);
if (substrings) {
substrings->push_back(ngram);
}
}
}
}
}核心在computeSubwords部分, 乍一看十分迷幻的是(wordi & 0xC0) == 0x80) 。这里0xC0二进制是11 00 00 00,和它做位运算是取字节的前两个bit,0x80二进制是10 00 00 00,前两位是10,其实也就是判断wordi前两个bit是不是10,。。。10又是啥?
简单来说就是Fasttext要求输入为UTF-8编码,这里需要用到UTF-8的两条编码规则:
- 单字节的符号,字节的第一位是0后面7位是unicode,英文的ASCII和utf-8是一样滴
- n字节的符号,第一个字节的前n位是1,后面字节的前两位一律是10,是的此10就是彼10。

因为所有的英文都是单字节,而中文在utf-8中通常占3个字节,也就是只有读到中文字符中间字节的时候(wordi & 0xC0) == 0x80) 判断成立。所以判断本身是为了完整的读取一个字符的全部字节,也就是说中文的subword最小单位只能到单个汉字,而不会有更小的粒度了。而个人感觉汉字粒度并不能像英文单词的构词一样带来十分有效的信息,所以Fasttext的这一创新感觉对中文并不会有太多增益。
不过说起拆偏旁部首,蚂蚁金服人工智能部在2018年还真发表过一个引入汉子偏旁部首信息的词向量模型cw2vec理论及其实现,感兴趣的可以去看看哟~
学习
我使用PlantUML绘制了一份技能树脑图,把大模型路线分成L1到L4四个阶段,这份大模型路线大纲已经导出整理打包了,在 >gitcode ←←←←←←
L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。
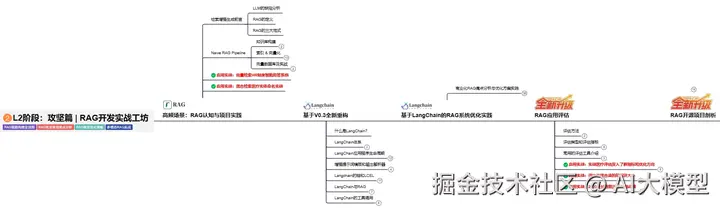
L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。
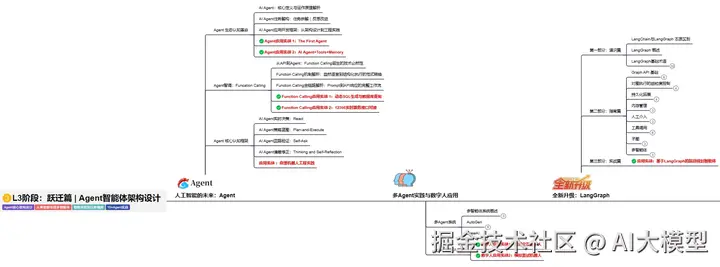
L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。
L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇