前言:名词解释
**RAG:**检索增强生成(Retrieval-Augmented Generation),是一种结合信息检索与生成模型的技术。其核心机制是从知识库中检索出与用户查询有相关性的文本,再将文本内容嵌入到提示词中,最后由大语言模型基于嵌入文本的提示词生成最终答案。这种在提示词加入外部文本知识的方式可以弥补大语言模型知识时效性不足、领域专业知识欠缺等缺点,进而缓解大语言模型生成内容的幻觉问题,提升准确性、时效性和可信度。
**Dify:**开源的大语言模型应用开发平台,融合了后端即服务(Backend as Service, BaaS)和 LLMOps 理念。它支持多种大型语言模型,如 Claude3、OpenAI 等,并提供强大的数据集管理功能、可视化的 Prompt 编排以及应用运营工具。Dify 采用模块化设计,通过低代码 / 无代码开发,允许开发者轻松定义 Prompt、上下文和插件等,能够快速搭建生产级的 AI 应用。
**钉钉自动化小助手:**居然之家采用钉钉作为日常办公协同软件,钉钉自动化小助手是由钉钉连接平台提供的群聊机器人。在自动化小助手中,不同的群成员可以创建多条不同的自动化流程,帮助我们自动化处理一些常见的任务,如发送定时消息、回答问题等。群主或群管理员可以在电脑端钉钉的群设置中添加自动化小助手,并按需选择已有模板或新建自动化流程。
**DOS:**全渠道商管系统 DOS,作为居然之家的数字化底座,家居行业内首个全渠道商业管理系统。依托 "三横三纵" 架构(横向覆盖招商、营销、财务、物业,纵向打通设计、生产、销售、服务)构建差异化优势;通过整合招商、营销、财务等六大模块,实现了从商户入驻到售后服务的全流程数字化。
**DMA:**洞窝智能营销系统是由运营人员管理的客户数据库,可采集整合不同渠道的客户数据并分析应用,对内实现数据打通分析与可视化,对外通过客户生命周期管理提供个性化服务,最终提升营销效率、优化客户体验并促进业绩利润增长。
一、背景介绍
1、业务背景
居然之家成立于1999年,是国内家居连锁行业龙头,目前的主要业态包括家居连锁主业、家装设计和装修、供应链物流配送、家政服务、购物中心、以及生活超市和海外站等,洞窝是居然之家的全资子公司,主要负责以上业态相关数字化产业服务平台建设,包括自研和第三方系统维护,主要包含:
(1)、卖场经营管理、智慧零售终端等,涉及数字化招商、品牌运营、导购收银、资金清结算、物流配送、安装售后等全链条业务闭环;
(2)、多个创新业务子赛道,比如iot智能家居、乐屋装饰、智慧家、洞车等等;
(3)、集团、各分公司、门店使用的内部管理系统,比如人力、宜搭、招采、财务等内部平台;
以上B端系统占比超过80%,最高峰阶段涉及B端使用用户数量超过1万+。
2、痛点介绍
2.1、系统多且复杂度高,日常答疑咨询量大
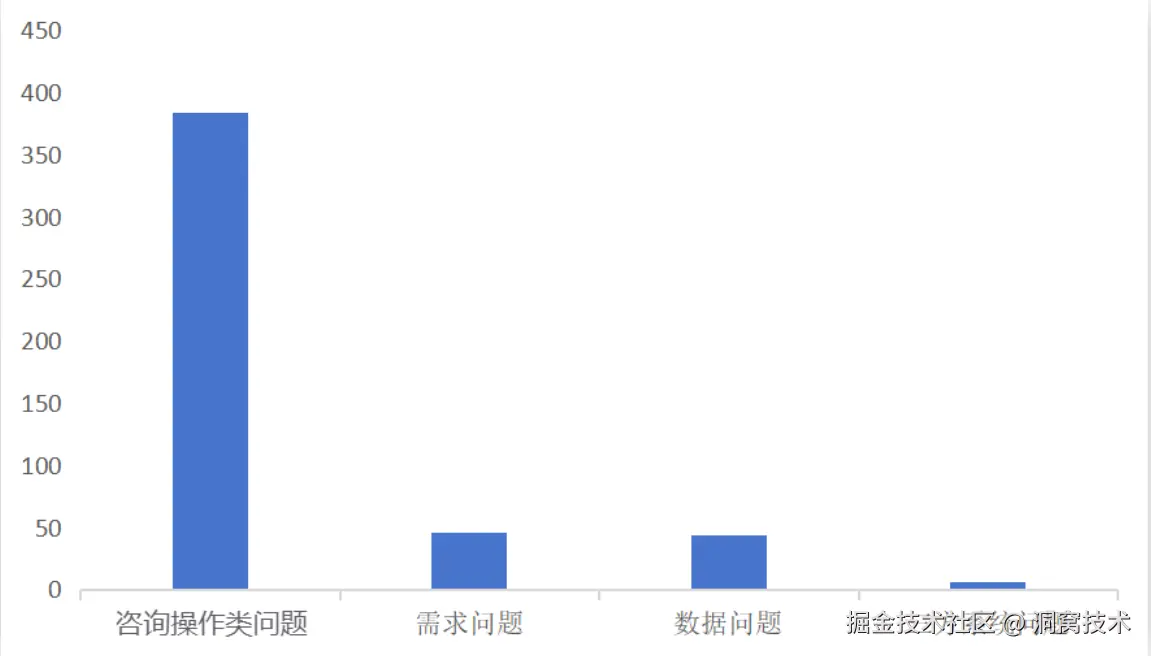
内部系统较多,并且系统间协同复杂度较高,日常答疑咨询量大。仅DOS业务线咨询量将近400条/月,涉及各分公司、门店财务日结、月结、日常返款以及对账等场景答疑,如果只靠人工客服,需在不同系统之间来回查询,响应时间长,处理效率低。
2.2、重复性操作类问题多、重复回答占用人力成本高
基于已有的数据分析,咨询操作类问题占80%左右,其中重复问题占比超过40%。每月仅操作类问题就需投入约 64 小时(相当于 8 个标准工作日)。产研运测团队需持续承接高频重复咨询,大量精力被 "反复解答同类问题" 占用。这导致团队难以及时响应复杂问题,更无力聚焦核心任务,形成 "被动支持" 的恶性循环。
2.3、非工作日响应慢,不支持7*24小时服务
人工客服受限于工作时段与节假日,在目前降本增效的大背景下,以集团现有的人力资源,很难支持7x24小时响应,影响用户体验。
二、实践目标
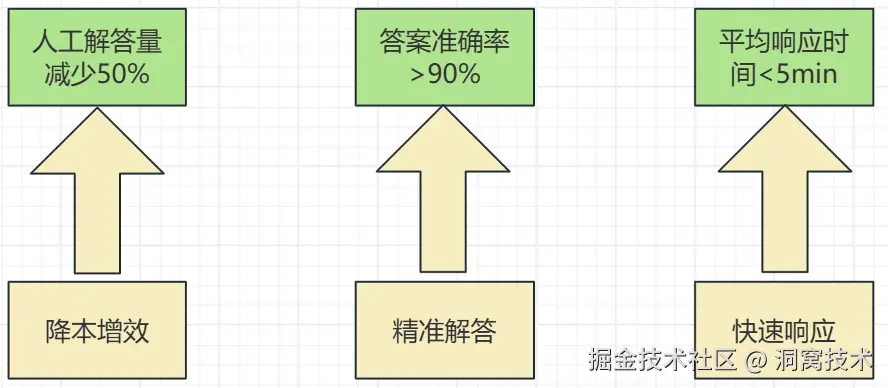
针对上述痛点,我们需要一套能覆盖 "问题接收 - 知识检索 - 精准解答 - 效果反馈" 全流程的智能问答工具,其核心目标是:
(1)、整合分散知识库形成统一检索出/入口
(2)、快速拦截 80% 操作类问题、40% 重复性问题
(3)、将单问题解答时长从平均 10 分钟压缩至 1 分钟内,支持7*24小时服务
三、解决方案
公司采用钉钉作为日常办公协同软件,经过调研和选型,我们选择钉钉作为入口,集成RAG+Dify的方案来完成智能问答工具的搭建,具体包括:
1、模型及其关键工具选型
1.1、向量化模型bge-m3:
BGE-M3模型由北京智源人工智能研究院 BAAI 开发,于2024 年发布的一个多功能的嵌入模型。它具有 多语言性(Multi-Linguality)、多功能性(Multi-Functionality)、多粒度性(Multi-Granularity) 特点。该模型基于 XLM-RoBERTa 架构进行了优化,训练数据规模高达 2.5TB,覆盖 100 多种语言,支持从短句到长达 8192 个 token 的文档处理。
相比 RoBERTa 和 XLM-RoBERTa,BGE-M3 的创新在于它不仅保留了 MLM(掩码语言模型)任务,还引入了多种检索功能:稠密检索(生成固定维度的密集向量,用于语义相似性匹配)、稀疏检索(生成高维稀疏向量,类似于 BM25,强调词的精确匹配)、多向量检索(用多个向量表示文本如 ColBERT,捕捉更细粒度的上下文信息)。
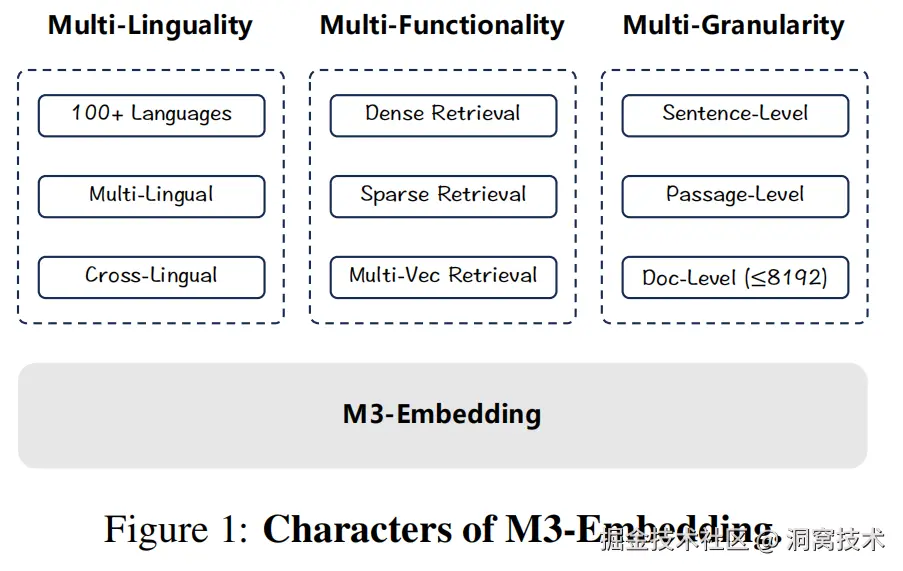
图1(来源于论文:M3-Embedding: Multi-Linguality, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation)
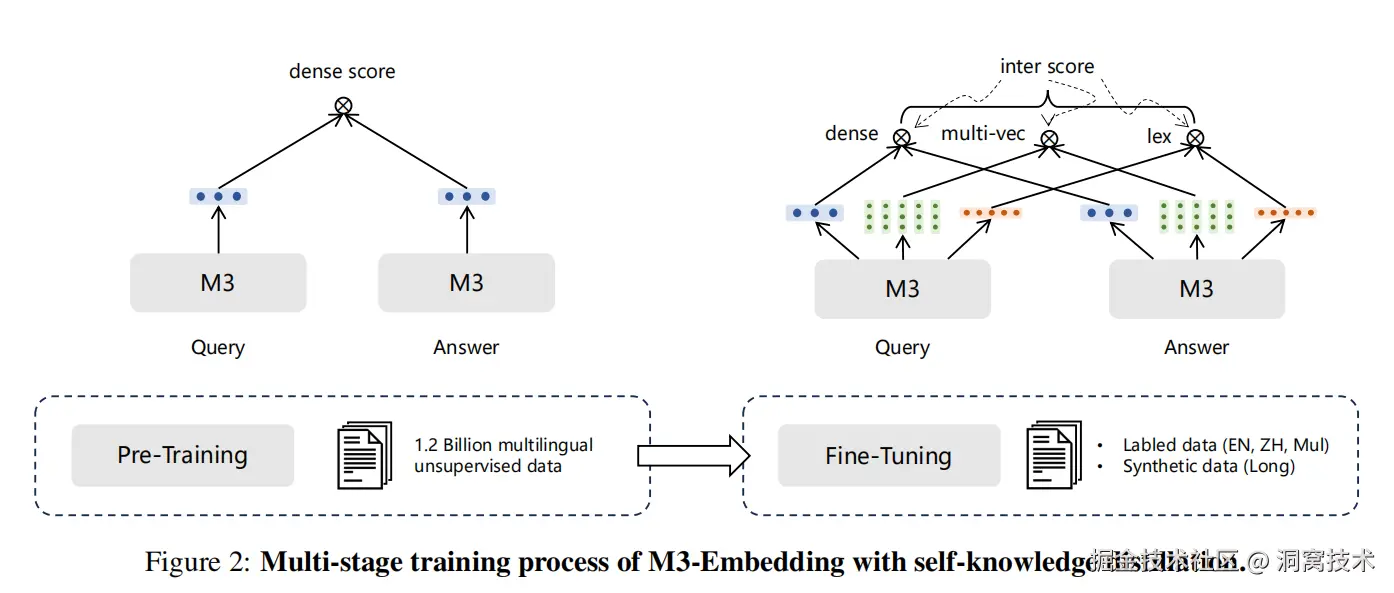
图2(来源于论文:M3-Embedding: Multi-Linguality, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation)
这种多功能设计让它可以灵活应对不同场景,比如结合稠密和稀疏检索的混合检索(Hybrid Retrieval),提升准确性和泛化能力。我们选择这种模型的原因在于该模型在长短文本检索中达到业内领先水平,同时其特有的稀疏检索也特别适合对话场景短query情形,无须再去额外做BM25之类的检索。一个模型即可兼顾语义级别检索与字词级别检索。
1.2、重排模型bge-reranker-v2-m3:
BGE-Reranker-v2-M3 是北京智源研究院(BAAI) 推出的一款轻量级重排序模型,参数量为568M,易于部署和快速推理。该模型基于BGE-M3-0.5B 架构优化,专门设计用于多语言检索任务,尤其在中文和英文混合场景中表现出色。它主要应用于RAG (检索增强生成) 流程中的重排序阶段,用于过滤无关信息,提升相关段落的优先级,从而改善生成式AI 的准确性和响应速度。也特别适用于各种需要文本重排序的场景,例如搜索、问答、推荐等。
在bge重排系列模型中还有许多模型如bge-reranker-large、bge-reranker-v2-gemma、
bge-reranker-v2-minicpm-layerwise等,但是综合对比各个模型参数量级、推理速度、排序指标后,我们最终选择BGE-Reranker-v2-M3模型作为RAG检索中重排模型。
1.3、Milvus数据库:
目前市面上可做向量检索的主流数据库有Milvus、Qdrant、Pinecone、Elasticsearch、OpenSearch、Chroma DB等,其中milvus数据库最初研发定位就是向量存储和检索,支持百亿级向量数据,并且提供多种向量索引方式,高性能、高扩展等特性让它非常适合AI语义搜索、推荐系统等大规模向量计算场景。
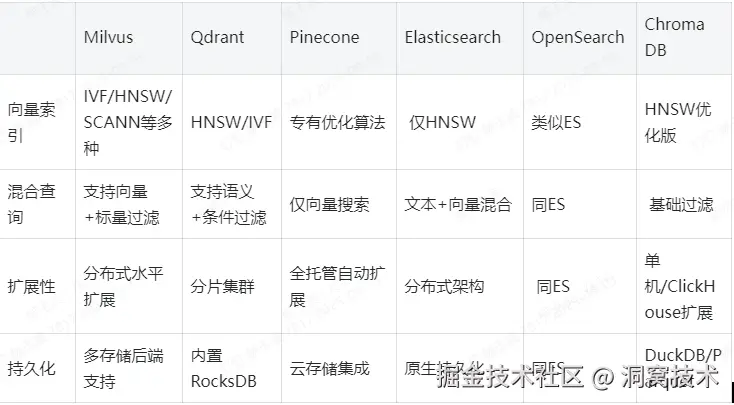
目前,Milvus 有三种部署选项:Milvus Lite、Milvus Standalone 和 Milvus Distributed。Milvus Lite是一个 Python 库,用于较小的数据集,可支持几百万个向量。Milvus Standalone 是单机服务器部署,适用于中型数据集,可扩展支持1亿向量。Milvus Distributed 可部署在Kubernetes集群上,专为大规模部署而设计,能够处理从一亿到数百亿向量的数据集。
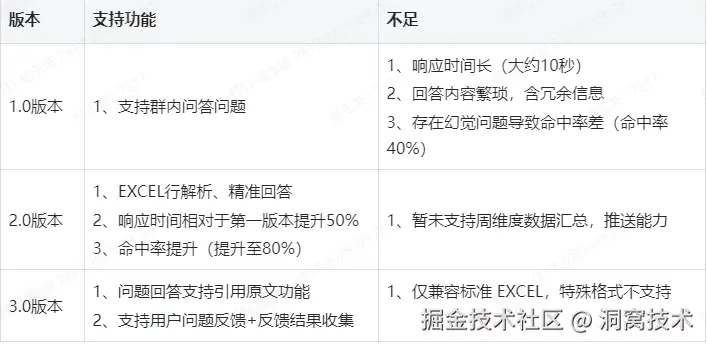
2、工具演进过程
为了能最大程度匹配 "用户提效、团队减负、知识增值" 的核心目标,我们经历了3个版本的迭代,具体包括:
3、核心流程
通过 RAG 技术解决 "知识精准检索与生成" 问题,借助 Dify 实现 AI 问答逻辑的快速开发,依托钉钉低代码平台完成与以上工具和业务场景的无缝集成 。
3.1、架构全景图
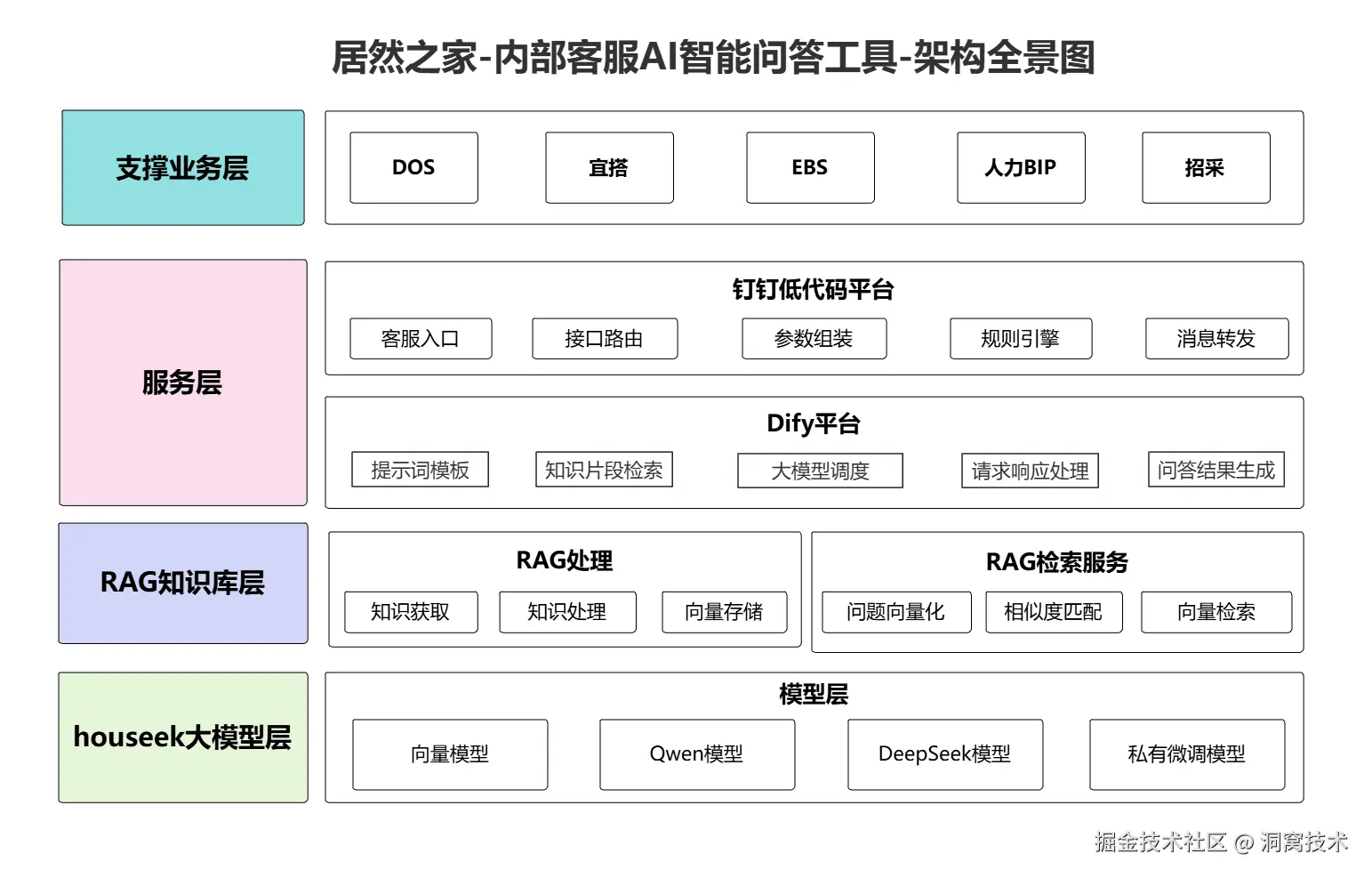
3.2、模块功能介绍
1)支撑业务层
核心定位:业务场景入口与用户交互载体
具体构成:公司内部系统,包含DOS 系统、钉钉宜搭、EBS等,承担用户问题发起、业务数据关联等基础交互功能。
2)服务层
钉钉低代码平台
核心定位:请求处理与服务衔接桥梁
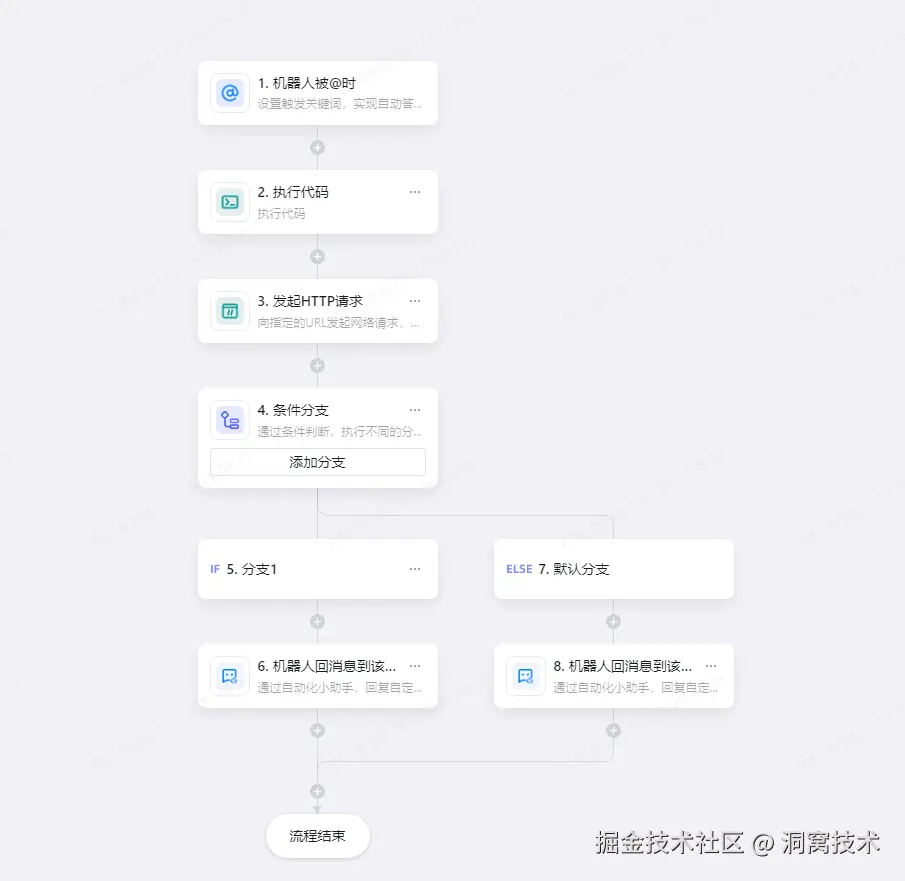
核心功能:接收业务接入层传递的用户问题,封装请求并转发至后端服务;接收后端返回的处理结果后,按钉钉生态规则整理并推送至目标群聊
钉钉低代码流程:
Dify平台
核心定位:交互流程中枢与结果分发节点
核心功能:根据 dify 平台配置的提示词模板,将检索到的知识片段与大模型能力结合,生成自然语言回答并返回至服务
3)RAG知识库层
RAG处理
核心定位:知识库构建与向量存储底座
核心功能:
-
知识获取:支持 Excel 等文件上传,通过解析工具提取文本内容
-
知识处理:对文本进行切片(按语义拆分)、清洗
-
向量存储:将处理后的文本转换为向量,存入 Milvus 向量数据库,为检索服务提供数据支撑
RAG检索服务
核心定位:智能检索与结果生成核心引擎
核心功能:
- 检索服务:接收后端请求后,对问题进行向量化处理,调用向量检索接口完成知识库相似度匹配
RAG原理:
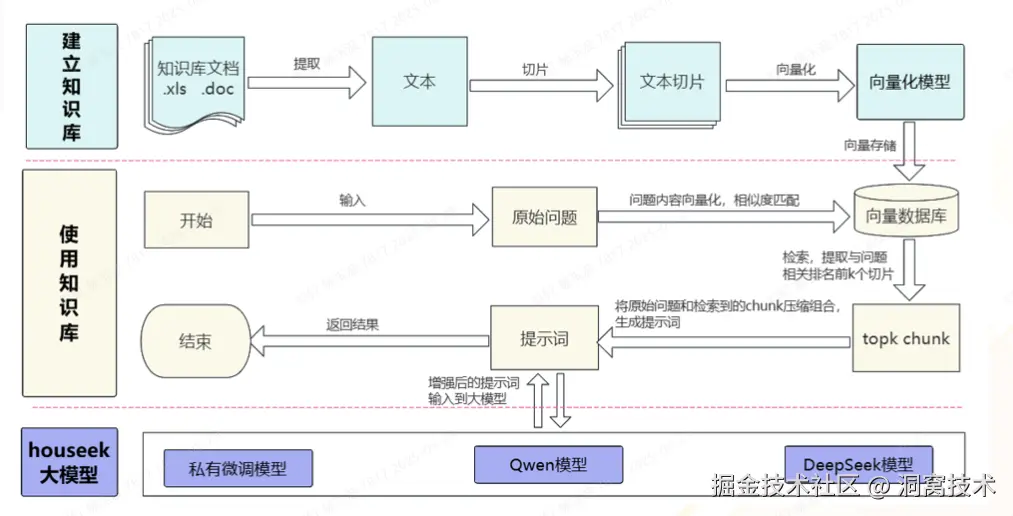
4)houseek大模型层
核心定位:作为基础支撑,为业务提供大模型技术能力
核心功能:
向量模型实现数据的向量化检索与相似性匹配,助力高效内容查找;Qwen、DeepSeek 等通用大模型为智能问答提供文本理解、生成的功能
3.3、数据流
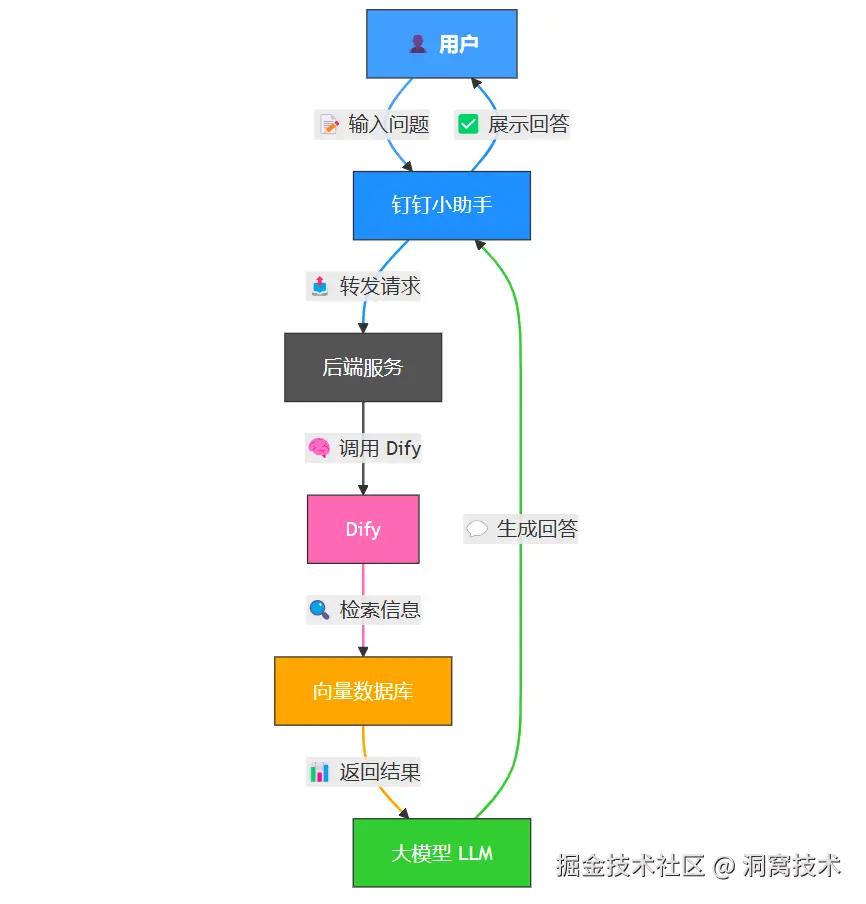
用户输入 -> 钉钉 -> 后端 -> Dify -> 向量库 -> 大模型 -> 钉钉 -> 用户
4、知识库治理
4.1、知识库维护策略
在智能问答体系中,知识库的维护至关重要,直接关系到回答的准确性与有效性。我们通过多渠道收集信息,经严格处理后更新知识库,确保其始终保持高质量状态。我们将问题反馈群作为重要信息来源,安排专人定期浏览群内消息,收集客户提出的各类问题,并详细记录问题的具体内容。除了反馈群,我们还分模块主动进行系统使用拆解,把系统使用步骤、逻辑限制填充到知识库,为知识库的更新提供全面的素材。
1)信息收集记录:

2)数据清洗与预处理: 从多渠道收集到的原始数据往往较为杂乱,需要进行清洗和预处理。首先,对问题进行去重处理,去除重复或相似的问题,避免冗余信息。接着对于不完整或表述模糊的问题,补充完整信息,明确问题含义。同时,对问题进行标准化处理,统一格式、术语,提高数据的规范性。
3)定期审查与优化: 为保证知识库的时效性和准确性,我们建立了定期审查机制。删除过时内容,调整不合理的内容,进一步完善问题及答案的表述。

4.2、知识库命中测试
在将用户原问题处理并归档至知识库后,我们会开展针对性的命中率测试,以此验证知识库对真实用户提问的响应精准度。
1)模拟检索验证:模拟用户真实提问场景,测试系统能否从知识库中精准检索对应答案。
2)偏差原因分析:未命中或结果偏差时,排查原因是问题表述与知识库内容匹配度低还是知识库相关答案缺失 / 不完善。
3)针对性优化:匹配度低则优化问题语言转换、调整关键词权重;知识库缺陷则补充、修正对应答案内容。
知识库命中测试部分截图:

四、实践效果
1、落地成果
我们先行接入了DOS系统进行试用,以8月份周维度对数据进行统计分析,关键数据如下:
1.1、知识沉淀与覆盖: 累计构建专属知识库案例 500 + 条,涵盖各模块高频操作指南、常见问题解法,基本覆盖70% 操作类问题场景。
1.2、咨询承接与分流: 8月份累计接收用户提问160次,其中机器人回答83次,机器人回答占比达 51.88%,机器人回答准确率78.31%,这部分问答无需人工介入,直接拦截了近半数基础咨询,初步实现人力分流。
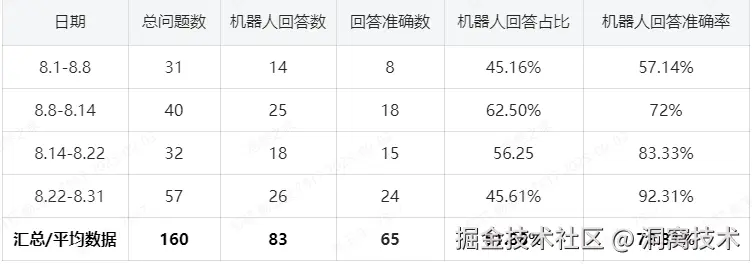
1.3、效率提升量化: 按平均单次人工咨询 10 分钟、机器人回答 1 分钟计算,83 次机器人解答累计节省人力时长约(10-1)×83=747 分钟(约 12.45 小时),相当于减少 1.5个标准工作日的人力投入;同时,机器人响应平均耗时不足 1 分钟,较人工咨询平均 10 分钟的等待时长,将用户问题解决效率提升 90% 以上。
从试用数据来看,方案已初步达成 "分流基础咨询、提升响应效率" 的目标,为后续全业务线推广及知识库迭代奠定基础。
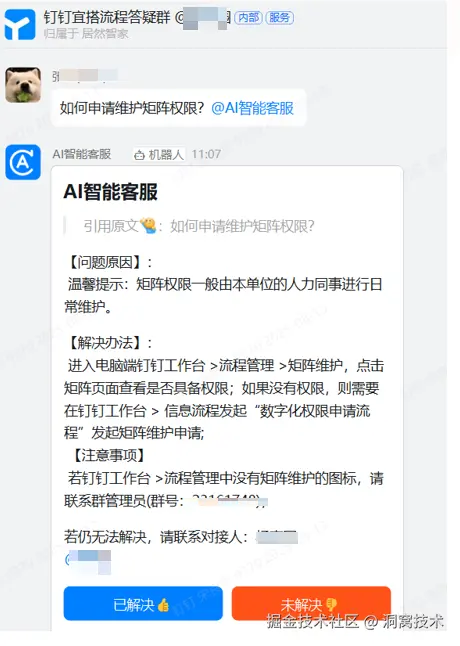
2、案例展示
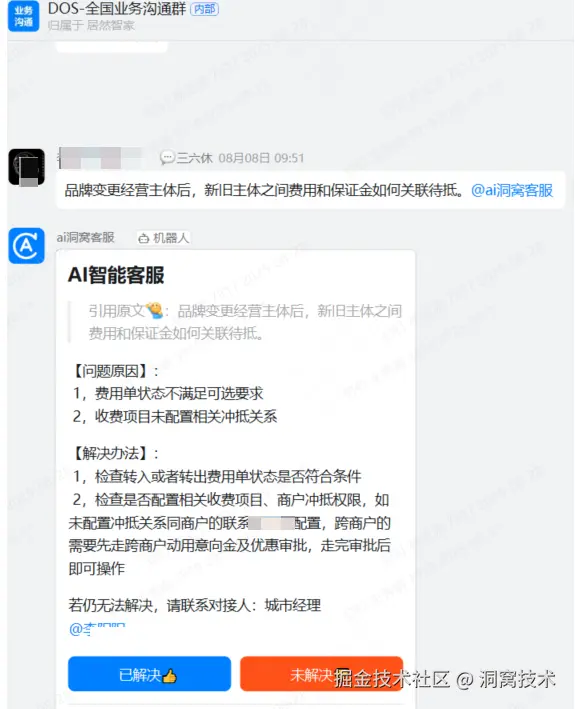
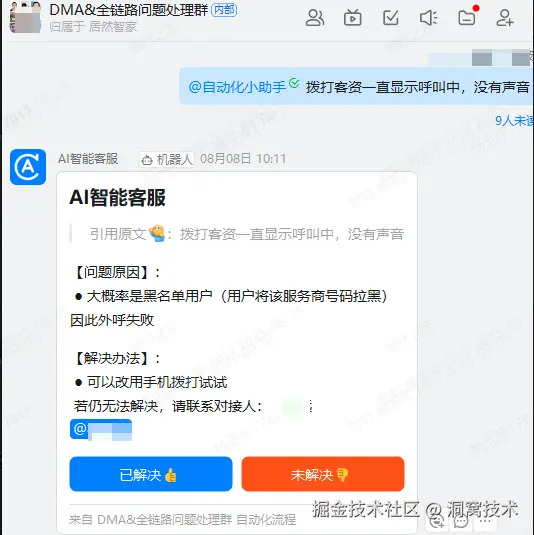
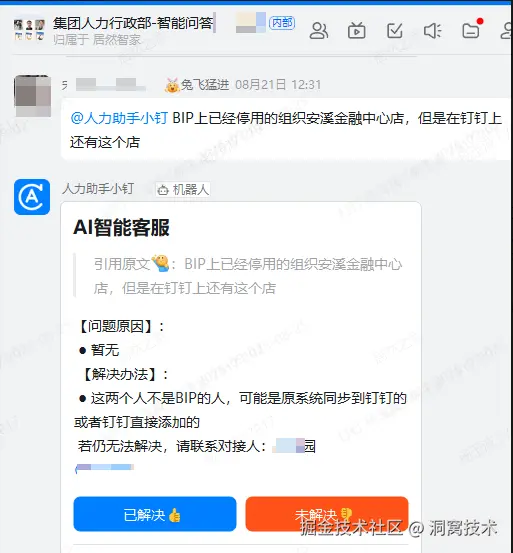
五、后续规划
1、业务覆盖:从 "核心线" 到 "全业务",实现咨询无死角
完成全公司其他业务线的全面接入,建立 "业务线 - 知识标签 - 咨询场景" 的关联体系,支持用户按业务线、岗位角色精准获取答案,彻底解决 "跨业务线咨询分散" 的历史问题。
2、知识库优化:从 "人工维护" 到 "半自动化迭代",降低成本 + 提升命中率
针对当前 "人工维护知识库耗时" 的不足,引入 "用户反馈驱动的知识更新机制":当用户标记 "机器人回答不准确" 时,系统自动触发知识审核流程,同步推送问题原文及相关业务数据给对应业务负责人,缩短知识更新周期从 "3 天" 至 "1 天内"。
每月开展 "知识库命中率复盘":分析提问中未命中的问题,归类为 "知识缺失""检索关键词不匹配""语义理解偏差" 三类,针对性补充知识条目、优化检索算法。
3、工具能力升级:从 "基础问答" 到 "场景化智能服务",提升用户体验
落地 "猜你还想问" 功能:基于用户当前提问,自动推荐关联高频问题,减少用户后续补充提问,提高单次咨询解决率
拓展 "图片识别解读 + 答案配图" 能力:针对系统报错、单据异常等需视觉判断的复杂问题,支持用户上传问题图片,系统通过图片识别技术提取关键信息,进行知识库检索回答,回答时不仅支持纯文本回答,还可以携带标注化配图,彻底解决 "纯文字难描述、人工需反复确认" 的痛点,进一步降低人工咨询占比。
六、总结
智能问答已在DOS、人力BIP、钉钉宜搭、DMA等业务线完成试用落地,通过构建专属知识库、优化 AI 问答逻辑,成功拦截大量基础咨询,既显著减少人力内耗,又大幅提升用户问题解决效率,顺利达成 "提效减负" 的初步目标。方案精准攻克跨平台适配难、知识复用不足的核心痛点,且凭借私有部署大模型方式保障业务数据安全,相比外购工具更契合企业实际运营需求。后续将围绕全业务线覆盖、图片交互功能升级、问答命中率优化持续推进,进一步释放智能服务对内部运营的支撑作用。
作者:杨玉波、候冲、张有华