
github: https://github.com/QwenLM/Qwen-Image-Layered?tab=readme-ov-file
huggingface 应用:
https://huggingface.co/spaces/Qwen/Qwen-Image-Layered
Qwen-Image-Layered 是一个专注于图像分层分解与编辑的仓库,核心功能是将输入图像分解为多个带透明通道(RGBA)的图层,从而支持对每个图层进行独立操作(如重新着色、替换内容、缩放等),实现高保真且一致的图像编辑。
核心功能
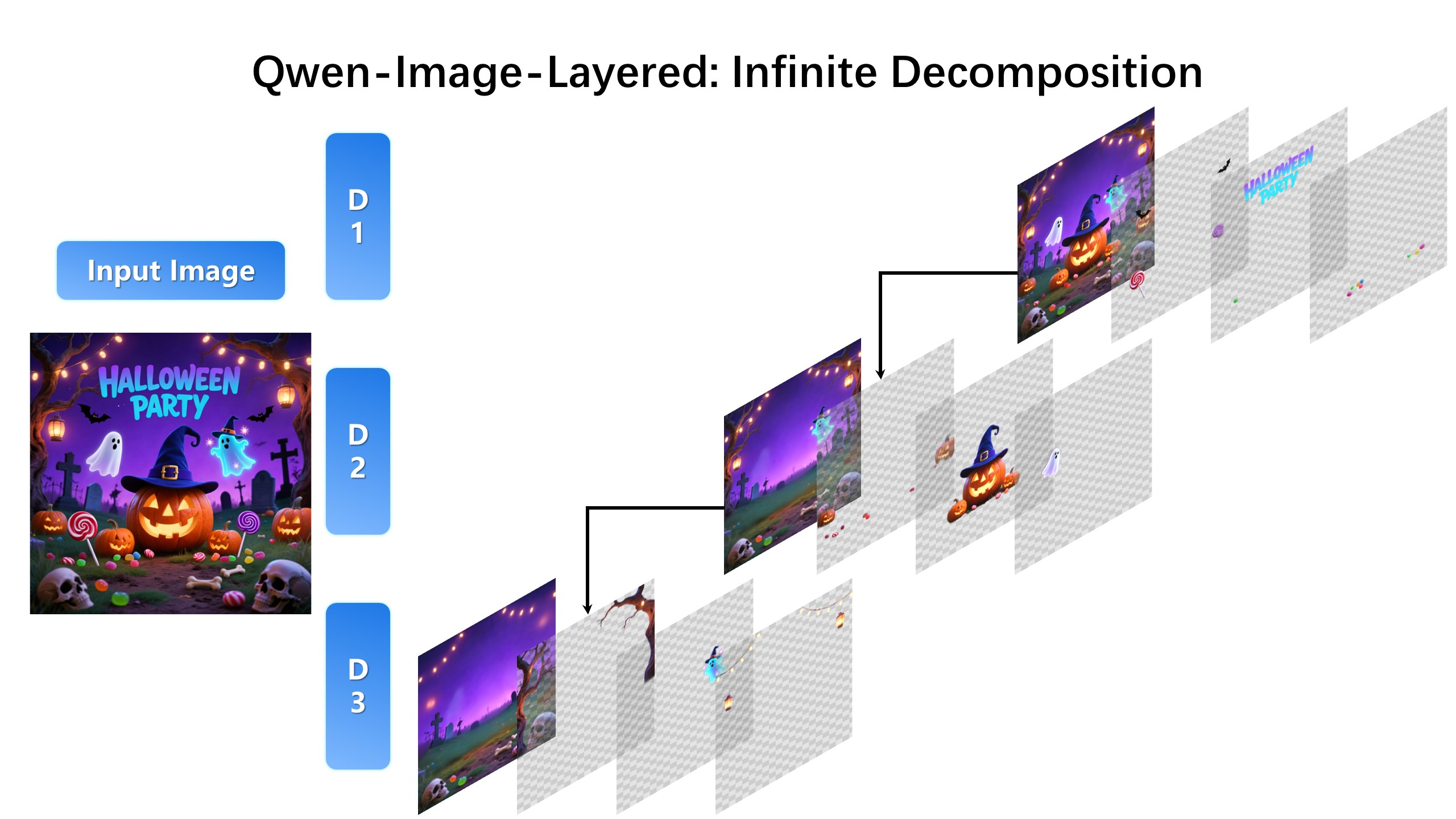
- 图像分层分解:将单张图像自动拆解为多个 RGBA 图层,每个图层物理隔离语义或结构组件(如前景物体、背景、文本等)。
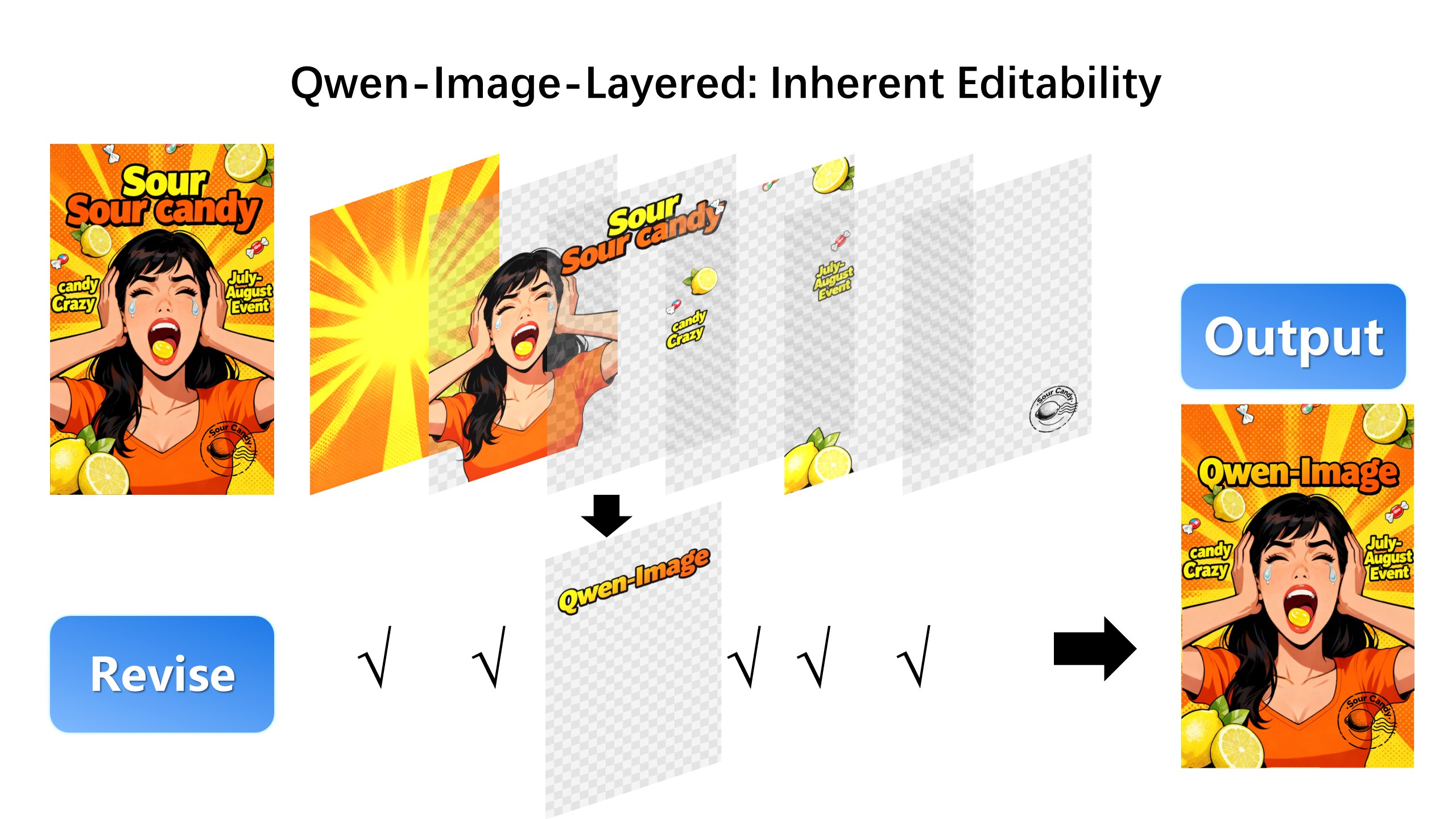
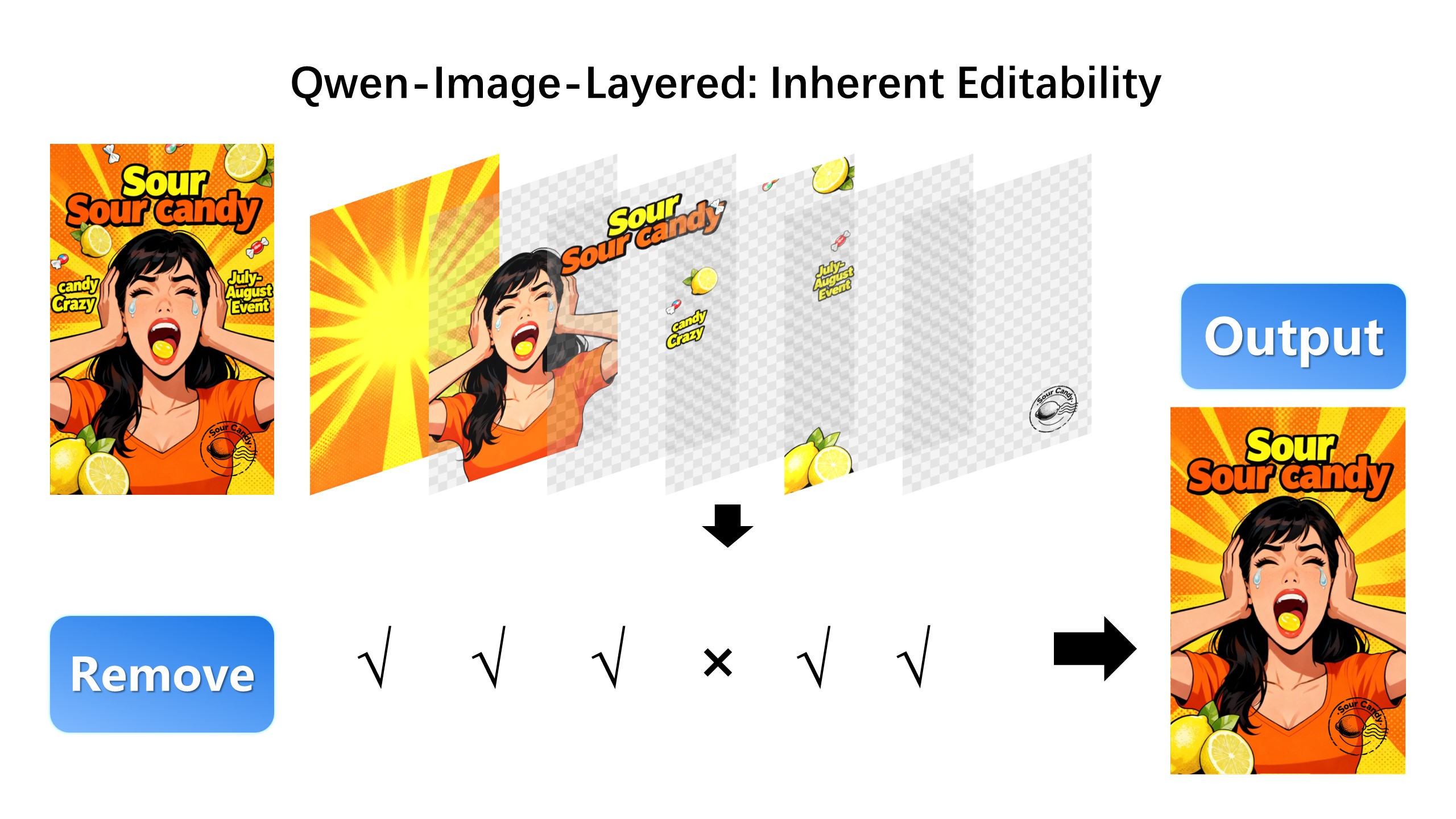
- 图层独立编辑:分解后的图层可单独修改,不影响其他内容,支持重着色、替换、删除、缩放等操作。
- 便捷部署与使用:提供 Gradio 可视化界面,支持一键分解图像并导出为 PPTX 文件(方便图层编辑),以及专门的图层编辑工具。
demo
图层分解与应用

编辑第一层:
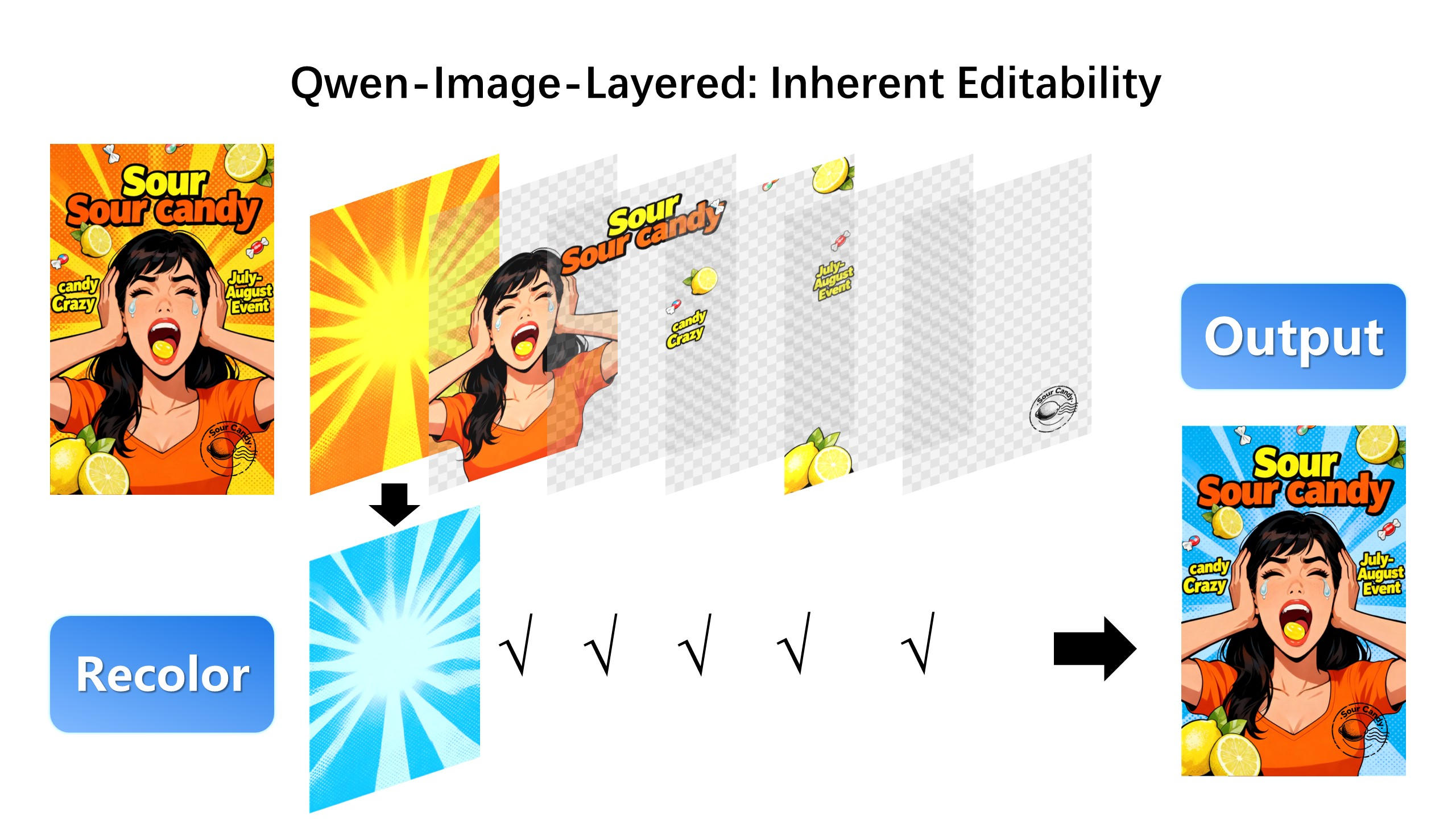
编辑第二层:
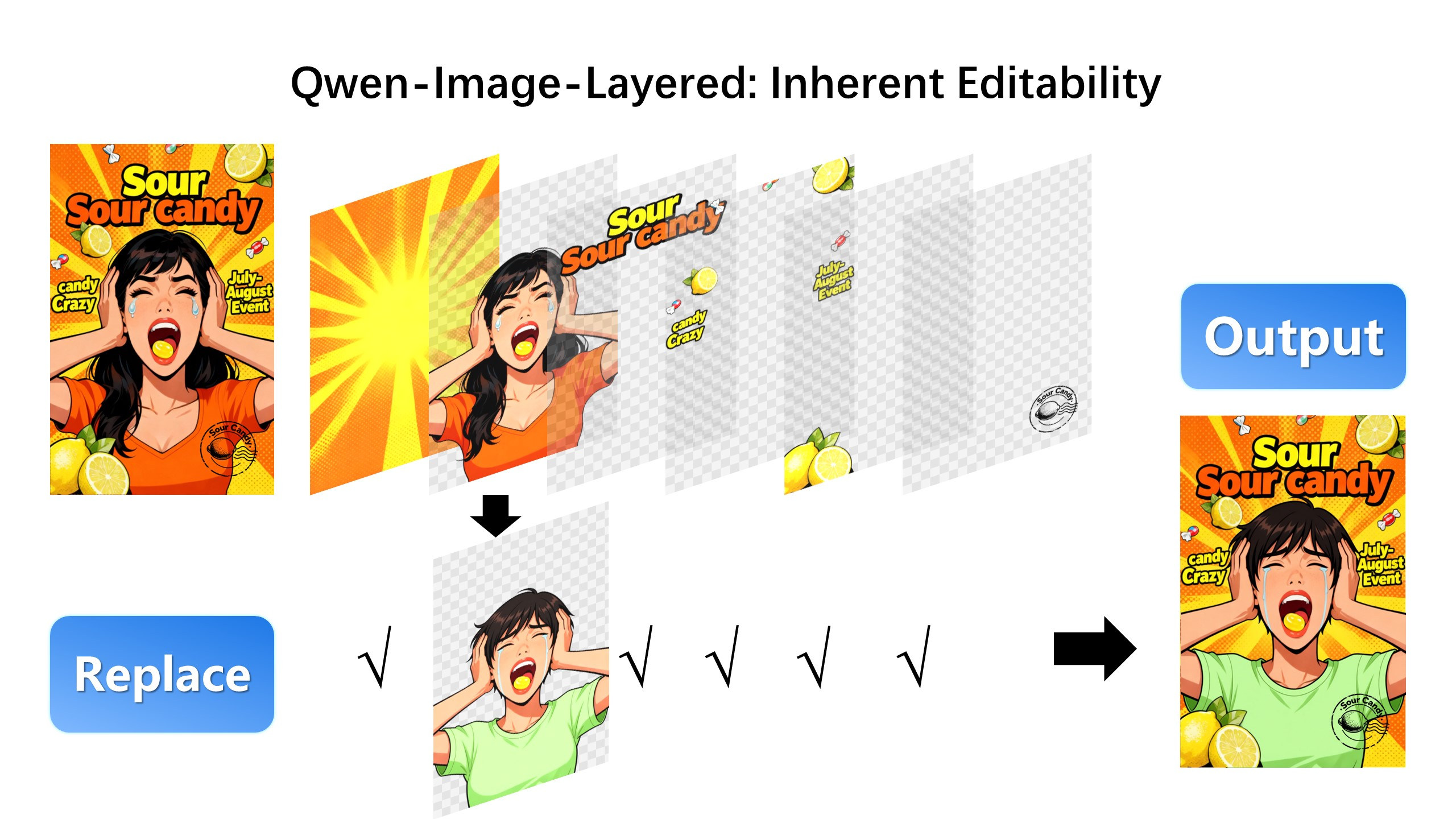
编辑第三层(修改OCR字符):
删除层:
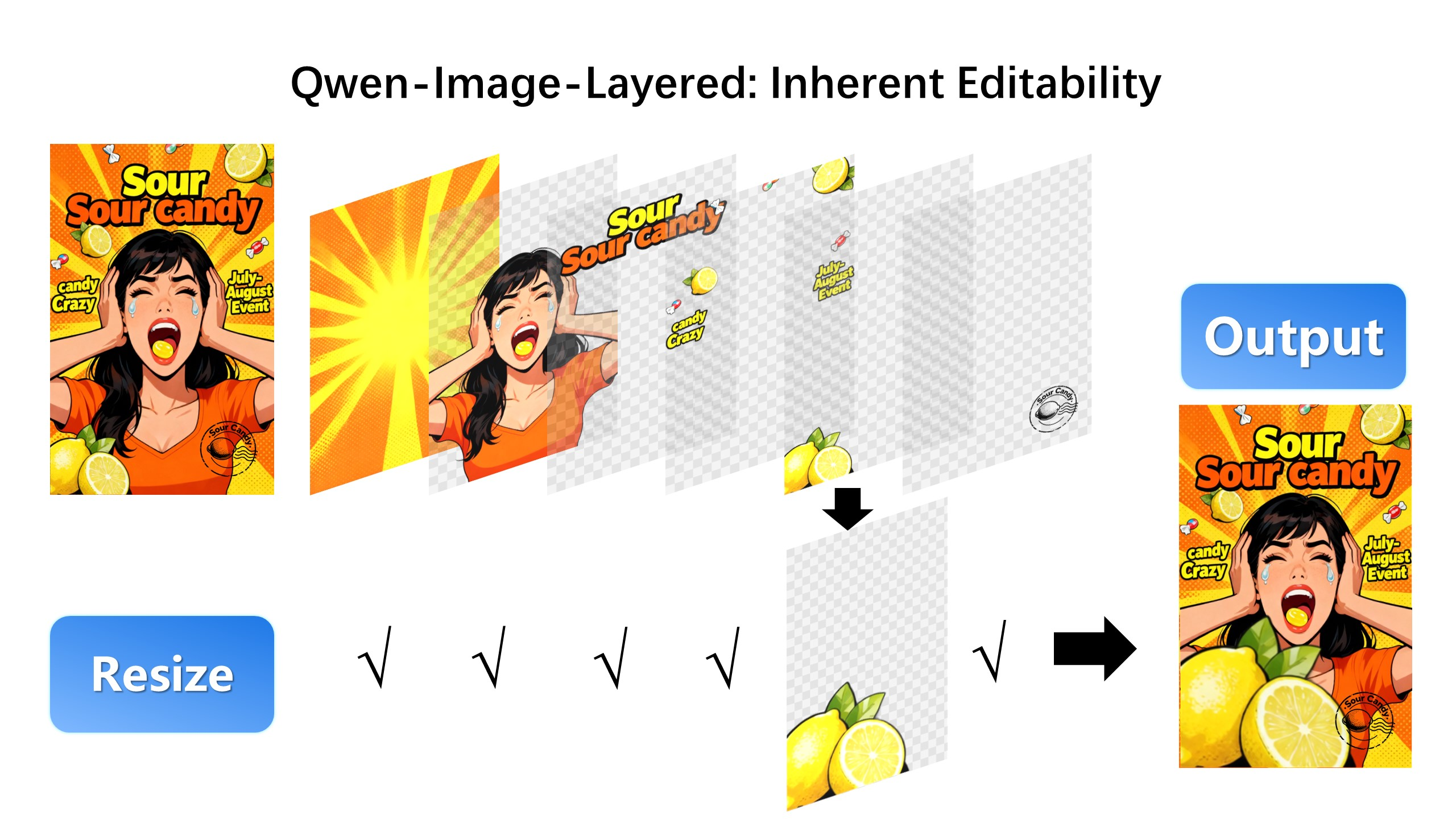
resize尺寸:
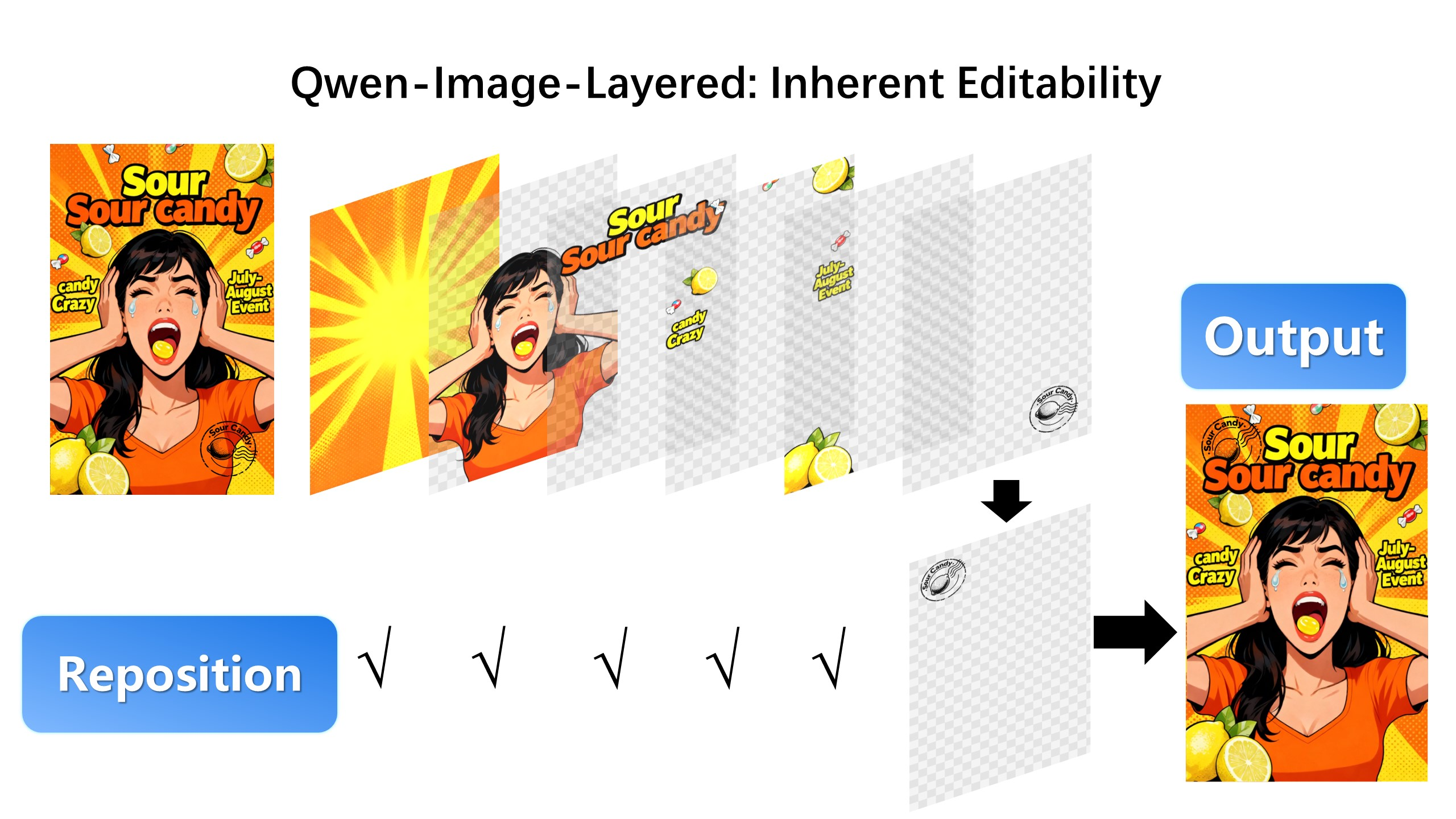
移动obj:
自定义分层数+further decomposition
仓库结构
Qwen-Image-Layered/
├── LICENSE # Apache License 2.0 许可证
├── README.md # 项目说明、快速开始及使用指南
├── assets/
│ └── test_images/ # 测试用例图像
└── src/
├── app.py # 启动图像分解与PPTX导出的Gradio界面
└── tool/
└── edit_rgba_image.py # 启动图层编辑的Gradio界面关键特性
- 分层表示优势:通过物理隔离图层,从根本上保证编辑的一致性(如修改某图层颜色时不影响其他内容)。
- 支持基础操作:天然适配缩放、重定位、删除等基础编辑操作,且不易失真。
- 文本提示辅助:可通过文本描述图像整体内容(包括被遮挡元素)辅助分解,但不直接控制单个图层的语义。
- 模型限制:当前权重主要优化"图像到多RGBA图层分解"任务,"文本到多RGBA图层生成"性能有限。
使用方式
-
环境准备:
-
需安装
transformers>=4.51.3(支持 Qwen2.5-VL) -
安装最新版
diffusers和python-pptx:bashpip install git+https://github.com/huggingface/diffusers pip install python-pptx
-
-
快速开始(代码示例):
pythonfrom diffusers import QwenImageLayeredPipeline import torch from PIL import Image pipeline = QwenImageLayeredPipeline.from_pretrained("Qwen/Qwen-Image-Layered") pipeline = pipeline.to("cuda", torch.bfloat16) image = Image.open("assets/test_images/1.png").convert("RGBA") inputs = { "image": image, "generator": torch.Generator(device='cuda').manual_seed(777), "true_cfg_scale": 4.0, "negative_prompt": " ", "num_inference_steps": 50, "layers": 4, "resolution": 640, "cfg_normalize": True, "use_en_prompt": True, } with torch.inference_mode(): output = pipeline(** inputs) for i, layer in enumerate(output.images[0]): layer.save(f"layer_{i}.png") # 保存分解后的图层 -
可视化界面部署:
-
启动图像分解与 PPTX 导出界面:
bashpython src/app.py -
启动图层编辑界面(基于 Qwen-Image-Edit):
bashpython src/tool/edit_rgba_image.py
-
许可证
项目采用 Apache License 2.0,允许自由使用、复制、修改和分发,但需保留原始版权信息和许可证说明。
更多细节可参考仓库的 Research Paper、Blog 或 Demo。
