R 语言是一种专为统计计算、数据分析和图形可视化而设计的编程语言,在学术界和工业界都备受青睐。RStudio是一款为 R 语言量身打造的集成开发环境(IDE)。它如同一个功能强大的指挥中心,能够将数据科学工作所需的一切:控制台、脚本编辑器、环境窗口、文件管理、包管理、帮助文档和绘图窗口等集成在一个界面中,极大地提升了编程与数据分析的效率和体验。
OpenBayes 平台现已内置了 RStudio 软件镜像,今天给大家介绍一下如何在 OpenBayes 平台使用 RStudio 进行高性能计算的入门操作,本教程导入了模拟心理学上一个比较常用的量表抑郁量表的测评数据进行分析演示。
新用户使用下方邀请链接注册,可获得 4 小时 RTX 4090 + 5 小时 CPU 的免费时长!
小贝总专属邀请链接(直接复制到浏览器打开):
go.openbayes.com/9S6Dr
一、工具准备
- 创建容器
首先进入「高性能计算」页面,点击「创建新容器」。
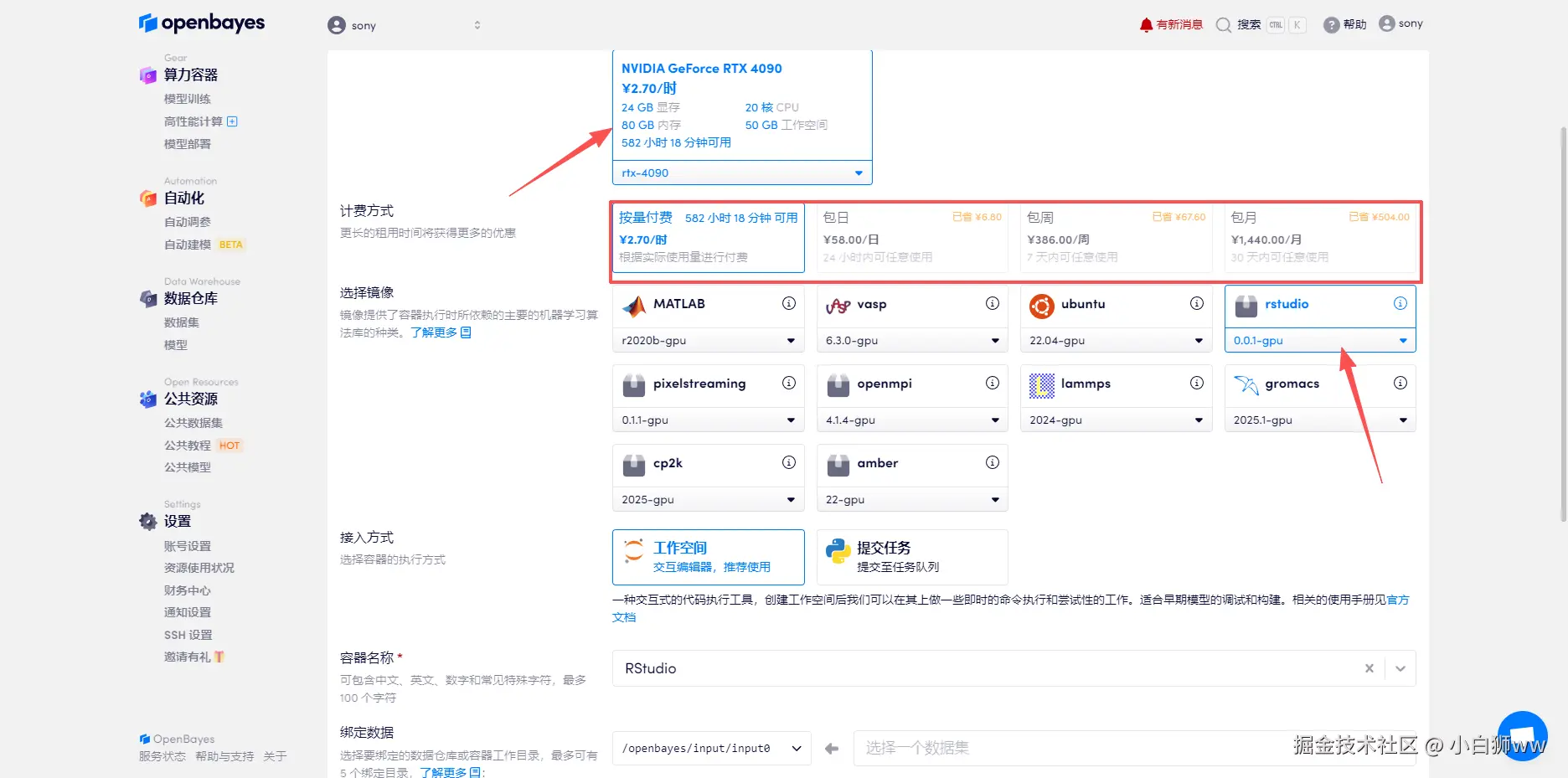
创建容器页面,选择和填写容器信息。然后点击「执行」
- 算力选择:默认为 RTX 4090;
- 计费方式:默认为「按量付费」。还可以选择包日/月/周。免费资源(邀请链接会写在简介中):使用视频下方邀请链接可以获得 4 小时 RTX 4090 和 5 小时 CPU。
- 镜像选择:已经内置了一些高性能计算所需软件,可以在研究范围内直接使用。这里我们要使用 R 软件进行数据分析,所以选「rstudio」。
- 容器名称:按照要求填写即可
2. 进入 R studio Server
待系统分配好资源,当状态变为「运行中」后,点击「打开工作空间」。
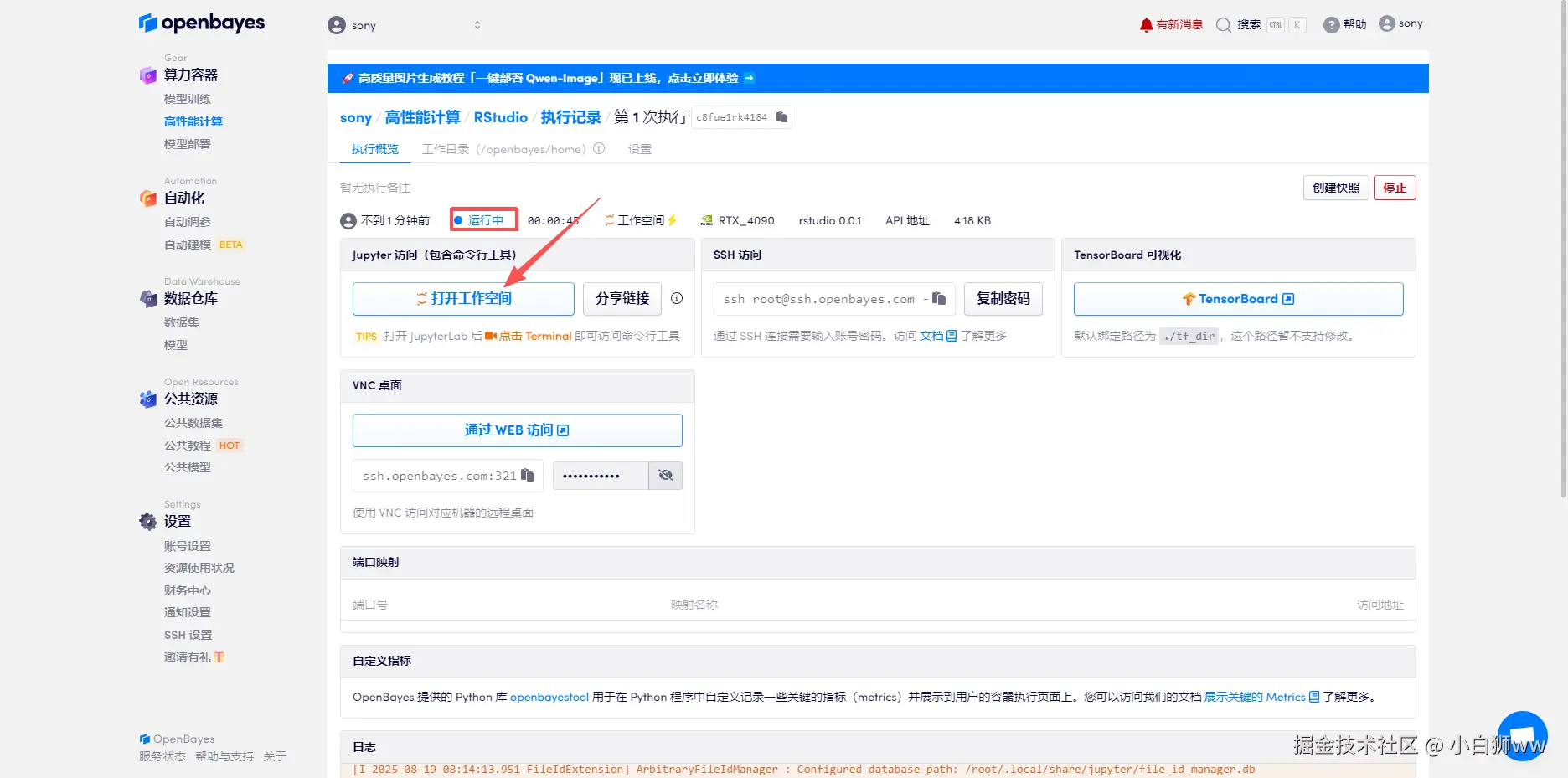
进入到工作空间后,在页面右边,点击「API 地址」打开(先要进行支付宝实名认证),默认用户名和密码都是 rstudio,填写正确后,即可进入了 Rstudio Server 的界面。
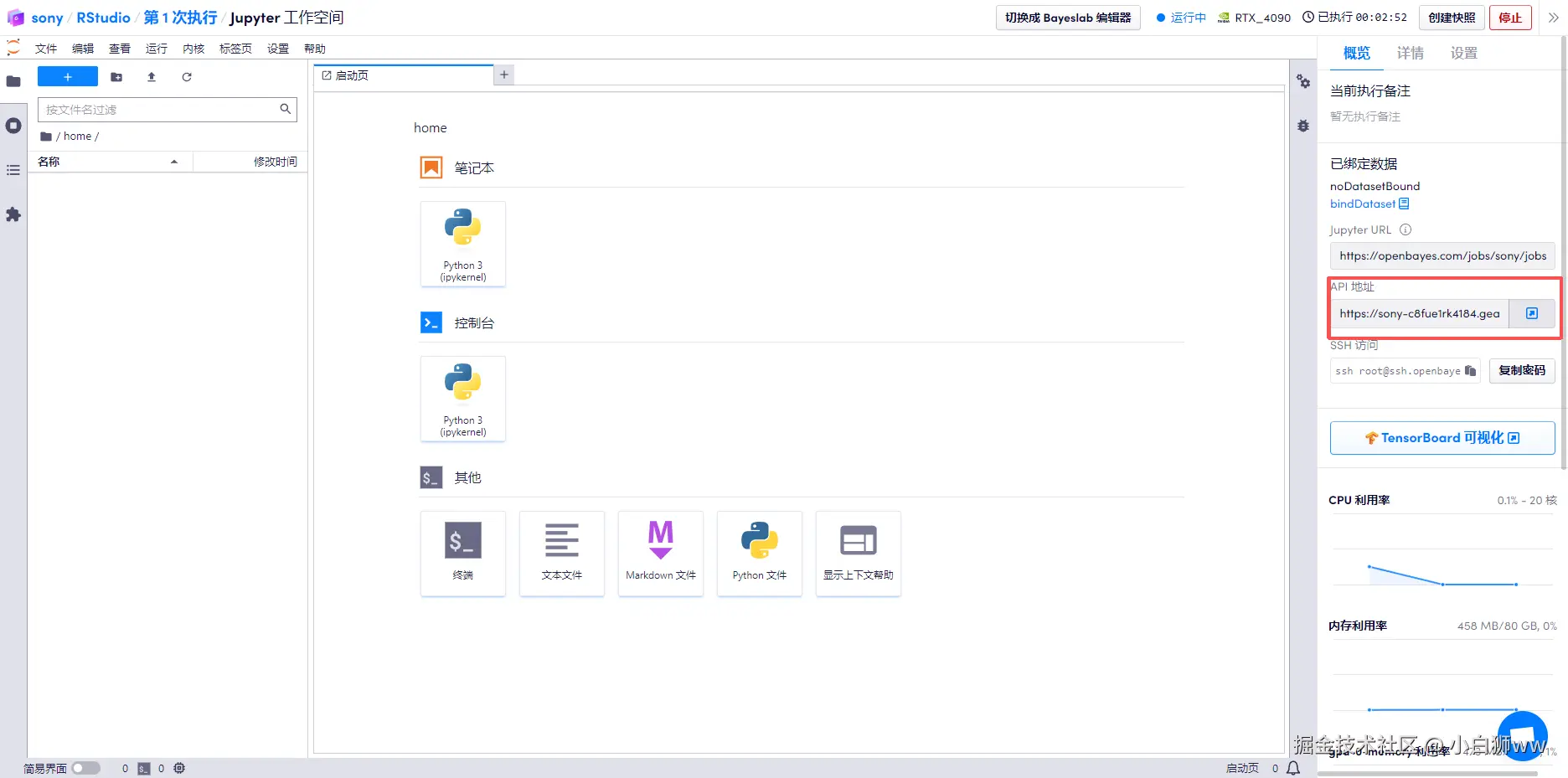
3. 设置 RStudio 工作目录
进入到 Rstudio Server 页面后,可以发现跟我们本地安装使用的 Rstudio 是一样的。而唯一不同的是工作目录。
输入以下命令查看当前工作目录,为:/home/rstudio
scss
getwd() 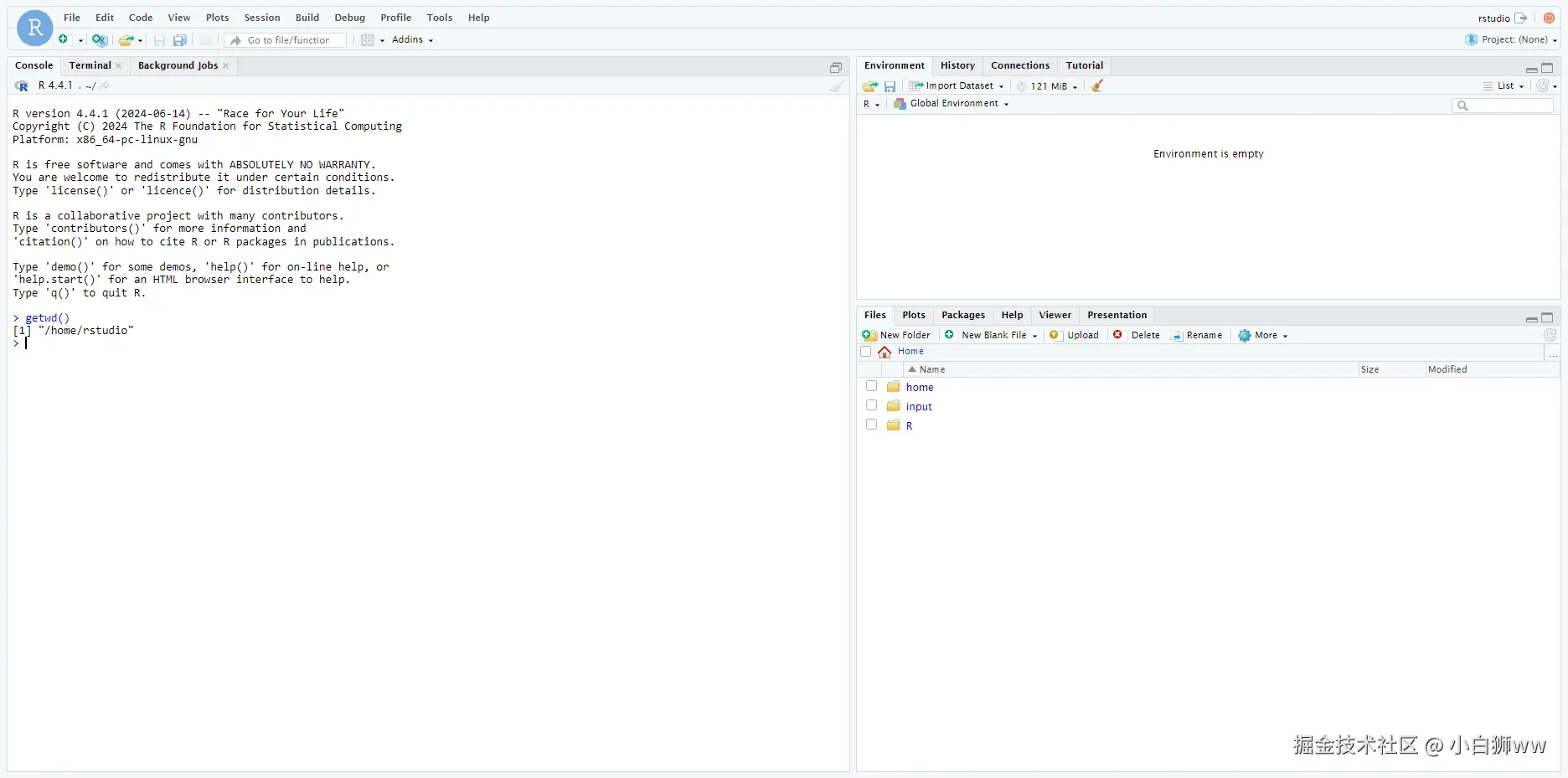
为了方便数据分析,我们可输入以下命令将 rstudio 当前工作目录变更为「/home」,在 home 目录下新增 data 文件夹和 output 文件夹,将原始数据、输出结果及源代码文件均存放在 home 文件夹中。
scss
setwd("~/home")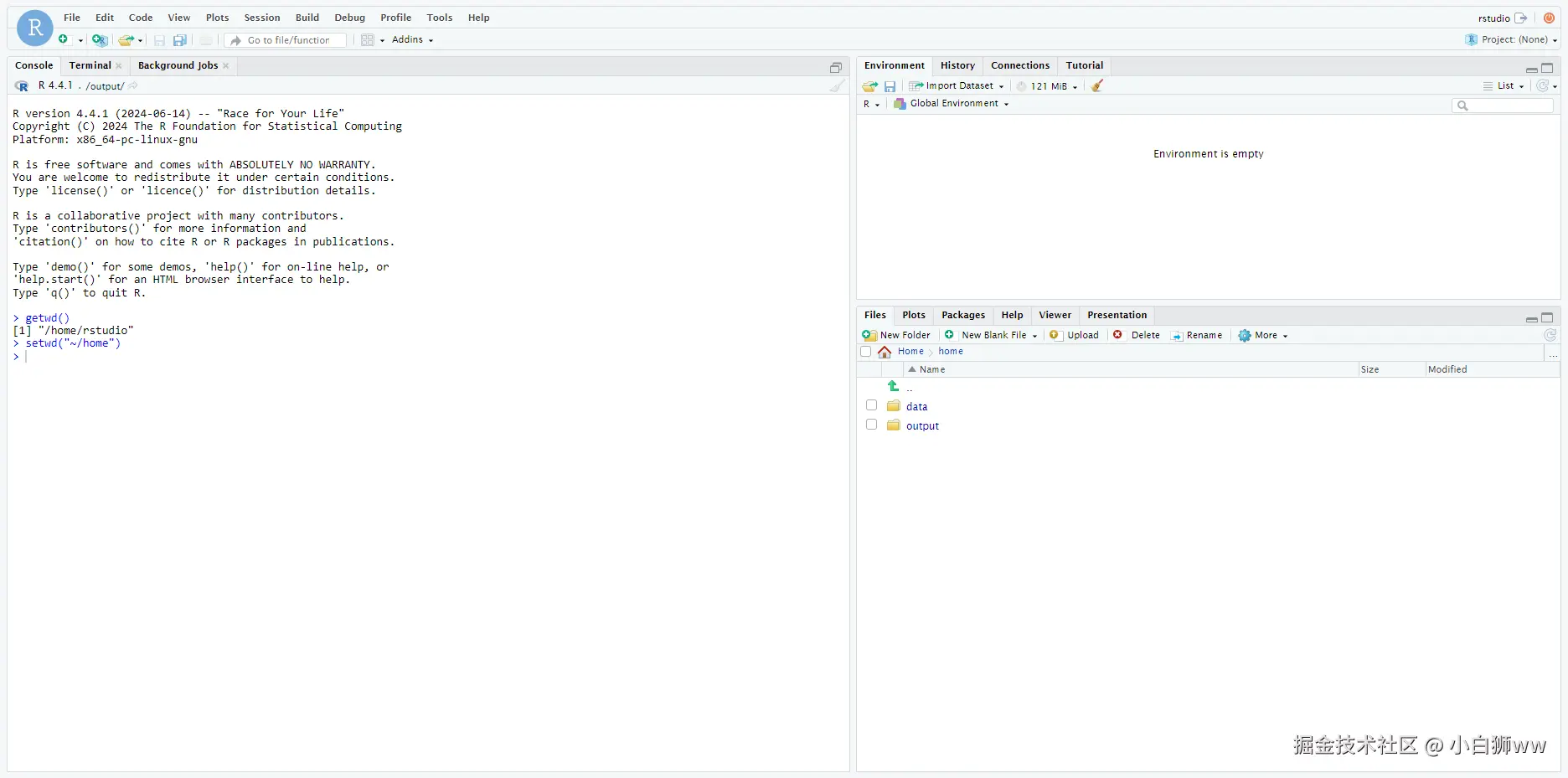
二、数据准备
将准备好的 Excel 数据文件,上传至当前工作目录下。本教程使用的数据集为「PHQ 心理学抑郁量表的测评数据」,是模拟心理学上一个比较常用的量表抑郁量表的测评数据。
获取数据集:go.openbayes.com/6uF7Y
运行以下命令读取准备好的 PHQ.xlsx 中的第 2 个 sheet。
scss
library(readxl)
df <- read_excel("~/home/data/PHQ.xlsx",1)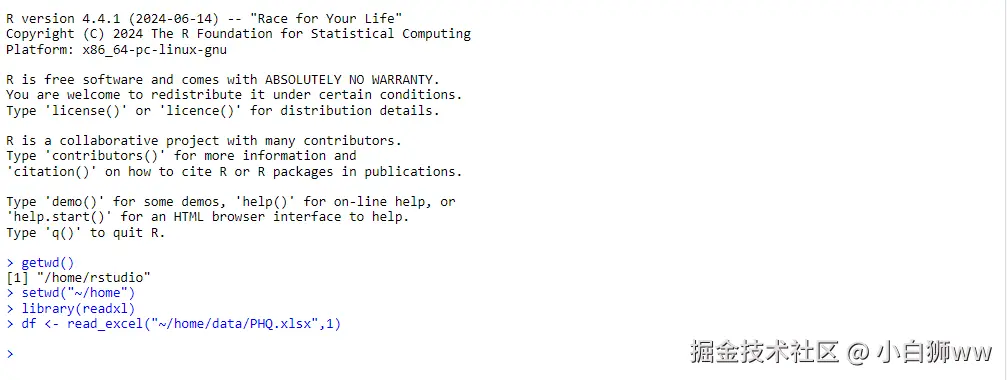
读取完成后在运行以下代码,读取它的前五行。
bash
head(df)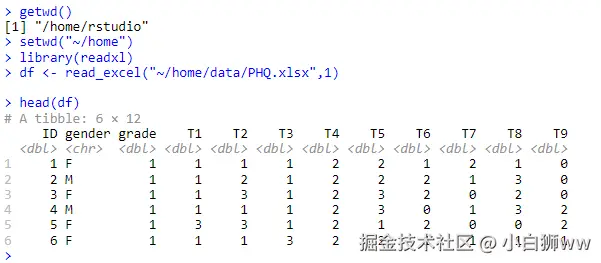
对数据进行初步预处理,核查:第一,数据类型;第二,分类因子化;第三,是否有缺失值。
分类因子化:
bash
factor(df$gender,ordered = TRUE)
factor(df$grade,ordered = TRUE)数据类型:
bash
str(df) #确认各列数据的类型查看是否有缺失值:
bash
sum(is.na(df))#查看是否有缺失值
na.omit(df)#如果有缺失值,删除缺失值
三、数据分析
- 计算量表总分
输入以下命令对 4---12 列按行求和。
bash
df$phq <- apply(df[c(4:12)],1,sum)
head(df)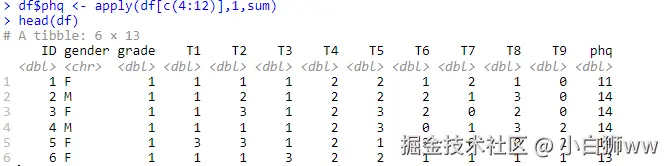
得到计算结果后要对分数进行划分,这里 PHQ 量表的划分标准为:1-4 分正常,5-9 分轻度抑郁,10-14 分中度抑郁,15-19 分中重度抑郁,20-27 分重度抑郁。输入以下命令,模型即可按照标准划分。
bash
df$level <- cut(df$phq,c(0,4,9,14,19,27),labels = c("正常","轻","中","中重","重"))
df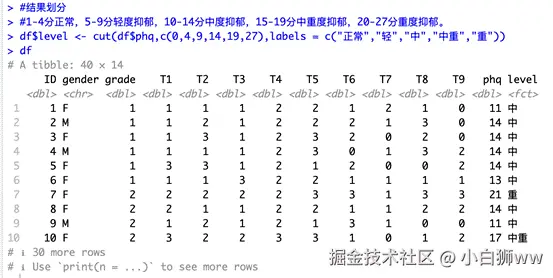
得到划分结果后,要对数据进行描述统计。首先需要安装「psych」,输入以下命令进行安装。
scss
library(psych)安装完成后输入以下命令加载「psych」。
arduino
phqdescri <- psych::describe(df)
phqdescri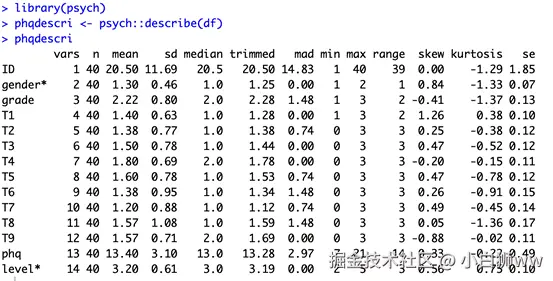
2. 不同得分等级的数量汇总分析
输入以下命令,对不同的分等级的数量进行汇总。
bash
levelphq <- table(df$level) #各等级的数量
levelphq然后输入以下命令,按年级和性别分类汇总不同等级下的数量分布。
scss
genderlevel <- df l>
subset(select=c(gender,level))l>
table()l> addmargins() #不同性别抑郁等级分布情况
genderlavel
genderlevel <- df l>
subset(select=c(gender,level))l>
table()l> addmargins() #不同年级抑郁等级分布情况
genderlavel
3. 计算得分均值
利用「psych」包中的「describeBy」函数计算得分均值,输入以下命令即可开始计算。
bash
henderDescri <-psych::describeBy(df[c("phq")],
list(df$gender))#不同性别得分差异
genderDescri
henderDescri <-psych::describeBy(df[c("phq")],
list(df$gende))#不同年级得分差异
genderDescri
4. 信度分析
运行以下命令,利用「psych」包中的「alpha」函数进行信度分析。
scss
#信度分析
library(psych)
phqr <-alpha(df[,c(4:12)])
phqr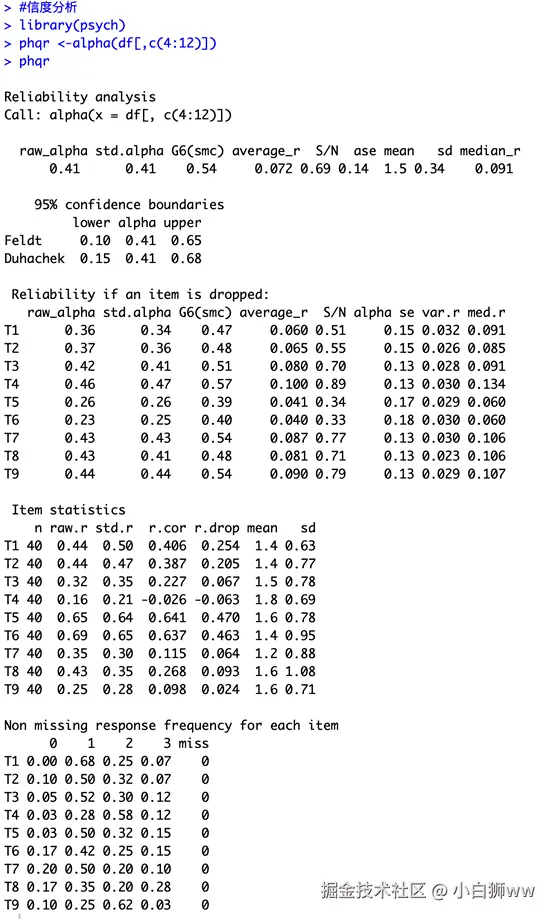
5. 计算量表信度
利用「psych」包中的「corr」函数可以进行题总相关的信度分析。
bash
rr <- corr.test(df[,c(4:12)],df$phq)
rr$r #提取相关系数
bash
rr$p #提取p值
scss
resultphq <- round(rr$p,3)#保存结果,设置小数点后位数为3位
conlnames(result) <- c("phq")#修改结果中的列表为phq
resultphq
四、报告保存
保存结果需要用到「writexl」包,运行以下命令安装。
arduino
install.packages("writexl")
安装完成之后,输入以下命令加载。
scss
library(writexl)我们在上述分析时,每一步分析都会把分析结果保存,命名为一个名称。然后把这些命名的对象创建成一个列表 list。用 sink 函数在目录中创建「output」文件夹。将分析结果保存到该文件夹下。
scss
result_list <- list(df,phgdescri,genderDescri,gradeDescri,levelphg,genderlevel,gradelevel ,phqr,resultphq)
sink("~/home/output/outout.txt")
print(result_list)
sink()
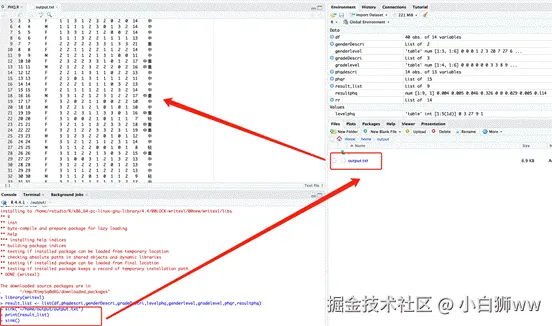
最后可以返回控制台界面查看输出文件。