Google Bigtable深度解析:分布式存储的设计典范
Google Bigtable 作为分布式结构化数据存储的里程碑技术,其设计理念深刻影响了 HBase、Cassandra 等开源分布式数据库。Bigtable 以高扩展性、高可用性和灵活的数据模型为核心,通过双层架构(GFS 持久化 + 分布式索引)支撑 PB 级数据存储与高效访问。本文将从数据模型、系统架构、核心组件及技术特点等方面全面解析 Bigtable,揭示其成为分布式存储标杆的底层逻辑。
Bigtable 核心定位与设计目标
Bigtable 是 Google 为解决大规模结构化数据存储问题开发的分布式数据库,主要目标包括:
- 高扩展性:支持从 TB 到 PB 级数据的无缝扩展,单表可容纳数万亿行数据;
- 高可用性:通过多副本、故障自动恢复等机制,确保数据不丢失且服务持续可用;
- 灵活的数据模型:支持半结构化数据存储,适应多样化的应用场景(如搜索索引、日志存储、用户数据);
- 高效读写:优化随机读写性能,支持按行键范围的批量操作。
Bigtable 数据模型:灵活的三维有序映射
Bigtable 的数据模型不同于传统关系型数据库,它是一种 稀疏的、分布式的、持久化的多维有序映射,核心结构可表示为:
plaintext
(row:string, column:string, timestamp:int64) → string 核心概念解析
- 行(Row)
- 每行通过 Row Key(行键) 唯一标识,按字典序全局排序,这是 Bigtable 高效范围查询的基础;
- 行的读写操作是 原子性的(无论操作涉及多少列),适合存储实体的完整信息(如一个用户的所有属性)。
- 列(Column)
- 列名由 列族(Column Family) 和 限定符(Qualifier) 组成,格式为
family:qualifier(如user:name、log:error); - 列族 是访问控制、存储和压缩的基本单元,需在表创建时预先定义,数量不宜过多(通常不超过数百个);
- 限定符 无需预先定义,可动态添加,使数据模型具备极强的灵活性(如
user:email、user:phone可随时扩展)。
- 列名由 列族(Column Family) 和 限定符(Qualifier) 组成,格式为
- 时间戳(Timestamp)
- 每个单元格(Cell)可存储多个版本的数据,通过时间戳区分(默认精确到毫秒);
- 版本管理策略可自定义(如保留最近 N 个版本、保留指定时间范围内的版本),适合存储历史数据(如用户操作日志的变更记录)。
- 单元格(Cell)
- 由
(Row Key, Column, Timestamp)唯一标识的最小数据单元,存储的值为字符串(二进制安全,可存储任意数据)。
- 由
数据模型示例
以存储用户行为日志为例,Bigtable 的数据结构如下:
| Row Key(用户 ID) | Column: log:login(登录日志) |
Column: log:action(操作日志) |
|---|---|---|
user_001 |
t1: "2023-10-01 08:00" |
t1: "view_page" |
t2: "2023-10-02 09:30" |
t2: "click_button" |
|
user_002 |
t1: "2023-10-01 10:15" |
t1: "submit_form" |
Bigtable 系统架构:分层设计与核心组件
Bigtable 采用 分层架构 ,底层依赖 Google 其他基础设施,上层通过分布式服务实现数据的存储与管理。整体架构可分为 客户端层 、主控服务器(Master) 、子表服务器(Tablet Server) 三大核心组件,依赖 GFS(持久化存储)和 Chubby(分布式锁服务)提供基础支撑。
架构总览
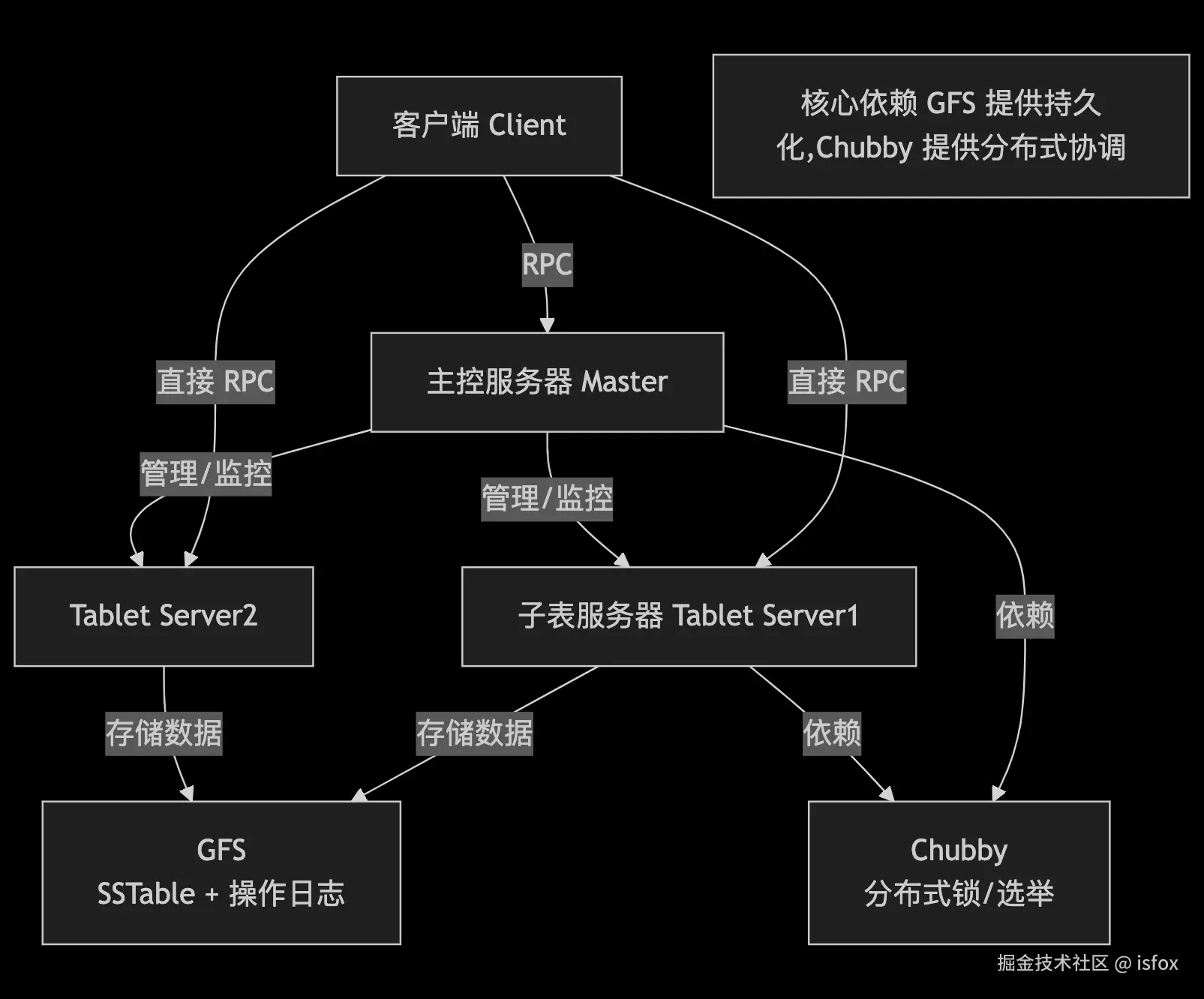
核心组件详解
1. 客户端(Client)
- 提供应用程序访问 Bigtable 的接口(如读写 API);
- 维护 子表位置缓存,直接与子表服务器通信(减少 Master 压力);
- 若缓存失效,通过查询根表和元数据表获取子表位置。
2. 主控服务器(Master)
Master 是 Bigtable 的 "管理者",主要负责 元数据管理 和 集群调度,不直接参与数据读写:
- 子表分配:将子表(Tablet)分配给子表服务器(Tablet Server);
- 负载均衡:监控子表服务器负载,实现子表的均衡分布;
- 故障恢复:检测子表服务器故障,将其管理的子表重新分配给其他服务器;
- 子表合并 / 分裂:指导子表服务器执行子表的分裂(数据量过大时)和合并(数据量过小时);
- 元数据维护:管理用户表的创建、删除、列族修改等元数据操作。
3. 子表服务器(Tablet Server)
子表服务器是数据读写的 "执行者",每个服务器管理多个子表(Tablet):
- 子表管理:加载 / 卸载子表,处理子表的分裂与合并;
- 数据读写:接收客户端的读写请求,操作子表数据(读取 SSTable、写入操作日志);
- 数据持久化:将内存中的数据(MemTable)定期刷写到 GFS 中的 SSTable 文件;
- 日志管理:所有写操作先记录到操作日志(WAL),再更新内存中的 MemTable,确保数据可靠性。
4. 底层依赖服务
- GFS(Google 文件系统):Bigtable 的持久化存储层,存储 SSTable 数据文件和操作日志,提供高容错的分布式存储;
- Chubby :分布式锁服务,用于:
- Master 选举(确保只有一个活跃 Master);
- 存储根表位置、子表服务器信息等全局元数据;
- 实现分布式锁,防止并发操作冲突。
子表(Tablet):数据分片的基本单位
Bigtable 将大表按 Row Key 范围 分裂为多个连续的子表(Tablet),每个子表是数据管理的基本单位:
- 初始状态下,一个表对应一个子表;
- 当子表数据量超过阈值(通常 100-200MB),自动分裂为两个子表;
- 子表可在子表服务器之间迁移,实现负载均衡。
三级元数据结构
Bigtable 通过 三级元数据 定位子表位置,类似文件系统的目录结构:
- 根表(Root Tablet):整个元数据结构的 "根",存储元数据表的元数据,是一个特殊的子表,永不分裂;
- 元数据表(Meta Table):存储所有用户表的子表元数据(如子表的 Row Key 范围、所在服务器);
- 用户表(User Table):存储实际业务数据,按 Row Key 分裂为多个子表。
定位流程:客户端 → 根表 → 元数据表 → 目标子表 → 子表服务器。
Bigtable 数据存储与读写流程
Bigtable 的数据存储依赖 内存结构(MemTable) 和 持久化文件(SSTable),结合操作日志(Write-Ahead Log)确保数据可靠性。
数据存储结构
- MemTable:内存中的有序映射表,接收新写入的数据(未持久化);
- SSTable:磁盘上的持久化文件(存储在 GFS),数据按 Row Key 排序,支持高效查询;
- 操作日志(Commit Log):所有写操作先写入日志,再更新 MemTable,防止内存数据丢失。
写操作流程
- 客户端通过元数据定位目标子表所在的子表服务器;
- 子表服务器将写操作记录到 操作日志(GFS 中,确保持久化);
- 更新内存中的 MemTable(有序数据结构);
- 当 MemTable 达到阈值,异步刷写到 GFS 生成 SSTable 文件。
读操作流程
- 客户端定位目标子表服务器;
- 子表服务器从 MemTable 和 SSTable 中读取数据(合并多版本数据);
- 返回最新版本的数据(按时间戳筛选)给客户端。
Bigtable 核心技术特点
- 高扩展性 通过子表分裂和动态负载均衡,支持集群规模线性扩展,单集群可容纳数万节点。
- 高可用性
- 数据多副本存储(依赖 GFS 的多副本机制);
- 子表服务器故障后,Master 自动将子表迁移到其他服务器;
- 操作日志确保内存数据不丢失。
- 高效读写
- 按 Row Key 排序的存储结构,支持高效的范围查询;
- 内存 MemTable 优化写入性能,SSTable 优化读取性能;
- 局部性原理:Row Key 相近的数据存储在同一子表,减少访问延迟。
- 灵活的数据模型
- 无需预定义表结构(列限定符可动态添加);
- 支持多版本数据,适应历史数据查询场景;
- 列族级别的访问控制和压缩策略,优化存储效率。
Bigtable 与 HBase 的渊源
Bigtable 是 HBase 的 "灵感来源",HBase 作为开源实现,几乎完全借鉴了 Bigtable 的设计理念:
| 特性 | Google Bigtable | HBase |
|---|---|---|
| 底层存储 | GFS | HDFS(模仿 GFS) |
| 分布式协调 | Chubby | ZooKeeper(模仿 Chubby) |
| 数据模型 | 三维映射(行键、列、时间戳) | 完全沿用 Bigtable 数据模型 |
| 元数据结构 | 根表 → 元数据表 → 用户表 | 完全沿用三级元数据结构 |
| 核心组件 | Master + Tablet Server | HMaster + RegionServer |
| 数据分片单位 | Tablet | Region(对应 Tablet) |
参考文献