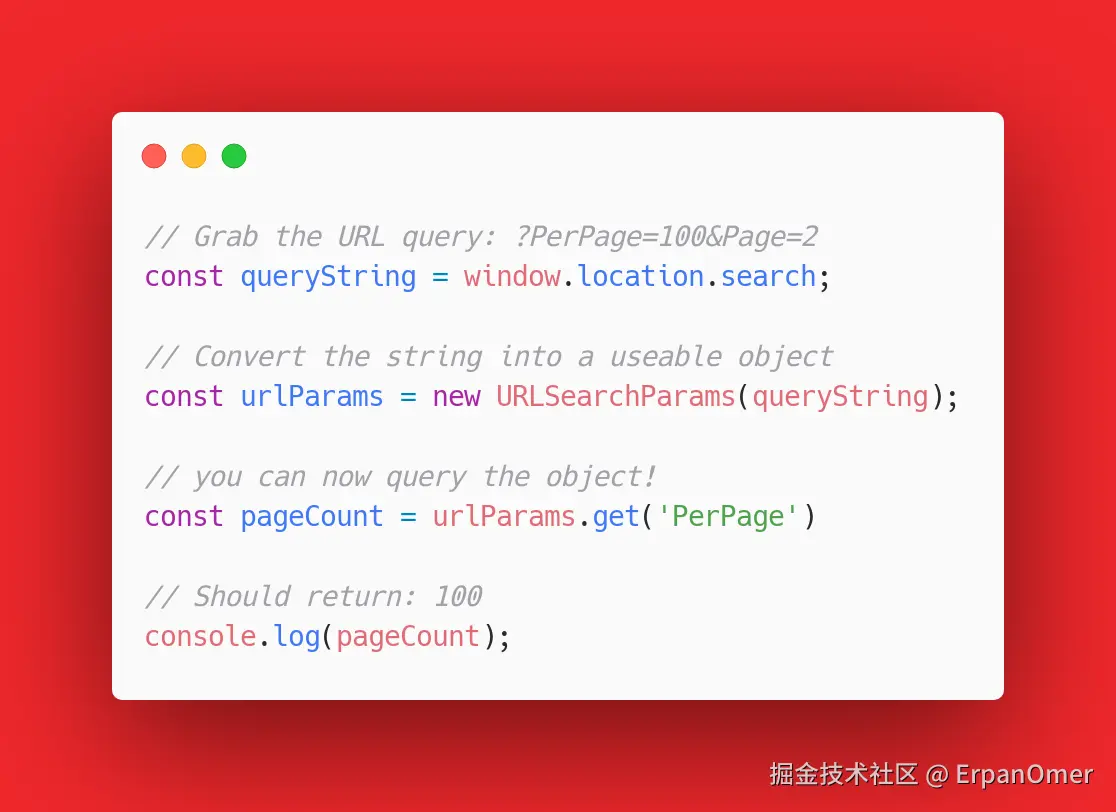
我在Code Review里最怕看到的代码之一,就是手写正则去解析URL参数。
每次看到类似下面这样的代码,我的血压就忍不住要升高:
JavaScript
// 一个试图从URL里获取'id'参数的函数
function getIdFromUrl(url) {
const match = url.match(/[?&]id=([^&]*)/);
return match ? match[1] : null;
}或者这种split链式调用:
JavaScript
const url = 'https://example.com?a=1&b=2';
const paramsStr = url.split('?')[1];
// ...然后再对paramsStr按'&'和'='去分割...这段代码,乍一看好像能用。但作为工程师,我们得考虑边界情况:
它能处理URL编码的字符吗?(比如name=%E5%BC%A0%E4%B8%89)。 它能处理同一个参数出现多次的情况吗?(比如tags=js&tags=css)。 如果参数在hash后面,它能正确处理吗?。
答案是,都不能。手写正则和split来处理URL,是一种极其脆弱和危险的写法。
其实,浏览器早就给我们提供了一套官方的、功能强大且极其健壮的工具来处理URL,那就是URL和URLSearchParams这两个Web API。今天,我就想彻底聊聊它们。
URL对象:URL的结构化表示
别再把URL当成一个简单的字符串了。我们可以用new URL()构造函数,把它变成一个清晰、易于操作的结构化对象。
JavaScript
const urlString = 'https://juejin.cn/user/12345/posts?type=hot&page=2#comments';
// 传入一个URL字符串,或者一个相对路径 + base URL
const myUrl = new URL(urlString);
console.log(myUrl);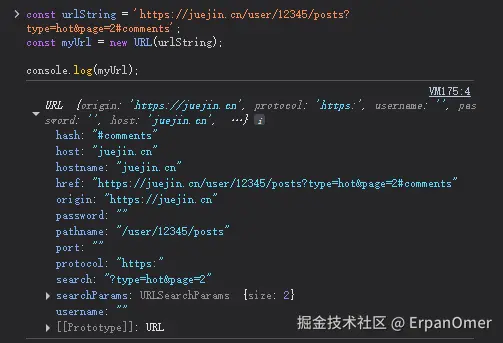
一旦你把它变成了URL对象,获取它的各个部分就变得极其简单:
JavaScript
console.log(myUrl.protocol); // "https:"
console.log(myUrl.hostname); // "juejin.cn"
console.log(myUrl.port); // "" (因为URL中没有指定)
console.log(myUrl.pathname); // "/user/12345/posts"
console.log(myUrl.search); // "?type=hot&page=2"
console.log(myUrl.hash); // "#comments"它不仅能读,还能写。修改URL的任何一部分,都像修改一个普通的JS对象属性一样简单:
JavaScript
myUrl.pathname = '/user/98765/articles';
myUrl.hash = '#profile';
myUrl.port = '8080';
// .href 属性会返回拼接好的完整URL字符串
console.log(myUrl.href);
// "https://juejin.cn:8080/user/98765/articles?type=hot&page=2#profile"看到没?所有部分都被清晰地解析出来了,你可以像操作普通JS对象一样去读写,完全不用担心拼接字符串时漏掉/或者?。
URLSearchParams:查询参数的进价用法
URL对象本身已经很强大了,而它里面还藏着一个宝藏属性:myUrl.searchParams。
这个searchParams就是一个URLSearchParams的实例,它专门用来处理?key=value&key2=value2这部分。我们也可以单独创建它。
JavaScript
const paramsString = 'type=hot&category=frontend&tags=react&tags=vue';
const searchParams = new URLSearchParams(paramsString);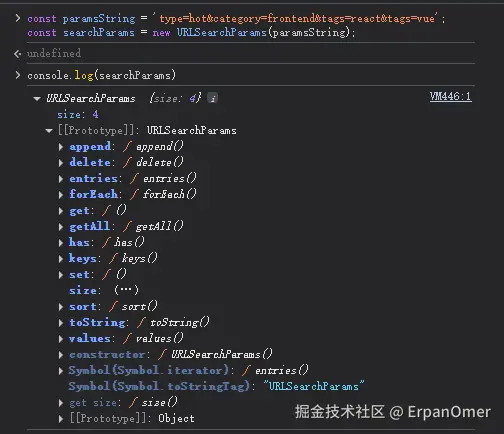
有了它,所有关于查询参数的操作,都有了清晰、标准的方法:
1. 读取参数 (.get())
JavaScript
console.log(searchParams.get('type')); // "hot"
console.log(searchParams.get('nonexistent')); // null2. 检查参数是否存在 (.has())
JavaScript
console.log(searchParams.has('category')); // true3. 处理同名参数 (.getAll())
这是手写正则最头疼的地方。URLSearchParams能完美处理。
JavaScript
console.log(searchParams.getAll('tags')); // ["react", "vue"]4. 修改与添加参数 (.set() & .append())
JavaScript
// .set() 会覆盖已有的值
searchParams.set('type', 'new');
// .append() 会在已有的值后面追加,而不会覆盖
searchParams.append('tags', 'css');5. 删除参数 (.delete())
JavaScript
searchParams.delete('category');6. 迭代参数 (.forEach() 或 for...of)
JavaScript
for (const [key, value] of searchParams) {
console.log(`${key}: ${value}`);
}7. 转换回字符串 (.toString())
这是最重要的一步。它会自动帮你处理好URL编码。
JavaScript
// 假设我们添加一个带中文的参数
searchParams.set('author', '张三');
console.log(searchParams.toString());
// "type=new&tags=react&tags=vue&tags=css&author=%E5%BC%A0%E4%B8%89"看到%E5%BC%A0%E4%B8%89了吗?它自动帮你把"张三"给URL编码了。这一切,如果你用正则去实现,代码量至少多五倍,而且还全是bug。
一个常用场景:列表页的筛选功能
我们来看一个在日常工作中100%会遇到的场景:一个列表页,用户可以通过下拉框来筛选和排序,然后我们需要更新URL,并根据新的URL去重新请求数据。
JavaScript
function updateUrlAndFetchData() {
// 1. 从当前URL,或者一个基础URL,创建一个URL对象
const currentUrl = new URL(window.location.href);
// 2. 直接操作它的 searchParams 属性
const category = document.getElementById('category-select').value;
currentUrl.searchParams.set('category', category);
const sortBy = document.getElementById('sort-select').value;
currentUrl.searchParams.set('sort', sortBy);
// 3. 得到新的、完整的URL字符串
const newUrl = currentUrl.href;
// 4. 你可以用它来更新浏览器历史记录,或者发起请求
history.pushState({}, '', newUrl);
fetchData(newUrl); // 假设这是一个请求函数
console.log('Updated URL:', newUrl);
}整个过程,我们没有做任何一次字符串拼接或正则匹配,代码清晰、健壮,而且完全不用担心特殊字符的编码问题。这就是现代API的威力。
作为组长,我在Code Review里推行的一个原则就是:永远选择更明确、更健壮的写法。
手写正则去处理URL,是一种炫技式的、脆弱的写法,未来的同事(很可能就是几个月后的你自己)看到后,需要花很长时间去理解和维护。
而使用URL和URLSearchParams,是一种利用平台能力、为未来维护者着想的、专业的写法。
所以,下次再遇到URL相关的需求,请忘了split()和正则表达式吧。new URL() 和 new URLSearchParams(),应该是你的第一选择。
分享完毕,谢谢大家😀