为了熟悉 Azure Databricks ,最近在Azure平台上进行了数据分析、机器学习、ETL 处理以及 Delta Lake 操作的动手实践。
一、环境准备:工作区、集群与 Notebook
要开始使用 Azure Databricks,首先需要准备工作区、配置计算集群,并掌握 Notebook 的使用方法。
1. 创建 Azure Databricks 工作区
在使用 Azure Databricks 之前,需要在 Azure 上创建一个 Databricks 工作区。工作区是 Azure Databricks 部署的交互式环境,用于组织管理集群、Notebook 等资源。通常通过 Azure 门户创建工作区:
Azure 门户创建:登录 Azure 门户,在"创建资源"中搜索 Azure Databricks 服务并创建工作区。选择订阅、资源组、工作区名称、地区以及定价层(标准或高级)等配置,然后点击创建。几分钟后,工作区将部署完毕。
访问工作区:在 Azure 门户的 Databricks 工作区资源页,点击"启动工作区"打开 Databricks Web 界面。首次打开时,可能会提示登录 Databricks。
2. 配置并启动集群
工作区创建后,需要新建一个 Spark 集群来提供计算资源。集群是由一个驱动节点和多个工作节点组成的分布式计算资源,用于执行 Notebook 代码和作业任务。在 Azure Databricks 中,可以通过用户界面、CLI 或 API 创建集群。以下是配置集群的步骤和注意事项:
集群类型:Azure Databricks 提供通用集群(All-Purpose)和作业集群两种类型。通用集群是交互式的,可供多个用户共享用于数据探索分析;作业集群通常由调度的作业临时创建,任务完成后终止。一般日常开发使用通用集群,定时 Job 可使用作业集群以降低成本。
集群模式:创建集群时,可选择模式:标准模式(Single User)、高并发模式(支持多用户并发,具有笔记本隔离和公平调度)以及单节点模式(无工作节点,仅驱动节点运行)。通常标准模式适合个人开发,高并发集群适合多用户共享,而单节点模式常用于小规模测试或需要确保所有计算在单机完成的情况。
Databricks Runtime 版本:选择 Databricks Runtime(包括 Spark 版本)。对于机器学习任务,Databricks 提供带有预装机器学习库的 Runtime for ML 版本,可加速环境准备。确保选择合适的 Scala/Spark 版本以及是否需要 GPU 支持等。
节点类型和规模:根据数据量和工作负载选择 CPU/内存规格的虚拟机作为节点类型。可以启用弹性自动扩展,设定最小和最大工作节点数,Spark 会根据作业负载自动增加或减少节点,从而在保证性能的同时节约资源成本。
自动终止:为避免长时间空闲浪费资源,可设置集群闲置一定时长后自动终止(例如 20 分钟)。
创建集群:在 Databricks 工作区左侧边栏点击"(+)创建"并选择"集群",填写名称并按上述配置选项进行设置,最后点击创建。等待片刻集群即可启动完成。
集群治理提示:管理员可以通过集群策略限制集群配置以控制成本和规范。例如限制最大节点数或指定特定实例类型等。Databricks 还支持集群池来重用虚拟机以加快启动速度、降低开销,这是进阶优化功能,此处不展开。
3. 创建并使用 Notebook
Notebook 是 Azure Databricks 中进行交互式数据科学、开发机器学习工作流的主要工具。Databricks 笔记本支持多人实时协作、自动版本控制,并内置数据可视化功能。使用 Notebook 的基本步骤:
新建 Notebook:在工作区左侧的"工作区"栏中新建笔记本。可以右键单击文件夹选择"创建 > 笔记本",或者通过顶部"(+ 新建)"按钮创建Notebook。命名笔记本并指定默认语言(Python、本指南主要使用Python)。
连接集群:在笔记本编辑界面上方,选择一个活动集群进行附加。Notebook 必须连接到运行的集群才能执行 Spark 作业。如果尚未启动集群,选择后系统会自动启动它。
编写与运行代码:Notebook 单元格可以编写代码或使用 %md 写入Markdown文本说明。按 Shift+Enter 运行当前单元格,或使用运行按钮。多个单元格可按需组合。Databricks Notebook 支持 Python、SQL、R、Scala 等多种语言,可以通过魔术命令(如 %sql, %python 等)在单个笔记本中混用语言。
数据导入:Databricks 提供多种方式导入数据:
小型文件可以直接拖拽上传到工作区,或使用 dbutils 文件系统命令上传。
Azure Databricks 内置了一些示例数据集,无需下载即可使用。例如可以通过 dbutils.fs.ls("/databricks-datasets") 列出自带的示例数据。Databricks 在 Unity Catalog 的samples库中也提供了示例表,如 NYC 出租车行程数据表 samples.nyctaxi.trips。这些数据可用于测试分析。
连接外部数据源:可挂载 Azure Blob/Data Lake Storage,或使用 Spark 支持的连接器读取数据库、数据湖中的数据。
Notebook 功能:Databricks Notebook 提供许多便利功能,包括自动补全、多种主题、高亮语法、版本历史比对等。Notebook 执行结果(如数据表、图表)会直接内嵌显示。对于 Spark DataFrame,可以使用 Databricks 提供的 display() 函数查看表格数据和自动生成图表。
创建好工作区、集群并启动 Notebook 后,我们即可在此交互式环境中开始数据分析和机器学习的实践。
二、Python 数据分析与可视化实践
本节介绍如何利用 Azure Databricks 上的 Spark 引擎进行数据分析,以及结合 Pandas API on Spark 和可视化库进行数据探索。我们将读取示例数据,用 Spark DataFrame 和 Pandas API 进行操作,并绘制图表观察结果。
1. 加载数据到 Spark DataFrame
Azure Databricks 上可以方便地从多种来源加载数据为 Spark DataFrame。这里以 NYC出租车公开数据集 为例进行演示。该数据集包含纽约市出租车行程的详细记录,Databricks 已将其作为示例表 samples.nyctaxi.trips 提供。可以从下面这个网址下载原始数据:
https://www.nyc.gov/site/tlc/about/tlc-trip-record-data.page
然后上传到databricks:
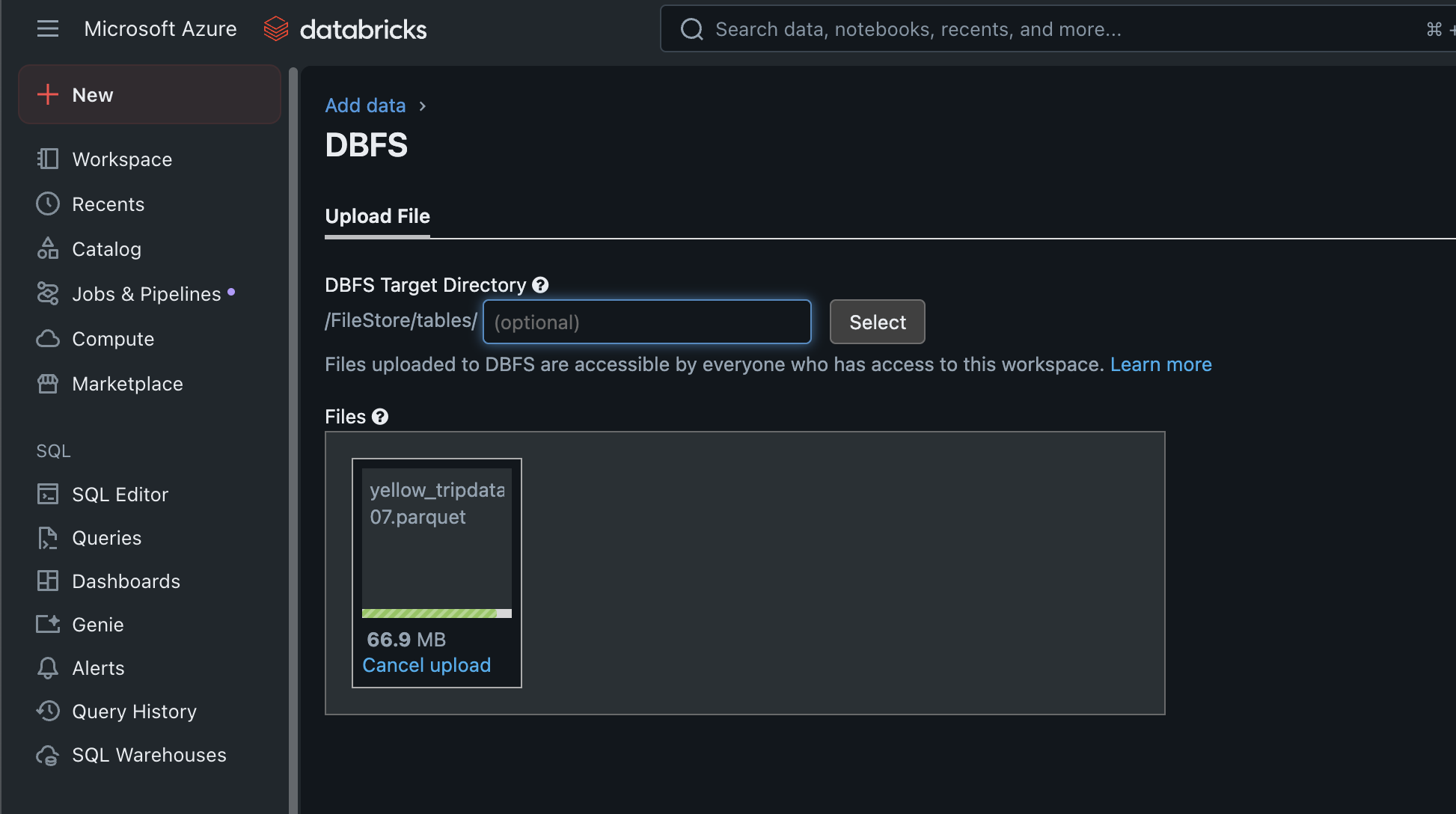
我们可以通过 Spark SQL 直接查询,或使用 Spark DataFrame API 加载:
python
# 方法1:直接从 Unity Catalog 的示例表读取
trips_df = spark.table("samples.nyctaxi.trips") # 载入NYC出租车行程数据
# 从 Databricks 文件系统示例文件加载(假设已存在CSV文件)
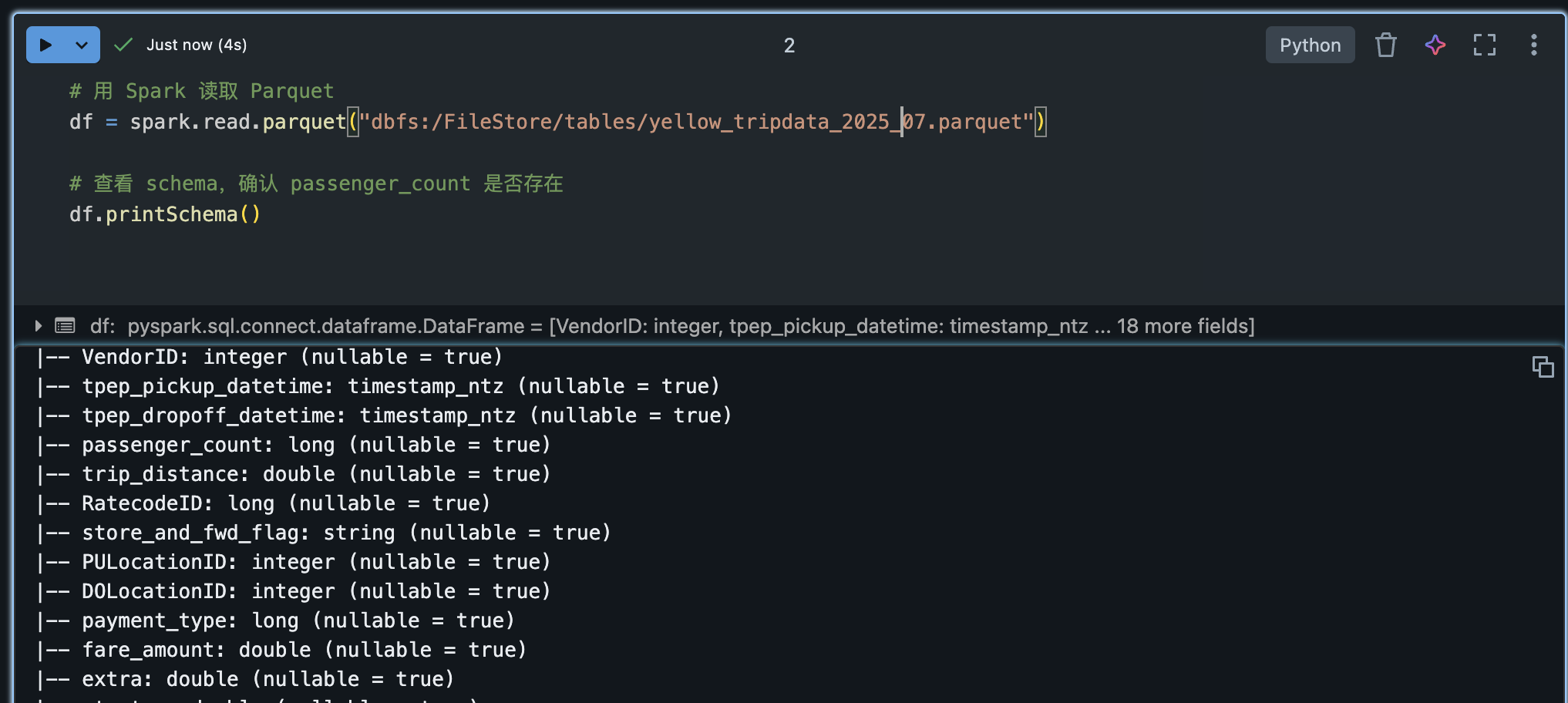
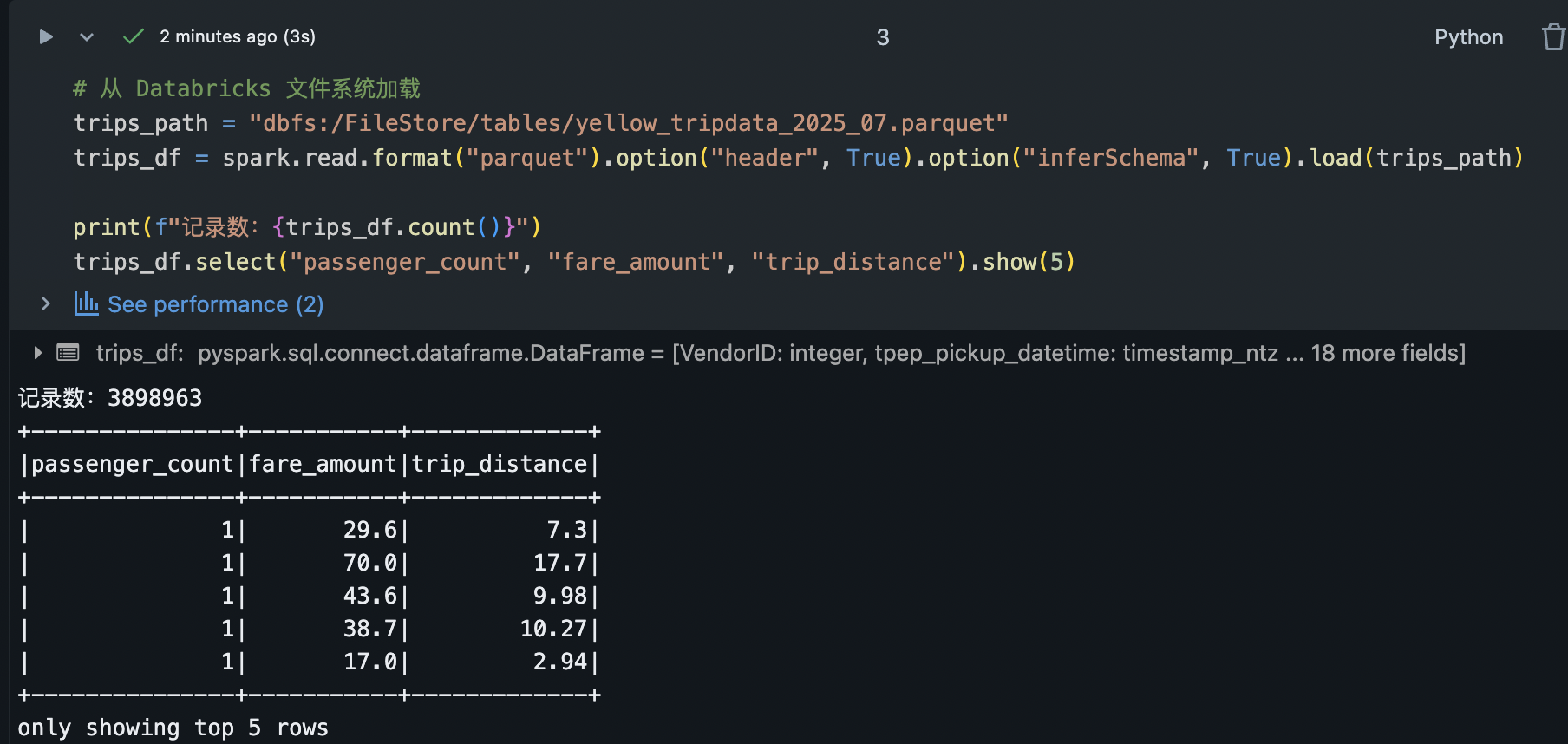
trips_path = "dbfs:/FileStore/tables/yellow_tripdata_2025_07.parquet"
trips_df = spark.read.format("parquet").option("header", True).option("inferSchema", True).load(trips_path)
print(f"记录数:{trips_df.count()}")
trips_df.select("passenger_count", "fare_amount", "trip_distance").show(5)上例使用 Spark 的 spark.read API 加载 CSV 数据,并推断字段类型。加载完成后,我们展示了行数统计和部分字段前5行。在 Databricks Notebook 中,也可以对 trips_df 使用 display(trips_df),以交互式表格形式查看数据。我实际环境使用的方法1,如下:
提示:Azure Databricks 上的 Spark 默认即使用 Delta Lake 格式(详见后文),但对于 CSV 等外部数据,可用 .load() 读取。inferSchema=True 会扫描部分数据推断列类型,生产环境大数据建议显式指定模式以避免推断开销。
2. 使用 Spark DataFrame API 进行数据分析
Spark 提供丰富的 DataFrame 操作用于数据分析,包括选择列、过滤、聚合、排序等。下面我们对出租车数据进行一些基本分析:
python
from pyspark.sql.functions import col, avg, desc
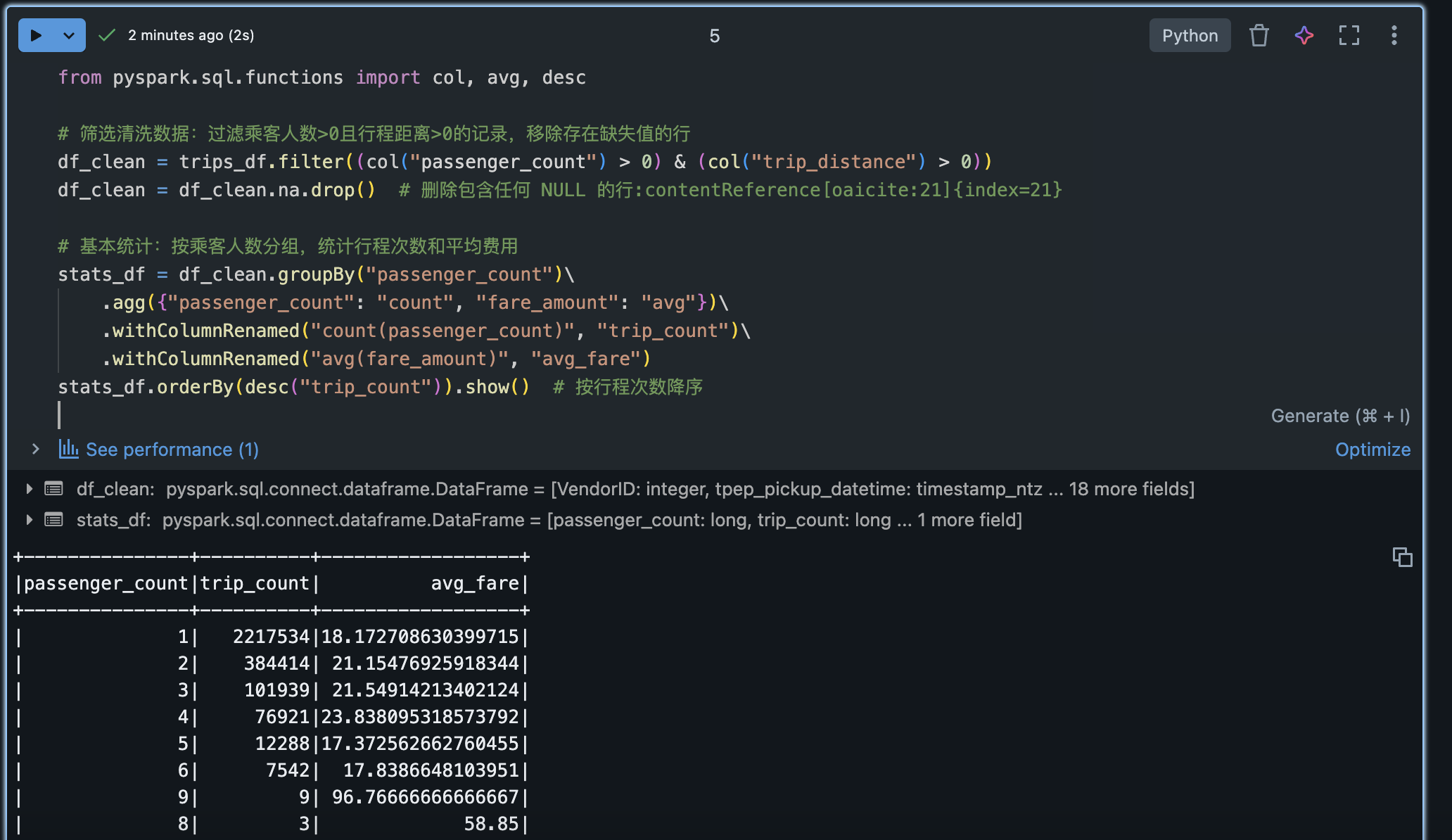
# 筛选清洗数据:过滤乘客人数>0且行程距离>0的记录,移除存在缺失值的行
df_clean = trips_df.filter((col("passenger_count") > 0) & (col("trip_distance") > 0))
df_clean = df_clean.na.drop() # 删除包含任何 NULL 的行:contentReference[oaicite:21]{index=21}
# 基本统计:按乘客人数分组,统计行程次数和平均费用
stats_df = df_clean.groupBy("passenger_count")\
.agg({"passenger_count": "count", "fare_amount": "avg"})\
.withColumnRenamed("count(passenger_count)", "trip_count")\
.withColumnRenamed("avg(fare_amount)", "avg_fare")
stats_df.orderBy(desc("trip_count")).show() # 按行程次数降序上述代码演示了几种常见操作:
过滤行:使用 filter 方法保留满足条件的记录,例如乘客人数和行程距离为正;使用 df.na.drop() 删除含有任意空值的行。
分组聚合:用 groupBy().agg() 按某字段分组并聚合统计。我们计算每种乘客人数情况下的总行程数和平均车费。
列选取与重命名:使用 withColumnRenamed 重命名聚合生成的列名,以便于阅读结果。
排序:使用 orderBy 或 sort 对结果排序,这里按照行程次数降序排列。
通过 stats_df.show() 可以看到不同载客量的行程次数和平均费用。例如,结果可能显示载客1人的行程次数最多,平均费用在$~X左右。
3. 利用 Pandas API on Spark 进行分析
对于熟悉 Pandas 的用户,Spark 3.2+ 提供了 Pandas API on Spark(原 Koalas 项目),允许使用类似 Pandas 的代码操作分布式数据。这降低了学习成本,并支持许多 PySpark 不易完成的任务,例如直接绘图等。在 Databricks Runtime 10.0+ 上,可以通过以下方式引入 Pandas API on Spark:
python
import pyspark.pandas as ps # 引入Spark上的Pandas API
# 将 Spark DataFrame 转换为 Pandas API DataFrame
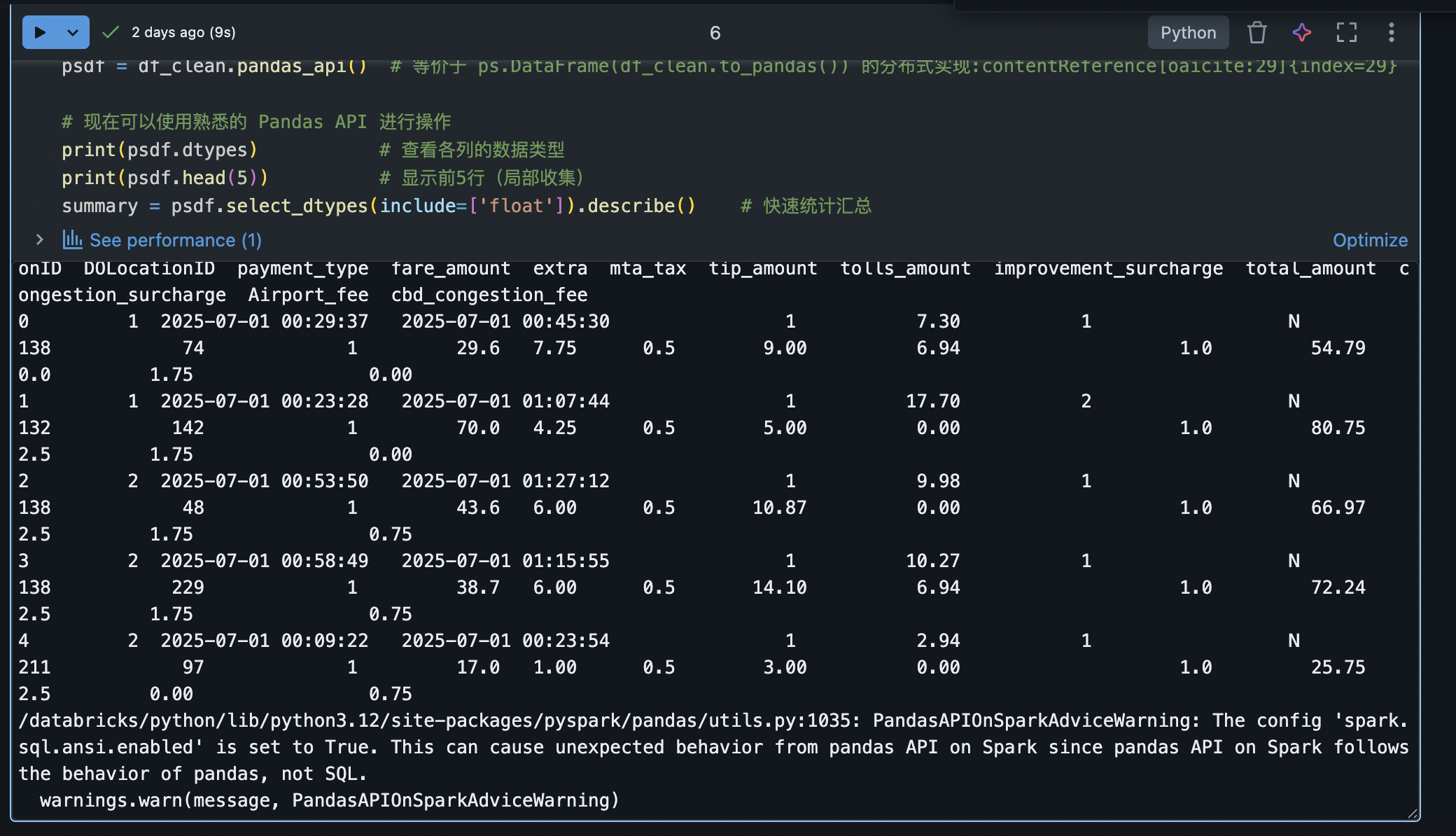
psdf = df_clean.pandas_api() # 等价于 ps.DataFrame(df_clean.to_pandas()) 的分布式实现:contentReference[oaicite:29]{index=29}
# 现在可以使用熟悉的 Pandas API 进行操作
print(psdf.dtypes) # 查看各列的数据类型
print(psdf.head(5)) # 显示前5行(局部收集)
summary = psdf.describe() # 快速统计汇总在上述代码中,我们使用 df_clean.pandas_api() 强制转换出了与 Spark DataFrame 对应的 Pandas API DataFrame。之后便可调用常见的 Pandas 方法,例如 head(), describe() 等。需要注意,psdf.describe() 返回结果仍是一个分布式 DataFrame,如果想在驱动节点查看,可以再调用 .to_pandas() 转为本地 Pandas 对象。
Pandas API on Spark 背后会将操作转化为 Spark 任务执行,因此可处理大规模数据,同时又提供了Pandasp风格的便捷语法。这对于数据科学家来说非常友好,可以用最小的代码改动将原有 Pandas 代码扩展到大数据场景。
4. 数据可视化(matplotlib/seaborn 等)
在数据分析过程中,可视化能够帮助理解数据分布和模式。Azure Databricks 笔记本支持使用常见的 Python 绘图库如 matplotlib 和 seaborn。Databricks 运行时自带了 seaborn 库。为了确保绘图正常显示,通常需要将绘图对象传递给 display() 函数进行渲染。例如,我们对上述出租车数据的车费分布绘制直方图:
python
import seaborn as sns
import matplotlib.pyplot as plt
# 从Spark获取抽样数据到Pandas(因直接绘大量数据可能开销大)
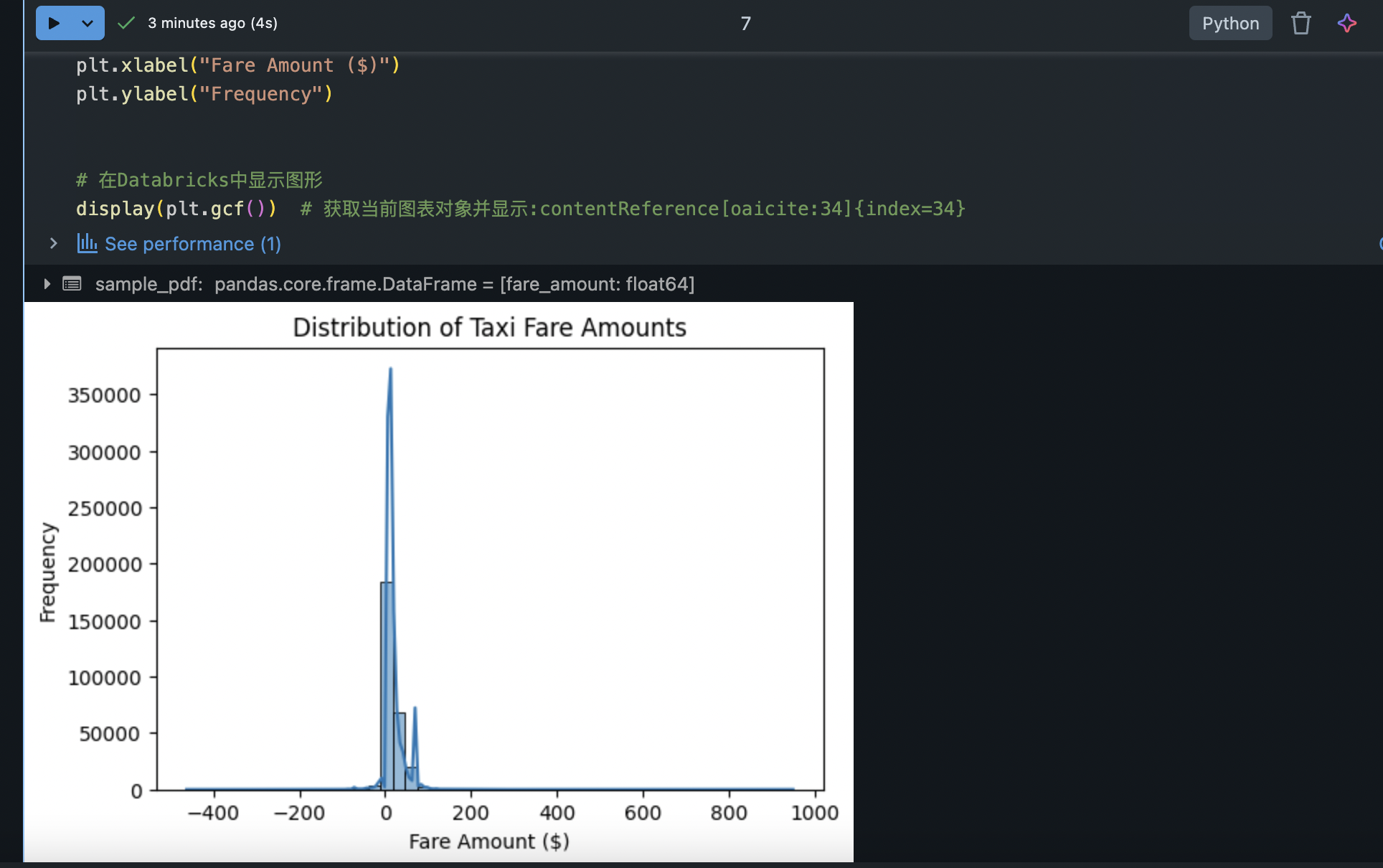
sample_pdf = df_clean.select("fare_amount").sample(fraction=0.1, seed=42).toPandas()
# 使用Seaborn绘制费用分布直方图
plt.figure(figsize=(6,4))
sns.histplot(sample_pdf['fare_amount'], bins=50, kde=True)
plt.title("Distribution of Taxi Fare Amounts")
plt.xlabel("Fare Amount ($)")
plt.ylabel("Frequency")
# 在Databricks中显示图形
display(plt.gcf()) # 获取当前图表对象并显示:contentReference[oaicite:34]{index=34}在上面的代码中,我们采取了抽样方式,仅随机抽取 ~10% 的数据转换为本地 Pandas DataFrame,再用 seaborn 绘制直方图(加上核密度曲线)。最后通过 display(plt.gcf()) 显式传入当前图表对象以确保在 Notebook 中渲染出来。生成的图表直观展示了出租车车费的大致分布情况(例如可能发现大多数行程费用集中在较低区间,有少数高额离群值)。
可视化技巧:
Databricks Notebook 对 matplotlib 绘图也能自动渲染,但使用 display() 更加可靠。
除了手动绘图,针对 Spark DataFrame,也可以直接使用 display(df) 后,在结果表格上方选择"图表"选项,以配置生成各种图表(柱状图、折线图、散点图等)。Databricks 提供了简易的可视化小组件来快速探索数据分布。
对于超大规模数据,绘图前建议使用 .sample() 或 .limit() 缩小数据量,或者使用 Spark 的内置概要统计(如 df.describe())获取摘要信息,用较少的参数绘制更为概括的可视化。
通过以上步骤,我们实现了在 Azure Databricks 上利用 Spark 进行数据加载和清洗,并结合 Pandas API 和可视化库对数据进行了探索分析。在实际工作中,可以根据需要进一步使用Spark SQL、窗口函数、机器学习统计等方法深入分析。在掌握数据分析方法后,我们继续进入数据工程的 ETL 环节。
三、使用 Spark 与 PySpark 构建 ETL 流程
ETL(抽取-转换-加载)过程是数据工程的重要组成部分。Azure Databricks 提供强大的 Spark 引擎和简单易用的 API 来构建可扩展的 ETL 管道。本节将展示如何在 Databricks 上使用 PySpark 执行典型的 ETL 操作:从数据源加载、数据清洗转换,以及将结果数据存储到目标位置。
1. 数据抽取:加载数据源
在 ETL 的 Extract 阶段,我们需要从各种源系统提取原始数据。在 Databricks 中,常用方法包括:
文件数据源:使用 spark.read 从数据湖中的文件加载数据(支持 CSV、JSON、Parquet、AVRO 等多种格式)。例如,从 Azure Data Lake Storage 提取日志文件,或从 DBFS(Databricks 文件系统)加载之前上传的文件。
数据库/数据仓库:使用 JDBC 连接从关系型数据库抽取数据;或通过 Spark 原生连接器读取 NoSQL 数据(如 Azure Cosmos DB、MongoDB)等。
流数据源:对于持续实时的数据源,可以使用 Spark Structured Streaming 连接,如从 Event Hub/Kafka 抽取流式数据(这一部分可用 Delta Live Tables 或 Spark Streaming,超出本指南范围)。
这里以CSV 文件为例说明。假设我们有一个 CSV 数据文件存储在人口和房价信息(Databricks 提供了示例文件 population-vs-price.csv),我们使用 Spark 读取它:
python
# 从文件加载CSV数据为 DataFrame
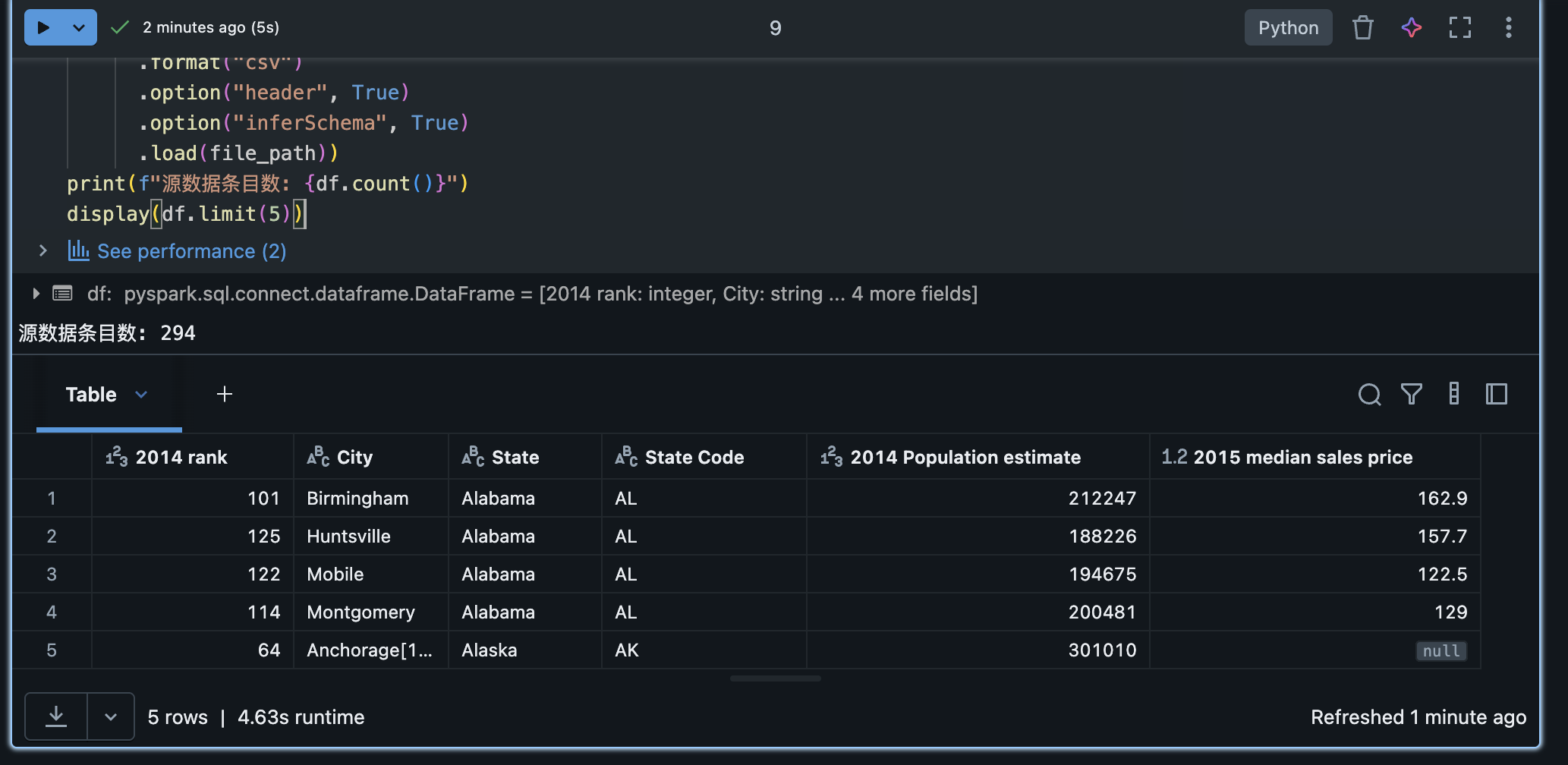
file_path = "/databricks-datasets/samples/population-vs-price/data_geo.csv"
df = (spark.read
.format("csv")
.option("header", True)
.option("inferSchema", True)
.load(file_path))
print(f"源数据条目数: {df.count()}")
display(df.limit(5))上述代码中,我们指定了 header=True 让 Spark 用首行作为列名,inferSchema=True 让 Spark 自动推断列的数据类型,然后加载给定路径的 CSV 文件。display(df.limit(5)) 将展示数据前5行以了解基本结构和内容。
实践建议:在生产场景中,建议明确指定模式而非依赖 inferSchema,因为对大型文件推断模式可能较慢。可通过 spark.read.schema(mySchema).csv(path) 提供预定义的 StructType 模式。
2. 数据清洗与转换
原始数据常常包含缺失值、异常值或不符合业务规则的字段。在 Transform 阶段,我们对数据进行清洗和结构化转换,以满足后续分析/存储需求。
典型的数据清洗转换操作包括:
滤除无效数据:使用 filter 或 where 函数按条件删除异常记录;使用 dropDuplicates() 去除重复项。
处理缺失值:使用 df.na.drop() 删除包含空值的行,或使用 df.na.fill() 为缺失值填充默认值。例如,将空字符串替换为 "UNKNOWN"。
派生新列:使用 withColumn 创建新列。例如根据现有列计算比率或分类标志。
修改列类型:使用 cast 方法转换列的数据类型,如将字符串转换为日期或数值。
重命名或删除列:使用 withColumnRenamed 重命名列;使用 drop 删除不需要的列。
数据合并:如果需要将来自不同来源的数据结合,可以使用 join 将 DataFrame 连接;或用 union/unionByName 追加行。
下面,我们对上一步加载的人口与房价数据进行一些清洗转换示例:
python
from pyspark.sql.functions import trim, upper
# 清洗:丢弃存在空值的记录,去除城市名字段的前后空格,并转换为大写
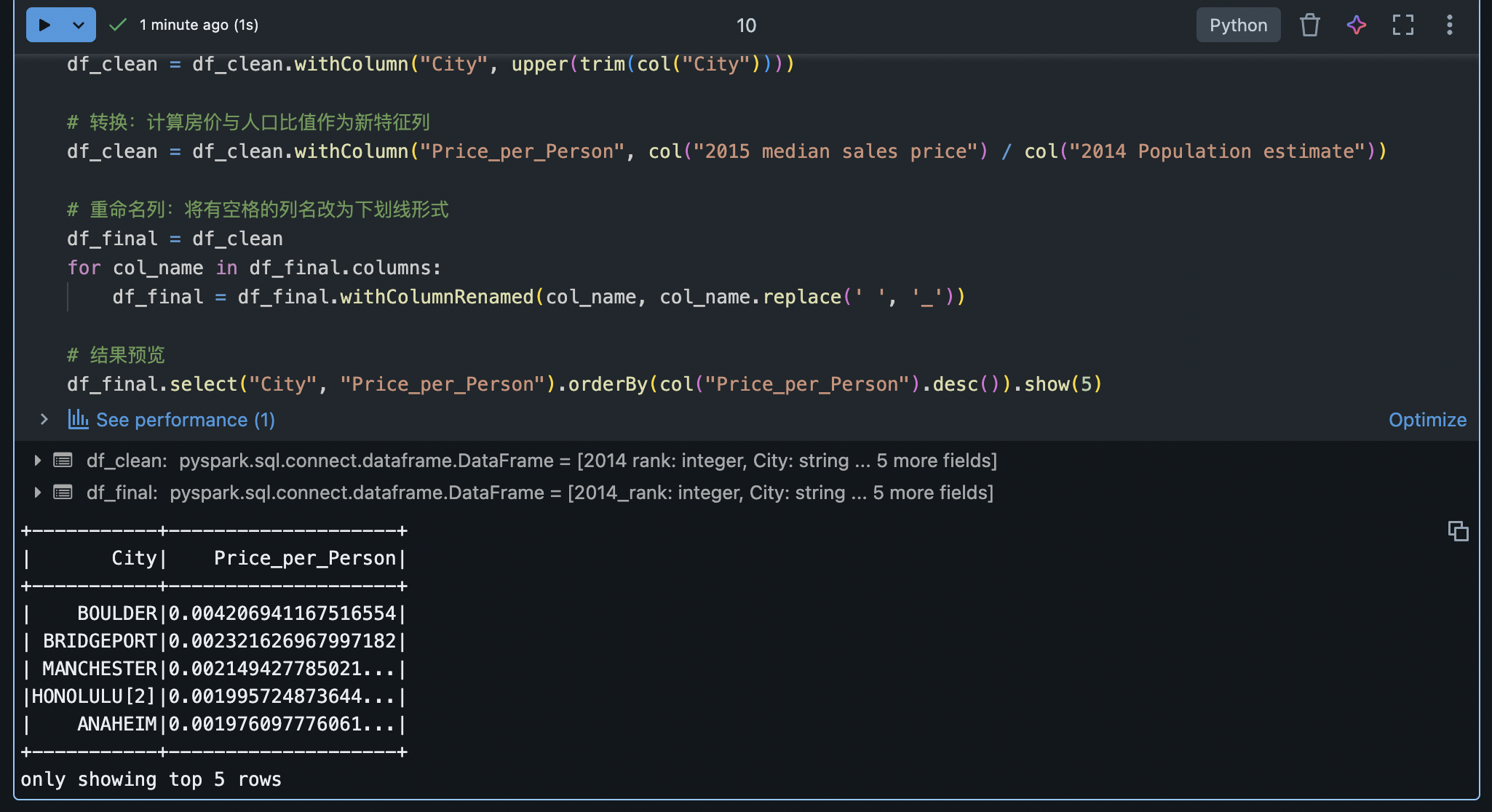
df_clean = df.na.drop(subset=["2015_median_sales_price"]) # 删除房价缺失的行:contentReference[oaicite:48]{index=48}
df_clean = df_clean.withColumn("City", upper(trim(col("City"))))
# 转换:计算房价与人口比值作为新特征列
df_clean = df_clean.withColumn("Price_per_Person", col("2015_median_sales_price") / col("2014_Population_estimate"))
# 重命名列:将有空格的列名改为下划线形式
df_final = df_clean
for col_name in df_final.columns:
df_final = df_final.withColumnRenamed(col_name, col_name.replace(' ', '_'))
# 结果预览
df_final.select("City", "Price_per_Person").orderBy(col("Price_per_Person").desc()).show(5)在这段代码中,我们做了如下处理:
使用 na.drop(subset=...) 删除了 2015_median_sales_price 为空的行,以确保后续计算字段完整。
使用 trim 和 upper 函数清理城市名称字符串,去掉多余空格并统一为大写,方便分组统计(这些是 Spark SQL 内置函数,通过 pyspark.sql.functions 导入)。
新增列 Price_per_Person,表示 房价除以人口 的比值,用于衡量相对房价水平。通过 withColumn 结合列运算直接生成。
批量重命名列,将空格替换为下划线。这是为了后续存储到数据库或文件时避免列名中的空格问题。
转换完成后,我们将结果按照每人房价从高到低排序,显示排名前5的城市及对应值。
进阶转换:Spark 支持使用 SQL 表达式完成复杂转换,如使用 selectExpr 编写 SQL 片段直接派生列;对于复杂业务规则,可以自定义 UDF(用户定义函数)应用于 DataFrame 的列。
3. 数据加载:保存结果到目标
在完成数据转换后,需要将结果数据加载(Load)到目标存储,以便下游使用。在 Azure Databricks 中,我们可以:
将 DataFrame 保存为表:使用 DataFrame.write.saveAsTable() 将结果保存为 Spark 表(默认为 Delta 格式),注册到 Hive/Unity Catalog 元数据中,方便通过 SQL 查询和跨笔记本访问。
写入文件:使用 DataFrame.write 将数据以 Parquet、CSV、Delta 等格式写入数据湖存储路径。常用格式包括 .parquet(), .csv(), .json(), .format("delta").save() 等。
追加或覆盖模式:Spark 写入时默认目标路径若已存在会抛错,我们可以指定保存模式:
mode("overwrite") 覆盖写入,替换目标中的现有数据;
mode("append") 追加写入,在已有数据后附加新数据;
mode("ignore") 忽略写入,如果目标已存在则不执行且不报错。
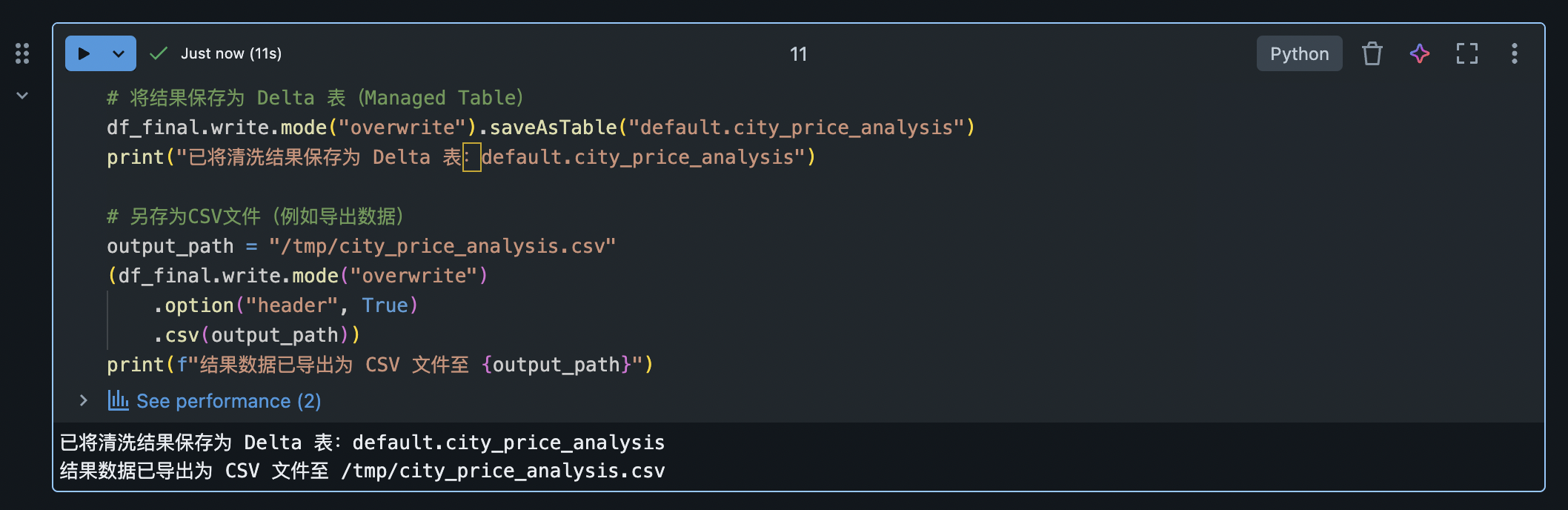
例如,我们将清洗转换后的结果 DataFrame 保存为一个 Delta Lake 表格 供后续分析,并同时演示保存为 CSV 文件:
python
# 将结果保存为 Delta 表(Managed Table)
df_final.write.mode("overwrite").saveAsTable("default.city_price_analysis")
print("已将清洗结果保存为 Delta 表:default.city_price_analysis")
# 另存为CSV文件(例如导出数据)
output_path = "/tmp/city_price_analysis.csv"
(df_final.write.mode("overwrite")
.option("header", True)
.csv(output_path))
print(f"结果数据已导出为 CSV 文件至 {output_path}")上述代码首先使用 saveAsTable 将 DataFrame 保存为名为 city_price_analysis 的表。因为未指定数据库,此表位于默认数据库中,可通过 Spark SQL 查询。接着,我们演示了将同一数据以 CSV 格式写入 DBFS 路径 /tmp/city_price_analysis.csv。使用了 mode("overwrite") 确保如果该路径已有旧文件则将其替换。
执行成功后,我们的 ETL 管道就完成了:从数据源抽取->清洗转换->加载到目标。在 Databricks 上构建 ETL 还有一些高级选项,例如使用 Autoloader 实现云存储中文件的增量自动发现加载,或使用 Delta Live Tables (DLT) 声明性地构建持续 ETL 流水线等。用户可根据需要进一步探索这些功能。下面,我们将进入机器学习阶段,使用清理后的数据或公开数据集来训练模型。
四、构建机器学习管道(Pipeline)
在 Azure Databricks 上,借助 Spark MLlib 和集成的 ML 工具,我们可以构建端到端的机器学习管道,涵盖特征工程、模型训练、评估以及模型部署。本节将以一个经典示例展示如何使用 Spark 的 ML Pipeline API 训练模型,并介绍自动超参数调优和 MLflow 跟踪等进阶功能。我们将使用Iris 鸢尾花数据集(包含150条花卉的特征和品种类别)来演示分类模型的训练流程。
1. 准备训练数据
首先获取 Iris 数据集。Iris 数据集可以通过 sklearn 或 seaborn 库直接加载,或者使用 Databricks 自带的小型数据源。为简单起见,这里利用 seaborn 提供的数据:
python
import seaborn as sns
iris_pd = sns.load_dataset("iris") # 加载鸢尾花数据集为 Pandas DataFrame
iris_pd.head(3)该数据集包含四个数值特征(花萼长宽、花瓣长宽)和一个目标列 species(类别,共3类)。我们将把它转换为 Spark DataFrame,并进行必要的预处理,如将标签列由字符串转为数值索引:
python
# 使用本地sklearn库将字符串标签species转为数字索引
import pandas as pd
from sklearn.preprocessing import LabelEncoder
iris_pd["label"] = LabelEncoder().fit_transform(iris_pd["species"])
# 创建Spark DataFrame
iris_df = spark.createDataFrame(iris_pd)
# 如果支持MLlib库,可以使用下面的方法实现将字符串标签species转为数字索引
# from pyspark.ml.feature import StringIndexer
# label_indexer = StringIndexer(inputCol="species", outputCol="label")
# iris_df = label_indexer.fit(iris_df).transform(iris_df)
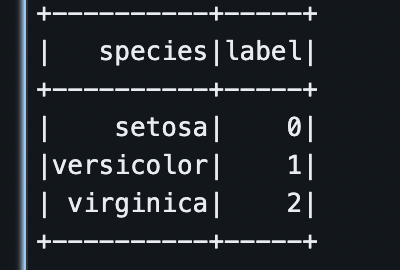
iris_df.select("species", "label").distinct().show()上面,我们用 Spark 的 StringIndexer 将 species 字段映射为机器学习算法可用的数值标签列 label(例如 setosa->0,versicolor->1,virginica->2)。
接下来,我们将数据集拆分为训练集和测试集:
python
train_df, test_df = iris_df.randomSplit([0.7, 0.3], seed=42)
print(f"训练集大小: {train_df.count()}, 测试集大小: {test_df.count()}")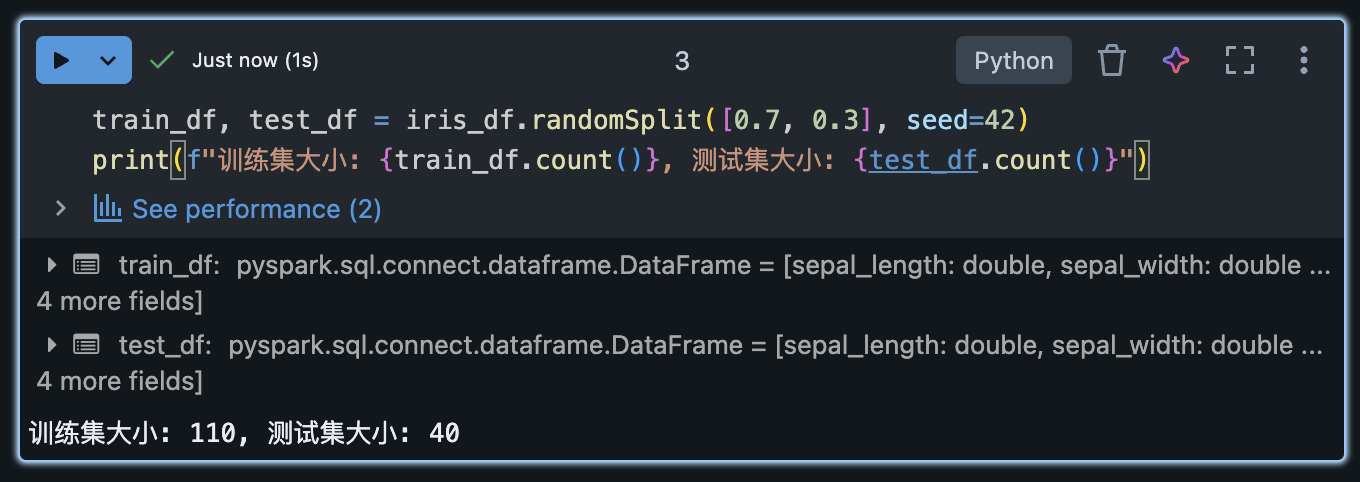
2. 构建 ML Pipeline:特征工程和模型训练
Spark MLlib 提供了 Pipeline API,将数据的特征处理步骤(如特征提取、标准化等转换器)和学习算法(估计器)串联成一个管道,方便统一拟合和管理。当我们调用 pipeline.fit(train_data) 时,会按顺序自动执行各个步骤:对训练数据先后应用特征工程转换,再训练模型。同样地,对于新数据调用 model.transform(test_data) 时,管道模型也会依次执行转换器并输出预测结果。
在本例中,我们的特征工程包括将四个数值特征拼接成向量,以及对该特征向量进行标准化。然后选择一个分类算法(逻辑回归)作为模型。我们可以使用 Pipeline 封装这些步骤:
python
from pyspark.ml import Pipeline
from pyspark.ml.feature import VectorAssembler, MinMaxScaler
from pyspark.ml.classification import LogisticRegression
# 定义特征列名称
feature_cols = ["sepal_length", "sepal_width", "petal_length", "petal_width"]
# 配置 Pipeline Stages
assembler = VectorAssembler(inputCols=feature_cols, outputCol="features_raw")
scaler = MinMaxScaler(inputCol="features_raw", outputCol="features") # 归一化特征到0-1
lr = LogisticRegression(featuresCol="features", labelCol="label", maxIter=10)
pipeline = Pipeline(stages=[assembler, scaler, lr])
# 在训练集上拟合Pipeline,得到模型
model = pipeline.fit(train_df)
print("Model training completed!")这里,我们构建了包含3个阶段(stages)的管道:
VectorAssembler:将原始数值特征列合并为一个特征向量列 features_raw。
MinMaxScaler:对特征向量各维度归一化到 0,1 区间,输出标准化后的特征列 features。这一步属于特征缩放,非必需但有助于一些算法的收敛。
LogisticRegression:逻辑回归分类器,设置特征列和标签列,训练迭代上限为10次。
通过 pipeline.fit(train_df) 即可一次性完成上述所有步骤在训练集上的执行和模型训练,得到 model(其实是一个 PipelineModel,内部包含各阶段的子模型)。由于 Pipeline 会将特征工程步骤封装进模型中,因此我们可以直接将 model 应用于测试集,无需手动对测试数据重复特征处理:
python
# 在测试集上预测
predictions_df = model.transform(test_df)
predictions_df.select("features", "prediction", "label").show(5)我们可以看到输出 DataFrame 增加了预测结果列 prediction。Pipeline 模型自动对 test_df 应用了与训练时相同的 assembler 和 scaler 转换,然后生成预测,无需我们显式处理测试集特征。这体现了 Pipeline 的便利:特征工程步骤与模型训练集成,避免训练和预测流程不一致的风险。
3. 模型评估与指标计算
模型训练完成后,需要评估其在测试集上的表现。我们使用 Spark 提供的评估器 MulticlassClassificationEvaluator 来计算常见分类指标,例如准确率(Accuracy):
python
from pyspark.ml.evaluation import MulticlassClassificationEvaluator
evaluator = MulticlassClassificationEvaluator(labelCol="label", predictionCol="prediction", metricName="accuracy")
accuracy = evaluator.evaluate(predictions_df)
print(f"Test Accuracy = {accuracy:.2f}")输出的准确率衡量了模型对测试集鸢尾花品种的预测准确度。由于 Iris 数据相对简单,逻辑回归模型的准确率可能在 0.9 左右,表示90%+的预测正确率。
我们也可以进一步计算每个类别的精确率、召回率、F1值等指标。例如,通过为 evaluator 设置 metricName="precisionByLabel" 并指定 metricLabel=0/1/2 来得到每个类别的精确率。同理可以计算 recallByLabel 和 fMeasureByLabel。在此不展开,Databricks Notebook 上打印这些指标可以帮助我们详细了解模型对各类别的性能。
4. 模型调优(超参数自动调节)
提升模型性能的一个重要方面是超参数调优(Hyperparameter Tuning)。手动尝试不同参数组合既耗时又易出错。Databricks 提供多种自动化超参调优手段:
CrossValidator(交叉验证):Spark MLlib 自带的调优工具。可以定义参数网格(ParamGrid)和评估器,对每组参数进行 K 折交叉验证评估,选择最佳模型。适用于中小规模参数搜索。
Hyperopt + SparkTrials:Databricks 集成了 Hyperopt 库,可以通过分布式方式高效搜索参数空间,支持高级的贝叶斯优化算法,比网格搜索更高效。
AutoML:Databricks 提供自动化机器学习(AutoML)功能。AutoML 不仅自动尝试模型及参数组合,还包含自动特征工程。用户只需提供训练数据和目标,AutoML 会生成一系列试验并返回效果最优的模型。这对于快速建立基线模型非常有用。
在本例中,我们可以尝试用 CrossValidator 对逻辑回归的正则化参数 regParam 进行简单调优,寻找更优的准确率。然而,由于数据集很小,出于演示考虑这里不具体展开代码。需要了解的是,通过这些自动调优工具,Databricks 可大大简化模型优化的工作量,实现自动化超参数优化,以最少的代码自动生成高质量模型。
5. 使用 MLflow 跟踪实验
MLflow 是 Databricks 开源的机器学习生命周期管理工具。Azure Databricks 已原生集成 MLflow,用于记录和跟踪机器学习实验(参数、指标、模型等)。当我们反复训练模型调整参数时,MLflow 能帮助我们比较不同实验的结果,管理模型版本。
在 Databricks Notebook 中,使用 MLflow 非常简单:
自动记录:调用 mlflow.pyspark.ml.autolog() 或 mlflow.autolog() 开启自动记录。之后运行的 Spark ML (或其他库)训练过程将自动记录模型参数和评估指标,无需手工插桩代码。
手动记录:使用 MLflow API 在代码中显式记录。典型流程是用 mlflow.start_run() 开启跟踪上下文,然后使用如 mlflow.log_param(), mlflow.log_metric(), mlflow.log_model() 等方法记录参数、指标和模型文件。
例如,我们可以在训练逻辑回归管道时集成 MLflow:
python
import mlflow
mlflow.pyspark.ml.autolog() # 自动记录Spark ML参数和模型
with mlflow.start_run():
model = pipeline.fit(train_df) # 训练模型,会自动记录超参数和模型
preds = model.transform(test_df)
acc = evaluator.evaluate(preds)
mlflow.log_metric("test_accuracy", acc) # 手动记录测试集准确率运行上述代码后,在Databricks界面右侧的"Experiment"面板中就能看到新记录的运行。每次运行的参数(如逻辑回归的 maxIter、RegParam 等)、训练得到的模型 artifact,以及我们记录的 test_accuracy 等都会被保存。通过 MLflow,我们可以方便地跟踪实验、比较模型性能、管理完整的模型开发生命周期。
Azure Databricks 的 MLflow Tracking 使用的是工作区自带的跟踪服务器,无需额外搭建,并且与 Notebook 深度集成。当实验结果满意后,我们还可将模型注册到 MLflow 模型注册表中,以进行部署。
6. 模型部署与推理
训练并评估出满意的模型后,即可考虑将其部署用于生产预测。Azure Databricks 提供两种主要部署方式:
批量部署:对于批处理场景,可以将模型以 Spark 作业的形式应用于新数据集(例如定期预测)。这通常直接使用保存的 PipelineModel 通过 model.transform(new_data) 实现。
实时部署:Databricks 支持将模型部署为实时服务(REST API)。在 Databricks 的模型页面,可以将注册的模型创建为一个 Model Serving Endpoint 实时端点。该服务会启动一个托管集群,监听 REST 请求并返回模型预测结果。
我们演示第二种:将刚才训练的鸢尾花模型注册并部署为实时服务:
注册模型:在 Notebook 中使用 mlflow.spark.log_model(model, "model") 已将模型保存并关联到当前 MLflow 运行。打开 Databricks 左侧的"实验"页面,找到本次运行并点选"注册模型"按钮,将模型登记到注册表中,命名为 "IrisClassifier"(实际操作可在UI完成)。
创建服务端点:进入Databricks左侧"模型"菜单,找到 IrisClassifier 模型。选择刚才注册的版本(例如 Version 1),点击"部署模型"或"创建端点"按钮。在配置中填写端点名称(如 iris-predict),选择计算规模(Small默认)并确认创建。Databricks 将自动启动一个托管服务来加载模型。
调用测试:部署完成后,可以在模型页面点击"查询终结点"来测试。通过向生成的 REST URL 发送包含特征的 JSON 请求,即可获取预测输出。例如发送如下JSON:
python
{
"dataframe_records": [
{ "sepal_length": 5.1, "sepal_width": 3.5, "petal_length": 1.4, "petal_width": 0.2 }
]
}服务将返回类似 {"predictions": 0} 的结果,表示类别预测为0(对应 setosa)。
上述流程表明,在 Databricks 上注册和部署模型非常便捷。从实验追踪到模型上线,都可以在一个统一的平台完成。需要注意实时服务功能目前需要 Azure Databricks 高级定价层,并非所有地区都支持。部署后应监控端点的延迟和负载,并可结合 Databricks 的模型监控功能查看服务的调用情况、模型漂移等。
通过这一系列步骤,我们完成了一个机器学习项目从数据准备、模型训练调优到部署的完整周期。在此过程中,我们利用了 Azure Databricks 提供的协作 Notebook环境、分布式 Spark 算法库以及 MLflow 等强大工具,加速了开发流程并确保了模型管理的规范可控。
进阶提示:Databricks 还支持将训练好的模型导出为 Spark独立可用的格式(如 MLeap 或 ONNX),或下载本地部署。同时,可以使用 Databricks 与 Azure Machine Learning 服务集成,在 AML 中托管模型。根据业务需求选择合适的部署方案。
五、Delta Lake 的使用与高级功能
Delta Lake 是构建在数据湖之上的开源存储层,也是 Azure Databricks 默认采用的表格式。它为数据湖引入了类似数据仓库的可靠性和性能特性,包括 ACID 事务、数据版本控制、Schema Enforcement、审计历史等,使得在云存储上也能实现高可靠的表存储。本节我们将介绍 Delta Lake 的基本操作(创建表、读写数据、更新删除)以及其强大的高级功能:时间旅行查询、版本历史和事务机制。
1. 创建和写入 Delta 表
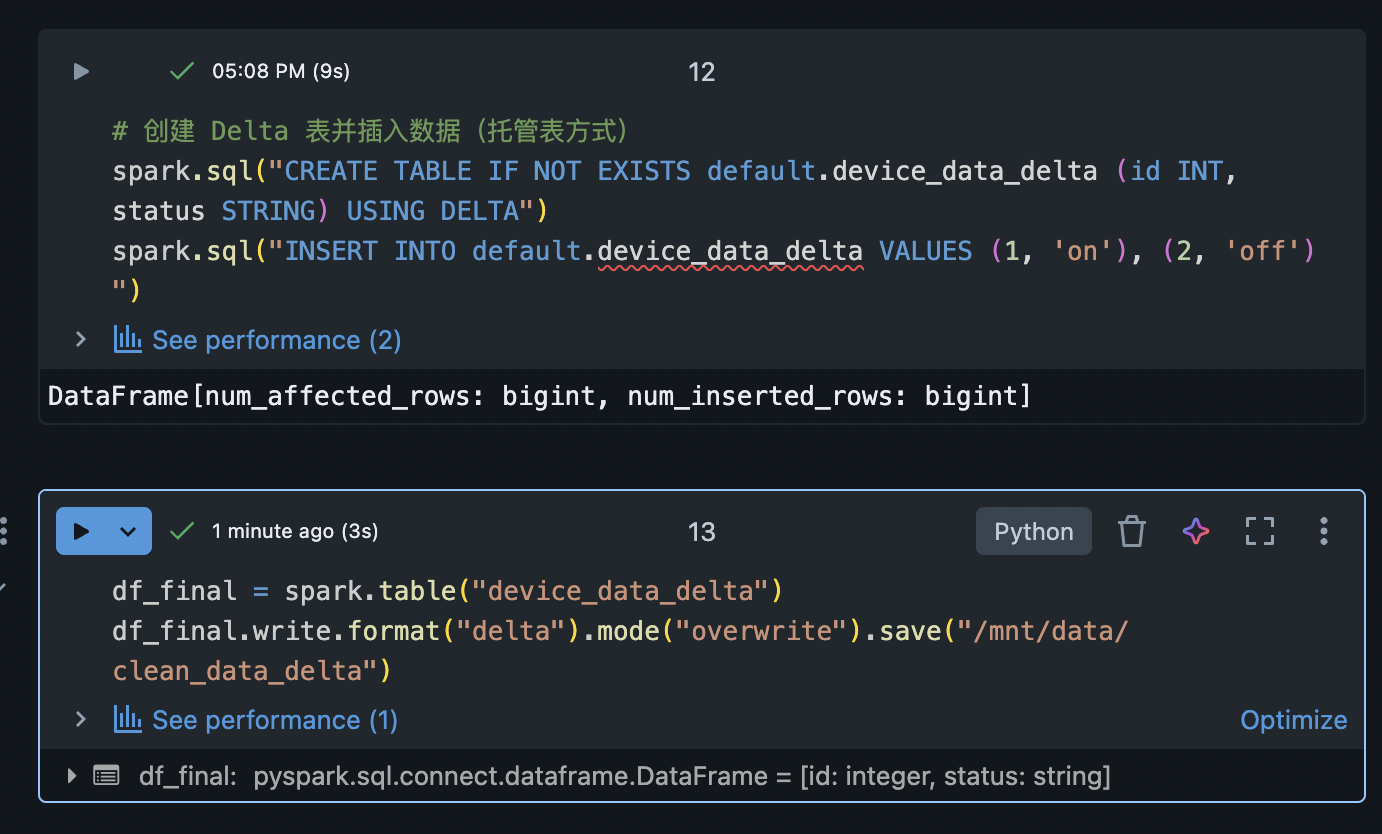
在 Azure Databricks 中,新创建的表默认即为 Delta 表(除非另行指定格式)。将 DataFrame 保存为表或路径时,只需指定 Delta 格式,即可创建 Delta Lake 表。例如:
python
# 将 DataFrame 保存为 Delta 格式的数据文件(非托管表)
df_final.write.format("delta").mode("overwrite").save("/mnt/data/clean_data_delta")
# 创建 Delta 表并插入数据(托管表方式)
spark.sql("CREATE TABLE IF NOT EXISTS default.device_data_delta (id INT, status STRING) USING DELTA")
spark.sql("INSERT INTO default.device_data_delta VALUES (1, 'on'), (2, 'off')")上面第一行演示直接保存 Delta 文件:在指定路径写入 Delta 格式数据文件。第二段使用 Spark SQL 以 Delta 方式创建了一张表,并插入了两行数据。无论采用哪种方式,数据都被存储为 Delta Lake 表格式。Delta 表的核心是维护一个 事务日志(_delta_log),用于跟踪每次数据操作,从而提供 ACID 事务保证。
ACID 事务意味着:对 Delta 表的一系列操作要么全部成功要么全部回滚,外部查询永远不会看到中间不一致状态的数据。这解决了传统云存储上多文件更新不原子、并发读写不隔离的问题
。例如,在 Delta 表上同时进行读取查询和写入更新,读者要么看到更新前的数据,要么看到更新完成后的数据,不会看到部分更新的混杂状态。
2. 读写 Delta 表
读取 Delta 表与读取普通 Parquet 表相似,但 Delta 会自动利用事务日志提供的一致性视图。可以通过 Spark DataFrame API 或 Spark SQL 读取:
python
# 方法1:使用 Spark DataFrame 读取 Delta 路径
delta_df = spark.read.format("delta").load("/mnt/data/clean_data_delta")
# 方法2:查询 Delta SQL 表
result = spark.sql("SELECT * FROM default.device_data_delta")
Delta 支持常见的 DataFrame 写入模式。例如可以使用 df.write.mode("append").format("delta")... 追加新数据到表,或用 "overwrite" 模式覆盖。不同于简单文件格式,Delta 的 overwrite 操作也是原子完成的:它会生成新的快照而不是直接物理覆盖文件,从而避免读写冲突。
3. 更新和删除操作(UPSERT/MERGE)
传统数据湖格式(如 Parquet)对数据更新、删除非常不便,而 Delta Lake 原生支持DML操作:
DELETE:删除符合条件的记录。如 spark.sql("DELETE FROM default.device_data_delta WHERE id = 2") 会删除 id=2 的行。
UPDATE:更新符合条件的记录的某些字段。例如 spark.sql("UPDATE default.device_data_delta SET status='on' WHERE id = 2")。
MERGE(UPSERT):合并操作,可根据主键从另一数据源插入新记录或更新已存在记录。这相当于"插入-更新"操作,可以方便地将增量数据合并到主表中。
举个 MERGE 的例子,假设我们有一张 Delta 表 user_events 存储用户行为数据,我们想将最新的一批事件流增量合并进去,可以这样做:
sql
MERGE INTO user_events AS target
USING new_events AS source
ON target.userId = source.userId
WHEN MATCHED THEN
UPDATE SET target.last_activity = source.last_activity
WHEN NOT MATCHED THEN
INSERT (userId, last_activity) VALUES (source.userId, source.last_activity);这条 SQL 含义是:对于主表中已存在的用户,更新其最后活动时间;对于不存在的用户,插入新记录。Delta Lake 会保证此操作的原子性和隔离性,多用户并发 MERGE 也能正确序列化执行。这在纯 Parquet 文件的场景几乎无法轻易实现,而 Delta Lake 通过其日志和版本控制实现了这一点。
4. 时间旅行:数据版本控制与历史查询
Delta Lake 的一大特色是数据版本控制。每次对 Delta 表的修改(如插入、删除、合并)都会生成一个新的表版本,并记录在事务日志中。我们可以方便地查看表的操作历史,或查询表在过去某个时间点的状态,这被称为时间旅行 (Time Travel)。
查看历史:使用 DESCRIBE HISTORY 表名 可以列出表的所有版本及其操作记录。其中包含版本号、时间戳、操作类型、提交用户等信息,方便审计和调试。
时间点查询:可以通过版本号或时间戳来查询表先前的状态。例如:
sql
SELECT * FROM default.device_data_delta VERSION AS OF 0;
SELECT * FROM default.device_data_delta TIMESTAMP AS OF '2025-08-01 00:00:00';第一条语句将返回表的初始版本(版本0)的数据。第二条按照给定时间点返回当时的表内容(如果该时间点精确命中一次提交则返回对应版本,或者返回最后一个早于该时间的版本)。
数据回滚:利用时间旅行机制,可以恢复表到某个旧版本。使用 RESTORE TABLE 表名 TO VERSION AS OF n 即可将表数据回滚到第 n 版。这对于误操作导致的数据错误提供了便利的补救手段。
举例:假设我们对 device_data_delta 表进行了几次更新删除操作,现在想查询最初插入时的状态,可以执行:
sql
SELECT *
FROM default.device_data_delta VERSION AS OF 0;如果版本0包含2行数据,上述查询将返回那2行,即使当前表早已是修改后的新版本。这种**"时光查询"**能力极大方便了数据溯源和审计。例如,可以比较两版本数据的差异,或者临时基于旧数据重新运行某分析作业验证结果等。
需要注意,Delta 默认只保留30天的操作日志(可配置),超过保留期的旧版本可能会被清理。因此时间旅行一般用于近些天内的数据追溯,不应替代正式的备份归档方案。
5. 性能优化与其他高级特性
Delta Lake 还提供了许多高级功能来提升性能和维护便利:
数据压缩与文件优化:随着数据写入增多,Delta 表可能出现许多小文件。可以定期使用 OPTIMIZE 表名 命令对存储文件进行压缩整合,并可配合 ZORDER BY 列 优化数据的存储排序。例如对常用过滤字段 Z-order,可显著加快范围查询。Databricks 也支持自动优化功能,在写入时自动合并小文件和收集统计信息。
缓存:由于 Delta 数据文件和日志都是不可变的,Databricks 集群节点会自动将热数据缓存到本地SSD以加速读取。这对于反复访问相同表的数据分析作业大有裨益。
Schema Enforcement & Evolution:Delta 在写入时可以强制新数据模式与表模式兼容(字段类型匹配等),不符则报错,保证数据一致性。如果需要也可以开启 自动 schema 演化(SparkSession.conf.set("spark.databricks.delta.schema.autoMerge.enabled","true")),允许新增列等模式变化自动合并进表模式,方便渐进式拓展表结构。
Change Data Feed:Delta 可以跟踪表的每次变更内容。在表属性开启 delta.enableChangeDataFeed 后,可查询增量的插入/更新/删除记录,方便实现下游增量同步和审计。
细粒度权限:结合 Unity Catalog,Delta 表可以实现列级、行级的访问控制以及屏蔽,满足数据安全和合规需求(这部分属于数据治理范畴,在此不详述)。
通过 Delta Lake,Azure Databricks 实现了湖仓一体架构,使用户能够在数据湖中享受类似数据仓库的可靠事务和高性能查询。同时,Delta Lake 的开源特性也允许在Azure之外的Spark环境使用,具有很强的灵活性。
六、总结与实践建议
通过上述各章节的指南,我们完整演示了在 Azure Databricks 上的动手实践过程。从环境搭建、数据分析处理,到机器学习模型的构建调优、部署,以及 Delta Lake 在数据湖上的高级特性运用。体会到 Azure Databricks 提供的一站式数据分析与机器学习平台的强大之处:
环境整合:开发者可以在 Notebook 中无缝完成数据工程和机器学习的所有步骤,利用云上弹性 Spark 集群实现大数据处理和训练加速。
数据分析:Spark DataFrame API 结合 Pandas API on Spark,让我们得以用简洁的代码处理海量数据,并快速可视化结果。
ETL 构建:借助 PySpark 的丰富算子,构建清晰的ETL流程,实现从数据加载、清洗到写出的一系列操作,并且能方便地写入 Delta Lake 提供可靠存储。
机器学习:利用 Spark ML Pipelines,我们将特征工程和模型训练有机结合,简化了流程管理。同时 MLflow 的追踪和 Databricks AutoML 的自动化,大幅降低了实验管理和参数调优的难度。
Delta Lake:我们体验了Delta Lake的 ACID 交易保障和强大的时间旅行功能,使数据湖存储的管理和数据可信度上了一个台阶。此外,Delta 提供的MERGE等操作使数据增量更新不再繁琐。