布隆过滤器:原理、实现与海量场景应用解析
大家好,我是程序员云喜,今天想和大家深入聊聊布隆过滤器------这个在"海量数据存在性判断"场景中堪称"空间效率王者"的技术。我初次接触它,是为了解决Redis缓存穿透问题,后续在分布式系统、爬虫去重等场景中反复实践,才逐渐摸清它"高效背后的设计逻辑"。接下来,我们从原理、代码实现到落地场景,一步步拆解它的核心价值。
一、认识布隆过滤器:核心定义与工作逻辑
布隆过滤器(Bloom Filter)的核心功能非常明确:快速判断"一个元素是否存在于某个海量集合中",它用极小的空间开销和极快的查询速度实现目标,但存在"可控的假阳性",且绝对不会出现"假阴性"。
1. 核心原理:二进制数组 + 多哈希函数
布隆过滤器的底层结构由两部分组成:二进制位数组(BitSet) 和 多个独立哈希函数,具体工作流程如下:
- 添加元素时:将元素传入所有哈希函数,计算出多个"数组索引位置",并将这些位置的二进制值从"0"设为"1"。
- 查询元素时:同样用所有哈希函数计算元素的索引位置,若所有位置的二进制值均为"1",则判断元素"可能存在";若任意一个位置为"0",则判断元素"一定不存在"。
2. 三大关键特性
| 特性 | 详细说明 |
|---|---|
| 高效性 | 插入和查询的时间复杂度均为 O(k)(k为哈希函数数量),且占用内存极小。 |
| 概率性 | 存在"假阳性"(误判不存在的元素为"可能存在"),但绝对无假阴性(不会将存在的元素判为"不存在")。 |
| 不可逆 | 无法从过滤器中删除元素------删除某元素的哈希位置会影响其他元素的判断结果。 |
3. 基础应用场景(初阶)
- 防止Redis缓存穿透(核心场景)
- 邮件黑名单过滤(快速拦截垃圾邮件发送者)
- 网页爬虫URL去重(避免重复爬取浪费资源)
- 数据库查询优化(快速判断记录是否存在,减少无效IO)
4. 原理可视化(辅助理解)
- 图1:布隆过滤器基础结构
展示一个8位二进制数组(初始全为0)和2个哈希函数的初始状态,无任何元素映射。 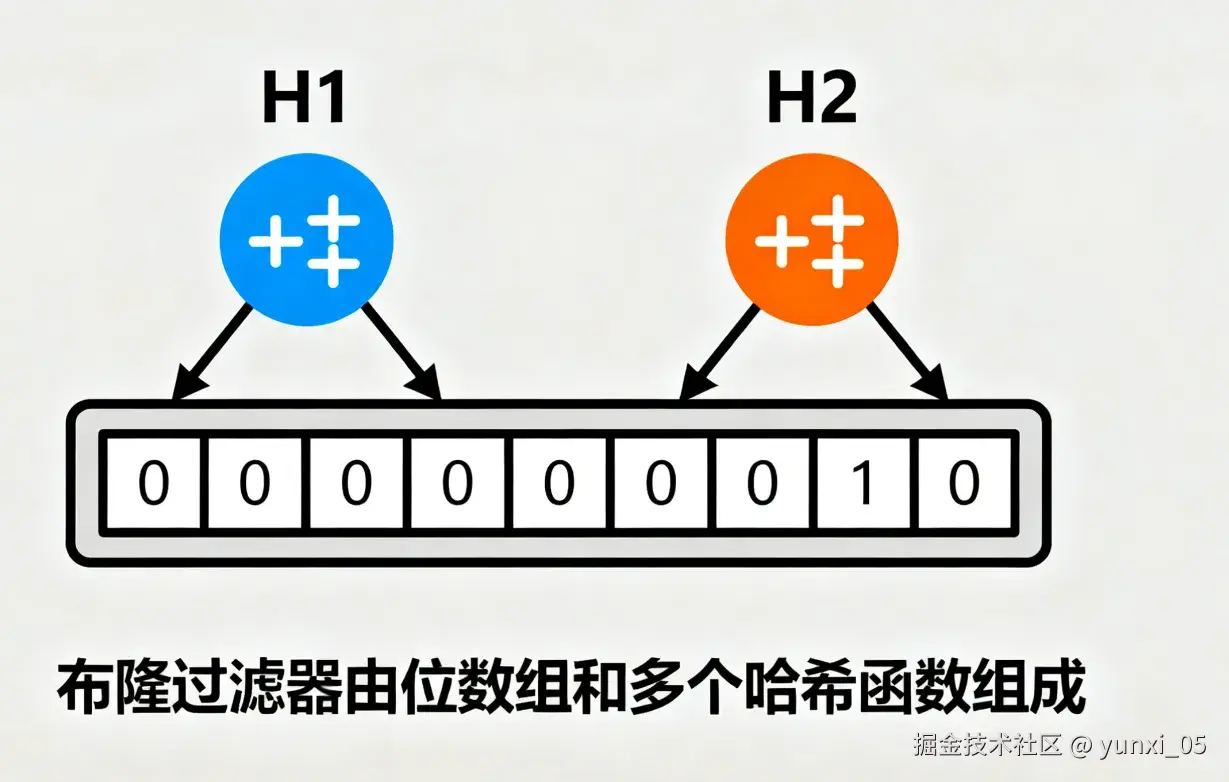
- 图2:添加元素"Apple"的过程
"Apple"经2个哈希函数计算后,对应数组的2个位置被置为1,完成元素映射。 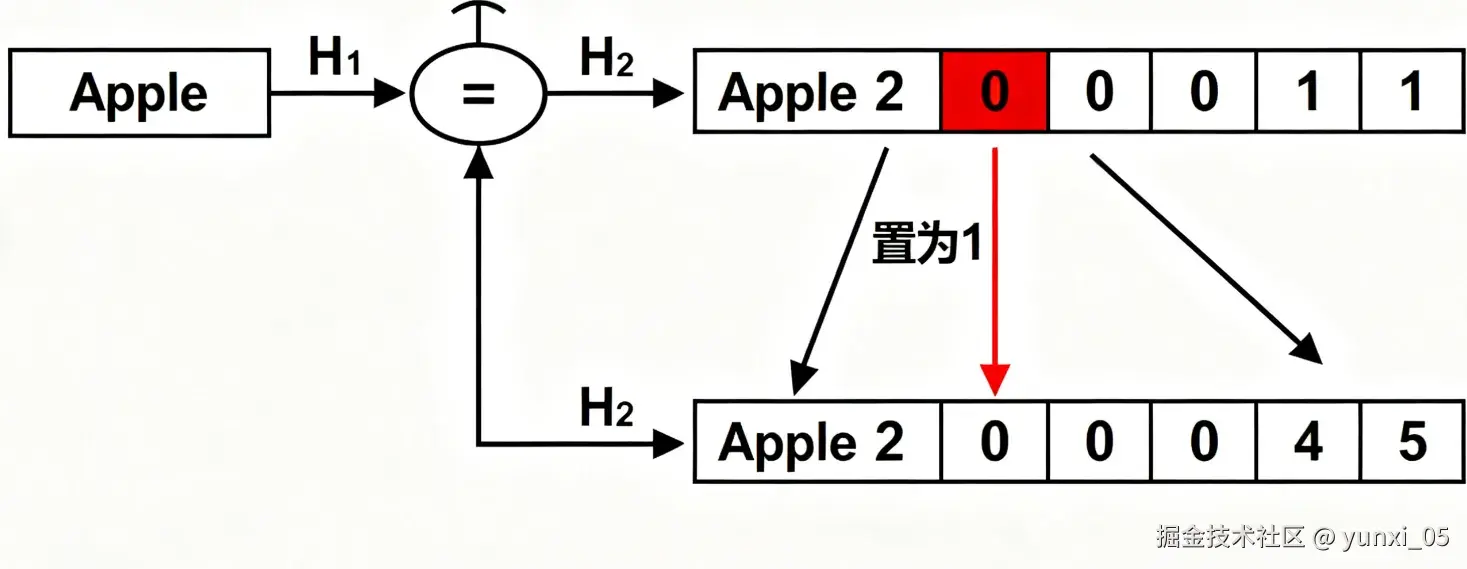
- 图3:查询存在元素"Apple"
再次计算"Apple"的哈希位置,所有位置均为1,判断"可能存在"(实际存在)。 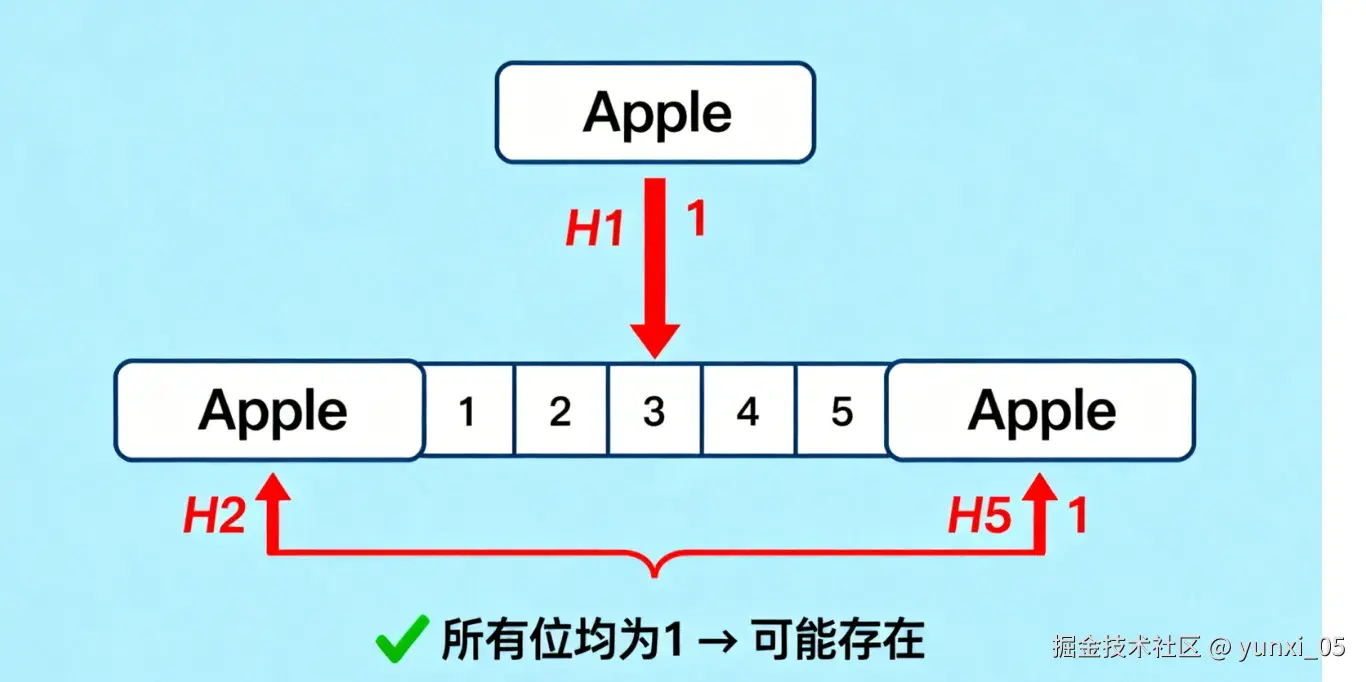
- 图4:查询不存在元素"Banana"
"Banana"的哈希位置中至少1个为0,直接判断"一定不存在"。
二、代码实现:从基础结构到Redis实战
下面通过Java代码,先实现布隆过滤器的核心逻辑,再结合Redis+数据库,演示"防止缓存穿透"的完整方案。
1. 布隆过滤器基础实现(核心骨架)
java
/**
* 简单的布隆过滤器实现(基于BitSet和多哈希函数)
*/
public class BloomFilter {
// 位数组大小:2^25 = 33554432位(约4MB),可根据数据量调整
private static final int DEFAULT_SIZE = 2 << 24;
// 6个不同的哈希种子(生成不同哈希值,降低碰撞率)
private static final int[] SEEDS = new int[]{3, 13, 46, 71, 91, 134};
private BitSet bits; // 底层二进制数组
private HashFunction[] functions; // 哈希函数数组
/**
* 构造方法:初始化位数组和哈希函数
*/
public BloomFilter() {
bits = new BitSet(DEFAULT_SIZE);
functions = new HashFunction[SEEDS.length];
// 为每个种子创建一个哈希函数实例
for (int i = 0; i < SEEDS.length; i++) {
functions[i] = new HashFunction(DEFAULT_SIZE, SEEDS[i]);
}
}
/**
* 哈希函数内部类:通过"种子+元素哈希值"生成数组索引
*/
public static class HashFunction {
private int size; // 位数组大小(用于取模)
private int seed; // 哈希种子(区分不同哈希函数)
public HashFunction(int size, int seed) {
this.size = size;
this.seed = seed;
}
/**
* 计算元素的哈希索引(确保非负)
*/
public int hash(Object value) {
if (value == null) {
return 0;
}
int hash = value.hashCode();
// 种子参与计算,生成不同哈希结果
int result = (int) ((seed * hash) % size);
return Math.abs(result); // 避免负索引
}
}
/**
* 1. 添加元素到布隆过滤器
* 逻辑:用所有哈希函数计算索引,将对应位置设为1
*/
public void add(Object value) {
for (HashFunction f : functions) {
bits.set(f.hash(value), true);
}
}
/**
* 2. 判断元素是否在布隆过滤器中
* 逻辑:所有哈希索引均为1 → 可能存在;否则 → 一定不存在
*/
public boolean contains(Object value) {
if (value == null) {
return false;
}
boolean isPossibleExist = true;
for (HashFunction f : functions) {
// 短路判断:只要一个索引为0,直接返回false
isPossibleExist = isPossibleExist && bits.get(f.hash(value));
if (!isPossibleExist) {
break;
}
}
return isPossibleExist;
}
}代码核心说明
- 位数组大小(DEFAULT_SIZE):直接影响空间占用和误判率,数据量越大,需设置更大的数组(可通过公式计算最优值)。
- 哈希种子(SEEDS):多个种子生成不同哈希函数,减少"哈希碰撞",平衡误判率(通常取5-10个种子即可)。
- add/contains方法:严格遵循"多哈希映射"逻辑,确保特性不被破坏。
2. 实战:布隆过滤器 + Redis + 数据库 三级防穿透
在高并发场景中,恶意查询"不存在的ID"会穿透Redis直达数据库,导致数据库压力骤增。通过"布隆过滤器前置拦截+空值缓存",可彻底解决该问题。
java
/**
* 用户查询服务:实现"布隆过滤器→Redis→数据库"三级过滤
*/
public class UserService {
// 注入依赖(实际项目中用Spring等框架注入)
private BloomFilter bloomFilter;
private RedisClient redisClient;
private UserDao userDao;
// 缓存过期时间(30分钟,可根据业务调整)
private static final int CACHE_EXPIRE_SECONDS = 30 * 60;
/**
* 根据用户ID查询用户信息(核心方法)
*/
public String getUserById(String userId) {
// 1. 第一级:布隆过滤器预判断(绝对拦截不存在的ID)
if (!bloomFilter.contains(userId)) {
System.out.println("布隆过滤器拦截:ID不存在 → " + userId);
return null; // 直接返回,不进入后续流程
}
// 2. 第二级:Redis缓存查询(命中则直接返回,避免查库)
String userInfo = redisClient.get("user:" + userId);
if (userInfo != null) {
System.out.println("Redis命中:返回用户信息 → " + userId);
return userInfo;
}
// 3. 第三级:数据库查询(缓存未命中时查库,并更新缓存)
userInfo = userDao.findUserById(userId);
if (userInfo != null) {
// 数据库存在该用户:缓存真实数据
redisClient.set("user:" + userId, userInfo, CACHE_EXPIRE_SECONDS);
System.out.println("数据库命中:缓存并返回用户信息 → " + userId);
} else {
// 数据库不存在该用户(布隆过滤器假阳性):缓存空值(短期)
redisClient.set("user:" + userId, "", 60); // 空值缓存1分钟,避免重复穿透
System.out.println("数据库未命中:缓存空值 → " + userId);
}
return userInfo;
}
}防穿透核心设计
- 布隆过滤器前置拦截:对"绝对不存在"的ID直接返回,避免请求到达Redis和数据库,从源头减少无效流量。
- 空值缓存机制:针对布隆过滤器的"假阳性"(判断存在但实际不存在),缓存空值1分钟,防止同一ID重复穿透数据库。
- 三级过滤顺序:严格遵循"布隆过滤器→Redis→数据库"的顺序,层层过滤高成本操作,最大化减轻数据库压力。
三、布隆过滤器的高频落地场景(进阶)
除了Redis缓存穿透,布隆过滤器在分布式系统、网络安全、存储优化等领域也有广泛应用,核心都是"用极小空间快速排除不存在的情况"。
1. 互联网与大数据领域
场景1:分布式缓存预热与空值过滤(Redis Cluster)
- 问题:分布式缓存中,大量key同时过期(缓存雪崩前兆)或频繁查询不存在的key,会导致请求穿透到数据库。
- 解决方案 :
- 缓存预热:大促前(如双11),将所有"有效缓存key"(如商品ID、用户ID)批量写入布隆过滤器。
- 请求拦截:请求到来时,先查布隆过滤器------不存在则直接返回,存在再查缓存/数据库。
- 示例:电商大促前,将1000万商品ID写入布隆过滤器(仅需约140MB内存),减少90%以上的无效数据库请求。
场景2:分布式数据库分片路由(MySQL分库分表)
- 问题:分库分表后,查询某条数据需先确定"在哪个分片",传统方案需维护"分片-数据范围"映射表,查询成本高。
- 解决方案 :
- 为每个分片维护一个布隆过滤器,存储该分片内的所有主键(如用户ID)。
- 查询时,依次检查各分片的过滤器------不存在则跳过该分片,存在再查询。
- 优势:减少无效分片的访问次数,例如10个分片仅需检查2-3个,大幅提升查询效率。
2. 网络与安全领域
场景1:网络爬虫URL去重
- 问题:爬虫爬取亿级URL时,用HashMap存储已爬URL会占用数百GB内存,资源开销极大。
- 解决方案 :
- 将已爬URL写入布隆过滤器(误判率0.1%,1亿URL仅需140MB内存)。
- 新URL爬取前先查过滤器------不存在则爬取并写入,存在则跳过。
- 妥协与弥补:接受极低的假阳性(少数未爬URL被误判为已爬),可通过"增量爬取"(间隔一段时间重新检查)弥补。
场景2:垃圾邮件/恶意IP过滤
- 垃圾邮件过滤 :
- 邮件服务商(如Gmail)维护"垃圾邮件发送者邮箱/域名"的布隆过滤器。
- 新邮件到来时,先查过滤器------不存在则正常投递,存在则触发二次验证(如内容检测),避免误判正常邮件。
- 恶意IP拦截 :
- 服务器(Web服务器/API网关)维护"恶意IP"(频繁攻击、刷接口)的布隆过滤器。
- IP请求到来时,先查过滤器------不存在则允许访问,存在则拒绝或要求验证码。
3. 存储与文件系统领域
场景1:磁盘/SSD缓存效率优化
- 问题:存储系统(如操作系统页缓存、SSD缓存)中,直接查询缓存索引(哈希表)耗时较长,尤其缓存数据量大时。
- 解决方案 :
- 在缓存索引前加一层布隆过滤器,存储"已缓存数据的标识"(如数据块哈希值)。
- 判断数据是否在缓存时,先查过滤器------不存在则直接读磁盘,存在再查缓存索引。
- 优势:减少缓存索引的无效查询,提升存储IO效率(尤其适合高频小文件读取场景)。
场景2:HBase数据库RowKey存在性判断
- 问题:HBase查询"某RowKey是否存在"时,传统方式需扫描对应Region(数据分区),若RowKey不存在,会浪费大量IO资源。
- 解决方案 :
- HBase默认在每个Region的元数据中嵌入布隆过滤器,存储该Region内所有RowKey的哈希值。
- 查询RowKey时,先查Region的过滤器------不存在则直接返回"不存在",存在再扫描Region。
- 效果:减少90%以上的无效Region扫描,大幅降低HBase的IO开销。
4. 其他高频场景
场景1:推荐系统"已推荐内容"过滤
- 需求:短视频/商品推荐系统需避免向用户重复推荐同一内容(如用户已看过的视频)。
- 实现 :
- 为每个用户维护一个"已推荐内容ID"的布隆过滤器。
- 推荐新内容前,先查过滤器------不存在则加入推荐列表并写入过滤器,存在则跳过。
- 妥协:接受极低的假阳性(少数未推荐内容被误判为已推荐),用户敏感度低,不影响体验。
场景2:账号系统"用户名/手机号已注册"判断
- 问题:高并发注册场景(如电商新用户活动),直接查询数据库判断"用户名是否已注册",会导致数据库压力骤增。
- 实现 :
- 在数据库前部署布隆过滤器,存储所有"已注册的用户名/手机号"。
- 注册请求到来时,先查过滤器------不存在则查数据库确认(避免假阳性导致误判"可注册"),存在则直接返回"已被占用"。
- 优势:大幅减轻数据库压力,例如100万注册请求,仅10%需查数据库确认。
四、所有应用场景的核心共性
布隆过滤器的所有落地场景,都围绕一个核心需求:在"海量数据"场景下,用"极小的空间"和"极快的速度",快速排除"绝对不存在"的情况,从而减少后续高成本操作(如数据库查询、磁盘IO、网络请求)。
同时,这些场景都满足两个关键前提:
- 可接受"极低的假阳性"(如重复推荐、误判未注册账号);
- 绝对不能接受"假阴性"(如漏判垃圾邮件、误将已注册账号判为可注册)。
这正是布隆过滤器"零假阴性"特性的核心价值------在"效率优先、可接受微小误差"的场景中,它是无可替代的高效工具。
希望以上内容能帮你彻底理解布隆过滤器的原理与应用!我是云喜,我们下次再见~