有没有经历过这样的恐怖时刻?618大促前夕,你信心满满,感觉自己的系统坚如磐石。活动一开始,流量像钱塘江大潮一样涌来,然后...监控警报响得跟过年放鞭炮一样,数据库CPU直接飙到100%,页面加载慢得像回到了2G网时代。
恭喜你,大概率是缓存这哥们没顶住,给你上演了一出"缓存三连"的精彩戏码。
别慌,今天咱们就来好好盘一盘缓存世界里最著名的三座大山:缓存穿透、缓存击穿、缓存雪崩。看完这篇,你就能把它们治得服服帖帖,让你的系统在流量洪峰前稳如老狗。
先唠两块钱的:缓存是个啥?
在正式开打之前,咱得先统一一下思想。
缓存(Cache),说白了就是数据库前面的一个"临时小本本"。
- 核心思想:把那些读多写少、计算还贼耗时的数据,从慢吞吞的数据库(硬盘)里捞出来,放到速度飞快的内存里。
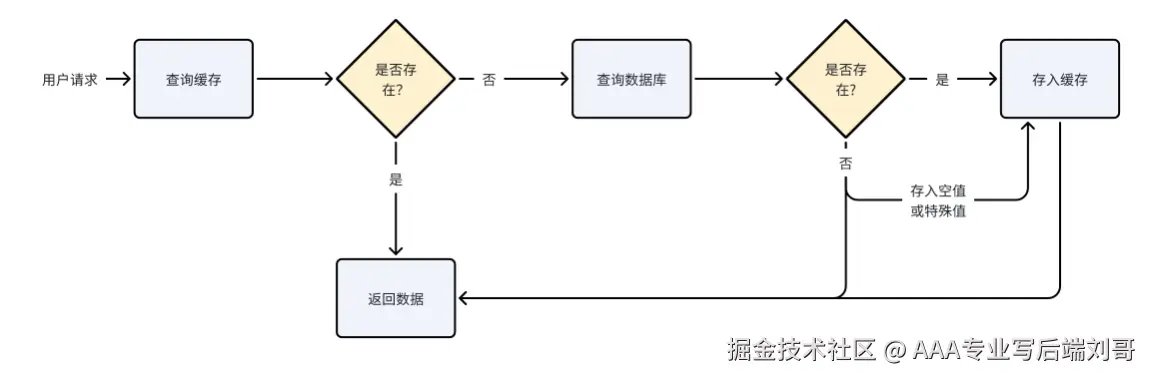
- 工作流程(经典读场景) :
- 请求来了,先屁颠屁颠地去缓存里查。
- 缓存有(命中):太好了!直接返回数据,又快又省力。
- 缓存没有(未命中):唉,只能苦哈哈地去数据库查。
- 从数据库查到数据后,塞一份到缓存里,方便下一个兄弟来查。
- 最后再把数据返回回去。
你看,用了缓存之后,大部分请求根本不会去打扰数据库大佬,系统性能直接起飞🛫。但这小本本要是没用好,那就不是助力,而是"爆破鬼才"了。
第一座大山:缓存穿透(Cache Penetration)
现象 :缓存和数据库里,都!没!有!这!个!数!据! 导致请求每次都像穿透了缓存一样,直接怼到数据库上。
举个栗子🌰 : 有个坏蛋,疯狂请求 GET /user/=-1234567。这user_id明显不存在啊!你的缓存里肯定没有,数据库里也不可能有。于是,这个请求每次都会命中数据库。如果这坏蛋用脚本搞个几万次并发请求,你的数据库可能就直接口吐白沫,当场宕机了。
危害:利用根本不存在的数据发起攻击,打崩数据库。
解决方案 :给他堵上!
- 接口层增加校验:大哥,你先看看请求合不合法吧!比如id<=0的直接拦截返回,别往下走了。
- 缓存空对象(Cache Null Object) :就算在数据库没查到,我也在缓存里把这个诡异的key存起来,值就设为
null(或者一个特殊标记),并给它一个较短的过期时间 。下次同样的请求过来,缓存里就有东西了,虽然是个null,但也能保护数据库。- 缺点 :可能会在缓存里存一堆没用的
null键,如果被攻击的key是随机的大量字符串,效果会打折扣。
- 缺点 :可能会在缓存里存一堆没用的
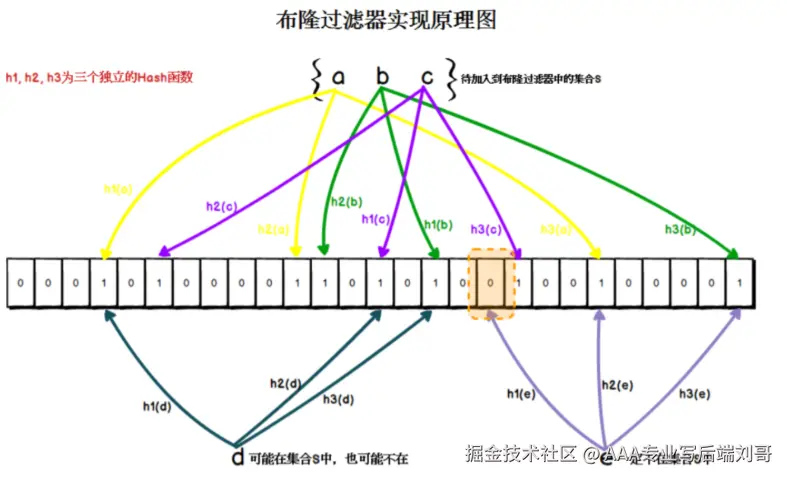
- 布隆过滤器(Bloom Filter) :这是对付穿透的大杀器!
-
它就是一个巨大的二进制位数组(bitmap)和一系列哈希函数。
-
工作原理 :把所有可能存在的key提前放到布隆过滤器里。当一个请求来了,先用布隆过滤器判断一下这个key是否存在。
- 如果不存在 :那这个key肯定不存在,直接返回
null,完美拦截! - 如果存在 :这个key不一定真的存在(有极小的误判率),那就继续后面的缓存、数据库查询流程。
- 如果不存在 :那这个key肯定不存在,直接返回
-
优点:内存占用极小,效率极高,能从源头彻底堵住恶意攻击。
-
第二座大山:缓存击穿(Cache Breakdown)
现象 :某个热点key (比如某个爆款商品详情)在缓存过期的一瞬间,有大量的请求同时涌来。此时缓存没了,所有请求都跑到数据库上去,相当于把这个热点数据直接"击穿"了。
注意 :这个key是真实存在的,只是刚好"卡点"过期了。
危害:秒杀等场景下,一个热点key的失效可能导致数据库瞬间压力巨大。
解决方案 :让请求排队 ,或者永不过期。
- 互斥锁(Mutex Lock) :只让一个请求去干活!
- 当发现缓存失效时,不是所有人都能去查数据库。先去抢一把分布式锁。
- 抢到锁的请求,负责去数据库加载数据,并回填到缓存中。
- 没抢到锁的请求呢?要么休眠一下稍等片刻,要么直接返回个"稍后再试"的提示,等缓存有了再来读。
- 优点:能极大地减轻数据库压力。
- 缺点:有点麻烦,引入了锁的逻辑,性能上会有细微损耗。
- 逻辑过期(Logical Expiration) / "永不过期" :
- 咱们不设置物理过期时间(TTL),而是在缓存value里藏一个逻辑过期时间。
- 请求来时,发现数据逻辑上过期了,就像上面一样,抢个锁去后台异步更新缓存。
- 在更新期间,其他请求仍然可以先返回旧的缓存数据,虽然有点"脏",但不会造成卡顿。
- 优点:用户体验丝滑,不会出现卡顿等待。
- 缺点:实现复杂,需要保证数据的最终一致性。
小结:击穿是"点"的问题,是针对某一个热点key的。
第三座大山:缓存雪崩(Cache Avalanche)
现象 :大量的缓存key在同一时间过期 ,或者Redis缓存服务直接挂了。导致瞬间所有请求都砸向数据库,数据库压力山大,直接崩溃,引起整个系统崩溃,就像雪崩一样,连锁反应,一发不可收拾。
危害:比击穿更恐怖,是"面"的问题,可能导致整个系统瘫痪。
解决方案 :错开过期时间 + 高可用。
- 给过期时间加随机值 :这是预防雪崩最简单有效的办法。比如原本统一设置1小时过期,现在改成
1小时 + [0-300秒]的随机时间。这样就能保证key不会在同一时间点集体去世,而是均匀地过期。 - 构建高可用的缓存集群:比如Redis的哨兵(Sentinel)模式或者集群(Cluster)模式。就算一台Redis节点挂了,也能自动进行主从切换,保证缓存服务整体可用,不至于全盘崩溃。
- 服务降级和熔断 :借助Hystrix、Sentinel等工具。当检测到数据库快要被拖垮时,对请求进行熔断,直接返回一个预设的默认值(比如"系统繁忙,请稍后再试")或者兜底数据,保护数据库不死,保住大部分用户的基本可用性。
总结一下
| 问题类型 | 问题描述 | 核心解决方案 |
|---|---|---|
| 穿透 | 查不存在的数据,缓存和DB都没有 | 堵:参数校验、缓存空对象、布隆过滤器 |
| 击穿 | 热点key 在过期瞬间,被高并发访问 | 散:互斥锁、逻辑过期 |
| 雪崩 | 大量key同时过期 或缓存服务宕机 | 均:过期时间随机、集群高可用、服务熔断降级 |
好了,各位后端大佬,缓存世界的三座大山已经给大家铲平了!下次面试或者设计系统时,再问到这些问题,你就可以嘴角上扬,微微一笑,绝对不抽,然后从容地说出你的解决方案。
大家还有什么应对高并发的骚操作?或者在实践中踩过哪些坑?欢迎在评论区一起交流摸鱼(学习)心得!
希望这篇博客对你有帮助!如果觉得不错,点个赞再走吧~