| 大家好,我是工藤学编程 🦉 | 一个正在努力学习的小博主,期待你的关注 |
|---|---|
| 实战代码系列最新文章😉 | C++实现图书管理系统(Qt C++ GUI界面版) |
| SpringBoot实战系列🐷 | 【SpringBoot实战系列】SpringBoot3.X 整合 MinIO 存储原生方案 |
| 分库分表 | 分库分表之实战-sharding-JDBC分库分表执行流程原理剖析 |
| 消息队列 | 深入浅出 RabbitMQ-RabbitMQ消息确认机制(ACK) |
写在前面,博主本身也没有AI大模型知识,因此希望可以通过自己学习然后以写文章的形式向大家同样想零基础学习大模型的同学进行互相交流,欢迎大家在评论区打出自己的疑问或者本文不正确的地方,我们一起学习
本文章目录
- 零基础学AI大模型之读懂AI大模型:从"能聊天"到"能干活",拆解背后逻辑与落地真相
-
- 一、什么是AI大模型?先搞懂LLM的本质
-
- [1. 大模型的"两大过人之处":学得多、脑更活](#1. 大模型的“两大过人之处”:学得多、脑更活)
- [2. 大模型的核心能力:不止"聊天",更是"全能选手"](#2. 大模型的核心能力:不止“聊天”,更是“全能选手”)
- 二、为什么大模型能回答问题?它不是"记答案",而是"找规律"
-
- [1. 训练过程:把"知识"变成"规律手册"](#1. 训练过程:把“知识”变成“规律手册”)
- [2. 回答问题:像"超级猜谜手"拼答案](#2. 回答问题:像“超级猜谜手”拼答案)
- 三、大模型不只是"聊天工具":智能体如何解决实际问题?
- 四、解惑:为什么企业不直接调用大模型API?
-
- [1. 大模型API的3个核心局限](#1. 大模型API的3个核心局限)
- [2. 企业真正要开发的是AI智能体:大模型的"升级版"](#2. 企业真正要开发的是AI智能体:大模型的“升级版”)
- 五、主流大模型横向对比:选对的,不选"贵的"
- 最后:AI大模型的核心不是"越复杂越好",而是"越实用越好"
零基础学AI大模型之读懂AI大模型:从"能聊天"到"能干活",拆解背后逻辑与落地真相
日常用ChatGPT写文案、用文心一言查政策、用讯飞星火改代码时,你或许会好奇:这些"聪明"的工具背后,"AI大模型"到底是什么?为什么它能回答我们的各种问题?甚至企业里说的"开发大模型",真的是从头造一个"大脑"吗?
今天就用通俗的语言,把AI大模型的核心逻辑、能力边界和落地场景讲透,最后再给大家一份主流模型的选择指南。
一、什么是AI大模型?先搞懂LLM的本质
我们常说的"AI大模型",核心是LLM(Large Language Model,大语言模型) ------字面意思是"处理语言的大型模型",但它的能力早已超出"语言"本身,更像一个"超级智能学习者"。
1. 大模型的"两大过人之处":学得多、脑更活
普通人的学习,是读几十本课本、几千篇文章;而大模型的"学习",是把全网上的文字、图片、视频、专业论文、代码甚至历史数据"吞"一遍------相当于读完了几千万本"超级厚书",这些海量信息构成了它的"知识库"。
更关键的是它的"大脑结构":普通人脑有几十亿神经元,而大模型的"人工神经元"(业内叫"参数")能达到几百亿、几千亿甚至万亿级。参数越多,意味着它能处理越复杂的逻辑------比如读懂你话里的"弦外之音"(比如"这方案我再想想"可能是"不太满意"),或是关联不同领域的知识(比如用物理学原理解释"为什么夏天的冰饮会出汗")。
2. 大模型的核心能力:不止"聊天",更是"全能选手"
它的能力覆盖了我们工作生活的很多场景,不是单一的"对话工具":
- 文本生成:写文案、编故事、写代码、生成合同模板,甚至模仿你的语气写邮件;
- 语义理解:总结长文(比如把10页报告缩成300字)、回答问题(比如"个税专项附加扣除有哪些")、给内容分类(比如把客户反馈分成"投诉""建议""咨询");
- 推理能力:做数学题(比如"计算复利收益")、逻辑判断(比如"分析两个方案的利弊")、甚至帮你排错(比如"为什么这段Python代码跑不起来");
- 多模态能力:看图片(比如"分析这张财报图表的关键信息")、生图片(比如"画一张'未来城市交通'的插画")、处理语音(比如"把会议录音转文字并生成纪要")。
我们平时用的ChatGPT、文心一言、讯飞星火,其实是大模型的"应用窗口"------就像手机APP背后是手机系统,这些工具背后的核心,就是大模型。
二、为什么大模型能回答问题?它不是"记答案",而是"找规律"
很多人以为大模型"背下了所有答案",其实不然------它的核心逻辑是:先吃透海量"语言规律",再用规律"拼出合理答案"。
1. 训练过程:把"知识"变成"规律手册"
大模型的"学习期"(业内叫"训练"),本质是"啃规律":它会从海量数据里提炼出各种关联------比如"月亮"和"地球绕转""反光"相关,"圆缺"和"视线遮挡"相关;"苹果"和"水果""红色/绿色""甜"相关,"橘子"和"柑橘类""酸甜""剥皮吃"相关。
这些规律会被转化成大模型内部的"参数"------可以理解为一本超级厚的"规律手册":参数越多,手册里的规则越细,比如不仅能区分"苹果和橘子",还能区分"红富士和嘎啦果"。
2. 回答问题:像"超级猜谜手"拼答案
当你提问时,大模型不会"回忆某个固定答案"(它甚至不"记"具体内容),而是按以下步骤"拼答案":
- 抓关键词:比如你问"月亮为什么会圆缺?",它先锁定"月亮""圆缺"两个核心词;
- 查"规律手册":从手册里调出所有和"月亮""圆缺"相关的规律(月球绕地球转、月球反光、地球遮挡光线);
- 计算合理组合:把这些规律按逻辑串联,生成最符合常识的回答------"因为月球围绕地球公转,地球会遮挡太阳照射到月球的光线,我们看到的月球反光面变化,就形成了圆缺。"
简单说:它没记住"标准答案",但记住了"怎么说才合理"。就像一个听了10万个故事的人,哪怕你问一个他没听过的新问题,也能顺着逻辑给你一个靠谱的回答。
三、大模型不只是"聊天工具":智能体如何解决实际问题?
光会"聊天"的大模型,还无法满足企业的实际需求------比如"订机票""生成销售报表并发邮件"。这时候,AI智能体(Agent) 才是大模型的"落地形态"。
先看几个真实案例,感受智能体的价值:
- 城市公共服务:成都新津的"民意速办"系统,居民用语音/拍照反馈问题(比如"小区路灯坏了"),智能体能自动解读诉求、匹配对应部门,工单响应效率提升5倍;广州黄埔区的政务智能体整合了2000多项服务,能精准识别你要办"社保补缴"还是"营业执照注销",实现"咨询-预约-办理"一站式,连夜间都能响应;
- 金融科技:智能投资顾问会分析市场趋势和你的风险偏好,生成个性化投资组合,年化收益比传统方案提升15%;银行的智能客服响应速度快了3倍,客户满意度从72%涨到89%;
- 在线教育:AI会根据学生的错题生成"知识图谱",比如发现你"英语时态总错",就定制针对性练习,薄弱学生的词汇量提升速度快了2倍;智能作业批改能从语法、逻辑、文采多维度评作文,帮老师减少60%的工作量。
这些案例的核心,是智能体把大模型的"语言能力"延伸成了"执行能力"------它不只是"说",还能"做"。
四、解惑:为什么企业不直接调用大模型API?
很多人会问:OpenAI、通义千问都提供API(接口),直接调用不就能用了吗?为什么企业还要花钱开发?
答案是:直接调用API的短板太明显,撑不起复杂的生产场景。
1. 大模型API的3个核心局限
-
"只会说,不会做":任务理解与执行脱节
API能生成文本,但无法自主调用工具、访问数据库或操作软件。比如你问"订一张明天北京飞上海最便宜的机票",API只能回复"建议去某平台比价",却不能真的查价格、填信息、下单;再比如你要"生成Q2销售报表",API能写报表框架,却不能读取公司数据库里的销售数据,更不能导出成Excel。
-
"记不住事":缺乏持续学习与记忆
API是"无状态服务"------每次交互都是"从零开始"。比如你之前告诉它"我喜欢靠窗的机票",下次再问订机票,它不会记得这个偏好;客服用API接待客户,客户说"我昨天咨询过贷款",API也无法调取之前的对话记录,导致客户要重复说明。
-
"不安全":存在合规与数据风险
直接用第三方API,需要暴露API密钥,一旦泄露可能被恶意调用(比如生成违规内容);更关键的是,企业的核心数据(比如银行客户的资产信息、医院的病历、公司的财务数据)不能上传到第三方服务器,否则会违反数据安全法规(比如《数据安全法》),导致信息泄露。
2. 企业真正要开发的是AI智能体:大模型的"升级版"
所谓"AI智能体(Agent)",是给大模型加上"手脚""记忆"和"规划能力",让它从"聊天工具"变成"能干活的助手"。它的核心公式是:
智能体 = 大模型(Brain,负责思考) + 工具(Tools,负责执行) + 记忆(Memory,负责记信息) + 规划(Planning,负责拆任务)
举个例子:当你说"分析Q2销售数据,生成报告并邮件发给团队"------
-
纯API调用:只能生成"报告应该包含销售额、增长率、区域分布"这样的文本;
-
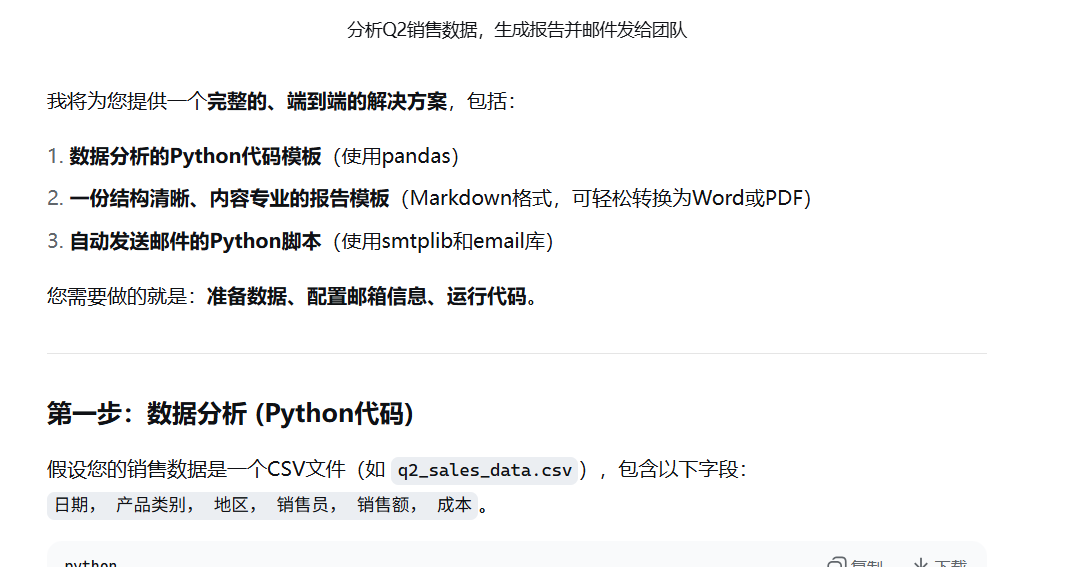
-
智能体的执行流程:
- 规划任务:把"发报告"拆成"读数据→分析→画图→写报告→发邮件"5步;
- 调用工具:用Python脚本读取公司数据库的销售数据,用Matplotlib画增长率图表;
- 生成内容:大模型基于数据写报告,结合图表整理成PDF;
- 执行动作:调用邮件API,自动填写团队邮箱地址,发送报告;
- 记忆信息:如果下次你要"分析Q3数据",它会记得上次的报告格式和收件人。
五、主流大模型横向对比:选对的,不选"贵的"
不同大模型的优势差异很大,没有"绝对的最好",只有"最适合的场景"。下面整理了当前主流模型的核心能力与适用场景,帮你快速匹配需求:
| 核心需求 | 推荐模型 | 核心优势 | 适用人群/企业 | 注意点 |
|---|---|---|---|---|
| 复杂推理与工具调用 | OpenAI O3 / DeepSeek R1 | 擅长自主分解复杂任务(比如数学证明、代码调试),多步推理能力强 | 需做复杂工具开发的团队(如做AI编程助手、数学教育工具) | API调用成本较高,适合核心业务场景 |
| 多模态内容生成(图文音视频) | 通义千问 Qwen2.5-Omni / Gemini 2.5 | 支持文本、图片、视频、语音全模态交互,能实时生成短视频、教育课件 | 做内容创作的团队(如短视频公司、教育机构) | 视频生成分辨率和时长有限,需结合后期工具 |
| 中文专业领域(法律/金融) | 通义千问 Qwen2.5 / DeepSeek V3 | 中文语义理解准确率达92%,能结构化输出合同审查结果、生成金融量化策略 | 中文企业(如律所、券商、银行) | 专业领域需结合行业数据微调,效果更好 |
| 企业级长文本处理 | Claude 3.7 Sonnet / Qwen2.5-Turbo | 支持200K+ tokens上下文(相当于15万字),能分析法律文书、学术论文 | 做法律、科研、咨询的企业(如律所、高校、咨询公司) | 长文本处理速度较慢,需预留响应时间 |
| 低成本本地部署 | Llama 3 / DeepSeek R1 Distill | MIT协议开源(可免费商用),参数覆盖14B-70B,适合中小企业本地部署 | 预算有限、需保护核心数据的中小企业 | 大参数模型(70B)对硬件配置要求较高 |
最后:AI大模型的核心不是"越复杂越好",而是"越实用越好"
看完这些,你会发现:AI大模型的本质是"用海量规律解决问题",而它的落地关键是"智能体"------把"语言能力"变成"执行能力"。
对普通人来说,不用纠结"参数有多少",而是看"它能不能帮我省时间";对企业来说,不用盲目追求"最先进的模型",而是选"适配自己场景的方案"------比如小企业想本地部署,Llama 3就够;做中文金融业务,通义千问Qwen2.5更贴合。
未来的AI大模型,会越来越"接地气"------不是"炫技",而是悄悄融入我们的工作:帮HR筛简历、帮医生写病历、帮工程师调设备......这才是大模型真正的价值。
觉得有用请点赞收藏!
如果有相关问题,欢迎评论区留言讨论~