
1. 一段话总结
论文针对文本条件扩散模型中实体与视觉属性绑定错误 (如"粉色向日葵和黄色火烈鸟"误生成黄色向日葵与粉色火烈鸟)的核心问题,提出SynGen方法 :首先通过spaCy句法解析器提取 prompt 中的实体名词及其修饰词(如颜色、材质),再设计正负结合的注意力损失函数 (正损失最大化实体-修饰词注意力图重叠,负损失最小化其与无关词的重叠),在推理阶段前25个去噪步骤(共50步)中优化 latent 变量(无需模型重训练或微调)。该方法在ABC-6K、A&E数据集及新构建的DVMP挑战集 上经人类评估,在概念分离(如A&E集得分38.42,远超基线)和视觉吸引力上显著优于Stable Diffusion、Structured Diffusion等基线,Proper Binding指标最高达94.76%(A&E集),部分场景准确率翻倍,最终证明句法结构信息能高效提升文本到图像生成的忠实度。
2. 思维导图(mindmap)
mindmap
## 一、研究背景与核心问题
- 模型现状:文本条件扩散模型(如Stable Diffusion)生成逼真图像,但存在缺陷
- 核心问题:语言绑定(实体-修饰词)与视觉绑定不匹配
- 问题表现:语义泄露(prompt内/外)、属性遗漏、实体混淆
- 问题根源:CLIP等文本编码器无法编码**句法结构**,扩散过程"盲目"
- 现有方法不足:未聚焦"实体-修饰词绑定"这一核心痛点
## 二、SynGen方法设计
- 核心思路:推理时融入句法信息,通过注意力图对齐优化生成
- 步骤1:实体-修饰词识别
- 工具:spaCy的transformer-based依赖解析器
- 提取内容:实体名词(非修饰性名词)+ 修饰词集合(amod/compound等6类关系)
- 步骤2:交叉注意力损失函数
- 正损失(L_pos):最小化实体-修饰词注意力图距离(对称KL散度)
- 负损失(L_neg):最大化实体-修饰词与无关词注意力图距离
- 总损失:L = L_pos + L_neg
- 工作流:50步去噪→前25步用损失梯度更新latent→U-Net继续去噪
## 三、实验设计
- 基线方法:Stable Diffusion 1.4、Structured Diffusion、Attend-and-Excite(A&E)
- 数据集(共3个)
- ABC-6K:3.2K自然提示+3.2K交换修饰词提示,采样600个
- A&E数据集:3类提示,采样33(类型1)+144(类型2)个,排除类型3
- DVMP(新挑战集):600个提示,多修饰词(1-3个)、多类型(颜色/材质等)
- 评估方法
- 人类评估(AMT):3名评估者,测"概念分离""视觉吸引力",多数投票
- 细粒度评估:Proper Binding(正确绑定)、Improper Binding(错误绑定)、Entity Neglect(实体遗漏)
## 四、实验结果
- 定量结果:SynGen全数据集排名第一(表1/表2)
- 概念分离:A&E集38.42、DVMP集24.84、ABC-6K集28.00
- Proper Binding:A&E集94.76%、DVMP集74.90%、ABC-6K集63.68%
- 定性结果:解决语义泄露、属性遗漏、实体混淆(如"baby rabbit"不误判为人类婴儿)
- 消融实验:正负损失结合最优,单独使用会导致语义泄露或实体遗漏
## 五、局限性与结论
- 局限性:修饰词增多性能下降(但慢于基线)、依赖解析器质量、生成速度慢(比SD慢44%)
- 核心贡献:推理时句法融合新方法、DVMP新数据集
- 结论:句法信息显著提升生成忠实度,为文本到图像研究提供新方向3. 详细总结
1. 引言:问题提出与研究动机
1.1 模型现状
文本条件扩散模型(如Stable Diffusion、DALL-E 2)能生成高逼真度图像,但存在实体-属性绑定错误 ------即 prompt 中"实体名词-修饰词"的语言绑定,与生成图像中"物体-视觉属性"的视觉绑定不匹配。
1.2 问题具体表现

- 语义泄露:修饰词错误迁移到其他实体(如"粉色向日葵+黄色火烈鸟"生成黄色向日葵),或迁移到 prompt 未提及的物体;
- 属性遗漏 :完全未生成 prompt 中的修饰词(如"带角狮子+斑点猴子"未生成"斑点");
1.3 问题根源
扩散模型依赖的文本编码器(如CLIP)无法编码句法结构 ,导致扩散过程对"实体-修饰词绑定"呈"盲目"状态。
1.4 现有方法不足
此前方法(如Structured Diffusion、Attend-and-Excite)仅优化 prompt 语义与视觉的映射,未聚焦"实体-修饰词绑定"这一核心痛点。
2. SynGen方法:句法引导的生成优化
2.1 核心思路
通过句法分析提取实体-修饰词关系 ,再通过注意力图对齐损失,在推理阶段引导扩散模型的视觉绑定匹配语言绑定(无需重训练模型)。
2.2 关键步骤1:实体-修饰词识别
- 工具:使用spaCy的transformer-based依赖解析器(en_core_web_trf模型);
- 提取逻辑:
- 识别"非修饰性实体名词"(对应图像中的物体,如"sunflower""flamingo");
- 递归收集修饰词集合,涵盖6类句法关系:
- amod(形容词修饰,如"red crown")、compound(复合词,如"treasure map")、nmod(名词修饰)、npadvmod(副词修饰)、acomp(形容词补语)、conj(修饰词并列,如"black and white dog")。
2.3 关键步骤2:注意力损失函数设计
损失核心目标:实体的注意力图与对应修饰词高度重叠,与无关词低重叠。
-
距离度量:采用对称Kullback-Leibler(KL)散度 ,公式为:
dist(Ai,Aj)=12DKL(Ai∥Aj)+12DKL(Aj∥Ai)dist(A_{i}, A_{j})=\frac{1}{2} D_{K L}(A_{i} \| A_{j})+\frac{1}{2} D_{K L}(A_{j} \| A_{i})dist(Ai,Aj)=21DKL(Ai∥Aj)+21DKL(Aj∥Ai)其中AiA_iAi、AjA_jAj为归一化后的注意力图,DKLD_{KL}DKL为KL散度(衡量分布差异)。
-
具体损失组成:
- 正损失(LposL_{pos}Lpos) :最小化实体-修饰词对的注意力距离(最大化重叠):
Lpos(A,S)=∑i=1k∑(m,n)∈P(Si)dist(Am,An)\mathcal{L}{pos }(A, S)=\sum{i=1}^{k} \sum_{(m, n) \in P\left(S_{i}\right)} dist\left(A_{m}, A_{n}\right)Lpos(A,S)=i=1∑k(m,n)∈P(Si)∑dist(Am,An)
(SiS_iSi为第i个实体-修饰词集合,P(Si)P(S_i)P(Si)为集合内所有(修饰词m,实体n)对) - 负损失(LnegL_{neg}Lneg) :最大化实体-修饰词对与无关词的注意力距离(最小化重叠):
Lneg=−∑i=1k1∣U(Si)∣∑(m,n)∈P(Si)∑u∈U(Si)12(dist(Am,Au)+dist(Au,An))\mathcal{L}{neg }=-\sum{i=1}^{k} \frac{1}{\left|U\left(S_{i}\right)\right|} \sum_{(m, n) \in P\left(S_{i}\right)} \sum_{u \in U\left(S_{i}\right)} \frac{1}{2}\left(dist\left(A_{m}, A_{u}\right)+dist\left(A_{u}, A_{n}\right)\right)Lneg=−i=1∑k∣U(Si)∣1(m,n)∈P(Si)∑u∈U(Si)∑21(dist(Am,Au)+dist(Au,An))
(U(Si)U(S_i)U(Si)为 prompt 中除SiS_iSi外的所有无关词) - 总损失 :L=Lpos+Lneg\mathcal{L}=\mathcal{L}{pos }+\mathcal{L}{neg }L=Lpos+Lneg
- 正损失(LposL_{pos}Lpos) :最小化实体-修饰词对的注意力距离(最大化重叠):
2.4 工作流
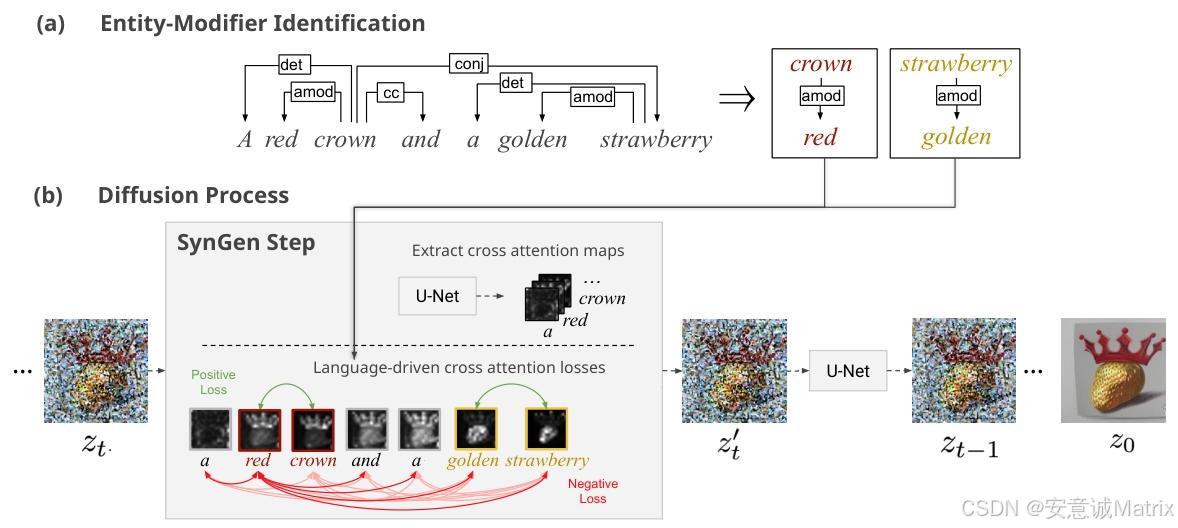
- 初始化:使用预训练扩散模型(如Stable Diffusion)的 latent 变量ztz_tzt;
- 去噪与优化:在前25个去噪步骤 (共50步)中,先通过U-Net去噪ztz_tzt,再计算注意力损失,用梯度下降更新ztz_tzt(zt′=zt−α⋅∇ztLz_{t}'=z_{t}-\alpha \cdot \nabla_{z_{t}} Lzt′=zt−α⋅∇ztL,α\alphaα为缩放因子=20);
- 后续去噪:更新后的zt′z_t'zt′输入U-Net,完成剩余25步去噪。
3. 实验设计:数据集、基线与评估
3.1 基线方法(3个)
| 基线方法 | 核心机制 |
|---|---|
| Stable Diffusion 1.4 | 基础文本条件扩散模型,无额外优化 |
| Structured Diffusion | 提取名词短语并单独编码,优化注意力映射 |
| Attend-and-Excite(A&E) | 聚焦实体遗漏,通过损失确保指定token的注意力存在 |
3.2 数据集(3个,关键数字突出)
| 数据集 | 规模与特点 | 采样方式 |
|---|---|---|
| ABC-6K | 共6.4K提示(3.2K自然组合+3.2K交换修饰词),含至少2个颜色修饰词 | 随机采样600个 |
| A&E数据集 | 3类提示: 1. 2个带颜色无生命物体; 2. 1个带颜色无生命物体+1个动物; 3. 2个动物(无修饰词,排除) | 采样33个(类型1)+144个(类型2),共177个 |
| DVMP(新挑战集) | 600个提示,特点: - 修饰词数量1-3个; - 修饰词类型多(颜色、材质、设计等,如"pink spotted panda"); - 视觉可验证、语义连贯 | 全量使用600个 |
3.3 评估方法
-
人类评估(Amazon Mechanical Turk,AMT)
- 任务:给定1个prompt+4张图像(3基线+SynGen),评估"概念分离"(图像与prompt匹配度)和"视觉吸引力";
- 规则:3名评估者,多数投票决定最优,无多数则记为"无获胜者";
- 公平性:图像顺序随机,评估者需通过资格考试(满分),时薪$10。
-
细粒度评估
- 指标定义:
- Proper Binding:正确绑定的属性数/总属性数(越高越好);
- Improper Binding:错误绑定的属性数/总属性数(越低越好);
- Entity Neglect:1 -(生成的实体数/ prompt 中实体数)(越低越好)。
- 指标定义:
4. 实验结果:定量与定性分析
4.1 定量结果(核心表格)
表1:人类评估综合结果(概念分离/视觉吸引力,单位:%)
| 数据集 | 模型 | 概念分离 | 视觉吸引力 |
|---|---|---|---|
| A&E | SynGen(ours) | 38.42 | 37.85 |
| A&E | Attend-and-Excite | 18.08 | 18.65 |
| A&E | Structured Diffusion | 4.52 | 4.52 |
| A&E | Stable Diffusion | 1.69 | 2.26 |
| A&E | 无获胜者 | 37.29 | 36.72 |
| DVMP | SynGen(ours) | 24.84 | 16.00 |
| DVMP | Attend-and-Excite | 13.33 | 12.17 |
| DVMP | Structured Diffusion | 4.33 | 7.83 |
| DVMP | Stable Diffusion | 3.83 | 7.17 |
| DVMP | 无获胜者 | 53.67 | 56.83 |
| ABC-6K | SynGen(ours) | 28.00 | 18.34 |
| ABC-6K | Attend-and-Excite | 11.17 | 10.00 |
| ABC-6K | Structured Diffusion | 5.83 | 6.33 |
| ABC-6K | Stable Diffusion | 4.83 | 7.83 |
| ABC-6K | 无获胜者 | 50.17 | 57.50 |
表2:细粒度评估结果(单位:%)
| 数据集 | 模型 | Proper Binding(↑) | Improper Binding(↓) | Entity Neglect(↓) |
|---|---|---|---|---|
| A&E | SynGen(ours) | 94.76 | 23.81 | 2.82 |
| A&E | Attend-and-Excite | 81.90 | 63.81 | 1.41 |
| A&E | Structured Diffusion | 55.71 | 67.62 | 21.13 |
| A&E | Stable Diffusion | 59.05 | 68.57 | 20.56 |
| DVMP | SynGen(ours) | 74.90 | 19.49 | 16.26 |
| DVMP | Attend-and-Excite | 52.47 | 31.64 | 10.77 |
| DVMP | Structured Diffusion | 48.73 | 30.57 | 28.46 |
| DVMP | Stable Diffusion | 47.80 | 30.44 | 26.22 |
| ABC-6K | SynGen(ours) | 63.68 | 14.37 | 34.41 |
| ABC-6K | Attend-and-Excite | 56.26 | 26.43 | 33.18 |
| ABC-6K | Structured Diffusion | 51.47 | 29.52 | 34.57 |
| ABC-6K | Stable Diffusion | 52.70 | 27.20 | 36.57 |
- 关键结论:SynGen在所有数据集的"概念分离"和"Proper Binding"上显著领先,部分场景(如A&E集Proper Binding)比基线高12.86个百分点,错误绑定率降低40个百分点以上。
4.2 定性结果


SynGen解决了基线的4类核心错误:
- 语义泄露:如"粉色时钟+棕色椅子",基线将粉色误用于椅子,SynGen正确绑定;
- 属性遗漏:如"青蛙+棕色苹果",基线未生成棕色,SynGen正确生成;
- 实体混淆:如"baby rabbit",基线误判"baby"为实体(生成人类婴儿),SynGen正确视为修饰词;
- 实体纠缠:如"蓝色狗+黑色门",基线因"狗通常为黑白"生成黑白狗,SynGen生成蓝色狗。
4.3 消融实验(损失函数有效性)
| 损失组合 | 概念分离(%) | 视觉吸引力(%) |
|---|---|---|
| 正负损失结合(L_pos+L_neg) | 27 | 22 |
| 仅正损失(L_pos) | 0 | 11 |
| 仅负损失(L_neg) | 3 | 35 |
| Stable Diffusion | 4 | 28 |
| 无获胜者 | 66 | 4 |
- 结论:正负损失必须结合------仅正损失导致语义泄露,仅负损失导致实体遗漏。
5. 局限性与核心贡献
5.1 局限性
- 性能随修饰词数量下降:修饰词越多,性能越差,但下降速度慢于基线;
- 依赖句法解析器:若解析器未正确提取实体-修饰词关系,SynGen退化为Stable Diffusion;
- 生成速度:比Stable Diffusion慢44%(SD需4秒/张,SynGen需9.76秒/张),比A&E慢10.9%(A&E需8.8秒/张)。
5.2 核心贡献
- 方法创新:提出推理阶段通过"句法分析+注意力损失"优化实体-属性绑定的新方法,无需重训练;
- 数据集创新:构建DVMP挑战集,填补"多修饰词、多类型修饰词"评估空白;
- 实证价值:证明句法结构能显著提升文本到图像生成的忠实度,为后续研究提供方向。
4. 关键问题与答案
问题1:SynGen相比现有注意力干预方法(如Attend-and-Excite),在解决"实体-属性绑定错误"上的核心创新差异是什么?
答案 :两者的核心差异在于优化目标与句法信息的利用:
- 优化目标:Attend-and-Excite的损失目标是"确保指定实体token的注意力存在",聚焦解决"实体遗漏"问题;而SynGen的损失目标是"对齐实体-修饰词的注意力图、分离与无关词的注意力图",直接针对"实体-属性绑定错误";
- 句法信息利用:Attend-and-Excite仅通过词性标注选择实体token,未利用句法结构;SynGen通过spaCy解析器提取"实体-修饰词的句法依赖关系",并将该关系转化为注意力对齐规则,使优化过程更贴合语言逻辑,从根源上解决绑定错误。
问题2:DVMP作为新构建的挑战集,其设计特点如何弥补现有数据集的不足?SynGen在该数据集上的表现是否验证了其优势?
答案:
- 现有数据集不足:ABC-6K仅含颜色修饰词,A&E数据集修饰词数量少(多为1个)、类型单一,无法评估模型对"多修饰词、多类型修饰词"的绑定能力;
- DVMP的设计特点:
- 修饰词数量:1-3个(如"blue furry spotted bird"),可测试模型对复杂绑定的处理;
- 修饰词类型:涵盖颜色(pink)、材质(wooden)、设计(checkered)、状态(sleepy)等,超出单一颜色范畴;
- 语义控制:视觉可验证(避免"big"等主观修饰词)、语义连贯(避免"sliced bowl"等无意义prompt);
- SynGen的优势验证:在DVMP集上,SynGen的"概念分离"得分(24.84%)是Attend-and-Excite(13.33%)的1.86倍,Proper Binding(74.90%)比基线最高(A&E的52.47%)高22.43个百分点,证明其在"多修饰词、多类型修饰词"的复杂场景下,仍能保持优异的绑定性能,弥补了现有数据集未覆盖的评估空白。
问题3:SynGen的性能受哪些关键因素影响?其"推理阶段优化"的设计为何选择"前25个去噪步骤"进行干预,而非全部50步?
答案:
-
影响SynGen性能的关键因素:
- 修饰词数量:修饰词越多(如3个),负损失可能过大,导致latent变量偏离训练分布,图像模糊或实体混淆;
- 句法解析器质量:若解析器误判修饰词关系(如将"baby rabbit"的"baby"视为实体),SynGen无法生成正确绑定,退化为Stable Diffusion;
- 缩放因子(α):α过小(如1)会导致latent更新不足,实体遗漏;α过大(如40)会导致图像模糊,视觉吸引力下降(实验中最优α=20)。
-
选择"前25个去噪步骤"干预的原因:
- 扩散模型特性:前25步(去噪早期)latent变量噪声多,此时通过损失干预,能更高效地引导注意力图的初始分布,避免后期噪声减少后干预导致的图像失真;
- 实验验证:若干预步骤<25(如15步),则绑定错误纠正不充分(如"teal spotted skateboard"未生成斑点);若干预步骤=50(全步骤),则latent变量过度偏离训练分布,生成图像模糊率显著上升(附录B.2实验结果),因此25步是"纠正绑定错误"与"保持图像质量"的最优平衡。