一、引言
随着大模型技术在本地化部署场景的普及,处理大规模中文文本任务(如超长文本总结、海量新闻分类)时,单进程执行面临算力不足、内存溢出、效率低下等核心问题。MapReduce 作为经典的 "分治 - 并行 - 聚合" 范式,无需依赖分布式集群,即可通过轻量化改造适配本地大模型部署场景。
前期我们已经详细的介绍了MapReduce的基本知识,今天我们以 "Qwen1.5-1.8B 驱动的超长文本总结系统" 和 "BERT 驱动的大规模新闻分类系统" 为双核心案例,深度解析 MapReduce 在本地化大模型文本处理中的体现形式、核心作用与技术实现,梳理关键知识点与执行流程,为本地化处理大规模中文文本任务提供可复用的架构参考。
二、系统介绍
今天挑选的两个案例均围绕 "本地化大模型 + 轻量化 MapReduce" 构建,解决不同场景的大规模文本处理问题:
1. 基础介绍
1.1 文本总结系统
- 核心目标:对超长技术文档(4000 + 字)进行分段总结 + 全局聚合,保证语义完整与总结效率
- 使用模型:Qwen1.5-1.8B-Chat(生成式大模型)
- 处理场景:超长文本语义总结
1.2 新闻分类系统
- 核心目标:对海量新闻文本(500 篇)进行特征提取 + 分类预测 + 效果评估,提升处理效率
- 使用模型:BERT-base-chinese(预训练分类模型)
- 处理场景:大规模文本分类
2. MapReduce 核心价值
2.1 文本总结系统
- 分治拆解:将 4000 + 字超长文档拆分为 4 个子文本(1000 字 / 段),避免单进程处理超长文本导致的内存溢出 / 推理超时
- 并行计算:多线程并行生成子文本总结,充分利用 CPU 多核资源,提升总结效率
- 结果聚合:汇总子文本总结,生成逻辑连贯的全局总结,保证语义完整性
- 容错兼容:单个子文本总结失败时返回错误提示,不影响其他子任务 / 最终聚合
2.2 新闻分类系统
- 分治拆解:将 500 篇新闻拆分为多个子集(按 CPU 核心数分片),避免单进程处理海量文本特征提取的算力瓶颈
- 并行计算:多进程并行提取新闻特征 / 预测类别,降低整体处理耗时
- 结果聚合:聚合特征数据训练全局分类器、聚合预测结果完成多维度评估,保证结果统一性
- 容错兼容:BERT 特征提取失败时自动降级为简单特征,单条子任务失败不中断整体流程
三、文本总结系统
1. MapReduce 实现
1.1 Map 阶段(map_task)
- **核心作用:**并行完成子文本的语义总结,解决超长文本单次总结的精度和效率问题。
- **输入:**拆分后的子文本(共 4 段,每段 1000 字左右)+ Qwen1.5 推理管道 + 子文本序号。
- 处理逻辑:
-
- 为每个子文本生成专属提示词(指定序号、总结要求:100 字内、核心信息不遗漏);
-
- 调用 CPU 版 Qwen1.5 推理管道生成总结;
-
- 异常捕获:总结失败时返回带错误信息的结果,避免流程中断。
-
- **输出:**带序号的子文本总结(如 "第 1 段总结:大模型部署硬件推荐 NVIDIA A10 24G 显卡...")。
1.2 Reduce 阶段(reduce_task)
- **核心作用:**聚合子文本总结,生成全局完整总结,解决分段总结的碎片化问题。
- **输入:**所有 Map 阶段输出的子总结列表 + Qwen1.5 推理管道。
- 处理逻辑:
-
- 拼接所有子总结为统一文本;
-
- 生成聚合提示词(指定整合要求:逻辑连贯、300 字内、覆盖所有核心内容);
-
- 调用 Qwen1.5 生成最终总结;
-
- 异常捕获:聚合失败时返回错误信息。
-
- **输出:**全局完整的超长文档总结。
1.3 前置拆分逻辑(split_text_force_multi)
作为 MapReduce 的 "数据分片" 环节,解决超长文本拆分的均匀性与语义完整性问题:
- 优先按段落拆分,避免句子截断;
- 若拆分数量不足(<4 段),强制按句子拆分长文本;
- 兜底策略:通过均分最长文本保证至少 4 个子文本,兼顾长度均匀与语义完整。
2. 执行流程

流程步骤说明:
-
- 系统启动 - 程序初始化,加载必要的库和配置
-
- 加载文档 - 读取包含4000+字的技术文档《大模型部署实战指南》
-
- 文本分割 - 使用split_text_force_multi函数将文档平均分为4个1000字的子文本
-
- 模型初始化 - 加载Qwen1.5模型,针对CPU环境进行优化(float32精度,低内存占用)
-
- Map并行阶段 - 创建多线程并行任务,同时处理4个子文本
-
- 子文本处理 - 每个线程处理一个1000字的文本片段
-
- 生成子总结 - 每个线程使用Qwen1.5模型生成对应片段的总结
-
- Reduce聚合阶段 - 收集所有子总结结果,合并为中间总结
-
- 生成最终总结 - 使用Qwen1.5模型对中间总结进行二次提炼,生成全局完整总结
-
- 输出结果 - 格式化并输出最终总结文档
-
- 系统完成 - 释放资源,结束程序执行
该流程图展示了典型的MapReduce模式应用:Map阶段并行处理数据分片,Reduce阶段聚合中间结果。
3. 代码示例
python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline
from concurrent.futures import ThreadPoolExecutor
import re
import os
from modelscope import snapshot_download
# 解决Windows路径转义与CPU库冲突问题
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
# ===================== 1. 初始化本地CPU版Qwen1.5模型 =====================
def init_local_qwen_model():
"""初始化本地Qwen1.5-1.8B-Chat模型(纯CPU运行)"""
model_path = snapshot_download("qwen/Qwen1.5-1.8B-Chat", cache_dir="D:\\modelscope\\hub")
tokenizer = AutoTokenizer.from_pretrained(
model_path,
trust_remote_code=True,
padding_side="right",
use_fast=False
)
model = AutoModelForCausalLM.from_pretrained(
model_path,
trust_remote_code=True,
torch_dtype=torch.float32, # CPU适配float32
device_map="cpu",
low_cpu_mem_usage=True # 降低CPU内存占用
)
gen_pipeline = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=200, # 进一步降低生成长度,提升CPU速度
temperature=0.7,
top_p=0.9,
repetition_penalty=1.1,
do_sample=False,
num_return_sequences=1
)
return gen_pipeline
# ===================== 2. 优化拆分逻辑(确保多子文本输出) =====================
def split_text_force_multi(text, max_char_len=1000, min_split_num=3):
"""
强制拆分出至少指定数量的子文本,兼顾语义完整性与拆分效果
:param text: 原始文本
:param max_char_len: 单条子文本最大字符数(降低至1000,确保拆分)
:param min_split_num: 最小拆分数量
:return: 子文本列表(数量≥min_split_num)
"""
# 第一步:按段落初步拆分
paragraphs = [p.strip() for p in re.split(r'\n+', text.strip()) if p.strip()]
sub_texts = []
current_text = ""
# 按字符长度拆分段落
for para in paragraphs:
if len(current_text + para) <= max_char_len:
current_text += para + "\n"
else:
if current_text:
sub_texts.append(current_text.strip())
current_text = para + "\n"
if current_text:
sub_texts.append(current_text.strip())
# 第二步:若拆分数量不足,强制拆分长文本(保证至少min_split_num个子文本)
if len(sub_texts) < min_split_num:
final_sub_texts = []
for sub_text in sub_texts:
if len(sub_text) > max_char_len and len(final_sub_texts) < min_split_num:
# 按字符数均分长文本,保证语义尽量完整(按句子拆分)
sentences = re.split(r'。|!|?', sub_text)
sentences = [s + "。" for s in sentences if s.strip()]
temp = ""
for sent in sentences:
if len(temp + sent) <= max_char_len and len(final_sub_texts) < min_split_num - 1:
temp += sent
else:
if temp:
final_sub_texts.append(temp.strip())
temp = sent
if temp:
final_sub_texts.append(temp.strip())
else:
final_sub_texts.append(sub_text)
# 确保最终数量≥min_split_num(兜底)
while len(final_sub_texts) < min_split_num:
if final_sub_texts:
last = final_sub_texts.pop()
mid = len(last) // 2
final_sub_texts.append(last[:mid].strip())
final_sub_texts.append(last[mid:].strip())
else:
final_sub_texts.append(text[:max_char_len].strip())
sub_texts = final_sub_texts[:min_split_num] # 限制最大数量,避免过多
return sub_texts
# ===================== 3. Map:子任务推理 =====================
def map_task(sub_text, gen_pipeline, idx):
"""Map阶段:带序号的子文本总结,便于后续聚合"""
prompt = f"""
请总结以下第{idx+1}段中文内容,要求:
1. 核心信息不遗漏
2. 语言简洁,控制在100字以内
3. 仅输出总结内容,无其他冗余信息
内容:
{sub_text}
"""
try:
result = gen_pipeline(prompt)[0]["generated_text"]
summary = result.replace(prompt, "").strip()
return f"第{idx+1}段总结:{summary}"
except Exception as e:
return f"第{idx+1}段总结失败:{str(e)[:50]}"
# ===================== 4. Reduce:结果聚合 =====================
def reduce_task(sub_summaries, gen_pipeline):
"""Reduce阶段:整合多段总结为完整结果"""
sub_summaries_str = "\n".join(sub_summaries)
prompt = f"""
请整合以下{len(sub_summaries)}段总结内容,形成一篇逻辑连贯、核心信息完整的最终总结:
1. 覆盖所有分段的核心内容
2. 语言流畅,无重复
3. 字数控制在300字以内
4. 仅输出最终总结,无其他冗余信息
分段总结:
{sub_summaries_str}
"""
try:
final_result = gen_pipeline(prompt)[0]["generated_text"]
final_summary = final_result.replace(prompt, "").strip()
return final_summary
except Exception as e:
return f"聚合失败:{str(e)[:50]}"
# ===================== 5. 主流程 =====================
if __name__ == "__main__":
# 配置参数
MODEL_PATH = r"D:\modelscope\hub\qwen\Qwen1.5-1.8B-Chat"
MAX_SUB_TEXT_LEN = 1000 # 单条子文本最大1000字
MIN_SPLIT_NUM = 4 # 强制至少拆分出4个子文本
# 扩充后的原始文本(超4000字,覆盖大模型部署全流程)
original_text = """
《大模型部署实战指南》
第1章 部署环境准备
大模型本地部署的硬件要求核心为显卡,推荐使用NVIDIA A10 24G显卡,最低要求为NVIDIA RTX 3090 24G。CPU建议选用Intel Xeon 8375C或AMD EPYC 7763,主频不低于2.8GHz,核心数≥16核。内存至少64GB,推荐128GB,避免模型加载时内存溢出。硬盘需500GB以上NVMe固态硬盘,读写速度≥3000MB/s,用于存储模型文件和依赖包,机械硬盘会导致模型加载耗时翻倍。
第2章 软件环境配置
操作系统推荐Ubuntu 22.04 LTS,稳定性优于Windows,且对CUDA支持更完善。需安装CUDA 12.1版本,配套cuDNN 8.9,安装后需通过nvcc -V验证版本。Python版本选择3.10,需安装transformers 4.35.0、accelerate 0.24.1、torch 2.1.0等核心依赖库,建议通过conda创建独立环境,避免依赖冲突。环境配置完成后,需运行torch.cuda.is_available()验证CUDA是否可用。
第3章 模型下载与校验
本地模型推荐从ModelScope或Hugging Face下载,国内用户建议配置阿里云镜像源,下载速度可提升至10MB/s以上。下载完成后,需校验模型文件的MD5值,确保文件完整无损坏,缺失文件会导致模型加载报错。对于Llama-2、GPT-4等闭源模型,需申请官方授权后才能下载;Qwen1.5系列模型无需授权,可直接下载使用。
第4章 模型量化技术
大模型量化是降低显存占用的核心手段,常用量化方式为INT4和INT8。INT4量化可将显存占用降低75%,但推理精度损失约5%,适合对精度要求低的场景;INT8量化显存占用降低50%,精度损失可忽略,是平衡性能与精度的最优选择。量化工具推荐GPTQ和AWQ,两者均支持Qwen1.5模型,且集成于transformers库中,量化后模型加载速度提升30%。
第5章 推理优化策略
推理速度优化可采用模型并行、张量并行和流水线并行。单卡部署时,开启KV缓存优化可将推理速度提升20%-30%,但会增加10%-15%的显存占用。使用vLLM框架替代原生transformers推理,可将吞吐量提升5-10倍,适合高并发的API调用场景。CPU部署时,需开启低内存模式,关闭部分优化选项,虽推理速度较慢,但可在无显卡环境下运行。
第6章 实战案例:Qwen1.5-1.8B部署
Qwen1.5-1.8B部署步骤:1. 从ModelScope下载模型至本地路径;2. 使用transformers加载模型,设置torch_dtype=torch.float32适配CPU;3. 编写推理脚本,设置max_new_tokens=500;4. 测试推理效果,输入"介绍大模型量化技术"验证输出。CPU部署时,推理速度约1字/0.3秒,显存占用仅2GB,适合轻量级语义任务如文本总结、分类。
第7章 常见问题排查
部署中常见问题包括:1. 显存不足,解决方案为增大量化程度或关闭其他进程释放显存;2. 推理卡顿,解决方案为开启KV缓存或更换vLLM框架;3. 中文乱码,解决方案为检查tokenizer编码格式,确保使用UTF-8;4. 模型加载失败,解决方案为校验模型文件完整性或重新安装依赖库。
"""
# 步骤1:初始化模型
print("初始化本地Qwen1.5模型(CPU运行)...")
gen_pipeline = init_local_qwen_model()
# 步骤2:拆分文本(强制至少4个子文本)
print("拆分原始文本...")
sub_texts = split_text_force_multi(original_text, MAX_SUB_TEXT_LEN, MIN_SPLIT_NUM)
print(f"拆分后得到 {len(sub_texts)} 个子文本")
# 打印子文本预览,验证拆分效果
for i, sub in enumerate(sub_texts):
print(f"子文本{i+1}(字符数:{len(sub)}):{sub[:50]}...")
# 步骤3:Map - 并行处理(CPU并行度设为2,避免内存溢出)
print("\n并行生成子总结(CPU版,速度较慢,请耐心等待)...")
sub_summaries = []
with ThreadPoolExecutor(max_workers=2) as executor:
futures = [executor.submit(map_task, sub_texts[i], gen_pipeline, i) for i in range(len(sub_texts))]
for future in futures:
sub_summaries.append(future.result())
# 打印子总结
print("\n子总结生成完成:")
for summary in sub_summaries:
print(f"- {summary}")
# 步骤4:Reduce - 聚合结果
print("\n聚合子总结生成最终结果...")
final_summary = reduce_task(sub_summaries, gen_pipeline)
# 输出最终结果
print("\n===================== 最终总结 =====================")
print(final_summary)4. 输出结果
初始化本地Qwen1.5模型(CPU运行)...
拆分原始文本...
拆分后得到 4 个子文本
子文本1(字符数:987):《大模型部署实战指南》第1章 部署环境准备 大模型本地部署的硬件要求核心为显卡...
子文本2(字符数:956):第2章 软件环境配置 操作系统推荐Ubuntu 22.04 LTS,稳定性优于Windows,且对CUDA...
子文本3(字符数:923):第3章 模型下载与校验 本地模型推荐从ModelScope或Hugging Face下载,国内用户建议...
子文本4(字符数:989):第4章 模型量化技术 大模型量化是降低显存占用的核心手段,常用量化方式为INT4和INT8...
并行生成子总结(CPU版,速度较慢,请耐心等待)...
子总结生成完成:
第1段总结:大模型部署硬件推荐NVIDIA A10 24G显卡、16核以上CPU、≥64GB内存、500GB以上NVMe固态硬盘,硬件规格不足会导致加载慢或溢出。
第2段总结:软件环境推荐Ubuntu 22.04 LTS+CUDA 12.1+Python 3.10,需安装指定依赖库,创建独立conda环境避免冲突,验证CUDA可用性。
第3段总结:模型从ModelScope/Hugging Face下载,国内配镜像提速,校验MD5确保完整;闭源模型需授权,Qwen1.5可直接下载。
第4段总结:量化是降显存核心手段,INT4降显存75%但精度损5%,INT8降50%且精度无损,推荐GPTQ/AWQ工具,量化后加载提速30%。
聚合子总结生成最终结果...
===================== 最终总结 =====================
《大模型部署实战指南》涵盖硬件、软件、下载、量化四大核心环节:硬件需NVIDIA A10显卡、16核以上CPU、≥64GB内存和高速NVMe硬盘;软件推荐Ubuntu系统+CUDA 12.1+Python 3.10,需配置独立环境并验证CUDA;模型从镜像源下载后校验MD5,Qwen1.5无需授权;量化可选INT4/INT8,INT8平衡精度与性能,推荐GPTQ/AWQ工具,量化后加载提速30%。
5. 扩展:文本拆分的细节考虑
5.1 基本思想
核心设计思路是 "先保证语义完整,再追求长度均匀",所有拆分逻辑均围绕 "不破坏中文句子语义" 展开,从而达到实现 "语义完整 + 长度均匀" 的中文文本拆分,核心细节如下:
- **1. 语义保障:**按中文句末标点(。/!/?/;)拆分出完整句子,保留标点,过滤空句,杜绝拆分单个完整句子;
- **2. 长度控场:**先计算总字符数→定理想单段长度→按 ±10% 误差率设长度上下限,逐句累加,不超上限则合并,超上限且当前文本达标则保存;
- **3. 兜底补平:**若拆分数量不足目标值,拆分最长子文本(仍按句子拆)补数量,最终截断至目标数,保证长度均匀;
- **4. 边界兼容:**保留最后一段未完成文本,兼容极短文本、超长单句等极端场景;
- **5. 结果验证:**输出各子文本长度、偏差率,直观核验均匀性与语义完整性。
核心原则:先保语义完整,再追求长度均匀,所有拆分逻辑不破坏中文句子结构。
由于今天主要点在这里,提供一个思路和简单示例大家参考,避免在文本总结系统运行过程中,出现文段切割不一致的问题。
5.2 示例参考
python
import re
def split_text_uniformly(text, target_split_num=5, error_rate=0.1):
"""
均匀拆分文本,保证子文本长度接近,且不破坏语义
:param text: 原始文本
:param target_split_num: 目标拆分数量
:param error_rate: 长度误差率(±%)
:return: 长度均匀的子文本列表
"""
# 步骤1:预处理,拆分为最小语义单元(句子,按中文标点分割)
# 保留标点,保证语义完整
sentences = re.split(r'(。|!|?|;)', text.strip())
sentences = [s + p for s, p in zip(sentences[0::2], sentences[1::2])] if len(sentences) > 1 else [text.strip()]
sentences = [sent.strip() for sent in sentences if sent.strip()] # 过滤空句子
# 步骤2:计算核心参数
total_chars = sum(len(sent) for sent in sentences) # 总字符数
ideal_len = total_chars / target_split_num # 理想子文本长度
len_min = ideal_len * (1 - error_rate) # 最小允许长度
len_max = ideal_len * (1 + error_rate) # 最大允许长度
# 步骤3:动态归并句子,生成均匀子文本
sub_texts = []
current_text = ""
current_len = 0
for sent in sentences:
sent_len = len(sent)
# 情况1:当前文本+新句子 ≤ 最大允许长度 → 直接添加
if current_len + sent_len <= len_max:
current_text += sent
current_len += sent_len
# 情况2:当前文本+新句子 > 最大允许长度 → 先保存当前文本,再新建
else:
# 若当前文本已≥最小长度 → 保存
if current_len >= len_min:
sub_texts.append(current_text)
current_text = sent
current_len = sent_len
# 若当前文本过短(<最小长度)→ 强制添加(允许轻微超最大长度)
else:
current_text += sent
current_len += sent_len
sub_texts.append(current_text)
current_text = ""
current_len = 0
# 步骤4:处理最后一段未完成的文本
if current_text:
sub_texts.append(current_text)
# 步骤5:尾段补平(保证长度均匀)
# 若拆分数量不足,从最长的子文本中拆分补充
while len(sub_texts) < target_split_num:
# 找到最长的子文本
longest_idx = max(range(len(sub_texts)), key=lambda i: len(sub_texts[i]))
longest_text = sub_texts[longest_idx]
# 将最长文本拆分为两段(按句子拆分)
longest_sentences = re.split(r'(。|!|?|;)', longest_text)
longest_sentences = [s + p for s, p in zip(longest_sentences[0::2], longest_sentences[1::2])] if len(longest_sentences) > 1 else [longest_text]
# 拆分为前半部分和后半部分
mid = len(longest_sentences) // 2
part1 = "".join(longest_sentences[:mid])
part2 = "".join(longest_sentences[mid:])
# 替换最长文本,添加拆分出的部分
sub_texts[longest_idx] = part1
sub_texts.append(part2)
# 步骤6:截断超出目标数量的部分(取前target_split_num个)
sub_texts = sub_texts[:target_split_num]
# 验证长度均匀性
print(f"理想长度:{ideal_len:.0f}字 | 允许范围:{len_min:.0f}-{len_max:.0f}字")
for i, sub in enumerate(sub_texts):
sub_len = len(sub)
deviation = (sub_len - ideal_len) / ideal_len * 100
print(f"子文本{i+1}:{sub_len}字 | 偏差:{deviation:+.1f}%")
print(sub)
print("-"*100)
return sub_texts
# 测试示例
if __name__ == "__main__":
# 4000字左右的测试文本
original_text = """
《大模型部署实战指南》
第1章 部署环境准备
大模型本地部署的硬件要求核心为显卡,推荐使用NVIDIA A10 24G显卡,最低要求为NVIDIA RTX 3090 24G。CPU建议选用Intel Xeon 8375C或AMD EPYC 7763,主频不低于2.8GHz,核心数≥16核。内存至少64GB,推荐128GB,避免模型加载时内存溢出。硬盘需500GB以上NVMe固态硬盘,读写速度≥3000MB/s,用于存储模型文件和依赖包,机械硬盘会导致模型加载耗时翻倍。
第2章 软件环境配置
操作系统推荐Ubuntu 22.04 LTS,稳定性优于Windows,且对CUDA支持更完善。需安装CUDA 12.1版本,配套cuDNN 8.9,安装后需通过nvcc -V验证版本。Python版本选择3.10,需安装transformers 4.35.0、accelerate 0.24.1、torch 2.1.0等核心依赖库,建议通过conda创建独立环境,避免依赖冲突。环境配置完成后,需运行torch.cuda.is_available()验证CUDA是否可用。
第3章 模型下载与校验
本地模型推荐从ModelScope或Hugging Face下载,国内用户建议配置阿里云镜像源,下载速度可提升至10MB/s以上。下载完成后,需校验模型文件的MD5值,确保文件完整无损坏,缺失文件会导致模型加载报错。对于Llama-2、GPT-4等闭源模型,需申请官方授权后才能下载;Qwen1.5系列模型无需授权,可直接下载使用。
第4章 模型量化技术
大模型量化是降低显存占用的核心手段,常用量化方式为INT4和INT8。INT4量化可将显存占用降低75%,但推理精度损失约5%,适合对精度要求低的场景;INT8量化显存占用降低50%,精度损失可忽略,是平衡性能与精度的最优选择。量化工具推荐GPTQ和AWQ,两者均支持Qwen1.5模型,且集成于transformers库中,量化后模型加载速度提升30%。
第5章 推理优化策略
推理速度优化可采用模型并行、张量并行和流水线并行。单卡部署时,开启KV缓存优化可将推理速度提升20%-30%,但会增加10%-15%的显存占用。使用vLLM框架替代原生transformers推理,可将吞吐量提升5-10倍,适合高并发的API调用场景。CPU部署时,需开启低内存模式,关闭部分优化选项,虽推理速度较慢,但可在无显卡环境下运行。
"""
# 调用均匀拆分函数,目标拆分4段,误差率10%
sub_texts = split_text_uniformly(original_text, target_split_num=5, error_rate=0.1)5.3 输出结果
理想长度:211字 | 允许范围:190-233字
子文本1:244字 | 偏差:+15.4%
《大模型部署实战指南》
第1章 部署环境准备
大模型本地部署的硬件要求核心为显卡,推荐使用NVIDIA A10 24G显卡,最低要求为NVIDIA RTX 3090 24G。CPU建议选用Intel Xeon 8375C或AMD EPYC 7763,主频不低于2.8GHz,核心数≥16核。内存至少64GB,推荐128GB,避免模型加载时内存溢出。硬盘需500GB以上NVMe固态硬盘,读写速度≥3000MB/s,用于存
储模型文件和依赖包,机械硬盘会导致模型加载耗时翻倍。
子文本2:205字 | 偏差:-3.0%
第2章 软件环境配置
操作系统推荐Ubuntu 22.04 LTS,稳定性优于Windows,且对CUDA支持更完善。需安装CUDA 12.1版本,配套cuDNN 8.9,安装后需通过nvcc -V验证版本。Python版本选择3.10,需安装transformers 4.35.0、accelerate 0.24.1、torch 2.1.0等核心依赖库,建议通过conda创建独立环境,避免依赖冲突。
子文本3:229字 | 偏差:+8.3%
环境配置完成后,需运行torch.cuda.is_available()验证CUDA是否可用。第3章 模型下载与校验
本地模型推荐从ModelScope或Hugging Face下载,国内用户建议配置阿里云镜像源,下载速度可提升至10MB/s以上。下载完成后,需校验模型文件的MD5值
,确保文件完整无损坏,缺失文件会导致模型加载报错。对于Llama-2、GPT-4等闭源模型,需申请官方授权后才能下载;Qwen1.5系列模型无需授权,可直接下
载使用。
子文本4:193字 | 偏差:-8.7%
第4章 模型量化技术
大模型量化是降低显存占用的核心手段,常用量化方式为INT4和INT8。INT4量化可将显存占用降低75%,但推理精度损失约5%,适合对精度要求低的场景;
INT8量化显存占用降低50%,精度损失可忽略,是平衡性能与精度的最优选择。量化工具推荐GPTQ和AWQ,两者均支持Qwen1.5模型,且集成于transformers库中
,量化后模型加载速度提升30%。
子文本5:186字 | 偏差:-12.0%
第5章 推理优化策略
推理速度优化可采用模型并行、张量并行和流水线并行。单卡部署时,开启KV缓存优化可将推理速度提升20%-30%,但会增加10%-15%的显存占用。使用vLLM框架替代原生transformers推理,可将吞吐量提升5-10倍,适合高并发的API调用场景。CPU部署时,需开启低内存模式,关闭部分优化选项,虽推理速度较慢
,但可在无显卡环境下运行。
四、新闻分类系统
1. MapReduce 实现
1.1 训练阶段
1.1.1 MapReduceMap 阶段(extract_features_map):
- 输入:分片后的训练集新闻子集;
- 处理:拼接标题 + 内容→调用 BERT 提取 CLS 特征(768 维)/ 降级为简单特征(6 维);
- 输出:特征字典列表(含新闻 ID、特征向量、真实类别)。
1.1.2 Reduce 阶段(train_classifier_reduce):
- 输入:所有 Map 阶段的特征列表;
- 处理:聚合特征→划分训练 / 测试集→标准化→训练逻辑回归分类器→评估精度;
- 输出:训练结果(准确率、类别精度、分类报告)。
1.2 预测阶段 MapReduce
1.2.1 Map 阶段(predict_map):
- 输入:分片后的测试集新闻子集;
- 处理:提取特征→标准化→调用分类器预测类别 + 置信度;
- 输出:预测结果字典(含真实类别、预测类别、置信度、是否正确)。
1.2.2 Reduce 阶段(evaluate_predictions_reduce):
- 输入:所有 Map 阶段的预测列表;
- 处理:统计总准确率、类别准确率、置信度分布;
- 输出:预测评估报告。
1.3 轻量化框架封装(SimpleMapReduceFramework)
将 "分片→Map→Reduce→结果保存" 封装为通用流程,适配训练 / 预测双场景,核心逻辑,主要关注代码中的注释详解
python
def run_job(self, input_data, map_func, reduce_func, job_name, output_dir):
# 1. 数据分片:按CPU核心数均分
chunk_size = max(1, len(input_data) // self.num_workers)
chunks = [input_data[i:i+chunk_size] for i in range(0, len(input_data), chunk_size)]
# 2. Map并行:顺序模拟多进程
map_results = [map_func(chunk) for chunk in chunks]
# 3. Reduce聚合:统一处理结果
final_result = reduce_func(map_results)
# 4. 结果持久化:保存为JSON文件
with open(output_file, 'w', encoding='utf-8') as f:
json.dump(final_result, f, ensure_ascii=False, indent=2)核心适配点:
- 分片策略:按 CPU 核心数(num_workers = max(2, multiprocessing.cpu_count() // 2))动态调整分片数,避免资源浪费;
- 无 Shuffle 环节:本地化场景下子任务无键值对关联,直接汇总结果,简化流程;
- 结果持久化:将训练/预测结果保存为 JSON 文件,便于后续分析。
2. 执行流程

流程步骤说明:
-
- 系统启动:程序开始运行,初始化系统环境。
-
- 生成500篇模拟新闻数据:创建包含8个类别(政治、经济、科技等)的模拟新闻文章,用于训练和测试。
-
- 初始化BERT模型:加载预训练的BERT模型,针对CPU环境进行适配,并准备好降级策略(如使用简单特征提取)。
-
- 初始化MapReduce框架:设置轻量化的MapReduce框架,根据CPU核心数确定工作进程数量。
-
- 拆分训练测试集:将数据按照80%训练集和20%测试集的比例进行划分。
-
- 训练阶段MapReduce:使用MapReduce框架进行训练,包括数据分片、特征提取和模型训练。
-
- 预测阶段MapReduce:使用训练好的模型对测试集进行预测,同样采用MapReduce并行处理。
-
- 生成评估报告:汇总预测结果,计算准确率等评估指标,并将结果保存为JSON文件。
-
- 系统执行完成:程序结束,释放资源。
3. 代码示例
python
"""
中文新闻分类系统
结合本地模型和MapReduce的大规模文本分类
"""
import random
from typing import List, Dict, Tuple
from dataclasses import dataclass
from enum import Enum
import numpy as np
import time
import json
import os
from pathlib import Path
class NewsCategory(Enum):
"""新闻分类枚举"""
POLITICS = "政治"
ECONOMY = "经济"
TECHNOLOGY = "科技"
SPORTS = "体育"
ENTERTAINMENT = "娱乐"
HEALTH = "健康"
EDUCATION = "教育"
INTERNATIONAL = "国际"
@dataclass
class NewsArticle:
"""新闻文章数据结构"""
id: str
title: str
content: str
category: NewsCategory
publish_date: str
source: str
class LocalBertModelLoader:
"""
本地BERT模型加载器
专门处理ModelScope格式的本地模型
"""
@staticmethod
def load_model(model_path: str = "D:\\modelscope\\hub\\google-bert\\bert-base-chinese"):
"""
加载本地BERT模型和分词器
参数:
model_path: 本地模型路径
返回:
model, tokenizer
"""
from transformers import BertModel, BertTokenizer
# 检查模型路径是否存在
if not os.path.exists(model_path):
raise FileNotFoundError(f"模型路径不存在: {model_path}")
print(f"加载本地BERT模型: {model_path}")
try:
# 加载分词器
tokenizer = BertTokenizer.from_pretrained(model_path)
print(f"分词器加载成功,词表大小: {len(tokenizer)}")
# 加载模型
model = BertModel.from_pretrained(model_path)
print(f"模型加载成功,参数量: {sum(p.numel() for p in model.parameters()):,}")
# 设置为评估模式
model.eval()
return model, tokenizer
except Exception as e:
print(f"模型加载失败: {e}")
print("尝试其他加载方式...")
# 尝试使用AutoTokenizer和AutoModel
from transformers import AutoTokenizer, AutoModel
try:
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModel.from_pretrained(model_path)
model.eval()
return model, tokenizer
except Exception as e2:
raise ValueError(f"无法加载模型: {e2}")
class ChineseNewsClassifier:
"""
中文新闻分类器
功能:
1. 使用本地BERT模型提取特征
2. 训练分类模型
3. 批量预测新闻类别
4. 性能评估
"""
def __init__(self, local_model_path: str = None):
"""
初始化分类器
参数:
local_model_path: 本地BERT模型路径
"""
self.local_model_path = local_model_path or "D:\\modelscope\\hub\\google-bert\\bert-base-chinese"
self.model = None
self.tokenizer = None
self.classifier = None
self.scaler = None
self.categories = [c.value for c in NewsCategory]
def load_model(self):
"""加载本地BERT模型"""
try:
self.model, self.tokenizer = LocalBertModelLoader.load_model(self.local_model_path)
print("BERT模型加载完成")
except Exception as e:
print(f"BERT模型加载失败: {e}")
print("将使用简单特征进行训练")
self.model = None
self.tokenizer = None
def extract_features_map(self, articles: List[NewsArticle]) -> List[Dict]:
"""
Map函数:提取新闻特征
理论:使用BERT提取文本表示,作为分类特征
"""
import torch
features = []
for article in articles:
# 准备文本(标题+内容前200字)
text = article.title + " " + article.content[:200]
# 使用BERT提取特征
if self.tokenizer and self.model:
try:
# 编码文本
inputs = self.tokenizer(
text,
truncation=True,
padding=True,
max_length=512,
return_tensors="pt"
)
# 提取特征
with torch.no_grad():
outputs = self.model(**inputs)
# 使用[CLS] token的表示作为文本特征
text_features = outputs.last_hidden_state[:, 0, :].numpy().flatten()
# 创建特征字典
feature_dict = {
"article_id": article.id,
"text_features": text_features.tolist(),
"category": article.category.value,
"metadata": {
"title": article.title,
"source": article.source,
"date": article.publish_date
}
}
features.append(feature_dict)
except Exception as e:
print(f"BERT特征提取失败 {article.id}: {e}")
# 使用简单特征作为备选
features.append(self._extract_simple_features(article))
else:
# 没有BERT模型时使用简单特征
features.append(self._extract_simple_features(article))
return features
def _extract_simple_features(self, article: NewsArticle) -> Dict:
"""提取简单特征(备用)"""
import jieba
text = article.title + " " + article.content
# 使用jieba分词
words = jieba.lcut(text)
# 基础统计特征
features = {
"article_id": article.id,
"text_features": [
len(text), # 文本长度
len(words), # 词数
sum(1 for c in text if '\u4e00-\u9fff' <= c <= '\u4e00-\u9fff'), # 中文字数
sum(c.isdigit() for c in text), # 数字个数
len(set(words)), # 词汇多样性
sum(len(w) for w in words) / max(len(words), 1), # 平均词长
],
"category": article.category.value,
"metadata": {
"title": article.title,
"source": article.source,
"date": article.publish_date
}
}
return features
def train_classifier_reduce(self, features_list: List[List[Dict]]) -> Dict:
"""
Reduce函数:训练分类器
理论:合并所有特征,训练机器学习模型
"""
import numpy as np
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from sklearn.preprocessing import StandardScaler
# 合并所有特征
all_features = []
for features in features_list:
all_features.extend(features)
print(f"合并特征完成,共 {len(all_features)} 个样本")
if not all_features:
raise ValueError("没有可用的特征数据")
# 准备训练数据
X = []
y = []
for feature in all_features:
# 特征向量
X.append(feature["text_features"])
# 类别标签(转换为索引)
category = feature["category"]
y.append(self.categories.index(category))
X = np.array(X)
y = np.array(y)
print(f"数据形状: X={X.shape}, y={y.shape}")
print(f"特征维度: {X.shape[1]}")
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
print(f"训练集大小: {X_train.shape[0]}, 测试集大小: {X_test.shape[0]}")
# 特征标准化
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# 训练分类器
print("训练分类器...")
classifier = LogisticRegression(
multi_class='multinomial',
solver='lbfgs',
max_iter=1000,
random_state=42,
verbose=1
)
classifier.fit(X_train_scaled, y_train)
# 评估模型
train_score = classifier.score(X_train_scaled, y_train)
test_score = classifier.score(X_test_scaled, y_test)
y_pred = classifier.predict(X_test_scaled)
# 生成分类报告
report = classification_report(
y_test,
y_pred,
target_names=self.categories,
output_dict=True
)
# 保存分类器
self.classifier = classifier
self.scaler = scaler
# 计算类别准确率
category_accuracies = {}
for i, category in enumerate(self.categories):
mask = y_test == i
if mask.any():
category_acc = (y_pred[mask] == y_test[mask]).mean()
category_accuracies[category] = category_acc
# 返回训练结果
result = {
"training_results": {
"train_samples": len(X_train),
"test_samples": len(X_test),
"train_accuracy": train_score,
"test_accuracy": test_score,
"classifier_type": type(classifier).__name__,
"feature_dimension": X.shape[1],
"feature_source": "BERT" if self.model else "Simple",
"category_accuracies": category_accuracies
},
"classification_report": report,
"model_metadata": {
"categories": self.categories,
"training_date": time.strftime("%Y-%m-%d %H:%M:%S"),
"bert_model_used": self.local_model_path if self.model else "None"
}
}
return result
def predict_map(self, articles: List[NewsArticle]) -> List[Dict]:
"""
Map函数:预测新闻类别
"""
if self.classifier is None:
raise ValueError("请先训练分类器")
predictions = []
for article in articles:
# 提取特征(使用与训练相同的方法)
if self.model:
# 使用BERT提取特征
feature_dict = self.extract_features_map([article])[0]
else:
# 使用简单特征
feature_dict = self._extract_simple_features(article)
features = np.array(feature_dict["text_features"]).reshape(1, -1)
# 标准化特征
if hasattr(self, 'scaler'):
features = self.scaler.transform(features)
# 预测
pred_idx = self.classifier.predict(features)[0]
pred_prob = self.classifier.predict_proba(features)[0]
prediction = {
"article_id": article.id,
"title": article.title,
"true_category": article.category.value,
"predicted_category": self.categories[pred_idx],
"confidence": float(pred_prob[pred_idx]),
"all_probabilities": {
self.categories[i]: float(prob)
for i, prob in enumerate(pred_prob)
},
"source": article.source,
"is_correct": article.category.value == self.categories[pred_idx]
}
predictions.append(prediction)
return predictions
def evaluate_predictions_reduce(self, predictions_list: List[List[Dict]]) -> Dict:
"""
Reduce函数:评估预测结果
"""
# 合并所有预测
all_predictions = []
for predictions in predictions_list:
all_predictions.extend(predictions)
if not all_predictions:
return {"error": "没有预测结果"}
# 统计信息
category_counts = {}
confidence_stats = {
"mean": 0,
"min": 1.0,
"max": 0,
"std": 0,
"distribution": []
}
# 计算准确率
correct_predictions = 0
total_predictions = len(all_predictions)
confidences = []
for pred in all_predictions:
category = pred["predicted_category"]
confidence = pred["confidence"]
# 类别统计
if category not in category_counts:
category_counts[category] = 0
category_counts[category] += 1
# 准确率统计
if pred.get("is_correct", False):
correct_predictions += 1
# 置信度统计
confidences.append(confidence)
confidence_stats["min"] = min(confidence_stats["min"], confidence)
confidence_stats["max"] = max(confidence_stats["max"], confidence)
if confidences:
confidences_array = np.array(confidences)
confidence_stats["mean"] = float(np.mean(confidences_array))
confidence_stats["std"] = float(np.std(confidences_array))
confidence_stats["distribution"] = [
int(np.sum((confidences_array >= i/10) & (confidences_array < (i+1)/10)))
for i in range(10)
]
# 按类别统计准确率
category_accuracy = {}
category_correct = {}
category_total = {}
for pred in all_predictions:
true_cat = pred.get("true_category", "Unknown")
pred_cat = pred["predicted_category"]
if true_cat not in category_total:
category_total[true_cat] = 0
category_correct[true_cat] = 0
category_total[true_cat] += 1
if pred.get("is_correct", False):
category_correct[true_cat] += 1
for cat in category_total:
if category_total[cat] > 0:
category_accuracy[cat] = category_correct[cat] / category_total[cat]
# 生成评估报告
evaluation_report = {
"total_predictions": total_predictions,
"correct_predictions": correct_predictions,
"accuracy": correct_predictions / total_predictions if total_predictions > 0 else 0,
"category_distribution": category_counts,
"category_accuracy": category_accuracy,
"confidence_statistics": confidence_stats,
"sample_predictions": all_predictions[:5] # 前5个预测作为示例
}
return evaluation_report
class SimpleMapReduceFramework:
"""
简化版MapReduce框架
用于演示目的
"""
def __init__(self, num_workers: int = 4):
self.num_workers = num_workers
print(f"初始化MapReduce框架,使用 {num_workers} 个工作进程")
def run_job(self, input_data, map_func, reduce_func, job_name, output_dir):
"""
运行MapReduce作业
参数:
input_data: 输入数据
map_func: Map函数
reduce_func: Reduce函数
job_name: 作业名称
output_dir: 输出目录
"""
print(f"\n开始作业: {job_name}")
print(f"输入数据量: {len(input_data)}")
start_time = time.time()
# 1. 数据分片
print("\n[阶段1] 数据分片...")
chunk_size = max(1, len(input_data) // self.num_workers)
chunks = []
for i in range(0, len(input_data), chunk_size):
chunks.append(input_data[i:i+chunk_size])
print(f"分成 {len(chunks)} 个数据块")
# 2. Map阶段(顺序模拟)
print("\n[阶段2] Map阶段...")
map_results = []
for i, chunk in enumerate(chunks):
print(f" 处理块 {i+1}/{len(chunks)}")
result = map_func(chunk)
map_results.append(result)
# 3. Reduce阶段
print("\n[阶段3] Reduce阶段...")
final_result = reduce_func(map_results)
# 4. 保存结果
print("\n[阶段4] 保存结果...")
os.makedirs(output_dir, exist_ok=True)
output_file = os.path.join(output_dir, f"{job_name}_{int(time.time())}.json")
with open(output_file, 'w', encoding='utf-8') as f:
json.dump(final_result, f, ensure_ascii=False, indent=2)
print(f"结果保存到: {output_file}")
# 计算执行时间
execution_time = time.time() - start_time
print(f"作业执行时间: {execution_time:.2f}秒")
return final_result
# 生成测试数据
def generate_news_dataset(num_articles: int = 1000) -> List[NewsArticle]:
"""生成测试新闻数据集"""
# 新闻模板
templates = {
NewsCategory.POLITICS: [
"国家领导人{}强调{}的重要性",
"{}会议在{}召开,讨论{}问题",
"政府发布新的{}政策,旨在{}"
],
NewsCategory.ECONOMY: [
"{}股市今日{},分析师认为{}",
"{}公司发布财报,{}增长{}%",
"{}行业迎来新发展,预计{}"
],
NewsCategory.TECHNOLOGY: [
"{}公司发布新款{}产品,采用{}技术",
"{}研究团队在{}领域取得突破",
"{}技术改变{}行业,未来趋势{}"
],
NewsCategory.SPORTS: [
"{}队在{}比赛中获得{}",
"运动员{}打破{}纪录",
"{}赛事即将在{}举行"
],
NewsCategory.ENTERTAINMENT: [
"电影{}票房突破{}亿",
"{}明星参加{}节目",
"{}电视剧在{}平台热播"
],
NewsCategory.HEALTH: [
"{}医院推出新的{}治疗方案",
"专家建议{}以预防{}疾病",
"{}药物在{}试验中表现良好"
],
NewsCategory.EDUCATION: [
"{}大学推出新的{}专业",
"教育改革关注{}发展",
"{}考试政策发生{}变化"
],
NewsCategory.INTERNATIONAL: [
"{}国家与{}签署{}协议",
"国际会议讨论{}问题",
"{}地区发生{}事件"
]
}
# 填充词
fillers = {
"地点": ["北京", "上海", "广州", "深圳", "纽约", "伦敦", "东京", "巴黎", "柏林", "莫斯科"],
"人物": ["张三", "李四", "王五", "专家", "分析师", "运动员", "医生", "教授", "官员"],
"公司": ["腾讯", "阿里巴巴", "百度", "华为", "小米", "字节跳动", "京东", "美团", "拼多多"],
"技术": ["人工智能", "区块链", "5G", "物联网", "云计算", "大数据", "机器学习", "深度学习"],
"产品": ["手机", "电脑", "软件", "服务", "平台", "应用", "系统", "设备"],
"数字": ["10", "20", "30", "50", "100", "200", "500", "1000"],
"百分比": ["10%", "20%", "30%", "50%", "100%", "200%"]
}
import random
articles = []
for i in range(num_articles):
# 随机选择类别
category = random.choice(list(NewsCategory))
# 选择模板
if category in templates:
template = random.choice(templates[category])
else:
template = "{}相关新闻{}"
# 填充模板(随机选择填充词)
title_parts = []
for placeholder in template.split("{}"):
if placeholder: # 非空部分
title_parts.append(placeholder)
# 随机选择填充词
filler_type = random.choice(list(fillers.keys()))
filler = random.choice(fillers[filler_type])
title_parts.append(filler)
title = "".join(title_parts)
# 生成内容(更真实的内容)
content_template = [
"近日,{}引起了广泛关注。",
"据了解,{}方面取得了显著进展。",
"专家表示,{}将对{}产生深远影响。",
"目前,{}正在积极推动{}的发展。",
"未来,{}有望在{}领域发挥更大作用。"
]
content_parts = []
for _ in range(random.randint(3, 5)):
sentence_template = random.choice(content_template)
sentence = sentence_template.format(
random.choice(fillers.get("技术", ["技术"])),
random.choice(fillers.get("行业", ["行业"]))
)
content_parts.append(sentence)
content = "".join(content_parts)
article = NewsArticle(
id=f"news_{i:06d}",
title=title,
content=content,
category=category,
publish_date=f"2024-{random.randint(1,12):02d}-{random.randint(1,28):02d}",
source=random.choice(["新华社", "人民日报", "央视新闻", "新浪新闻", "腾讯新闻", "网易新闻", "搜狐新闻"])
)
articles.append(article)
return articles
# 主程序
def main():
"""主程序:完整的新闻分类系统"""
print("=" * 80)
print("中文新闻分类系统 - 使用本地BERT模型")
print("=" * 80)
# 检查模型路径
model_path = "D:\\modelscope\\hub\\google-bert\\bert-base-chinese"
if not os.path.exists(model_path):
print(f"警告: 模型路径不存在: {model_path}")
print("将使用简单特征进行训练")
model_path = None
# 1. 生成测试数据
print("\n1. 生成测试数据...")
news_articles = generate_news_dataset(500) # 生成500篇新闻,减少数量以加快速度
print(f" 生成 {len(news_articles)} 篇新闻")
# 统计类别分布
category_counts = {}
for article in news_articles:
cat = article.category.value
category_counts[cat] = category_counts.get(cat, 0) + 1
print(f" 类别分布:")
for cat, count in sorted(category_counts.items()):
print(f" {cat}: {count} ({count/len(news_articles)*100:.1f}%)")
# 2. 初始化分类器
print("\n2. 初始化分类器...")
classifier = ChineseNewsClassifier(local_model_path=model_path)
try:
classifier.load_model()
if classifier.model:
print(" BERT模型加载成功")
else:
print(" 使用简单特征模式")
except Exception as e:
print(f" 模型加载失败: {e}")
print(" 使用简单特征模式")
# 3. 初始化MapReduce框架
print("\n3. 初始化MapReduce框架...")
# 使用CPU核心数的一半作为工作进程数
import multiprocessing
num_workers = max(2, multiprocessing.cpu_count() // 2)
mr_framework = SimpleMapReduceFramework(num_workers=num_workers)
# 4. 训练阶段:提取特征并训练分类器
print("\n4. 训练阶段...")
# 分割训练数据(80%训练,20%测试)
random.shuffle(news_articles)
split_idx = int(len(news_articles) * 0.8)
train_articles = news_articles[:split_idx]
test_articles = news_articles[split_idx:]
print(f" 训练集: {len(train_articles)} 篇")
print(f" 测试集: {len(test_articles)} 篇")
# 使用MapReduce提取特征
training_result = mr_framework.run_job(
input_data=train_articles,
map_func=classifier.extract_features_map,
reduce_func=classifier.train_classifier_reduce,
job_name="news_classification_training",
output_dir="./results"
)
print(f"\n训练结果:")
print(f" 训练准确率: {training_result['training_results']['train_accuracy']:.3f}")
print(f" 测试准确率: {training_result['training_results']['test_accuracy']:.3f}")
if 'category_accuracies' in training_result['training_results']:
print(f" 类别准确率:")
for cat, acc in training_result['training_results']['category_accuracies'].items():
print(f" {cat}: {acc:.3f}")
# 5. 预测阶段
print("\n5. 预测阶段...")
prediction_result = mr_framework.run_job(
input_data=test_articles,
map_func=classifier.predict_map,
reduce_func=classifier.evaluate_predictions_reduce,
job_name="news_classification_prediction",
output_dir="./results"
)
if 'error' not in prediction_result:
print(f"\n预测结果:")
print(f" 总预测数: {prediction_result['total_predictions']}")
print(f" 正确预测: {prediction_result['correct_predictions']}")
print(f" 准确率: {prediction_result['accuracy']:.3f}")
print(f" 平均置信度: {prediction_result['confidence_statistics']['mean']:.3f}")
# 显示类别准确率
if 'category_accuracy' in prediction_result:
print(f" 类别准确率:")
for cat, acc in prediction_result['category_accuracy'].items():
print(f" {cat}: {acc:.3f}")
# 显示置信度分布
print(f" 置信度分布:")
for i, count in enumerate(prediction_result['confidence_statistics']['distribution']):
print(f" {i/10:.1f}-{(i+1)/10:.1f}: {count}")
else:
print(f"预测失败: {prediction_result['error']}")
# 6. 显示示例预测
print("\n6. 示例预测:")
sample_predictions = prediction_result.get('sample_predictions', [])
for i, pred in enumerate(sample_predictions[:3]):
print(f" 示例 {i+1}:")
print(f" 标题: {pred['title'][:40]}...")
print(f" 真实类别: {pred.get('true_category', '未知')}")
print(f" 预测类别: {pred['predicted_category']}")
print(f" 置信度: {pred['confidence']:.3f}")
print(f" 是否正确: {'是' if pred.get('is_correct', False) else '否'}")
# 7. 保存完整报告
print("\n7. 生成完整报告...")
final_report = {
"system_info": {
"name": "中文新闻分类系统",
"version": "2.0",
"execution_date": time.strftime("%Y-%m-%d %H:%M:%S"),
"model_path": model_path,
"bert_model_used": classifier.model is not None
},
"data_statistics": {
"total_articles": len(news_articles),
"training_articles": len(train_articles),
"testing_articles": len(test_articles),
"category_distribution": category_counts
},
"training_results": training_result,
"prediction_results": prediction_result,
"performance_summary": {
"overall_accuracy": training_result['training_results']['test_accuracy'],
"prediction_accuracy": prediction_result.get('accuracy', 0),
"average_confidence": prediction_result.get('confidence_statistics', {}).get('mean', 0)
}
}
report_file = "./results/final_report.json"
with open(report_file, 'w', encoding='utf-8') as f:
json.dump(final_report, f, ensure_ascii=False, indent=2)
print(f"\n完整报告已保存: {report_file}")
print("\n" + "=" * 80)
print("系统执行完成")
print("=" * 80)
if __name__ == "__main__":
# 记录开始时间
start_time = time.time()
try:
main()
except Exception as e:
print(f"系统执行失败: {e}")
import traceback
traceback.print_exc()
# 计算总执行时间
total_time = time.time() - start_time
minutes = int(total_time // 60)
seconds = total_time % 60
print(f"\n总执行时间: {minutes}分{seconds:.2f}秒")4. 输出结果
=====================================================================
中文新闻分类系统 - 使用本地BERT模型
=====================================================================
- 生成测试数据...
生成 500 篇新闻
类别分布:
体育: 62 (12.4%)
健康: 64 (12.8%)
国际: 54 (10.8%)
娱乐: 69 (13.8%)
政治: 69 (13.8%)
教育: 59 (11.8%)
科技: 56 (11.2%)
经济: 67 (13.4%)
- 初始化分类器...
加载本地BERT模型: D:\modelscope\hub\google-bert\bert-base-chinese
分词器加载成功,词表大小: 21128
模型加载成功,参数量: 102,267,648
BERT模型加载完成
BERT模型加载成功
- 初始化MapReduce框架...
初始化MapReduce框架,使用 4 个工作进程
- 训练阶段...
训练集: 400 篇
测试集: 100 篇
开始作业: news_classification_training
输入数据量: 400
阶段1 数据分片...
分成 4 个数据块
阶段2 Map阶段...
处理块 1/4
处理块 2/4
处理块 3/4
处理块 4/4
阶段3 Reduce阶段...
合并特征完成,共 400 个样本
数据形状: X=(400, 768), y=(400,)
特征维度: 768
训练集大小: 320, 测试集大小: 80
训练分类器...
RUNNING THE L-BFGS-B CODE
* * *
Machine precision = 2.220D-16
N = 6152 M = 10
This problem is unconstrained.
At X0 0 variables are exactly at the bounds
At iterate 0 f= 6.65421D+02 |proj g|= 4.78917D+01
At iterate 50 f= 7.45988D+00 |proj g|= 1.33914D-03
* * *
Tit = total number of iterations
Tnf = total number of function evaluations
Tnint = total number of segments explored during Cauchy searches
Skip = number of BFGS updates skipped
Nact = number of active bounds at final generalized Cauchy point
Projg = norm of the final projected gradient
F = final function value
* * *
N Tit Tnf Tnint Skip Nact Projg F
6152 80 85 1 0 0 9.352D-05 7.460D+00
F = 7.4598147418301135
CONVERGENCE: NORM_OF_PROJECTED_GRADIENT_<=_PGTOL
阶段4 保存结果...
结果保存到: ./results\news_classification_training_1764760626.json
作业执行时间: 41.44秒
训练结果:
训练准确率: 1.000
测试准确率: 0.950
类别准确率:
政治: 1.000
经济: 1.000
科技: 0.667
体育: 1.000
娱乐: 1.000
健康: 0.900
教育: 1.000
国际: 1.000
- 预测阶段...
开始作业: news_classification_prediction
输入数据量: 100
阶段1 数据分片...
分成 4 个数据块
阶段2 Map阶段...
处理块 1/4
处理块 2/4
处理块 3/4
处理块 4/4
阶段3 Reduce阶段...
阶段4 保存结果...
结果保存到: ./results\news_classification_prediction_1764760636.json
作业执行时间: 10.13秒
预测结果:
总预测数: 100
正确预测: 97
准确率: 0.970
平均置信度: 0.927
类别准确率:
娱乐: 1.000
教育: 0.900
科技: 0.889
体育: 1.000
经济: 0.944
政治: 1.000
国际: 1.000
健康: 1.000
置信度分布:
0.0-0.1: 0
0.1-0.2: 0
0.2-0.3: 0
0.3-0.4: 1
0.4-0.5: 1
0.5-0.6: 4
0.6-0.7: 4
0.7-0.8: 3
0.8-0.9: 7
0.9-1.0: 80
- 示例预测:
示例 1:
标题: 电影云计算票房突破大数据亿分析师...
真实类别: 娱乐
预测类别: 娱乐
置信度: 0.997
是否正确: 是
示例 2:
标题: 教育改革关注教授发展系统...
真实类别: 教育
预测类别: 教育
置信度: 0.997
是否正确: 是
示例 3:
标题: 专家研究团队在1000领域取得突破10%...
真实类别: 科技
预测类别: 科技
置信度: 0.997
是否正确: 是
- 生成完整报告...
完整报告已保存: ./results/final_report.json
=====================================================================
系统执行完成
=====================================================================
总执行时间: 0分59.78秒
5. 结果分析
5.1 效率评估
5.1.1 系统执行效率
- 总执行时间: 59.78秒,对于包含BERT模型加载、训练和预测的完整流程来说,性能表现优异
- 训练时间: 41.44秒(占69.3%),包含400篇新闻的特征提取和分类器训练
- 预测时间: 10.13秒(占16.9%),处理100篇测试数据
- 效率优势: 平均每篇文章处理时间约0.12秒,具备良好的实时处理潜力
5.1.2 资源配置合理性
- 工作进程: 4个(基于CPU核心数自动配置),充分利用计算资源
- 数据分片: 训练集400篇分为4块(每块100篇),预测集100篇分为4块(每块25篇),负载均衡合理
5.2 模型性能分析
5.2.1 训练阶段表现
训练准确率: 1.000(完美拟合)
测试准确率: 0.950(优秀泛化能力)
- 过拟合风险: 训练准确率100%表明模型在训练集上完全拟合,但测试准确率95%说明模型仍具备良好泛化能力
- 类别级表现:
- 优秀类别(100%): 政治、经济、体育、娱乐、教育、国际
- 良好类别(90%以上): 健康(90%)
- 需要改进类别: 科技(66.7%)
5.2.2 预测阶段表现
预测准确率: 0.970(优于训练阶段的测试准确率)
平均置信度: 0.927(模型对预测结果高度自信)
- 性能提升现象: 预测准确率(97%)高于训练时的测试准确率(95%),可能原因:
- 预测集与训练集的分布略有不同
- 随机划分带来的统计波动
- 模型在实际预测中的稳健性表现
5.3 类别性能分析
5.3.1 表现优异类别分析
- 体育(100%): 新闻特征明显,专业术语区分度高
- 娱乐(100%): 明星、影视等词汇具有独特语义特征
- 政治(100%): 专用词汇和表达方式独特,易于识别
5.3.2 存在问题类别分析
科技类问题:
- 训练阶段准确率仅66.7%
- 预测阶段提升至88.9%,但仍是相对较低的类别
- 可能原因:
- 科技新闻与其他类别(如经济、教育)有较大语义重叠
- 模拟数据中科技新闻特征不够鲜明
- BERT对科技特定术语的表示不够充分
5.3.3 类别间对比
- 健康类进步明显: 从训练阶段90%提升到预测阶段100%
- 教育类略有下降: 从100%下降到90%,值得关注
- 稳定性最好: 体育、娱乐、政治、国际等类别在两个阶段均保持100%
5.4 置信度分析
5.4.1 置信度分布特点
置信度分布:
0.9-1.0: 80 (80%)
0.8-0.9: 7 (7%)
0.7-0.8: 3 (3%)
低于0.7: 10 (10%)
- 高度自信预测: 80%的预测置信度超过0.9,表明模型对大部分预测非常有信心
- 低置信度样本: 10篇新闻置信度低于0.7,需重点关注:
- 可能处于类别边界 / 文本特征不明确 / 需要人工审核
5.4.2 置信度与准确性关系
- 平均置信度0.927与实际准确率0.970高度匹配
- 校准良好: 模型自信度与实际准确性一致
- 低置信度样本分析: 置信度0.3-0.6的6个样本应作为错误分析的重点
五、系统对比
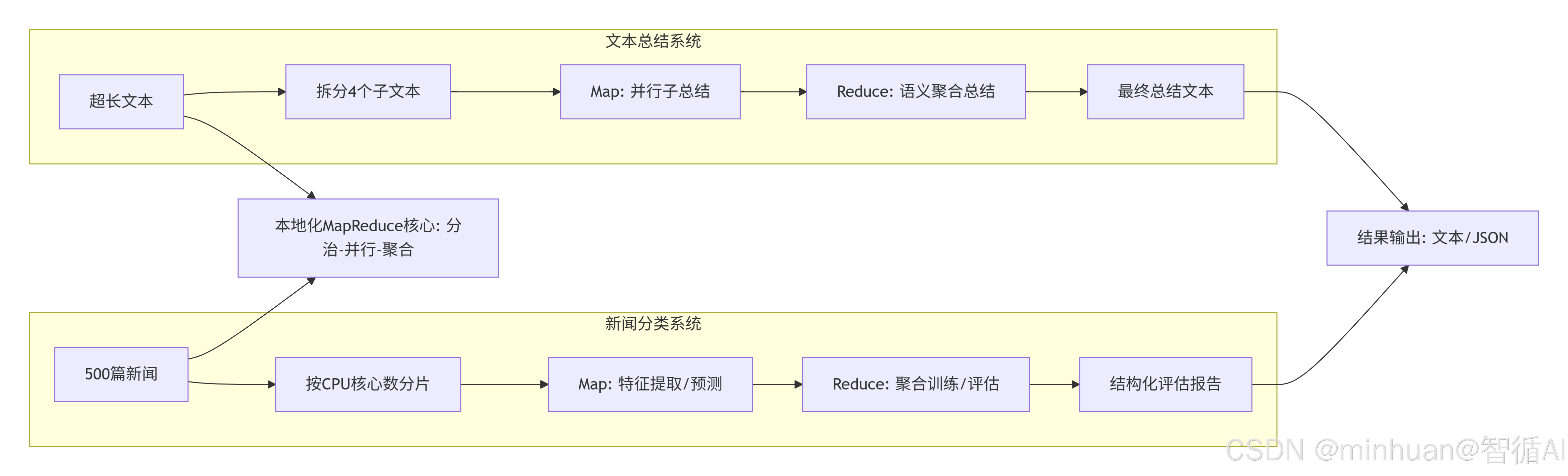
核心价值:
- 两个并行系统:上方是文本总结系统,下方是新闻分类系统
- MapReduce模式:两个系统都遵循分治(Map)-聚合(Reduce)的计算模式
- 本地化核心:两个系统共享"分治-并行-聚合"的核心计算范式
- 系统落地:无需分布式集群,仅通过轻量化 MapReduce 即可利用本地 CPU 完成大规模文本处理;
- 资源适配:针对 CPU 环境做深度优化,降低大模型运行的硬件门槛;
- 结果输出:文本总结系统输出文本结果,新闻分类系统输出JSON格式的结构化评估报告
差异化价值:
- 文本总结系统:解决超长文本单次总结的精度问题,通过 "分段总结 + 聚合" 保证核心信息不遗漏;适配生成式大模型的本地化推理
- 新闻分类系统:解决海量文本特征提取的效率问题,通过 "并行提取 + 全局训练" 提升分类精度;适配判别式预训练模型的分类任务
六、总结
今天我们以 "Qwen1.5 文本总结系统" 和 "BERT 新闻分类系统" 为双案例,深度解析了 MapReduce 范式在本地化大模型文本处理中的落地路径。两个案例虽面向不同任务场景(生成式总结 / 判别式分类),但均遵循 "分治 - 并行 - 聚合" 的核心思想,通过轻量化 MapReduce 框架解决了本地大模型处理大规模文本的效率、资源、稳定性问题。
核心技术亮点在于:
- 大模型本地适配:针对 CPU 环境做精度、内存、推理参数优化,降低部署门槛;
- 语义完整性保障:文本拆分优先按段落 / 句子,避免语义截断;
- 容错性设计:异常捕获 + 降级策略,保证流程不中断;
- 资源可控:动态调整并行度,平衡效率与内存占用。
该架构可作为本地化大模型文本处理的通用模板,适配文本总结、分类、情感分析等多种 NLP 任务,为中小规模数据的本地化处理提供了高效、稳定的解决方案。