在我们日常工作中,经常会遇到一些看似简单却极其繁琐的任务。手动处理一份结构复杂的Excel考勤表,就是典型的例子。它充满了合并单元格、不规则的布局和隐藏的格式陷阱。面对这样的挑战,我们是选择"卷起袖子,日复一日地手动复制粘贴",还是能换一种更聪明的"思考方式"来一劳永逸地解决问题?
答案当然后者。这种更聪明的思考方式,就是计算思维 (Computational Thinking) 。
计算思维并非程序员的专利,它是一种人人都可以学习和运用的高级问题解决框架。它包含四大核心原则,能帮助我们将现实世界中的复杂问题,转化为计算机可以理解并高效执行的解决方案。
今天,我将带你走一遍我们解决一个真实世界Excel自动化问题的旅程,并深入剖析这四大原则------分解 (Decomposition) 、模式识别 (Pattern Recognition) 、抽象 (Abstraction) 和算法设计 (Algorithm Design)。
第一步: 分解 (Decomposition) - 拆解问题
分解 ,顾名思义,就是将一个复杂的问题,系统性地拆解成一系列更小、更简单、更易于管理和解决的子问题。它的核心思想是分而治之。如果一个问题太大让你无从下手,那就把它分开,直到每一小块都变得清晰可见。
生活实例
想象一下你要策划一场大型的婚宴。直接面对"大型的婚宴"这个任务可能会让你头大。但如果你运用分解思维,你会自然地把它拆解成:
- 确定宾客名单:邀请谁?
- 选择场地与时间:在哪里办?什么时候办?
- 准备食物与饮料:大家吃什么,喝什么?
- 策划活动与娱乐:玩什么?
- 发送邀请函与确认 :如何通知大家?
现在,每一个子任务都变得具体、可执行,整个婚宴的策划也变得井井有条。
本项目应用
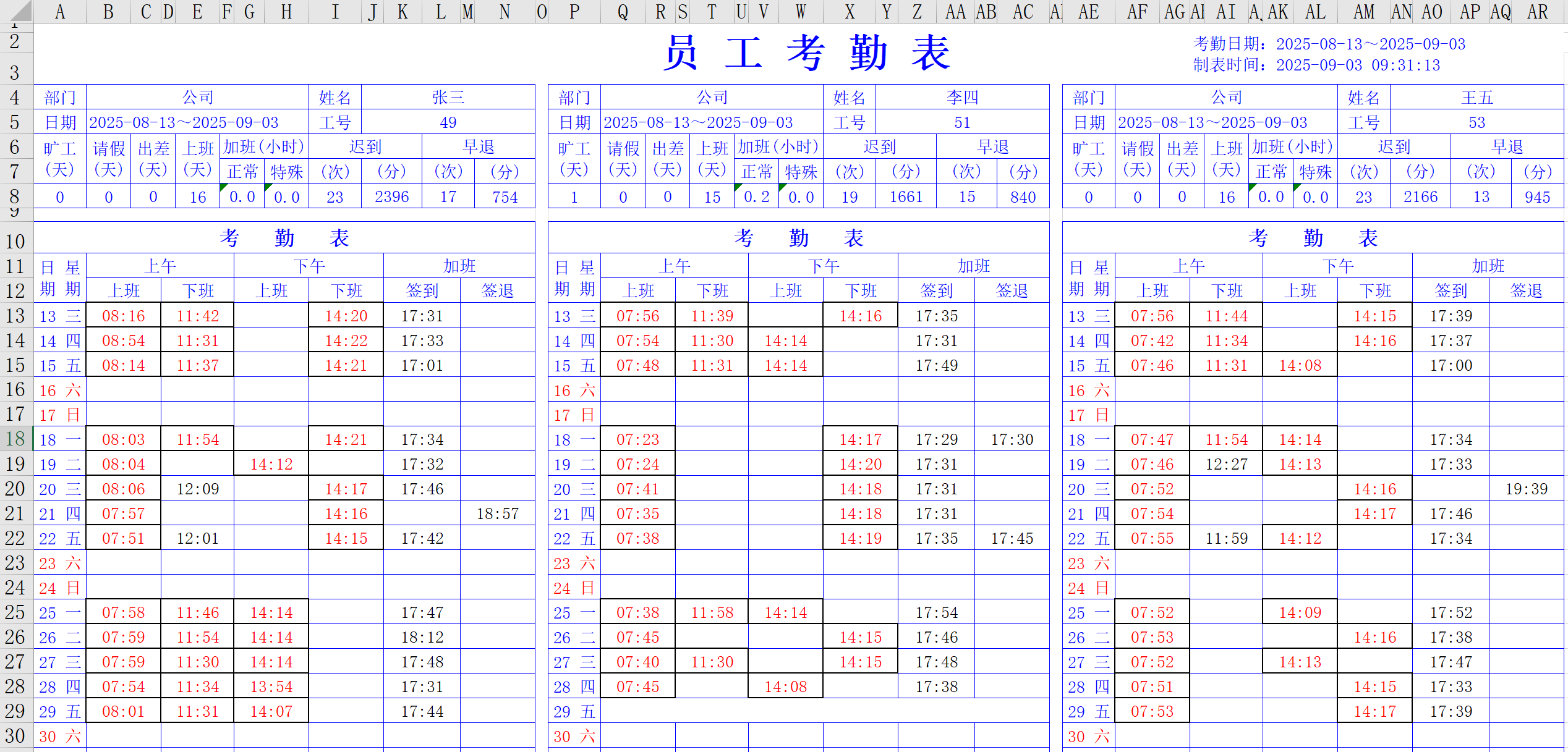
我们最初面对的"自动化处理考勤表"就是一个庞然大物。直接动手写代码,必然会陷入混乱。因此,我们首先对其进行了分解:
-
文件读取与兼容性问题 :如何让Python读取这个老旧的
.xls文件,并理解其内部的合并单元格结构? -
员工定位问题 :在一个Sheet内,如何准确地找到每一个员工(张三、李四、王五)的数据区域?
-
数据定位问题:对于每一个员工,如何精确地找到其打卡记录的起始行?
-
数据提取问题:如何从充满合并单元格的行中,准确地抓取到每一个独立的打卡时间?
-
日期与时间处理问题 :如何将Excel的小数时间转换为
HH:MM格式?如何智能处理跨月份的日期? -
数据整合与排序问题:如何将所有零散数据,按照"工号从小到大"的顺序,聚合成"每人每天一行"的结构?
-
报表生成与格式化问题 :如何生成一个带有两级复杂表头的最终
.xlsx文件?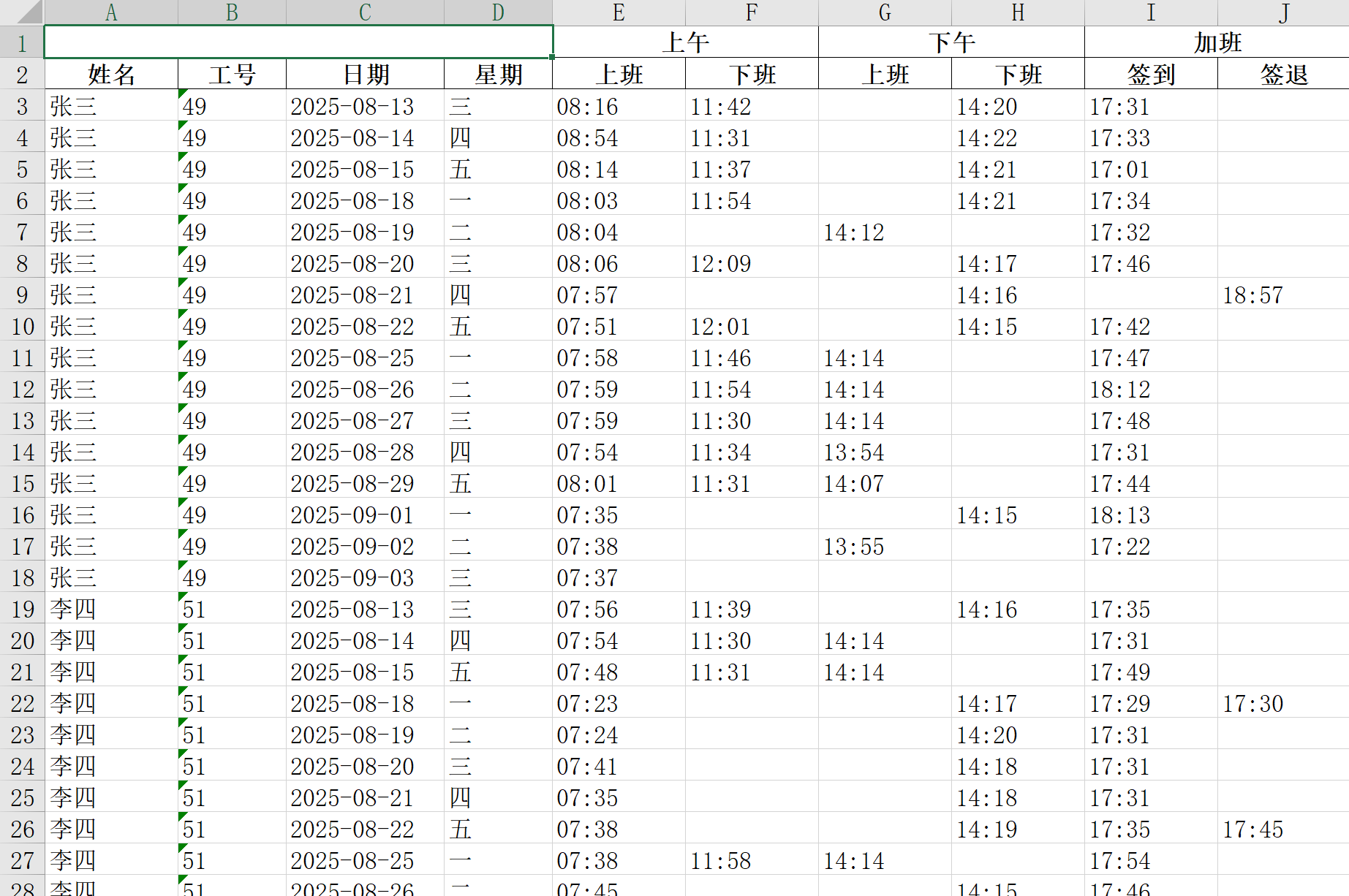
通过这次分解,原本模糊不清的任务被转化成了一张清晰的"任务清单"。我们可以逐个攻克这些子问题。
第二步:模式识别 (Pattern Recognition) - 寻找规律
模式识别是在不同的子问题或数据片段中,发现其共有的、重复出现的规律、趋势或特征。人类天生就擅长模式识别,而计算机则能将这种能力发挥到极致。识别出模式,是设计高效、可复用解决方案的前提。
生活实例
当你经常去超市买菜时,会发现一些规律:
- 牛奶、面包经常放在一起 → 因为它们常被一起买。
- 水果的价格通常周末打折 → 你学会了挑选最佳购买时间。
- 打折标签的颜色总是红色 → 一眼就能识别出来哪些是优惠商品。
久而久之,你不需要每次都从头到尾逛一遍超市,而是根据这些规律,直接去"该去的货架",用更快更省钱的方式完成购物。这种模式识别,就像计算机在处理大量数据时,发现隐藏的共性,从而提高效率。
本项目应用
在分解后的子问题中,我们开始运用模式识别来寻找自动化处理的突破口:
-
识别出"员工布局模式":我们观察到,三个员工的数据块并非随机排列,而是以一个**"固定间隔(约15列)"**的模式横向展开。这个发现让我们无需为每个员工都去手动定位,而是可以用一个简单的循环和固定的步长来批量处理。
-
识别出"数据列模式" :我们发现,每个员工内部的列布局也是高度一致的。无论员工数据从哪一列开始,他的"上午上班"时间总是在其起始列的**"右边第1格"。这个"相对列偏移量"**的模式是通用的,它构成了我们数据提取算法的核心。
-
识别出"跨月模式" :我们注意到,当日期从
31号突然变为1号时,这标志着一个必然发生的**"月份更替"**模式。这个规律让我们能够设计出智能判断日期并自动更新月份的逻辑。模式识别让我们从繁杂的细节中提炼出了普适的规则,为"一次编写,到处适用"的自动化方案奠定了基础。
第三步:抽象 (Abstraction) - 抓住本质
抽象是计算思维中最具创造力的一步。它要求我们主动忽略那些与当前目标无关的、次要的、令人分心的细节,将问题的核心本质提炼出来,并用一个简洁的模型或概念来代表它。就像一张地铁线路图,它忽略了真实的街道和建筑,只保留了站点和线路这些核心信息。
生活实例
当你开车时,你不需要理解发动机的内燃原理、变速箱的齿轮构造。你只需要知道踩下油门车会加速,转动方向盘车会转向。汽车设计师已经为你抽象出了一套简洁的"接口"(油门、刹车、方向盘),让你能够轻松地驾驭一个极其复杂的机械系统。
本项目应用
在我们的项目中,抽象思维的应用是解决最棘手问题的关键:
-
抽象出
get_cell_value函数 :面对各种不规则的合并单元格,我们没有陷入"这里是两格合并,那里是三格合并"的细节泥潭。我们进行了一次抽象 :我们不关心一个单元格如何 合并,我们只关心它的真实值是什么。于是,我们创造了
get_cell_value(sheet, row, col)这个"抽象模型"。它像一个黑盒子,封装了所有处理合并单元格的复杂逻辑。主程序只需调用这个函数,就能得到任何坐标的真实值,而无需关心其底层的合并状态。这个抽象让我们成功地忽略了"合并格式"这个最大的噪音。 -
抽象出"内存工作簿" :为了解决
.xls和.xlsx的兼容性问题,我们抽象出了一个"在内存中进行格式转换"的概念。主程序无需关心底层的库调用和数据复制过程,它只需要知道,通过一个简单的函数调用,就能得到一个可以直接处理的、现代化的工作簿对象。抽象,让我们能够站在更高的维度思考问题,用简洁的模型来驾驭底层的复杂性,写出更清晰、更易于维护的代码。
第四步:算法设计 (Algorithm Design) - 绘制清晰的行动路线图
算法设计是将我们通过前三个阶段得出的解决方案,转化为一步步清晰、明确、有序、可执行的指令集。一个好的算法,就像一份完美的菜谱,任何严格按照它执行的人(或计算机)都能做出同样美味的菜肴。
生活实例
宜家家具的组装说明书就是一份典型的算法。它没有长篇大论,而是用一系列带编号的、清晰的图示和步骤,告诉你:1. 拿出A号螺丝和B号木板;2. 将A拧入B的C孔中;3. ...。只要你严格遵循这个"算法",即使你不是木工,也能成功组装出一件家具。
本项目应用
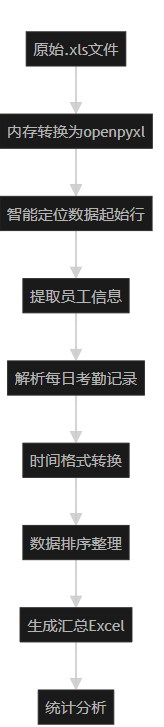
我们最终的Python脚本,就是我们为"处理考勤表"这个问题设计的终极算法。它的每一步都清晰无误:
- 初始化:准备好空的容器来存放数据。
- 预处理:调用"内存转换"抽象模型,解决文件格式问题。
- 循环与定位 :
a. 按照"员工布局模式",遍历每个员工块。
b. 智能地找到每个员工块的数据起始行。 - 数据提取 :
a. 在每个员工块内逐行读取。
b. 运用"跨月模式"和"相对列偏移量模式"。
c. 循环调用get_cell_value这个"抽象黑盒",安全地获取每一个打卡时间。 - 后处理:对提取到的所有数据进行排序和聚合。
- 生成报表 :调用
XlsxWriter,按照预设的格式和样式,手动构建并保存最终的Excel文件。
这个算法的每一步都直接源于我们之前的分析,它将我们的"思考"固化为了一套计算机可以精确执行的"行动计划"。
结论:计算思维,赋能未来的思考方式
通过这次真实的旅程,我们可以看到,计算思维并非编程本身,而是一种在编程之前、指导我们如何系统性地思考和解决问题的强大框架 。它是一套可以被任何人学习和应用的"思维工具箱"。当你再遇到一个令人头疼的、复杂的、重复性的任务时,无论是在工作中还是生活中,不妨先停下来,泡杯咖啡,尝试用分解、模式识别、抽象、算法设计这四个"镜头"去审视它。你可能会惊奇地发现,任何看似坚不可摧的复杂问题,都可以在这种系统性的思考方式下,被你优雅地、一步步地"攻破"。
源码
python
# 导入所有必需的"工具包",这是我们实现算法的基础。
import xlrd # 用于读取老旧的.xls文件格式。
import openpyxl # 用于处理现代的.xlsx文件格式,特别是其强大的合并单元格处理能力。
import re # 用于正则表达式,从字符串中精确提取日期范围等模式。
from datetime import datetime, time # 用于处理日期和时间对象。
import pandas as pd # 用于最终的数据整合与强大的Excel写入功能。
from collections import defaultdict # 用于创建一个方便的数据聚合结构。
# --- ABSTRACTION (抽象) 阶段 ---
# 我们将解决一个复杂问题的具体方法,封装成一个独立的、可复用的"黑盒子"。
# 主程序只需要知道这个函数能做什么(它的功能),而不需要关心它内部如何实现(它的细节)。
def convert_xls_to_xlsx_in_memory(xls_path):
"""
【抽象】将 .xls 文件转换为内存中的 .xlsx 对象。
这是一个核心的抽象,它将"解决文件格式兼容性"这个复杂的子问题,
封装成了一个简单的函数调用。主程序不再需要关心底层的格式转换细节。
"""
# DECOMPOSITION (分解): 这个问题被分解为三个小步骤:
# 1. 打开.xls文件。
# 2. 创建一个空的.xlsx对象。
# 3. 逐一复制数据和格式。
xls_book = xlrd.open_workbook(xls_path, formatting_info=True)
xlsx_book = openpyxl.Workbook()
for sheet_index in range(xls_book.nsheets):
xls_sheet = xls_book.sheet_by_index(sheet_index)
if sheet_index == 0:
xlsx_sheet = xlsx_book.active
xlsx_sheet.title = xls_sheet.name
else:
xlsx_sheet = xlsx_book.create_sheet(title=xls_sheet.name)
# 复制单元格的值
for row in range(xls_sheet.nrows):
for col in range(xls_sheet.ncols):
xlsx_sheet.cell(row=row + 1, column=col + 1).value = xls_sheet.cell_value(row, col)
# 复制合并单元格信息,这是确保格式正确的关键。
for crange in xls_sheet.merged_cells:
rlo, rhi, clo, chi = crange
xlsx_sheet.merge_cells(start_row=rlo + 1, start_column=clo + 1, end_row=rhi, end_column=chi)
# 清理openpyxl默认创建的不需要的'Sheet'。
if 'Sheet' in xlsx_book.sheetnames and len(xlsx_book.sheetnames) > 1:
del xlsx_book['Sheet']
return xlsx_book
def get_cell_value(sheet, row, col):
"""
【抽象】安全地获取单元格的值,能自动处理合并单元格。
这是整个项目中最重要的一个抽象。我们忽略了"两格合并还是三格合并"的复杂细节,
只关注"获取这个坐标的真实值"这一核心需求。
这个函数封装了所有与合并单元格相关的复杂逻辑。
"""
if row > sheet.max_row or col > sheet.max_column: return None
cell = sheet.cell(row=row, column=col)
# ALGORITHM (算法): 这里有一个清晰的算法来处理合并单元格。
# 1. 检查当前单元格是否在某个合并区域内。
# 2. 如果是,则找到该区域的起始单元格并返回其值。
# 3. 如果不是,则直接返回当前单元格的值。
for merged_range in sheet.merged_cells.ranges:
if cell.coordinate in merged_range:
return merged_range.start_cell.value
return cell.value
def parse_day_weekday(value_str):
"""
【抽象】从'13 三'这样的字符串中解析出日期和星期。
这个函数抽象了"从混合字符串中分离信息"的任务。
"""
if not value_str: return None, None
# PATTERN RECOGNITION (模式识别): 我们识别出这类字符串的模式总是 "数字 + 空格 + 字符"。
# 基于这个模式,我们使用 split() 方法进行分割。
parts = str(value_str).strip().split()
return (parts[0] if parts else None, parts[1] if len(parts) > 1 else None)
def excel_time_to_hhmm(excel_time):
"""
【抽象】将Excel的小数或时间对象转换为 HH:MM 格式的字符串。
封装了时间格式转换的逻辑,主程序无需关心Excel内部如何存储时间。
"""
if isinstance(excel_time, (datetime, time)):
return excel_time.strftime('%H:%M')
if isinstance(excel_time, (float, int)):
total_seconds = int(round(excel_time * 24 * 3600))
hours = total_seconds // 3600
minutes = (total_seconds % 3600) // 60
return f"{hours:02d}:{minutes:02d}"
if isinstance(excel_time, str):
return excel_time
return None
def find_data_start_row(sheet, start_col):
"""
【抽象】智能查找数据记录的起始行。
这个函数抽象了"定位数据从哪里开始"的问题,避免了硬编码行号带来的风险。
"""
# PATTERN RECOGNITION (模式识别): 我们识别出数据记录的上方必然存在一个包含"日 期"和"上班/上午"的表头行。
# 这个模式是定位的"路标"。
for r in range(10, 16):
header_val = str(get_cell_value(sheet, r, start_col) or "")
next_header_val = str(get_cell_value(sheet, r, start_col + 1) or "")
is_date_header = "日" in header_val and "期" in header_val
is_time_header = "上午" in next_header_val or "上班" in next_header_val
if is_date_header and is_time_header:
# ALGORITHM (算法): 我们的算法是:数据起始行 = 标题行 + 2。
return r + 2
print(f" -> 警告:未能自动定位到数据起始行,将使用默认值14。")
return 14
# --- ALGORITHM DESIGN (算法设计) 阶段 ---
# 这是整个解决方案的"总指挥部"或"菜谱"。
# 它清晰地定义了从头到尾的每一个步骤,并调用我们之前抽象好的函数来完成具体的子任务。
def process_attendance_final_solution(input_filename="考勤报表.xls"):
"""
终极版:这是解决整个考勤表问题的核心算法。
"""
# DECOMPOSITION (分解): 整个过程被分解为预处理、数据提取、后处理和报表生成四个主要步骤。
# === 步骤 1: 预处理 ===
try:
print("检测到 .xls 文件,正在进行内存转换...")
# 调用我们抽象好的函数,解决文件兼容性问题。
workbook = convert_xls_to_xlsx_in_memory(input_filename)
print("转换成功!开始处理数据...")
except FileNotFoundError:
print(f"错误:文件 '{input_filename}' 未找到。")
return
except Exception as e:
print(f"读取或转换Excel文件时出错: {e}")
return
# === 步骤 2: 数据提取 ===
if len(workbook.sheetnames) < 3:
print("错误:文件中的Sheet数量不足3个,无法跳过前两个总览表。")
return
sheets_to_process = workbook.sheetnames[2:]
print(f"将要处理的Sheet列表: {sheets_to_process}")
daily_records = defaultdict(dict)
date_range_for_filename = None
# PATTERN RECOGNITION (模式识别): 识别出员工数据块总是从这几列开始的模式。
employee_start_cols = [1, 16, 31]
# 外层循环: 遍历所有需要处理的Sheet。
for sheet_name in sheets_to_process:
print(f"\n--- 正在提取Sheet: '{sheet_name}' ---")
sheet = workbook[sheet_name]
# 中层循环: 遍历每个Sheet内的员工块。
for start_col in employee_start_cols:
name = get_cell_value(sheet, 4, start_col + 11)
if name is None or str(name).strip() == "": continue
emp_id_val = get_cell_value(sheet, 5, start_col + 11)
emp_id = str(int(float(emp_id_val))) if emp_id_val is not None else ""
print(f"找到员工: {name} (工号: {emp_id})")
# 调用抽象函数,智能定位数据从哪一行开始读取。
data_start_row = find_data_start_row(sheet, start_col)
print(f" -> 数据将从第 {data_start_row} 行开始读取。")
if date_range_for_filename is None:
date_cell_val = str(get_cell_value(sheet, 5, start_col + 1))
match = re.search(r'(\d{4}-\d{2}-\d{2})~(\d{4}-\d{2}-\d{2})', date_cell_val)
if match: date_range_for_filename = match.group(0)
start_date_str = (date_range_for_filename or "2025-01-01~2025-01-01").split('~')[0]
start_date = datetime.strptime(start_date_str, '%Y-%m-%d')
current_year, current_month, last_day = start_date.year, start_date.month, 0
# 内层循环: 逐行提取打卡记录。
for r in range(data_start_row, sheet.max_row + 1):
day_str, weekday = parse_day_weekday(get_cell_value(sheet, r, start_col))
if day_str is None: continue
try:
day = int(float(day_str))
except (ValueError, TypeError):
continue
# PATTERN RECOGNITION (模式识别): 识别并应用"跨月份"的模式。
if day < last_day:
current_month += 1
if current_month > 12: current_month, current_year = 1, current_year + 1
full_date_str, last_day = f"{current_year}-{current_month:02d}-{day:02d}", day
record_key = (name, emp_id, full_date_str, weekday)
# PATTERN RECOGNITION (模式识别): 应用"相对列偏移量"模式来定位各个时间点。
# ABSTRACTION (抽象): 每次都调用 get_cell_value 和 excel_time_to_hhmm 这两个"黑盒子"。
times = {
'上午上班': excel_time_to_hhmm(get_cell_value(sheet, r, start_col + 1)),
'上午下班': excel_time_to_hhmm(get_cell_value(sheet, r, start_col + 3)),
'下午上班': excel_time_to_hhmm(get_cell_value(sheet, r, start_col + 7)),
'下午下班': excel_time_to_hhmm(get_cell_value(sheet, r, start_col + 9)),
'加班签到': excel_time_to_hhmm(get_cell_value(sheet, r, start_col + 11)),
'加班签退': excel_time_to_hhmm(get_cell_value(sheet, r, start_col + 12)),
}
for event_type, event_time in times.items():
if event_time:
daily_records[record_key][event_type] = event_time
# === 步骤 3: 后处理 (排序与聚合) ===
if not daily_records:
print("\n未能提取到任何有效的考勤记录。")
return
print("\n--- 所有数据提取完毕,正在排序并生成最终报表... ---")
final_rows = []
# ALGORITHM (算法): 定义清晰的排序规则:先按工号(转为数字),再按日期。
sorted_records = sorted(daily_records.items(), key=lambda item: (int(item[0][1]), item[0][2]))
for (name, emp_id, date, weekday), times in sorted_records:
final_rows.append({
"姓名": name, "工号": emp_id, "日期": date, "星期": weekday,
"上午上班": times.get('上午上班'), "上午下班": times.get('上午下班'),
"下午上班": times.get('下午上班'), "下午下班": times.get('下午下班'),
"加班签到": times.get('加班签到'), "加班签退": times.get('加班签退'),
})
# === 步骤 4: 报表生成 ===
df = pd.DataFrame(final_rows)
output_filename = f"员工考勤表_最终版_{date_range_for_filename or ''}.xlsx"
try:
# ALGORITHM (算法): 这是一个手动构建复杂Excel文件的清晰算法。
# 1. 创建一个writer对象。
# 2. 将纯数据写入(从第3行开始)。
# 3. 手动写入并合并两级表头。
# 4. 调整格式。
# 5. 保存并关闭。
writer = pd.ExcelWriter(output_filename, engine='xlsxwriter')
df.to_excel(writer, sheet_name='考勤汇总', index=False, header=False, startrow=2)
workbook = writer.book
worksheet = writer.sheets['考勤汇总']
header_format = workbook.add_format({'bold': True, 'align': 'center', 'valign': 'vcenter', 'border': 1})
worksheet.write('A2', '姓名', header_format)
worksheet.write('B2', '工号', header_format)
worksheet.write('C2', '日期', header_format)
worksheet.write('D2', '星期', header_format)
worksheet.write('E2', '上班', header_format)
worksheet.write('F2', '下班', header_format)
worksheet.write('G2', '上班', header_format)
worksheet.write('H2', '下班', header_format)
worksheet.write('I2', '签到', header_format)
worksheet.write('J2', '签退', header_format)
worksheet.merge_range('A1:D1', '', header_format)
worksheet.merge_range('E1:F1', '上午', header_format)
worksheet.merge_range('G1:H1', '下午', header_format)
worksheet.merge_range('I1:J1', '加班', header_format)
worksheet.set_column('A:A', 10)
worksheet.set_column('B:B', 8)
worksheet.set_column('C:C', 12)
worksheet.set_column('D:D', 8)
worksheet.set_column('E:J', 10)
writer.close()
print(f"\n处理成功!\n汇总报表已保存为: '{output_filename}'")
except Exception as e:
print(f"保存最终文件时出错: {e}")
# 程序的入口点,算法从这里开始执行。
if __name__ == "__main__":
process_attendance_final_solution(input_filename="考勤报表.xls")