本系列文章将围绕东南亚头部科技集团 GoTerra 的真实迁移历程展开,逐步拆解 BigQuery 迁移至 MaxCompute 过程中的关键挑战与技术创新。本篇为第 9 篇,聚焦于 dbt‑maxcompute 在本次迁移中的落地实践与技术贡献。
本文围绕 dbt 在 GoTerra 项目中的实践,讲述 dbt-maxcompute 能为我们做哪些事,并通过示例来讲述 dbt 使用方式。
注:客户背景为东南亚头部科技集团,文中用 GoTerra 表示。
1. 前言与背景
GoTerra 作为东南亚数字经济的核心参与者,拥有巨大的出行、支付、电商、物流等多元业务矩阵。其数据体系每天处理 PB 级订单与交易,服务亿级用户。
在迁移至 MaxCompute 之前,GoTerra 的数据建模与转换主要依赖 BigQuery + dbt(data build tool) 组合:
-
BigQuery 提供 Serverless 的计算能力与较强的 SQL 表达力;
-
dbt 承载 SQL 组织、依赖管理、代码复用、测试与文档等能力,贯穿数据开发全流程。
为了在 MaxCompute 上延续这一高效、敏捷的开发模式,我们研发了 dbt‑maxcompute ------ 一个开源 dbt Adapter,旨在:
-
平滑迁移:让原有 BigQuery + dbt 项目能够在 MaxCompute 上以最小成本运行;
-
性能卓越:与 MaxCompute 特性深度结合,提供更好的性能表现;
-
生态兼容 :支撑第三方 dbt 包和组织内部开发规范,保护现有资产。
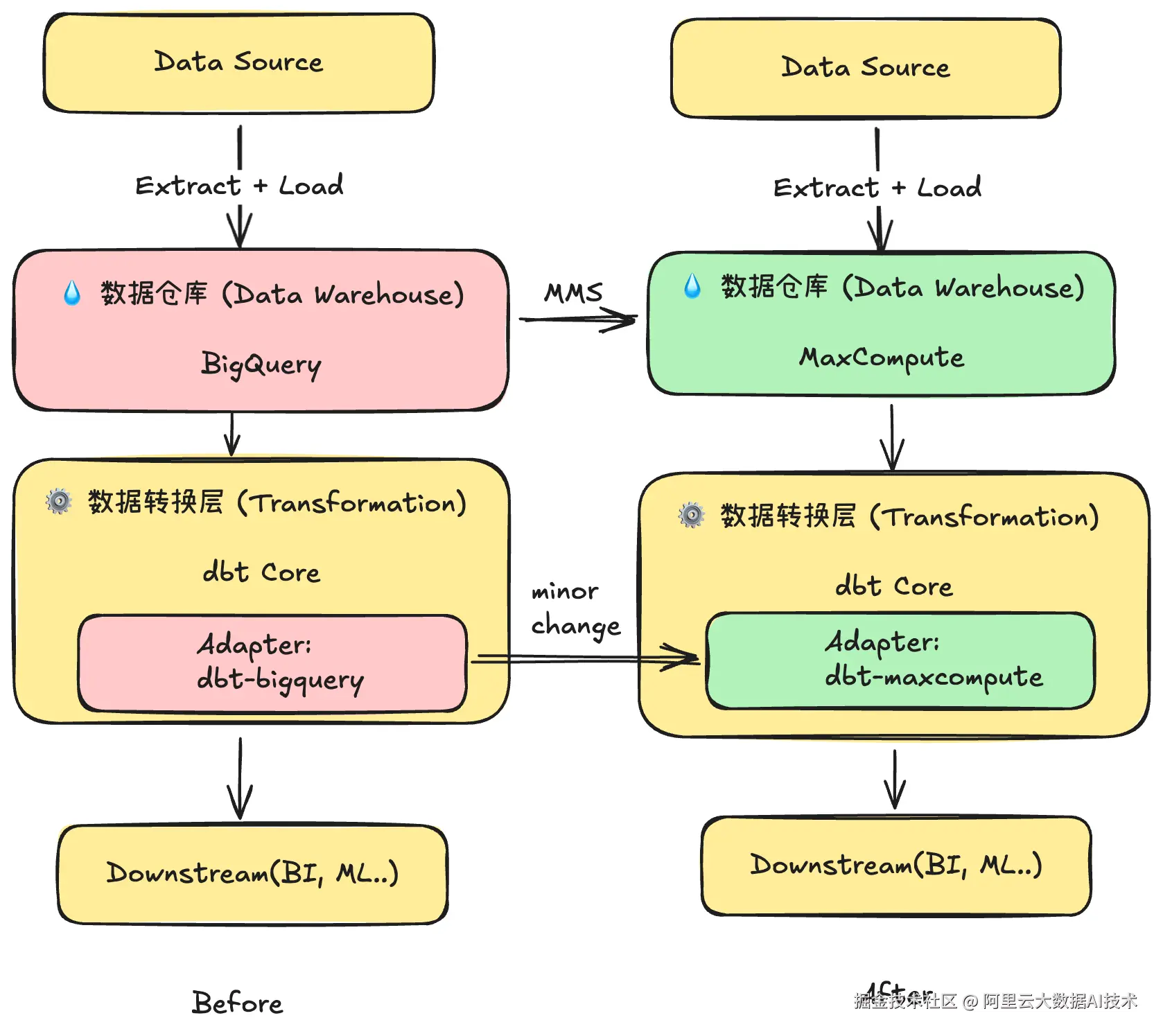
原BigQuery + dbt 架构" → "MC + dbt‑maxcompute 架构
2. dbt 理念:ELT 取代 ETL 的现代数据仓库实践
2.1 传统 ETL 模式的局限性
在传统的数据仓库架构中,ETL(Extract, Transform, Load)是标准的数据处理流程,但存在转换逻辑与存储分离、ETL 服务器成为性能瓶颈、开发维护成本高等问题。
2.2 dbt 主张的 ELT 新范式
dbt(data build tool)主张使用 ELT(Extract, Load, Transform)的新理念,将原始数据直接加载到数据仓库,再利用数据仓库强大的计算能力进行转换。这种模式带来了 简化架构、性能优势、开发高效、协作友好、可测试、可文档化 等诸多好处。
2.3 在 GoTerra 迁移项目中的价值体现
在 GoTerra 的迁移项目中,dbt 的 ELT 理念带来了显著价值:
-
快速迁移:原有的 BigQuery SQL 逻辑可以快速适配到 MaxCompute。
-
团队协作:基于 Git 的开发流程提升了庞大团队的协作效率。
-
质量保障:内置的测试框架确保了迁移后数据的质量。
-
文档透明:自动生成的数据文档提升了跨团队的业务理解度。
为了将 dbt 的理念在 MaxCompute 上完美落地,并解决 GoTerra 在真实业务场景中的具体痛点,dbt-maxcompute 并非简单的语法翻译器,而是深度结合 MaxCompute 原生能力的增强适配器。下面,我们将深入剖析在 GoTerra 项目中发挥关键作用的几大核心实践与技术贡献。
3. 核心实践(一):灵活的增量策略
3.1 背景与痛点
GoTerra 业务数据体量巨大,大部分事实表按时间分区。数据更新需求多样,既有全量覆盖,也有行级更新,对性能和成本极其敏感。因此,需要一套灵活、高效的增量处理方案来满足:
-
多样化的增量需求:适配不同业务线的更新频率和逻辑。
-
分区表优化:高效处理每日更新的最新数据分区。
-
性能与成本:在保证数据一致性的前提下,最大化性能、最小化资源消耗。
-
生态兼容:平滑迁移 dbt-bigquery 生态中已有的各种增量策略。
3.2 dbt-maxcompute 支持的全量增量策略
dbt-maxcompute 完整适配了 dbt 的所有增量策略,覆盖率 dbt-bigquery 支持的策略,便于 GoTerra 迁移并为 GoTerra 提供了灵活的增量处理能力。

dbt-maxcompute 与 dbt-bigquery 支持的增量策略对比
3.2.1 Merge 策略(默认策略)
Merge 策略通过一条原子性的 MERGE INTO 语句,优雅地实现了"如果记录存在则更新,不存在则插入"(即 UPSERT)的逻辑,是处理用户维度表(SCD Type 1)、数据去重等场景的理想选择。
在 MaxCompute 的数据开发实践中,开发者面临着不同表类型的选择。如果直接使用普通表(Non-Transactional Table), **MERGE** 语句是不可用的 。因此,为了在普通表上实现增量更新,一种常见的、但有风险的模式便是手动组合 DELETE + INSERT 操作。这种模式的致命缺陷在于其非原子性 :如果在 DELETE成功后 INSERT 失败,便会造成数据永久丢失,引发严重的数据质量问题。
dbt-maxcompute 巧妙地解决了这个问题。 它将 dbt 的增量策略与 MaxCompute 的底层表类型深度绑定。当开发者在模型中配置 strategy='merge' 时,dbt-maxcompute 会自动将目标表物化为支持 **MERGE** 操作的事务表(Transactional Table)或 Delta Table,而不是普通表。
Codegen SQL 代码示例:
sql
merge into target_table as DBT_INTERNAL_DEST
using temp_table as DBT_INTERNAL_SOURCE
on (DBT_INTERNAL_SOURCE.id = DBT_INTERNAL_DEST.id)
when matched then update set ...
when not matched then insert ...;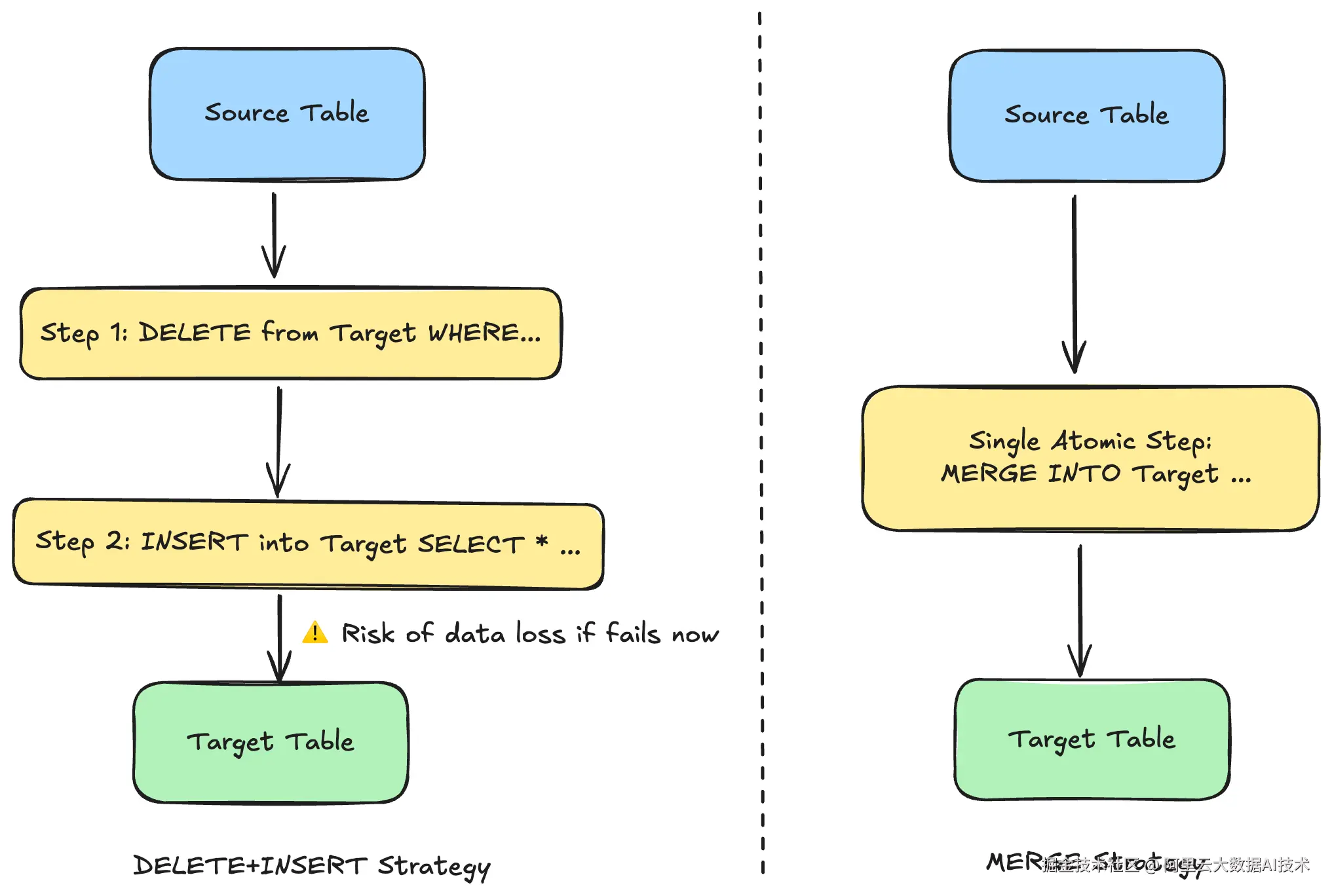
左侧在普通表上采用的 DELETE + INSERT 手动更新方式,右侧为 dbt-maxcompute 自动启用事务表后所使用的 MERGE 单步原子操作
GoTerra 应用场景 :在 GoTerra 的用户维度表(一个典型的 SCD Type 1 场景)中,Merge 策略被广泛用于维护用户信息的最新状态。得益于 dbt-maxcompute 的自动化能力,开发团队无需手动管理表类型,就能确保当用户联系方式或地址变更时,记录被安全、可靠地更新,杜绝了数据在更新过程中丢失的风险。
3.2.2 Insert Overwrite 策略
通过 INSERT OVERWRITE 语句高效替换指定分区的数据,是处理大规模分区表的最佳选择。
Codegen SQL 代码示例:
sql
INSERT OVERWRITE TABLE target_table PARTITION(date_col)
(SELECT * FROM temp_table WHERE date_col in ('...'));
Insert Overwrite 策略只更新特定分区,节省资源消耗。
GoTerra 应用场景:在 GoTerra 的支付流水事实表(海量分区)场景下,Insert Overwrite 策略相比 Merge 能显著降低计算资源消耗,提升数据交付效率。
3.2.3 其他策略:Delete+Insert 与 Append
-
Delete+Insert:这是使用普通表时不支持 MERGE 语句时的经典实现方式,可以作为功能强大的 MERGE 的备选方案。
-
Append:最高性能的追加模式,适用于事件日志、不可变事实等场景。
3.3 策略选择矩阵
| 场景 | 推荐策略 | 原因 |
|---|---|---|
| 分区时间序列数据 | Insert Overwrite | 高效的分区替换 |
| 缓慢变化维度(SCD Type 1) | Merge | 原子更新和插入 |
| 事件日志 | Append | 性能优越,不担心数据重复 |
| 现有物化表为普通表 | Delete+Insert | 普通表不支持 Merge 操作 |
4. 核心实践(二):增强的 Table 物化
4.1 背景与挑战
MaxCompute 提供了 Append Delta Table、Auto Partition Table 等强大的原生表类型,而 dbt-core 原生的表参数无法直接定义这些高级特性。为了充分利用 MaxCompute 的能力,dbt-maxcompute 必须扩展其配置项。
4.2 技术方案与使用方式
dbt-maxcompute 增强了 config 宏,支持直接配置 MaxCompute 的高级表属性:
-
分区表 (
partition_by):支持静态和自动分区。 -
高性能写入表 (
tblproperties) :通过{"append2.enable": "true"}启用。 -
生命周期管理 (
lifecycle):自动管理数据保留时间。 -
Delta Table (
delta,primary_keys等):创建高性能事务表。
示例:创建自动分区表并开启高性能写入
sql
{{ config(
materialized='table',
partition_by={'fields': 'dt', 'data_types': 'timestamp'},
tblproperties={'append2.enable': 'true'},
lifecycle=90
) }}
select ...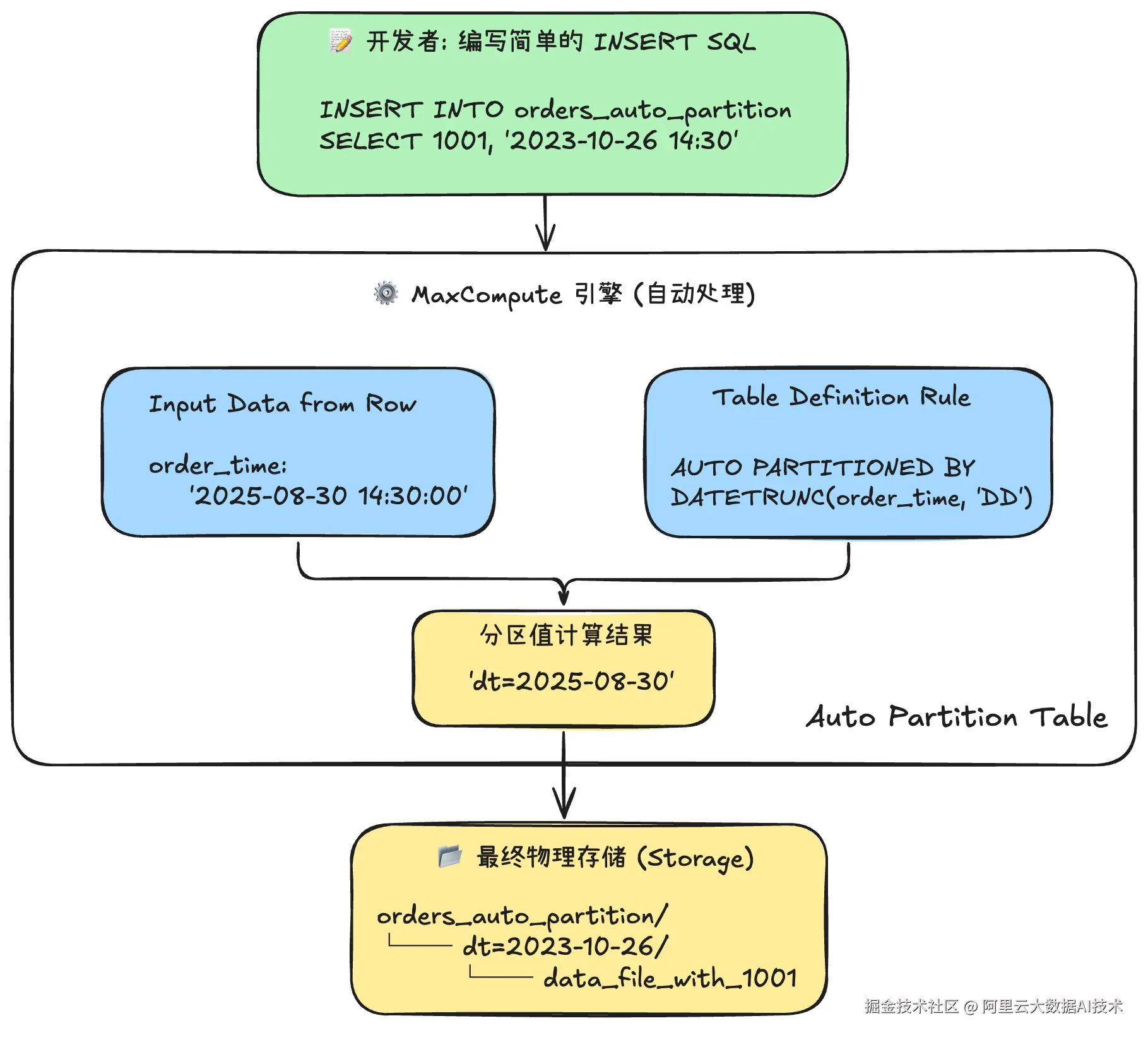
写入 Auto Partition Table 流程
关于 普通表,Transactional Table,Delta Table,以及 Append Delta Table 的介绍,可参考附录一
5. 核心实践(三):优化的 Seed 数据加载
5.1 背景与挑战
GoTerra 项目启动时,需要通过 dbt Seed 功能加载大量配置表和维度表。dbt-core 默认使用标准 INSERT 语句逐条加载,在 MaxCompute 上处理百万级记录时性能较差,初始化时间长。
5.2 技术方案与效果
dbt-maxcompute 对 Seed 加载进行了深度优化:
-
采用 Tunnel 加速:底层调用 MaxCompute 高效的 Tunnel 批量数据上传服务,绕过低效的 INSERT。
-
自动类型推断:根据 CSV 数据内容智能推断列类型。
实际效果 :在加载百万级配置表的场景中,性能提升数倍,大幅缩短了项目初始化时间并降低了资源消耗。
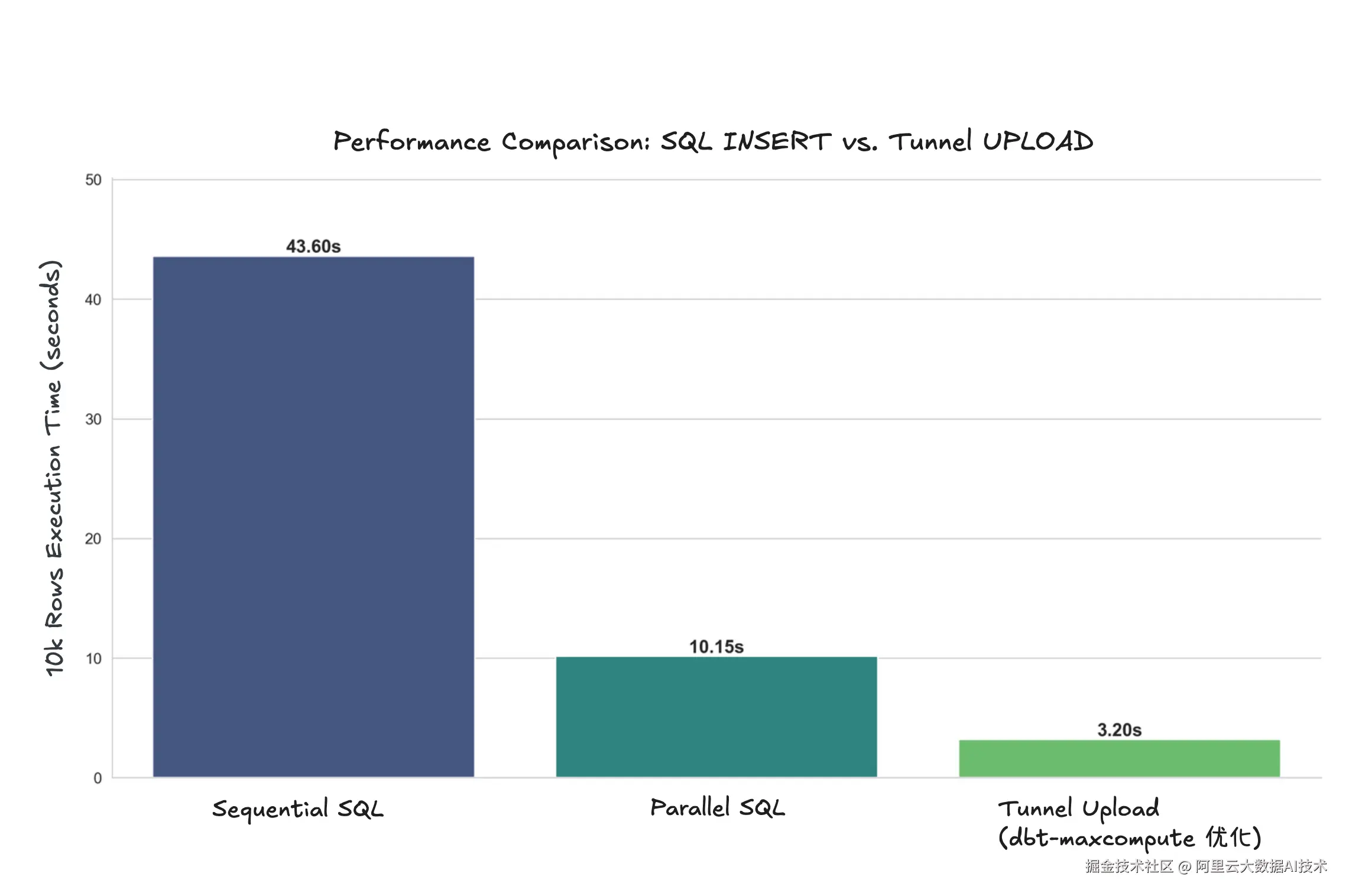
写入 1w 条数据所耗费的时间
6. 核心实践(四):数据新鲜度监控
6.1 背景与挑战
在 GoTerra 复杂的多源数据环境中,确保数据管道的健康和及时性至关重要。需要一种机制来:
-
监控关键源表的数据更新频率。
-
及时发现数据延迟或中断问题,触发告警。
6.2 技术方案与使用方式
dbt-maxcompute 完整实现了 dbt 的 source freshness 功能,并利用了 MaxCompute 的元数据特性进行优化。
-
技术方案 :优先利用 MaxCompute 表的
last_data_modified_time元数据属性来获取最后修改时间。这种方式 无需扫描数据,性能极高,几乎零开销。同时兼容基于时间戳字段的传统监控方式。 -
使用方式 :在
sources.yml中简单配置freshness阈值即可。
yaml
version: 2
sources:
- name: jaffle_shop
database: raw
tables:
- name: orders
freshness:
warn_after: { count: 6, period: hour }
error_after: { count: 12, period: hour }实际效果:在 GoTerra 的数百个源表监控场景中,建立了自动化的、高性能的数据新鲜度告警机制,极大提升了数据团队对数据管道健康状况的可见性。
7. 核心实践(五):第三方 dbt 包适配
7.1 挑战
GoTerra 的 dbt 项目广泛依赖 dbt-utils、dbt-date 等社区常用包。这些包中的宏函数(Macro)通常是为 BigQuery/Postgres 等数据库方言编写的,其 SQL 语法、函数、information_schema 查询等与 MaxCompute 不兼容。
7.2 改造点
为了让社区生态在 MaxCompute 上无缝运行,我们对常用包的核心宏进行了适配和重写,将它们分发到 dbt-maxcompute 适配器内部:
| 包名 | 改造内容 |
|---|---|
| dbt-utils | 适配聚合函数(如 listagg)、字符串函数和类型转换函数,映射到 MaxCompute 对应函数。 |
| dbt-date | 重写日期时间函数,如 datetrunc、datediff 等,使其适配 MaxCompute 语法。 |
| dbt-expectations | 适配数据质量测试宏,使其能在 MaxCompute 上执行。 |
| dbt-codegen | 适配生成模型或源配置的宏。 |
通过在 dbt-maxcompute 适配器中内建这些宏的 MaxCompute 版本,用户无需修改自己的业务代码,即可平滑迁移依赖这些包的 dbt 项目。
8. 总结与未来展望
在 GoTerra 从 BigQuery 向 MaxCompute 的迁移过程中,dbt‑maxcompute 不仅作为一个适配器工具成功落地,更是承载了迁移效率、性能优化、生态兼容三大核心任务,并在真实的 PB 级别业务场景中得到了检验与迭代。
回顾本次实践,dbt‑maxcompute 取得了显著成果:
- 无缝迁移
-
支持 BigQuery + dbt 项目的平滑切换,最小化改造成本。
-
完整适配 dbt 增量策略,满足 GoTerra 各业务线的多样化需求。
-
通过内建宏适配,使得
dbt-utils等第三方包开箱即用,保护现有 SQL 资产。
- 性能优化
-
物化模式与 MaxCompute 原生表(如 Delta Table)深度结合,显著缩短任务运行时间。
-
Seed 数据加载引入 Tunnel 加速,将初始化效率提升数倍。
-
Source Freshness 监控利用元数据实现,近乎零成本。
未来展望
dbt‑maxcompute 未来的演化方向将聚焦于:
- GA(General Availability)版本发布
- 通过更全面的测试与生产验证,提供企业级稳定性保障,发布正式版本。
- 更丰富的 MaxCompute 特性支持
-
深入支持 MaxCompute 新一代表格式与事务能力,结合数据湖生态。
-
提供智能化的增量策略推荐与执行优化。
- 社区化与开源协作
-
将通用适配逻辑贡献回 dbt-labs 和相关社区。
-
与社区维护者建立协作通道,保持与 dbt 最新版本同步。
-
打造基于 MaxCompute 的 dbt 最佳实践模板仓库。
我们相信,随着 dbt‑maxcompute 在功能和生态的双重迭代,它不仅会成为 MaxCompute 用户的重要建模工具,也会成为 东南亚乃至全球范围内大规模云数仓迁移与治理的通用方案。
附录一:MaxCompute 中的内表
为了帮助读者更好地理解 dbt-maxcompute 在不同场景下物化表的选择,本附录概述了 MaxCompute 中与 dbt 策略密切相关的几种核心内表类型及其演进关系。
| 表类型 (Table Type) | 主键支持 | 支持的关键操作 | 核心特点与适用场景 / 演进关系 |
|---|---|---|---|
| 普通表 (Standard Table) | 无 | INSERT OVERWRITE INSERT INTO |
定位 :MaxCompute 最基础、最常见的表类型,结构简单,专为大规模批量处理(ETL/ELT)设计。 适用场景 :适合经典的 dbt 全量物化 ( **materialized='table'**) 和 分区覆盖增量 ( **strategy='insert_overwrite'**)。不适用于需要行级更新的场景。 |
| 事务表 (Transactional Table) | 无 | MERGE INTO UPDATE DELETE |
定位 :MaxCompute 对 ACID 事务支持的早期探索版本 。它首次引入了 MERGE INTO等行级变更能力。 演进关系 :由于其性能限制和较旧的设计,官方已不推荐在新项目中使用,其功能已被 Delta Table 全面覆盖和优化。 |
| Delta 表 (Delta Table) | 强制要求 | MERGE INTO(UPSERT) UPDATE DELETE |
定位 :MaxCompute 当前主力推荐的增量事务表格式 ,是构建增全量一体化数仓的基石。 核心优势 :基于 Base+Delta 文件结构和主键,原生支持高效的 UPSERT、ACID 事务和时间旅行 (Time Travel)。 适用场景 :完美支持 dbt 的 **merge**策略 和 **snapshot**物化,是实现 SCD1 和 SCD2 的最佳选择。 |
| Append Delta 表 (Append Delta Table) | 可选 | INSERT INTO MERGE INTO |
定位 :Delta Table 的最新演进版本 ,旨在提供更大的灵活性。 核心优势 :移除了对主键的强制要求 。当不定义主键时,它像一个带事务能力的普通表,适合高性能的流式追加(Append-only);当定义主键时,其行为与 Delta 表一致。 适用场景:适用于需要事务保障但业务逻辑主要是追加写入的场景,如日志、事件流等。 |