4.4 组件级评估 (Component-Level Evals)
作者:司沐
课程地址: learn.deeplearning.ai/courses/agentic-ai
github地址: datawhalechina/agentic-ai
在上一节中,我们通过错误分析确定了要改进的单个组件,那么之后就是引入组件级评估针对性改进。
端到端评估和组件级评估的关系有些类似端到端测试/集成测试与单元测试:
-
端到端评估成本高昂,即使是更换搜索引擎这样的小改动,都需要重新运行整个复杂的工作流程进行端到端评估,时间和金钱成本很高。同时,其他组件的随机性或噪声可能会掩盖被改进组件带来的微小、增量改进。
-
组件级评估更高效, 信号更清晰,避免了整体系统的复杂性带来的噪声。还适用于团队分工: 如果有多个团队分别负责不同组件,每个团队可以自行维护指标。
接下来,我们以研究Agent的网页搜索为例,构建组件级评估。
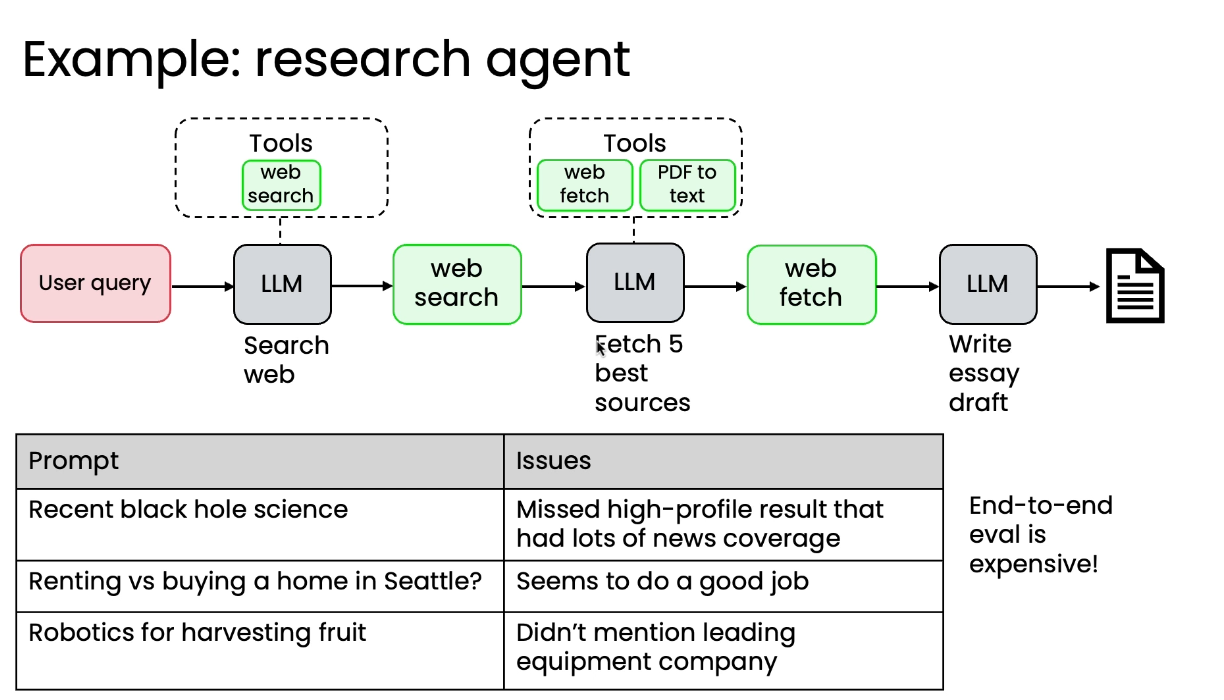
-
问题: 错误分析表明研究代理遗漏关键点的问题主要出在网页搜索组件上。
-
构建评估方法:
-
创建测试样例: 针对少数几个查询,请人类专家提供一份黄金标准网页资源列表,即最权威、最应该找到的网页。
-
编写评估代码: 使用信息检索领域的标准指标(如 F1 分数),编写代码来衡量网页搜索的输出列表与黄金标准列表之间的重叠程度。
-
-
用途:
-
利用这个指标,开发者可以快速高效地调整网页搜索组件的参数或超参数,如更换搜索引擎、更改结果数量、调整日期范围。
-
快速实现增量改进:在调优过程中,可以快速判断网页搜索质量是否提高。
-
组件级评估与端到端评估的关系与顺序如下:
-
通过错误分析确定一个问题组件(如网页搜索)。
-
构建和使用组件级评估来高效地进行调优和增量改进。
-
在调优后,运行最终的端到端评估,以验证组件的改进确实提升了整个系统的整体性能。
4.6 改进代理式 AI 工作流程组件的方法与模型选择技巧
在跑了评估,找到问题后,就要开始着手修改了。本节介绍的正是如何改善系统中不同组件的效果。
对于非 LLM 组件,比如网页搜索、RAG 检索、代码执行、传统 ML 模型来说,改进方式非常多样。
-
调整参数或超参数:
-
网页搜索: 调整结果数量、日期范围等。
-
RAG 检索: 更改相似度阈值、文本分块大小等。
-
人物检测: 调整检测阈值,以权衡误报和漏报。
-
-
替换组件: 尝试更换不同的服务提供商,如不同的 RAG 搜索引擎、不同的 Web 搜索 API找到最适合系统的一个。按笔者经验,在国内查询企业营收报表和财务信息,使用百度搜索的效果就远超Bing或Google,但查询学术资源却完全相反。
对于LLM 组件,改进主要围绕输入、模型本身和工作流程结构展开。
-
改进提示词:增加明确指令(在提示词中指明一些资源和任务应有的规划路径,而不是让LLM自己猜);使用少样本提示 (添加具体的输入和期望输出示例)
-
尝试不同的 LLM: 不要嫌麻烦,多测试几款 LLM,并使用评估 (Evals) 来选择最适合特定应用的最佳模型。
-
任务分解:如果单个步骤的指令过于复杂,导致 LLM 难以准确执行,考虑将任务分解为更小的、更易于管理的步骤,比如拆成生成步骤 + 反思步骤,或连续多次调用。
-
微调模型:这是最复杂、成本最高的选项。只有在穷尽所有其他方法后,仍需要挤出最后几个百分点的性能改进时才考虑。它适用于更成熟且性能要求极高的应用。
如果你之前也做过类似工作,那你一定拥有一定程度的模型选择直觉
比如笔者对于当前时间节点(2025年11月初)的模型,就认为Qwen比较嘴硬,Gemini2.5比较逆来顺受,GPT比较言简意赅,DeepSeek比较有创意和鬼点子。不同模型擅长的领域也不一样,比如Gemini对一口气生成上千行代码非常在行,而Claude对在现有系统里做小范围修改更有心得。如果谈到具体任务,那么嘴硬的Qwen就更适合用作一些比较严谨的,比如数据报表查询场景。又比如非常有逻辑但容易过度自信的KimiK2,就能在中低难度场景以简短而有信服力的输出大放异彩,但在比较复杂的场景要做好它过于自信而出错的心理准备。
在模型层面以外,还有其他类型的直觉,比如在笔者感受中,大参数模型通常比小参数模型的情商更高,对模糊指令的理解能力更强。最典型的例子是今年年初发布的昂贵的GPT-4.5,甚至可以在时下流行的"山东饭局"风格高情商场景下讲出让人眼前一亮的回复。
又比如,新架构+大参数量的模型,一般在多步骤复杂指令的任务中,能够完美地列出并编辑所有敏感信息,而较小的模型容易出错或遗漏信息。
拥有对不同 LLM 能力的直觉,能使开发者更高效地选择模型和编写提示词。这样的直觉要如何培养?
- 频繁试玩不同模型: 经常测试新的闭源和开源模型,观察它们在不同查询上的表现。
笔者对自己的要求是,至少有3~5种主力使用的模型(同一提供商只计算一次),并保持一个月内至少使用过10种以上模型,并能报出20种以上模型的型号。
-
建立个人评估集: 使用一套固定的评估任务来校准不同模型的能力。
-
阅读他人的提示词: 大量阅读从业者、专家或开源框架中的提示词,了解不同任务/模型/场景下的最佳实践,提高自己编写提示词的能力。
-
在工作流程中尝试: 实际在Agent工作流程中尝试不同的模型,查看追踪 (Traces) 和组件/端到端评估,观察它们在特定任务中的性能、价格和速度的权衡。