作者:来自 Elastic Jeffrey Rengifo
学习如何使用 LangExtract 从自由文本中提取结构化数据,并将其作为字段存储在 Elasticsearch 中。
Elasticsearch 配备了新功能,帮助你为你的用例构建最佳搜索解决方案。深入查看我们的示例笔记本以了解更多内容,开始免费的云试用,或立即在本地机器上尝试 Elastic。
LangExtract 是 Google 创建的一个开源 Python 库,它通过多个 LLM 和自定义指令帮助将非结构化文本转换为结构化信息。与单独使用 LLM 不同,LangExtract 提供结构化且可追溯的输出,将每个提取结果链接回原始文本,并提供可视化工具进行验证,使其成为在不同场景中进行信息抽取的实用解决方案。
当你想将非结构化数据 ------ 如合同、发票、书籍等 ------ 转换为定义好的结构,使其可搜索和可筛选时,LangExtract 就很有用。例如,对发票的支出进行分类、提取合同中的当事人,甚至检测书中某一段落人物的情绪。
LangExtract 还提供了一些功能,例如长上下文处理、远程文件加载、多轮处理以提高召回率,以及多工作线程并行处理。
用例
为了演示 LangExtract 和 Elasticsearch 如何协同工作,我们将使用一个包含 10 份不同类型合同的数据集。这些合同包含标准数据,如费用、金额、日期、期限和承包方。我们将使用 LangExtract 从合同中提取结构化数据,并将其作为字段存储在 Elasticsearch 中,从而可以对其运行查询和筛选。
你可以在这里找到完整的 notebook。
步骤
-
安装依赖并导入包
-
设置 Elasticsearch
-
使用 LangExtract 提取数据
-
查询数据
安装依赖并导入包
我们需要安装 LangExtract 来处理合同并从中提取结构化数据,同时还需要安装 elasticsearch 客户端来处理 Elasticsearch 请求。
erlang
`%pip install langextract elasticsearch -q`AI写代码依赖安装完成后,让我们导入以下内容:
-
json ------ 用于处理 JSON 数据
-
os ------ 用于访问本地环境变量
-
glob ------ 用于基于模式搜索目录中的文件
-
google.colab ------ 在 Google Colab notebooks 中很有用,可以加载本地存储的文件
-
helpers ------ 提供额外的 Elasticsearch 工具,例如批量插入或更新多个文档
-
IPython.display.HTML ------ 允许你在 notebook 中直接渲染 HTML 内容,使输出更易读
-
getpass ------ 用于安全输入敏感信息,如密码或 API key,而不会在屏幕上显示
python
`
1. import langextract as lx
2. import json
3. import os
4. import glob
7. from google.colab import files
8. from elasticsearch import Elasticsearch, helpers
9. from IPython.display import HTML
10. from getpass import getpass
`AI写代码设置 Elasticsearch
设置密钥
在开发应用之前,我们需要设置一些变量。我们将使用 Gemini AI 作为我们的模型。你可以在这里学习如何从 Google AI Studio 获取 API key。同时,确保你有一个 Elasticsearch API key 可用。
scss
`
1. os.environ["ELASTICSEARCH_API_KEY"] = getpass("Enter your Elasticsearch API key: ")
2. os.environ["ELASTICSEARCH_URL"] = getpass("Enter your Elasticsearch URL: ")
3. os.environ["LANGEXTRACT_API_KEY"] = getpass("Enter your LangExtract API key: ")
6. INDEX_NAME = "contracts"
`AI写代码Elasticsearch client
ini
`
1. es_client = Elasticsearch(
2. os.environ["ELASTICSEARCH_URL"], api_key=os.environ["ELASTICSEARCH_API_KEY"]
3. )
`AI写代码索引映射
让我们为要用 LangExtract 提取的字段定义 Elasticsearch 映射。注意,对于只想用于过滤的字段我们使用 keyword ,而对于既要搜索又要过滤的字段我们使用 text + keyword。
python
`
1. try:
2. mapping = {
3. "mappings": {
4. "properties": {
5. "contract_date": {"type": "date", "format": "MM/dd/yyyy"},
6. "end_contract_date": {"type": "date", "format": "MM/dd/yyyy"},
7. "service_provider": {
8. "type": "text",
9. "fields": {"keyword": {"type": "keyword"}},
10. },
11. "client": {"type": "text", "fields": {"keyword": {"type": "keyword"}}},
12. "service_type": {"type": "keyword"},
13. "payment_amount": {"type": "float"},
14. "delivery_time_days": {"type": "numeric"},
15. "governing_law": {"type": "keyword"},
16. "raw_contract": {"type": "text"},
17. }
18. }
19. }
21. es_client.indices.create(index=INDEX_NAME, body=mapping)
22. print(f"Index {INDEX_NAME} created successfully")
23. except Exception as e:
24. print(f"Error creating index: {e}")
`AI写代码使用 LangExtract 提取数据
提供示例
LangExtract 代码定义了一个训练示例,展示如何从合同中提取特定信息。
contract_examples 变量包含一个 ExampleData 对象,其中包括:
-
示例文本:一份包含典型信息(如日期、当事人、服务、付款等)的示例合同
-
预期提取结果:一个提取对象列表,将文本中的每条信息映射到一个特定类(extraction_class)及其规范化值(extraction_text)。extraction_class 将作为字段名,而 extraction_text 将作为该字段的值
例如,文本中的日期 "March 10, 2024" 被提取为类 contract_date(字段名),其规范化值为 "03/10/2024"(字段值)。模型通过这些模式学习,从而能从新合同中提取类似信息。
contract_prompt_description 提供了关于提取什么以及以什么顺序提取的额外上下文,用来补充单靠示例无法表达的内容。
ini
`
1. contract_prompt_description = "Extract contract information including dates, parties (contractor and contractee), purpose/services, payment amounts, timelines, and governing law in the order they appear in the text."
3. # Define contract-specific example data to help the model understand what to extract
4. contract_examples = [
5. lx.data.ExampleData(
6. text="Service Agreement dated March 10, 2024, between ABC Corp (Service Provider) and John Doe (Client) for consulting services. Payment: $5,000. Delivery: 30 days. Contract ends June 10, 2024. Governed by California law.",
7. extractions=[
8. lx.data.Extraction(
9. extraction_class="contract_date", extraction_text="03/10/2024"
10. ),
11. lx.data.Extraction(
12. extraction_class="end_contract_date", extraction_text="06/10/2024"
13. ),
14. lx.data.Extraction(
15. extraction_class="service_provider", extraction_text="ABC Corp"
16. ),
17. lx.data.Extraction(extraction_class="client", extraction_text="John Doe"),
18. lx.data.Extraction(
19. extraction_class="service_type", extraction_text="consulting services"
20. ),
21. lx.data.Extraction(
22. extraction_class="payment_amount", extraction_text="5000"
23. ),
24. lx.data.Extraction(
25. extraction_class="delivery_time_days", extraction_text="30"
26. ),
27. lx.data.Extraction(
28. extraction_class="governing_law", extraction_text="California"
29. ),
30. ],
31. )
32. ]
`AI写代码数据集
你可以在这里找到完整的数据集。下面是合同的示例:
markdown
`
1. This Contract Agreement ("Agreement") is made and entered into on February 2, 2025, by and between:
2. * Contractor: GreenLeaf Landscaping Co.
4. * Contractee: Robert Jenkins
6. Purpose: Garden maintenance and landscaping for private residence.
7. Terms and Conditions:
8. 1. The Contractor agrees to pay the Contractee the sum of $3,200 for the services.
10. 2. The Contractee agrees to provide landscaping and maintenance services for a period of 3 months.
12. 3. This Agreement shall terminate on May 2, 2025.
14. 4. This Agreement shall be governed by the laws of California.
16. 5. Both parties accept the conditions stated herein.
18. Signed:
19. GreenLeaf Landscaping Co.
20. Robert Jenkins
`AI写代码有些数据在文档中是明确写出的,但其他值可以由模型推断并转换。例如,日期将被格式化为 dd/MM/yyyy,期限以月为单位的会转换为天数。
运行提取
在 Colab notebook 中,你可以用以下方式加载文件:
go
`files.upload()`AI写代码LangExtract 使用 lx.extract 函数提取字段和值。必须对每个合同调用它,传入内容、提示、示例和模型 ID。
ini
`
1. contract_files = glob.glob("*.txt")
3. print(f"Found {len(contract_files)} contract files:")
5. for i, file_path in enumerate(contract_files, 1):
6. filename = os.path.basename(file_path)
7. print(f"\t{i}. {filename}")
9. results = []
11. for file_path in contract_files:
12. filename = os.path.basename(file_path)
14. with open(file_path, "r", encoding="utf-8") as file:
15. content = file.read()
17. # Run the extraction
18. contract_result = lx.extract(
19. text_or_documents=content,
20. prompt_description=contract_prompt_description,
21. examples=contract_examples,
22. model_id="gemini-2.5-flash",
23. )
25. results.append(contract_result)
`AI写代码为了更好地理解提取过程,我们可以将提取结果保存为 NDJSON 文件:
ini
`
1. NDJSON_FILE = "extraction_results.ndjson"
3. # Save the results to a JSONL file
4. lx.io.save_annotated_documents(results, output_)
6. # Generate the visualization from the file
7. html_content = lx.visualize(NDJSON_FILE)
9. HTML(html_content.data)
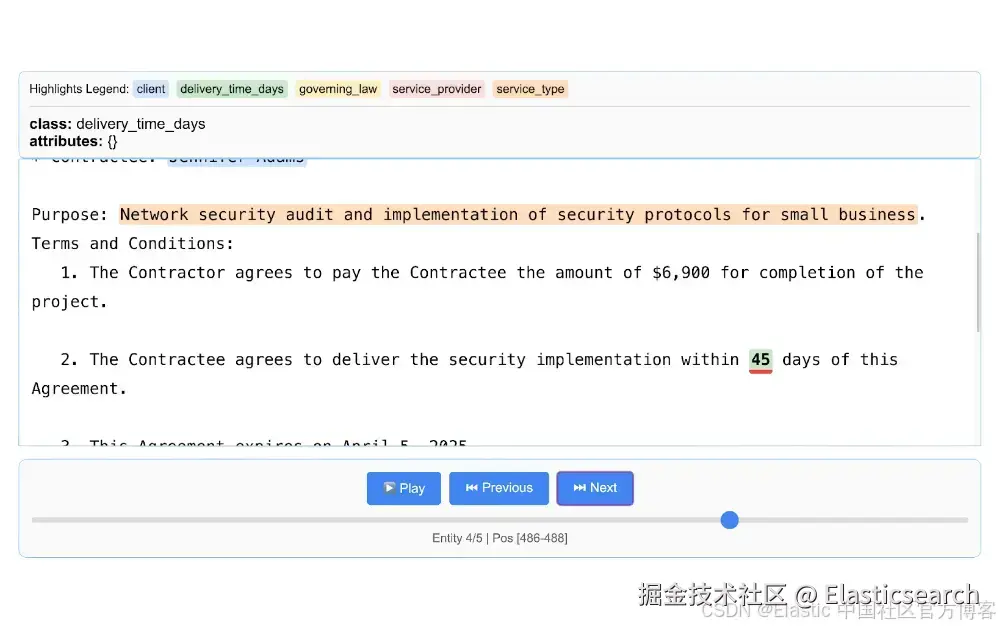
`AI写代码lx.visualize(NDJSON_FILE) 生成一个 HTML 可视化,其中包含单个文档的引用,你可以看到数据被提取的具体行。
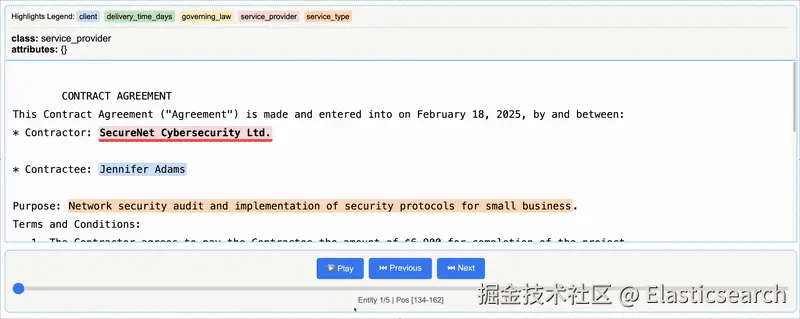
从一份合同中提取的数据如下所示:
swift
`
1. {
2. "extractions": [
3. {
4. "extraction_class": "contract_date",
5. "extraction_text": "02/02/2025",
6. "char_interval": null,
7. "alignment_status": null,
8. "extraction_index": 1,
9. "group_index": 0,
10. "description": null,
11. "attributes": {}
12. },
13. {
14. "extraction_class": "service_provider",
15. "extraction_text": "GreenLeaf Landscaping Co.",
16. ...
17. },
18. {
19. "extraction_class": "client",
20. "extraction_text": "Robert Jenkins",
21. ...
22. },
23. {
24. "extraction_class": "service_type",
25. "extraction_text": "Garden maintenance and landscaping for private residence",
26. ...
27. },
28. {
29. "extraction_class": "payment_amount",
30. "extraction_text": "3200",
31. ...
32. },
33. {
34. "extraction_class": "delivery_time_days",
35. "extraction_text": "90",
36. ...
37. },
38. {
39. "extraction_class": "end_contract_date",
40. "extraction_text": "05/02/2025",
41. ...
42. },
43. {
44. "extraction_class": "governing_law",
45. "extraction_text": "California",
46. ...
47. }
48. ],
49. "text": "This Contract Agreement (\"Agreement\") is made and entered into on February 2, 2025, by and between:\n* Contractor: GreenLeaf Landscaping Co.\n\n* Contractee: Robert Jenkins\n\nPurpose: Garden maintenance and landscaping for private residence.\nTerms and Conditions:\n 1. The Contractor agrees to pay the Contractee the sum of $3,200 for the services.\n\n 2. The Contractee agrees to provide landscaping and maintenance services for a period of 3 months.\n\n 3. This Agreement shall terminate on May 2, 2025.\n\n 4. This Agreement shall be governed by the laws of California.\n\n 5. Both parties accept the conditions stated herein.\n\nSigned:\nGreenLeaf Landscaping Co.\nRobert Jenkins",
50. "document_id": "doc_5a65d010"
51. }
`AI写代码基于此结果,我们将把数据索引到 Elasticsearch 并进行查询。
查询数据
将数据索引到 Elasticsearch
我们使用 _bulk API 将数据导入到 contracts 索引中。我们将把每个 extraction_class 结果存储为新字段,并将 extraction_text 作为这些字段的值。
python
`
1. def build_data(ndjson_file, index_name):
2. with open(ndjson_file, "r") as f:
3. for line in f:
4. doc = json.loads(line)
6. contract_doc = {}
8. for extraction in doc["extractions"]:
9. extraction_class = extraction["extraction_class"]
10. extraction_text = extraction["extraction_text"]
12. contract_doc[extraction_class] = extraction_text
14. contract_doc["raw_contract"] = doc["text"]
16. yield {"_index": index_name, "_source": contract_doc}
18. try:
19. success, errors = helpers.bulk(es_client, build_data(NDJSON_FILE, INDEX_NAME))
20. print(f"{success} documents indexed successfully")
22. if errors:
23. print("Errors during indexing:", errors)
24. except Exception as e:
25. print(f"Error: {str(e)}")
`AI写代码有了这些,我们就可以开始编写查询了:
go
`10 documents indexed successfully`AI写代码查询数据
现在,让我们查询已过期且付款金额大于或等于 15,000 的合同。
css
`
1. try:
2. response = es_client.search(
3. index=INDEX_NAME,
4. source_excludes=["raw_contract"],
5. body={
6. "query": {
7. "bool": {
8. "filter": [
9. {"range": {"payment_amount": {"gte": 15000}}},
10. {"range": {"end_contract_date": {"lte": "now"}}},
11. ]
12. }
13. }
14. },
15. )
17. print(f"\nTotal hits: {response['hits']['total']['value']}")
19. for hit in response["hits"]["hits"]:
20. doc = hit["_source"]
22. print(json.dumps(doc, indent=4))
24. except Exception as e:
25. print(f"Error searching index: {str(e)}")
`AI写代码结果如下:
bash
`
1. {
2. "contract_date": "01/08/2025",
3. "service_provider": "MobileDev Innovations",
4. "client": "Christopher Lee",
5. "service_type": "Mobile application development for fitness tracking and personal training",
6. "payment_amount": "18200",
7. "delivery_time_days": "100",
8. "end_contract_date": "04/18/2025",
9. "governing_law": "Colorado"
10. },
11. {
12. "contract_date": "01/22/2025",
13. "service_provider": "BlueWave Marketing Agency",
14. "client": "David Thompson",
15. "service_type": "Social media marketing campaign and brand development for startup company",
16. "payment_amount": "15600",
17. "delivery_time_days": "120",
18. "end_contract_date": "05/22/2025",
19. "governing_law": "Florida"
20. },
21. {
22. "contract_date": "02/28/2025",
23. "service_provider": "CloudTech Solutions Inc.",
24. "client": "Amanda Foster",
25. "service_type": "Cloud infrastructure migration and setup for e-commerce platform",
26. "payment_amount": "22400",
27. "delivery_time_days": "75",
28. "end_contract_date": "05/15/2025",
29. "governing_law": "Washington"
30. }
`AI写代码结论
LangExtract 使从非结构化文档中提取结构化信息变得更容易,具有清晰的映射并可追溯回源文本。结合 Elasticsearch,这些数据可以被索引和查询,从而能够对合同字段(如日期、付款金额和当事人)进行筛选和搜索。
在我们的示例中,我们保持数据集简单,但相同的流程可以扩展到更大的文档集合或不同领域,如法律、金融或医疗文本。你还可以尝试更多提取示例、自定义提示或额外的后处理,以优化结果以满足你的特定用例。