点一下关注吧!!!非常感谢!!持续更新!!!
🚀 AI篇持续更新中!(长期更新)
AI炼丹日志-31- 千呼万唤始出来 GPT-5 发布!"快的模型 + 深度思考模型 + 实时路由",持续打造实用AI工具指南!📐🤖
💻 Java篇正式开启!(300篇)
目前2025年09月08日更新到: Java-118 深入浅出 MySQL ShardingSphere 分片剖析:SQL 支持范围、限制与优化实践 MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解
章节内容
上节完成的内容如下:
- SparkSession
- RDD、DataFrame、DataSet
- 三者之间互相转换 详细解释

核心操作
Transformation(转换操作)
定义详解
Transformation是Spark中一类重要的操作类型,其核心特点是"懒执行"(Lazy Evaluation)。这意味着当我们在代码中调用Transformation操作时,Spark不会立即执行实际的计算任务,而是会:
- 记录下操作逻辑和依赖关系
- 构建一个逻辑执行计划(DAG,有向无环图)
- 返回一个新的数据集(RDD/DataFrame)表示转换后的数据形态
这种延迟执行机制带来了多个优势:
- 允许Spark优化整个执行计划
- 减少不必要的中间结果存储
- 提高整体执行效率
只有当遇到Action操作(如count()、collect()等)时,Spark才会触发整个执行计划的运算。
常见操作详解
select()
功能:从DataFrame中选择特定的列
参数说明:
- 可以接受列名的字符串列表
- 也可以通过Column对象指定
示例场景:
python
# 选择单列
df.select("name")
# 选择多列
df.select("name", "age")
# 使用表达式
df.select(df["name"], (df["age"]+1).alias("age_plus_one"))filter()
功能:根据条件过滤行数据
参数说明:
- 接受一个布尔表达式作为过滤条件
执行特点:
- 会生成一个新的DataFrame
- 不会改变原DataFrame
示例场景:
python
# 简单条件过滤
df.filter(df["age"] > 18)
# 复杂条件过滤
df.filter((df["age"] > 18) & (df["gender"] == "male"))join()
功能:合并两个DataFrame
常见join类型:
- inner join(内连接)
- outer join(外连接)
- left join(左连接)
- right join(右连接)
- cross join(交叉连接)
关键参数:
- 连接条件(on)
- 连接类型(how)
示例场景:
python
# 内连接
df1.join(df2, df1["id"] == df2["id"], "inner")
# 左连接
df1.join(df2, df1["id"] == df2["id"], "left")
# 多条件连接
df1.join(df2, (df1["id"] == df2["id"]) & (df1["date"] == df2["date"]))groupBy()
功能:按照指定列对数据进行分组
典型使用方式:
- 通常与聚合函数配合使用
- 可以指定一个或多个分组列
执行特点:
- 返回GroupedData对象
- 需要配合聚合操作使用
示例场景:
python
# 简单分组
df.groupBy("department")
# 多列分组
df.groupBy("department", "gender")
# 分组后聚合
df.groupBy("department").agg({"salary": "avg"})agg()
功能:执行聚合操作
常见聚合函数:
- count()
- sum()
- avg()
- max()
- min()
- first()
- last()
参数形式:
- 可以接受字典形式指定各列聚合方式
- 也可以使用表达式形式
示例场景:
python
# 字典形式聚合
df.agg({"age": "max", "salary": "avg"})
# 表达式形式聚合
from pyspark.sql import functions as F
df.agg(F.max("age"), F.avg("salary"))
# 与groupBy配合使用
df.groupBy("department").agg(F.avg("salary"), F.countDistinct("employee_id"))性能优化提示
- 尽量避免在Transformation中执行数据收集操作
- 合理选择join策略(广播join等)
- 注意数据倾斜问题,特别是在groupBy操作时
- 合理使用缓存策略(cache/persist)减少重复计算
Action(行动操作)
定义: Action操作会触发Spark的计算并返回结果。与Transformation不同,Action操作会执行整个计算逻辑,并产生最终的输出,如将结果写入外部存储或将数据返回给驱动程序。
常见操作:
- show(): 显示DataFrame的内容。
- collect(): 将DataFrame的数据收集到驱动程序上,作为本地集合返回。
- count(): 计算DataFrame中的行数。
- write(): 将DataFrame的数据写入外部存储(如HDFS、S3、数据库等)。
- take(): 返回DataFrame的前n行数据。
Action操作
与RDD类似的操作
- show
- collect
- collectAsList
- head
- first
- count
- take
- takeAsList
- reduce
与结构相关
- printSchema
- explain
- columns
- dtypes
- col
生成数据
保存并上传到服务器上
shell
EMPNO,ENAME,JOB,MGR,HIREDATE,SAL,COMM,DEPTNO
7369,SMITH,CLERK,7902,2001-01-02 22:12:13,800,,20
7499,ALLEN,SALESMAN,7698,2002-01-02 22:12:13,1600,300,30
7521,WARD,SALESMAN,7698,2003-01-02 22:12:13,1250,500,30
7566,JONES,MANAGER,7839,2004-01-02 22:12:13,2975,,20
7654,MARTIN,SALESMAN,7698,2005-01-02 22:12:13,1250,1400,30
7698,BLAKE,MANAGER,7839,2005-04-02 22:12:13,2850,,30
7782,CLARK,MANAGER,7839,2006-03-02 22:12:13,2450,,10
7788,SCOTT,ANALYST,7566,2007-03-02 22:12:13,3000,,20
7839,KING,PRESIDENT,,2006-03-02 22:12:13,5000,,10
7844,TURNER,SALESMAN,7698,2009-07-02 22:12:13,1500,0,30
7876,ADAMS,CLERK,7788,2010-05-02 22:12:13,1100,,20
7900,JAMES,CLERK,7698,2011-06-02 22:12:13,950,,30
7902,FORD,ANALYST,7566,2011-07-02 22:12:13,3000,,20
7934,MILLER,CLERK,7782,2012-11-02 22:12:13,1300,,10写入内容如下图所示: 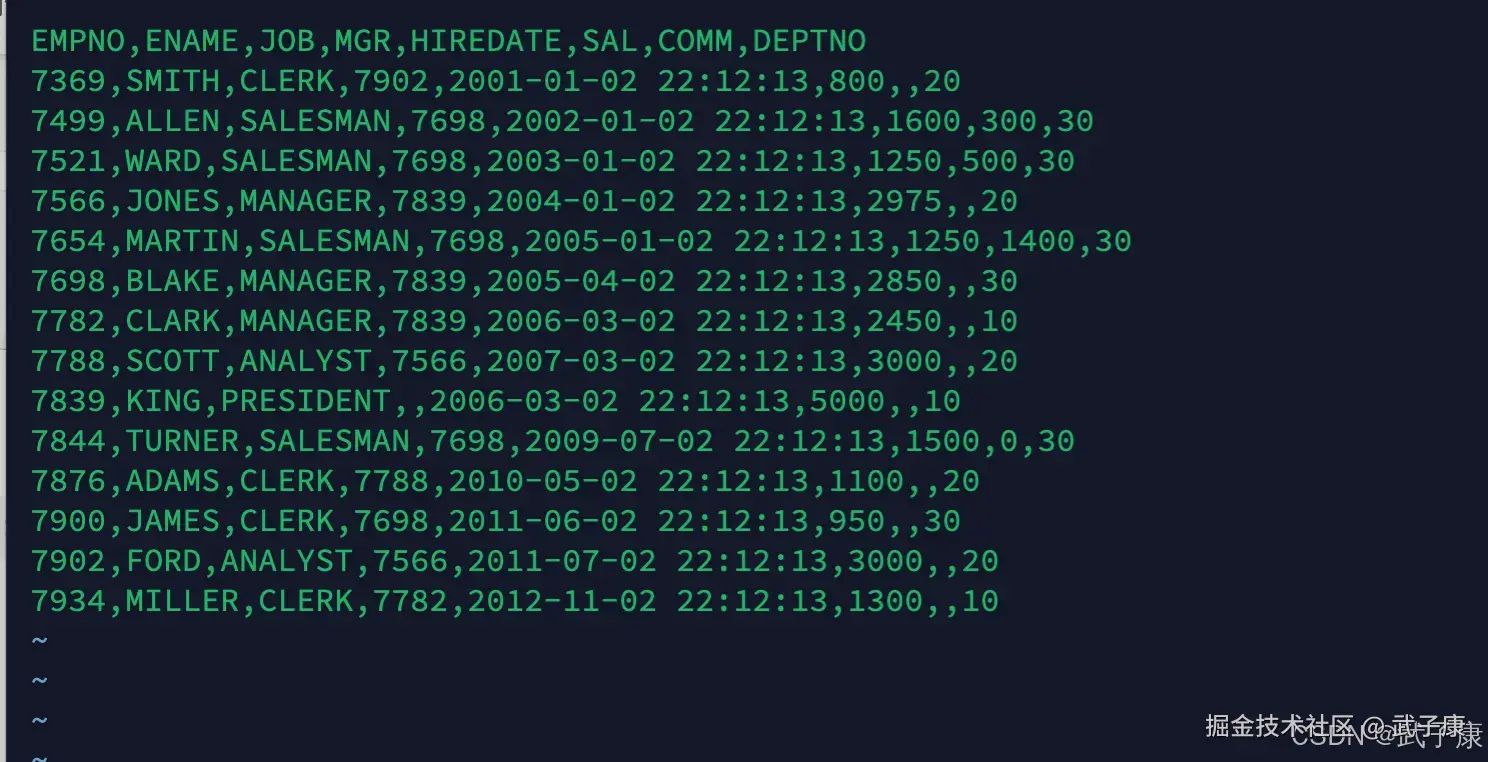
测试运行
我们进入 spark-shell 进行测试
scala
// 处理头,使用自动类型推断
val df1 = spark.read.option("header", true).option("infershema", "true").csv("test_spark_03.txt")
df1.count
// 缺省显示20行
df1.union(df1).show()
// 显示2行
df1.show(2)执行结果如下图所示: 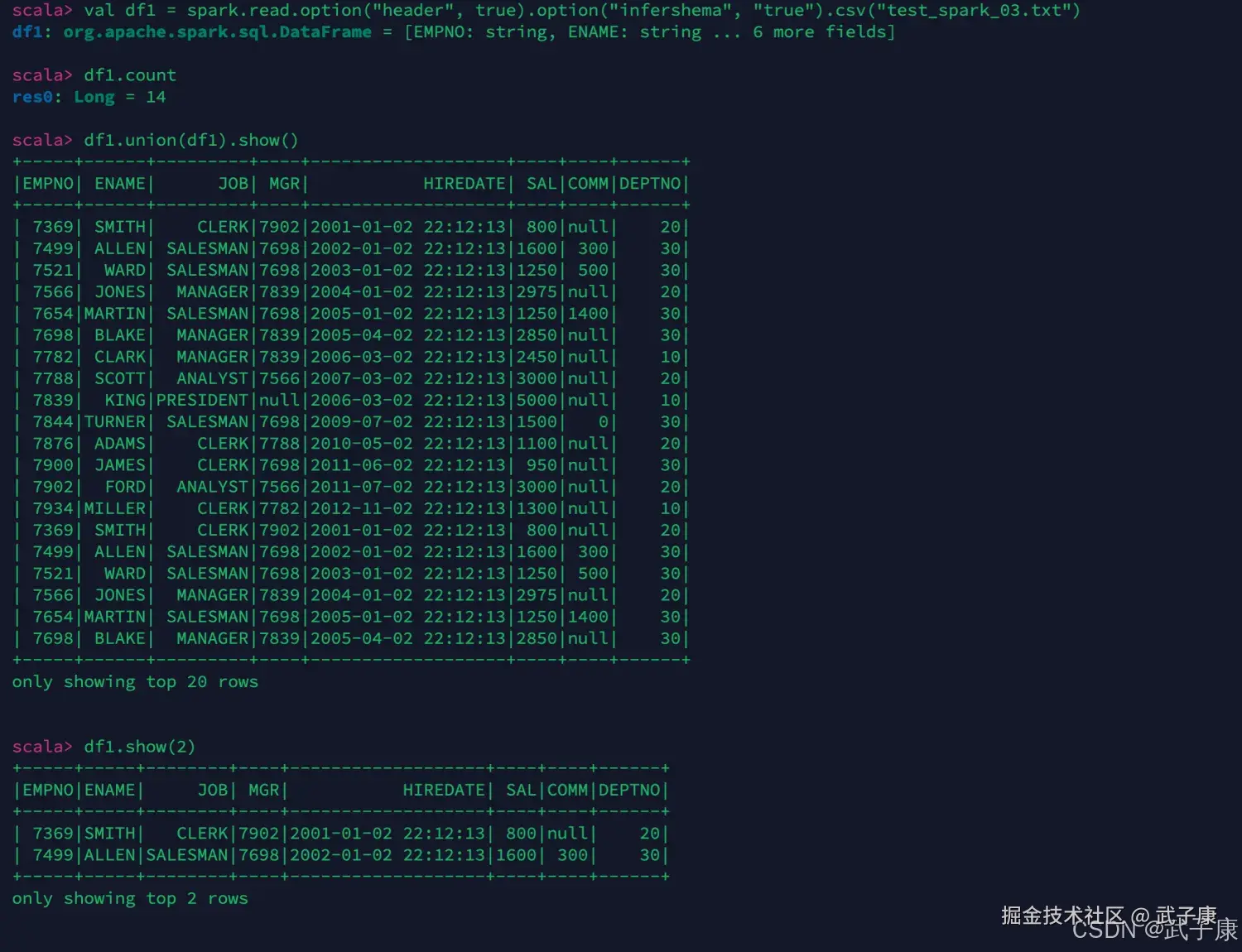 继续进行测试:
继续进行测试:
scala
// 不截断字符
df1.toJSON.show(false)
// 显示10行 不截断字符
df1.toJSON.show(10, false)运行结果如下图所示: 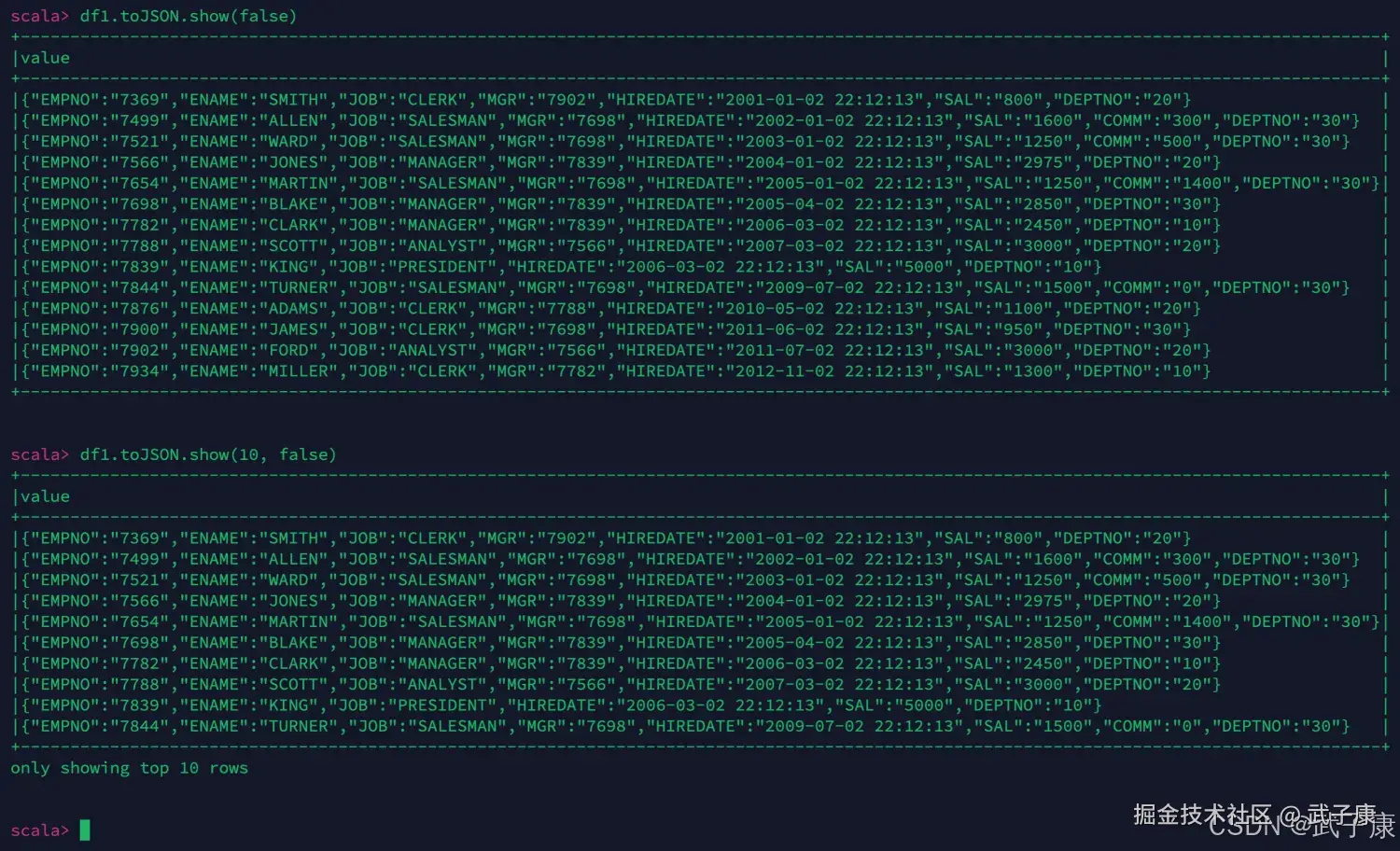 继续进行测试:
继续进行测试:
scala
// collect 返回数组 Array[Row]
val c1 = df1.collect()
// collectAsList 返回List Lits[Row]
val c2 = df1.collectAsList()
// 返回 Row
val h1 = df1.head()
val f1 = df1.first()
// 返回 Array[Row]
val h2 = df1.head(3)
val f2 = df1.take(3)
// 返回 List[Row]
val t2 = df1.takeAsList(2)运行结果如下图所示: 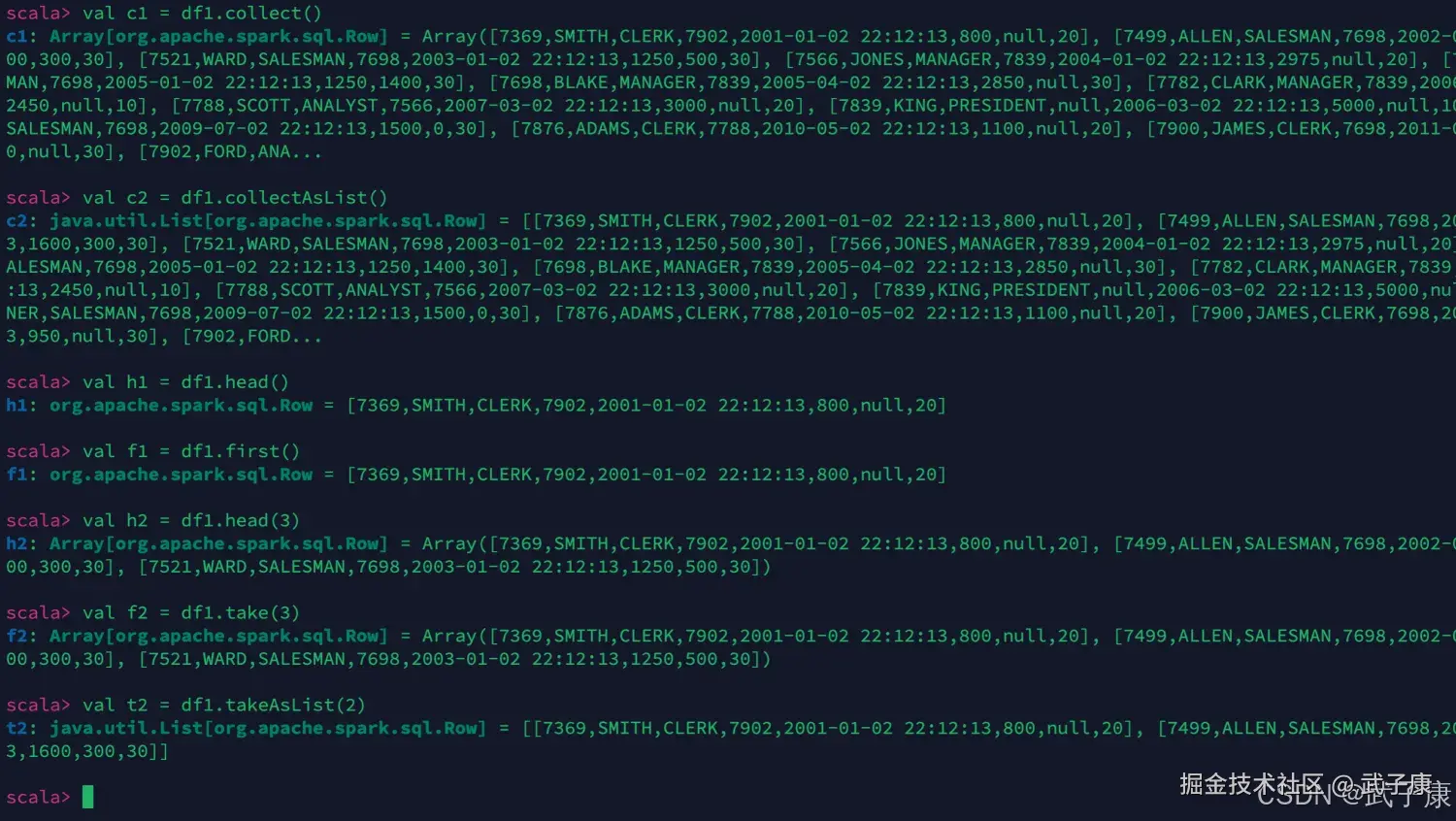 继续进行测试:
继续进行测试:
scala
// 结构属性
// 查看列名
df1.columns
// 查看列名和类型
df1.dtypes
// 查看执行计划
df1.explain()
// 获取某个列
df1.col("ENAME")
// 常用
df1.printSchema运行结果如下图所示: 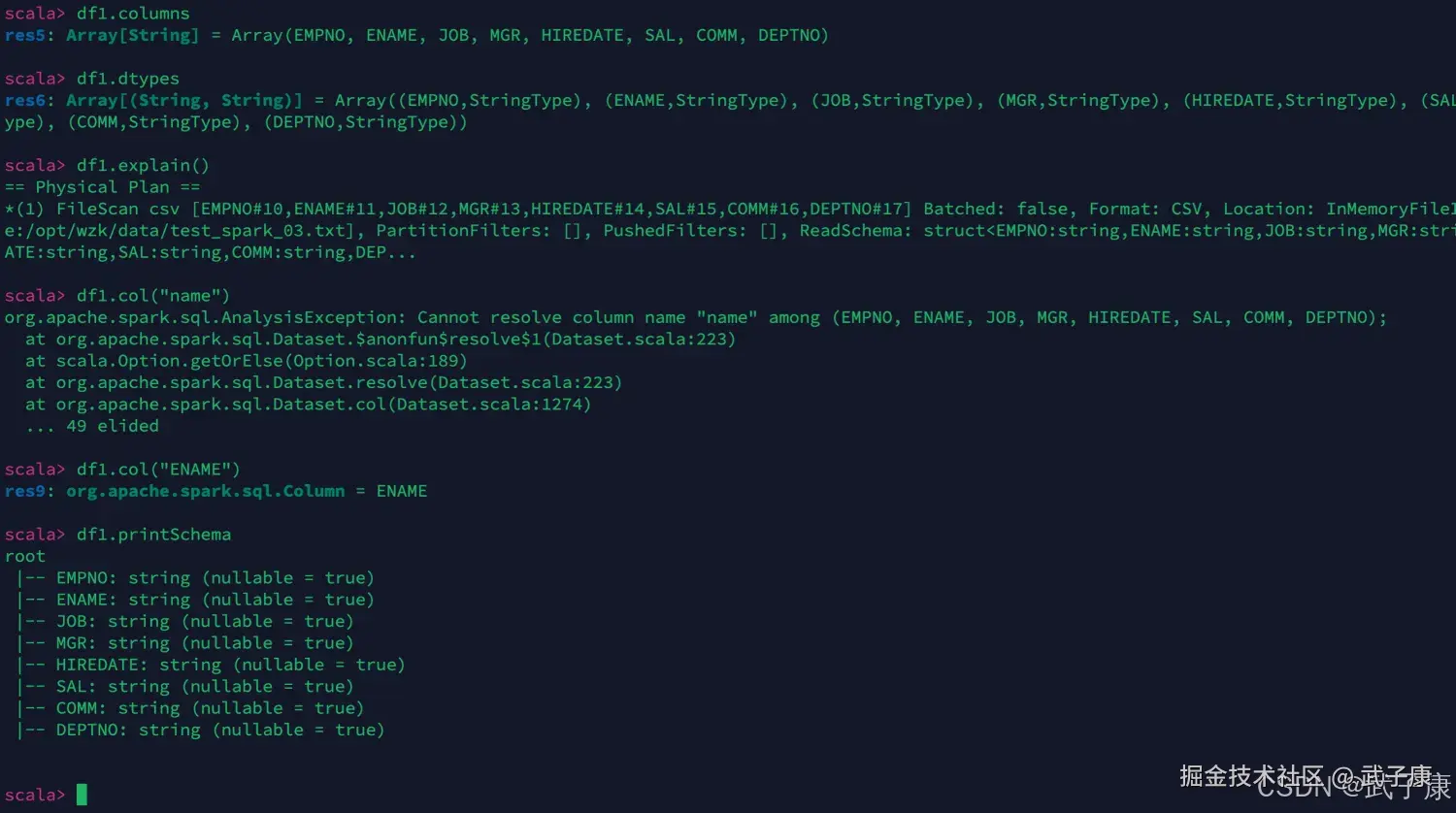
Transformation 操作
- RDD 类似的操作
- 持久化/缓存 与 checkpoint
- select
- where
- group by / 聚合
- order by
- join
- 集合操作
- 空值操作(函数)
- 函数
与RDD类似的操作
- map
- filter
- flatMap
- mapPartitions
- sample
- randomSplit
- limt
- distinct
- dropDuplicates
- describe
我们进行测试:
scala
val df1 = spark.read.csv("/opt/wzk/data/people1.csv")
// 获取第1列
df1.map(row => row.getAs[String](0)).show
// randomSplit 将DF、DS按给定参数分成多份
val df2 = df1.randomSplit(Array(0.5, 0.6, 0.7))
df2(0).count
df2(1).count
df2(2).count测试结果如下图: 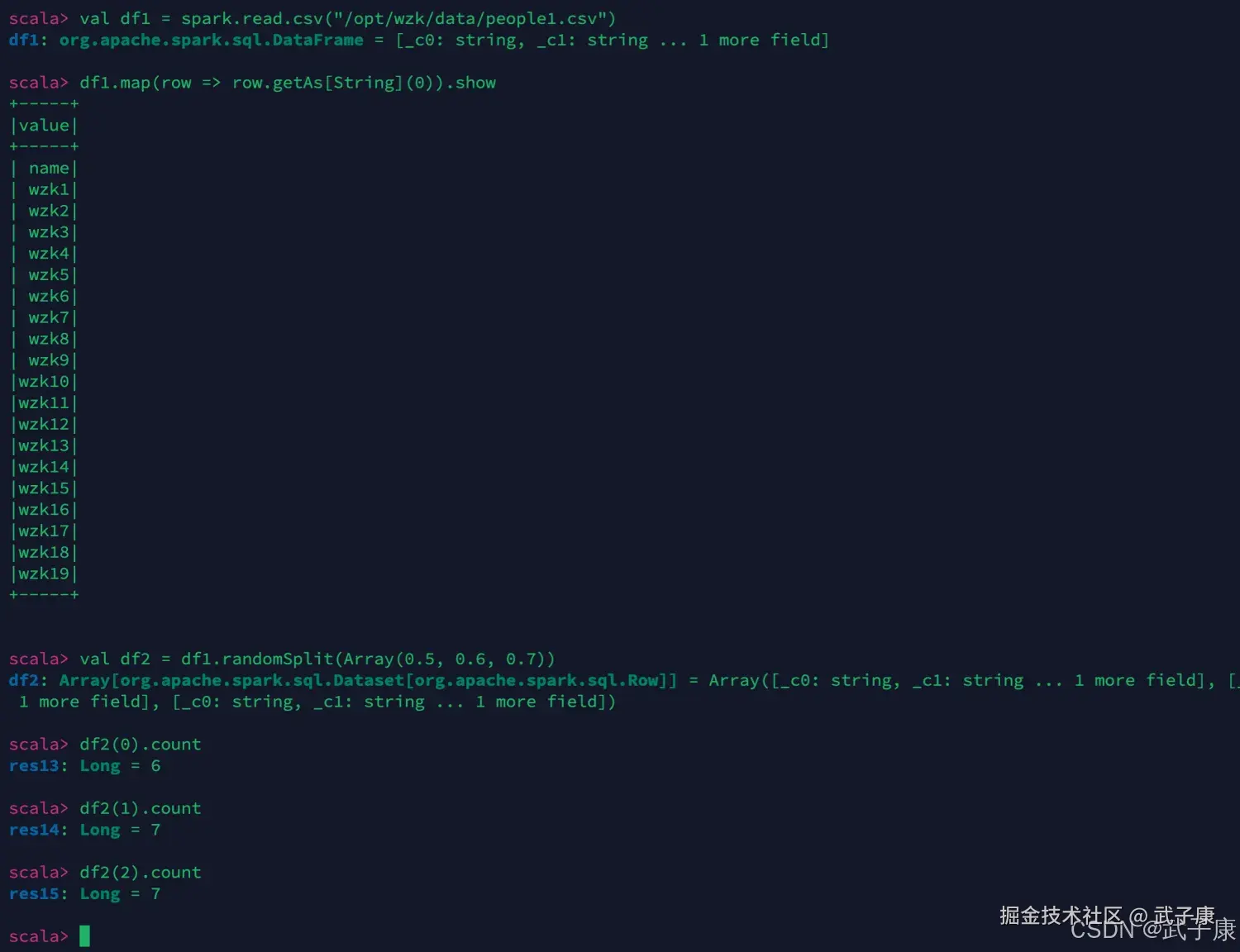
我们继续进行测试:
scala
// 取10行数据生成新的Dataset
val df2 = df1.limit(10)
// distinct 去重
val df2 = df1.union(df1)
df2.distinct.count
// dropDuplicates 按列值去重
df2.dropDuplicates.show
df2.dropDuplicates("_c0").show执行结果如下图: 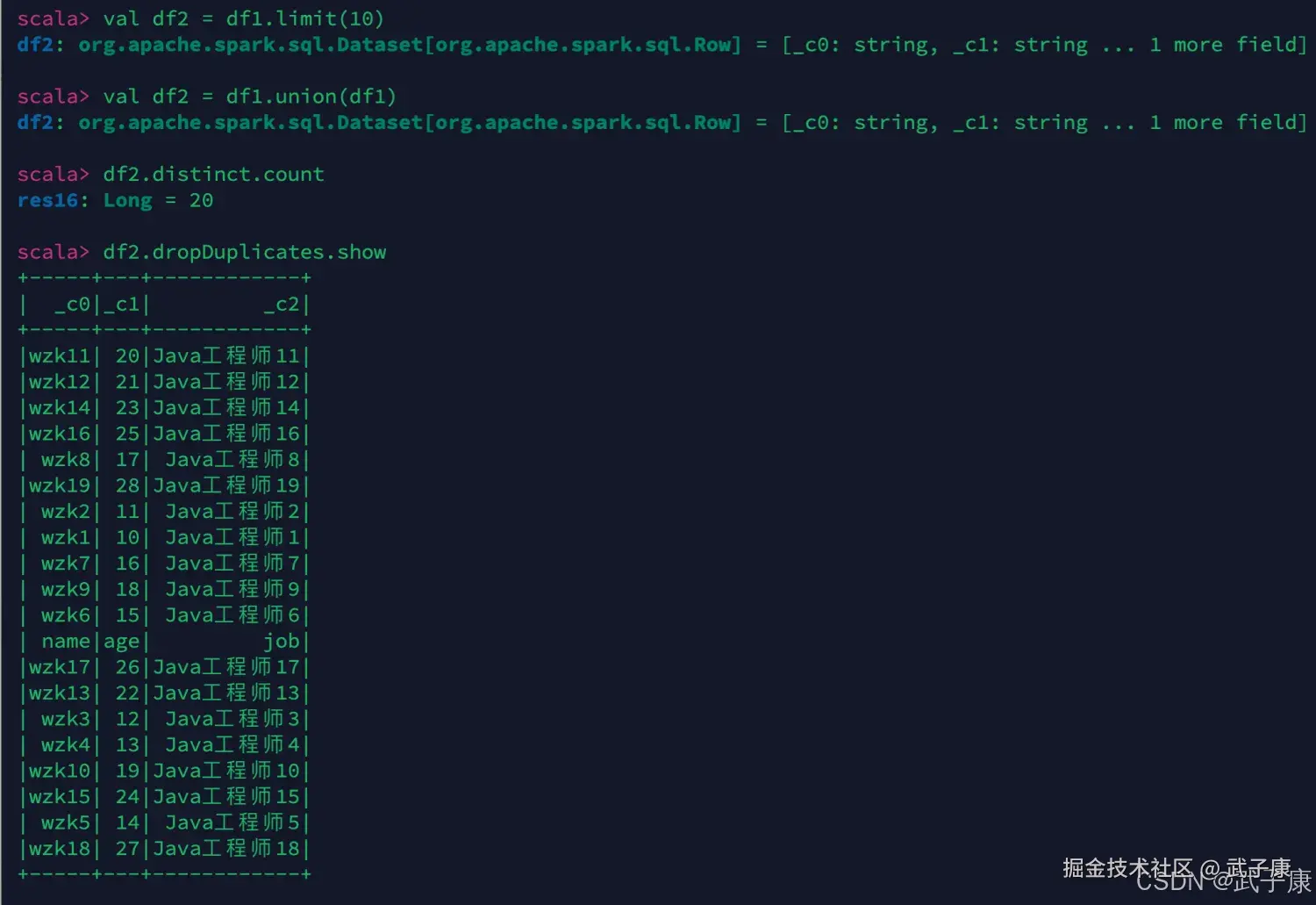
存储相关
- cacheTable
- persist
- checkpoint
- unpersist
- cache
备注:Dataset默认的存储级别是 MEMEORY_AND_DISK
scala
spark.sparkContext.setCheckpointDir("hdfs://h121.wzk.icu:9000/checkpoint")
df1.show()
df1.checkpoint()
df1.cache()
import org.apache.spark.storage.StorageLevel
df1.persist(StorageLevel.MEMORY_ONLY)
df1.count()
df1.unpersist(true)执行结果如下图所示: 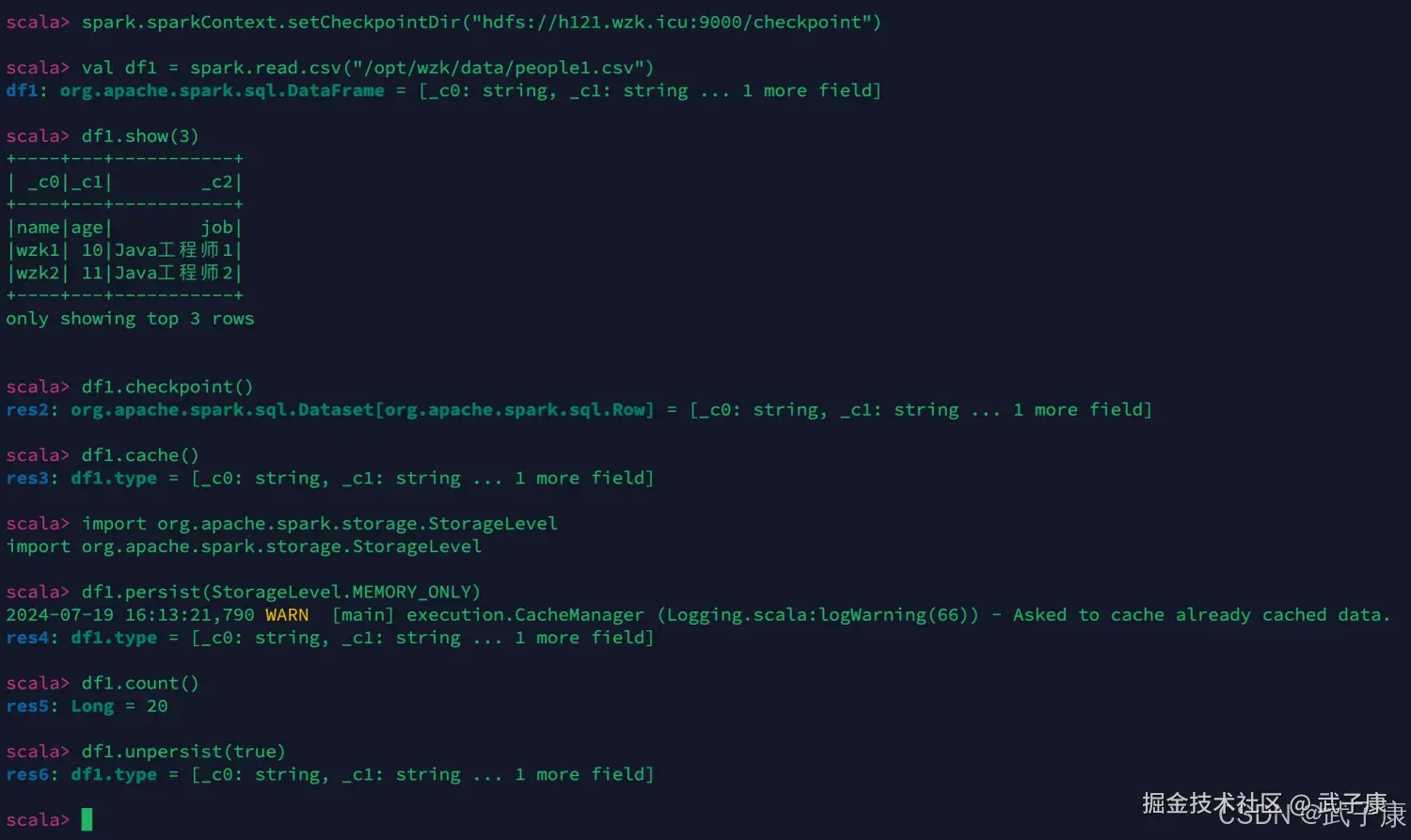
select相关
- 列的多种表示
- select
- selectExpr
启动 Spark-Shell 继续进行测试
scala
// 这里注意 option("header", "true") 自动解析一下表头
val df1 = spark.read.option("header", "true").csv("/opt/wzk/data/people1.csv")
// $ col() 等等 不可以混用!!!(有解决方法,但是建议不混用!!!)
// 可以多种形式获取到列
df1.select($"name", $"age", $"job").show执行结果如下图所示: 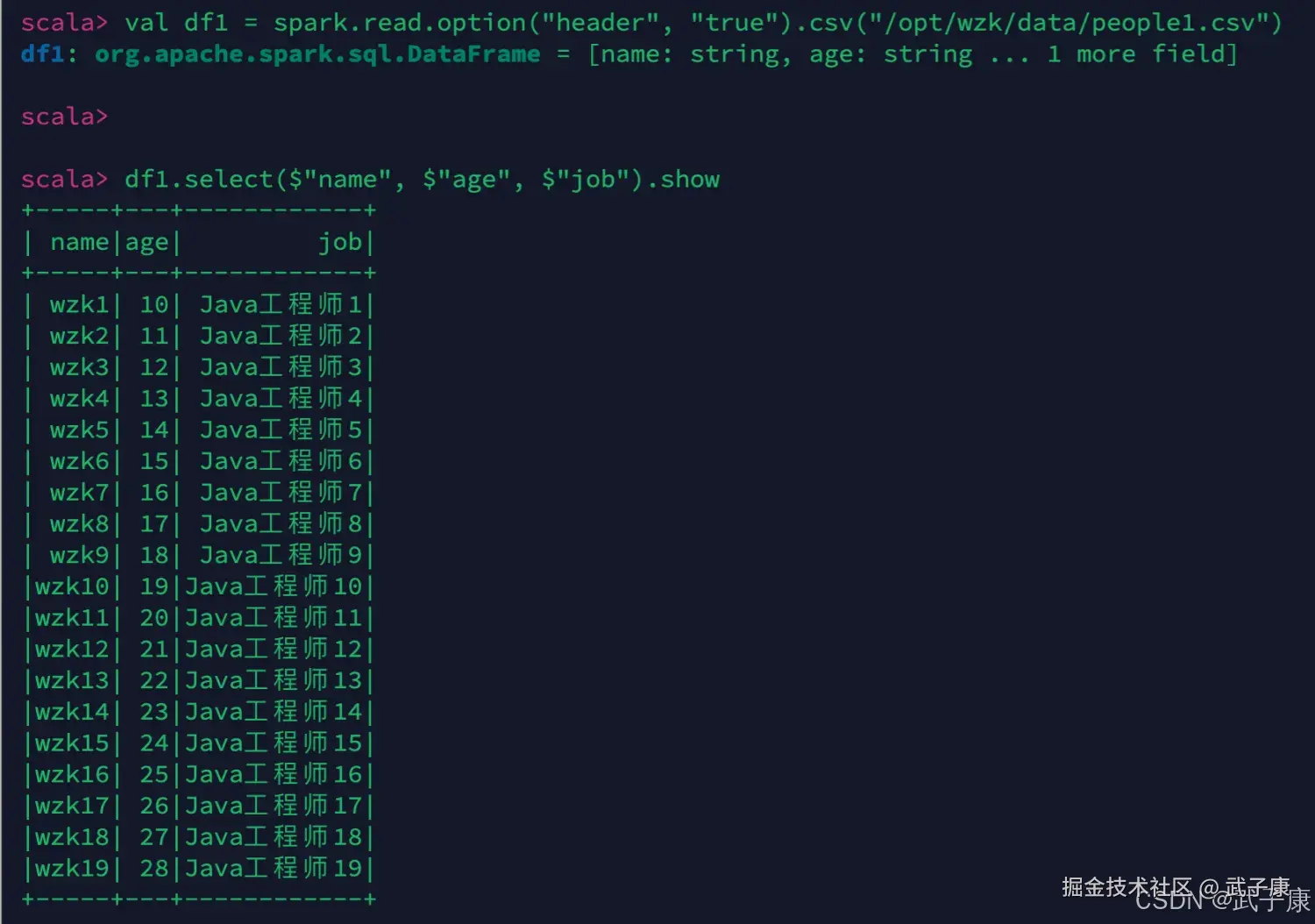
继续进行测试
scala
df1.select("name", "age", "job").show(3)
df1.select(col("name"), col("age"), col("job")).show(3)
df1.select($"name", $"age"+1000, $"job").show(5)运行结果如下图所示: 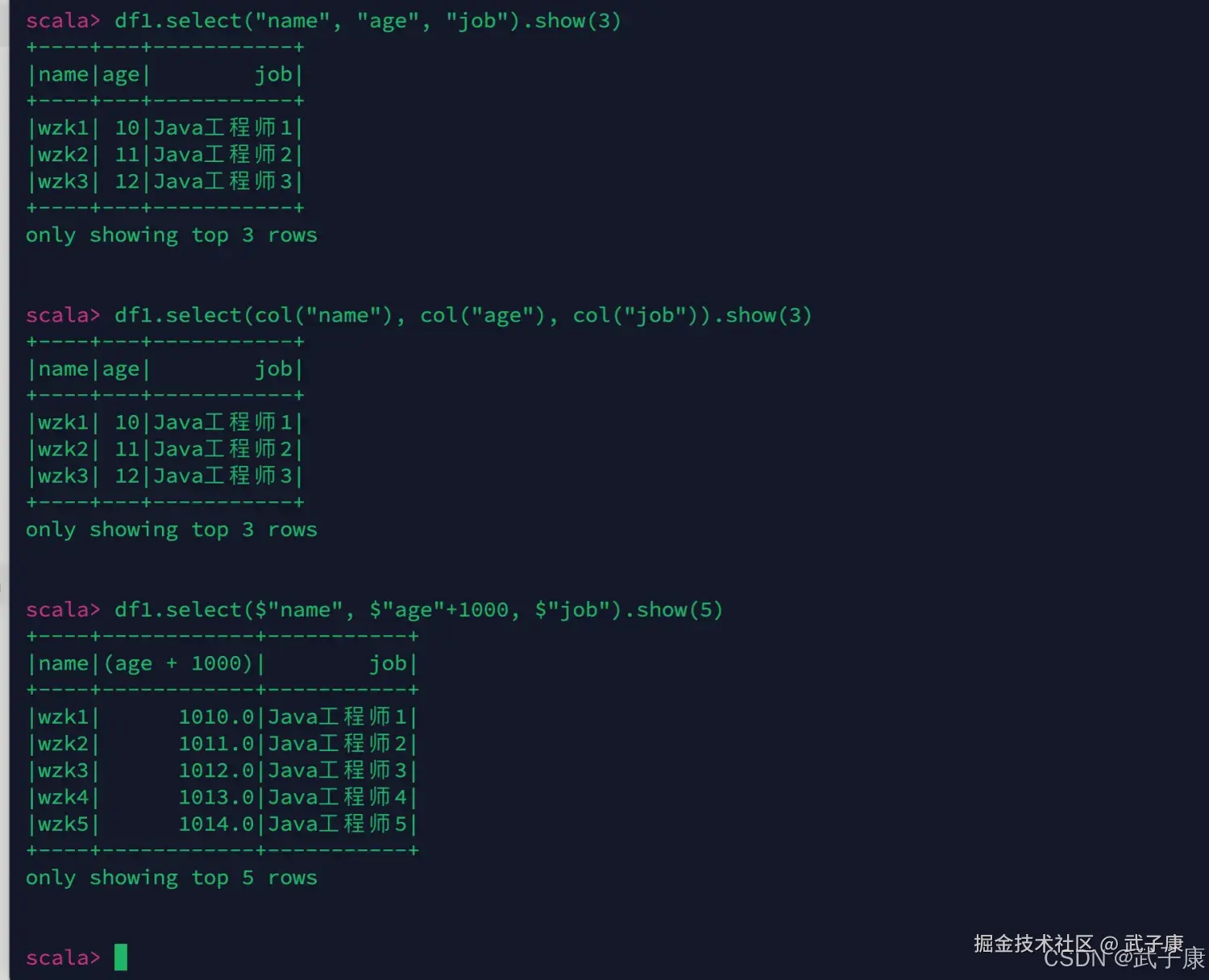
where相关
接着对上述内容进行测试:
scala
df1.filter("age > 25").show
df1.filter("age > 25 and name == 'wzk18'").show
df1.where("age > 25").show
df1.where("age > 25 and name == 'wzk19'").show运行测试结果如下图: 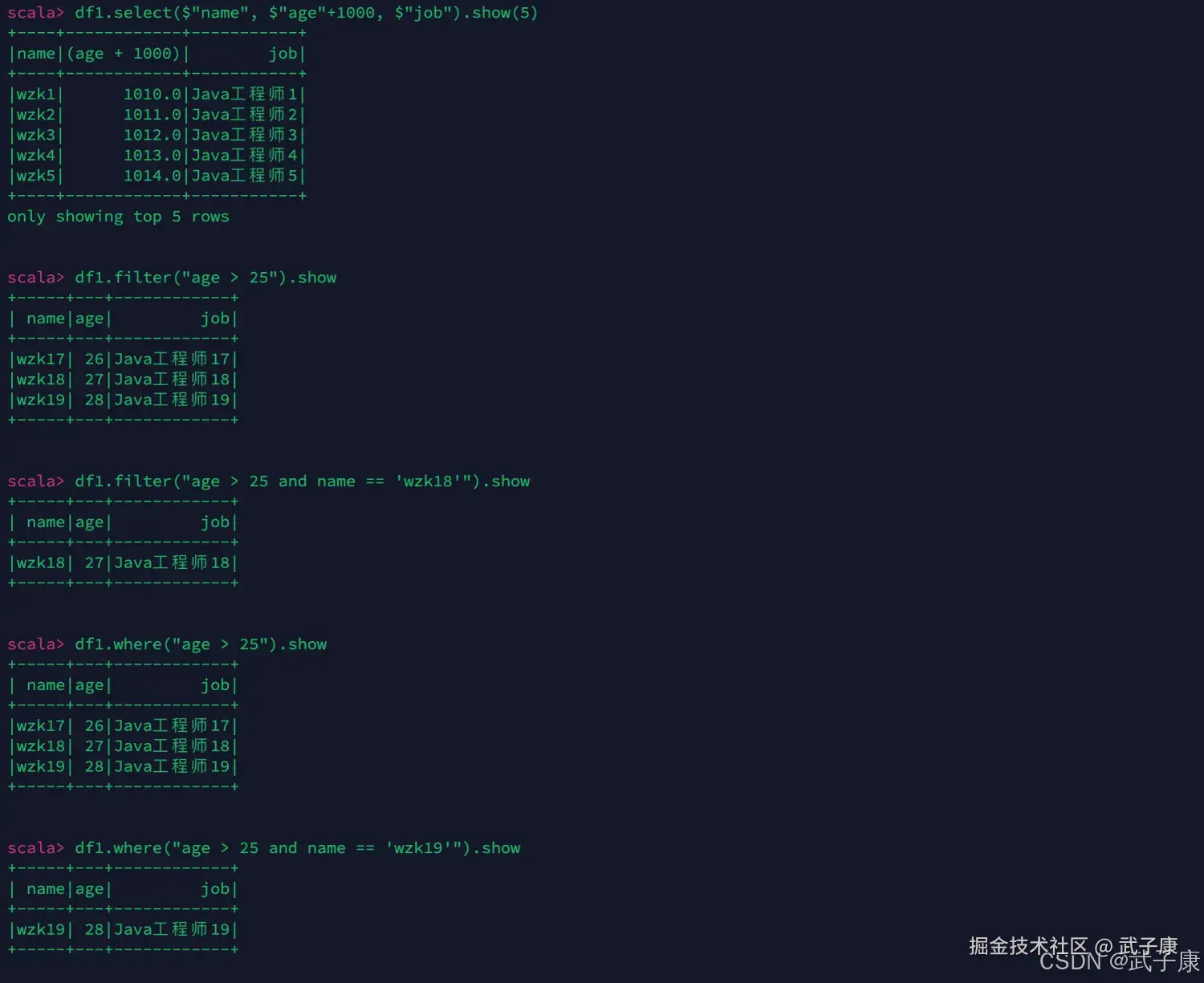
groupBy相关
- groupBy
- agg
- max
- min
- avg
- sum
- count
进行测试:
scala
// 由于我的字段中没有数值类型的,就不做测试了
df1.groupBy("Job").sum("sal").show
df1.groupBy("Job").max("sal").show
df1.groupBy("Job").min("sal").show
df1.groupBy("Job").avg("sal").show
df1.groupBy("Job").count.show
df1.groupBy("Job").avg("sal").where("avg(sal) > 2000").show
df1.groupBy("Job").avg("sal").where($"avg(sal)" > 2000).show
df1.groupBy("Job").agg("sal"->"max", "sal"->"min", "sal"-
>"avg", "sal"->"sum", "sal"->"count").show
df1.groupBy("deptno").agg("sal"->"max", "sal"->"min", "sal"-
>"avg", "sal"->"sum", "sal"->"count").showorderBy相关
orderBy == sort
scala
df1.orderBy("name").show(5)
df1.orderBy($"name".asc).show(5)
df1.orderBy(-$"age").show(5)运行测试的结果如下图所示: 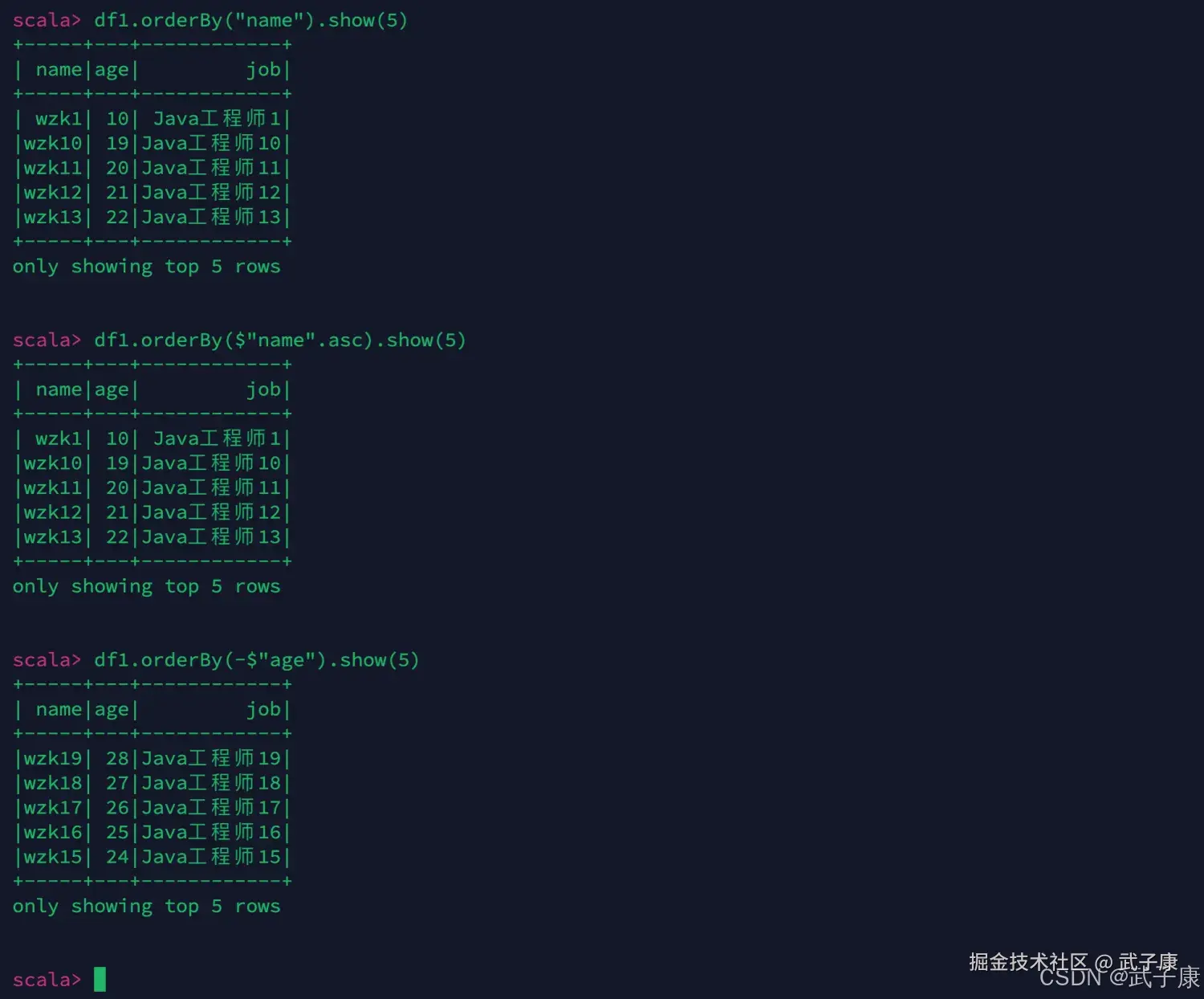 继续进行测试:
继续进行测试:
scala
df1.sort("age").show(3)
df1.sort($"age".asc).show(3)
df1.sort(col("age")).show(3)测试结果如下图所示: 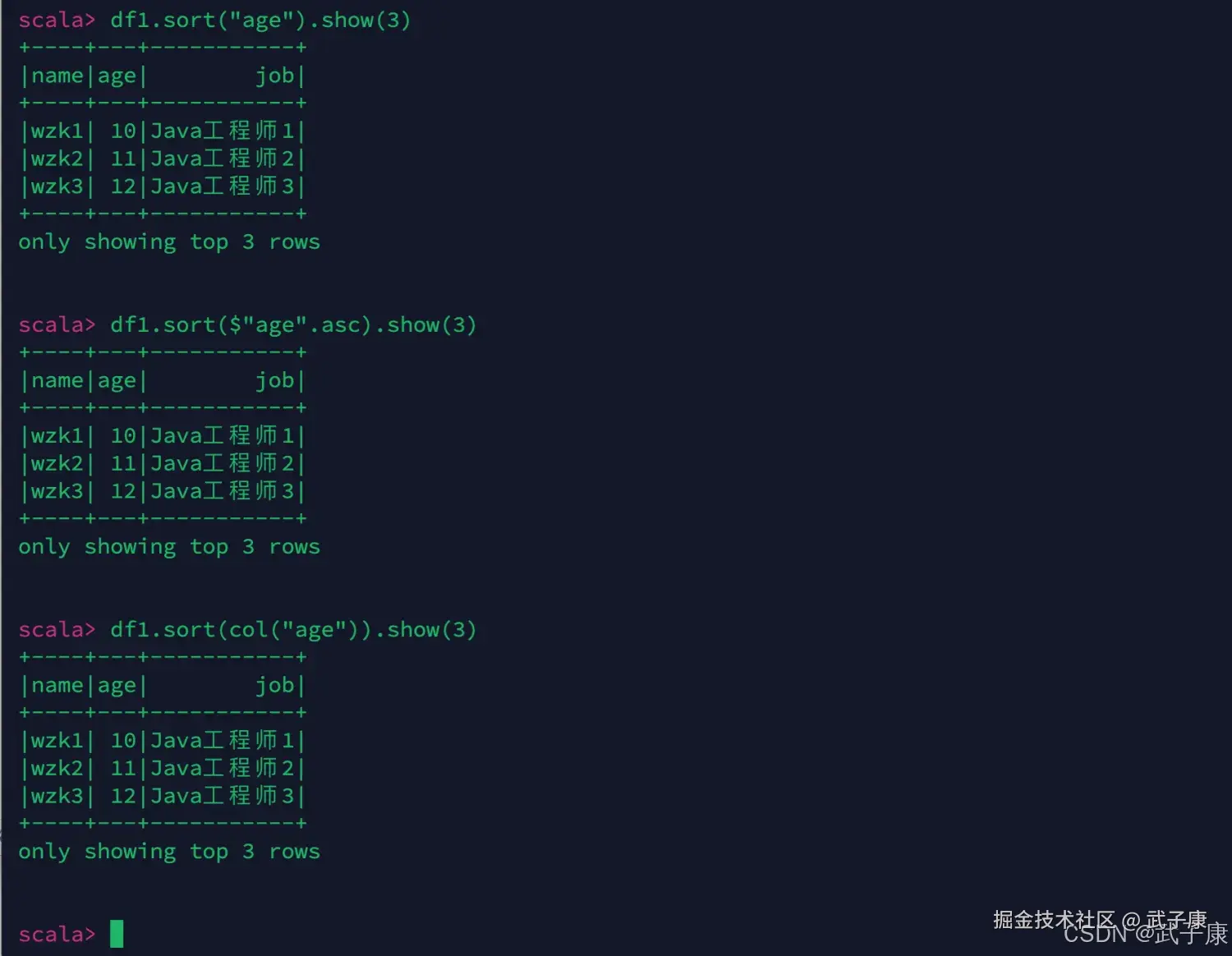
JOIN相关
scala
// 笛卡尔积
df1.crossJoin(df1).count
// 等值连接(单字段)
df1.join(df1, "name").count
// 等值连接(多字段)
df1.join(df1, Seq("name", "age")).show运行的测试结果如下图所示: 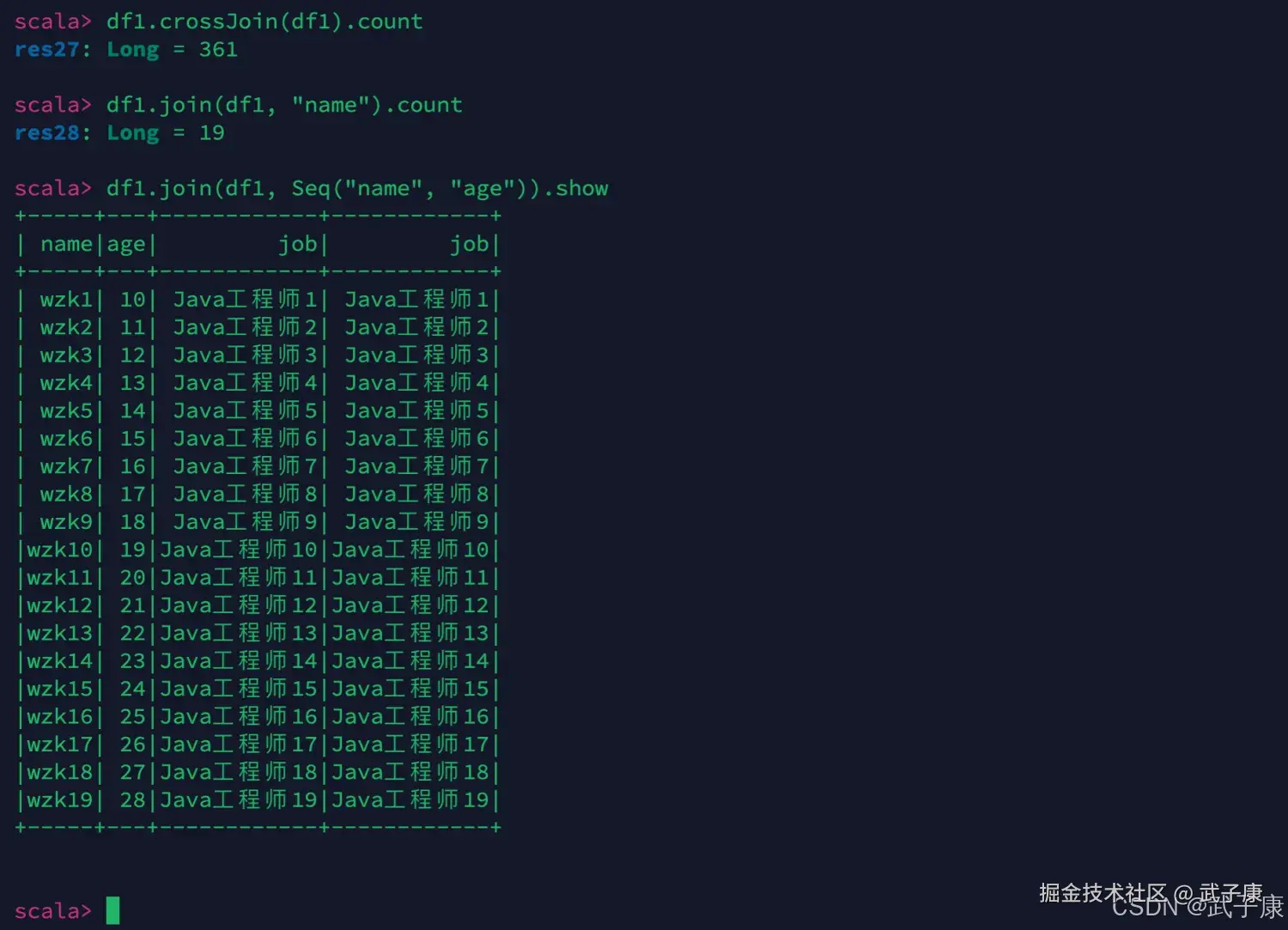
这里编写两个case:
scala
// 第一个数据集
case class StudentAge(sno: Int, name: String, age: Int)
val lst = List(StudentAge(1,"Alice", 18), StudentAge(2,"Andy", 19), StudentAge(3,"Bob", 17), StudentAge(4,"Justin", 21), StudentAge(5,"Cindy", 20))
val ds1 = spark.createDataset(lst)
// 第二个数据集
case class StudentHeight(sname: String, height: Int)
val rdd = sc.makeRDD(List(StudentHeight("Alice", 160), StudentHeight("Andy", 159), StudentHeight("Bob", 170), StudentHeight("Cindy", 165), StudentHeight("Rose", 160)))
val ds2 = rdd.toDS运行测试的结果如下图所示: 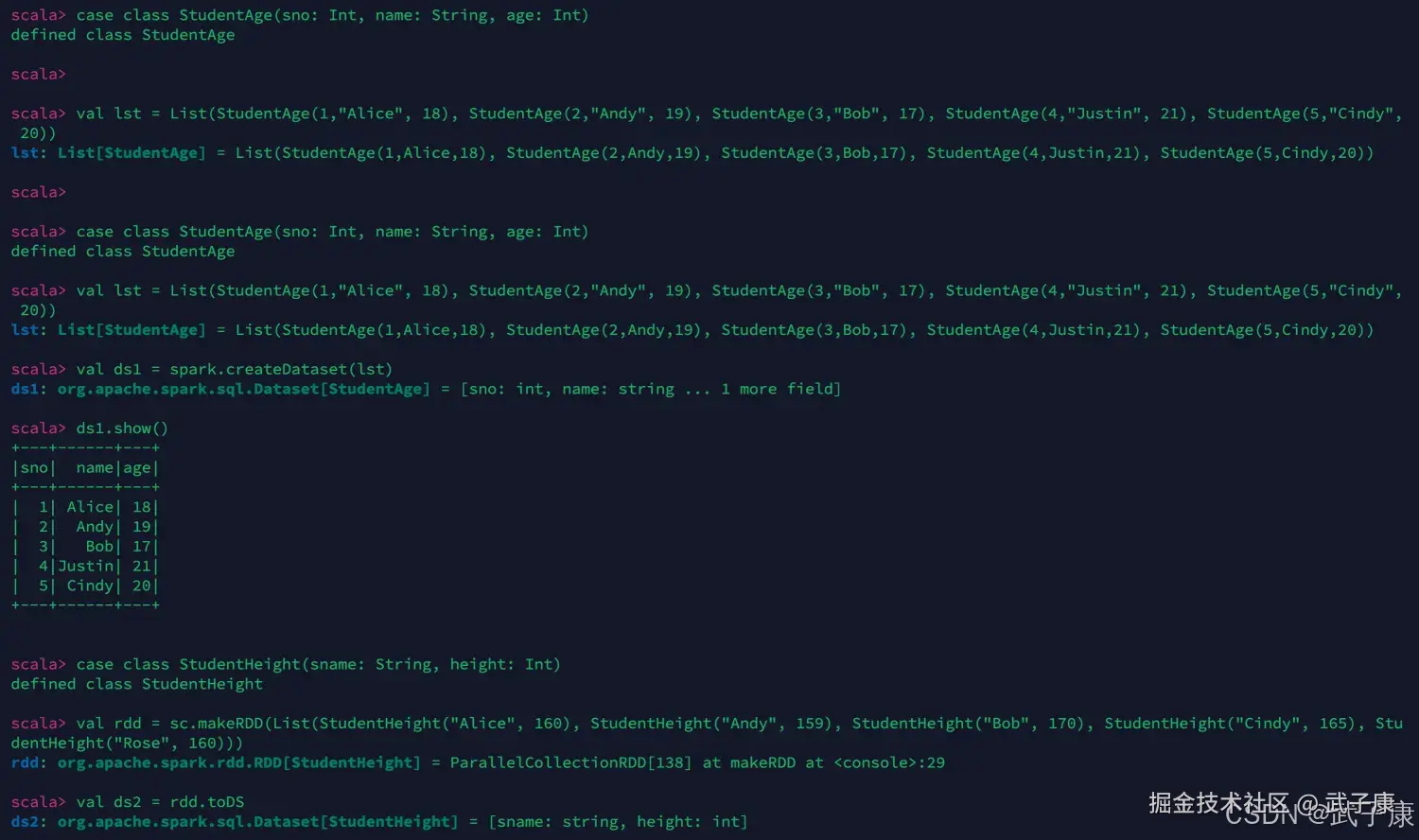 接下来我们进行连表操作:
接下来我们进行连表操作:
scala
// 连表操作 不可以使用 "name"==="sname" !!!
ds1.join(ds2, 'name==='sname).show
ds1.join(ds2, ds1("name")===ds2("sname")).show
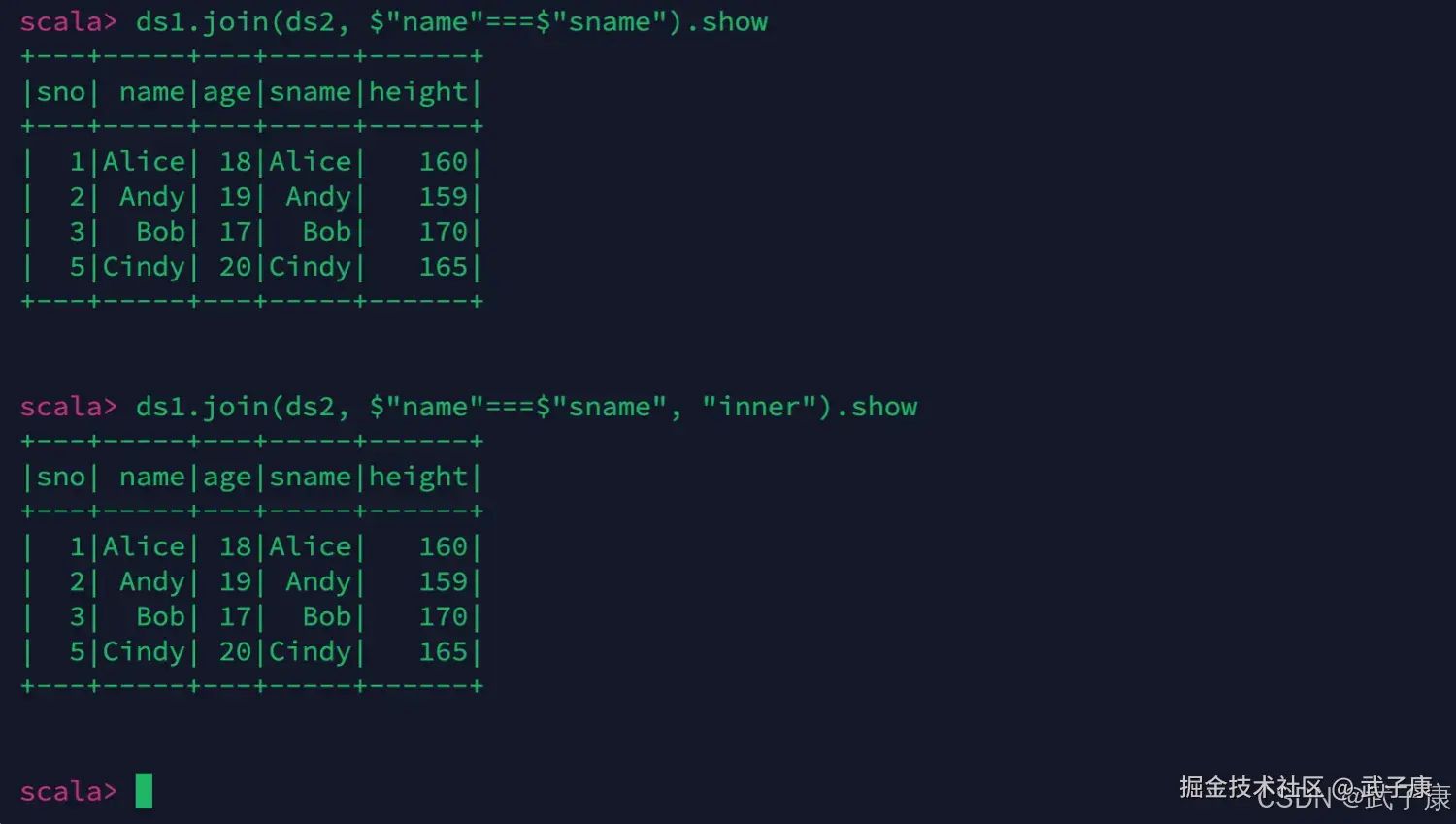
ds1.join(ds2, $"name"===$"sname").show
ds1.join(ds2, $"name"===$"sname", "inner").show测试的运行结果如下图所示: 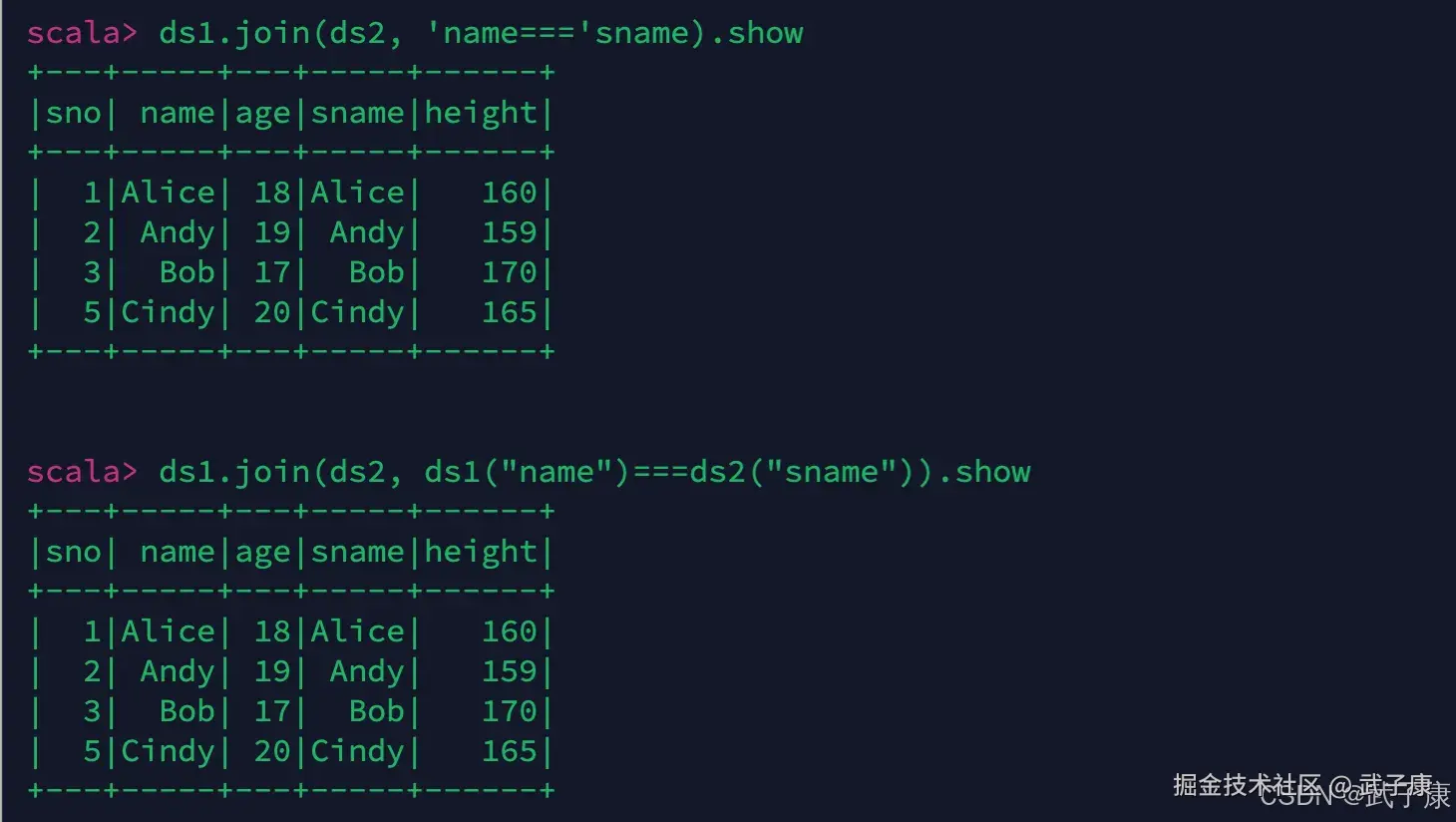
集合相关
scala
val ds3 = ds1.select("name")
val ds4 = ds2.select("sname")
// union 求并集、不去重
ds3.union(ds4).show
// unionAll(过时了)与union等价
// intersect 求交
ds3.intersect(ds4).show
// except 求差
ds3.except(ds4).show运行结果如下图所示: 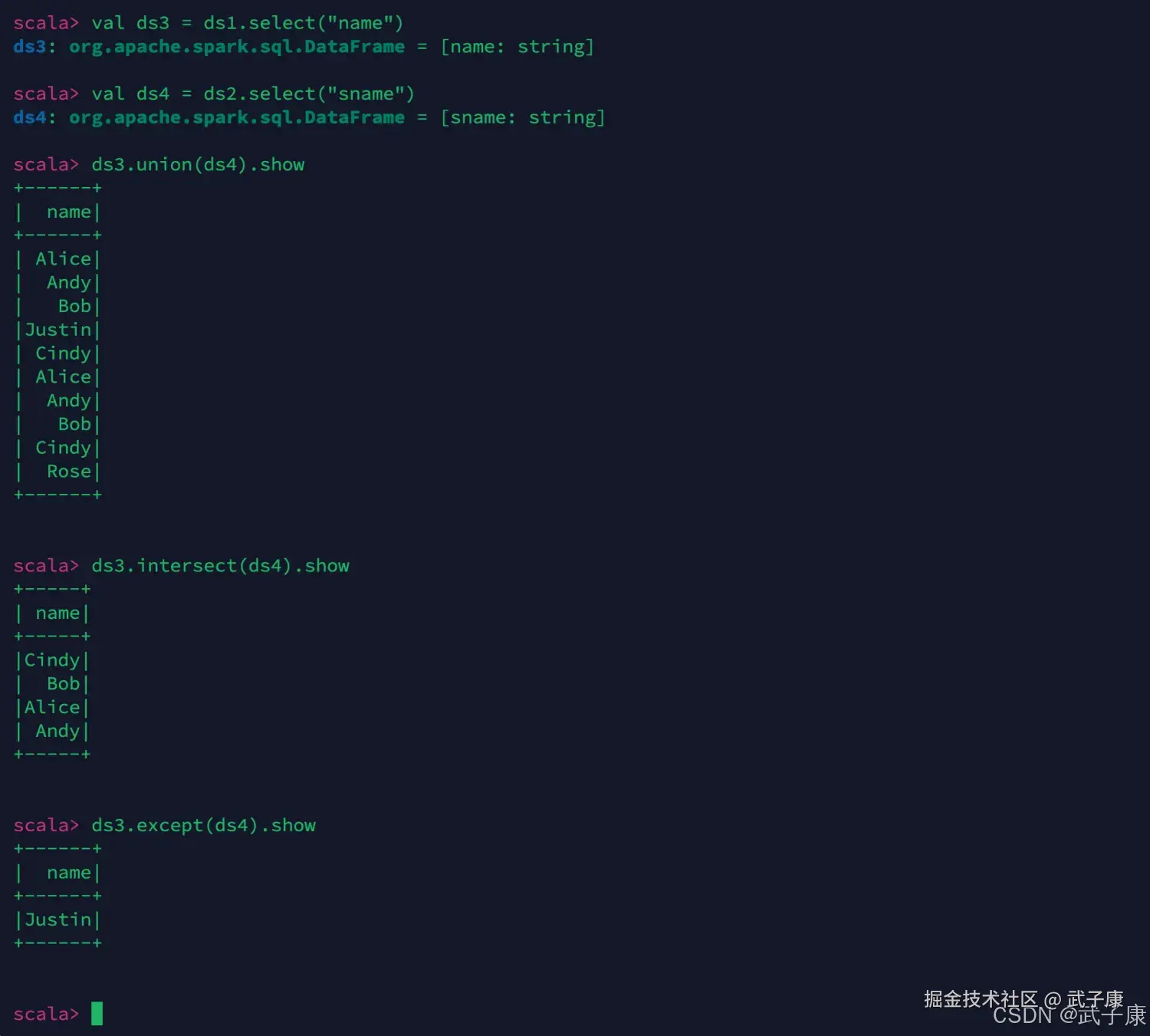
空值处理
scala
math.sqrt(-1.0)
math.sqrt(-1.0).inNaN()
df1.show
// 删除所有列的空值和NaN
df1.na.drop.show
// 删除某列的空值和NaN
df1.na.drop(Array("xxx")).show
// 对列进行填充
df1.na.fill(1000).show
df1.na.fill(1000, Array("xxx")).show