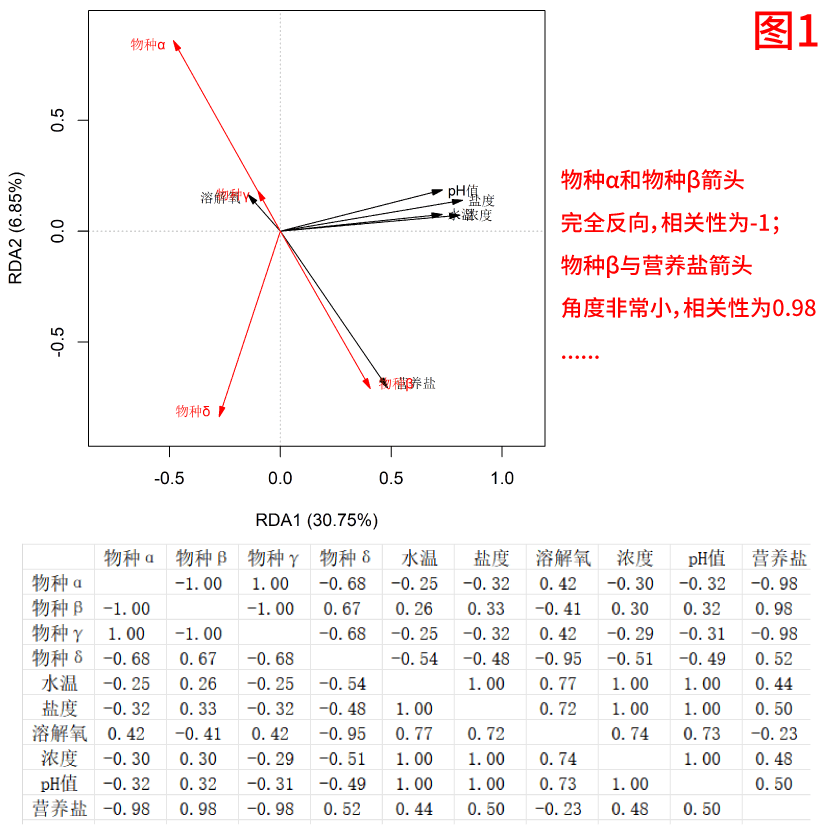
大部分文章在讲冗余分析里变量关系的时候,包括我之前也是,常常通过"锐角表示正相关,钝角表示负相关,直角表示没关系"去判断。
乍一看好像挺简单,但其实很笼统,也很主观------除了大概分出锐角、直角和钝角,你很难判断具体角度是多少,更别说比较谁更强、谁更弱了,尤其是那些角度差不多的箭头。
应该把这种正向/负向关系量化出来,让数据来说话。研究问题的时候,不能靠主观判断,量化之后,原本的"锐角、直角、钝角"就变成了实实在在的数字,更直观,也更有说服力。
01 用夹角的余弦值(cosθ)衡量相关程度
在排序图里,每个变量都是一个箭头。两个箭头的夹角越小,方向越接近,说明它们的关系越强,对于这个关系,我们习惯使用的相关程度的范围是-1,1,越强越接近1,越弱越接近-1,而cosθ就刚好落在这个范围内,回顾一下数学的知识:
当0° ≤ θ ≤ 90°:cosθ大于0,角度越大值越小,从 1 降到 0,对应的是锐角变直角。
当90° ≤ θ ≤ 180°:cosθ小于 0,角度越大值越小,从 0 降到 -1,对应的是直角变钝角。
当180° ≤ θ ≤ 270°:cosθ小于 0,递增,从 -1 升到 0,对应的是钝角变直角。
当270° ≤ θ ≤ 360°:cosθ大于 0,递增,从 0 升到 1,对应的是直角变锐角。
也就是说,一整圈里 cosθ 的走势就是:1 → 0 → -1 → 0 → 1。所以当我们都用夹角余弦值这个统一标准来衡量相关程度的话,就可以实现孰高孰低、孰强孰弱的比较,而不是主观地去判断。
通过图1我们可以看到,角度和相关性大小都可以对应上的,如果不量化根本没办法描述小多小,大是多大。
02 量化完之后可以做些什么
第一个,我们可以绘制一些可视化的图表,最常见就是热图了,这样不仅可以高效呈现我们的成果,也可以增加工作量,使文章的内容更加饱满。
第二个,我们可以设一个相关性阈值,比如绝对值大于0.7,就认为两个变量之间关系比较密切,值得讨论。这个阈值的作用就是,筛选掉一些不重要的信息,如果我总共有20个变量,那做出来的结果是非常多的,如果把它们都写出来,那就很容易被认为是在记流水账,这个时候我们通过阈值就可以把一些重要的信息挑出来讨论,这也是一个丰富文章内容的策略。
03 理解难点
- 为什么不用sinθ或者tanθ?
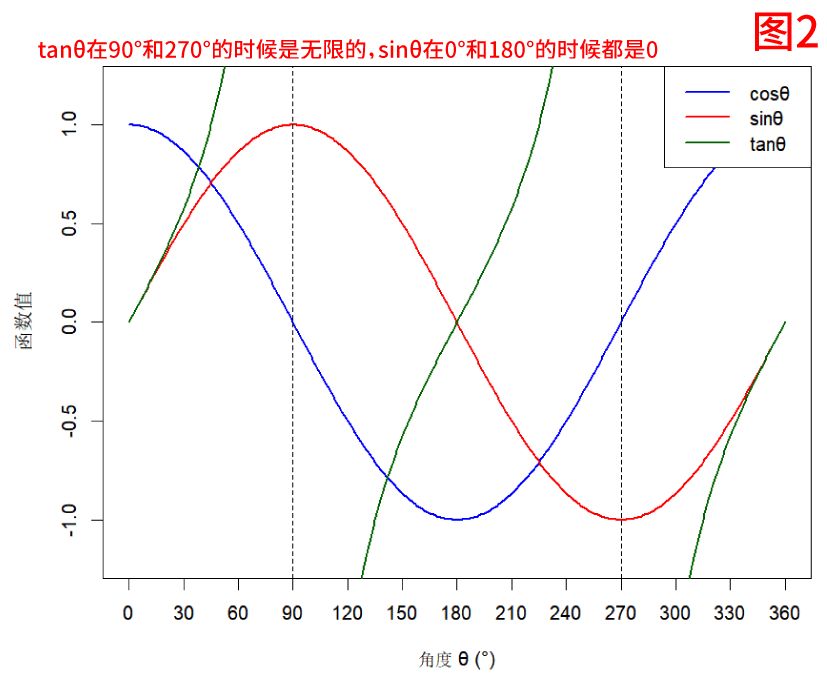
sinθ 在 0° 和 180° 都等于 0,无法区分正相关和负相关;tanθ 在接近 90° 或 270° 时其值为无限,无法比较(图2)。
- cosθ的值怎么计算?
在 RDA 排序图中,每个变量都被量化成直角坐标系中的一个从零发射出来的箭头,也就是一个向量。两个箭头之间的 cosθ,其实就是看一个向量在另一个向量上的投影占原长度的比例,公式如图3:

TomatoSCI数据分析平台,陪你过完最后一关!✅冗余分析一键完成 ✅ 免登录 ✅ 实时专业答疑 ✅ 附参考资料。
