信息技术:工业化、信息化、数字化、智能化(5G、云计算、大数据、大模型)......天知道以后会是什么,用脑机接口为第四次工业革命画上句号并开启新的革命?
采集狩猎文明→农业化 (核心主导,新石器革命起)→手工业化(农业化后期分工,过渡形态)→工业化 (第一二次工业革命驱动)→信息化 (第三次工业革命)→数字化 (信息化深化,数据驱动)→智能化(第四次工业革命,当前前沿,自主决策)
〇、人工智能
一、关键总结
- 范围大小:人工智能是最大的概念,包含了机器学习、深度学习、传统 AI 方法等;机器学习包含了数据挖掘的核心技术;数据分析与 AI 是交叉关系。
- 核心驱动 :当前人工智能的发展几乎完全依赖机器学习,尤其是深度学习;贝叶斯和马尔可夫链则为这些技术提供了关键的数学理论支撑。
- 应用逻辑 :
- 基础流程:数据分析(预处理)→ 数据挖掘(发现知识)→ 机器学习(构建模型)→ 人工智能(实现智能系统)
二、 核心层级关系
可以用 "学科金字塔" 来理解它们的定位:
-
顶层:人工智能(AI)
- 核心目标:让机器具备类似人类的智能(推理、学习、感知、决策、创造等)。
- 本质:一门研究 "如何构建智能系统" 的交叉学科,涵盖所有使机器智能化的方法。
-
中层:机器学习(ML)
- 核心定位 :人工智能的核心实现路径(也是目前最成功的路径)。
- 本质:让机器通过数据自主学习规律,而非依赖人工编写的规则,是 AI 的 "学习引擎"。
-
下层分支
- 数据挖掘(DM) :机器学习的重要应用场景 + 数据分析的高级阶段,核心是从数据中发现有价值的知识,为 AI 系统提供决策依据。
- 数据分析(DA) :与 AI 交叉,基础分析(描述性、诊断性)属于传统数据科学,高级分析(预测性、规范性)属于 AI 的应用层。
人工智能(Artificial Intelligence, AI)
├─ 核心实现路径(子领域)
│ ├─ 机器学习(Machine Learning, ML)
│ │ ├─ 学习范式:监督学习、无监督学习、半监督学习、强化学习(行为主义)
│ │ ├─ 模型类型:
│ │ │ ├─ 传统模型:逻辑回归、决策树、SVM、KNN
│ │ │ ├─ 概率模型:朴素贝叶斯(贝叶斯)、GMM(贝叶斯)、HMM(马尔可夫链)
│ │ │ ├─ 集成模型:随机森林、XGBoost
│ │ │ └─ 深度学习模型:CNN、RNN、Transformer、VAE(贝叶斯)
│ │ └─ 应用任务:分类、回归、聚类、异常检测、序列标注
│ │
│ ├─ 传统AI方法(非机器学习)
│ │ ├─ 符号主义:专家系统、逻辑推理、知识图谱
│ │ ├─ 进化计算:遗传算法、粒子群优化
│ │ └─ 模糊逻辑:模糊推理、模糊控制
│ │
│ └─ 深度学习(Deep Learning, DL)(连接主义)
│ ├─ 作为机器学习的子领域,是当前AI的核心技术
│ └─ 模型:CNN、RNN、LSTM、Transformer、GAN、VAE
│
├─ 交叉应用领域
│ ├─ 数据挖掘(Data Mining, DM)
│ │ ├─ 核心任务:关联规则挖掘、序列模式挖掘、频繁项集挖掘
│ │ └─ 技术支撑:机器学习(分类、聚类、模式挖掘算法)
│ │
│ └─ 数据分析(Data Analysis, DA)- 交叉关系
│ ├─ 属于AI的部分:预测性分析、规范性分析(依赖机器学习)
│ └─ 不属于AI的部分:描述性分析、诊断性分析(传统统计、可视化)
│
├─ 核心理论基础(数学工具)
│ ├─ 概率统计:贝叶斯理论(贝叶斯定理、后验概率)、高斯分布、假设检验
│ ├─ 随机过程:马尔可夫链、隐马尔可夫模型、马尔可夫决策过程(MDP)
│ ├─ 线性代数:矩阵运算、特征值、向量空间
│ └─ 最优化理论:梯度下降、牛顿法、拉格朗日乘子
│
└─ 应用场景(智能系统)
├─ 计算机视觉:图像分类、目标检测、语义分割
├─ 自然语言处理:文本分类、机器翻译、问答系统
├─ 智能决策:强化学习决策、兵棋推演、资源调度
└─ 机器人学:路径规划、自主导航、智能控制
一、数据挖掘DM
-
以 "是否预测未知信息" 分为预测性挖掘 和描述性挖掘,这是数据挖掘最主流的顶层分类标准。
- 预测性挖掘的输出是 "未知标签 / 数值",需要依赖有标注数据(或半监督数据)。
- 描述性挖掘的输出是 "数据内在规律",通常处理无标注数据,聚焦 "发现" 而非 "预测"。
-
关键从属关系明确
- 关联规则挖掘、序列模式挖掘不是独立的顶层任务 ,而是隶属于 描述性挖掘 → 模式挖掘 的子类。
- 频繁项集挖掘是关联规则挖掘的前置步骤(先找频繁项集,再生成关联规则)。
-
覆盖边界 这个分类树包含了数据挖掘的核心任务,同时也涵盖了特征挖掘这一基础支撑任务(特征是所有挖掘任务的前提)。
整体对于这些算法的分类树(顶层分类预测性挖掘 和描述性挖掘)如下:
数据挖掘(Data Mining)
├─ 预测性挖掘(Predictive Mining)------ 基于数据预测未知标签/数值
│ ├─ *分类(Classification)------ 预测离散类别标签
│ │ ├─ 传统机器学习方法:逻辑回归、*朴素贝叶斯、*K近邻(KNN)、*SVM
│ │ ├─ 集成学习方法:随机森林、GBDT、*XGBoost、LightGBM、AdaBoost
│ │ └─ 深度学习方法:DNN、CNN(图像分类)、RNN/LSTM(序列分类)
│ ├─ *回归(Regression)------ 预测连续数值输出
│ │ ├─ 线性回归类:线性回归、岭回归、Lasso回归、ElasticNet
│ │ ├─ 非线性回归类:决策树回归、随机森林回归、XGBoost回归
│ │ └─ *深度学习方法:全连接神经网络回归、时序神经网络回归
│ └─ 异常检测(Anomaly Detection)------ 预测偏离正常模式的异常样本
│ ├─ 统计类方法:3σ原则、箱线图分析
│ ├─ 聚类衍生方法:K-Means离群点检测、DBSCAN噪声点检测
│ ├─ 机器学习方法:孤立森林(Isolation Forest)、One-Class SVM
│ └─ 深度学习方法:自编码器(AutoEncoder)、GAN异常检测
└─ 描述性挖掘(Descriptive Mining)------ 刻画数据内在规律与结构
├─ *聚类(Clustering)------ 无监督划分相似数据为簇
│ ├─ 划分式聚类:*K-Means、K-Medoids、CLARA
│ ├─ 层次式聚类:凝聚式(AGNES)、分裂式(DIANA)
│ ├─ 密度聚类:DBSCAN、OPTICS
│ └─ 模型聚类:高斯混合模型(GMM)
├─ 模式挖掘(Pattern Mining)------ 发现数据中频繁出现的规律模式
│ ├─ 频繁项集挖掘(Frequent Itemset Mining)
│ │ └─ 典型方法:Apriori、FP-Growth、Eclat
│ ├─ *关联规则挖掘(Association Rule Mining)------ 基于频繁项集生成逻辑规则
│ │ └─ 典型方法:Apriori规则生成、FP-Growth规则生成
│ ├─ *序列模式挖掘(Sequential Pattern Mining)------ 发现带顺序的频繁序列
│ │ └─ 典型方法:GSP、PrefixSpan、SPADE、CloSpan
│ ├─ 子图模式挖掘(Subgraph Pattern Mining)------ 发现图数据中的频繁子图
│ │ └─ 典型方法:gSpan、FSG、GraphChi
│ └─ *时间序列模式挖掘(Time Series Pattern Mining)------ 发现时序数据的周期/趋势模式
│ └─ 典型方法:傅里叶变换、小波分析、周期图谱分析
└─ 特征挖掘(Feature Mining)------ 提取数据的关键特征表示
├─ 特征选择:过滤式(方差选择、卡方检验)、包裹式(递归特征消除)、嵌入式(L1正则化)
└─ 特征降维:主成分分析(PCA)、线性判别分析(LDA)、t-SNE、UMAP二、机器学习ML
机器学习领域的三大方向------强化学习(樱桃)& 监督学习(蛋糕的外皮)& 非监督学习(蛋糕)
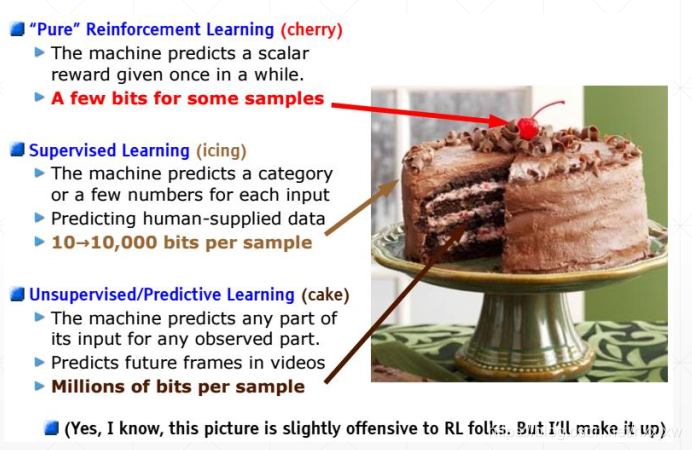
按不同的标准进行划分有多种分类子树:
机器学习(Machine Learning, ML)
├─ 1.按学习范式划分(核心顶层分类)
│ ├─ 监督学习(Supervised Learning)
│ │ ├─ 任务目标
│ │ │ ├─ 分类(Classification)------ 预测离散标签
│ │ │ │ ├─ 二分类:逻辑回归、朴素贝叶斯、SVM、KNN、决策树
│ │ │ │ ├─ 多分类:Softmax回归、多类SVM、随机森林、XGBoost、LightGBM
│ │ │ │ └─ 多标签分类:ML-KNN、Binary Relevance、Label Powerset
│ │ │ └─ 回归(Regression)------ 预测连续数值
│ │ │ ├─ 线性回归类:线性回归、岭回归、Lasso、ElasticNet
│ │ │ └─ 非线性回归类:决策树回归、随机森林回归、GBDT回归、DNN回归
│ │ └─ 模型类型
│ │ ├─ 线性模型:逻辑回归、线性回归、岭回归
│ │ ├─ 树模型:决策树(ID3/C4.5/CART)、随机森林、GBDT、XGBoost
│ │ ├─ 核方法:SVM、核岭回归
│ │ ├─ 概率模型:朴素贝叶斯、高斯混合模型(GMM)
│ │ └─ 深度学习模型:DNN、CNN、RNN/LSTM/GRU、Transformer
│ │
│ ├─ 无监督学习(Unsupervised Learning)
│ │ ├─ 任务目标
│ │ │ ├─ 聚类(Clustering)------ 无监督分组
│ │ │ │ ├─ 划分式聚类:K-Means、K-Medoids、CLARA、CLARANS
│ │ │ │ ├─ 层次式聚类:AGNES(凝聚式)、DIANA(分裂式)
│ │ │ │ ├─ 密度聚类:DBSCAN、OPTICS、DENCLUE
│ │ │ │ ├─ 模型聚类:高斯混合模型(GMM)、隐马尔可夫模型(HMM)
│ │ │ │ └─ 网格聚类:STING、WaveCluster
│ │ │ ├─ 降维(Dimensionality Reduction)------ 特征空间压缩
│ │ │ │ ├─ 线性降维:PCA、LDA、MDS、ICA
│ │ │ │ └─ 非线性降维:t-SNE、UMAP、Isomap、LLE
│ │ │ ├─ 模式挖掘(Pattern Mining)------ 发现频繁规律
│ │ │ │ ├─ 频繁项集挖掘:Apriori、FP-Growth、Eclat
│ │ │ │ └─ 序列模式挖掘:GSP、PrefixSpan、SPADE
│ │ │ └─ 异常检测(Anomaly Detection)------ 识别离群点
│ │ │ ├─ 基于统计:3σ原则、箱线图
│ │ │ ├─ 基于密度:孤立森林、One-Class SVM
│ │ │ └─ 基于重构:自编码器(AutoEncoder)
│ │ └─ 模型类型
│ │ ├─ 聚类模型:K-Means、DBSCAN、GMM
│ │ ├─ 降维模型:PCA、t-SNE、UMAP
│ │ └─ 生成模型:自编码器、GAN
│ │
│ ├─ 半监督学习(Semi-Supervised Learning)
│ │ ├─ 核心思想:利用少量标注数据 + 大量未标注数据训练模型
│ │ ├─ 典型方法
│ │ │ ├─ 生成式方法:高斯混合模型半监督分类
│ │ │ ├─ 直推式方法:TSVM(半监督SVM)
│ │ │ └─ 图论方法:标签传播算法(Label Propagation)
│ │ └─ 典型任务:半监督分类、半监督聚类
│ │
│ └─ 强化学习(Reinforcement Learning, RL)
│ ├─ 核心思想:智能体通过与环境交互,以"奖励最大化"为目标学习策略
│ ├─ 任务目标
│ │ ├─ 策略优化:学习最优决策策略
│ │ ├─ 价值估计:估计状态/动作的价值
│ │ └─ 模型学习:学习环境的转移模型
│ ├─ 典型方法
│ │ ├─ 基于价值:Q-Learning、SARSA、DQN
│ │ ├─ 基于策略:Policy Gradient、REINFORCE、PPO
│ │ └─ 演员-评论家(Actor-Critic):A2C、A3C
│ └─ 扩展方向:深度强化学习(DRL)、多智能体强化学习(MARL)
│
├─ 2.按模型结构划分
│ ├─ 传统机器学习模型:逻辑回归、决策树、SVM、KNN、GMM
│ ├─ 集成学习模型:Bagging(随机森林)、Boosting(GBDT、XGBoost)、Stacking
│ └─ 深度学习模型:CNN(卷积)、RNN(循环)、Transformer(注意力)、GAN(生成对抗)
│
└─ 3.按数据特性划分
├─ 批量学习(Batch Learning):一次性使用所有数据训练
├─ 在线学习(Online Learning):逐份/逐批接收数据,动态更新模型
├─ 增量学习(Incremental Learning):在已有模型基础上,学习新数据的知识
└─ 分布式学习(Distributed Learning):在多节点上分布式训练模型(如Spark MLlib、TensorFlow分布式)三、机器学习ML与数据挖掘DM二者的关系
机器学习(Machine Learning, ML)与数据挖掘(Data Mining, DM)是高度交叉、相互依存但定位不同 的两个领域,二者的关系可以概括为:数据挖掘以 "从数据中发现有价值的知识" 为核心目标,机器学习为数据挖掘提供了核心的算法工具;同时,数据挖掘的业务场景也推动了机器学习算法的发展和落地。
下面从核心定位、关系层次、重叠与区别三个维度,系统梳理二者的关系:
一、 核心定位的差异
| 维度 | 机器学习(ML) | 数据挖掘(DM) |
|---|---|---|
| 核心目标 | 构建能从数据中学习并自主预测 / 决策的模型 | 从大规模数据中发现隐藏、有用、可理解的知识 |
| 研究视角 | 聚焦算法设计与模型优化(如何让模型学得更好) | 聚焦全流程解决方案(从数据到知识的完整链路) |
| 应用导向 | 偏算法理论与技术实现 | 偏业务价值与知识落地 |
| 典型输出 | 预测模型、分类器、回归器、聚类器等 | 关联规则、序列模式、簇结构、异常模式、知识规则等 |
二、 二者的核心关系层次
1. 机器学习是数据挖掘的核心技术支撑
数据挖掘的核心任务(分类、回归、聚类、模式挖掘等) 几乎都依赖机器学习算法实现:
- 预测性挖掘中的分类、回归:直接使用逻辑回归、决策树、SVM、神经网络等机器学习算法。
- 描述性挖掘中的聚类:依赖 K-Means、DBSCAN、GMM 等机器学习的无监督算法。
- 模式挖掘中的频繁项集、关联规则:虽然部分经典算法(如 Apriori)最初为数据挖掘设计,但现代模式挖掘也常结合机器学习的优化策略(如基于决策树的频繁模式提取)。
- 异常检测:大量使用孤立森林、One-Class SVM 等机器学习算法。
可以说,没有机器学习的算法支撑,数据挖掘就无法高效完成大规模数据的知识发现任务。
2. 数据挖掘是机器学习的重要应用场景
机器学习的算法往往是通用的、抽象的 ,而数据挖掘的业务场景(如购物篮分析、用户分群、欺诈检测)为机器学习算法提供了具体的落地场景和验证环境:
- 机器学习的分类算法,在数据挖掘中被用于客户流失预测、垃圾邮件识别等业务问题。
- 机器学习的聚类算法,在数据挖掘中被用于用户分群、市场细分等场景。
- 数据挖掘中大规模、高维、噪声数据的处理需求,也推动了机器学习算法的优化(如从传统 SVM 到分布式 XGBoost 的发展)。
3. 二者共享核心基础理论
机器学习和数据挖掘都依赖统计学、概率论、信息论、计算机科学等基础理论:
- 统计学:提供了假设检验、概率分布、回归分析等核心方法。
- 信息论:指导了决策树的特征选择(如信息增益、基尼系数)。
- 计算机科学:提供了算法复杂度分析、数据结构(如 FP 树、哈希表)等实现基础。
三、 重叠与区别的关键边界
1. 重叠领域
二者的重叠核心是**"基于数据的模型构建与知识提取"**,具体包括:
- 分类、回归、聚类、异常检测等任务的算法实现。
- 数据预处理(特征工程、数据清洗、归一化)的通用流程。
- 模型评估(准确率、召回率、F1 值、轮廓系数)的指标体系。
2. 关键区别
- 范围不同 :数据挖掘的范围更广泛,除了使用机器学习算法,还包括数据预处理、数据可视化、知识表示与解释 等全流程环节;而机器学习更聚焦于模型的学习机制与算法优化。
- 目标不同 :机器学习的目标是构建高性能的预测模型 (如更高的分类准确率);数据挖掘的目标是发现对业务有价值的知识(如 "买尿布的用户大概率买啤酒" 这一规则,即使模型准确率不是最高,只要有业务价值就是成功的)。
- 历史渊源不同 :机器学习起源于人工智能领域 ,旨在让计算机自主学习;数据挖掘起源于数据库领域,旨在解决大规模数据库中的知识发现问题(早期称为 KDD,即知识发现于数据库)。
四、 经典关系总结:KDD 流程中的角色
数据挖掘的核心流程是KDD(Knowledge Discovery in Databases,数据库中的知识发现) ,其流程为:数据采集 → 数据预处理 → 数据变换 → 数据挖掘 → 知识评估 → 知识应用
在这个流程中:
- 机器学习 主要作用于数据挖掘阶段,提供核心算法工具。
- 数据挖掘 覆盖了从数据到知识的全流程,机器学习是其中的关键环节,但不是全部。
四、数据分析
数据分析(Data Analysis)是从原始数据中提取有效信息、分析数据规律、支撑决策制定 的全流程方法论,其核心目标是 "理解数据、解释现象、辅助决策" ,与数据挖掘、机器学习的关系是:数据分析是更宽泛的上层概念,数据挖掘是数据分析的高级阶段,机器学习是数据分析的技术工具之一。
以下是数据分析的分类树 ,按 分析目标与方法层级 作为顶层划分依据,逐层拆解为具体类型、方法和应用,同时标注与数据挖掘、机器学习的关联:
数据分析(Data Analysis)
├─ 按分析目标与方法层级划分(核心顶层分类)
│ ├─ 描述性分析(Descriptive Analysis)------ 「发生了什么?」
│ │ 核心目标:总结数据的基本特征,描述历史数据的现状
│ │ 适用场景:业务报表、数据概览、现状监控
│ │ 典型方法
│ │ ├─ 数据清洗:缺失值处理(填充/删除)、异常值处理(过滤/修正)、重复值去重
│ │ ├─ 数据探索(EDA)
│ │ │ ├─ 统计描述:均值、中位数、众数、方差、标准差、分位数
│ │ │ ├─ 分布分析:正态分布、泊松分布、二项分布
│ │ │ └─ 相关性分析:皮尔逊相关系数、斯皮尔曼相关系数
│ │ ├─ 数据可视化
│ │ │ ├─ 基础图表:柱状图、折线图、饼图、散点图、箱线图
│ │ │ └─ 进阶图表:热力图、雷达图、漏斗图、桑基图
│ │ └─ 报表制作:静态报表、动态仪表盘(如Tableau、Power BI)
│ │ 关联领域:无(纯基础分析,不涉及挖掘/机器学习)
│ │
│ ├─ 诊断性分析(Diagnostic Analysis)------ 「为什么会发生?」
│ │ 核心目标:深入分析数据,找到现象背后的原因
│ │ 适用场景:问题根因分析、业务异常排查、因果关系探究
│ │ 典型方法
│ │ ├─ 对比分析:同期对比、组间对比、维度拆解对比
│ │ ├─ 细分分析:用户分群、产品细分、地域细分
│ │ ├─ 漏斗分析:转化漏斗、流失漏斗、留存漏斗
│ │ ├─ 归因分析:多触点归因、末次归因、首次归因
│ │ └─ 假设检验:t检验、卡方检验、ANOVA方差分析
│ │ 关联领域:少量涉及数据挖掘的聚类(用于分群)
│ │
│ ├─ 预测性分析(Predictive Analysis)------ 「将会发生什么?」
│ │ 核心目标:基于历史数据构建模型,预测未来趋势或结果
│ │ 适用场景:销量预测、客户流失预测、风险预警
│ │ 典型方法
│ │ ├─ 传统统计模型:时间序列分析(ARIMA、SARIMA)、线性回归、逻辑回归
│ │ ├─ 机器学习模型:决策树、随机森林、XGBoost、SVM、DNN
│ │ └─ 模型评估:准确率、召回率、MSE、MAE、RMSE
│ │ 关联领域:完全对应数据挖掘的**预测性挖掘**,依赖机器学习的监督学习算法
│ │
│ └─ 规范性分析(Prescriptive Analysis)------ 「应该怎么做?」
│ 核心目标:在预测基础上,提供最优决策建议,指导行动
│ 适用场景:智能推荐、资源调度、路径优化、策略制定
│ 典型方法
│ ├─ 优化算法:线性规划、整数规划、动态规划
│ ├─ 强化学习:Q-Learning、PPO、A2C
│ ├─ 推荐系统:协同过滤、内容推荐、混合推荐
│ └─ 决策支持系统(DSS):结合规则引擎与预测模型
│ 关联领域:对应数据挖掘的**智能决策类任务**,依赖机器学习的强化学习、优化算法
│
├─ 按分析技术手段划分
│ ├─ 统计分析(Statistical Analysis)
│ │ 方法:假设检验、相关分析、回归分析、时间序列分析
│ │ 工具:SPSS、SAS、R(统计包)
│ ├─ 机器学习分析(Machine Learning Analysis)
│ │ 方法:分类、回归、聚类、异常检测
│ │ 工具:Python(Scikit-learn、TensorFlow)、Spark MLlib
│ ├─ 数据挖掘分析(Data Mining Analysis)
│ │ 方法:关联规则、序列模式、频繁项集
│ │ 工具:Python(MLxtend)、WEKA
│ └─ 可视化分析(Visual Analysis)
│ 方法:交互式可视化、仪表盘、地理信息可视化(GIS)
│ 工具:Tableau、Power BI、ECharts、Matplotlib
│
└─ 按数据类型划分
├─ 结构化数据分析:关系型数据库数据(MySQL、PostgreSQL)、Excel表格
├─ 半结构化数据分析:JSON、XML、日志数据
└─ 非结构化数据分析:文本、图像、音频、视频
├─ 文本分析:分词、情感分析、主题建模(LDA)、命名实体识别(NER)
├─ 图像分析:目标检测、图像分类、语义分割
└─ 音频/视频分析:语音识别、行为分析分类树核心说明
-
顶层划分逻辑 以分析目标的层级为核心划分依据,从基础到高级形成完整链路:
- 描述性分析:最基础,回答 "是什么"
- 诊断性分析:深入一层,回答 "为什么"
- 预测性分析:高级阶段,回答 "会怎样"
- 规范性分析:最高阶段,回答 "怎么做"这个层级也是数据分析的能力进阶路径,从简单的报表制作到智能决策支持。
-
与数据挖掘、机器学习的核心关联
- 数据分析的前两个层级 (描述性、诊断性)是基础分析,不依赖数据挖掘或机器学习,主要用统计和可视化方法。
- 数据分析的后两个层级 (预测性、规范性)是高级分析 ,数据挖掘是预测性分析的核心技术 ,机器学习是预测性和规范性分析的核心工具。
- 范围关系:数据分析 ⊃ 数据挖掘 ⊃ 机器学习(算法层)
-
关键补充
- 按技术手段划分的分类,体现了数据分析的工具多样性,统计分析是基础,机器学习和数据挖掘是高级工具。
- 按数据类型划分的分类,体现了数据分析的应用场景扩展,非结构化数据分析是当前的热点,依赖深度学习等技术。
五、其他自己问到的(贝叶斯、马尔可夫链)
贝叶斯、马尔可夫链都属于机器学习和数据分析的核心理论与模型基础 ,它们并非独立的 "任务类型",而是概率统计框架下的方法论,可支撑多个层级的分析任务和机器学习范式。
下面先明确二者的核心定位,再分别给出它们在数据分析分类树 和机器学习分类树中的具体归属,最后梳理其衍生模型的归属关系。
一、 核心定位
-
贝叶斯(Bayesian) 核心是贝叶斯定理 (\(P(A|B) = \frac{P(B|A)P(A)}{P(B)}\)),基于先验概率 和观测数据 计算后验概率 ,强调对不确定性的建模。属于概率统计理论 ,衍生出一系列概率模型,可应用于监督学习、无监督学习、数据分析等多个领域。
-
马尔可夫链(Markov Chain, MC) 核心是马尔可夫性 (未来状态仅依赖当前状态,与过去状态无关),用于建模序列性、动态性数据 。属于随机过程理论 ,衍生出一系列序列模型,可应用于无监督学习、预测性分析、序列模式挖掘等领域。
二、 在分类树中的具体归属
1. 贝叶斯相关体系的归属
数据分析(Data Analysis)
└─ 按分析技术手段划分
└─ 统计分析
└─ 概率统计方法
└─ 贝叶斯统计(对应诊断性分析、预测性分析)
机器学习(Machine Learning)
├─ 按学习范式划分
│ ├─ 监督学习
│ │ └─ 模型类型
│ │ └─ 概率模型
│ │ ├─ 朴素贝叶斯(Naive Bayes)------ 分类任务
│ │ └─ 贝叶斯回归(Bayesian Regression)------ 回归任务
│ ├─ 无监督学习
│ │ └─ 模型类型
│ │ └─ 概率模型
│ │ └─ 贝叶斯聚类(如贝叶斯高斯混合模型)------ 聚类任务
│ └─ 半监督学习
│ └─ 生成式方法
│ └─ 贝叶斯半监督分类
└─ 按模型结构划分
└─ 概率模型
└─ 贝叶斯模型族
├─ 朴素贝叶斯
├─ 贝叶斯网络(Bayesian Network)------ 因果推理、概率图模型
└─ 变分自编码器(VAE)------ 深度生成模型(无监督学习)2. 马尔可夫链相关体系的归属
数据分析(Data Analysis)
├─ 按分析目标与方法层级划分
│ └─ 预测性分析
│ └─ 传统统计模型
│ └─ 时间序列分析
│ └─ 马尔可夫链模型(用于离散时间序列预测)
└─ 按数据类型划分
└─ 非结构化数据分析
└─ 文本分析
└─ 序列建模(如词性标注、文本生成)
机器学习(Machine Learning)
├─ 按学习范式划分
│ ├─ 无监督学习
│ │ ├─ 任务目标
│ │ │ ├─ 模式挖掘
│ │ │ │ └─ 序列模式挖掘(依赖马尔可夫性建模序列关系)
│ │ │ └─ 异常检测(马尔可夫链用于序列异常识别)
│ │ └─ 模型类型
│ │ └─ 概率模型
│ │ └─ 隐马尔可夫模型(HMM)------ 序列数据建模
│ └─ 强化学习
│ └─ 核心理论
│ └─ 马尔可夫决策过程(MDP)------ 智能体与环境交互的基础模型
└─ 按模型结构划分
└─ 序列模型
├─ 隐马尔可夫模型(HMM)
├─ 马尔可夫随机场(MRF)------ 图模型,用于空间数据建模
└─ 条件随机场(CRF)------ 监督学习,用于序列标注任务三、 衍生模型的归属梳理
为了更清晰,整理关键衍生模型的归属表:
| 核心理论 | 衍生模型 | 所属领域 | 典型任务 |
|---|---|---|---|
| 贝叶斯 | 朴素贝叶斯 | 机器学习 - 监督学习 | 文本分类、垃圾邮件识别 |
| 贝叶斯 | 贝叶斯网络 | 机器学习 - 概率图模型 | 因果推理、故障诊断 |
| 贝叶斯 | 变分自编码器(VAE) | 机器学习 - 深度学习 | 无监督生成、数据降维 |
| 马尔可夫链 | 隐马尔可夫模型(HMM) | 机器学习 - 无监督 / 监督学习 | 语音识别、词性标注、序列预测 |
| 马尔可夫链 | 马尔可夫决策过程(MDP) | 机器学习 - 强化学习 | 智能决策、路径优化、兵棋推演 |
| 马尔可夫链 | 条件随机场(CRF) | 机器学习 - 监督学习 | 序列标注、命名实体识别 |
四、 与数据挖掘任务的关联
- 贝叶斯模型 :在数据挖掘的分类任务 (朴素贝叶斯)、聚类任务 (贝叶斯 GMM)、关联规则挖掘(贝叶斯置信网络)中均有应用。
- 马尔可夫链及衍生模型 :在数据挖掘的序列模式挖掘 (建模序列依赖)、时间序列模式挖掘 (预测时序趋势)、智能决策挖掘(MDP 支撑策略优化)中核心应用。