导读
2023 年被称为大模型元年,但真正让人记住的模型并不多。到了 2024 年,技术与应用的双重驱动,让大模型进入前所未有的"快车道"。2025 年初,DeepSeek 的爆火更是点燃了全球的热情,每周都有数个乃至十余个新模型问世,文本、语音、图像、视频全线开花。可是在这琳琅满目的发布与宣传中,谁才是真正的 SOTA?通用榜单、技术报告的数据真的可靠么?面对眼花缭乱的分数、榜单与宣传语,企业和开发者又该如何选型?这篇文章带你穿梭大模型"井喷之年"的浪潮,揭开榜单背后的真相,并分享一套面向业务实践的评测方法论。读完之后,你也许会发现:选模型,不只是追逐最新的名字,而是一次关乎判断力与洞察力的考验。
01 大模型井喷之年
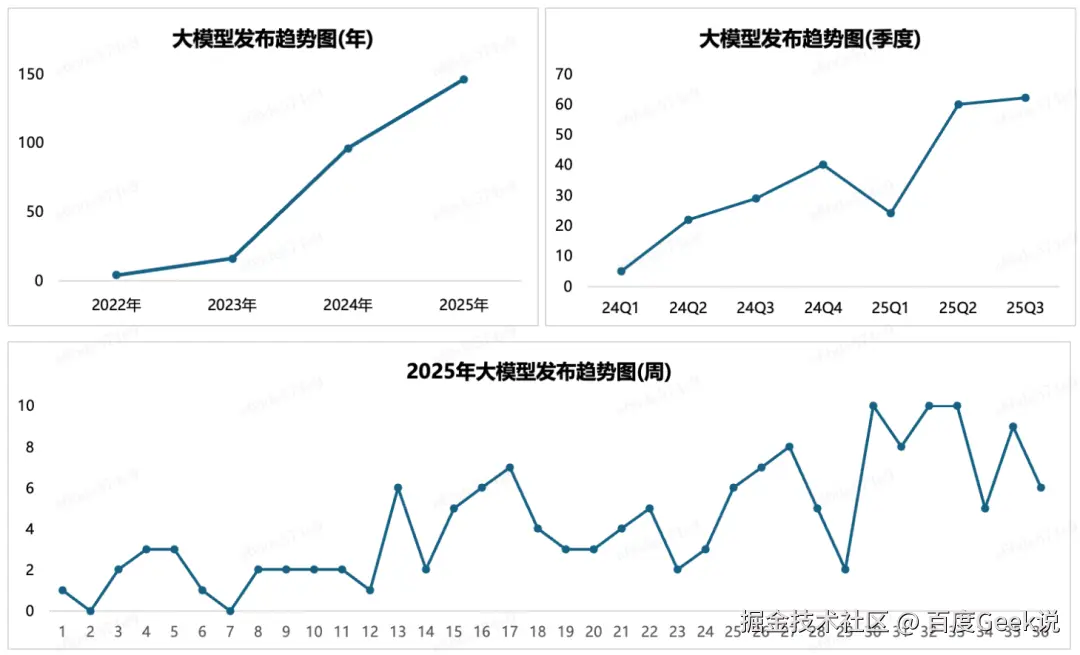
作为大模型元年的 2023 年,虽然有百余款模型发布,但是经过 2024 年的应用实践的洗礼之后,真正被大家记住的大模型并不多。随着技术与应用的双重驱动,在 2024 年 Q4,我们发现大模型的发布数量、发布速度都呈现除了前所未有的规模。尤其是在 DeepSeek 火爆全球的 2025 年 Q1,大模型更是呈现出了井喷之势,几乎所有的场景,无论是文本、推理、语音、图片、视频,都会不停地有新的 SOTA 模型发布,模型之间的竞争也逐渐呈现白热化态势。
2025 年之前的数据可以参考:
在 2025 年 3 月,我们提出这个春天是大模型的春天,在这个大模型的春天里,乱花渐欲迷人眼,处处早莺争暖树。今天,当再次回顾年初的判断时,我们虽然猜到了大模型白热化竞争的趋势,但是依然没有猜到竞争会如此之快、如此之烈。
当时我们认为,2025年,每周至少会有1款大模型发布,但是在第 30 周 ~ 第 33 周的这4周时间里,有 3 周每周都有 10 款大模型发布。大模型的发布周期慢慢的从"年"为单位,提升到"月"为单位。
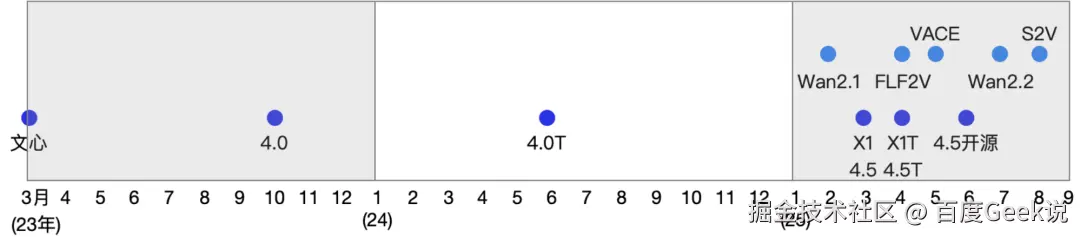
通过下图的文心系列大模型的发布节奏能够看出,文心系列大模型的发布节奏从之前的"年度"发布已经提升到"月度"发布。对于 Wan 系列的开源视频生成大模型而言,也能看出,Wan 系列模型的迭代周期也已经达到了"月度"发布。
02 究竟谁才是真正的SOTA?
正如 Dr Singularity 前几天发的一篇帖子那样:每个小时,都会有人发布新的模型、新的测试基准、新的突破。每个小时,也总有新的 SOTA 出现,那么究竟谁才是真正的 SOTA 呢?我们如何从繁花般的 SOTA 中汲取技术上的优势,以便可以应用于自己的模型研发?在如此林立的 SOTA 中,我们又将如何选择最适用于业务场景的模型?

根据我们的观察,每次模型发布的时候,在模型效果的评估上往往会有三种操作:不同的数据集、不同的指标、不同的竞对,从而能够从数据上说明自己确实是 SOTA。
2.1 视频大模型技术报告中的评估报告
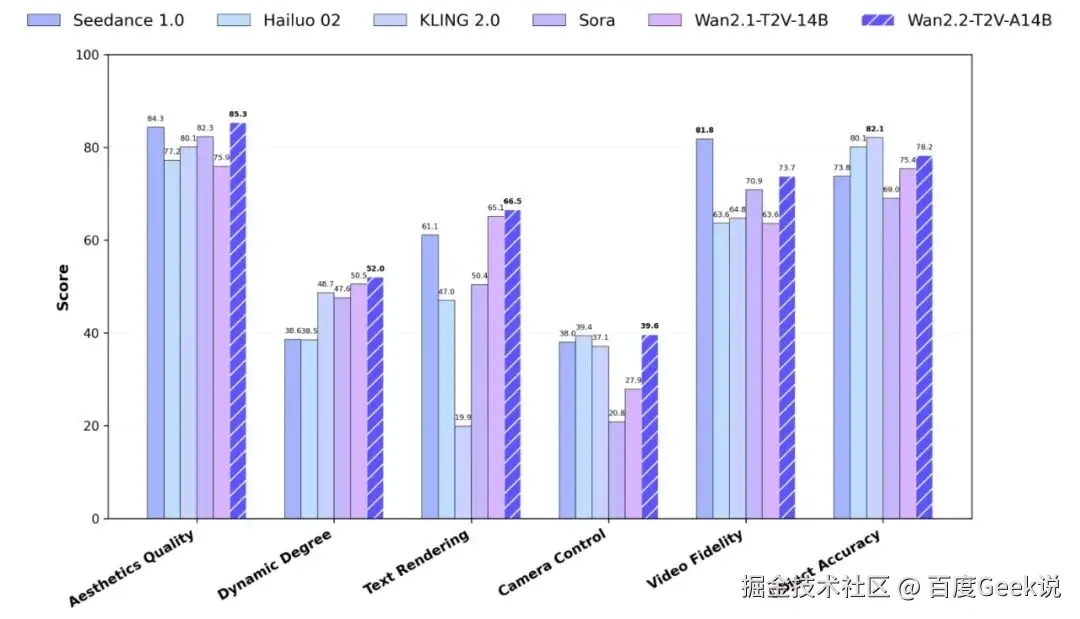
- 在新的 Wan-Bench 2.0 (指标相对较少)上的评估表明,Wan2.2 在多个关键维度上的性能优于对应的闭源、商业模型。
- 潞晨科技的 Open-Sora2: 在竞对的选取和指标的选取上更有目标性,整体得分达到开源模型第一,直逼闭源的 OpenAI Sora。
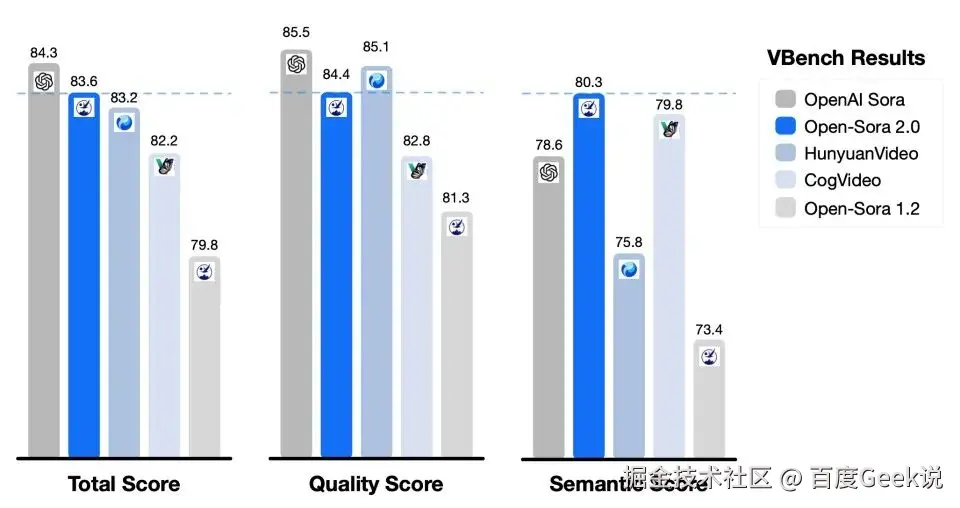
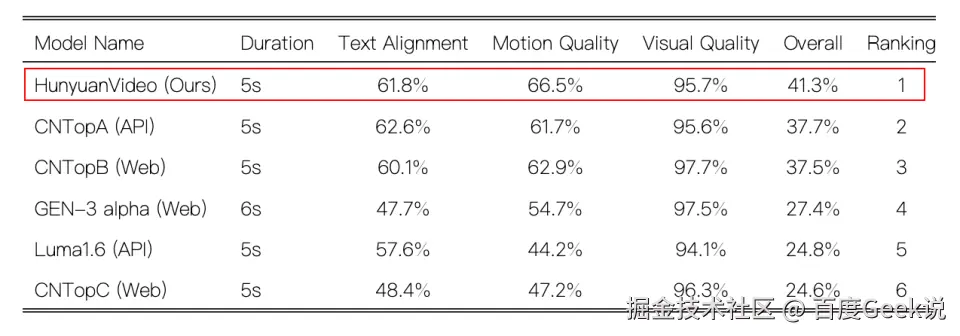
- 腾讯混元图生视频:选择的指标相对较少,选择的竞品没有包含开源的万相 2.1以及可灵1.6。
2.2 视觉理解大模型技术报告中的评估报告
- 总能找到自己能力最强的数据集,像视频理解 VideoMME 数据集,豆包得分是 74.1,明显比 Qwen2.5-VL 好,但是竞对选择上没有豆包。
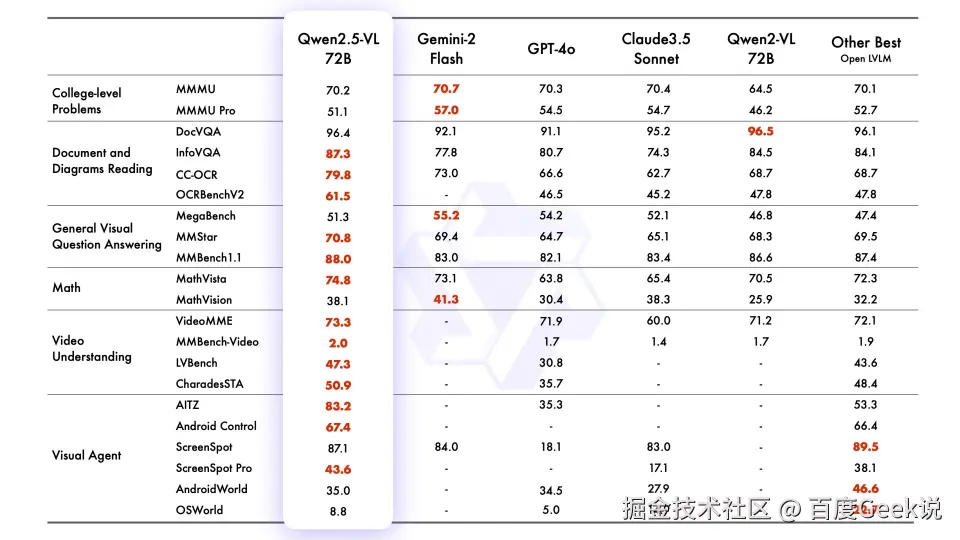
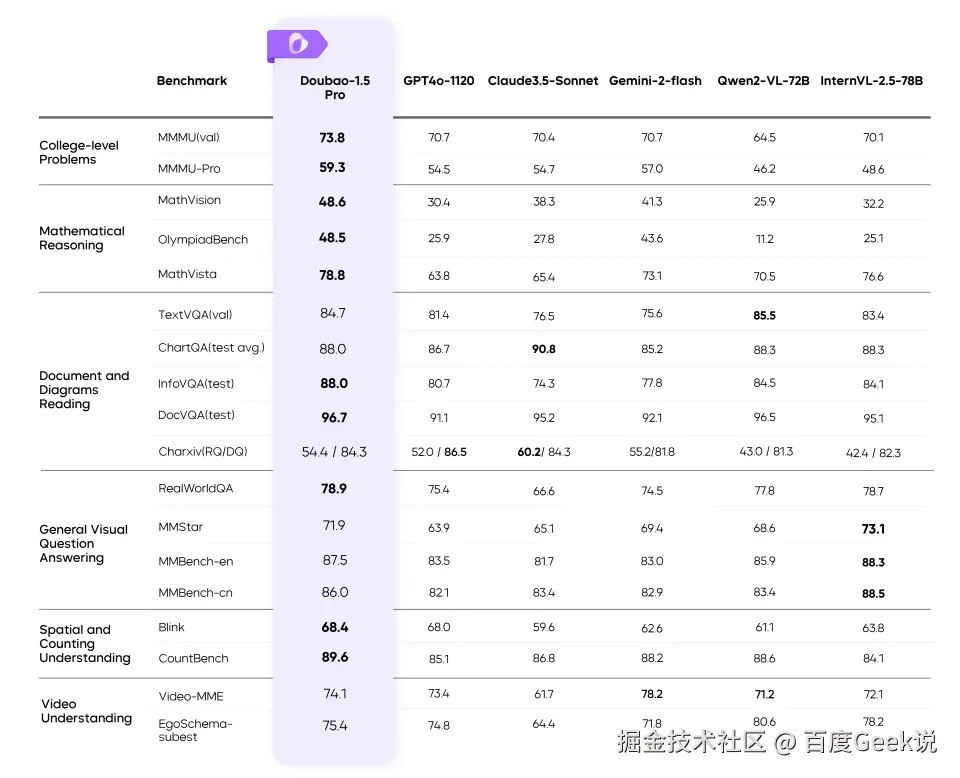
- MiniMax-VL-01:MMMU,MMMU-Pro 数据集虽然不是第一但是也不差,其他数据集优势非常明显。
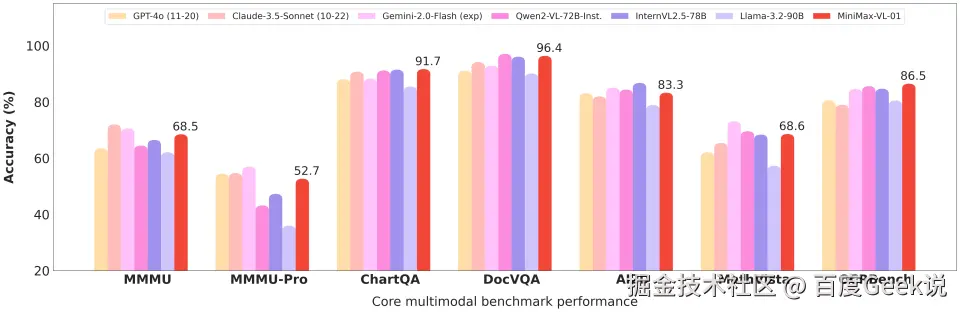
- Gemma 3 27B:什么数据集也不用了,直接上了 LLM Arena 的主观对抗打分。
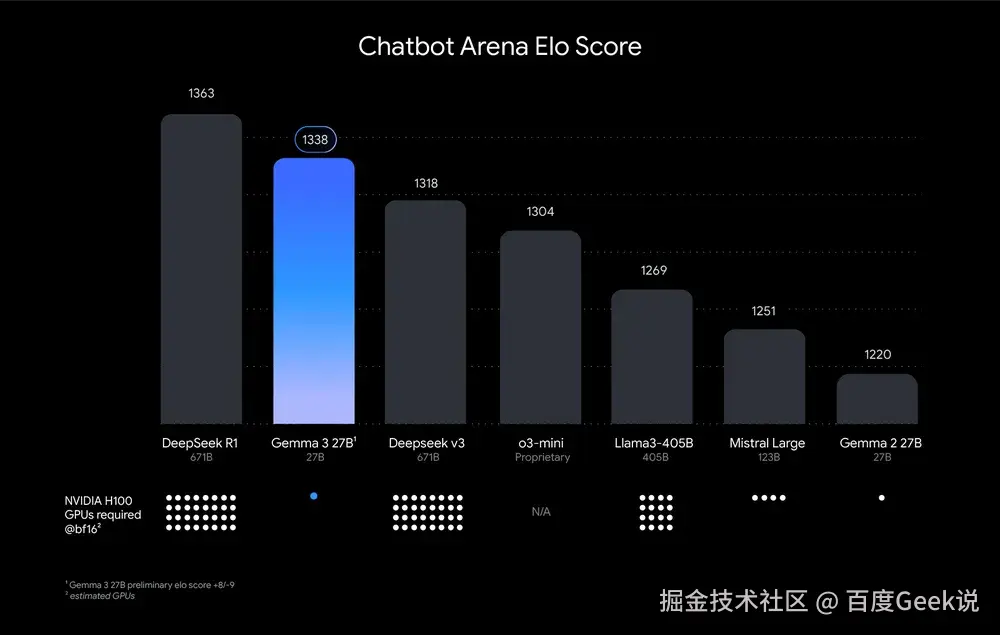
所以,在实际的大模型评估过程中,总能找到特定的数据集、特定的指标和特定的对比对象,使得从数据上看,新发布的模型性能看起来就是 SOTA。
2.3 琳琅满目的通用榜单
如果说技术报告中的性能对比会存在偏差,那么通用榜单应该是靠谱的吧?还记得今天 2 月底,Wan2.1 是如何一炮走红、火爆全网的不?当时,Wan2.1 的宣传语就是:权威评测集 VBench 的信息显示,Wan2.1 大模型大幅领先 Sora、HunyuanVideo、Minimax、Luma、Gen3、Pika 等国内外视频生成模型,以总分 86.22% 的成绩登上榜首位置,成为视频生成领域的全新标杆。
仔细看当时的 Vbench 榜单,我们就会发现,虽然 Wan2.1 确实位于榜首,但是榜单中的 KLING 用的是 24 年 7 月份的模型。
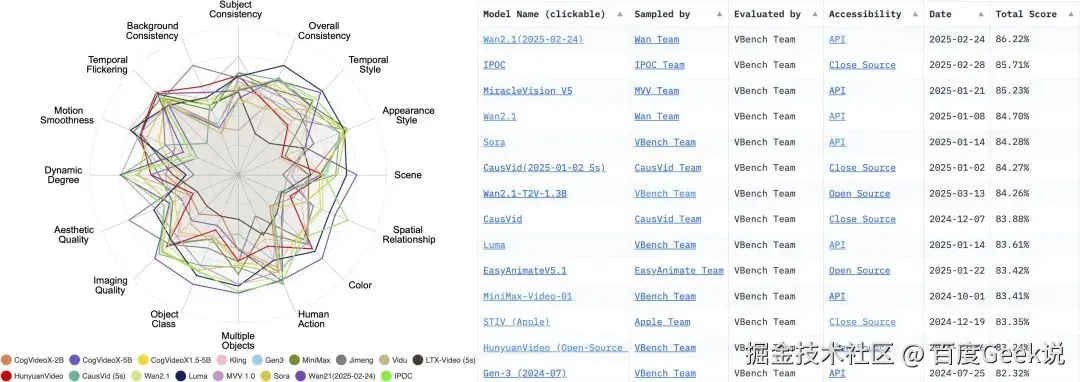
对于其他的榜单,例如 AGI-Eval 和 SuperCLUE的文生视频榜单,或者缺乏最新的模型,或者对比的模型不一致,这导致了同样的模型,在不同的榜单中的排名并不一致。
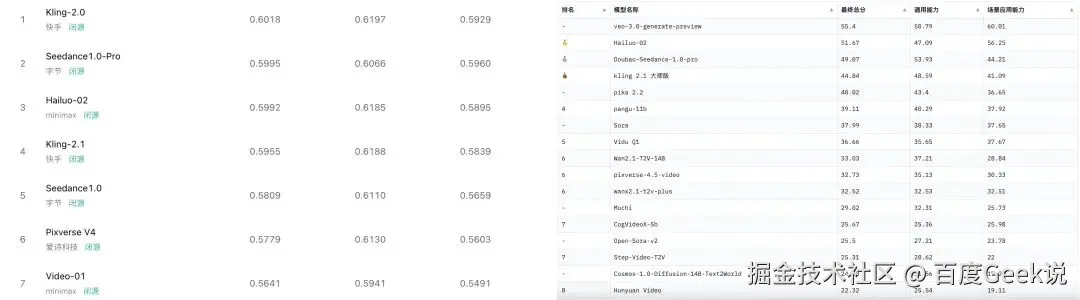
所以,即便想采用通用榜单来评估模型的性能,因为不同的榜单评测方法、评测数据集存在很大的差异,因此也会得到不同的结果,这确实是一件令人非常困惑的事情。
2.4 对于业务,我们该如何决策?
一方面,面对快速发展、甚至是竞争白热化的大模型技术;另一方面,面对如此众多的榜单和SOTA模型。当面临模型选型的时候,作为业务方,我们又当如何决策?
- 创意生成提示词
卡通漫画风格,舞台上聚光灯聚焦,四大巨型机器人------豆包、通义万相、OpenAI、腾讯混元,高举"业界第一"横幅,头部醒目位置嵌入各自公司标志。机器人设计独特,色彩鲜艳,充满未来感。台下人类观众表情困惑,眼神交流中满是疑问,头部上方飘浮着大大的问号,展现他们内心的犹豫与不解。背景是繁华的发布会场,两侧AI技术海报林立,增添科技氛围。整体画面色彩对比强烈,表情夸张,强化幽默讽刺效果。采用近景舞台视角,特写机器人与观众互动瞬间,捕捉戏剧性场面。

03 基于业务的大模型评测实践
如前所述,对于业务而言,技术报告中的评估结果以及通用榜单并不能提供全面、有效的决策信息。
正如 skcd 在 8 月 29 日发布的一条宣传 Grok-code-fast-1 的帖子说的那样:在实际使用中,基准测试确实只能提供有限的信息。
When I joined the coding team, the team was just 3 people and we very quickly built a model which was SOTA on SWEBench. But as things go, in the real world benchmarks matter less.

为此,我们从评测数据集的构建、评估指标、评估方法等多个方面进行优化与实践,探索出了一套适合业务的、置信的大模型评估体系。同时,为了提高整个评估过程的效率,我们也探索了数据集的自动化构建流程、模型效果自动打分等相关的自动化机制。
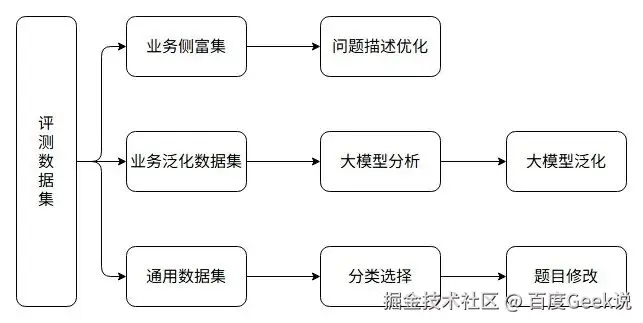
3.1 评测数据集的构建
评测本质上是一个"抽样"的过程,不同的样本会严重影响到最终的评测结果。为了保障评测结果能够反映出不同模型在业务实际使用场景下的真实表现,同时也为了避免模型可能会在训练阶段学习到了部分的榜单数据,我们从三个维度构建了自己的评测数据集。
-
从业务侧富集数据集:这部分数据集不会做大的调整,仅会做细微的修改,比如优化语言表述、优化数据集中存在的明显的错误的表述
-
业务侧数据集的泛化数据集:对业务侧富集到的数据集进行分析,并根据分析结果进行数据集的泛化,例如通过大模型生成相似数据集、生成同一个问题的变体描述等
-
业界通用数据集的泛化数据集:对通用数据集中的原始评测样本进行一定的处理,比如英文样本转换成中文样本、题目选项进行变换、题目中的数据进行修改......
以 MMMU 数据集中的样本为例,不同泛化方式的区别如下表所示。

3.2 自动获取模型结果
针对不同类型的大模型评估,评估集所包含的数据集量级也不同,在实践中,我们的文本评估集数据量级为 1000,图片评估集数据量级为 500,视频评估集数据量级为 200。每次评估,我们一般会选择 3~5 个模型进行对比评估。
从数据获取效率方面看:
-
每次评估,我们需要获取上千个
QUERY的模型结果,因此如何快速的获取这些QUERY的结果是影响评测效率的关键环节。 -
同时,虽然现在大部分大模型都支持
OpenAI API格式,但是也存在不支持该格式的大模型。 -
再者,不同的大模型厂商提供的
API的限流策略和API KEY,因此在获取大模型的结果数据时,如何对这些大模型 API 进行高效的管理也将影响着最终的评测效率。
在评测的实践中,我们发现对于同时提供 API 接口 和 WEB 页面两种服务方式的大模型而言,不同的服务方式获取到的结果会存在差异,例如 WEB 页面一般会提供 联网搜索的功能,但是 API 却没有该功能。

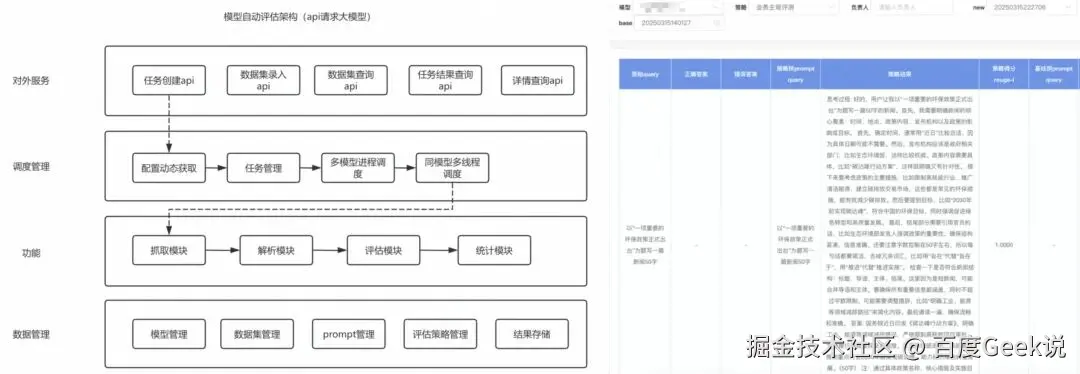
针对如上的问题,我们自研了模型管理平台,该平台支持以API和WEB两种方式自动化获取各种大模型的响应结果。

对于 API而言,平台实现了从数据拼装、模型结果获取到解析、性能统计(首 token 耗时、推理耗时、总 token数等)等全流程管理,可通过模型配置快速接入新模型,可自由定制不同模型实现高并发快速获取模型结果。
3.3 LLM as Judge 的评估方法
在 2024 年 9 月分的时候,我们对发布在 arXiv 上的和大模型评估有关的论文进行了分析,我们提取了提交时间位于 2023 年 4 月至 2024 年 9 月这个区间的 130+ 篇论文进行了分析发现:有 23% 的论文在研究如何利用大模型来评估大模型的效果
在过去的 12 个月内,arXiv 上与 LLM-as-a-Judge相关的论文更是有 700+ 篇,平均每天就有 2 篇论文在研究该课题。

因此,我们认为采用大模型来评估大模型具备一定的可行性。
虽然,近期也有学者不断提出:LLM as a Judge 的方式并不靠谱,例如:
-
2025 年 8 月,Neither Valid nor Reliable? Investigating the Use of LLMs as Judges 这篇论文中提到:LLMs 是人类判断的有效代理 (LLMs as a Proxy for Human Judgment),只要AI裁判的评分和人类专家的评分高度相关,就证明 LLM as a Judge 是有效的,但这个逻辑链条的起点,所谓"人类判断"这个金标,本身就是摇摇欲坠的。既然"人类判断"这个金标本身就存在问题,那么在这个基础之上构建的 LLM as a Judge 也就并非那么靠谱。
-
2025 年 8 月,上海上海交通大学的学者在 PersonaEval: Are LLM Evaluators Human Enough to Judge Role-Play? 这篇论文中也提到:即便是表现最好的模型Gemini-2.5-pro,其准确率仅为68.8%,而人类实验组的平均准确率为90.8%。目前的LLM裁判,还远不够"拟人",不足以可靠地评判角色扮演。对模型进行角色相关的微调,不仅没有提升其角色识别能力,反而可能导致性能下降。
但是,根据我们的时间,在评估标准详细且无二义性的前提下,LLM as a Judge 的方式在评估中还是相对靠谱的。在实践中,我们采用了 Prompt Enginning 和SFT这两种方式是实现 LLM as a Judge。

- 基于千帆平台进行模型微调的流程和效果如下所示:
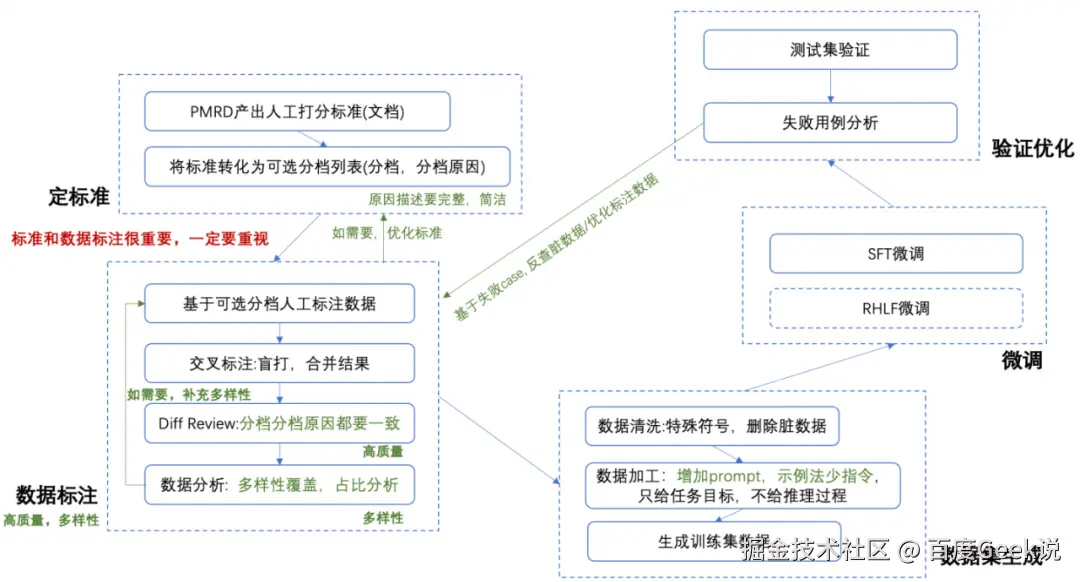
△微调的流程

△微调的数据集示例
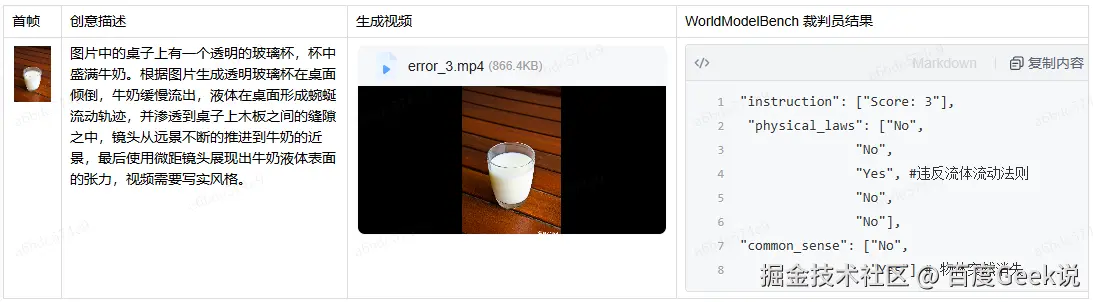
在视频生成大模型的评估中,我们采用了 Dacheng Li 等人 基于 Qwen2-VL-2B 微调的 WorldModelBench 模型作为物理规则检测的裁判员模型,虽然准确率只有 65% 左右,但是确实能比较好的、高效的检测出部分场景下的物理规则问题。
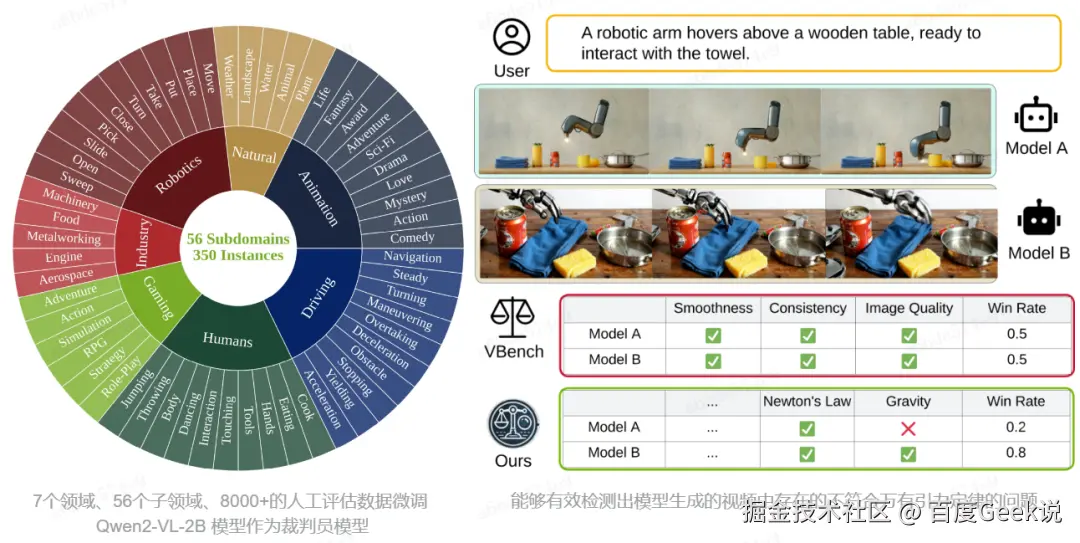
04 大模型评测五条原则
4.1 评测样本必须无歧义
评测数据集中的样本描述必须是准确的、无歧义的,存在歧义的样本无法保证最终的评估结论的准确性。
最典型的就是 OpenAI 在 24 年 8 月 发布的 SWE-bench Verified 数据集,OpenAI 认为 ****原始 SWE-bench 低估了大模型在代码方面的能力,****于是对该数据进行了重新标注并构建了 SWE-bench Verified 数据集。在整个标注的过程中,OpenAI 发现:原始 SWE-bench 中的样本有很大一部分是不合格的。
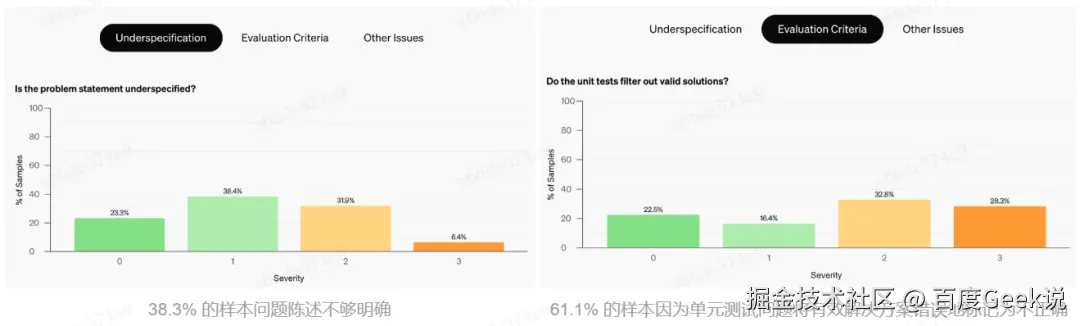
构建图片理解评测样本时的样本歧义举例:

4.2 评测样本必须覆盖模型的新增能力
模型在不断优化的过程中,会针对特定场景进行优化,评测的样本必须能够覆盖这些特定场景,否则就无法对模型性能进行正确的评估。
我们在不同的评估集上对万相 2.1 和可灵 1.6 进行了评估,却得出了不同的结论。
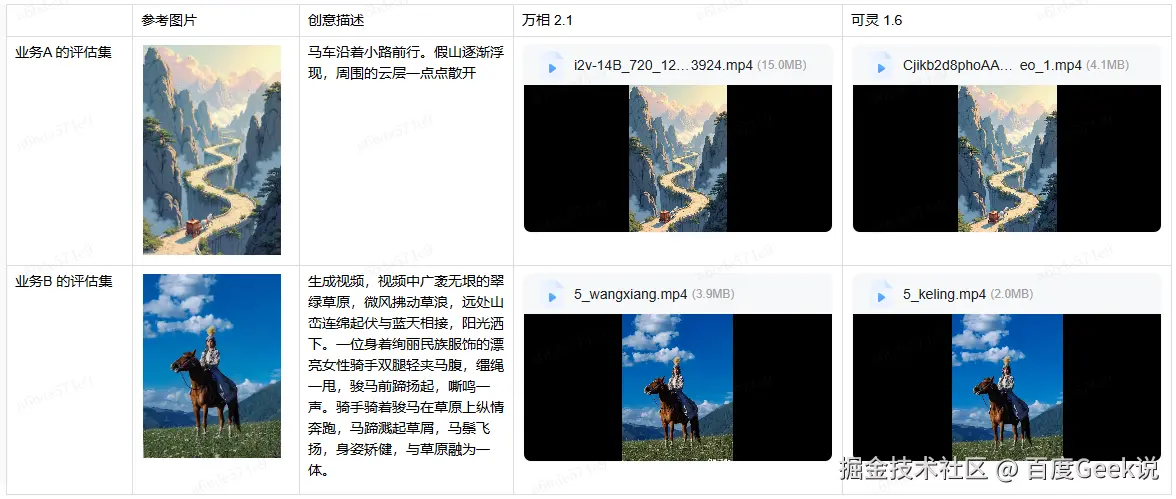
4.3 评测样本必须分场景组织
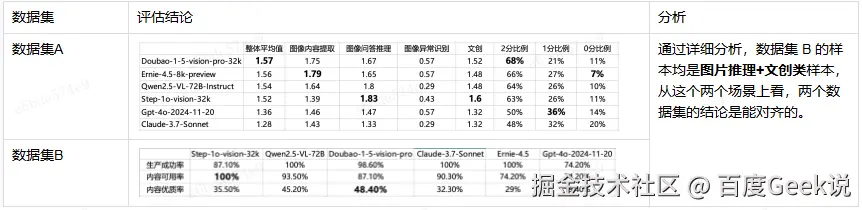
在 3 月 15 日,评估 EB4.5 的图片理解能力的时候,我们在两个数据集上得到了完全不同的结论:
4.4 评测样本中大模型生成结果的参数必须明确
在评测中,我们发现,虽然是相同的模型,对于同样的 Query,不同的渠道获得的结果并不相同,因此在评测时,必须明确产生当前结果的模型的参数。
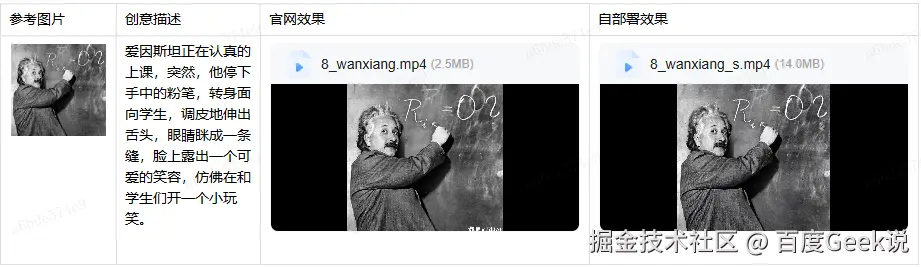
推理模型,如果是 API 访问模型,会缺少联网搜索的能力
如果是 WEB 访问模型,则可以增加联网搜索能力

4.5 评估样本必须细化打分准则,不能只打整体分
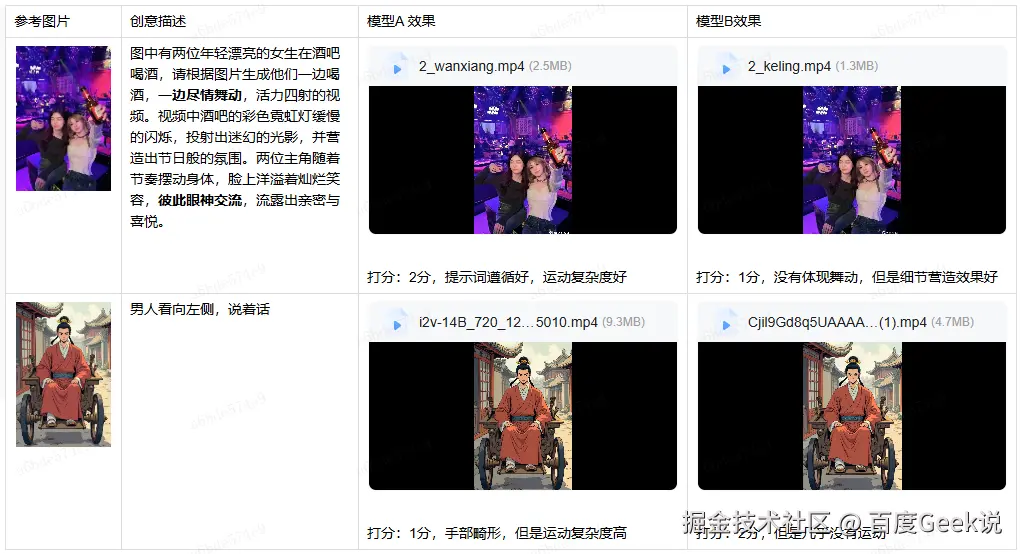
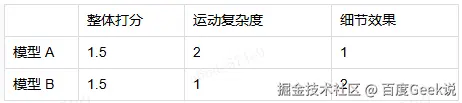
只进行整体评估容易忽略模型的在特殊场景下的优势,也容易忽略模型在特殊场景下的缺点。
对于 Vbench 榜单,对于不同的视频生成模型,从单维度打分来看,不同模型之间有很大的区别。但是从总分来,模型之间的差距反而变的不明显了(80%~86%之间的模型有30+个)。
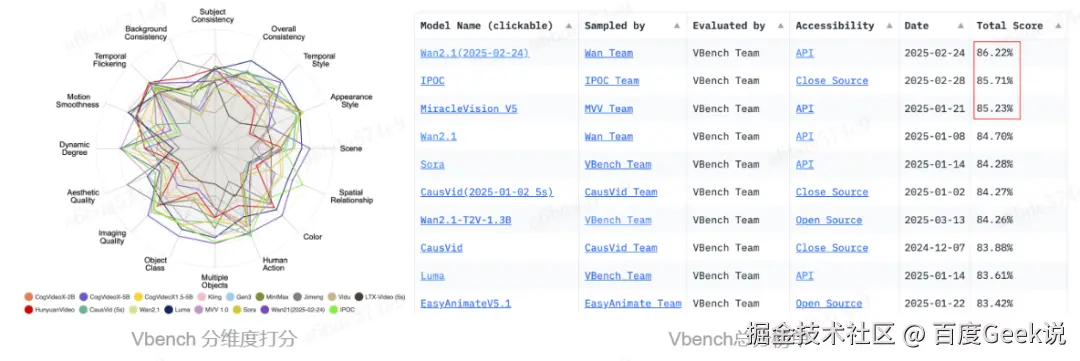
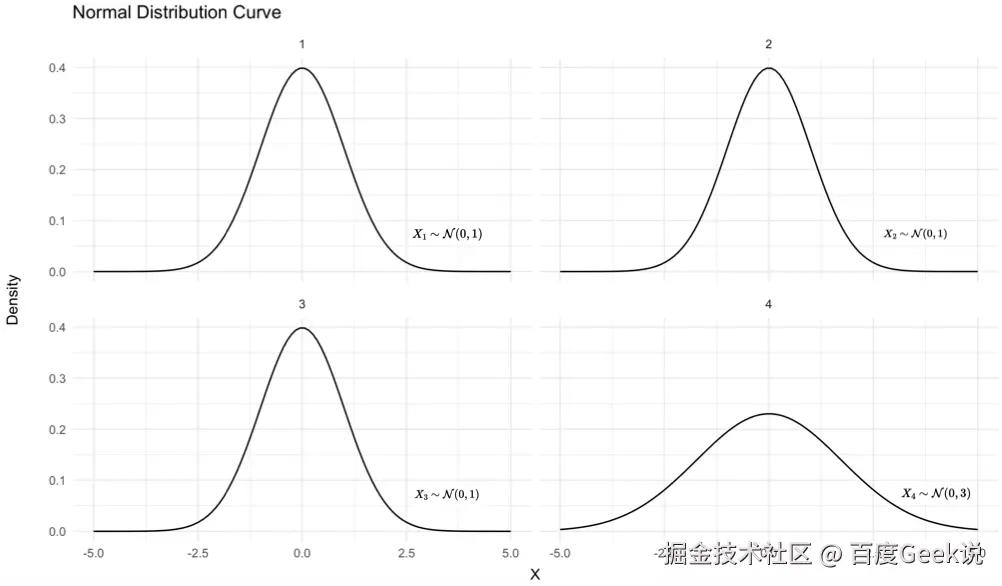
从数学的角度看待分维度打分的必要性。

05 本周有新的大模型发布的概率是多少?