备注 :回顾看过的论文,对目前看过的OLMo系列进行整理在此总结。(注:笔者水平有限,若有描述不当之处,欢迎大家留言。后期会继续更新LLM系列,文生图系列,VLM系列,agent系列等。如果看完有收获,可以【点赞】【收藏】【加粉】)
阐述的思维逻辑:会给出论文中的核心点和核心点的描述。
一句话总结: OLMo 3 是 Allen AI 推出的第三代完全开源"基础模型系列(7B/13B/34B),基于 30 万亿 tokens的 Dolma 3.0 语料库训练,架构上采用 Deep and Wide 缩放策略和 Sliding Window Attention (SWA) 技术将上下文扩展至64K tokens,在保持训练体系完全透明的同时,实现了性能与效率的平衡。
技术亮点:
1 数据管线与架构升级:数据上 模型基于 18 万亿 tokens 的 Dolma 2 数据集进行训练,该数据集经过全面升级,强调数据质量、安全性、长文本结构和可复现性 ,所有语料清洗和混合流程均完全公开。架构上,模型坚持简洁的 Dense Transformer 架构(未引入 MoE/GQA),但通过优化 RoPE 和扩展上下文长度至 32K,实现了长文本能力和训练稳定性的显著提升。
2 训练流程与对齐策略: Instruct 版本通过高质量 SFT 数据、偏好训练(RLHF/DPO)和多轮对话优化进行后训练,并且对齐策略完全透明公开,支持学术界和社区对模型的行为、偏差和安全性进行全面验证和复刻。
摘要
我们介绍了 Olmo 3,一个在 7B 和 32B 参数规模上达到最前沿水平的、完全开放的语言模型家族。Olmo 3 的模型构建目标涵盖长上下文推理、函数调用、代码生成、指令遵循、通用对话以及知识回忆。本次发布包含整个模型流程,即该模型家族从头到尾的完整生命周期,包括用于构建它的每一个阶段、检查点、数据点和依赖项。我们的旗舰模型 Olmo 3 Think-32B 是迄今发布的最强大的完全开放的思考类模型。
一 介绍
我们介绍了 Olmo 3,一个在 7B 和 32B 参数规模上具备最先进性能、完全开源的语言与思考模型家族,拥有多样化的能力,包括长上下文推理、函数调用、代码生成、指令遵循、通用对话以及知识回忆。随着 Olmo 3 的发布,我们更进一步,提供其完整的模型流程:一个语言模型从头到尾的完整生命周期,包括创建它所需的每个阶段、检查点、数据点以及依赖项。这使得开发者可以在模型开发流程的任意阶段进行干预,从而实现无限的定制------而不仅仅局限于最终权重。
为了真正推动开源 AI 研究与开发,我们认为发布一个最先进的语言模型应该使其完整的模型流程------而不仅是最终结果------透明且可访问。借助 Olmo 3 的发布,我们提供了从最初构思到创建完全开源的最先进语言模型的完整路径访问。
我们首先训练 Olmo 3 Base ,作为构建具备思考与工具使用能力模型的基础。在 Olmo 3 Base 的基础上,我们开发了旗舰模型 Olmo 3 Think ,其训练目标是通过生成中间思维轨迹来执行逐步推理,然后再给出最终答案。Olmo 3 Think-32B 是目前最强大的完全开源思考模型,在我们的推理基准测试中缩小了与同规模最佳开源权重模型(如 Qwen 3-32B thinking models(Yang et al., 2025a))的差距,同时使用的训练 token 数量仅为其六分之一。Olmo 3 发布首次实现了从最终推理链回溯至原始训练数据。
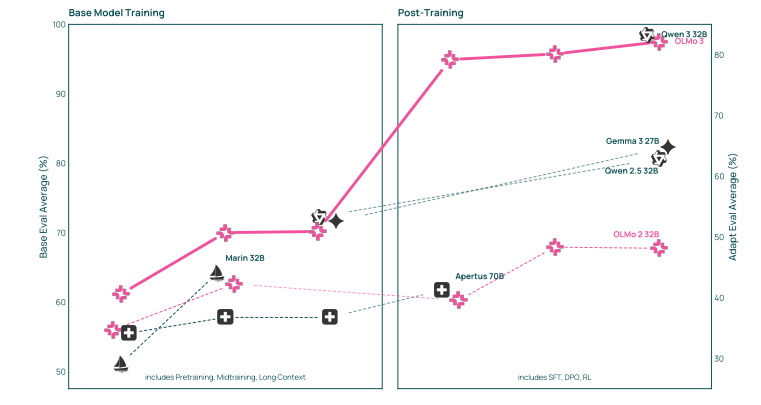 图1 在 Olmo 3 中,我们发布了完整的模型流程包括所有开发阶段的数据、代码和权重。Olmo 3Think 32B(如图所示)与 Qwen 3 328 相比毫不逊色,后者尚未发布基础模型。我们底层的 Olmo 3Base 32B与Qwen 2.5 32B和Gemma3 27B等最佳开源权重基础模型相媲美,此外,它还包含中间检查点,方便用户研究训练过程中的策略和长时间的上下文扩展方案。
图1 在 Olmo 3 中,我们发布了完整的模型流程包括所有开发阶段的数据、代码和权重。Olmo 3Think 32B(如图所示)与 Qwen 3 328 相比毫不逊色,后者尚未发布基础模型。我们底层的 Olmo 3Base 32B与Qwen 2.5 32B和Gemma3 27B等最佳开源权重基础模型相媲美,此外,它还包含中间检查点,方便用户研究训练过程中的策略和长时间的上下文扩展方案。
此外,我们训练了 Olmo 3 Instruct ,其生成的序列比对应的 Olmo 3 Think 模型更短,以提高推理效率,并专注于通用对话和函数调用。Olmo 3 Instruct 的表现优于 Qwen 2.5(Qwen et al., 2024)、Gemma 3(Gemma 3 Team, 2025)、Llama 3(Grattafiori et al., 2024)等开源权重模型,并缩小了与 Qwen 3(Yang et al., 2025a)同规模模型家族的差距。Olmo 3 家族是当前最强的完全开源基础模型集合,表现优于 Stanford Marin(Hall et al., 2025)、Apertus(Apertus Team, 2025)和 LLM360(Liu et al., 2025c)。最后,我们推出 Olmo 3 RL-Zero,在基础模型上进行 RL 训练,使研究者能够在开源预训练数据上进行 RL 基准评测。
The Olmo 3 家族是目前最强的完全开放基础模型集合,性能优于 Stanford Marin(Hall et al., 2025)、Apertus(Apertus Team, 2025)以及 LLM360(Liu et al., 2025c)。为实现这些结果,我们为模型训练流水线的每个阶段构建了全新的前沿数据集。这包括 Dolma 3------我们细粒度的预训练数据混合集,涵盖了经过高度去重的来自网络的自然数据;我们的中期训练数据混合集,包含旨在快速启动推理能力的高质量数据;以及我们的全新长上下文训练数据混合集。我们还引入了 Dolci,这是一个用于后期训练的数据套件,可在监督微调中提升逐步推理能力,为偏好微调提供高质量的对比数据,并为强化学习提供具有挑战性的通用与推理提示。
此外,我们在数据处理、评估、预训练和强化学习方面开发了一系列新的算法与基础设施改进。这包括 OlmoBaseEval------一个专门用于在计算效率尺度下做出基础模型开发决策的基准测试套件;以及 OlmoRL------我们的 RL 训练方法,在算法与基础设施上进行了针对性改进,特别用于训练我们的思维模型。为了设计这些训练方案并在模型训练流水线的各个阶段协调针对广泛能力的定向改进,我们的开发框架在分布式创新与中心化评估之间实现了平衡。
二 Olmo 3 的模型流程
在本节中,我们对 Olmo 3 模型流程的所有组件进行简要概述,重点说明我们在面向推理和工具使用能力方面采用的方法,这些方法相较于 OLMo 2(OLMo et al., 2024)和其他开源权重量级模型实现了进一步的提升。后续章节将对每个模型流程组件进行深入解析。Olmo 3 的训练分为两个主要阶段:预训练和后训练,每个阶段又如图 2 所示进一步划分为多个子阶段。
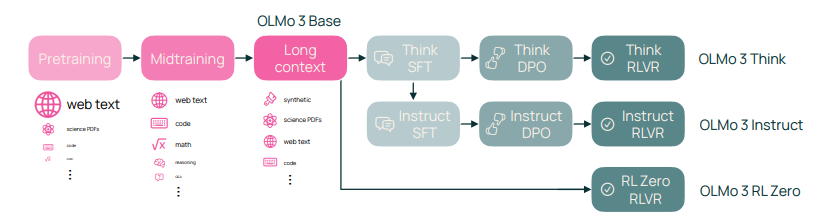 图 2展示了 Olmo3 的模型流程。开发过程分为主要的预训练和后训练阶段,每个阶段又细分为若干子阶段,每个子阶段都有其自身的流程(例如,训练数据和方法)。
图 2展示了 Olmo3 的模型流程。开发过程分为主要的预训练和后训练阶段,每个阶段又细分为若干子阶段,每个子阶段都有其自身的流程(例如,训练数据和方法)。
2.1 基础模型训练
我们以三个阶段来开发 Olmo 3 Base,包括最长 5.9T tokens 的预训练(第 3 节)、1000 亿 tokens 的中期训练(第 3.5.1 节),以及新增的长上下文扩展阶段,训练 500 亿(Olmo 3 7B)或 1000 亿(Olmo 3 32B)tokens(第 3.6 节)。
Evaluation。 我们开发了 OlmoBaseEval,这是一套用于支持基础模型开发(预训练和中期训练)期间决策的基准测试集合。我们的目标是通过在小规模模型上的评估来实现计算效率,并基于这些评估进行开发决策。挑战在于此类小规模模型在某些任务上可能呈现随机水平的表现,其得分间可能存在难以区分于基准噪声的微小差异。为此,我们采取以下措施:(1)将评估相似能力的任务聚合为簇来进行得分汇总(§3.3.1);(2)开发用于小规模模型评估的代理指标(§3.3.2);(3)通过对噪声较大任务使用更多样例进行评估,或直接移除这些任务来提升总体信噪比(§3.3.3)。
Data Curriculum。 我们为每个训练阶段精心构建了专门的数据集,逐步加强对核心能力的关注,使下游能够激发目标能力,如思考、指令跟随等:
•Pretraining :我们首先使用 Dolma 3 Mix(包含 6T tokens 的预训练数据混合)对 Olmo 3 Base 进行训练。虽然 Dolma 3 Mix 在数据来源类型上与其他开源预训练方案中使用的来源基本一致(Soldaini et al., 2024;Bakouch et al., 2025;OLMo et al., 2024),但我们展示了三个关键创新:
-- 用于万亿 tokens 规模的快速可扩展全局去重的新工具;
-- 两种用于优化训练 token 选择的新方法:token 约束混合与质量感知上采样;
-- 一个新的学术 PDF 数据来源------olmOCR Science PDFs------通过 olmOCR(Poznanski et al., 2025a)转换为线性化的纯文本(§3.4.2)。
• Midtraining :我们继续使用 Dolma 3 Dolmino Mix(§3.5)进行训练,这是一个 100B 的数据集,旨在通过以下方式增强代码、数学与通用知识问答等目标能力:
-- 一个新的两部分方法框架,将 1)对单个数据源进行轻量级、分布式反馈循环 与 2)集中式集成测试相结合,以便评估候选混合物在基础模型质量与后训练能力上的表现;
-- 更加有意识地引入某些数据类型------指令数据和思维链数据------以为后训练打下基础。
• Long-context extension(Dolma 3 Longmino Mix):我们构建了高质量数据,包括大量使用我们最新 OCR 工具 olmOCR(Poznanski et al., 2025a,b)处理的科学 PDF。虽然这些 PDF 在基础模型训练的所有阶段均会使用,但在长上下文扩展阶段尤为重要;该集合包含超过 450 万份长度超过 32K 的文档,总 tokens 超过 3800 亿,是目前公开可用于长上下文研究的最大规模集合。Olmo 3 是我们首个具备长上下文能力的模型,可在扩展后支持最高 64K 的上下文长度。
Open Artifacts 我们发布了所有中间检查点以及每个训练阶段的最终模型。我们不仅发布训练数据,还发布数据池(10T 的清洗后源 tokens)以及数据混合物,即用于基础模型训练的实际 tokens。对于数据混合物,我们同时发布 Olmo 3 Base 的真实训练混合物,以及更小规模的样本,用于在较少计算条件下进行可访问性实验(例如 Dolma 3 Mix 的 5.9T 混合物与 100B 混合物)。
2.2 后训练
图 2 展示了 Olmo 3 模型流程的后训练管线,该流程包含三条路径。该管线支持 Olmo 3 Think(§4)和 Olmo 3 Instruct(§5)的训练,这两者均由三阶段训练路径组成,同时也支持 Olmo 3 RL-Zero(§6)的训练,后者在基础模型训练后直接进行强化学习训练。对于后训练,我们引入了 Dolci,这是一个在后训练各阶段具有专门定制数据的全新最先进数据集,主要用于解决思考和函数调用能力。同时我们引入 Olmo 3-RL,这是我们在具备长思维链的 RLVR 方面提出的新算法进展。
• Olmo 3 Think(§4)通过在生成最终答案之前生成扩展的思考过程来进行推理训练。为实现这一点,我们采用由监督微调(SFT)、基于直接偏好优化(DPO)的偏好微调以及可验证奖励强化学习(RLVR)组成的三阶段后训练流程。我们在这三个阶段均观察到持续的收益,展示了细致的数据策划、算法改进和基础设施工程的影响。
-- 我们引入了 Dolci Think SFT(§4.2)、Dolci Think DPO(§4.3)和 Dolci Think RL(§4.4),这是针对数学、编码、指令跟随以及通用对话等广泛关键能力设计的最新后训练数据集。这些数据集包括带有长思维链的 SFT 合成示例、基于 Delta Learning(Geng et al., 2025)洞见构建的高质量对比数据,以及包含可验证与不可验证领域的强化学习挑战提示。值得注意的是,我们在构建偏好微调的对比实例时采用的新方法扩展了模型的推理边界,使其超越仅靠 SFT 所能达到的水平,并为有效强化学习做好准备。
-- 我们在可验证奖励的强化学习方面引入了算法和基础设施的改进(§4.4)。该方法将可验证推理推广到多个领域,超越了 OLMo 2 中探索的设置,扩展至代码与通用聊天。我们的改进支持在不同领域进行更长、更稳定的 RL 训练,并提升训练周期的总体效率,使 RL 训练速度提高了 4 倍。
• Olmo 3 Instruct(§5)训练目标是在不生成内部思考过程的情况下,对用户查询产生高效且有帮助的响应。该模型优先满足典型用户需求,例如避免冗长回答以便于理解,以及通过函数调用来满足检索信息的需求。在此类场景中,思维链并非必要,推理时的效率比推理时的可扩展性更重要。我们引入 Dolci Instruct SFT,这是一个专门增强了函数调用数据的数据集(§5.2.1)。为了在能力的基础上直接优化模型的交互性,我们在 Dolci Instruct DPO 中扩展了 Delta Learning 偏好流程,加入多轮偏好数据和鼓励简洁回答的目标长度干预(§5.3.1)。最后,我们通过可验证奖励强化学习(§5.4)进一步优化核心能力,在这个阶段偏好微调与强化学习协同提升模型性能,同时保持其学到的简洁性。
• Olmo 3 RL-Zero(§6)迄今为止,所有领先的开源 RLVR 基准与算法均基于开源权重量级模型进行训练,而这些模型并不公开其预训练或中期训练数据(Chu et al., 2025;Yang et al., 2025a)。这限制了研究社区分析预训练数据对 RLVR 性能影响的能力。这会导致多种问题,例如基准评估被污染(例如中期训练数据包含评估数据,使得伪奖励与真实奖励同样有效(Shao et al., 2025;Wu et al., 2025c)),或修复 prompt 模板带来的提升超过来自 RL 的提升(Liu et al., 2025b)。
因此,我们发布了完全开放的数据集 Dolci RL-Zero、用于 Olmo 3 的算法化 RL-zero 设定,以及开源的 OlmoRL 代码,以便为生态系统建立清晰的基准。我们在四个基准领域上基于 Olmo 3 Base 进行 RLVR,以创建 Olmo 3 RL-Zero 系列:数学、代码、精准指令跟随(IF)和通用混合领域。在所有情况下,我们均进一步将 Dolci RL-Zero 与预训练和中期训练数据去污染,以确保我们的设定能够在无数据泄漏影响的情况下严格研究 RLVR 的效果。
2.3 结果
表 13 展示了我们对 Olmo 3 Think 的评估快照,并与其他开源权重及完全开放模型进行对比。关于 Olmo 3 Base 的评估请参考第 §3.1 节,关于 Olmo 3 Instruct 请参考第 §5.1 节,关于 Olmo 3 Think 的细节请参考第 §4.1 节。
Olmo 3 Think 是我们所知最强的完全开放思维模型。它优于 Qwen2.5-Instruct、Gemma 2 和 3 27B、DeepSeek R1 Distilled Qwen 32B;它同时也接近 Qwen 3 和 Qwen 3 VL 32B 模型。它正在缩小与同等规模最佳开源权重模型(例如 Qwen 3 32B)之间的差距,同时其训练所用的 tokens 大约少了 6 倍。
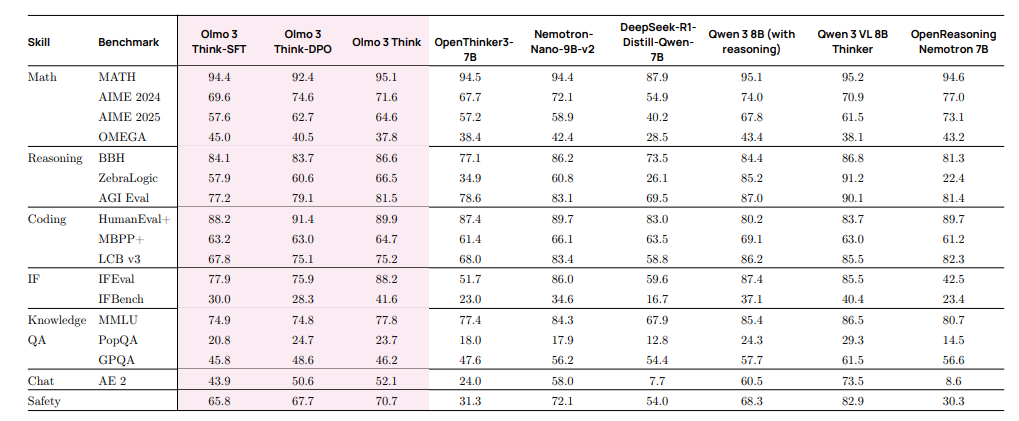 表 13 0lmo 3 Think-7B 在 Olmo 3 评估套件上的结果概述。所有数值均为三次运行的平均值。我们使用评估框架对所有模型进行评估,最多生成 32768个 token.
表 13 0lmo 3 Think-7B 在 Olmo 3 评估套件上的结果概述。所有数值均为三次运行的平均值。我们使用评估框架对所有模型进行评估,最多生成 32768个 token.
三 OLMo3 基模
Olmo 3 Base 的目标是建立一个强大的基础,以支持广泛的一般能力,同时使推理、工具使用和指令跟随等下游能力能够在后训练阶段容易被引出。在本节中,我们描述了 Olmo 3 Base 的配方,组织如下:
• Modeling(§3.2) Olmo 3 Base 与 OLMo 2 高度一致,它是一个 7B 和 32B 尺度的稠密模型,超参数大体相同。除了提升吞吐量的工程改进外,我们重点关注扩大上下文窗口。我们在 §3.2 中给出细节。
• Evaluation(§3.3) 为了避免将基础模型过拟合到某一单一能力,我们大幅扩展了来自 OLMo 2 的评估套件,加入了更多基准。同时,我们改进了在开发过程中依赖小规模实验的方式,包括如何选择和使用基准。更多细节见 §3.3。
• Data 我们引入 Dolma 3,一个支持基础模型开发多个阶段的数据集合:
-
Pretraining(§3.4) 我们在 Dolma 3 Mix 上进行训练,包含 5.9T tokens 的多样自然数据,包括网页、学术 PDF、代码库等来源。我们使用 1024 个 H100 进行训练。2 Olmo 3 Base-7B 的训练吞吐量达到每设备每秒 7.7K tokens。
-
Midtraining(§3.5) 我们在 Dolma 3 Dolmino Mix 上继续训练,包含 100B tokens,将我们最高质量的预训练数据与大量任务数据结合,包括数学与代码问题、指令跟随、阅读理解等。我们使用 128 个 H100 GPU 进行训练。3
-
Long-context extension(§3.6) 我们在 Dolma 3 Longmino Mix 上进行训练,包含 50B / 100B tokens,将长文档与中期训练数据结合。我们使用 256 个 H100 进行训练。4 长上下文扩展需要特殊的训练考虑,我们在 §3.6 中详细说明。
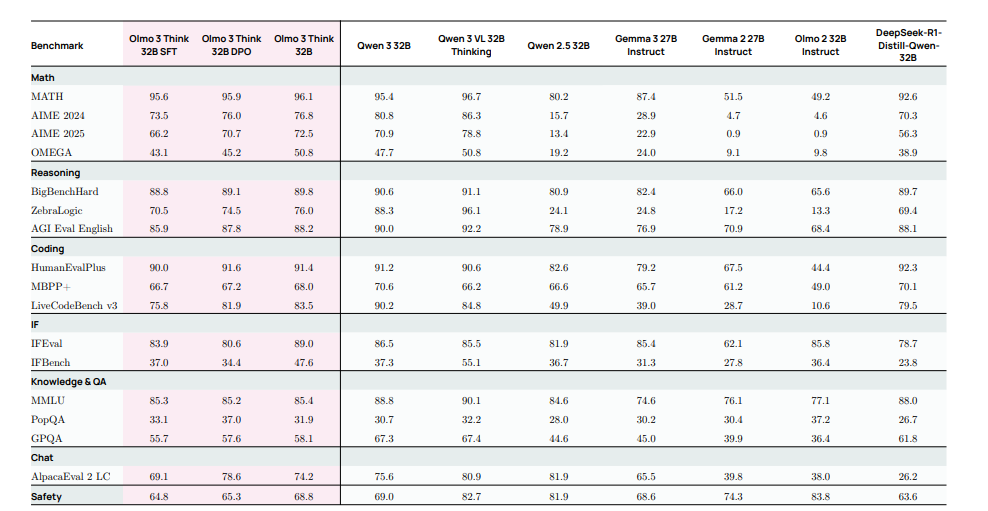 表1展示了我们旗舰机型 Olmo 3 Think-32B 在Olmo3评估套件上的测试结果。Olmo3Think-32B 是目前最好的 32 位全开源机型。
表1展示了我们旗舰机型 Olmo 3 Think-32B 在Olmo3评估套件上的测试结果。Olmo3Think-32B 是目前最好的 32 位全开源机型。
3.1 Olmo 3 Base 的主要结果
表 2 和表 3 将 Olmo 3 Base 与领先的开放基础模型进行比较,展示了我们的评估设计的有效性以及 Olmo 3 Base 在广泛能力上的强劲表现。
Olmo 3 Base 是目前最强的完全开放的 32B 参数模型,性能优于 Stanford Marin 32B。对于 32B 尺度,在数学和代码性能上,Olmo 3 Base 显著优于其他完全开放模型,并与最优秀的开放权重模型保持接近。在 MCQA 表现上,Olmo 3 Base 在非 STEM 领域与其他开放模型相当,在 STEM 领域则与完全开放模型表现一致。最后,在 GenQA 任务中,Olmo 3 Base 优于大多数列出的开放模型。对于 7B 尺度,Olmo 3 Base 在数学和代码性能上显著优于其他完全开放模型,仅在数学任务上被 Qwen 模型超越,在代码任务上则被 Qwen 和 Nemotron 超越。在 MCQA 中,Olmo 3 Base 与最强的完全开放模型在 STEM 与非 STEM 领域均表现相当。最后,在 GenQA 任务中,Olmo 3 Base 在列出的完全开放模型中仅次于 Marin,并且仅落后于更大的 Gemma 2 9B 和 Llama3.1 8B(对于开放权重模型)。
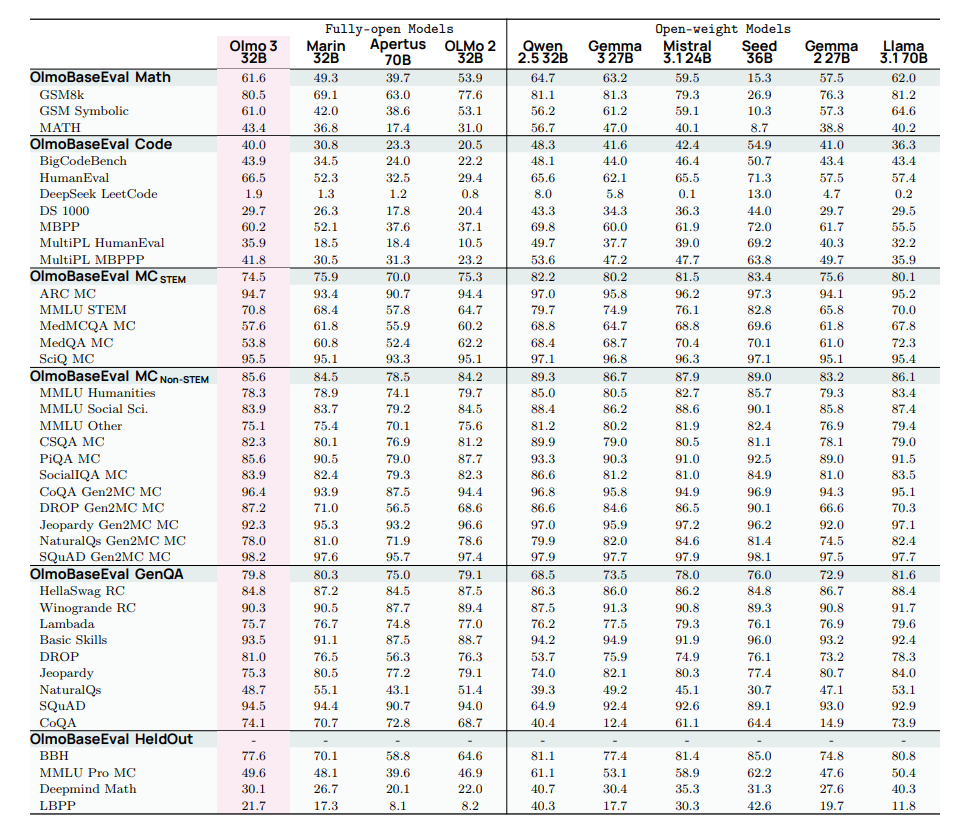 表2 使用 OlmoBaseEval Main 测试套件(详见3.3 节)将 Olmo 3 Base 328 与其他基础模型进行了比较。Olmo3 在发布前未针对预留基准测试进行评估。
表2 使用 OlmoBaseEval Main 测试套件(详见3.3 节)将 Olmo 3 Base 328 与其他基础模型进行了比较。Olmo3 在发布前未针对预留基准测试进行评估。 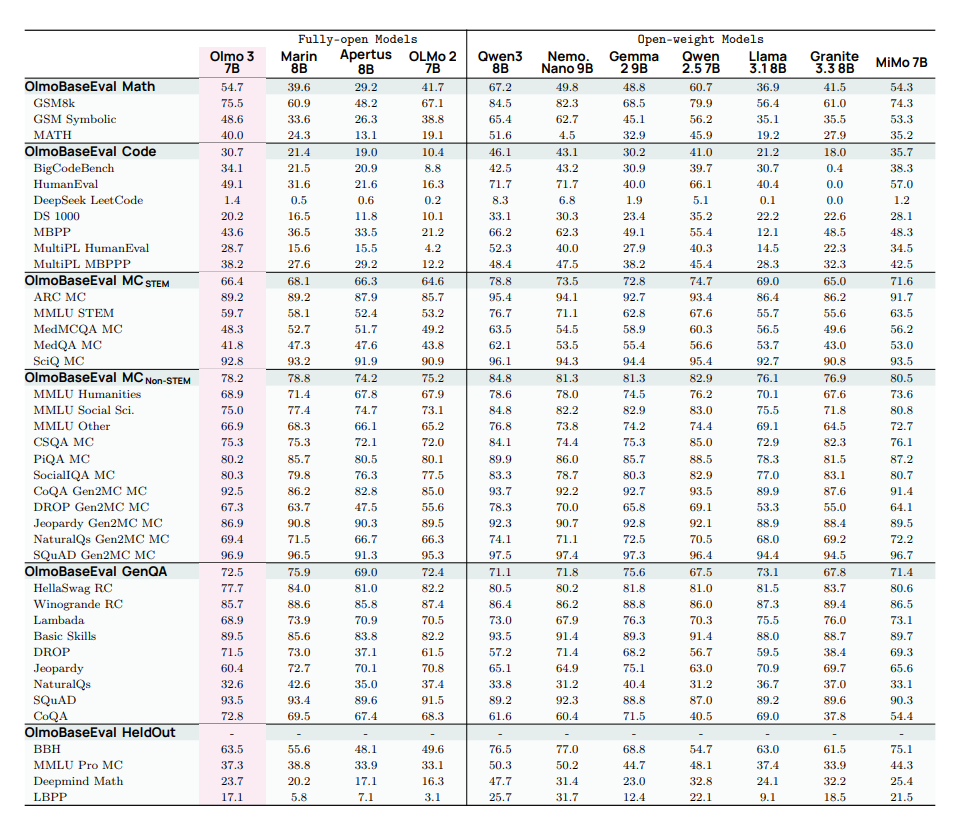 表3列出了使用 OlmoBaseEval Main 测试套件(详见 3.3 节)将 Olmo 3 Base 7B 与其他基础模型进行比较的结果。Olmo3在发布前未针对预留基准测试进行评估。
表3列出了使用 OlmoBaseEval Main 测试套件(详见 3.3 节)将 Olmo 3 Base 7B 与其他基础模型进行比较的结果。Olmo3在发布前未针对预留基准测试进行评估。
3.2 建模与架构
Olmo 3 的建模与训练在很大程度上遵循 OLMo 2。本节我们重点介绍关键差异,更多细节参见附录。
Architecture. 我们采用基于 Vaswani et al. (2017) 的仅解码器 transformer 架构。架构细节呈现在附录 A.1 的表 30 中。与 OLMo 2 相比:
• 在预训练和中期训练阶段,我们将上下文窗口从 4096 扩展到 8192 tokens。
• 为了在更长序列长度下支持可扩展的预训练,并使推理成本保持可控,我们引入滑动窗口注意力(SWA)模式(Beltagy et al., 2020),其中每个 token 可关注前 4096 大小窗口内的 tokens。我们在每四层中的三层加入 SWA,并确保最后一层始终使用全注意力。
• 在长上下文扩展阶段,我们使用 YaRN(Peng et al., 2023)将上下文窗口从 8k 扩展到 64k,覆盖 50B / 100B tokens。更多细节参见第 3.6.4 节。
Training. Olmo 3 Base 使用 OLMo-Core 代码库进行训练。使用此代码库,我们可以在序列长度为 8192、全程采用 bfloat16 精度的情况下,以每 GPU 每秒 7700 tokens 的速度训练 7B 模型,以每 GPU 每秒 1900 tokens 的速度训练 32B 模型。这分别约等于 43% 与 41% MFU。我们通过依赖 PyTorch 内置的 torch.compile()、用于注意力和语言建模头等操作的自定义 kernel、异步与批量化 metrics 聚合、异步写入检查点等方式实现上述性能。OLMo-core 支持预训练、中期训练和 SFT,以及用于检查点转换为 Huggingface 格式或从其转换回来的辅助工具,并提供模型检查点合并工具。对 DPO 和 RL 的支持已规划但尚未完成。更多细节及代码可在 github.com/allenai/OLMo-core 获取。
用于训练 Olmo 3 Base-7B 和 32B 的参数呈现在附录 A.1 的表 31 与表 32 中。与 OLMo 2 一样,我们采用由数据课程与学习率调度定义的分阶段训练(更多细节见附录表 31 和 32)。
**Tokenizer.**我们在各阶段对数据的处理使用与 OLMo 2 相同的 tokenizer,该 tokenizer 派生自 OpenAI 的 cl100k(OpenAI, 2023a,b)。
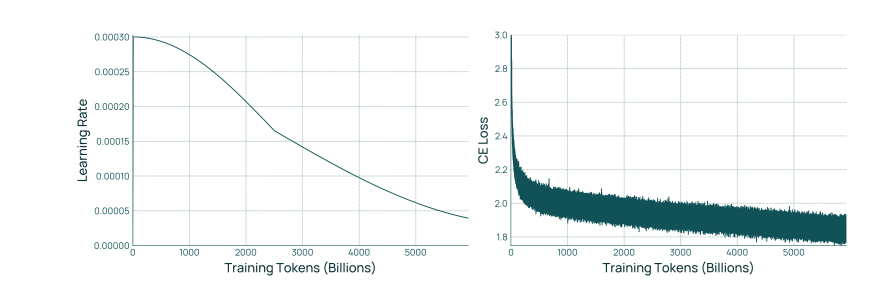 图 3 展示了 Olmo 3 Base 78 的学习率调度和损失函数。学习率调度的前半部分采用余弦调度,处理5T个 token。后半部分则拉伸至一个 epoch 的目标长度(5.93T个token)。预热阶段为2000 步,峰值学习率为3 x10-",最终学习率为峰值学习率的10%。
图 3 展示了 Olmo 3 Base 78 的学习率调度和损失函数。学习率调度的前半部分采用余弦调度,处理5T个 token。后半部分则拉伸至一个 epoch 的目标长度(5.93T个token)。预热阶段为2000 步,峰值学习率为3 x10-",最终学习率为峰值学习率的10%。 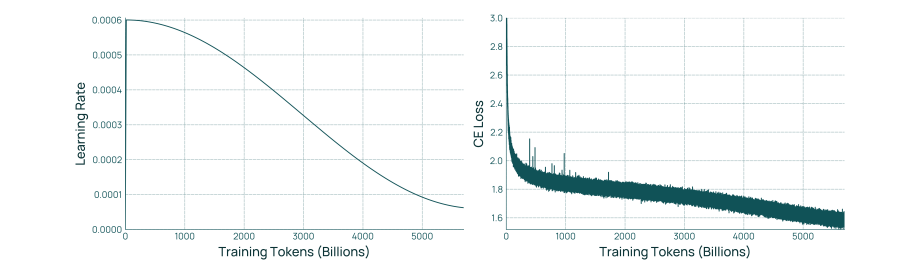 图 4 Olmo 3 Base 32B 的学习率调度与损失。学习率调度是在一个 epoch(5.93 万亿 tokens)上的余弦调度,并在 5.5 万亿 tokens 处被截断。预热(warm-up)为 2000 步,峰值学习率为 6 × 10⁻⁴。该调度目标是达到峰值学习率 10% 的最终学习率。由于截断,实际的最终学习率为 6.210 × 10⁻⁵。与直觉相反,32B 的学习率比 7B 的学习率更高,但这一点在某种程度上被 32B 更大的批大小(每批 800 万 tokens vs. 每批 400 万 tokens)所补偿。
图 4 Olmo 3 Base 32B 的学习率调度与损失。学习率调度是在一个 epoch(5.93 万亿 tokens)上的余弦调度,并在 5.5 万亿 tokens 处被截断。预热(warm-up)为 2000 步,峰值学习率为 6 × 10⁻⁴。该调度目标是达到峰值学习率 10% 的最终学习率。由于截断,实际的最终学习率为 6.210 × 10⁻⁵。与直觉相反,32B 的学习率比 7B 的学习率更高,但这一点在某种程度上被 32B 更大的批大小(每批 800 万 tokens vs. 每批 400 万 tokens)所补偿。
3.3 实验设计与评估
模型开发需要进行许多关于数据和训练的迭代决策。然而,基准并不是完美的决策工具:不同评估仅在特定规模或能力范围内对开发决策敏感(Magnusson et al., 2025)。众所周知,在小规模计算下训练的模型在数学、代码和多项选择问答(MCQA)任务上会表现出接近随机水平的性能(Wei et al., 2022;Gu et al., 2024b),同时基准噪声会降低对分数小差异的信任度(Heineman et al., 2025)。为解决这些问题,我们开发了 OlmoBaseEval,一个用于支持基础模型开发过程中决策的基准集合。OlmoBaseEval 具有以下改进:
• 我们将任务按评估能力分组成簇后对分数进行聚合(§3.3.1),
• 我们通过识别能力在训练中何时"出现"来开发用于评估小规模模型的代理指标(§3.3.2),
• 我们通过在噪声较大的任务上使用更多示例,或在必要时完全移除某些任务,来提升整体信噪比(§3.3.3)。
我们首先以覆盖更多能力为目标,选择了优先科学知识、医学/实验知识、数学和代码任务的基准。由于我们对数据的干预目标是核心能力而非某一个具体基准(例如,"Code" 而非 "DS-1000"),因此我们将任务分组成簇,并期望簇内基准在面对特定数据变化时表现出相似行为。
为了处理使用小计算预算训练的模型(例如我们最大的 1B 参数、100B tokens 的小规模实验),我们进行了 scaling 分析以确定哪些基准在小规模下仍能提供有效信号,并找到用于决策的代理指标。最后,我们分析了每个基准的信噪比------我们选择可提升 SNR 的基准指标,移除对于决策而言噪声过大的基准,并在某个基准的噪声主导聚合分数时,将其从平均中移除。
3.3.1 聚类任务
为处理大量任务,我们将相似任务聚类为宏观平均(macro-averages)。我们的目标是使任务聚类与我们进行数据干预的粒度相匹配,并使每个聚类内的任务表现相似。我们的聚类程序需要一个确定两个评估相似性的过程------我们通过收集来自 70 个外部开放权重模型的 23K 个基准分数池来实现这一点。
使用我们的评估结果数据集,如果两个基准对模型的排名相似,我们假设它们评估的是相似的构造。我们使用 Ward 的方差最小化法(Ward Jr, 1963)进行层次聚类,该方法通过迭代合并评估分数来最小化聚类内基准之间的分数方差。图 5 展示了聚类程序的结果,我们手动选择一个阈值以平衡聚类的数量和粒度。重要的是,我们不使用聚类程序的精确结果------我们手动移动一些任务,以确保每个聚类内任务的格式一致(例如,所有需要执行代码的任务都位于同一聚类)。最终的任务聚类包括:MCSTEM、MCNon-STEM、GenQA、Math、Code 和 Code FIM。
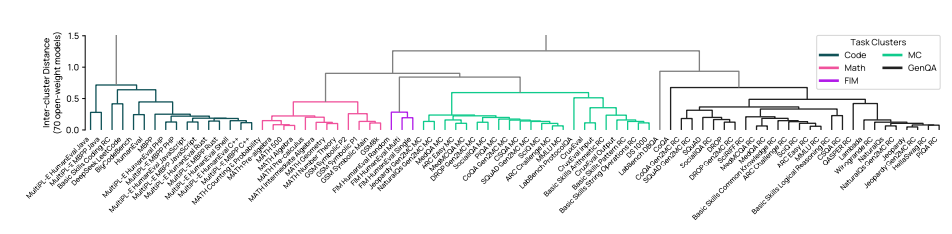 图5 展示了 OlmoBaseEval 的任务聚类。该聚类方法使用 23K 个基准测试结果,迭代地合并模型排名相似的任务,直至达到停止条件。为了构建OlmoBaseEval,我们将格式相同的任务移至同一簇,并将 MC 分为 STEM 和非 STEM 任务。
图5 展示了 OlmoBaseEval 的任务聚类。该聚类方法使用 23K 个基准测试结果,迭代地合并模型排名相似的任务,直至达到停止条件。为了构建OlmoBaseEval,我们将格式相同的任务移至同一簇,并将 MC 分为 STEM 和非 STEM 任务。
3.3.2 尺度分析
我们评估开放权重模型在从 10¹⁸ 到 10²⁵ FLOPs 的计算规模下的表现,以确定特定指标和任务在何种计算规模下对开发决策有用。在某些评估基准上,当模型在小规模下训练时很难看到信号(Wei et al., 2022),而其他基准在接近基准标注错误时会"饱和"(Vendrow et al., 2025)。然而,虽然许多任务表现为新兴能力,但连续代理指标已被证明是在退出噪声底线之前评估模型性能的更好决策工具(Schaeffer et al., 2023; Huang et al., 2024b; Magnusson et al., 2025)。我们提出了 Base Easy 任务套件,它测量 Base Main 任务套件中具有黄金标签或人工编写答案的任务的 bits-per-byte,计算方法为答案的负对数似然除以答案字符串的 UTF-8 字节数,如 Gao 等(2020)所述。
我们使用来自 (Bhagia 等2024)的 25 个 OLMo 2 缩放法模型套件评估,以了解低计算规模下的缩放行为,并使用 70 个开放权重模型评估高计算规模下的缩放行为。图 6 展示了我们最终 Base Main 基准的缩放行为。对于每个任务族,Base Easy 任务套件在小数据消融规模下显示信号,而 Base Main 任务套件在大规模下未饱和,为中期训练的数据实验留下了空间。
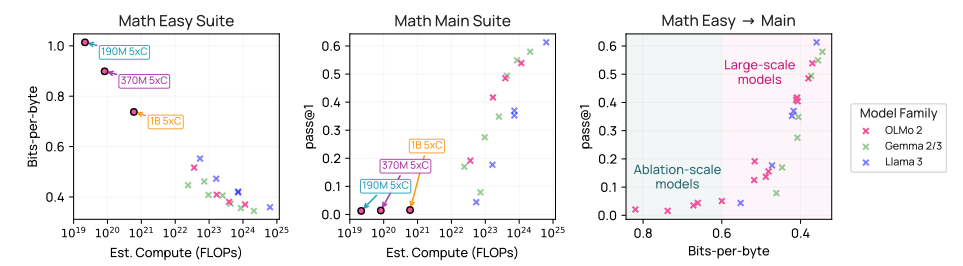 图6 展示了 OlmoBaseEval Math 套件的规模分析。我们使用 OLMo 2 规模模型(Bhagia 等人2024)来寻找基准和指标,这些基准和指标能够为小规模模型(左侧和中间)提供有效信号。然后,我们使用小规模的 OlmoBaseEval Easy 套件作为代理指标,用于数据决策。
图6 展示了 OlmoBaseEval Math 套件的规模分析。我们使用 OLMo 2 规模模型(Bhagia 等人2024)来寻找基准和指标,这些基准和指标能够为小规模模型(左侧和中间)提供有效信号。然后,我们使用小规模的 OlmoBaseEval Easy 套件作为代理指标,用于数据决策。
3.3.3 信噪比分析
在报告宏观平均时,我们旨在排除每个聚类中过于噪声的任务,这些任务对开发不具帮助。我们根据 Heineman 等(2025)的方法计算每个基准的信噪比(SNR),评估 OLMo 2 13B 训练的最后 50 个检查点,以及大约在相同计算规模下训练的 10 个外部基础模型(4 ⋅ 10²³ FLOPs)。根据我们的发现,当可用时,我们从使用 1K 实例子集过渡到完整评估集。我们完全移除了一些基准,特别是 BoolQ 等二元基准(Clark et al., 2019),因为我们发现模型通常在预测多数类和少数类之间振荡。
我们对中期训练重复相同分析,使用 5 次初步预训练运行的中间检查点。其中一个重要发现是将一些基准从宏观平均中分离,如 CruxEval(Gu et al., 2024a),它测量一个相关且独特的能力(代码输入/输出预测),但会向宏观平均引入过多噪声。图 7 展示了在中期训练中三个单独基准的信噪比与基础主要任务平均值的对比示例。
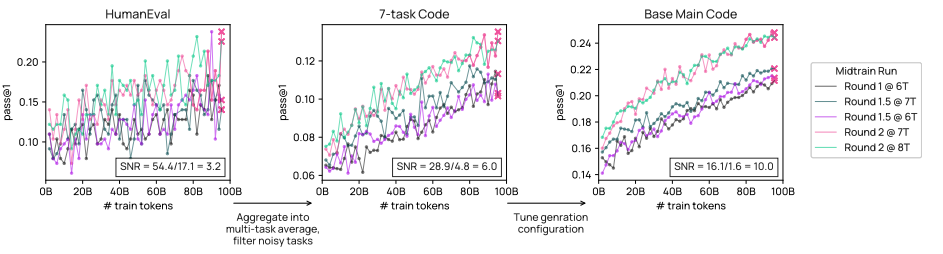 图7展示了 OlmoBaseEval 算法在训练中期使用中间检查点对代码多任务平均值进行的信噪比分析。首先,我们将结果聚合为多任务平均值,并移除噪声较高的任务,例如 CruxEval(左中)。然后,我们调整生成参数以提高信噪比,例如通过增加 pass@k中的 n值(右中):
图7展示了 OlmoBaseEval 算法在训练中期使用中间检查点对代码多任务平均值进行的信噪比分析。首先,我们将结果聚合为多任务平均值,并移除噪声较高的任务,例如 CruxEval(左中)。然后,我们调整生成参数以提高信噪比,例如通过增加 pass@k中的 n值(右中):
3.3.4 OlmoBaseEval
最终得到的 OlmoBaseEval 包含一个 Base Easy 套件,用于在小计算预算(如小于 10 亿参数)下做开发决策,以及一个 Base Main 套件,用于最终预训练运行和中期训练的开发决策。我们在 §4.1 中详细介绍 Chat 套件。OlmoBaseEval 包含 43 个任务,比 OLMo 2 多 4 倍,包括在预训练中跟踪数学和代码基准。为了防止对开发套件过拟合,我们包括 4 个保留基准------MMLU Pro、Deepmind Math、LBPP 和 BBH------每个基准匹配我们在预训练期间目标的一个广泛能力。
这包括四个新基准:BasicSkills,一组 6 个任务,用于在预训练期间隔离技能发展(例如基本算术、推理和编程);Gen2MC,5 个短期生成任务的多选版本;MT MBPP,为 MBPP 的 17 种编程语言翻译的 BPB 集;Masked Perplexity,一种新评估方法,通过应用 token 掩码并仅在难以学习的 token 上计算困惑度。我们使用 UltraChat 和 WildChat 对 Masked Perplexity 进行评估,这提供了在预训练中对真实用户交互评估的广泛覆盖。OlmoBaseEval 的其他设计和实现细节见附录 A.3。
3.4 Stage 1: Pretraining
我们首先在 Dolma 3 Mix 上训练 Olmo 3 Base,这是我们的 6 万亿 token 预训练数据混合。虽然 Dolma 3 Mix 主要由其他开放预训练方案中使用的相同类型数据源组成(Soldaini et al., 2024; Bakouch et al., 2025; OLMo et al., 2024),我们展示了三个关键创新:
• 用于在万亿 token 规模上快速且可扩展的全局去重的新工具,
• 两种优化训练 token 选择的新方法:token-约束混合和质量感知上采样,
• 一种新的学术 PDF 来源------olmOCR Science PDFs,通过 olmOCR 转换为线性化纯文本(§3.4.2)(Poznanski et al., 2025a)。
表 4 总结了我们的数据源、池大小和最终训练混合。由于开发基础模型是我们开发过程中计算最密集的部分,需要训练数万亿 tokens 并消耗超过 90% 的总体计算,我们遵循两个主要原则来指导数据策略:
-
如果一个数据源有潜力在预训练规模上产生足够的 tokens 来影响模型能力,我们才考虑用于预训练。小型但有价值的数据源在预训练中可能影响有限,更适合保留用于中期训练。
-
虽然我们接受探索结构化"任务"数据(例如 QA 对、聊天实例)用于基础模型训练,但仅在中期训练的后期阶段(§3.5)和长上下文扩展(§3.6)中使用。任务数据即使通过合成生成,也往往无法满足影响预训练阶段所需的数据池大小,而且任务数据往往对评估结果影响过大,可能干扰其他来源的数据消融实验。
图 11 总结了创建 Dolma 3 Mix 预训练数据的流程步骤。本节剩余部分将对其进行更详细的描述。
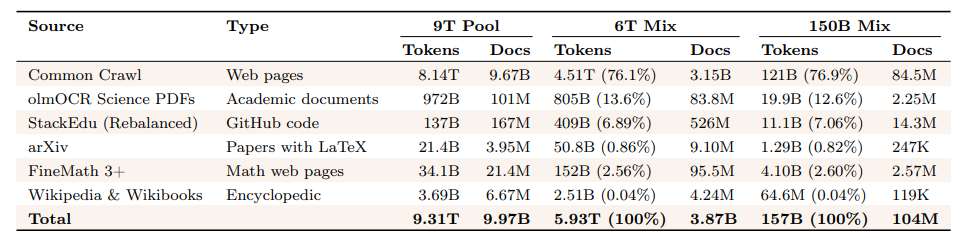 表 4 Dolma3 的组成,包括我们的 9T 数据集、用于最终模型训练的 6T 混合数据集以及用于实验的150B 混合数据集。
表 4 Dolma3 的组成,包括我们的 9T 数据集、用于最终模型训练的 6T 混合数据集以及用于实验的150B 混合数据集。
3.4.1 Preparing our Web Data Pool
我们采取以下步骤从 CommonCrawl(Common Crawl Foundation)策划预训练数据,该数据构成了我们预训练语料库的大部分。
文本提取 我们从 CommonCrawl 语料库的 104 个 dump 开始,截止日期为 2024 年 12 月 31 日。遵循 DCLM(Li et al., 2024a),我们移除 HTML 伪影,并使用 Resiliparse(Bevendorff et al., 2018)从 WARC 文件中提取语义文本。在适用情况下,我们直接利用 DCLM-pool(Li et al., 2024a)中由 Resiliparse 提取的原始数据,并对 DCLM-pool 中未包含的 dump 应用 Resiliparse 提取。
启发式过滤 我们应用了一系列启发式过滤步骤,将最初收集的 252.6B 文档修剪到适合预训练的规模。我们的过程紧跟 DCLM(Li et al., 2024a),并进行少量修改以提高数据质量和计算效率。我们首先应用 URL 过滤,从扩展的黑名单中删除垃圾和成人内容。随后删除过短或过长的文档,再过滤包含过多符号或字母字符不足的文档。接下来,我们删除包含大量内部重复的文档,并应用过滤移除常见的垃圾短语,完全移除被此类过滤破坏的文档。然后,我们使用 fastText 分类器识别每个文档的语言,仅保留包含英文文本的文档。最后,我们应用 Madlad400(Li et al., 2024a)提供的句子级启发式规则。总体而言,此过程将数据池大小减少了 84.6%,得到 38.8B 文档。更多细节见 §A.1。
去重 从 CommonCrawl 收集的网页数据自然包含大量重复文档。这些重复来源于对同一网站的重复爬取、跨多个网页出现的近似文档副本以及高度重复的模板文本。我们的去重策略受到先前工作的三点观察启发:i) 去重通常能带来更高的 token 使用效率(Lee et al., 2022);ii) 重复计数是数据质量的弱信号,重复计数越高表示质量越高(Fang et al., 2025a);iii) 文档重复超过少数几次收益迅速递减(Muennighoff et al., 2025a)。
基于这些观察,我们设计去重策略以支持未来的基于质量的上采样步骤(§3.4.4)。我们在多个粒度上对数据集进行积极去重,目标是移除完全复制、近似重复和重复填充文本。虽然这不可避免地丢弃了重复计数的质量信号,但它产生了一个干净的基础数据集,我们可以在之后为高质量文档选择性地重新引入重复。我们的目标是最终数据集整体重复最小,任何重复集中在高质量数据中。我们的去重程序分三个阶段实施:
• 精确去重:基于文档文本哈希进行全局去重,移除所有完全复制的文档。此步骤识别出 67% 的池为重复文档,将数据集从 38.7B 减少到 12.8B 文档。
• 模糊去重:使用基于 MinHash 的去重识别并移除近似相同的文档,如跨多个域复制的文档,仅在页眉或页脚有所差异。我们将数据集划分为 32 个分片,在每个分片上运行 MinHash 去重,然后对每个识别的聚类内执行详尽的成对 Jaccard 相似度检查。从每个聚类中保留爬取日期最新的文档。该步骤识别 23% 的池为重复文档,得到 9.8B 文档。
• 子字符串去重:前两步移除了整个重复文档,但未处理单个文档内重复内容。许多文档包含大量模板文本或 HTML 伪影(如页眉和页脚),训练价值有限。为移除这些重复子字符串,我们应用了一种新型的基于模糊后缀数组的去重方法。我们将数据集划分为 57 个分片,对每个分片应用此方法,标记出现多次的 500 字节或以上的子字符串。不同于以往的后缀数组方法,我们保留了语料库中每个重复子字符串的至少一次出现。然后合并标记重复子字符串的区间,以移除长重复片段之间的短子字符串。此步骤移除 14% 的文本字节,得到 9.7B 文档,总计 36.5T 字节未压缩文本。
这三阶段过程将网页语料从 38.7B 减少到 9.7B 文档------文档数量减少 75%。得到的积极去重数据集可按主题和质量进行划分,并可控制性地上采样用于训练。
为扩展我们的去重策略,我们开发了 Duplodocus 工具,一款用于大规模分布式执行基于哈希精确去重和 MinHash 模糊去重的本地 Rust 工具包。
主题和质量分类 我们使用 WebOrganizer 工具(Wettig et al., 2025a)将去重后的语料划分为 24 个主题(如 "Science and Technology"、"Politics")。我们还训练并应用基于 fastText 的质量分类器,为每个文档分配质量分数。遵循 DCLM(Li et al., 2024a),我们使用 OpenHermes-2.5(Teknium, 2023)和 ELI5(Fan et al., 2019)作为正训练样本,并补充 UltraChat-200k(Ding et al., 2023)和 WildChat-1M(Zhao et al., 2024a)。负训练样本来自从 DCLM-RefinedWeb 抽样的 30GB 数据。
我们将主题和质量分类器应用于完整的去重语料,以便划分数据集。文档首先按主题划分,然后在每个主题分区内计算质量分数百分位数,并将文档细分为 20 个质量等级(每个等级 5% 百分位)。这一两阶段划分得到 480 个不相交子集(24 个主题 × 20 个质量等级),实现对预训练混合中主题和质量分布的精细控制。
最终网页数据池 以上步骤得到一个 8T token 的标注数据池,按主题和文本质量划分桶。该数据池作为我们预训练混合的基础,尽管构建最终训练数据仍需额外处理,具体来说,我们应用基于质量的过滤和主题重加权,以生成平衡且高质量的混合,如 §3.4.4 所述。
3.4.2 Preparing our PDF Data Pool
我们策划了一组新的学术 PDF 数据集,取代了之前使用的 peS2o(Soldaini and Lo, 2023)。这些文档采用"礼貌"方式爬取:使用公开用户代理、遵守 robots.txt 并尊重付费墙。爬虫主要针对学术网站和论文存储库。我们使用 olmOCR(Poznanski et al., 2025a)处理所有 PDF。最终,此次爬取生成了 238M 个独特 PDF 文档,截止日期为 2024 年 12 月。
OlmOCR 文本提取。 为将 PDF 转换为训练器可用格式,我们进行了预过滤和文本提取。如果文档包含原生数字文本,我们使用 Lingua 语言检测器保留仅英文文档,并移除垃圾或 SEO 优化关键词超过总词数 0.4% 的文档。随后使用 olmOCR(Poznanski et al., 2025a,版本 0.1.49-0.1.53)提取文本。当 olmOCR 失败时,我们使用 Poppler 的 pdftotext 作为备用;超过 1/250 页需要此备用的文档从语料中排除。最终得到 160M PDF 文档的数据集。
去重。 然后我们使用 MinHash 算法识别并移除模糊重复文档。这与 §3.4.1 网页文本语料的 MinHash 步骤略有不同:我们使用 FineWeb(Penedo et al., 2024)中的 MinHash 参数,针对相似度至少 75% 的文档对;并省略了详尽的成对 Jaccard 相似度检查。此去重步骤后,语料库剩余 156M 文档,去重率为 2.3%。
PII 过滤。 接下来,我们从 PDF 池中移除包含 PII 的文档。我们希望删除包含敏感独立 PII(如政府 ID、登录信息)的文档,同时也删除将个人的传记、医疗、位置、就业或教育信息关联到特定个体的文档,但此过滤需具备上下文意识。一些文档如公共会议记录包含 PII 标识符(如与地址关联的姓名),但用于公开传播,我们不希望移除这些文档。在尝试使用人工标注者识别和移除 PII 后,我们开发了多阶段模型基础的 PII 识别流水线。首先,使用 gemma-3-12B(Gemma 3 Team, 2025)对每个文档的第一页进行提示分类,判断其是否包含敏感独立 PII 或将敏感信息关联到个体。然后,使用 gemma-3-4B 对每个文档的前 5000 个字符进行分类,得到描述文档类型的标识。基于这些分类结果,我们制定了一套规则,识别哪些包含 PII 的文档应公开,哪些应过滤。最终此步骤移除剩余池的 4.9%,得到 148M 文档。更多 PII 移除细节见 Poznanski et al.(2025a)。
启发式过滤。 在 PII 移除后,我们进行一轮启发式过滤以进一步去除低质量文档。此步骤的过滤包括检查:Lingua 过滤未捕获的非英文文档;超过 30% 为表格的文档;包含超过 20% 数字的文档。随后我们将 markdown 表格转换为 HTML 并移除 URL 引用。最后,出于法律目的,我们移除未包含宽松许可证的文档。上述过滤步骤组合得到 108M 文档的语料库。随后,将此语料库根据 WebOrganizer 主题分类器(Wettig et al., 2025b)划分为 24 个主题桶,并交由混合阶段处理。
3.4.3 准备代码、数学及其他来源
Code 对于代码数据,我们使用了 StackEdu(Allal 等人,2025),这是对 the-stack-v2 数据集(Lozhkov 等人,2024)中 GitHub 代码库的一种改进整理,并额外针对教育类编程内容进行了过滤。我们按照编程语言对数据进行划分,以便后续混合使用。
Math 与 OLMo 2 一样,我们包含来自 Proof-Pile-2 数据集(Azerbayev 等人,2023)的 arXiv 文档,此数据集源自 RedPajama 数据集(Together AI,2023),其截止日期为 2023 年 4 月。我们主要使用这个来源是因为它保留了原始的 LaTeX 表达,使模型能够同时学习数学内容及如何正确排版数学公式。
此外,我们用 FineMath(Allal 等人,2025)替代了之前使用的 OpenWebMath(Paster 等人,2023),FineMath 是 Common Crawl 文档的一个子集,其中包含数学教育内容,并经过重新处理以保留正确的数学符号格式。我们包含所有 FineMath 质量评分至少为 3(满分 4)的文档。该数据截止日期为 2024 年 9 月。
Other 最后,我们加入 Dolma1.7(Soldaini 等人,2024)中的 Wikipedia 和 Wikibooks 作为百科知识的基础来源。这些数据包括"English"和"Simple"版本的 Wikipedia 与 Wikibooks,截止日期为 2023 年 3 月。所有这些来源都使用 WikiExtractor(Attardi,2015)处理以移除标记格式,并过滤掉所有词数不超过 25 的文档,以排除模板化页面或 XML 解析错误的页面。
3.4.4 在数据池中进行采样与混合
上述数据来源整体提供了超过 9 万亿 token 的多样化文本数据。将这一集合转换为训练数据集,需要一个混合与采样流程,用以精确规定最终训练混合中各来源包含多少数据,以及是否、以及在多大程度上对特定来源进行上采样。我们采用一种混合策略,该策略利用 swarm-based 方法训练和评估大量较小的代理模型,并使用这些结果来指导最优混合。此外,我们应用了一种新的条件混合方法,以应对数据来源在整个开发周期中不断被优化与更新的事实。本节描述我们如何得到每个来源的混合比例;对于 web 文本,我们仅在 WebOrganizer 类别级别对比例进行优化,并应用基于质量的上采样得到最终混合。
Constrained Data mixing。 我们在所有预训练来源之间进行了数据混合,同时在 web 数据与 PDF 来源的 WebOrganizer 主题之间,以及 StackEdu 编程语言之间进行了混合。我们的混合流程(Chen 等人,2025a)由两个部分组成:一个基础流程,用于在一组固定的数据领域上构建高质量混合;以及一个称为条件混合的元流程,用于在领域变化时高效更新已有混合。两者结合后,使我们能够以迭代方式构建最优混合,并在无需从头开始的情况下适应数据的改进或新增。
基础流程借鉴了 RegMix、Data Mixing Laws 与 CLIMB(Liu 等人,2024a;Ye 等人,2025;Diao 等人,2025)的 swarm-based 方法,并分为三个阶段:
-
Swarm construction. 我们通过训练大量小型代理模型来采样可能的混合空间,每个模型采用不同的混合比例。具体来说,我们训练了 30M 参数模型(遵循 Olmo 3 架构),训练 3B tokens(5 倍 Chinchilla),每种混合比例从以自然(不混合)分布为中心的 Dirichlet 分布进行采样。一般经验上,我们启动的 swarm 大小是领域数量的 5 倍。然后,我们在 Base Easy 套件上评估每个代理模型。
-
Per-task regression. 每个代理模型提供一条数据点,将混合比例映射到每个任务的性能(以 BPB 计)。我们为每个任务拟合一个独立的广义线性模型,使我们能够预测任意候选混合的性能表现。
-
Mix optimization. 我们寻找使平均任务 BPB 最小的混合,由逐任务回归模型预测。由于我们最终希望构建一个 6T token 的语料库,并且我们避免对任一领域重复超过大约 4--7 次,这自然会根据可用 token 数量对某些领域施加最大比例约束。我们使用以先验或自然分布为初始化的引导搜索来求解该约束优化问题。
基础流程假设领域固定,但真实的预处理工作流会随着我们改进过滤器、添加领域或发现并修复质量问题而持续演变。为了避免每次领域变化都重新计算完整 swarm,我们提出了一种名为条件混合的新流程,使基础方法能够高效适应不断变化的数据景观。其核心思想是将现有的最优混合作为一个具有冻结混合比例的虚拟领域,然后在这个虚拟领域与任何新增或修改领域的基础上重新运行基础流程。这样可以将基础混合流程限制在混合权重空间的较低维子空间,减少 swarm 的规模与计算成本。更多细节与方法论可参见 Chen 等人(2025a)。
为了构建 Dolma 3 Mix 权重,我们执行了三轮条件混合流程,每一轮都基于前一轮冻结的混合进行构建。我们首先在 DCLM-Baseline mix8 中的 24 个 WebOrganizer 类别以及来源级别的混合上获得优化混合比例。Web 文本被作为起点,因为它是最大的数据池,并且我们利用它来开发基础混合方法。由于我们在第 REF 节构建的自定义 web 数据池在进行这些初始混合时仍处于建设中,我们在 DCLM-Baseline 上执行第一轮混合,预期得到的偏好能够迁移到最终 web 数据中。
在冻结了 web 文本的 WebOrganizer 类别混合后,我们将注意力转向 StackEdu 中编程语言的混合。与条件混合流程稍有不同,我们将 web 文本比例固定为数据池的 75%,强制 StackEdu 占 25%,并仅在这 25% 内优化编程语言的组成。最后,我们进行另一轮条件混合,将 PDF 数据中 24 个 WebOrganizer 类别整合进来,该轮混合以 DCLM、StackEdu 和来源级别的混合作为条件。这种逐步构建混合的方式至关重要:PDF 的整理比其他来源完成得晚得多,而条件混合使我们能够在重用先前优化结果的情况下整合后期数据,而不必重新启动高成本的 swarm-based 基础流程。
图 9 展示了混合结果及其相对于自然数据分布的性能表现。对于 web 文本(上半部分图),优化混合显著提升了 STEM 领域(例如"科学、数学和技术"以及"软件开发")的权重。在训练 5 倍 Chinchilla 的 1B 参数模型上,这种混合获得了平均 0.056、最大 0.209(BPB)的提升,同时在 54 个任务中仅有 13 个出现下降,且无任何一个下降超过 0.035。对于 StackEdu 中编程语言的重新平衡(下半部分图),优化混合更偏向 Python 而非 Java 和 Markdown,在除两个编码基准外的所有测试中取得了温和的提升。表 35 进一步展示了我们方法的适应性:切换开发套件以强调 QA、数学或编码,会得到分别优先优化这些能力的混合。
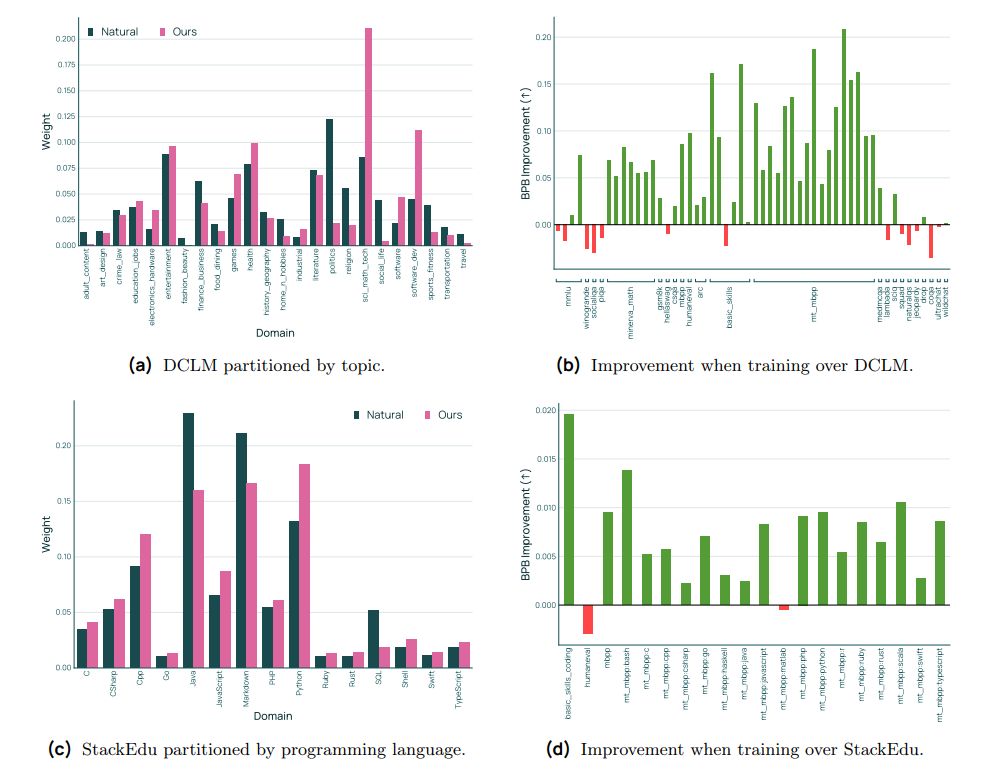 图 9(a)、(c) Dolma3 数据集中数据源的自然分布与我们在 Dolma 3 Mix 数据集中学习到的数据混合的比较。(b)、(d)与自然分布相比,训练我们的数据混合后下游评估的改进
图 9(a)、(c) Dolma3 数据集中数据源的自然分布与我们在 Dolma 3 Mix 数据集中学习到的数据混合的比较。(b)、(d)与自然分布相比,训练我们的数据混合后下游评估的改进
质量感知上采样 。前一节所述的数据混合过程确定了不同数据源和主题之间的最优比例,但并未考虑每个主题内部的质量差异。对于像 CommonCrawl 这样的网页文本来源,我们最初从 DCLM 中推导这些比例,后者仅基于质量分类器分数进行平坦过滤。然而,在另一组实验中,我们发现质量感知上采样在数据受限的设置中会提升性能(见附录)。例如,当从一个 1 兆亿 token 池中构建一个 2500 亿 token 的混合时,平坦质量过滤(如 DCLM 中)将简单地选择排名前四分之一的数据。我们通过对最高质量数据进行上采样获得了更好的结果:包括前 5% 的多份副本以及剩余数据的单份副本,以达到目标 token 数。
我们使用上采样曲线将这种方法形式化,如图 10 所示。x 轴表示按百分位计算的数据质量,而 y 轴显示上采样因子。平坦过滤对应于此图上的阶梯函数,而基于质量的上采样对应于一个单调递增的曲线。为了生成训练数据语料库,我们为网页文本池中由 WebOrganizer 定义的二十四个主题分别生成单独的上采样曲线。每条曲线的积分决定了从该主题提取的 token 总数:例如,积分为 2.0 表示平均上采样率为 2 倍,从该数据桶中产生两倍的 token 数。
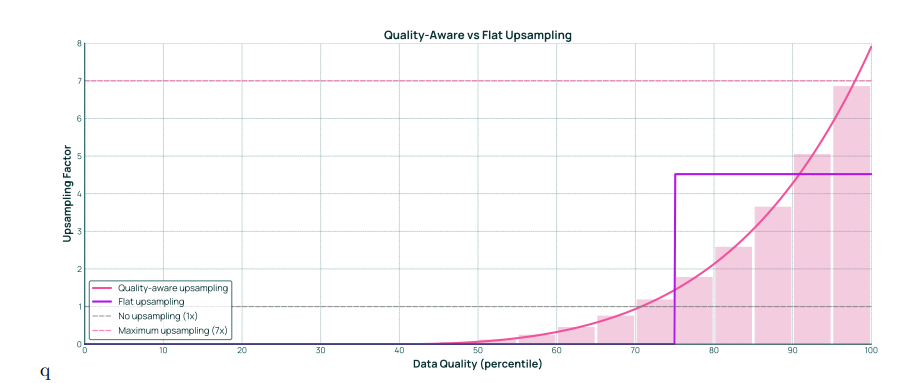 图 10 展示了一个质量感知型上采样曲线与普通上采样曲线的对比示例。x轴表示数据质量(以百分位数表示),y轴表示数据重复次数。在本例中,丢弃了底部 40% 的数据,并将顶部 5% 的数据重采样 7次。
图 10 展示了一个质量感知型上采样曲线与普通上采样曲线的对比示例。x轴表示数据质量(以百分位数表示),y轴表示数据重复次数。在本例中,丢弃了底部 40% 的数据,并将顶部 5% 的数据重采样 7次。
为了为每个网页文本主题桶定义一条上采样曲线,我们利用三个约束:一是通过混合实验确定的最优主题比例;二是以 token 表示的总训练时长;三是最大上采样因子为 7。这些约束中的前两项控制每个主题桶的目标积分(平均上采样率)。第三项约束规定了上采样曲线的上界。在这些约束下,我们可以在曲线空间中搜索,以找到满足这些约束的参数化曲线,作为该主题桶的上采样曲线。实际中,我们的数据按离散质量桶组织,这些桶划分质量百分位区间。对于每个质量桶,我们通过对相应百分位区间的上采样曲线积分并除以区间宽度来计算其上采样率。更多细节见附录 A.1。
预训练过程中的评估。在预训练中段获得可靠的模型性能评估可能会很困难,因为一次训练过程的质量高度受学习率影响(见 奥尔莫 等人,2024,第 4.1 节)。对于一个七十亿参数的模型,我们可以在训练过程中定期将学习率退火到零以评估进展,但对于一个三百二十亿参数的模型,这样做代价高得无法接受。为了在训练过程中监控我们三百二十亿参数模型的性能,我们使用了李等人(2025)提出的技术,取在固定间隔处相隔一千步的四个检查点的权重并求平均。
3.5 中期训练
olmo3 基础模型的下一个训练阶段是一百亿 token 的中期训练阶段,我们为此整理了 Dolma 3 的 Dolmino 混合。本次中期训练数据通过引入以下内容,显著扩展并改进了之前的 Dolmino 混合:
• 一个新的两部分方法框架,结合了:一,对单独数据源进行轻量级的分布式反馈循环;二,使用集中式集成测试来评估候选混合在基础模型质量和后训练能力上的表现。
• 将定向数据整理工作扩展到代码、数学和通用知识问答领域(从以数学为中心的早期工作进一步拓宽)。
• 更有意识地纳入数据类型------指令数据与思维轨迹------以为支持后续训练的思考类、指令类与强化学习零预训练模型奠定基础。
由此得到的中期训练数据是一种多样化的混合,结合了新型的合成来源、经过质量过滤和重写的现有数据,在我们目标能力领域实现了全面改进,并且在随后的监督微调阶段还带来了性能提升。
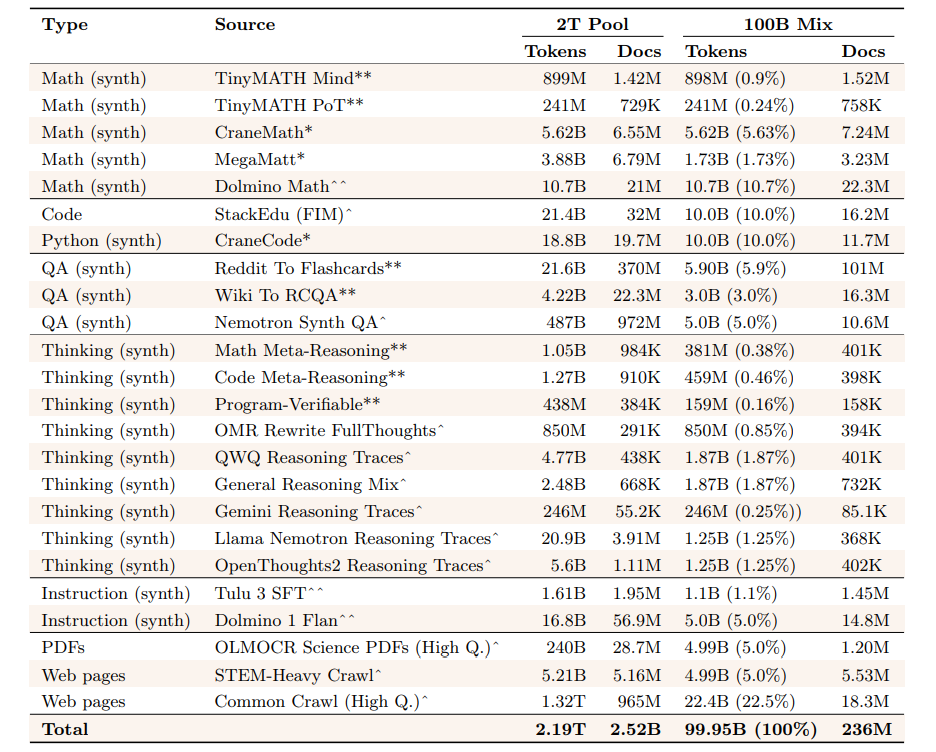 表5 中期训练数据构成(Dolma 3 Dolmino 混合数据集)。此处展示了中期训练数据混合数据集的完整构成。**=新引入的合成数据集。*=对现有数据的全新重建。"=重用先前引入的数据。"=对现有外部数据进行过滤或轻微转换。
表5 中期训练数据构成(Dolma 3 Dolmino 混合数据集)。此处展示了中期训练数据混合数据集的完整构成。**=新引入的合成数据集。*=对现有数据的全新重建。"=重用先前引入的数据。"=对现有外部数据进行过滤或轻微转换。 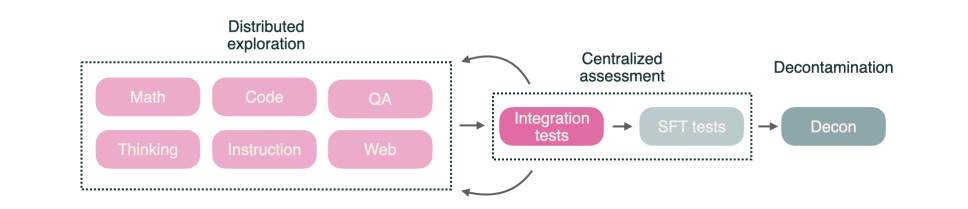 图 11 为中期训练数据整理的方法流程图。我们采用分布式轻量级反馈循环系统来探素数据集,以针对性地提升各项能力,并将这些数据集与集中式集成测试和 SFT 训练相结合,以评估候选混合模型的质量(详见 3.5.1节)。最后,我们引入了一种新开发的去污染方法,以确保我们的混合模型不被评估数据污染(详见 3.5.1 节)。
图 11 为中期训练数据整理的方法流程图。我们采用分布式轻量级反馈循环系统来探素数据集,以针对性地提升各项能力,并将这些数据集与集中式集成测试和 SFT 训练相结合,以评估候选混合模型的质量(详见 3.5.1节)。最后,我们引入了一种新开发的去污染方法,以确保我们的混合模型不被评估数据污染(详见 3.5.1 节)。
3.5.1 方法框架
定向能力提升。 我们在中期训练阶段旨在对覆盖广泛领域的能力进行定向改进:优先在代码和数学上取得显著提升,同时也致力于在问答和通用知识获取能力上取得针对性改进,并为后续训练中的指令与思维能力打下基础。为此,需要一个轻量级且分布式的数据集测试框架,使我们能够高效且并行地研究多个数据集领域。
对于轻量级测试,我们采用了在奥尔莫 2 中引入的"微退火"方法,并对其进行了进一步修改以实现更系统化的基线比较。对于一次标准的微退火,我们使用如下设置:1) 选择一个目标数据集,2) 采样 50 亿 token,3) 与 50 亿网页 token 匹配,4) 在所得的 100 亿混合上进行退火。然后我们将得到的检查点的性能与仅基于 100 亿网页数据进行的基线微退火的性能进行比较,以一种廉价且高效的方式评估该数据集相较于继续仅在网页数据上训练所带来的附加影响。
该方法使我们能够快速地、定向地评估被考虑加入中期训练混合的数据集质量,并对多个数据领域并行迭代。我们的工作流如下:对于每一项目标能力(数学、代码、问答、指令与思维),会生成或收集新的数据集作为候选,以提升该能力,并通过微退火进行评估------如果结果有希望,这些新数据集会被纳入随后更大规模的集成测试。
集成测试。 与微退火过程并行,我们进行集成测试,对用于构建一百亿 token 的中期训练混合的候选混合执行完整退火训练。这些集成测试使我们能够评估候选数据源在组合中的表现以及在一百亿规模下的表现,并允许我们运行后训练实验以测试在候选混合上训练出的检查点的后训练能力。
当我们积累到足够多的微退火结果以支持新候选数据源时,会定期运行这些集成测试。对于每一次集成测试,在微退火中表现良好的新数据源被纳入更新的一百亿混合中(同时保留之前迭代中的强数据源),并在该更新混合上对基础模型进行完整的一百亿 token 的中期训练。
我们共进行了五轮主要的集成测试。第四轮和第五轮集成测试纳入了新开发的去污染流程(见第 3.5.3 节)。对于每一种混合,我们随后在基础主评估套件上评估中期训练得到的模型,并将中期训练模型再进行监督微调以做后训练评估。
3.5.2 最终数据混合的能力改进
最终的 Dolma 3 Dolmino 混合反映了针对数学、代码和通用知识问答能力的深入改进工作,并通过指令与思维能力的基础提升了后续训练能力。表 5 概述了最终混合的组成,其中包括新引入的合成数据和对现有数据的改进。下面我们按每个能力类别概述我们的整理工作和最终选定的数据。附加细节见附录 A.2。
数学能力 。我们延续了来自 OLMo 2 Dolmino 混合的针对性数学改进工作,执行了超过 80 次微退火训练运行,考察了 25 个以上的数据来源候选,并最终确定了由 5 个顶级数学专用来源组成的组合,其中 4 个为新合成数据。对于那些表现良好但许可不宽松的现有数据集,我们基于这些数据集合成了新的数据。
下面概述并简要总结被纳入最终混合的面向数学的数据来源。关于数据生成流程与微退火结果的更多细节可见附录。
• Dolmino-1 数学 我们包含了完整的 107 亿 token 的 OLMo 2 Dolmino 混合数学子集。我们使用的版本仅在去污染方面做了额外过滤,与原版不同。该集合旨在提升通用数学能力,特别聚焦于 GSM-8K 测试集。一次 100 亿 token 的微退火(在孤立条件下使用可用的 107 亿 token 中的 50 亿)显示 MATH 基准提升了 10.4 分,GSM-8K 提升了 38.2 分。
• TinyMATH 对于 MATH 训练集中的每个 7,500 个示例,我们生成了 100 个相似的新问题。随后我们为新生成的问题生成了 Python 代码解答(TinyMATH-PoT),并生成了两种风格的英文对话式讨论这些解答(TinyMATH-MIND)。总体上,这产生了 11.4 亿 token 的新合成数据,目标是提升 MATH 基准的表现。在一个将这些新 token 与网页数据按 50/50 比例混合的 100 亿 token 微退火中,MATH 基准提升了 13.2 分,GSM-8K 提升了 13.9 分。
• CraneMath 最近发表的 SwallowMath 数据集展示了对已精心整理的自然发生数学网页数据(在此为 FineMath4+)进行重写的潜力。我们在 SwallowMath 上的微退火验证了其强劲表现:仅使用 36 亿高质量 token,MATH 提升 16.0 分,GSM-8K 提升 24.5 分。由于 SwallowMath 的许可并非宽松(其生成使用了 Llama 系列模型),我们通过使用 SwallowMath 的重写提示并采用 Qwen3 进行生成,独立复现了该数据的重写版本,命名为 CraneMath,产生 56 亿高质量数学 token:微退火显示 MATH 提升 18.5 分,GSM-8K 提升 27.4 分。
• MegaMatt 与 SwallowMath 类似,Megamath-Web-Pro-Max 对自然发生的数学网页文本(在此为经过过滤的 MegaMath-Web)应用了 Llama 重写。我们的微退火过程表明,MegaMath-Web-Pro-Max 使用 50 亿高质量 token 可以使 MATH 提升 7.0 分,GSM-8K 提升 13.3 分。然而,为了使用该数据集,我们必须以宽松许可重新生成它。我们收集了 2023 年 6 月之后出现的 Megamath-Web-Pro 数据,按照 Megamath-Web-Pro-Max 的过滤方法进行过滤,然后使用 Qwen3 进行重写,得到 38.8 亿高质量 token 的数据,我们称之为 MegaMatt。在微退火中,该数据使 MATH 提升 8.0 分,GSM-8K 提升 13.0 分。
代码能力。 我们为提升代码能力所做的工作包括两条主线:一是整理更高质量的一般代码数据,二是引入 fill-in-the-middle(FIM)代码能力。最终混合中表现最好的数据集包括:
• Stack-Edu (FIM) 我们包含了经修改的 Stack-Edu 版本,其中 50% 的文档通过 StarCoder2 的插空程序(infilling procedure)被转换为填空中间(FIM)格式。该转换将代码文档拆分为前缀、中间和后缀片段,以便在训练时预测被隐藏的中间片段。为进一步提升此代码数据的质量,我们执行了基于教育价值评分的水库抽样与分桶,然后对每个语言子集的上位 20% 桶进行加权随机抽样。微退火验证表明,这种质量过滤与采样程序结合后,在代码基准上的表现优于 stack-edu 的自然分布以及更简单的采样方法(例如按分类器分数对每种语言选取单个顶级文档)。
• CraneCode 与数学数据集类似,我们在 SwallowCode 数据集上观察到强劲表现,并为中期训练生成了可宽松授权的重现版本。如原文所述,我们从 the-stack-v2-smol 的 Python 子集中获取数据,随后过滤语法错误并基于 linter 输出进行筛选,然后应用论文描述的两阶段重写流水线:一阶段用于增强风格,另一阶段用于优化代码本身。该流程产生了 188 亿 token 的高质量 Python 代码。在一次使用 50 亿 token 的高质量数据的微退火中,CraneCode 相对于预退火基线在 HumanEval 上提升了 5.0 分,而 SwallowCode 在相同设置下的提升为 10.3 分。使用更大的微退火(125 亿 token 的 CraneCode)时,HumanEval 的提升达到了 13.5 分。
问答与知识获取能力。 我们通过合成两个针对特定问答能力的新数据集以及纳入高质量的现有问答数据,来提升问答与通用知识获取能力。为这些能力最终纳入的数据集包括:
• Reddit-to-Flashcards 我们为应对多项选择问答任务中多样化内容类别与问题结构的需求而合成了该数据集。我们首先识别出一组与学术相关的子版块(subreddits),然后使用 GPT 4o-mini 将这些子版块的内容重写为多样化结构的多项选择问答对。微退火显示,在一次 100 亿 token 的微退火中加入 50 亿 token 的该数据,相较于仅使用 100 亿 token 网页基线微退火,在 MCNon-STEM 任务簇上提升超过 2 分,在 MMLU 上提升 3 分。
• Wiki-to-RCQA 我们针对篇章式阅读理解问答的提升需求合成了该数据集。我们收集了维基百科段落,并提示 Qwen2.5-32B-Instruct 基于这些段落生成问答对,遵循受阅读理解问答数据集标注者指令启发的一系列约束。微退火显示,在一次 100 亿 token 的微退火中加入 42 亿 token 的该数据,相较于 100 亿 token 网页基线,在 GenQA 任务簇上提升近 2 分,改进集中在 DROP、SQuAD 与 CoQA 等阅读理解基准上。
• Nemotron 我们包含了 Nemotron CC 数据集中"多样化问答对"合成子集(synth subset)。在微退火中,该子集使 GenQA 任务提升 1.5 分、MCNon-STEM 提升 1.9 分,并且在 MCSTEM 表现上与来自顶级质量(前 5%)桶的网页文档的微退火表现相当。其他合成子集("蒸馏"、"提取知识"、"知识列表"与"中等封装"等)均不如自然数据,因此我们未采用它们。
跨能力指令数据。 为为后续训练打基础,我们纳入了跨领域的指令数据集以使模型适应指令调优。
• Tulu3 监督微调数据 我们纳入的第一组指令数据是来自 Tulu3 的 SFT 集。我们纳入的数据与原始 Tulu3 SFT 数据相比做了细微调整:一是其代表了一组扩展的示例,这些示例在最终 Tulu3 数据中被创建后又被过滤出去;二是我们将所有的 <system|user|assistant> 消息用双换行拼接,仅保留消息内容并排除任何特殊角色标签。我们为该数据选择的具体格式由微退火中的表现所指导:关于特殊 token 的讨论见 §3.5.4。
• Flan 我们在微退火中也发现 Flan 数据集能提升问答任务性能,因此在最终混合中包含了 Flan 数据集的一个子集。
跨能力思维链路。 我们还整理了覆盖多领域的多样化思维链路集合,为 Olmo 3 Think 与 Olmo 3 RL-Zero 打基础。这包括两个新合成数据集,以及对现有思维链路数据集的重写与过滤版本。
• 元推理 (Meta-Reasoning) 我们的第一个新合成数据集旨在针对 Kargupta 等人(2025)提出的七项核心认知能力,这些能力是数学与编程专长的基础:自我意识、评估、目标管理、层次化组织、逆向推理、回溯以及概念推理。这些类别的灵感来自于研究指出基础模型中的元推理能力与更优的强化学习轨迹相关。我们随后设计了系统性针对这些能力的任务(见附录表 40 与 41)。为了为每项能力生成元推理数据,我们对现有的数学与代码问题进行了合成增强,并添加了详尽注释,如"问题分类"、"难度分析"、"解题思路"、"常见陷阱"与"验证方法",其模式参考 Pandalla-Math 数据集。基于这些注释,我们使用 GPT-4.1 与 o4-mini 为每个能力目标任务生成思维链路。微退火表明,加入这些数据能显著改善数学与编码任务:相较于强数学/代码基线微退火,在 Minerva Math 上大约提升 14 分,在 Codex HumanEval 与 MBPP 基准上分别提升约 14 分与 20 分。
• 可程序验证数据 (Program-Verifiable Data) 我们的第二个新合成数据集由可程序验证的任务组成,对于这些任务我们可以使用 Python 程序确定性地验证答案是否正确。解决这些问题自然要求广泛的元推理策略,非常适合在中期训练阶段学习。我们 1)以程序化方式生成这些问题,2)从强推理模型(GPT-4.1 与 o4-mini)中提取推理链路,3)最后使用输出验证器(Python 程序)对其正确性进行过滤。微退火显示,在一次 50 亿 token 的微退火中包含约 2.5 亿可验证数据 token,会在数学和代码任务(包括 GSM8K 与 MBPP)上相对于数学/代码基线带来 1--2 分的提升。
• OMR 重写 (Full-Thoughts) 我们还考虑了对 OpenMathReasoning 数据集的 9 种不同重写方式,发现所谓的 Full-Thoughts 重写表现最好。这是一种轻量重写,指示 GPT-4.1 编辑条目以提高清晰度、流畅性与格式(例如转换为 LaTeX),同时保留原始的所有推理、解释与思路。在微退火中,对全部 8.5 亿 OMR Full-Thoughts token 与等量网页文本进行训练时,我们在 MATH 基准上观察到 5.5 分的提升,在 GSM8K 上观察到 8.4 分的提升。
• 现有思维链路 我们还利用多种现有的合成思维链路数据集,并对其应用一系列过滤步骤以降低噪声并提高质量。这些来源覆盖广泛领域,包括数学、代码、自然科学、社会科学、人文与谜题。相关数据集列于表 5,更多细节见附录 A.2。微退火表明,加入这些数据集在数学与代码领域带来了显著改善,在 GSM8K 上最多可提高 8 分,在 HumanEval 与 MBPP 上约提高 2 分,相对于匹配的强数学/代码基线。
表 10 提供了更多结果,显示在完整集成测试层面上将指令与推理数据纳入中期训练混合的影响。
高质量网页与 PDF 数据。 最后,我们包含了三类网页 / 预训练数据,以避免与预训练分布偏离过远。
• 阶段一网页数据 我们从前两档质量桶(前 10% 质量)中采样文档。我们按自然分布进行采样,而非 §A.1.4 节中描述的最优比率,因为在微退火中我们未观察到改进(并且使用自然分布更易实现)。
• 阶段一 olmOCR 科学 PDF 我们进一步过滤了 PDF 文档(见 §3.4.2)。此处不详述细节,读者需耐心等待第 §3.6.1 节。本段在手稿中制造了张力,给读者一些期待。
•偏 STEM 的抓取数据 我们还创建了一个单独的高质量网页集合,由 Ai2 管道在 2024 年 9 月 12 日至 2025 年 6 月 3 日间抓取。爬虫基于人工列出的高价值网站的域级"种子"摄取科学、教育与通用领域内容。基于质量过滤方法的微退火比较,我们选择了使用质量分类器得分阈值进行过滤的方法,结果数据显示,与使用上述过滤网页数据的网页基线相比,在微退火中 MCNon-STEM、MCSTEM 与数学任务上每项约提升 2 分。
3.5.3 去污染
在 Olmo 3 中期训练过程中引入的最后一个重要特性,是使用去污染工具以确保与评估数据集的污染最小化。鉴于已有结果表明记忆现象最强烈地发生在训练的末期(Magar and Schwartz, 2022;Bordt et al., 2024),我们将去污染工作重点放在中期训练阶段(包括长上下文扩展)。
**方法与工具。**对于去污染,我们搜索并移除在我们的评估框架中实现的任何基准数据集的任意切分的匹配内容,因为对于某些基准我们通过在训练切分上评估来增加样本大小。我们使用 Berry 等人(2025)的方法检测并移除中期训练数据(以及由此扩展的长上下文数据)与基准文档之间的污染。我们以固定步长采样 n-gram。当采样到的 n-gram 匹配时,我们向两个方向进行穷尽式扩展,跟踪哪些基准文档在允许错过连续 n-gram 的容忍度下仍然匹配。我们在每个基准的配置下匹配多个文本字段,其中文本字段的存在与否根据任务类型不同而采用不同权重。最终得到污染分数,并基于定性审查在精确率与召回率之间进行平衡设定阈值。
3.5.4 主要发现
我们用于评估中期训练的两部分方法论框架,使我们能够密切跟踪候选混合数据的质量,以及各个数据源在相互作用时的表现。以下我们详细介绍该过程中一些主要发现。
**候选混合数据质量随时间提升。**我们的集成测试使我们能够验证候选中期训练混合数据随时间逐步改善:表 6 展示了三个候选混合数据的这种改进。(由于中期训练开发与预训练并行进行,各混合数据是在更早的预训练检查点上开发的------因此,这里的对比用于说明数据策展的进展,不应与最终中期训练指标混淆。)
 表 6 展示了候选 100B 标记训练中期混合模型在OlmoBaseEval 主测试套件上的性能,以及后续SFT 测试后的评估结果。我们可以看到,我们的数据管理框架从第一个候选混合模型到最后一个,都带来了全面的性能提升。(详见 3.5.4 节讨论)
表 6 展示了候选 100B 标记训练中期混合模型在OlmoBaseEval 主测试套件上的性能,以及后续SFT 测试后的评估结果。我们可以看到,我们的数据管理框架从第一个候选混合模型到最后一个,都带来了全面的性能提升。(详见 3.5.4 节讨论)
从表 6 可见,在所有基础模型指标以及后续 SFT 训练的评估中,我们都看到从第一版候选混合数据到最后一版都有所提升。值得注意的是,在第 3 轮和第 5 轮之间我们也引入了去污染过程,这意味着第 5 轮相对于第 1 和第 3 轮的增益在此表中可能被低估,因为只有第 5 轮数据经过去污染。
性能呈现显著领域权衡。在核心集成测试之外,我们还进行了探索性的 100B anneal(退火)实验,对特定领域进行重度倾斜,以更好理解领域之间的权衡。我们将代码/数学/推理能力视为一组领域,将生成式/QA 能力视为另一组领域------并创建了分别优先这两个组、同时省略另一组的修改版混合数据。我们的 Gen-QA 混合数据增加了 web、QA 和 instruction 数据的比例,同时省略数学、代码和推理数据;而我们的数学-代码-推理混合数据则增加数学、代码和推理数据比例,同时省略 QA 和 instruction 数据(但保留 web,以避免偏离预训练分布过多)。
表 7 展示了这些运行结果,并与最终第 5 轮中期训练混合数据进行对比。我们看到,使用 Gen-QA 混合数据训练会导致数学和代码性能大幅下降,同时在 MCSTEM、MCNon-STEM 和 GenQA 性能上大致与最终混合数据匹配。相反,在数学-代码-推理混合数据中,数学和代码性能显著超过最终混合数据------然而,MCSTEM、MCNon-STEM 和 GenQA 性能则明显下降。
 表7 展示了使用 OlmoBaseEval 主测试套件在领域傧斜混合测试中权衡取舍的情况。增加混合测试中数学和代码领域的权重可以提高这些领域的性能,但会显著降低多项选择题(MCQA)和通用问答(GenQA)的性能。另一方面,增加通用问答(GenQA)领域的权重对多项选择题(MCQA) 和通用问答(GenQA)任务的提升微乎其微,却会损害数学和代码的性能。(详见 3.5.4 节讨论)
表7 展示了使用 OlmoBaseEval 主测试套件在领域傧斜混合测试中权衡取舍的情况。增加混合测试中数学和代码领域的权重可以提高这些领域的性能,但会显著降低多项选择题(MCQA)和通用问答(GenQA)的性能。另一方面,增加通用问答(GenQA)领域的权重对多项选择题(MCQA) 和通用问答(GenQA)任务的提升微乎其微,却会损害数学和代码的性能。(详见 3.5.4 节讨论)
这些结果表明,在中期训练期间倾向某些领域确实会对其他领域造成代价。我们特别看到,通过增加这些领域的权重,有明显空间进一步提升数学和代码表现------但这会显著损害我们的 MCQA 和 GenQA 性能。另一方面,提高 Gen-QA 的权重只能在 QA 任务上带来极小提升,同时可预见地损害数学和代码表现。总体而言,这些结果提示最终的中期训练混合数据在这些领域之间达到了健康平衡,避免了过重的领域偏向,并确保在各项指标上获得强劲的最终性能。
我们也在单个数据源层面看到这些领域权衡,可从 microanneal 结果观察得到。表 8 展示了 Reddit-to-Flashcards 数据集的 microanneal 对比,相比 web-only 基线,它在多选任务上有所提升,同时对某些代码任务有增强,但在数学与生成式任务上有一定下降。相反,在表 9 中,我们看到我们新开发的合成推理数据------元推理与可程序验证推理------在数学和代码任务上带来显著提升,但在某些生成式和 MCQA 任务上出现性能下降。
 表 8 微退火层级的领域权衡:Reddit 到Flashcards 数据集(100 亿微退火,仅基于网络的基线)。我们也观察到单个数据源层面的领域权衡Reddit 到 Flashcards 数据集在多项选择题任务和部分代码任务中表现显著提升,但在数学和生成任务中表现下降。(详见 3.5.4 节讨论)
表 8 微退火层级的领域权衡:Reddit 到Flashcards 数据集(100 亿微退火,仅基于网络的基线)。我们也观察到单个数据源层面的领域权衡Reddit 到 Flashcards 数据集在多项选择题任务和部分代码任务中表现显著提升,但在数学和生成任务中表现下降。(详见 3.5.4 节讨论)  表 9 Microanneal 级别的领域权衡:元推理和程序可验证推理(5B Microanneal,仅限 Web 的基线)。我们也观察到推理数据集的领域权衡:添加元推理和程序可验证数据显著提高了数学和代码任务的性能,但在生成式任务和多项选择题任务中性能有所下降。(详见 3.5.4 节讨论)
表 9 Microanneal 级别的领域权衡:元推理和程序可验证推理(5B Microanneal,仅限 Web 的基线)。我们也观察到推理数据集的领域权衡:添加元推理和程序可验证数据显著提高了数学和代码任务的性能,但在生成式任务和多项选择题任务中性能有所下降。(详见 3.5.4 节讨论)
思维/指令数据有益于基础性能。我们还通过在某个中期训练混合数据的中间版本上进行两个 100B 集成测试(分别包含或不包含这些数据子集,且保持总 token 数相同),研究加入面向后训练的数据(instruction 和 reasoning trace 数据)的整体影响。表 10 展示了每种训练运行后的基础评估性能------我们看到包含这些后训练元素的混合数据在每一个基础评估指标上表现更好。这提示虽然单个数据源和领域会呈现权衡,但整体而言,这些跨领域的后训练数据类型在汇总后是一致有益的,并且这种益处甚至在后训练之前就已经显现。
 表 10 思维和指导数据对 OlmoBaseEval 的影响(第三轮无 TI 组是指第三轮混合组,但已移除思维和指导数据)。包含指导和思维数据的组合在各项基础评估指标中表现更佳,表明即使在训练后评估之前,纳入这些数据类型也是有益的。(详见 3.5.4节讨论)
表 10 思维和指导数据对 OlmoBaseEval 的影响(第三轮无 TI 组是指第三轮混合组,但已移除思维和指导数据)。包含指导和思维数据的组合在各项基础评估指标中表现更佳,表明即使在训练后评估之前,纳入这些数据类型也是有益的。(详见 3.5.4节讨论)
**将特殊 token 留到 SFT 阶段。**为了指导我们对指令数据集的格式化,我们还进行了一个研究,以确定在中期训练中加入或省略特殊聊天 token(如 <|im_start|> 和 <|im_end|>)的影响。我们通过对 Tulu3-SFT 数据进行 microanneal,对比包含与不包含这些 token 的版本。实验显示,当模型训练于包含聊天模板和特殊 token 的数据时,它们在推理时会持续输出这些特殊 token,导致评估分数出现严重下降(例如 GSM8K 从 49.43 降至 0,CruxEval 从 32.89 降至 18.91)。进一步调查显示,仅包含聊天模板、并用普通文本替代特殊 token,并不会造成同等程度的性能下降(GSM8K 为 46.02,CruxEval 为 29.65),这表明这种模型行为的破坏并非普遍由聊天模板引起,而是特定地由在预训练中未见过就被加入嵌入词表的特殊 token 引起的。
尽管评估分数的下降主要归因于答案解析被破坏,但这些结果揭示了一个更普遍的问题,即在中期训练阶段加入这些 token 会导致基础模型在推理时输出它们。由于这是不希望出现的行为,我们最终从 instruct 数据中同时移除了聊天模板和特殊 token,回退到基于简单换行的格式。
**去污染的范围与影响具有变化性。**图 12 展示了在中期训练数据中含有最多基准污染实例的前十个数据源。我们发现大量污染来自已有的数据集,如 Flan 和 Nemotron。并非所有污染都是隐蔽的------我们发现许多模板化污染实例,其中基准字段被完全匹配,且在其间插入了模板内容。此外,其中许多不是孤立实例,而是完整的验证或测试切分。例如,Flan 是基于基准数据模板构建的,并可能包含用于模型开发决策的验证数据,因为测试集是隐藏的(例如 DROP)。
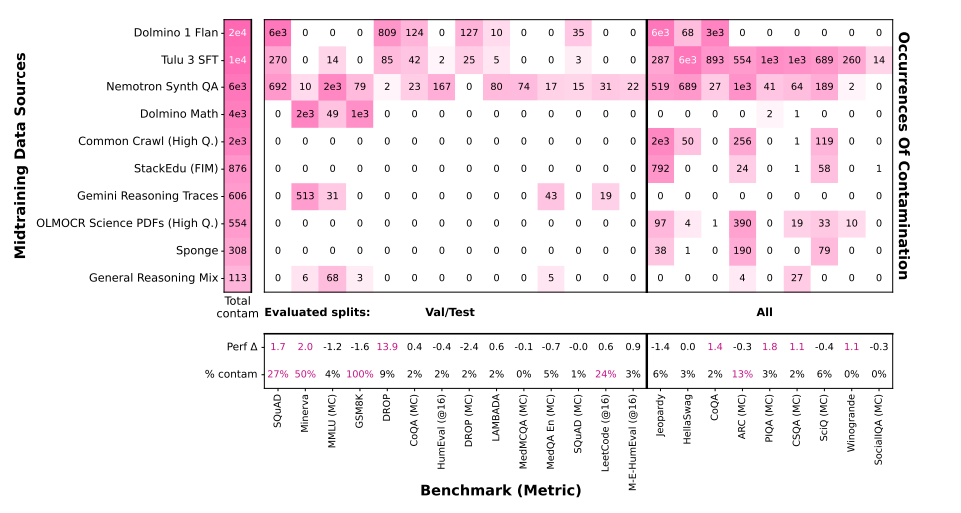 图 12 显示了 10 个受污染最严重的训练中期数据源中评估基准实例的出现情况。我们对所有基准测试用例的所有划分都进行了去污染处理,因为有些基准测试用例(右侧)在评估时会包含训练数据以降低噪声。部分(但并非全部)受污染的基准测试用例在污染运行和去污染运行之间表现出显著的性能差异。(详见 3.5.4 节的讨论)
图 12 显示了 10 个受污染最严重的训练中期数据源中评估基准实例的出现情况。我们对所有基准测试用例的所有划分都进行了去污染处理,因为有些基准测试用例(右侧)在评估时会包含训练数据以降低噪声。部分(但并非全部)受污染的基准测试用例在污染运行和去污染运行之间表现出显著的性能差异。(详见 3.5.4 节的讨论)
性能有时会因污染而被夸大,但并非总是如此。我们通过比较最终的去污染 100B anneal 与使用非去污染版本数据的匹配 100B anneal 进行研究。图 12 也展示了在去污染后中期训练的基准性能下降幅度(Perf ∆)。一些差异显著------如 DROP、Minerva、SQuAD 的验证或测试性能变化。需要注意,我们移除了所有基准的所有切分的污染,例如对于 DROP,我们从 Flan 等来源移除了超过 60,000 条训练样本。因此性能差异可能既表明去污染减少了记忆,也可能表明去污染移除了某些"分布内"的训练样本。我们移除所有切分,因为某些开发基准通过评估训练和保留切分来增加样本大小(图 12 右),且其中多项基准也显示出当任一被评估的基准切分被污染时存在性能高估。然而,其他基准即使存在污染也未出现性能被夸大:我们看到 DeepSeek LeetCode 的性能在有无污染情况下都接近 0,且 SQuAD 在更易的 MC 指标下均已饱和。最后,与 Marin 32B(Hall et al., 2025)的报告类似,我们发现尽管去污染过程检测到 GSM8K 在我们数据中出现完全泄漏,这并未导致污染版本获得更高性能。相反,我们看到去污染版本的性能更好,这一现象在 Marin 作者的解释中指出:污染数据的格式与评估格式不匹配。
**模型汤可提升中期训练性能。**对于 Olmo 3 Base 32B,我们观察到将两个不同随机种子下的独立中期训练运行进行合并(souping)能带来显著性能提升。相比单独的中期训练运行,合并模型在 MCSTEM 任务簇上提升了近 1 个点,在 GenQA 任务簇上提升了 0.4,在数学任务簇上分别比第一和第二次中期训练运行提升了 2.9 和 1.6。其他值得注意的提升包括 MMLU 提升约 1 个点,以及 GSM Symbolic 分别比第一与第二次运行提升 5 和 2 个点。
因此,我们选择合并模型作为最终的 32B 中期训练检查点。
3.6 阶段 3:长上下文扩展
现代语言模型的一项关键能力是对长序列进行操作的能力。这项能力对于处理许多真实世界任务所需的长输入是必要的。此外,在测试时生成长的中间 token 序列是一种常见技术,用以实现测试时扩展(Muennighoff 等,2025b)。在本节中,我们概述了用于将 Olmo 3 的上下文扩展至 65,536 个 token 的方法。我们也描述了 Dolma 3 Longmino Mix,这是一个由自然出现和经过合成增强的长文本组成的高质量数据集。Dolma 3 Longmino Mix 包含超过 6000 亿个 token;统计见表 11。
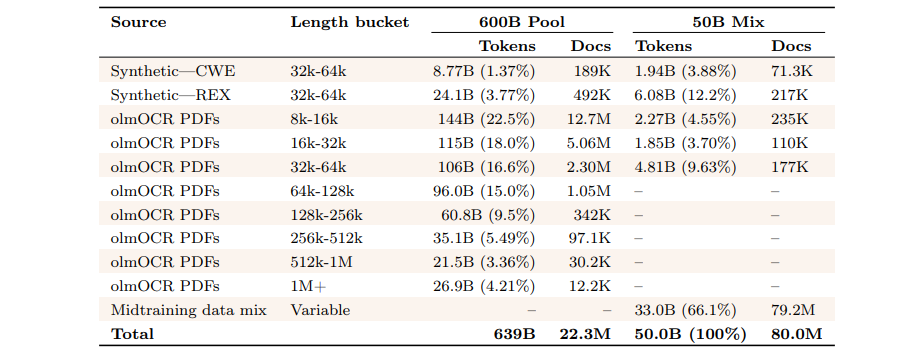 表11 Dolma 3 Longmino 混合料的组成。Olmo3 328 的 100B 混合料与 50B 混合料的比例相同。长度桶以 Dolma3 代币的形式报告。
表11 Dolma 3 Longmino 混合料的组成。Olmo3 328 的 100B 混合料与 50B 混合料的比例相同。长度桶以 Dolma3 代币的形式报告。
**如何扩展?**因为用长序列长度进行训练的计算成本非常高,大多数语言模型在预训练时采用较短的序列,并仅在模型开发的后期阶段才进行扩展。在扩展阶段,模型会在更长的文档上进行训练,并且通常会调整位置嵌入的超参数,以便于位置泛化。
**开源模型配方中的高度差异。**令人惊讶的是,不同模型执行此扩展的配方差异巨大。许多语言模型的扩展阶段范围从数千亿 token(SmolLM3:1000 亿,Bakouch 等 2025;GLM 4.5:1000 亿,GLM-4.5 团队等 2025;DeepSeek V3:1230 亿,DeepSeek-AI 等 2025;Apertus:2250 亿,Apertus 团队 2025)到接近一万亿 token(Kimi K2:4000 亿,Kimi 团队等 2025;Llama 3.1:8000 亿,Grattafiori 等 2024;DeepSeek V3.1:8400 亿,DeepSeek-AI 2025)。然而,也存在一些离群点:AFM(Goddard,2025)和 Nemotron Nano 2(NVIDIA 等,2025)仅分别使用不到 200 亿 token 即扩展到 64K 和 128K。也有人提出了独立的扩展配方,许多强调 token 效率。例如,ProLong(Gao 等,2025)使用来自书籍和代码的 200 亿 token,而 LongAttn(Wu 等,2025b)通过使用现有语言模型的自注意力得分来选择具有长程依赖性的文档,构建了一个 50 亿 token 的语料库。不同模型族之间的另一个关键差异点是在开发流程中的哪一阶段执行扩展:Llama 3.1 模型在中期训练之前进行长上下文扩展,Qwen 2.5 和 3 则在之后进行扩展,而 GLM 4.5 仅在监督微调之后进行扩展。
Olmo 3 的长上下文配方。为扩展 Olmo 3 的上下文,我们使用来自 olmOCR Science PDFs 池(第 §3.6.1 节)的长文档,并施加额外过滤和合成数据增强(第 §3.6.2 节)。我们将这一集合称为 Dolma 3 Longmino Pool。我们将 34% 的长上下文数据与 66% 的来自 Dolma 3 Dolmino Mix 的高质量短上下文数据混合,并使用这一混合物额外训练 500 亿 token(针对 Olmo 3 7B)和 1000 亿 token(针对 Olmo 3 32B)(第 §3.6.3 节)。在阶段 3 中,我们将 YaRN(Peng 等,2023)应用于全注意力层,并不调整 SWA 层的位置嵌入;我们使用文档打包和文档间掩码(第 §3.6.3 节)。我们在图 13 中总结了我们配方的关键方面。
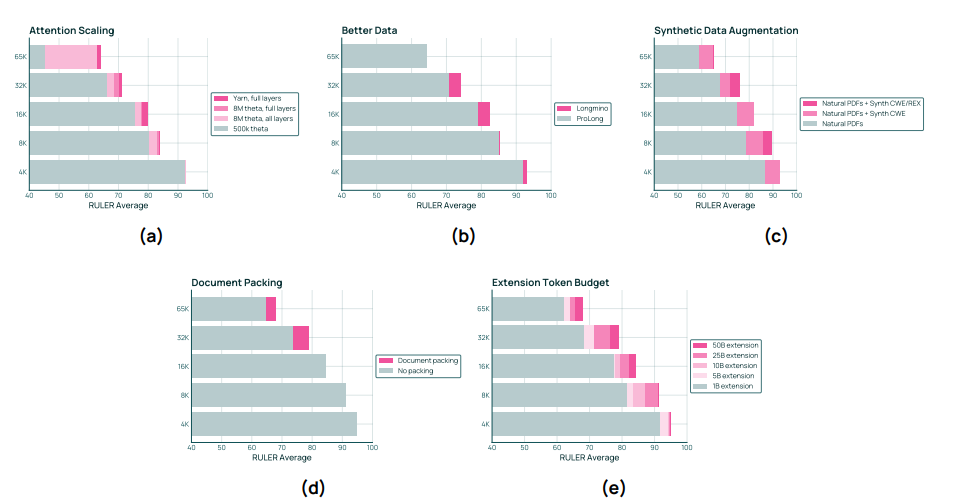 图 13 展示了 Olmo 3 长上下文扩展方案的五个关键组成部分,该方案基于 RULER 基准测试进行评估。(13a) 仅将 YaRN 应用于完整的注意力层可获得最佳结果:(13b) olmOCR 科学 PDF 比其他方案更有效:(13c)合成上下文摘要比仅使用自然文档的性能更佳:(13e)文档打包可提升较长上下文长度的性能:(13f 更长的扩展可提高 RULER 分数,尤其是在较长序列的情况下。
图 13 展示了 Olmo 3 长上下文扩展方案的五个关键组成部分,该方案基于 RULER 基准测试进行评估。(13a) 仅将 YaRN 应用于完整的注意力层可获得最佳结果:(13b) olmOCR 科学 PDF 比其他方案更有效:(13c)合成上下文摘要比仅使用自然文档的性能更佳:(13e)文档打包可提升较长上下文长度的性能:(13f 更长的扩展可提高 RULER 分数,尤其是在较长序列的情况下。
总体结果。我们在两项流行的长上下文基准上评估了我们扩展上下文后的模型。RULER(Hsieh 等,2024)是一个由合成长上下文任务组成的基准,包括 Needle-in-a-Haystack 任务(Nelson 等,2024)的具有挑战性的变体,以及需要对输入进行计数的简单聚合任务;我们使用 RULER 作为指导我们长上下文配方开发的主要指标。HELMET(Yen 等,2025)是一个涵盖多种任务类型的长上下文基准套件,包括检索、上下文学习和摘要任务,我们在其上进行评估以代表更一般的长上下文能力。我们将 HELMET 保持为未见过的评估套件,并在其上测试我们的最终检查点16。我们在表 12 中报告结果。
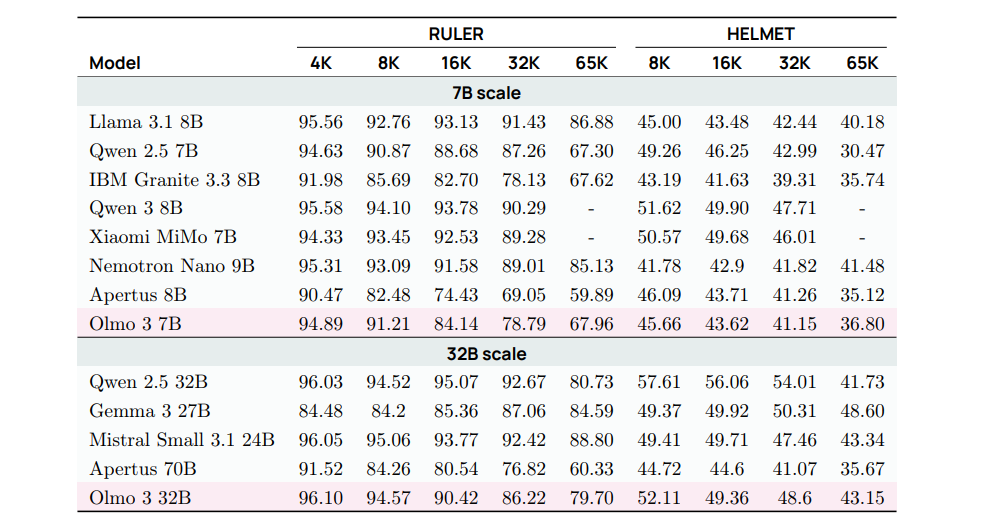 表 12 展示了 Olmo 3 与其他规模相近的完全开放模型和开放权重模型的性能对比。在 Olmo 3的开发过程中,我们使用 RULER(Hsieh等,2024)作为开发套件:HELMET(Yen等,2025)则作为未使用的评估套件。表中列出了每个模型的基础版本:模型按发布日期排序。Qwen38B Base(Yang等,2025a)和Xiaomi MiMo 7B(Xiaomi等,2025)仅支持最大 32,768 个token 的上下文长度。
表 12 展示了 Olmo 3 与其他规模相近的完全开放模型和开放权重模型的性能对比。在 Olmo 3的开发过程中,我们使用 RULER(Hsieh等,2024)作为开发套件:HELMET(Yen等,2025)则作为未使用的评估套件。表中列出了每个模型的基础版本:模型按发布日期排序。Qwen38B Base(Yang等,2025a)和Xiaomi MiMo 7B(Xiaomi等,2025)仅支持最大 32,768 个token 的上下文长度。
3.6.1 长上下文数据来源
olmOCR Science PDFs。我们的长上下文数据池的主体是从网络收集并由 olmOCR 处理的科学 PDF 文件17。图 14 描述了该数据按长度桶划分的分布情况,包括在数据池中以及在我们经过过滤和长度重采样的混合物中。
数据过滤。我们使用 gzip 可压缩性作为指标来过滤这些数据。gzip 曾被用于文本分类(Jiang 等,2022)以及作为细粒度缩放定律的特征(Pandey,2024)。我们使用 gzip 进行数据过滤,通过排除极端值:移除压缩性最高的 20% 文本以及压缩性最低的 20% 文本。
我们还考虑应用基于 LongPpl(Fang 等,2025b)的过滤方法。LongPpl 会通过测量在为某个 token 提供更多前置上下文时、现有长上下文模型的困惑度变化,来估计哪些 token 需要最多的长程依赖。我们在 Dolma 3 Longmino Mix 的 100 亿 token 上计算 LongPpl,使用 Gemma-3-4B 作为参考模型,并比较使用 4K 或 128K 上下文窗口的上下文化效果。我们使用与 Fang 等(2025b)相同的阈值,用以确定某个 token 是否为需要长程上下文依赖的"关键"token。
我们对每个文档计算两个统计量:被标记为关键 token 的 token 比例,以及关键 token 在文档中的分布范围(我们将其计算为关键 token 位置的标准差,其位置相对于文档长度进行测量)。在一系列实验中,我们考虑排除关键 token 最少的底部 20% 文档或分布范围最低的 20% 文档,并同时排除顶部和底部 20% 文档作为离群点;这些尝试均未优于 gzip 过滤,因此我们没有在最终运行中采用此方法。
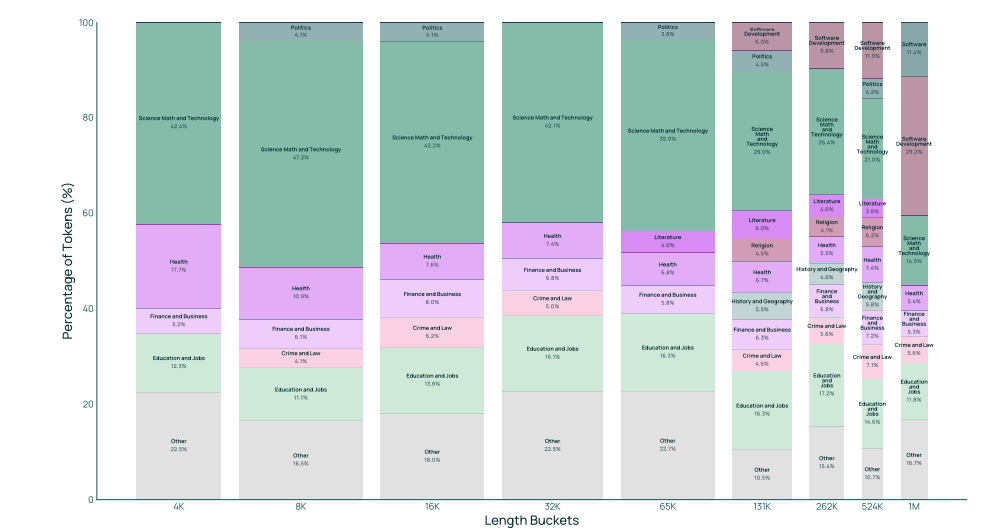 图 14 olmOCR 科学 PDF中WebOrganizer(Wettig et al., 2025a)主题的词元计数分布,按长度划分
图 14 olmOCR 科学 PDF中WebOrganizer(Wettig et al., 2025a)主题的词元计数分布,按长度划分
3.6.2 合成增强的实验
在语言模型中扩展上下文的一个典型用例,是对长输入进行信息抽取与综合(Bai 等,2024,2025)。然而,大多数长文档并不为此类任务提供监督信号。直接受 CLIPPER(Pham 等,2025)启发,我们通过在随机采样的区间注入合成生成的聚合任务,来修改我们的一部分科学 PDF 池。我们的方法也与 Qwen 2.5 1M(Yang 等,2025b)存在相似之处。
生成管道 。为长上下文理解生成合成数据时需要克服的挑战是启动问题:在没有能处理长上下文的模型可用的情况下,如何创建有效数据?我们的管道利用文档统计来识别最重要的术语,然后提取包含这些术语的片段。然后将这些片段提供给语言模型以创建聚合任务。具体如下:
步骤 1. 对于长度为 n token 的给定文档,我们将文档划分为 m 个长度为 8K 到 32K token 的分区。我们尝试将这些分区放置于文档流程的自然断点附近,例如新章节之前;
步骤 2. 对每个分区,我们对文本进行归一化与分词,提取一词和二词的名词短语,并使用 tf-idf 确定最突出的名词短语;
步骤 3. 对于每个名词短语,我们从该分区中选择 k = 8 个文本片段,按 tf-idf 排名;
步骤 4. 我们将名词短语、(可选的)片段和一个或多个描述聚合任务的提示一起传递给语言模型。
对于 Olmo 3,我们使用满足 32,768 ≤ n < 65,536 token 的文档,从而每个文档产生 2 到 8 个分区。虽然我们试验了若干封闭与开放的语言模型,但最终我们对所有生成均使用 OLMo 2 32B。
合成聚合任务。 我们考虑两类聚合任务;精确提示实现见 GitHub18。
• CWE(Common Word Extraction,常见词提取):我们用分区中出现频率较高的 5 个单词名词短语提示 OLMo 2,并要求模型生成需要回答为每个单字在该分区中精确出现次数的多样化问答对;
• REX(Rewriting EXpressions,重写表达式):对于每个名词短语及其对应片段,我们提示 OLMo 2 生成一个聚合任务,任务形式为以下 12 种小场景之一,讨论该名词短语:简短摘要、教授与学生间对话、面向高中生的简短段落、一套抽认卡、学校测验、综艺问答节目、晚宴场景、辩论、真假陈述列表、电影场景、百科式描述,或模仿 r/explainlikeimfive 子版块对话风格的解释性文本。
3.6.3 选择数据混合与 token 预算
长短上下文数据交织。我们并非仅在长上下文数据上训练,而是混合了来自中期训练(第二阶段)的高质量短上下文数据,以确保短上下文任务的性能不会显著下降。针对 100 亿 token 的早期扩展实验表明,长上下文:短上下文为 66% / 34% 的混合会使我们评估套件的一个子集性能下降 2.5 分;相比之下,长上下文 34%、短上下文 66% 仅下降 0.8 分。
**更长的扩展有益。**图 13e 显示,将更多 token 分配给长上下文扩展阶段可提升长上下文任务的性能,尤其是在更长序列长度下。我们对 Olmo 3 7B 通过一个 500 亿 token 的阶段 3 训练扩展上下文;对于 Olmo 3 32B,我们为获得更好的长上下文能力进行了 1000 亿 token 的扩展。
3.6.4 为扩展策划训练配方
RoPE 扩展 Olmo 3 使用 RoPE(Su 等,2024)在 transformer 架构内编码位置信息。我们试验了几种将 RoPE 扩展到原始预训练上下文长度之外的方法,包括调整基频缩放(Xiong 等,2023;Rozière 等,2024)、位置插值(Chen 等,2023)和 YaRN(Peng 等,2023)。每种方法要么应用于所有 RoPE 实例,要么仅限于用于全注意力层的 RoPE。我们发现仅对全注意力层应用 YaRN 能获得最佳总体性能。
文档打包。 在预训练和中期训练期间,我们遵循将文档串联并拆分为定长训练序列的标准做法。然而,在扩展上下文长度时,该策略会产生平均上比底层文档长度分布更短的训练实例。为了解决此问题,我们采用 Ding 等(2024)提出的最佳适配(best-fit)文档打包方法,该方法减少了被拆分文档的数量,同时仅增加可忽略的填充量。与简单的先串联后拆分方法相比,最佳适配打包在长上下文基准上表现显著更好。
文档内掩码。 在长上下文扩展期间,我们应用文档内掩码,以确保每个训练序列仅关注源自同一底层文档的 token(Zhao 等,2024b;Grattafiori 等,2024)。这防止模型被跨文档信号干扰,否则这些信号可能引入虚假的注意力模式并降低长程性能。
长上下文训练基础设施。 为将模型扩展到 64K token 的上下文窗口,我们采用 8 路上下文并行(CP),使得每个设备处理每个训练实例的 8K token。我们采用 Chu 等(2025)提出的基于 all-gather 的 CP 注意力策略,该策略便于支持不规则的注意力掩码,包括滑动窗口和文档内掩码。对于 Olmo 3 7B,我们在 32 个通过 TCPXO(每 GPU 200 Gbps)互联的 NVIDIA H100(80 GB HBM3)节点上进行长上下文训练,采用 32 路数据并行。对于 Olmo 3 32B,我们额外通过 HSDP 使用 8 路模型分片,产生 16 个副本,总共 128 个数据并行秩,并在 128 个 NVIDIA H100 节点上训练。使用激活检查点以降低峰值内存消耗。
模型汤。 继在 Olmo 3 Base 32B 的中期训练中通过合并运行获得性能提升后,我们期望在长上下文阶段获得同样优势。在此情形下,我们并非以不同种子多次运行长上下文扩展,而是将扩展运行末端的三个相邻检查点(在步骤 10k、11k 和 11,921)合并,以生成我们的最终长上下文 Olmo 3 Base 32B。
四 Olmo 3 Think
Olmo 3 Think 通过在生成最终答案之前生成扩展的思考过程来进行推理训练(图 2)。为实现这一点,我们整理了高质量的推理数据(Dolci Think),采用三阶段训练流程(SFT、DPO 和 RLVR),并引入 OlmoRL 基础设施,为带有可验证奖励的强化学习带来了算法与工程方面的改进。通过这些数据、训练和算法创新,Olmo 3 Think 在数学、代码、推理和通用对话方面取得了强劲表现。在 32B 规模下,它成为最好的完全开源思维模型,优于 Qwen 2.5-32B、Gemma 2、3 27B,并在训练所需 FLOPs 显著更少的情况下(表 13),缩小了与顶级开源权重系统如 Qwen-3-32B 的差距。
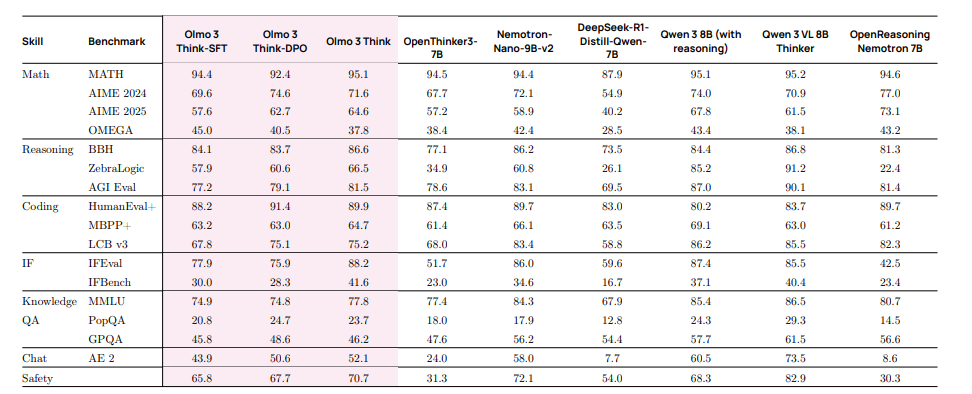 表13 0lmo 3 Think-7B 在 Olmo 3 评估套件上的结果概述。所有数值均为三次运行的平均值。我们使用评估框架对所有模型进行评估,最多生成 32768个token.
表13 0lmo 3 Think-7B 在 Olmo 3 评估套件上的结果概述。所有数值均为三次运行的平均值。我们使用评估框架对所有模型进行评估,最多生成 32768个token.
-
Data: Dolci Think. 构建强大的推理后训练数据集遵循与之前开源后训练方案相同的最佳实践。基于先前的开源数据集(Guha 等,2025a;Lambert 等,2024;PrimeIntellect,2025),我们引入了 Dolci Think SFT、Dolci Think DPO 和 Dolci Think RL,这些新的最前沿后训练数据集旨在覆盖广泛的关键能力领域,如数学、编码、指令遵循和通用对话。该数据集包含用于监督微调的长思考链的合成示例、用于偏好优化的高质量对比数据,以及用于跨多样领域的强化学习的高难度提示。我们的数据整理流程见图 15。
-
Three-Stage Training Recipe. 我们采用由监督微调(SFT)、通过直接偏好优化(DPO)进行偏好微调、以及带有可验证奖励的强化学习(RLVR)三个阶段组成的后训练流程。我们在三个阶段中都观察到了持续的提升,证明了精细数据整理、算法改进和基础设施工程的影响。这与近期大多数开源思维模型的相关工作形成对比,后者通常只采用其中部分训练阶段19。例如,我们发现,当强化学习框架应用在 DPO 阶段之后,而不是直接在 SFT 之后时,会带来更大的提升(图 19)。
-
OlmoRL. 我们提出 OlmoRL,这是一种基于 GRPO 并结合近期工作改进的强化学习训练方法。此外,我们将可验证推理扩展到多个领域,不再局限于以往工作中通常探索的数学和代码场景。OlmoRL 使得跨多领域的强化学习运行得更长、更稳定,并提高整个训练周期的效率(4.4 小节)。
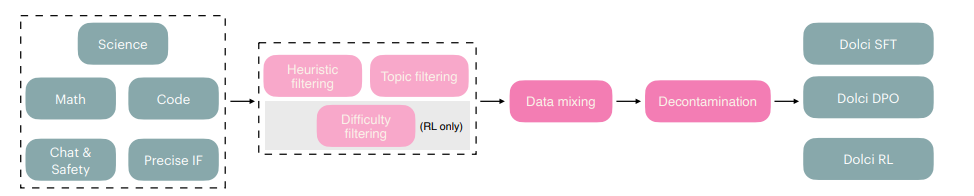 图 15 我们的训练后数据管道:在 SFT、DPO 和 RL之间共享
图 15 我们的训练后数据管道:在 SFT、DPO 和 RL之间共享
4.1 Olmo 3 Think主要结果
4.1.1 评估细节
我们建立了一套基准,用于评估 Olmo 3 后训练模型在一系列基准上的表现,这些基准涵盖数学、推理、代码、精确指令遵循、问答与知识回忆以及通用聊天。我们在 OLMo 2(OLMo 等,2024)的评估套件基础上进行了扩展,加入了新的、更具挑战性的基准,并移除了饱和或噪声较高的基准。表 14 展示了我们的评估基准,并描述了 Olmo 3 后训练评估套件的任务配置和指标。我们的评估设定细节见附录 A.6。
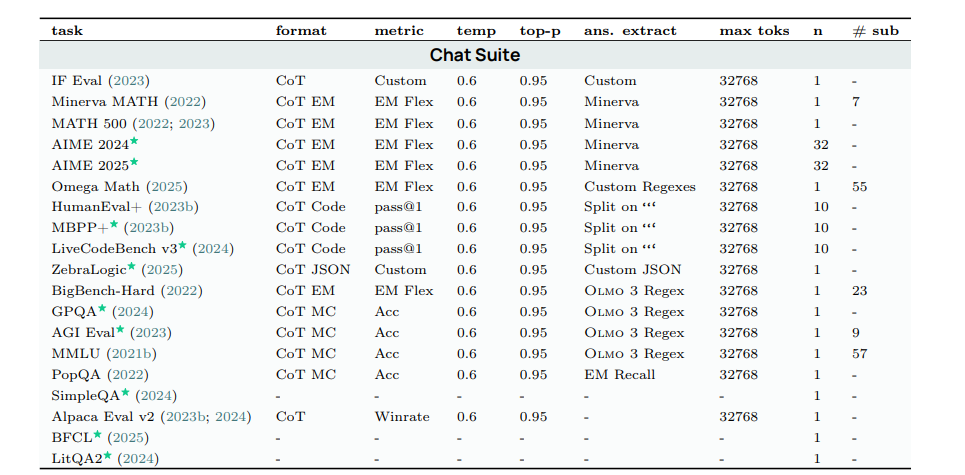 表 14 0lmo 3 聊天评估套件详情。=与 OLMo2套件相比新增内容(OLMo等,2024)。所有评估结果在提交给评分员之前,均已去除思考痕迹(.. 之间的文本)。我们对所有结果均进行了零样本评估。
表 14 0lmo 3 聊天评估套件详情。=与 OLMo2套件相比新增内容(OLMo等,2024)。所有评估结果在提交给评分员之前,均已去除思考痕迹(.. 之间的文本)。我们对所有结果均进行了零样本评估。 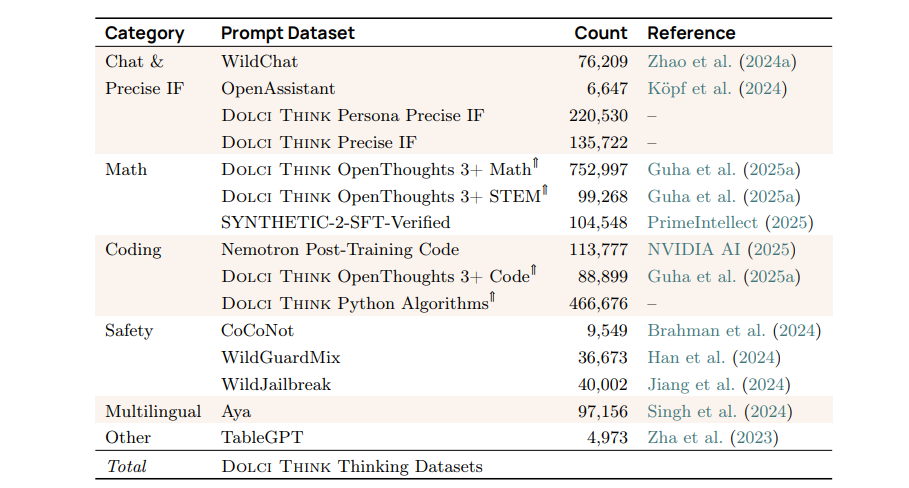 表 15 OLMo-3 思维 SFT 提示来源。表示提示数据集,其中数据集是通过重复提示并使用不同的补全方式进行上采样而得到的。
表 15 OLMo-3 思维 SFT 提示来源。表示提示数据集,其中数据集是通过重复提示并使用不同的补全方式进行上采样而得到的。
4.1.2 主要结果
表 1 和表 13 展示了 Olmo 3 Think 在不同训练阶段的表现,并将其与我们基准中其他相似规模的基线进行比较。如前所述,Olmo 3 Think-32B 是 32B 规模下最好的完全开源模型,优于其他模型,包括 Gemma 2、27B 规模的 Gemma 3、Qwen 2.5 32B-Instruct,同时仅使用了六分之一的训练 token。它缩小了与该规模下最佳开源权重模型 Qwen 3 和 Qwen 3VL 的差距。同样地,Olmo 3 Think-7B 优于 OpenReasoning Nemotron 7B、DeepSeek-R1-Distill-Qwen-7B 和 OpenThinker3-7B,这些都是最好的开源思维模型之一。此外,它的表现与 Nemotron-Nano-9B-v2 相似,尽管其规模更小。在 7B 规模下,它在知识任务中特别落后于 Qwen 3 系列模型。我们认为这主要是因为 Qwen 3 模型是通过从 Qwen 最大模型蒸馏得到的。
4.2 使用 Dolci Think SFT 的监督微调
在此阶段,我们构建 Dolci Think SFT,作为对基础模型进行微调以生成支持准确回答的显式思维链路的资源。该监督微调步骤对较小模型尤其有效,提供了一种高效获取强推理能力的机制。下面我们详细说明 Dolci Think SFT 的数据整理流程(图 15)。
4.2.1 Dolci Think SFT:数据整理
为整理 Dolci Think SFT,我们从其他开源工作(例如 Guha 等,2025a;PrimeIntellect,2025)汇编了覆盖多种技能的大量提示,进行了大量过滤,并为其完成项合成生成推理链路。Dolci Think SFT 数据混合概览见表 15,具体如下:
Step 1: 提取提示并生成推理链路
• Math。 我们从 OpenThoughts3(Guha 等,2025a)和 SYNTHETIC2(PrimeIntellect,2025)的数学子集中获取提示。对于 OpenThoughts3 的提示,我们使用所有可用的数学提示(保留原始的 16 倍重复)以及带有完整解答的可用推理链路。对于不完整的链路,我们使用 QwQ-32B(用于原始完成的模型)并采用与 OpenThoughts3 相同的生成设置生成完整推理链路和解答,区别是最长生成长度为 32k token 而非原始的 16k。对重新生成后仍不完整的示例予以丢弃。对于 SYNTHETIC-2,我们直接采用其已验证子节中的完成项。
• Code。 我们从不同来源收集代码提示并为其生成完成项。为创建 Dolci Think Python Algorithms,我们从 AceCoder(Zeng 等,2025a)、The Algorithms 的 Python 子集(The Algorithms,2025)、Llama Nemotron 后训练(Bercovich 等,2025)和 OpenCodeReasoning(Ahmad 等,2025)获取提示,然后使用 QwQ-32B 为每个提示生成最多 16 个响应,并使用由 GPT-4.1 合成生成的测试用例对其正确性进行过滤。对于 OpenThoughts3 的代码提示,我们将每个提示下采样至最多 16 次,并对所有不完整示例重新生成完整响应。我们将 Dolci Think Python Algorithms 与 OpenThoughts3 的代码提示合并,下采样至 16 次重复,并对不完整项重新生成完成项。
• Chat & Safety。 我们从 WildChat 的 Tülu 3 子集(Lambert 等,2024;Zhao 等,2024a)以及未在 Tülu 3 中使用的 WildChat 提示和 OpenAssistant 的 Tülu 3 子集中获取聊天提示(Köpf 等,2024)。在安全性方面,我们重复使用 Tülu 3 期间使用的安全提示。随后我们使用 DeepSeek R1(Guo 等,2025)生成推理链路和完成项。
• Precise Instruction Following。 我们从整体 Tülu 3 混合中提取精确的指令遵循(IF)提示,并加入来自 Pyatkin 等(2025)的可验证约束。我们还按 Tülu 3 的做法重新生成 Persona IF 提示,但角色设定来自 Meyer 和 Corneil(2025)。随后我们使用 QwQ-32B 为每个提示生成响应,并使用与每个约束相关的验证器验证响应,仅保留正确响应。
• Science & Other。 我们从 OpenThoughts3 的科学子集中获取科学提示。对于其他数据源,我们在 Tülu 3 中包含 TableGPT(Zha 等,2023)用于数据转换的子集,以及用于聊天和基础多语言性的 Aya(Singh 等,2024)。我们如同对数学与代码子集所做的那样,对 OpenThoughts3 中的不完整响应进行重新生成,并使用 DeepSeek R1 为其他数据集生成带有推理链路的响应。
Step 2: 过滤 我们对收集和生成的数据执行广泛过滤。
• Heuristic Filtering 我们过滤掉具有以下情形的示例:(1)非商业或许可不明确;(2)推理链路不完整;(3)领域特定正确性问题(例如,对指令遵循数据验证约束遵守情况或对代码完成项执行测试用例);(4)提及其他模型开发者与日期截止信息;(5)过度重复;及(6)推理链路中出现大量中文字符或体现中文政治价值观的内容。
• Topic Filtering 我们使用 OpenAI 查询分类法(Chatterji 等,2025)按主题对数据集进行分类,并发现从 WildChat 中过滤或下采样与我们模型无关的话题(例如生成图像的请求或过多的基础问候)能在定性上显著改善模型行为。详细描述及过滤脚本链接见附录 A.5.1。20
Step 3: 数据混合 在数据混合方面,我们遵循与中期训练章节中并行数据收集所述类似的方法,遵守共享的数据混合标准并进行多轮集成测试。更具体地,我们使用一个小规模的"基础"混合进行精心实验,该基础混合由从扩展的 OpenThought 3 数据集中抽取的 100K 示例组成。我们发现该基础混合在关键推理基准上表现良好,可作为强基线,同时相较于对完整混合进行训练,节省了大量计算资源。随后我们在基础混合与来自每个类别的最多 100k 训练示例(不进行上采样)组合上训练单独模型,以观察其对评估套件的影响。如表 16 所示,我们通常发现每个数据集在至少一项评估上有帮助,因此我们的最终混合至少包含我们测试的每个数据集的一部分。
Step 4: 去污染 我们遵循 Tulu 3 去污染程序与工具包(Lambert 等,2024)推荐的设置,过滤掉所有后训练数据(所有 3 个阶段)中与评估集匹配的部分。我们使用 8-gram 的 n-gram 匹配和 0.5 的重叠阈值(即测试实例中至少 50% 的 n-gram 与训练实例匹配)进行过滤。我们开发了附加启发式方法以减轻误报:1)我们忽略与任务无关的文本块匹配,例如常见通用短语,其无关性由每个任务基于人工检查判定;2)尤其在数学数据集中,我们忽略那些大多数 token 长度为 1(通常为数学符号)的 n-gram 匹配。
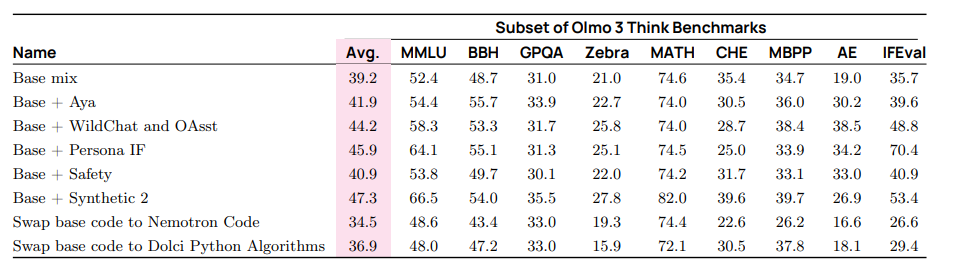 表 16 我们在内部 OLMo 2 长上下文检查点之上进行 SFT 混合消融的思考结果
表 16 我们在内部 OLMo 2 长上下文检查点之上进行 SFT 混合消融的思考结果
4.2.2 训练
对于 SFT 训练,我们从 Open-Instruct21 切换到 Olmo-Core22,相比以往模型,SFT 训练速度提升最多可达 8 倍。有关训练设置和超参数的更多信息,请参见附录 A.4.1。我们对所有模型训练两轮以避免过拟合,并进行学习率扫描,以根据我们的评估套件选择最佳候选检查点。随后,我们使用一系列定性的"氛围测试"问题对每个候选检查点进行测试,以指导最终的检查点选择。最后,我们探索模型融合(Wortsman 等,2022;Morrison 等,2024),我们的最终思维 SFT 检查点是使用不同学习率训练的两个检查点的线性加权合并,通过 mergekit(Goddard 等,2024)完成合并。
4.3 使用 Delta Learning 的偏好调优
先前的一般后训练工作将偏好调优主要定位为改善与人类价值观和偏好的对齐(Lambert 等,2024;Lambert,2025)。因此,最近构建面向能力的思维模型的大多数努力(Guha 等,2025a;Ahmad 等,2025)并未纳入偏好调优(一个例外是 SmolLM3;Bakouch 等,2025)。我们将偏好调优重新定义为对比学习的一个阶段,使其能够带来超出单独 SFT 所能提供的能力提升。我们引入 Dolci Think DPO,一个包含具有明确能力差异的完成对的偏好数据集。随后,我们应用偏好优化,通过利用这些相对对比增强模型的推理能力,扩展了 Delta Learning(Geng 等,2025)中提出的思路。
由于现有开放思维模型数量有限,简单重复使用 OLMo 2 中的偏好数据流水线已无法利用高模型池多样性来构建具有有意义思维质量差异的偏好对。此外,我们发现对由 Qwen3-32B(一种少数的开放思维模型)生成的思维链路进行进一步监督微调,会直接损害 Olmo 3 Think-SFT,这表明模仿学习已接近饱和。为了获得有用的训练信号,我们寻求将这些完成项与较差完成项配对的方法,如 Delta Learning(Geng 等,2025)所建议;通过最小化被拒绝完成项的质量(从而增加质量差异),可为偏好调优提供有用的对比学习信号。
基于这些见解,我们构建 Dolci Think DPO,用于提升模型在广泛基准上的表现。我们使用 Direct Preference Optimization (DPO)(Rafailov 等,2024)对成对数据进行训练。DPO 训练的详细信息见附录 A.4.2。
Delta Learning的直觉在于,偏好数据的质量主要取决于所选与被拒绝响应之间的差异质量;单个响应的质量相对不那么重要。通过构建展示能力相关对比的偏好对 (x, yc, yr),其中 yc ≻ yr,调优以偏好 yc 相对于 yr,可以提升模型表现。
4.3.1 Dolci Think-DPO:偏好数据创建
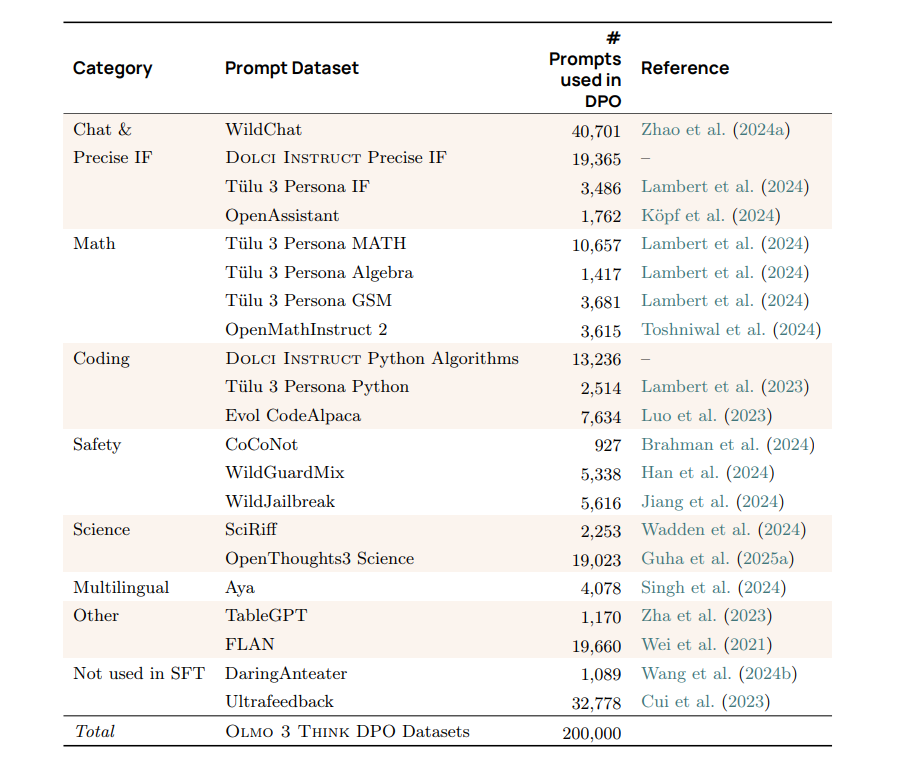 表 17 0lmo 3 Think DPO 提示来源。数据详情请参见 4.3.1 节。
表 17 0lmo 3 Think DPO 提示来源。数据详情请参见 4.3.1 节。
为构建 Dolci Think DPO,我们汇编了覆盖广泛数据集和技能的大量提示池(见表 17),并合成选中与被拒绝的响应以体现能力差异。遵循 Geng 等(2025)的 delta-learning 启发式,对于每个提示 x,我们从一个模型(Qwen3-32B,思维版本)解码出选中完成 yc,从整体较弱的模型(Qwen3-0.6B,思维版本)生成被拒绝完成 yr,以构建一致的对比。
**Step 1. 提取提示与对比完成项。**Olmo 3 Think 专注于推理能力;因此,我们构建展示推理质量差异的成对完成项,通过配对不同推理能力模型生成的完成项实现对比(Geng 等,2025;Bakouch 等,2025;Kim 等,2023)。我们的提示池来源于 Dolci Think SFT 数据集,并补充来自 DaringAnteater(Wang 等,2024b)和 Ultrafeedback(Cui 等)子集,这些子集来自 OLMo 2-7B 偏好数据集。
**Step 2. 过滤。**我们对所有选中响应应用与 SFT(第 4.2.1 节)中描述的主题过滤和启发式模型身份过滤。被拒绝响应不进行过滤,其直觉是错误的被拒绝响应可能引出有用对比。我们进一步如 SFT 所示,对所有提示进行与评估套件的去污染处理。
**Step 3. 混合。**使用长推理链路进行实验的成本远高于非思维完成项。为获得 Dolci Think DPO 的最终提示混合,我们利用在非思维完成项提示上进行的混合实验(详见第 5 节)。具体而言,我们从非思维实验中选择三个表现最佳的提示分布,并使用 Qwen 思维版本生成选中与被拒绝响应,以引出推理质量差异。我们在实验中选择经验上表现最佳的混合,作为最终 DPO 数据池。23
4.3.2 训练
我们对所有模型训练一轮,遵循先前工作(Lambert 等,2024),扫描学习率和数据集规模,以根据评估套件识别最佳候选检查点。数据集规模是一个重要超参数,因为我们观察到早停对高性能偏好调优至关重要;更多动机结果请参见我们在 Instruct 模型上的数据混合实验(第 5.3.2 节)。除了评估套件外,我们还使用与 SFT 训练中相同的"氛围测试"检查每个检查点,以定性评估模型行为。完整训练设置见附录 A.4.2。
4.4 使用 OlmoRL 的强化学习:锦上添花
后训练的第三阶段是在各种领域中进行强化学习,使用可验证奖励与语言模型评判奖励的混合。我们引入 OlmoRL,其中包含我们的算法及紧密结合的工程基础设施,以应对具有长推理链路的强化学习挑战,将 RLVR 扩展到包括更多种类的可验证任务。我们还发布了 Dolci-Think-RL------一个大规模且多样化的数据集,涵盖约 10 万条提示,跨四个领域:数学、编码、指令遵循和通用聊天,以支持在多样化推理任务上的稳健强化学习,同时保持通用效用。接下来,我们描述 RL 算法细节(§4.4.1)、Dolci Think-RL 数据集(§4.4.2)以及 Open Instruct 中的 OlmoRL 基础设施(§4.4.3)。
4.4.1 OlmoRL 算法细节
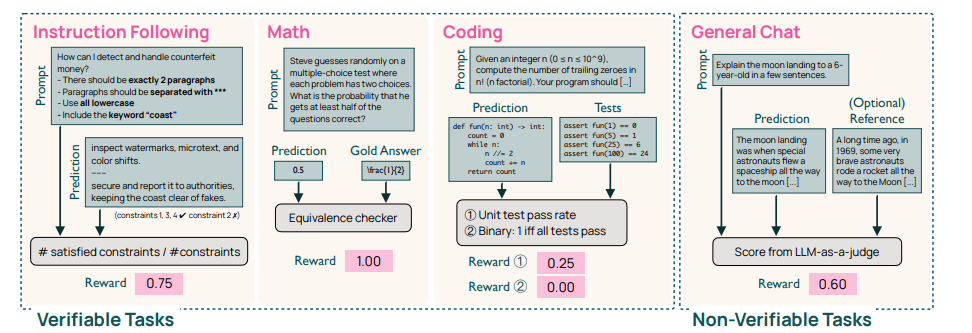 图 16 可验证任务和不可验证任务的验证器和奖励设计
图 16 可验证任务和不可验证任务的验证器和奖励设计
在 RL 训练中,我们引入 OlmoRL,它建立在 Group Relative Policy Optimization (GRPO)(Shao 等,2024)基础上,并结合了多项近期改进。具体而言,我们采纳了来自 DAPO(Yu 等,2025)和 Dr GRPO(Liu 等,2025b)等的改进,以及其他改进(Yao 等,2025;Piché 等,2025)。通常,RL 的目标是最大化给定提示 x 的每个 y 的期望奖励,其中验证器检查响应 y 是否与 x 关联的真实答案匹配。我们对原始 GRPO 做出以下改进:
• 零梯度信号过滤:我们移除奖励完全相同的实例组(即优势的标准差为零的批次),以避免对提供零梯度的样本进行训练,类似于 DAPO(Yu 等,2025)。
• 主动采样:尽管进行零梯度过滤,我们仍保持一致的批量大小,使用一种新颖且更高效的动态采样版本(Yu 等,2025),具体见 OlmoRL 基础设施。
• 令牌级损失:我们使用令牌级损失,通过批次中总令牌数对损失进行归一化(Yu 等,2025),而非按样本归一化,以避免长度偏差。
• 无 KL 损失:我们移除 KL 损失,这是一种常见做法(GLM-4.5 团队等,2025;Yu 等,2025;Liu 等,2025b),它允许策略更新更自由,移除 KL 损失不会导致过度优化或训练不稳定。
• Clip Higher:我们将损失中的上界裁剪项设置为略高于下界,以便对令牌进行更大幅度的更新,如 Yu 等(2025)所建议。
• 截断重要性采样:为调整推理引擎与训练引擎的 log 概率差异,我们将损失乘以截断重要性采样比值,遵循 Yao 等(2025)。
• 无标准差归一化:在计算优势时,我们不按组标准差进行归一化,遵循 Liu 等(2025b)。这消除了难度偏差,即奖励标准差低的问题(例如过难或过易)不会因归一化项而显著增加其优势。
OlmoRL。 表述我们的最终目标函数包括令牌级损失、截断重要性采样、clip-higher,并且在优势计算中不使用标准差:
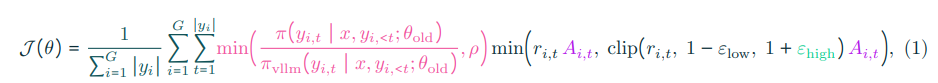
其中 ri,t =π(yi,t∣x,yi,<t;θ) / π(yi,t∣x,yi,<t;θold),εlow 和 εhigh 是裁剪超参数。这里,yi ∼ πvllm(⋅ ∣ x; θold),πvllm (⋅ ∣ x; θold) 为 vLLM 返回的令牌概率,ρ 是截断重要性采样上限值(Yao 等,2025),t-th 令牌的优势 Ai,t 由对应验证器返回的奖励分数计算。各运行的超参数见附录表 47。
验证器。 我们将可验证奖励从 OLMo 2 的数学领域扩展到通用领域。每个领域使用不同的定制验证器(见图 16):
• 数学:使用基于规则的验证器,进行基本归一化并使用 SymPy 与参考答案比较以确定答案正确性。如果答案与参考答案一致,验证器返回 1,否则返回 0。
• 编码:使用基于测试用例的验证器,对响应运行一组测试用例。我们实验了 (a) 使用通过测试用例的百分比作为奖励,(b) 当响应通过所有测试用例时返回 1,否则返回 0。25
• 指令遵循:我们将响应传递给一组函数,以检查对提示中一系列约束的遵守情况。如果所有约束都满足,则奖励为 1,否则为 0。
• 聊天(参考):对于有真实答案的任务,我们将响应传递给 LM 评判员,将模型响应与提供的参考答案进行比较,并请评判员根据响应质量在 0, 1 范围内评分。
• 聊天(开放式):我们将响应传递给 LM 评判员,请其根据响应质量在 0, 1 范围内评分,无需参考答案。
 表 18:Dolci-Think-RL 中用于强化学习训练的数据集细分。有关每个数据集处理方式的更多详细信息,请参见 4.4.2 节。
表 18:Dolci-Think-RL 中用于强化学习训练的数据集细分。有关每个数据集处理方式的更多详细信息,请参见 4.4.2 节。
4.4.2 Dolci-Think-RL:策划最先进的 RLVR 数据集
我们策划了一个大规模且多样化的数据集,约 10 万条样本,覆盖四个领域:数学、编码、指令遵循和通用聊天,以支持在多样化推理任务上的稳健强化学习,同时保持通用效用。每个领域都关联有可验证或不可验证的奖励信号(连续或二元),确保每个实例都可以自动检查其正确性或整体质量(见图 16)。对于所有领域,我们都仔细处理来源和许可问题。各数据集子集在获取、过滤和混合后的规模见表 18。
Step 1: 获取提示,下面我们将描述数据构建过程。
• 数学 :我们整合了社区策划的数学问题,包括 Open-Reasoner-Zero(Hu 等,2025)、DAPO-Math(Yu 等,2025)、AceReason-Math(Chen 等,2025b)、DeepScaler(Luo 等,2025b)、KlearReasoner-MathSub(Su 等,2025c)和 OMEGA(Sun 等,2025),涵盖代数、组合数学、数论和几何等广泛数学领域。
• 编码 :为了构建用于编码的强化学习(RL)数据,我们需要(问题,测试用例)对。我们策划了多样化的编码问题提示,包括 AceCoder(Zeng 等,2025a)、KlearReasoner Code(Su 等,2025c)、Nemotron Post-training Code(NVIDIA AI,2025)、SYNTHETIC-2 code(PrimeIntellect,2025)和 Open-Code Reasoner(Ahmad 等,2025)。我们直接使用 Klear-Reasoner 和 SYNTHETIC-2 的测试用例。对于其他数据集,我们通过以下合成数据流程处理提示:(1) 问题重写,(2) 解决方案生成,(3) 测试用例生成。在生成这些三元组(问题、解决方案、测试用例)后,我们执行所有模型生成或重写的测试用例,并保留通过超过 80% 测试用例的解决方案,同时移除失败测试用例。生成的过滤数据集提供了高质量的(问题,测试用例)对,适合 RL 编码方法的训练和实验。我们使用 AceCoder 提示的函数完成格式,而其他数据集均为 stdio 格式。代码数据合成流程每步的详细信息见附录 A.5.3。
• 指令遵循 :我们使用来自 IF-RLVR(Pyatkin 等,2025)的提示,最多包含 5 个约束,这些约束从 IFEval(Zhou 等,2023)和 IFBench-Train(Pyatkin 等,2025)中抽样。
• 通用聊天:我们从三个来源抽样通用聊天实例:(a) Tulu 3 SFT(Lambert 等,2024);(b) 新的 Wildchat-4.8M 数据集,涵盖用户-聊天机器人在模糊请求、代码切换、话题转换、政治辩论等方面的广泛交互;(c) Multi-subject-RLVR 数据集(Su 等,2025b),包含大学水平的英语问题及领域专家撰写的客观答案,用于考试。对于 Wildchat,我们仅抽取英文实例,并且不要求推理(如数学和编码)。对于 Tulu 3,我们首先使用 GPT-4.1 对样本进行重写,以获得更清晰的表达并提取 SFT 集中的参考答案。然后使用在 OpenThoughts 2 上微调的 Qwen 2.5 7B 模型为每个提示生成 8 个样本,并计算参考答案与每个响应的 F1 分数。我们移除平均 F1 分数 < 0.1 或 > 0.8 的样本,这样可以去除噪声样本和过难样本。Wildchat 中尤其存在大量角色扮演及其他基于角色的数据。为平衡数据,我们将单一角色的提及数量限制为最多 10 条。28 最后,我们还进行了事后人工过滤,以去除以代码和数学为中心的提示。
Step 2: 离线难度过滤
如前所述,为提高推理模型 RL 的样本效率,我们从模型训练的初始检查点(例如,从 DPO 训练模型开始,则使用 DPO 检查点)为每个提示生成八次 rollout。然后移除模型轻松解决的样本(即通过率超过 62.5% 的样本)。我们使用温度 1.0、top-p 1.0 进行采样,与 RL 训练时采样方式一致。对于 7B Olmo 3 Think,我们使用离线过滤,而 32B 模型由于计算和时间限制,则重用 7B DPO 过滤的数据并依赖主动采样。
Step 3: 数据混合
在开发数据混合和整体方案时,我们发现 RL 实验既耗时又计算量大,无法对数据集和算法选择的完整空间进行消融实验。因此,我们建立了如下流程:(a) 对中间 SFT 检查点进行特定数据集的训练,并观察前 500--1000 步 RL 中下游评估趋势;(b) 在测试新算法改动时,重点训练数学领域;(c) 定期进行整体混合实验,以确保混合稳定。最终运行时,我们选取最有潜力的数据集,进行离线过滤,并谨慎混合,以确保高质量数据被加权,同时每个领域的数据量大致相等(数学和指令遵循略多,因为在单数据集训练中效果最佳)。此外,我们根据离线过滤结果,对 OMEGA 中模型特别难处理的子任务进行下采样。29 我们使用该流程开发了 7B 模型的 RL 混合数据,然后出于计算和时间限制,32B 模型直接使用相同的数据混合。对于 Olmo 3 Think 7B 的训练,我们使用基础设施的初始版本(无 pipelineRL 或截断重要性采样),耗时约 15 天。后来使用更新的基础设施复现同一训练,仅用 6 天即达到相似性能。
4.4.3 Open Instruct 中的 OlmoRL 基础设施
我们对强化学习基础设施进行了大幅改进,以处理更长的序列并提高整体吞吐量。在 RL 中,针对生成长序列的模型进行微调的关键技术挑战是管理推理------也称为 rollouts。对于我们的最终模型,我们执行的 RL rollouts 长度可达 32k token,推理器模型的平均长度超过 10k token。推理在我们的成本中占主导地位,32B OlmoRL 推理器模型的训练使用 8 个 H100 节点,推理使用 20 个节点。鉴于自回归推理的成本,我们的学习器有 75% 的时间在等待数据,因此就 GPU 利用率而言,推理所用计算约为训练的 5 倍。实际上,我们使用了内存可容纳学习器的最小分片配置,并未优先考虑速度,这与监督学习设置不同。对于 7B 推理器模型,由于学习器的内存压力较小,情况更为显著,我们使用 7 个节点进行推理,仅用 2 个节点进行学习。鉴于学习器的低利用率,我们用于推理的计算量约为训练的 14 倍。我们怀疑 32B 学习器的分片配置不够优化,预计未来工作中可以改进。
完全异步训练。如图 17a 所示,我们采用离策略异步 RL 设置(Noukhovitch 等,2024),特色为通过 DeepSpeed(Rasley 等,2020)在多个节点上分布的集中学习器,以及大量执行独立 vLLM(Kwon 等,2023)实例的 actor。学习器生成提示,排入队列并分发给 actor,actor 执行提示、与环境交互,并通过结果队列返回结果,学习器使用这些结果更新模型参数。30 由于完成长度的差异,单个 RLVR 批次中完成之间可能出现较长时间间隔。缓解这一问题的指导原则是高效利用资源(避免空闲)并使进程异步。
连续批处理。我们采用连续批处理,在每次生成完成后持续入队新生成,以消除长序列生成的计算浪费(见图 17)。这与静态批处理形成对比,后者将一批提示拆分到 N 个 actor,每个 actor 生成整个批次32,将生成的响应返回给学习器,然后向每个学习器发送新的数据批次。静态批处理效率低下,因为当某个生成完成时,该批次的"槽"将保持空闲,直到获取新批次。计算浪费可通过最大序列长度减去平均序列长度,再除以最大序列长度来计算。在 OLMo3 中,32k 生成长度下,平均生成长度为 14628,最大为 32k,这意味着使用静态批处理时最多有 54% 的计算将被浪费。示例见图 17。
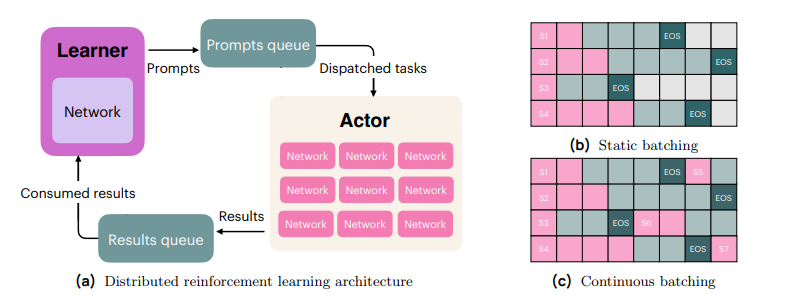 图 17(a) 分布式强化学习架构。(b,c)静态批处理与连续批处理。当选代序列长度可变时,静态批处理会浪费计算资源。粉色单元格表示预填充的标记,绿色单元格表示解码后的标记,深绿色表示序列结束(EOS)。灰色表示序列处于空闲状态,因此连续批处理会立即回填已完成的行(不会浪费计算资源)。
图 17(a) 分布式强化学习架构。(b,c)静态批处理与连续批处理。当选代序列长度可变时,静态批处理会浪费计算资源。粉色单元格表示预填充的标记,绿色单元格表示解码后的标记,深绿色表示序列结束(EOS)。灰色表示序列处于空闲状态,因此连续批处理会立即回填已完成的行(不会浪费计算资源)。
主动采样。为补偿过滤后的实例,我们的完全异步框架能够持续从 actor 拉取完成结果,并将提示重新采样入队列。我们主动采样和过滤,直到达到所需的非零梯度完成批次。此前 Yu 等(2025)的动态采样会过度采样,生成训练批次中使用提示的三倍,以合理保证批次中有足够的非零标准差完成。相比之下,我们的主动采样更高效利用基础设施。如第 6 节所示,这显著稳定了训练,并防止训练过程中批次大小减少(vanilla GRPO 常见问题)。
飞行中更新。LLM RL 训练的一个常见目标是最小化 actor 策略与学习器策略之间的差异,即尽量减少离策略(Van Hasselt 等,2018)。这可以通过在每次训练步骤后同步权重实现:每个 actor 完成所有正在进行的生成,清空 KV 缓存,并更新其权重副本。然而,这会导致 GPU 空闲,降低训练效率。相反,我们遵循 Piché 等(2025)的方法,在不暂停引擎的情况下立即更新权重,依赖生成框架的线程安全性,继续生成,而不使 KV 缓存失效。这显著提高了吞吐量:在相同资源下速度可提高至 4 倍,且不影响精度。
更好的线程管理和工程优化。这些改进主要涉及在每次训练步骤后处理权重同步,使 actor 更高效。我们的新设置解耦了 actor,使每个 actor 可以独立启动和停止,无需等待其他 actor 完成同步。同样,我们进行了大量非机器学习特定的优化,主要集中在高效利用 CPU。例如,我们最初实现的连续批处理在未添加预取线程前,速度反而比静态批处理慢,该线程不断填充推理队列以提高吞吐量。
我们的最终 RL 运行混合了来自所有领域的仔细过滤的数据,数据量大致相等,并在 DPO 检查点上运行。
4.5 关键发现
DPO 在 SFT 对同一数据无法取得提升时仍能获得收益。直接在 Dolci Think DPO 选择的响应上继续进行监督微调会明显损害初始 SFT 模型(表 19),所有评估任务表现下降。我们推测,这是因为所选响应(由 Qwen3-32B Thinking 生成)相较于模型在 Dolci Think SFT 中已见过的数据较弱,因此不再是有效的模仿目标。然而,通过将这些选定响应与由更弱模型生成的拒绝响应配对,我们构建了有用的对比,使偏好调优能够推动显著提升,超越初始 SFT 模型(表 19)。值得注意的是,这些提升不仅仅是将 pass@k 转换为 pass@1,而是扩展了模型的推理前沿(例如,在 AIME 评估中 pass@k 提升;图 20)。这些发现强调了即便在模仿饱和时,对比学习与偏好调优仍是提升能力的有效阶段。
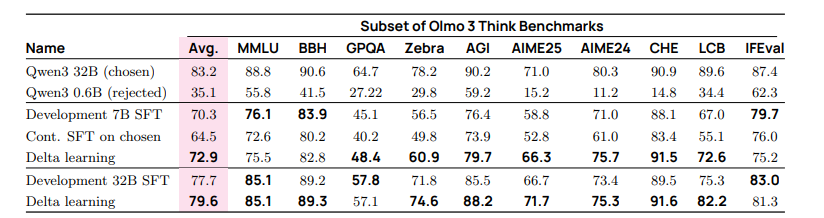 表 19 显示,选择响应与拒绝响应之间的差异至关重要。直接对 Qwen3-328 思维生成的已选择响应进行监督式微调会损害初始 SFT 模型。相反,通过DPO 调整,优先选择 328 响应而非较弱的Qwen3-0.68 思维响应,可以显著提升数学和代码推理能力。
表 19 显示,选择响应与拒绝响应之间的差异至关重要。直接对 Qwen3-328 思维生成的已选择响应进行监督式微调会损害初始 SFT 模型。相反,通过DPO 调整,优先选择 328 响应而非较弱的Qwen3-0.68 思维响应,可以显著提升数学和代码推理能力。
DPO 和 SFT 在 RL 中收益相似,但 DPO 仍是更好的起点。表 20 显示,在 DPO 模型上运行最终 RL 混合 consistently 获得的性能优于在 SFT 模型上运行。我们发现三点主要差异,如图 19 所示:对于 RL 无法提升的评估,DPO 模型通常表现更好,并在 RL 训练期间保持优势(如 AlpacaEval)。对于 RL 明确针对的评估(如 Omega),DPO 和 SFT 模型最终表现相似。对于 RL 针对但从 DPO 难以进一步提升的评估(如 AIME 2025),SFT 模型提升以接近 DPO 表现。在任何情况下,SFT 模型在 RL 后都未超过 DPO 模型,因此我们选择在 DPO 模型上应用 RL。有趣的是,我们发现 SFT 模型在使用 SFT 或 DPO 离线过滤数据训练时表现相似,这表明 DPO 过滤掉的额外样本(即已解决样本)并未提供额外信号以提升 SFT 模型。进一步研究显示,尽管 DPO 模型熵较低,但在 AIME 评估中 Pass@K 性能更高(见图 20)。这表明相较于 SFT 模型,DPO 模型仍是 RL 的强起点,因为 RL 往往将 Pass@K 性能转化为 Pass@1 性能(Yue 等,2025)。
 表 20 显示,与单独使用 SFT 相比,Delta 学习为后续的 RLVR 提供了更强的初始化。我们展示了在评估数据集的子集上,对 7B 模型进行 DPO 和 SFT 后执,行 1000 步 RLVR 的效果。请注意,此处的评估仅来自一次运行。先使用 Delta 学习进行偏好调优,再进行 RLVR,可以获得最佳的整体性能。对于RLVR,我们使用根据相应起始点(仅 SFT 或 SFT +DPO)离线过滤的数据。
表 20 显示,与单独使用 SFT 相比,Delta 学习为后续的 RLVR 提供了更强的初始化。我们展示了在评估数据集的子集上,对 7B 模型进行 DPO 和 SFT 后执,行 1000 步 RLVR 的效果。请注意,此处的评估仅来自一次运行。先使用 Delta 学习进行偏好调优,再进行 RLVR,可以获得最佳的整体性能。对于RLVR,我们使用根据相应起始点(仅 SFT 或 SFT +DPO)离线过滤的数据。  表 21 核心基础设施改进对 OlmoRL 的影响。我们通过测量训练速度(每秒令牌数)和利用率指标来评估每个组件的影响,方法是依次从原始 OLMo2RL基础设施中添加每个组件。其中,运行中更新带来的改进最为显著。
表 21 核心基础设施改进对 OlmoRL 的影响。我们通过测量训练速度(每秒令牌数)和利用率指标来评估每个组件的影响,方法是依次从原始 OLMo2RL基础设施中添加每个组件。其中,运行中更新带来的改进最为显著。 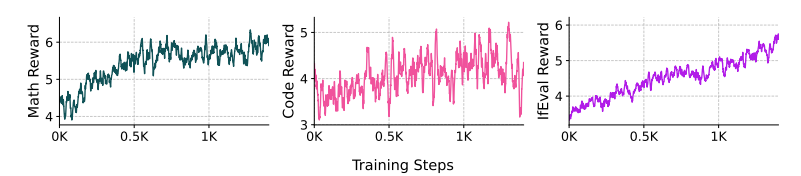 图 18 展示了 Olmo 3 Think 78 在训练过程中的奖励曲线。图中显示了 Olmo 3 Think 在最后一次RLVR 训练运行中,平均奖励、数学奖励、代码奖励和IF 奖励随强化学习 (RL) 过程的变化。奖励在各个领域稳步增长,表明训练过程较为平稳。更多RL曲线请参见图 35.
图 18 展示了 Olmo 3 Think 78 在训练过程中的奖励曲线。图中显示了 Olmo 3 Think 在最后一次RLVR 训练运行中,平均奖励、数学奖励、代码奖励和IF 奖励随强化学习 (RL) 过程的变化。奖励在各个领域稳步增长,表明训练过程较为平稳。更多RL曲线请参见图 35. 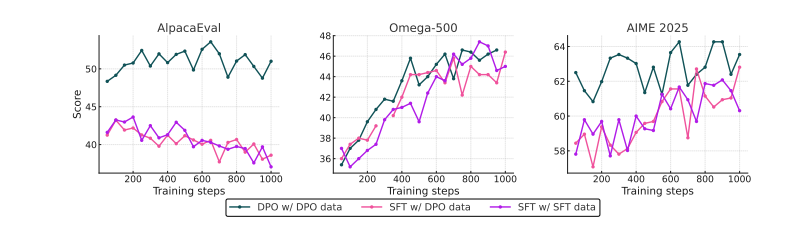 图 19 表明,以 DPO 作为 RLVR 的初始数据集效果最佳。图中展示了在 RLVR 训练过程中,使用Olmo 3 7B SFT 或 DPO 数据集作为初始数据集,分别使用经 DPO 模型过滤的数据(使用 DPO 数据集)或 SFT 模型过滤的数据(使用 SFT 数据集)进行训练时,AlpacaEval、Omega-500 和AIME2025 的性能表现。从 DPO 还是 SFT 数据集开始训练的重要性取决于具体的评估指标,但总体而言从 DPO 数据集开始训练更为理想。
图 19 表明,以 DPO 作为 RLVR 的初始数据集效果最佳。图中展示了在 RLVR 训练过程中,使用Olmo 3 7B SFT 或 DPO 数据集作为初始数据集,分别使用经 DPO 模型过滤的数据(使用 DPO 数据集)或 SFT 模型过滤的数据(使用 SFT 数据集)进行训练时,AlpacaEval、Omega-500 和AIME2025 的性能表现。从 DPO 还是 SFT 数据集开始训练的重要性取决于具体的评估指标,但总体而言从 DPO 数据集开始训练更为理想。
在 RL 中,各领域奖励稳步提升。图 18 绘制了每个验证器的奖励曲线及平均输出长度。我们发现各领域奖励稳步上升,但增速不同(指令遵循数据上升最稳定,编码奖励上升最慢)。更多 RL 曲线见附录(图 35)。有趣的是,我们发现序列长度先略微下降,然后随时间缓慢增加,这可能是因为推理 SFT 和 DPO 已训练模型生成最长 32k token 的推理序列。
**混合来自不同领域的 RL 数据可防止过度优化。**图 20(左)显示,在特定领域训练可能导致过度优化,使该领域以外的评估表现下降,而混合训练能在不同领域保持稳定提升。例如,仅在 IFEval 上执行 OlmoRL 时,高 IFEval 分数与低 AlpacaEval 分数存在权衡。然而,在最终混合训练中,我们能够保持高 AlpacaEval 分数,同时不损害 IFEval 性能,因为 LM judge 奖励确保模型持续生成格式良好的聊天响应。
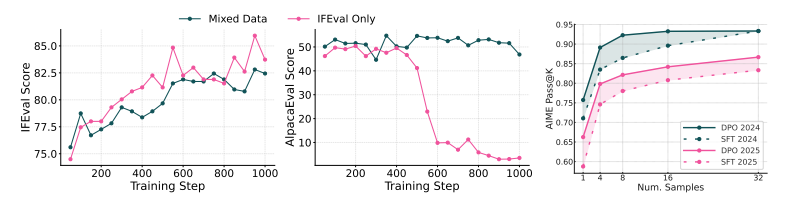 图 20 混合数据训练可防止过拟合(左图)。我们绘制了在 Olmo 3 Think SFT 7B 模型上,分别使用IFEval数据和混合数据进行强化学习训练时,IFEval和 AlpacaEval 的性能。混合数据训练在保持较高AlpacaEval 性能的同时,也获得了类似的 IFEval性能。DPO 的 pass@K性能优于 SFT(右图)。我们绘制了 SFT 和 DPO 思维模型在 AIME 2024 和2025 数据集上的 pass@K性能,K值最高可达32。即使在K值较低的情况下,DPO 的性能也始终优于 SFT。
图 20 混合数据训练可防止过拟合(左图)。我们绘制了在 Olmo 3 Think SFT 7B 模型上,分别使用IFEval数据和混合数据进行强化学习训练时,IFEval和 AlpacaEval 的性能。混合数据训练在保持较高AlpacaEval 性能的同时,也获得了类似的 IFEval性能。DPO 的 pass@K性能优于 SFT(右图)。我们绘制了 SFT 和 DPO 思维模型在 AIME 2024 和2025 数据集上的 pass@K性能,K值最高可达32。即使在K值较低的情况下,DPO 的性能也始终优于 SFT。
混合数据导致训练奖励降低,但不影响下游性能。图 20 显示,最终混合运行在下游任务中取得的性能与单领域 RL 训练相似或更好,但我们发现,相较单领域数据,混合数据训练时每个领域的训练奖励较低(见图 21)。这表明混合数据可能降低模型训练过程中的过度优化,防止一定程度的奖励作弊,从而更好地泛化到下游评估。这可能解释了为何在更广泛数据混合上的 RL 训练可超越领域特定混合(Cheng 等,2025)。
连续批处理和飞行中更新对训练速度至关重要。以推理器 SFT 或 DPO 为起点进行训练时,模型初始生成序列极长,RL 训练压力极大。表 21 显示,使用连续批处理和飞行中更新对训练速度至关重要,使我们在 GPU 数量减半的情况下实现两倍训练速度,使实验和长时间 RL 运行更可行。33 为进行仔细基准测试,我们对 OLMo 2 与 Olmo 3 之间的 RL 基础设施改动进行了消融。见表 21。对于每次消融,我们使用 2 个 8x A100 节点运行 2 小时基准实验。一个节点用于训练,一个用于推理。由于推理是瓶颈,我们仅基于用于推理的单节点报告模型 FLOPs 利用率(MFU)和模型带宽利用率(MBU)。典型全规模实验会使用更多推理节点,通常推理节点与训练节点的比例为 8:1 或更高。基准实验为每个训练步骤生成 128 个完成批次,使用 64 个提示,每个提示采样两次,最大输出长度 32000,最大输入长度 2048,导致上下文长度为 2048。
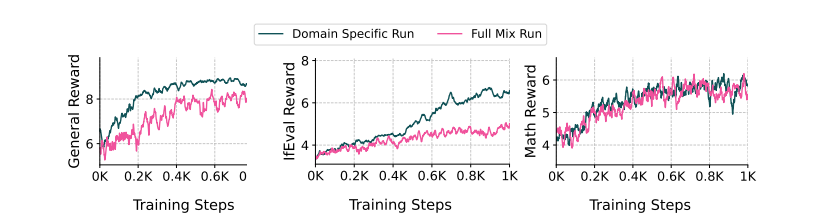 图 21 显示,按领域训练可以获得更高的训练奖励。我们绘制了按领域和整体混合(即最终)训练运行的训练奖励随强化学习(RL) 训练的变化曲线。在每个图中,我们使用 RLVR 训练一个中间 SFT 模型,该模型仅使用来自通用子集、正 子集和数学子集的数据,并与使用整体混合了集的数据进行训练进行比较。虽然特定领域的训练获得了更高的训练奖励,但图 20 显示,这并不一定能带来下游性能的提升。
图 21 显示,按领域训练可以获得更高的训练奖励。我们绘制了按领域和整体混合(即最终)训练运行的训练奖励随强化学习(RL) 训练的变化曲线。在每个图中,我们使用 RLVR 训练一个中间 SFT 模型,该模型仅使用来自通用子集、正 子集和数学子集的数据,并与使用整体混合了集的数据进行训练进行比较。虽然特定领域的训练获得了更高的训练奖励,但图 20 显示,这并不一定能带来下游性能的提升。
五 Olmo3 指导
近期研究表明,现实世界中对语言模型的使用主要集中在寻求建议与信息回忆等通用任务上(Chatterji 等,2025),这些任务可能不需要广泛的推理。因此,Olmo 3 Instruct 在构建时考虑了这些真实使用场景,因为用户期望聊天模型能够快速且有帮助地响应常见查询。日常聊天场景通常不需要 Olmo 3 Think 的推理时扩展,这使我们能够在常见任务上通过不生成扩展的内部思考而在推理时更高效。
这些不同类型的模型需要不同的数据来支持。我们通过引入多轮 DPO 数据并在我们的 delta-learning 偏好调优流水线中促进简洁回答,来着力提升模型的可交互性。此外,Olmo 3 Instruct 针对函数调用进行了训练,为此我们发布了新的 SFT 数据集。综合而言,我们的配方使 Olmo 3 Instruct 模型能够有效利用工具并高效响应用户查询。完整评估集见表 23,以及与类似模型的比较。除函数调用评估外,所有评估所用基准与用于 Olmo 3 Think(第 4.1 节)的一致。
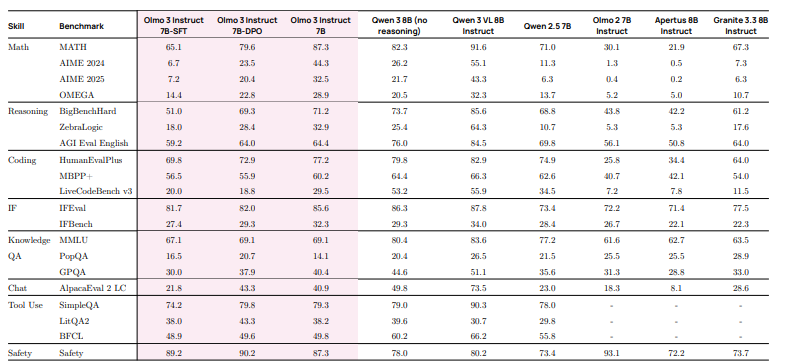 表23 0lmo 3 lnstruct-7B 在 Olmo 3评估套件上的结果概述。所有数值均为三次运行的平均值。
表23 0lmo 3 lnstruct-7B 在 Olmo 3评估套件上的结果概述。所有数值均为三次运行的平均值。
5.1 Olmo 3 Instruct 的主要结果
表 23 展示了 Olmo 3 Instruct 在我们的评估套件上的结果。Olmo 3 Instruct 显著优于 Qwen 2.5-7B Instruct、Olmo 2 7B Instruct 和 Apertus 8B Instruct。
5.2 使用 Dolci Instruct SFT 的监督微调
我们通过在 OLMo 2 Instruct 基础上构建,构造了 Dolci Instruct SFT,并进行了显著改进,以推进通用聊天、推理和函数调用能力。
5.2.1 新的函数调用训练数据
我们为 Olmo 3 Instruct 策划工具使用训练数据的目标,是为模型提供在基本函数调用方面的坚实基础,并向模型展示在真实环境(即 MCP 服务器)中有效使用工具执行任务的轨迹。因此,我们收集了两类由 LLM 合成的轨迹,描述如下。
具有真实互作用的轨迹 。我们收集了展示代理使用 MCP 服务器在以下两个领域回答查询的轨迹。所有这些轨迹均为单次用户轮次且包含多次代理-环境交互。
• Science QA 数据集包含两类广泛查询,均需对学术内容进行检索与推理:(i) 基于论文内容的查询,侧重于摘要或正文中存在的信息;(ii) 基于引用图的查询,涉及作者、会议和引文等元数据。与这些查询关联的轨迹由基于 GPT-4.1-mini 的代理通过配备 ASTA Scientific Corpus (ASC) MCP 服务器35 获得,该服务器提供对 Semantic Scholar 上元数据与论文内容的结构化访问36。关于这些数据集的更多细节见附录 A.5.2。
• Web Search QA 数据集由一个多阶段流程生成,结合了基准派生查询与真实世界查询。查询来源于开放获取基准:HotpotQA(Yang 等,2018)、TaskCraft(Shi 等,2025)和 WebWalkerQA(silver)(Wu 等,2025a),以及来自 SearchArena(Miroyan 等,2025)和 OpenScholar(Asai 等,2024)的经许可公开发布的用户提示。我们使用 GPT-5 对查询进行过滤,仅保留那些需要搜索、回答需为长文本且可验证的查询。这些查询的轨迹由配备 Serper API37(提供 Google 搜索工具与基于 URL 抓取网页工具)的 GPT-5 代理生成。关于查询过滤与轨迹生成的更多细节见附录 A.5.2。
具有模拟交互作用的轨迹。 虽然在可执行环境上训练的轨迹有望教会模型有效处理真实环境输出并应对意外错误,但在规模上策划此类轨迹较困难,可能限制模型在推理时对未见工具的泛化。为填补这一空白,我们还创建了一个使用 LLM 模拟环境的合成轨迹数据集,称为 SimFC。我们从现有数据集(例如 xLAM(Liu 等,2024c)、ToolACE(Liu 等,2024b))以及公开可用的 MCP 服务器中汇集大量工具集或 API,然后提示 LLM(GPT-4o、GPT-4.1 与 GPT-5)生成包含模拟用户查询、环境响应与助理消息的完整轨迹。我们设计提示以确保数据集包含多样的交互模式,包括多轮、多步骤以及因信息或工具不足而拒绝执行的情形。关于此数据集的更多细节及用于生成的示例提示见附录 A.5.2 与图 36、37。
在函数多样性与交互复杂性之间的平衡。如表 24 的统计所示,这两类轨迹存在关键差异。SimFC 包含大量具有多样函数集合的轨迹。我们发现合成具有多用户轮次的轨迹(多轮轨迹)相对比为单个用户请求合成多个助理-环境交互(多步骤轨迹)更容易;然而后者通常对应更复杂的任务。另一方面,基于 MCP 的数据集虽然规模较小,但在多步骤交互方面自然更复杂。
 表 24 函数调用数据集详情。多轮次指每条轨迹中用户多次转向,多步指每次用户请求中与环境的多次交互。
表 24 函数调用数据集详情。多轮次指每条轨迹中用户多次转向,多步指每次用户请求中与环境的多次交互。
**统一数据格式。**在所有工具使用数据中,我们采用一致的工具定义与函数调用格式,这对稳定且高质量的工具使用行为至关重要。具体而言,我们对所有工具定义使用 OpenAPI 规范38,并将所有函数调用表示为 pythonic 代码块。我们在系统提示中提供工具规范,在助手角色中用 XML 标签封装工具调用,并在特殊的 environment 角色中向模型呈现环境输出。我们还将对应这些标签的专用特殊 token 扩展到分词器词表中,发现这是工具使用训练的关键。
评估函数调用 。我们使用不同基准评估 Olmo 3 Instruct 的函数调用能力,衡量内在的函数调用与外在的任务完成准确率。我们使用 Berkeley Function Calling Leaderboard (BFCLv3)(Patil 等,2025)评估内在函数调用准确率。该基准聚焦模型在需要与模拟用户和环境进行一次或多次交互的设置中,选择相关函数及为其参数选择正确值以完成给定任务的能力。我们在模型作为可访问通过 MCP 服务器提供工具的代理部署时,比较 Olmo 3 Instruct 与类似模型的任务完成准确率。具体而言,我们使用提供八个用于访问科学文献函数的 Asta Scientific Corpus (ASC) 工具(Bragg 等,2025),以及提供 Google 搜索与网页浏览功能的 Serper API。为评估模型使用 ASC 工具的表现,遵循 Bragg 等(2025),我们使用 LitQA2(Skarlinski 等,2024)中的 75 个问题子集,其相关论文可在 ASC 索引中找到。我们使用 SimpleQA39(Wei 等,2024)的子集评估模型对搜索与浏览工具的使用。
我们使用 BFCLv3 官方 Gorilla 仓库40 进行评估。对于 LitQA2 和 SimpleQA,我们使用 OpenAI 的 Agent SDK 实现了一个基础的函数调用代理。该代理使用相关 MCP 服务器提供的工具,通过迭代地调用函数并处理其执行输出与环境交互以解决给定任务。对于 LitQA2 和 SimpleQA,我们还测量模型在 No-Tools 设置下的性能,即不向代理提供任何工具,要求其完全依靠模型参数化知识解决任务。对于所有这些基准,我们均使用零样本评估。我们在采样时将温度设为 0,对于 LitQA2 和 SimpleQA,允许代理最多 10 个轮次完成每项任务。我们对每次评估重复运行三次并报告平均准确率。我们已发布用于运行基于 MCP 的工具使用评估的代码41。
5.2.2 构建 Dolci Instruct SFT
Step 1. 收集提示与完成内容 我们的提示集合包括我们所有新的函数调用数据(第 5.2.1 节)、用于指令跟随 §4.2.1 和科学领域的新提示,以及来自 WildChat(Zhao et al., 2024a)的更多聊天提示。对于我们纳入的、最初包含推理轨迹的示例(例如 §4.2.1 中描述的 OpenThoughts3 科学子集),我们移除推理轨迹和特殊标记。我们还将来自旧模型(如 GPT-3.5 和 GPT-4)的完成内容更新为来自 GPT-4.1 的完成内容。我们在表 27 中展示了我们的 instruct SFT 数据混合的摘要。
Step 2: 过滤与混合 我们遵循第 4.2.1 节中详述的相同过滤和混合流程。对于 Olmo 3 Instruct,我们的基础混合是来自更新后的中间混合的 100k 个示例,该中间混合基于 OLMo 2 的 SFT 混合。我们在表 25 中展示了关于 OLMo 2 的数据混合实验结果。
从 Olmo 3 Think SFT 开始训练。 我们根据图 2 所示,从 Olmo 3 Think SFT 模型开始训练 Olmo 3 Instruct 的 SFT 阶段。我们发现这显著提升了 Instruct 模型的性能,如表 26 所示的结果。
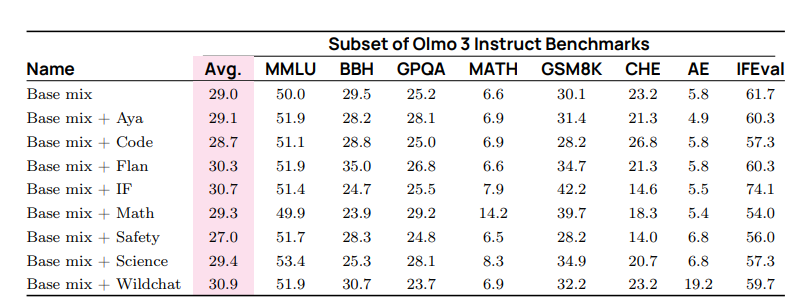 表25 我们在OLMo2上进行SFT混合消融的指导结果
表25 我们在OLMo2上进行SFT混合消融的指导结果  表 26 训练一名中级 Olmo 3 指导员检查点(有/无SFT 首先思考)的结果
表 26 训练一名中级 Olmo 3 指导员检查点(有/无SFT 首先思考)的结果  表 27 Olmo 3 SFT和 DPO 的指导提示来源
表 27 Olmo 3 SFT和 DPO 的指导提示来源
5.3 使用 Dolci Instruct-DPO 进行偏好微调
我们通过在强大的 delta-learning 启发式偏好流水线(第 §4.3 节)的基础上扩展更多偏好信号,创建 Dolci Instruct-DPO,以增强模型在通用使用场景中的行为。例如,我们通过改进的 GPT-judge 流水线生成对比样本来增强通用对齐。此外,用户与语言模型的交互通常需要多轮对话能力,因此我们向偏好数据中加入了合成的多轮对话。我们还观察到偏好数据流水线通常会促进过度冗长的回答;因此我们引入反向干预,通过缓解偏好数据中的长度偏置来促进模型回答的简洁性。
5.3.1 偏好信号
Dolci Instruct-DPO 由多种偏好信号组合构成,以提升模型能力和通用可用性:
Delta-learning 启发式对 。与 Dolci Think-DPO 类似,我们通过使用大模型(Qwen3-32B)生成"选择"回答,用小模型(Qwen3-0.6B)生成"拒绝"回答来构造启发式对比样本,遵循 Geng 等人(2025)。需要注意的是,我们关闭了思维模式,因为我们不需要内部思维轨迹。
Delta 感知的 GPT 评判对 。我们额外生成由 GPT 评判的偏好对,以提供进一步的偏好信号来源。我们最初尝试通过提升 LLM judge 的质量(GPT-4o → GPT-4.1)并更新数据生成模型池,来现代化 OLMo 2 与 Tülu 3 的 Ultrafeedback 流水线,但未能取得收益,甚至相较 OLMo 2 偏好数据集基线有所下降。我们推测原因在于我们的大部分数据生成器质量过高,因此所得"选择"与"拒绝"回答之间平均上缺乏有意义的差异。为缓解此问题,我们明确引入旨在降低"拒绝"回答质量的干预措施。我们 (1) 确保每个提示的待评判回答集合中始终包含弱模型的回答,并 (2) 选择最差回答作为"拒绝"完成内容,以最大化 delta。我们发现这些"delta 最大化"干预对偏好对数据质量至关重要;关于细节见第 5.5 节。
多轮偏好。 为确保 Olmo 3 在真实多轮对话中的可用性,我们进一步加入了一个多轮偏好数据集,其中提示通过从 Tülu 3-DPO 数据集中合成扩展而来。偏好对仅在对话的最后一轮有所不同,以避免同一对话不同轮次之间的质量排序歧义。合成对话通过两种方法生成:(1) 自我对话,即让 LLM 为原始提示生成后续请求,将提示扩展为多轮对话;(2) 合成上下文,即通过生成与初始提示相关的、独立的问题或释义,作为先前用户轮次及其完成内容。结合这些生成方法可确保对话的多样性。最终轮次使用 delta-learning 启发式(Geng et al., 2025)生成选择/拒绝完成对,分别由 GPT-4o 与 GPT-3.5 或 Qwen3-32B 与 Qwen3-0.6B(无思维模式)生成。
控制长度偏置。 偏好数据常存在长度偏置:选择回答显著长于拒绝回答。这源于从合成回答对中抽取更多信息量的回答被 LLM judge 与启发式方法视为更有帮助。也就是说,我们流水线中的 GPT judge 倾向偏好更长的回答。同样地,我们经验观察到 delta-learning 启发式生成的偏好对也呈现长度偏置;大模型会生成更长的回答(见图 23)。因此,除了有用的质量信号之外,这种长度偏置会在偏好微调时被模型学习,从而导致每个提示的生成长度显著增加。由于过度冗长在常见真实使用情况下可能是不理想的(示例见图 22),我们对聊天与多轮偏好数据子集进行过滤,以限制选择与拒绝回答之间的长度差不超过 100 个 token。
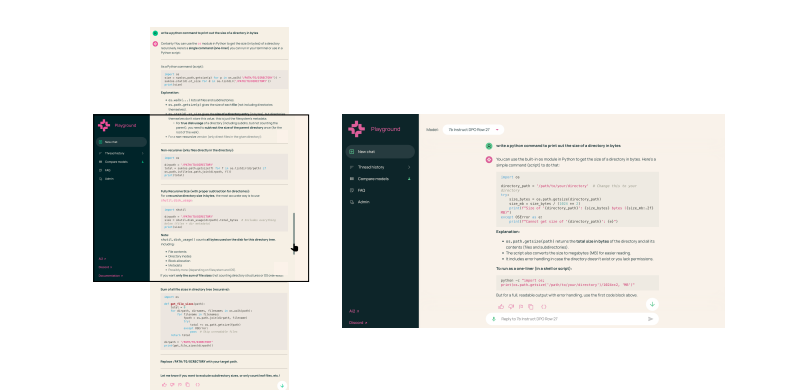 图 22 长度控制有助于生成简洁易用的响应。左侧是未进行长度控制训练的模型的响应:右侧是进行了长度控制的模型的响应。模型响应越简洁,就越容易使用和理解。
图 22 长度控制有助于生成简洁易用的响应。左侧是未进行长度控制训练的模型的响应:右侧是进行了长度控制的模型的响应。模型响应越简洁,就越容易使用和理解。 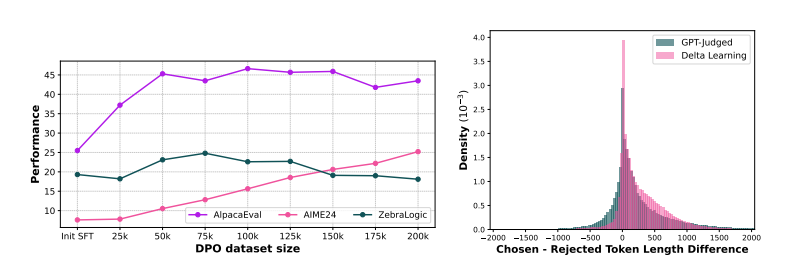 Figure 23 理想的偏好数据集规模取决于下游任务(左)。AlpacaEval 和 ZebraLogic 的性能会随数据量增加而提升,直到大约 75--100K 样本,此后进一步扩展数据规模会带来负面影响或无收益。相比之下,AIME2024 在 AlpacaEval 和 ZebraLogic 开始出现性能下降的点之前并未达到饱和。因此,为在所有下游任务之间取得理想平衡,我们在训练期间将数据集规模作为超参数进行扫描。未过滤的偏好数据表现出长度偏置(右)。分布中有显著部分呈现"选择回答"长于"拒绝回答"。例如,GPT 评判数据的 token 差异在第 80 百分位处为 538 个 token,delta-learning 启发式对的该数值为 564 个 token。
Figure 23 理想的偏好数据集规模取决于下游任务(左)。AlpacaEval 和 ZebraLogic 的性能会随数据量增加而提升,直到大约 75--100K 样本,此后进一步扩展数据规模会带来负面影响或无收益。相比之下,AIME2024 在 AlpacaEval 和 ZebraLogic 开始出现性能下降的点之前并未达到饱和。因此,为在所有下游任务之间取得理想平衡,我们在训练期间将数据集规模作为超参数进行扫描。未过滤的偏好数据表现出长度偏置(右)。分布中有显著部分呈现"选择回答"长于"拒绝回答"。例如,GPT 评判数据的 token 差异在第 80 百分位处为 538 个 token,delta-learning 启发式对的该数值为 564 个 token。
5.3.2 提示混合
我们的 GPT 评判与 delta-learning 启发式偏好对的提示池(见表 27)来源于 Dolci Instruct SFT 数据集,并补充了来自 OLMo 2-7b 偏好数据集的 DaringAnteater 与 Ultrafeedback 子集。由于 DPO 的性能并不会随数据量增加而单调提升(见图 23),我们在固定数据预算内优化提示分布,并在训练时将数据集大小视为超参数。
为确定最终偏好微调的提示分布,我们首先以对 100k 示例近乎均匀的随机采样作为经验强基线。随后,我们对提示领域子集进行消融,以确定各领域提示的影响。此外,我们还进行了实验,将基础混合中的 50k 示例与来自某一特定领域的 50k 示例配对,以了解对该提示领域进行上采样的效果。
值得注意的是,提示领域分布并不总是与 pair 中表现出的对比一致,也不总是与对应下游评测领域的提升一致。例如,上采样代码提示会产生一个违反直觉的效果:代码基准性能下降(见附录表 46)。在决定最终混合时,我们基于从消融中获得的专家直觉创建了 9 份候选混合,将这些手工构造的混合与随机采样基线进行比较。我们的最终混合是经验确定的;我们发现手工构造的混合通常略优于随机采样。
5.3.3 训练
我们遵循与 Olmo 3 Think 相同的设置,并扫描相同的超参数,即学习率和数据集大小。我们进一步通过创建具有不同 token 长度过滤阈值的数据集,扫描不同的长度控制干预。我们选择每个长度预算中表现最好的检查点,然后基于定性"氛围测试"和性能-长度分析,选出最终的 Olmo 3 Instruct-DPO 检查点。
5.4 使用 Dolci Instruct-RL 的强化学习
我们使用与 Dolci Think-RL (§4.4.2) 相同的提示池,但有两点例外:(i) 在数学和代码领域使用难度较低的数据集;(ii) 跳过离线难度过滤,因为我们的 Instruct 模型更侧重于通用的指令遵循而非复杂推理。
5.4.1 训练
遵循 Olmo 3 Think 的配方,我们在通用聊天、数学与代码数据的混合上训练 Olmo 3 Instruct43。我们同样采用 OlmoRL 进行训练,最大响应长度为 8K token。由于 Olmo 3 Instruct 的目标是避免生成过长输出并保持通用可用性,我们在两个 DPO 候选模型上施加 RL:一个在平均性能上最佳,另一个虽性能略低但在定性"氛围测试"上更好。我们基于最终平均性能、长度分析与"氛围测试"选择最终的 RL 检查点。具体而言,我们首先按平均得分对检查点进行排序;在并列情况下,我们更强调那些不会随测试时计算量扩展而变化的数据集(例如 MATH 和 AIME),以避免偏向生成过长响应的模型。最后,我们应用"氛围测试"以识别评估套件范围之外的回退或不良行为。
5.5 关键发现
以下为我们在 Olmo 3 Instruct 训练三个阶段中的关键发现总结:
从 Olmo 3 Think SFT 开始有帮助。 我们发现,在思维 SFT 模型之上训练我们的 Instruct 模型不仅提高了基准性能(如表 26 所示),且并未增加模型平均响应长度。
高对比度的偏好对推动 DPO 改进 。我们观察到,完成项之间具有高对比度对于在 DPO 训练中实现改进至关重要(表 29)。使用 LLM-judge 流水线需要仔细考虑如何最大化"选择"与"拒绝"回答之间的 delta。我们最初尝试通过改进用于生成响应的模型来现代化 OLMo 2 的偏好数据流水线,但未能超越 OLMo 2 数据基线(表 29),甚至有损表现。原因在于用于合成完成项的模型质量过高:所得"选择"与"拒绝"回答均来自质量良好的模型,从而缺乏有意义的对比。基于 delta learning 的发现------高对比对性能至关重要------我们引入了旨在显式降低"拒绝"回答质量的干预措施,从而增大"选择"与"拒绝"对之间的质量差异。由此产生的 delta 感知 GPT 对显著优于 OLMo 2 的偏好数据。
结合不同偏好信号可提升整体性能。 我们将 delta learning 与 GPT 评判偏好数据结合,以获得"兼得"的效果。在经验上,使用 delta learning 或 GPT 评判对进行调优会带来不同分布的收益;我们发现这些收益具有互补性。结合两类偏好信号优于仅使用其一(表 29)。
理想的偏好数据量取决于下游任务。 DPO 在不同下游任务领域的训练量达到峰值的点不同。我们在图 23 中绘制了示例任务相对于不同数量 delta-learning 启发式对的偏好调优表现。超出这些最优点的进一步优化会损害下游性能,这与理论结果一致,表明对 DPO 早停很重要(Geng 等,2025;Azar 等,2023)。在实践中,这指导了我们的训练方法:我们扫描学习率与数据集规模以控制总优化量,并选择表现最好的设置。
来自偏好调优的简洁且可用的模型输出可以提升 RL 性能。 在 DPO 阶段应用长度控制显著降低了模型的平均生成长度,使我们能够在部分性能上做出权衡以换取更好的简洁性与整体可用性。尽管该长度减少会在对长度敏感的评测(尤其是数学基准如 AIME 与 MATH500)上导致得分下降,但我们的内部定性评估("氛围测试")几乎一致偏好更短、更直接的模型。我们有意决定优先考虑可用性。
令人惊讶的是,尽管在 DPO 阶段基准性能较低,长度控制在 RL 之后产生了更高性能的模型。我们推测这源于 RL 训练环境:在固定上下文窗口(8K)下,较短的模型在"每个 token 的智能度"上可能更高,使其在优化时更有效地利用可用预算。因此,最初看似在可用性与性能之间的权衡最终在两者上均带来了改进。此外,我们发现当以长度受控的 DPO 策略作为初始化时,RL 训练更为稳定。在大多数基准上,与从得分较高但不受限的 DPO 检查点开始的 RL 运行相比,基于长度受控的起点的 RL 性能提升更稳健,而后者更早显示不稳定或退化迹象。这进一步支持将经过简洁化偏好调优的模型作为 RL 的有利起点。
对工具的需求。 我们评估了 Olmo 3 Instruct 在 LitQA2 与 SimpleQA 上的性能有多少可归因于工具使用,通过测量在仅依赖参数化记忆(无工具)与使用工具之间的性能差异。表 28 给出了这些差异,并与三款 Qwen 模型进行了比较。所有模型在 SimpleQA 上均从工具使用中受益良多。然而,与 Olmo 3 Instruct 7B 不同,Qwen 模型在 LitQA2 上主要似乎依赖参数化知识,其中两款模型在提供工具后性能反而下降。
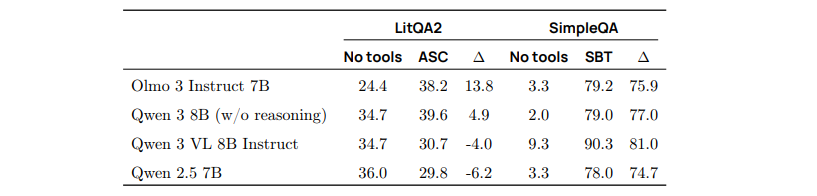 表 28:在 LitQA2 和 SimpleQA 数据集上,代理在有无工具访问情况下的性能比较。ASC指的是 AstaScientific Corpus 工具,SBT 指的是搜素和浏览工具。
表 28:在 LitQA2 和 SimpleQA 数据集上,代理在有无工具访问情况下的性能比较。ASC指的是 AstaScientific Corpus 工具,SBT 指的是搜素和浏览工具。 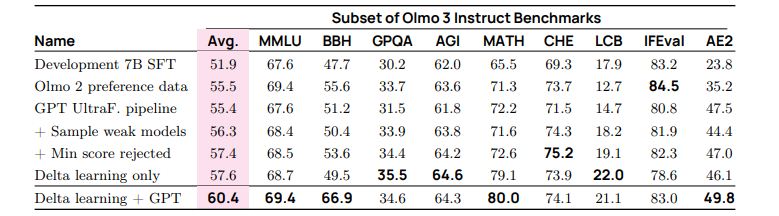 表 29 不同候好信号的比较结果:使用 delta 学习启发式方法创建的偏好对(选择=模型响应较大,拒绝=模型响应较小)与使用我们基于 delta 的 LLM-judge 流程创建的偏好对,其增益分布不同,表明它们提供了不同的候好信号。这些信号是互补的:将它们结合起来可以获得最大的平均增益。我们最终的Olmo 3Instruct 偏好数据显著提高了性能。
表 29 不同候好信号的比较结果:使用 delta 学习启发式方法创建的偏好对(选择=模型响应较大,拒绝=模型响应较小)与使用我们基于 delta 的 LLM-judge 流程创建的偏好对,其增益分布不同,表明它们提供了不同的候好信号。这些信号是互补的:将它们结合起来可以获得最大的平均增益。我们最终的Olmo 3Instruct 偏好数据显著提高了性能。
六 Olmo 3 RL-Zero
RL 已成为近期 LLM 流水线中的关键组件,部分原因在于 Deepseek R1-Zero(Guo et al., 2025),该方法显著地在基础模型之上利用 RL 训练以自举复杂推理行为(Marjanović et al., 2025)。这使得从基础模型进行 RLVR 微调成为 RL 算法的大规模标准基准(Liu et al., 2025a; Yu et al., 2025; Luo et al., 2025b)。迄今为止,所有领先的开源 RLVR 基准和算法都基于开源权重模型进行训练,而这些模型并未公开其预训练或中期训练数据(Chu et al., 2025; Yang et al., 2025a)。这限制了社区研究预训练数据对 RLVR 性能影响的能力。它会导致基准评估被污染的各种问题,例如中期训练数据包含评测内容,使得虚假奖励与真实奖励同样有效(Shao et al., 2025; Wu et al., 2025c),或修复提示模板的改进超过来自 RL 的改进(Liu et al., 2025b)。
因此,我们发布了完全开放的数据集 Dolci RL-Zero,这是 Olmo 3 的算法式 RL-zero 设置,并开源 OlmoRL 代码,以支持生态系统进行清晰的基准测试。我们在四个基准领域上从 Olmo 3 Base 执行 RLVR,以构建 Olmo 3 RL-Zero 系列:数学、代码、精确指令遵循(IF)以及三者混合。在所有情况下,我们进一步将 Dolci RL-Zero 与预训练和中期训练数据去污染,以确保我们的设置能够严格研究 RLVR 的效果,而不会因数据泄漏而混淆结论。
6.1 从 Dolci RL-Zero开始的基础强化学习
Data 我们创建了 Dolci RL-Zero,这是一个有效的 RL-zero 训练数据集。对于数学,我们对 DAPO math(Yu et al., 2025)和 Klear-Reasoner Math(Su et al., 2025c)进行强力过滤。我们对 DAPO 去重并移除所有非英语样本。由于 Klear-Reasoner 是一个更大的数据集,我们进一步进行语义聚类,并在每个簇中选择一个代表性问题。我们进一步按照小小节 4.2.1 对预训练数据和评测数据进行去污染,并对最终基础模型在 8 个样本补全中 8/8 完全解决的提示进行离线过滤。最终得到一个包含 13.3k 数学提示的数据集。代码和指令遵循的数据从 Dolci Think RL 中进行子采样。
Prompt and Eval. Template 结合 Liu et al. (2025b) 的发现,我们确认"简单"提示模板在从纯中期训练模型训练时显著优于标准的后训练模板(例如 <think></think>),因为 Dolma 3 Dolmino Mix 排除了大多数特殊格式。我们为每个领域开发了一个简单的自定义提示,并使用 zero-shot pass@k 作为指标。最终得到的提示类似于 Yu et al. (2025),如图 33 所示。我们进一步对所有评测提示进行"清洗",移除特殊格式(即 \boxed{}),以使评测提示更接近训练。
RL Algorithm我们遵循 § 4.4.1 的所有 RL 细节,除了 (i) 我们以 16K token 的响应长度进行训练,以更好地适应数学和代码领域中的长链式思维推理;以及 (ii) 我们以 32K token 的响应长度和温度 1.0 进行评测,以鼓励多样性,因为我们报告 pass@k。超参数细节见表 47。
6.2 关键发现
Olmo 3 RL-Zero 能显著提升推理能力 如图 24 所示,我们的基础模型在利用 RL 在我们的数据集上训练时,能够在不同领域显著提升训练奖励。为展示 OOD 改进,我们在去污染后的 AIME 2024 和 2025 上评测我们的数学运行。我们发现 Olmo 3 Base 在训练的前几百步中获得显著提升,之后保持稳定但缓慢地继续改进。我们还观察到 Pass@32 结果有轻微提升,表明我们的运行保持了多样性,并且 RLVR 将模型能力推进到其初始水平之外。值得注意的是,我们 7B 模型的初始得分和最终得分接近 DAPO(Yu et al., 2025),而 DAPO 使用更大的 Qwen 2.5 32B,并训练了数量级更多的步骤。这展示了 Olmo 3 RL-Zero 能成为现有 RLVR 实验更高效的替代方案。
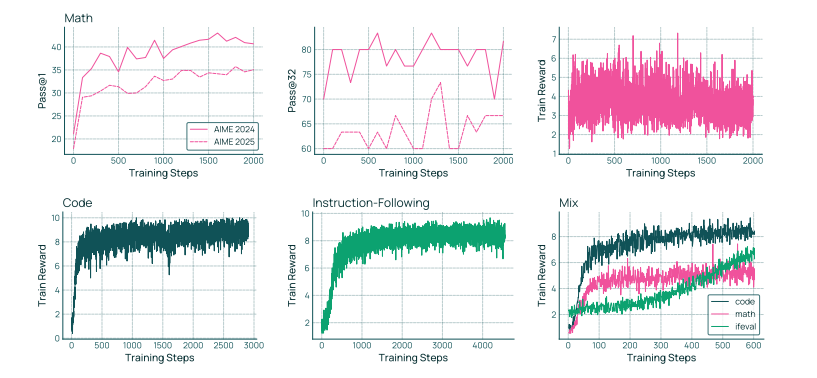 图 24 展示了 RL-Zero 在 Olmo 3 Base 数据集上不同领域的运行结果:数学、精确指令执行、代码编写以及三者混合。我们展示了数学领域的主要评估结果:AIME 2024 和 2025 测试,分别采用 Pass@1(基于 32 个样本的自举平均值计算)和 Pass@32两种方法。对于所有领域,我们都展示了训练过程中的奖励。对于混合测试,我们分别列出了每个领域的奖励。
图 24 展示了 RL-Zero 在 Olmo 3 Base 数据集上不同领域的运行结果:数学、精确指令执行、代码编写以及三者混合。我们展示了数学领域的主要评估结果:AIME 2024 和 2025 测试,分别采用 Pass@1(基于 32 个样本的自举平均值计算)和 Pass@32两种方法。对于所有领域,我们都展示了训练过程中的奖励。对于混合测试,我们分别列出了每个领域的奖励。
Olmo 3 RL-Zero Mix 能对多目标 RL 的挑战进行基准测试 大多数研究仅关注 RLHF(Stiennon et al., 2020)或单领域 RLVR(Yu et al., 2025; Luo et al., 2025a)。我们对数学、代码和指令遵循的混合构成了更具挑战性的 RLVR 基准。如图 24 所示,我们的通用运行在不同领域均取得提升,但每个领域都相较于单领域设置存在优化不足。未来工作可利用该设置研究多目标 RLVR 中领域间的交互。
Olmo 3 RL-Zero 能对中期训练中的推理数据混合进行基准测试 中期训练和 Olmo 3 RL-Zero 提供机会对特定数据源进行消融研究,这与 Olmo 3 Think 背后的大规模工作不同。我们利用 RL-Zero 来评估中期训练数据混合在通过 RL 发展下游推理能力方面的有效性。例如,我们在图 25 中比较两个早期模型。如停滞的响应长度所示,推理数据不足的模型没有学会回溯、验证答案及其他认知技能(Gandhi et al., 2025)。因此,Olmo 3 RL-Zero 可作为评估替代中期训练方法及其相对 Dolma 3 Dolmino Mix 改进的测试平台。
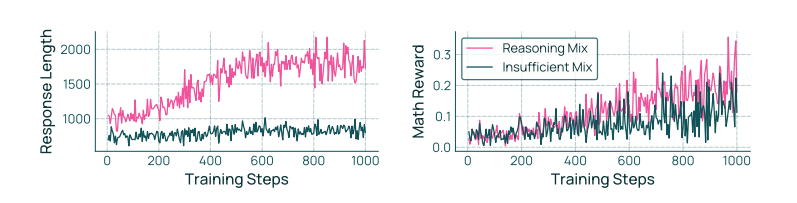 图 25 展示了两个早期中期训练的基础模型在强化学习过程中的响应长度和数学奖励。这表明基础模型的中期训练如何决定 RL-zero 是否能够学习更长、更复杂的推理,以及响应长度的增加。
图 25 展示了两个早期中期训练的基础模型在强化学习过程中的响应长度和数学奖励。这表明基础模型的中期训练如何决定 RL-zero 是否能够学习更长、更复杂的推理,以及响应长度的增加。
Active Sampling 稳定训练 Olmo 3 RL-Zero 还提供了更简单的测试平台,以消融 RL 算法和基础设施决策。我们对 active sampling(主动采样)进行消融,这是我们用于在过滤非零 advantage 后持续重新采样提示的新方法(见 OlmoRL Infra)。在数学领域运行时,如图 26 所示,主动采样确实保持了具有非零 advantage 的完整补全批次。这些一致的批大小对训练稳定性产生了有趣影响,我们观察到损失方差显著降低。
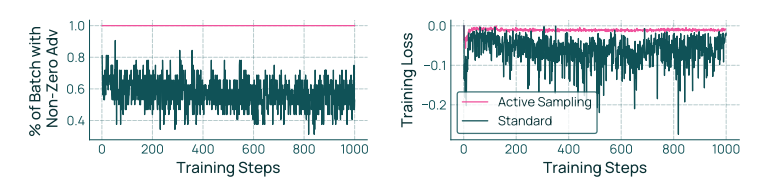 图 26 展示了主动采样如何通过在过滤后持续从结果队列中提取提示补全样本来维持一个完整的非零优势样本批次。图中绘制了启用和禁用主动采样的RL-Zero Math 运行中,具有非零优势的样本批次百分比以及训练损失。
图 26 展示了主动采样如何通过在过滤后持续从结果队列中提取提示补全样本来维持一个完整的非零优势样本批次。图中绘制了启用和禁用主动采样的RL-Zero Math 运行中,具有非零优势的样本批次百分比以及训练损失。
虚假奖励验证的净化效果 。 近期 RLVR 基准显示训练中虚假奖励带来显著提升,而这些奖励与模型效用无关。这可能表明 RLVR 任务已被污染,即模型在预训练或中期训练中接触了评测数据。带有虚假奖励的 RLVR 可激发模型召回这些记忆答案,从而与真正学习推理能力区分开来(Shao et al., 2025)。为验证 Olmo 3 RL-Zero 评测未被污染,我们进行负对照实验,在标准 RLVR 数据集上使用虚假奖励训练 Olmo 3 Base。具体地,我们为模型生成分配随机二元奖励,且与正确性无关,遵循 Shao et al. (2025) 的协议。我们使用去污染后的 OpenReasoner Zero(Hu et al., 2025)。如果我们的预训练或中期训练数据与评测集有显著重叠,我们将期望虚假奖励训练能够激发这些记忆解答并提升基准性能。
如图 27 所示,使用随机奖励训练不会提升任何基准评测的性能。性能要么保持平坦并伴随随机波动,要么下降,这与模型学习与任务无关的任意模式一致。该负面结果证明我们的数据去污染成功移除了基础模型流水线与 RLVR 评测数据之间的重叠。
 图 27 显示,在 Olmo 3 Base 数据集上使用随机,无信号奖励进行强化学习训练并未取得性能提升,这表明训练数据已成功去污染。
图 27 显示,在 Olmo 3 Base 数据集上使用随机,无信号奖励进行强化学习训练并未取得性能提升,这表明训练数据已成功去污染。
参考文献
1 OLMo3 :https://www.datocms-assets.com/64837/1763662397-1763646865-olmo_3_technical_report-1.pdf