本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发及AI算法学习视频及资料,尽在聚客AI学院。
在实际应用项目开发中,如何高效、精准地处理文本检索和相似性匹配已成为关键问题。不同的嵌入(Embedding)技术有各自的优缺点和适用场景,正确选型能够显著提升系统性能与效果。
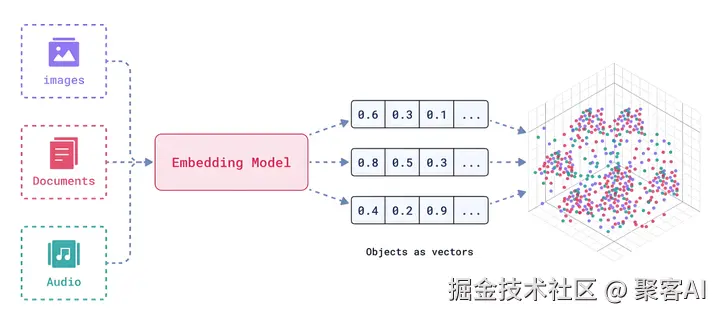
今天我将系统解析七种主流嵌入技术,包括 Sparse Embedding、Dense Embedding、Quantized Embedding、Binary Embedding、Matryoshka Embedding 以及 Multi-Vector 嵌入方法,并提供实用选型建议。

ps:在开始之前,建议你对向量数据库有一定的理解,如果你还不清楚,我之前也整理了一份关于向量数据库的技术文档,粉丝朋友自行领取:《适合初学者且全面深入的向量数据库》
一、Sparse Embedding(关键词式稀疏向量)
Sparse Embedding 是一种基于关键词匹配的稀疏向量表示方法,其维度通常超过 50,000 维,且95%以上的位置为零值。相似度计算常使用余弦相似度或点积,且只有被激活的维度参与运算。
典型实现包括 TF-IDF、BM25 和 SPLADE。它的优点在于关键词命中时准确率极高,且具备很强的可解释性------能够直接看到哪些词对匹配得分产生贡献。然而,它仅支持精确关键词匹配,无法处理同义词或句式变化的情况,同时高维稀疏性也会导致存储和索引成本急剧上升。
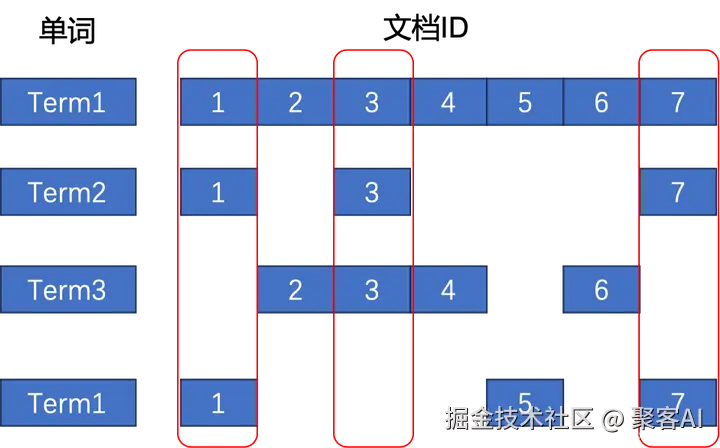
以下图的这个简易倒排索引所示,我们按照列为单元来看倒排索引,那么每列就可以表征为一个文档所包含的单词列表,这其实就是一种稀疏向量。图中的 3 个红色框分别代表了文档 ID 为 1,3,7 的三个不同的稀疏向量。而倒排索引则提供了稀疏向量的高效检索方式。
适用案例包括新闻版权去重场景,编辑使用原文中的五个核心实体词作为查询条件,借助 BM25 在毫秒级时间内返回疑似抄袭文章,准确率可达98%。
选型建议十分明确:如果业务场景中仅依赖关键词匹配即可解决,则无需引入神经网络模型。
二、Dense Embedding(语义级稠密向量)
Dense Embedding 能够将文本转化为低维稠密浮点数向量,维度通常在256至1536之间,且几乎所有维度都为非零值。它通过余弦距离计算相似度,能够有效捕捉语义层面的关联,如同义词、上下位关系甚至跨语言语义。
经典模型包括 text-embedding-3-large、BGE 以及 E5-mistral。然而,它也需要一定的计算资源(如 GPU/CPU)进行推理,单条处理时间在10~100毫秒之间。
这种方法特别适用于用户使用自然语言进行查询的场景。例如在 SaaS 客服 FAQ 检索中,用户提问"我忘了密码怎么办",通过稠密向量能够命中"如何重置登录密码"的标准问题,使TOP1命中率从关键词匹配的62%提升至89%。
三、Quantized Embedding(量化稠密向量)
Quantized Embedding 通过对稠密向量进行量化压缩,将 float32 类型转换为 int8 或 uint8 类型,从而实现存储和计算效率的提升。压缩率通常可达75%,而召回率损失可控制在1%以内。
需要注意的是,量化操作必须通过重新训练或训练后量化(PTQ)来实现,极低比特(如4 bit)量化可能会导致数值截断误差显著增加。带来的好处也是显而易见的:内存占用降低4倍,磁盘占用同样减少4倍,向量检索的QPS提升2倍。
电商场景下,原本占用 2.4TB 的2亿商品向量数据,经量化后仅需600GB存储空间,全内存检索的P99延迟从18毫秒降低到9毫秒。因此,当内存资源成为瓶颈时,量化是最直接的优化方案。
四、Binary Embedding(二值化嵌入)
Binary Embedding 通过 sign() 函数或 ITQ 旋转二值化技术,将浮点数向量转换为二值(0/1)向量,实现极致的压缩效果。其存储空间仅为 float32 向量的 1/32,使得计算方式转变为异或(XOR)和位计数(popcount)操作,CPU 单核每秒可完成超过1亿次相似度计算。
不过,二值化方法通常会导致精度下降约5%~15%,且汉明距离仅能提供排序结果,无法还原真实的相似度分值。它特别适合移动设备或离线环境中的检索任务。
例如在安卓相册的"重复照片清理"功能中,将256维 CNN 特征向量二值化后,在3万张照片中搜索相似图片仅耗时80毫秒,电量消耗低于1%。
五、Matryoshka Embedding(嵌套维度嵌入)
Matryoshka Embedding 允许模型在训练过程中构建一种嵌套结构的向量表示,例如前64维已经包含向量80%的信息。使用时可根据需要截取不同维度(如64、128、256维),实现精度与效率的动态平衡。
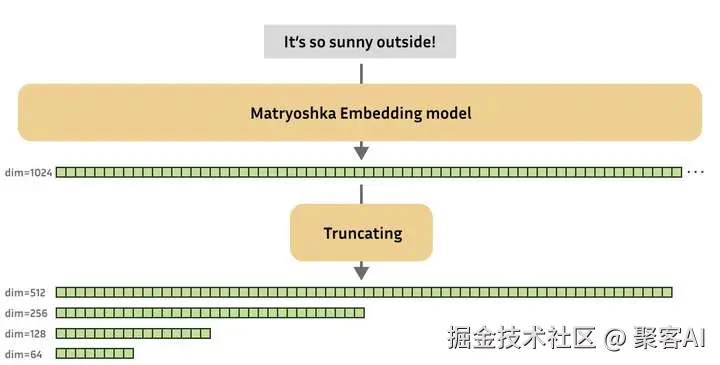
需要注意的是,必须选用专门进行 MRL 训练的模型,普通模型直接截断维度会导致效果显著下降。在低维情况下,不同语义可能被压缩到相近的向量空间中。
这种方法非常适合需求多变的业务场景。初创公司可以在 POC 阶段使用64维向量快速演示,而在客户签约后立即切换至512维向量,无需重新处理数据。
六、Multi-Vector Embedding(多向量交互匹配)
Multi-Vector Embedding 为文本中的每个 token 生成一个单独的向量,进而实现细粒度的词级匹配。以 ColBERT 为例,它会对每个 query token 与 document token 计算最大余弦相似度并求和(MaxSim)。
该方法的主要挑战在于索引体积可能增加百倍,需要借助专用压缩技术(如 ColBERTv2 的残差量化)进行优化。检索过程中的计算量也远高于单向量方法。
在法律文档检索中,律师输入"员工加班工资如何计算"这类自然语言问题,系统能够直接返回相关的段落,将阅读时间从15分钟缩短到3分钟。
七、技术选型指南
根据业务需求选择合适的嵌入技术至关重要:
- 关键词精确匹配:首选 Sparse Embedding,如 BM25;
- 通用语义搜索:首选 Dense Embedding,可变维度需求下可选择 Matryoshka;
- 内存或磁盘受限:Quantized 或 Binary Embedding;
- 设备端离线快速搜索:Binary Embedding;
- 长文档段落精确定位:Multi-Vector 方法;
- 需求频繁变动:Matryoshka Embedding 提供多维度支持。
八、方案选择总结
在实际选型过程中,建议从数据规模、延迟要求、内存限制、精度指标和可解释性五个维度进行综合评估。优先使用 Dense Embedding 建立基线效果,再根据具体需求决定是否引入更复杂的模型。
在对向量进行量化或二值化之前,务必在真实业务数据上测试召回率@K 的下降情况。若选择 Multi-Vector 方法,可借助残差量化等技术将索引体积从100GB压缩至8GB,同时保持95%的精度。
最终部署时,采用 Sparse 与 Dense 结合的混合排序(Hybrid Ranking)策略往往最为稳妥:稀疏向量保证精度,稠密向量保证召回率,并通过权重调整平衡结果。好了,今天的分享就到这里,点个小红心,我们下期见。