作者:周强,卡牌游戏公司高级开发工程师
向量数据库的独特优势与选型经验
#向量数据库 是专门为存储、索引和查询高维向量数据而设计的数据库系统,能够高效处理由机器学习模型生成的嵌入向量,并支持基于相似性的快速检索。
相较于#传统数据库,向量数据库在多方面显示出其独有的特性,可在前者涉及的领域之外发挥优势。如图1所示,传统数据库主要用于存储结构化数据,基于精准匹配进行查询,适用于业务数据管理,而向量数据库用于存储向量数据,基于相似性查询搜索,主要适用于 AI 和#机器学习 应用场景。
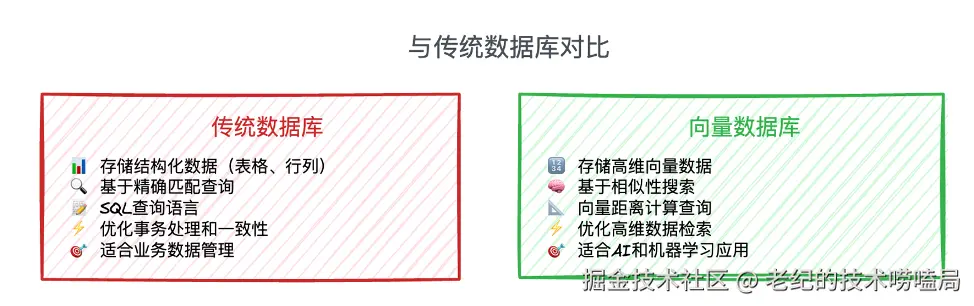
图1 传统数据库与向量数据库对比
目前,向量数据库被广泛应用于智能检索业务。非结构化数据如文本、图片、视频、音频等,通过深度学习神经网络进行向量嵌入,并存储到向量数据库中,以便业务方基于向量数据库进行语义相似度搜索,如图2所示。
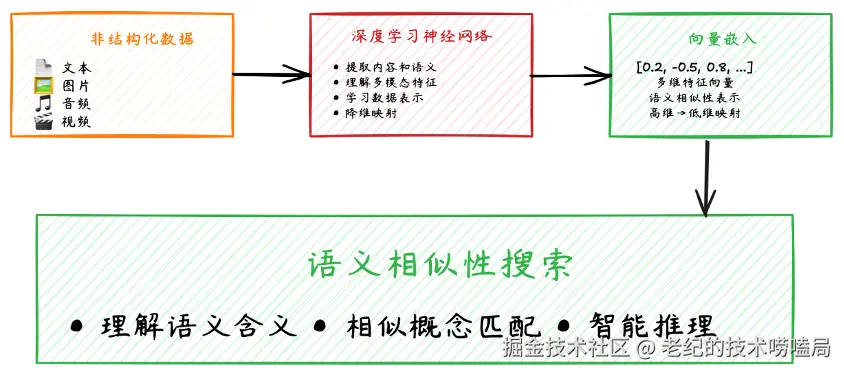
图2 智能检索业务流程
对应到真实的业务场景,向量数据库的作用分别是:
- 在智能搜索引擎中,用于理解用户意图,返回语义相关结果。
- 在推荐系统中,基于内容相似性进行个性化推荐。
- 在问答系统中,从知识库中找到最相关的答案。
- 在内容检索时,进行跨模态搜索(文本搜图片、图片搜文本等)。
- 在数据分析场景中,用于发现数据间的隐藏关联和模式。
在众多向量数据库中,我们选择 #OceanBase 支撑智能业务场景,原因主要分为以下四个方面。
1.一体化架构:保障一致性,运维成本低。
得益于OceanBase的一体化架构,可以使用同一套数据库存储结构化数据和向量数据,消除两库同步和一致性难题。同时,其#事务ACID 直接覆盖向量表,保证了数据的强一致性。此外,OceanBase还拥有统一的 SQL 接口和管理工具,可以降低我们的运维成本。
2.原生向量能力:业务性能有保障。
- 原生向量列类型 (VECTOR),数据库内核级支持。
- HNSW / IVFFlat 索引算法,优化检索性。
- 毫秒级 Top-K 检索,极速相似性搜索。
3.分布式弹性扩展:支持超大规模数据量。
支持分布式架构和数据分片,处理能力远超单机数据库,特别是在处理数百亿向量或数 TB 数据时性能表现优秀。
4.生态快速集成:兼容 MySQL 技术栈,开发接入成本低。
由于OceanBase支持 MySQL 协议,我们可以通过 Python 或 Java 的 SDK 访问。降低了接入成本。同时,由于OceanBase生态丰富,适配各种 AI 应用开发框架如 LlamaIndex、LangChain、 Dify 等,使用起来更加便捷。
综上所述,我们使用 OceanBase 在开发层面基本零学习成本,可以直接适配开发框架,方便易用。目前,我们已在多个场景应用OceanBase,下面以智能客服业务和UGC社区推荐系统为例,阐述应用经验。
智能客服业务实现毫秒级检索性能,效率提升 300%
在详细介绍智能客服业务前,我们先了解传统客服目前存在的问题,以感知智能客服系统中#向量检索 的关键作用。
对于传统客服,相信大家在生活中多少使用过,其典型的问题是响应慢,比如需要排队等待,高峰期的等待时间更久。在服务过程中由于对产品信息更新不及时或每位客服人员对产品信息的理解不一,还会出现回答标准不统一的问题,甚至一些客服的情绪也会影响服务质量。
在引入 AI 客服后,上述传统客服的问题可以得到基本解决。首先,#智能客服 可以全天候响应,无需客户等待,且秒级回复,能够提升用户满意度。其次,智能客服会分析用户行为,并提供个性化服务,对于客户不满意的回答可以持续学习进行自我优化,不断提升服务质量。
智能客服业务流程及关键技术
如图3所示,当智能客服收到客户消息后,首先进行智能总结,从消息中提取核心意图,然后到知识库中进行向量匹配,查询与客户消息最相似的话题。其次,根据话题选择对应标签并进行路由匹配,开始多源数据查询。在查询过程中会出现多种情况:如果是报错或#Bug 相关,需要在 Bug 表中查询故障记录和修复情况;如果是游戏玩法相关,需要查询游戏知识库;如果是工单类,需要查询历史工单。总而言之,通过多源数据查询与信息整合,生成个性化的回复或专业、准确的解决方案。
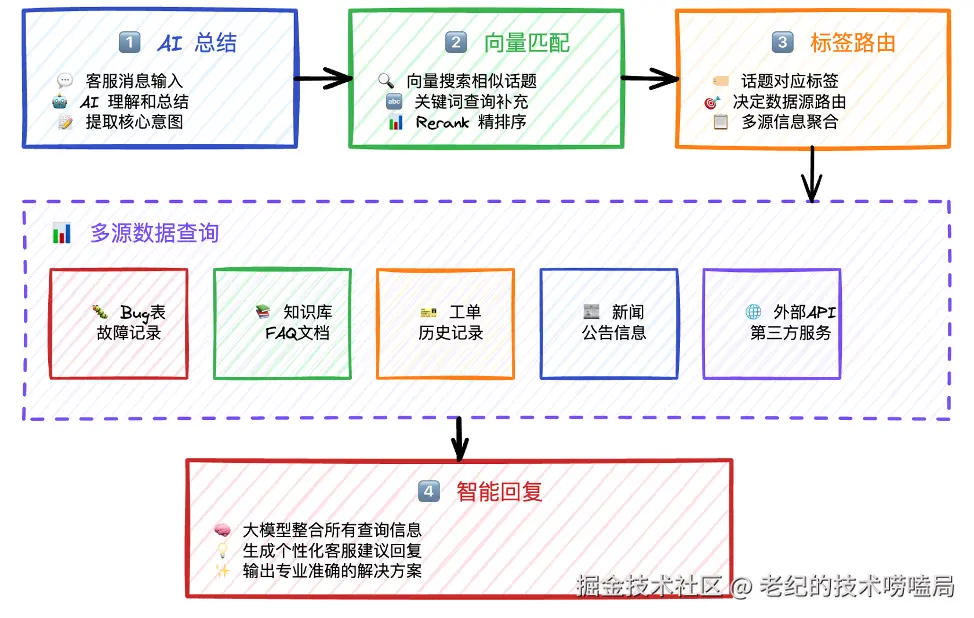
图3 智能客服系统工作流程
在这套智能客服系统工作流程中,最关键的步骤是向量检索,也就是搜索到与问题最相似的话题。其他技术细节包括关键字查询、Rerank 重排序、标签路由系统、LLM 智能生成等,是相对复杂的步骤。
- 向量检索:基于语义相似度快速匹配相关话题,提高召回率和准确性。
- 关键词查询:补充精确匹配,处理专业术语和特定名词。
- Rerank 重排序:对初步结果进行精确排序,确保最相关内容优先。
- 标签路由系统:根据话题类型智能路由到对应数据源,实现精准查询。
- LLM 智能生成:整合多源信息,生成上下文相关的专业客服回复。
那么,如何保证智能客服给出的信息是有效、准确的呢?
关键在于向量检索质量,如果检索的准确度不高,则无法精准匹配用户的业务意图。因此 嵌入质量(Embedding)决定"能检到什么"------是检索质量的上限;向量数据库的检索效果(ANN 索引、召回率)决定"实际能不能捞上来"------是检索质量的下限, 比如下面两种索引呈乘法关系,更低的一方就是瓶颈所在。
- 支持HNSW/HNSW_SQ/HNSW_BQ 索引,索引列最大维度为 4096。
- 支持IVF 索引/IVF_SQ 索引/IVF_PQ 索引,索引列最大维度为 4096。
因为嵌入向量通常使用开源模型,比如常见的开源中文嵌入模型 Qwen3-Embedding-8BBGE-large-zh-v1.5,所以我们没有可优化的方向,转而优化向量数据库检索,以更好地匹配实际数据。
向量数据库检索优化
1.数据表设计
如下是一个具体的知识库数据表设计,可以看到其中包含了 Embedding 模型、问题,放在一张表中。关于向量和索引算法,使用了768维的向量、HNSW 索引算法和余弦相似计算索引。
plain
CREATE TABLE `data_kf_faq` (
`id` varchar(36) NOT NULL COMMENT '主键ID,UUID格式,唯一标识一条FAQ记录',
`project_id` varchar(100) DEFAULT NULL COMMENT '项目ID,用于区分不同项目的数据归属',
`kid` varchar(100) DEFAULT NULL COMMENT '知识项ID(Knowledge ID)',
`question` text DEFAULT NULL COMMENT 'FAQ问题文本',
`embedding` VECTOR(768) DEFAULT NULL COMMENT '问题的向量表示,用于语义搜索(768维向量)',
PRIMARY KEY (`id`) COMMENT '主键索引,保证记录唯一性',
KEY `idx_kid` (`kid`) COMMENT 'kid字段普通索引,加快按知识项ID查询速度',
KEY `idx_proj_kid` (`project_id`, `kid`) COMMENT '项目ID+知识项ID联合索引,加快多条件精确查询',
VECTOR KEY `idx_embedding_faq` (`embedding`)
WITH (DISTANCE = COSINE, TYPE = HNSW, LIB=VSAG) COMMENT '向量索引,使用HNSW算法,余弦相似度计算,支持语义近似搜索'
)2.使用 jieba 进行分词,提取业务关键词
关键词表分为主表和附表,主要用于存储知识库的 Embedding 模型,以及问题关键词的分解,包括业务的特殊关键词。主表和附表结合进行查询。如果向量查询效果比较好,就可以省略关键词查询。
plain
CREATE TABLE `data_kf_faq_kw` (
`faq_id` CHAR(36) NOT NULL COMMENT 'FAQ主表的ID(UUID),关联data_kf_faq.id',
`kw` VARCHAR(100) NOT NULL COMMENT '关键词(单个词项),用于分词检索',
`project_id` BIGINT NOT NULL COMMENT '项目ID,用于区分不同项目数据',
PRIMARY KEY(`faq_id`, `kw`) COMMENT '联合主键,保证同一FAQ下关键词不重复',
INDEX `idx_kw_proj` (`kw`, `project_id`, `faq_id`) COMMENT '按关键词+项目ID快速查询FAQ列表'
) COMMENT='FAQ关键词表,用于按关键词快速定位FAQ记录';3.检索步骤及优化
检索分为五步,涉及两个优化。: 第一步:文本向量化,命令如下。
plain
embedding = vectorize_text(question)第二步:向量相似度搜索。当文本向量化完成后,需要在向量数据库进行检索,捞取部分数据,根据数据复杂度进行搜索。下文是一条直接在 OceanBase 中进行查询的 SQL。
plain
vector_results = database.vector_search(
project_id=project_id,
embedding=embedding,
top_k=20
)
SELECT id, kid, project_id, question, keywords,
COSINE_DISTANCE(embedding, %s) as distance,
(1.0 - COSINE_DISTANCE(embedding, %s)) as similarity
FROM {table_name}
WHERE project_id = %s
ORDER BY distance ASC
LIMIT %s第三步:关键词搜索补充 。关键词补充涉及向量查询和关键词查询。关键词指游戏中的专有关键词,AI 可能难以理解,需要单独作为分词。
plain
keyword_results = database.search_by_keywords(project_id, keywords)第四步:对关键字查询的候选结果进行合并去重。
plain
seen_ids = set()
result = []
for item in vector_results + keyword_results:
if item['id'] not in seen_ids:
seen_ids.add(item['id'])
result.append(item)第五步:智能重排序。前面几步完成后,我们会得到一个最佳匹配结果,并根据标签路由查询数据源,交给大模型进行个性化恢复。
plain
ranked_results = rerank_question(question, result)
# 按分数降序排序
sorted_ranked_results = sorted(ranked_results, key=lambda x:x.get("rerank_score", 0), reverse=True)
# 返回最佳匹配结果
sorted_ranked_results[0]在真实业务环境下实施上述检索步骤时,还涉及两个优化点。
一是智能候选数量控制。如果我们判断客户问题是复杂问题,就需要多取一些数据进行比对;如果是简单问题,则不需要取太多数据。
plain
# 优化:动态调整
def adaptive_search_size(project_id, question_complexity):
if question_complexity > 0.8: # 复杂问题
return {"vector_k": 20, "keyword_limit": 30}
else: # 简单问题
return {"vector_k": 10, "keyword_limit": 10}**二是早停机制。**如果在第二步即向量相似度搜索,匹配度已经很高,则不需要进行后续的关键字搜索和重排序,可以直接获取最佳匹配结果。
plain
# 优化:高置信度早停
if vector_results and vector_results[0]['similarity'] > 0.95:
logger.info("高置信度匹配,跳过关键词搜索和重排序")
return format_high_confidence_result(vector_results[0])使用 OceanBase 向量数据库的主要价值
在智能客服业务中,我们使用 OceanBase 后,在数据架构、检索性能、运维等方面获得了较大收益:
- 由于向量数据和结构化数据统一存储,降低了 50% 运维成本。
- HNSW 优化后,实现了毫秒级检索性能,客服效率提升 300%。
- 多节点快速扩容,实现99.99% 的可用性。
- OceanBase兼容 MySQL 协议,我们的运维和开发人员几乎零学习成本投入就实现了快速接入,开发效率非常高。
UGC 社区智能推荐系统,延迟降低75%
架构对比:传统推荐系统VS一体化智能推荐系统
如图4 所示,传统推荐系统架构的运行链路是:当收到用户请求推荐时,API 服务从 MySQL 中查询并获取用户信息,再到向量数据库中捞取相似数据,然后回到 MySQL 补充内容详情。此处查询数据后,可能还要缓存到 Redis 中,最后才能将结果返回给用户。整个流程共计4次网络往返,链路长、延迟高、复杂度高。由于涉及多个业务,很难保证数据一致性。
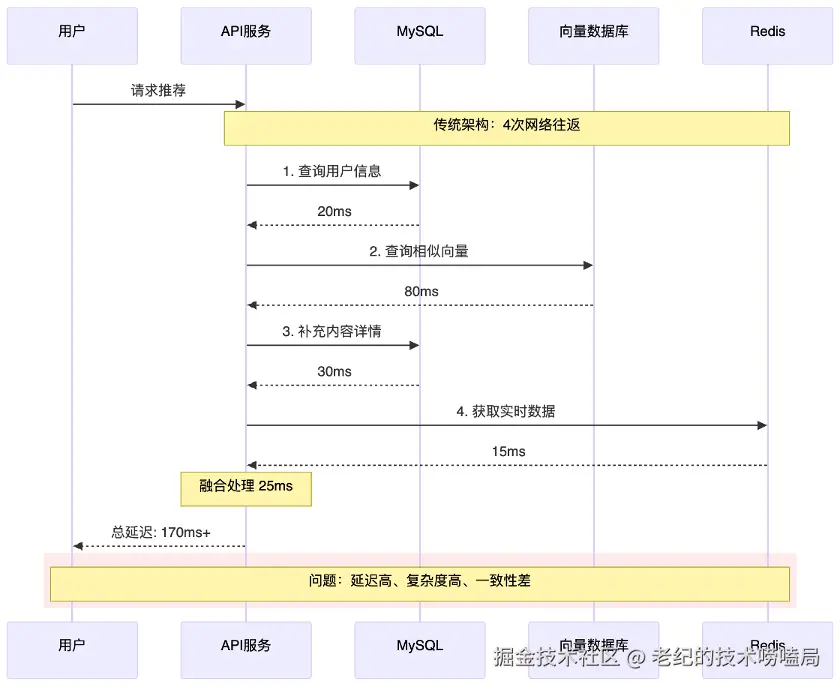 图4 传统推荐系统架构
图4 传统推荐系统架构
我们接入OceanBase 后,通过一套数据库就可以完成整个智能推荐系统的所有查询需求(见图5)。使用 OceanBase 只需进行一次查询,就可以达到传统推荐系统链路中 MySQL 查询、向量数据库查询,Redis 缓存等步骤的执行结果。换句话说,我们通过一套 OceanBase 替换多种数据库,获得了更低的网络延迟、更简单的架构,以及数据强一致性。
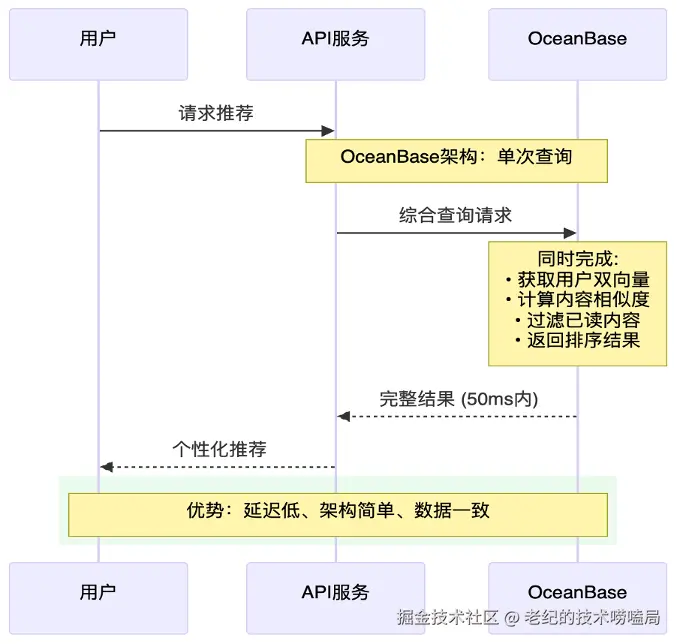
图5 使用OceanBase的智能推荐系统架构
图6是基于 OceanBase 实现的 UGC 社区智能推荐系统的详细架构,可以看到 OceanBase 在统一存储的同时实现了向量存储、关系数据存储。由于OceanBase高度兼容 MySQL 语法和协议,使原本基于 MySQL 的 UGC 社区推荐系统可以平滑迁移到 OceanBase。只需DBA 实现一些兼容性内容,不涉及开发改造,同时,开发侧无需额外操作就得到了事务一致性的保证。
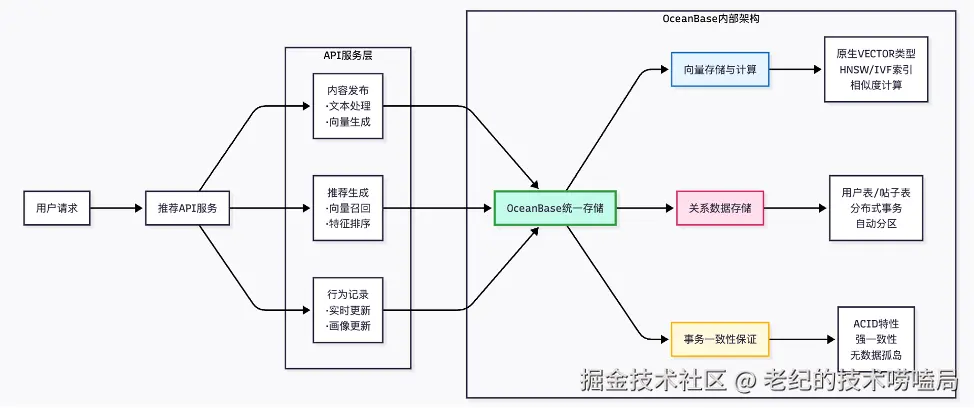
图6 基于 OceanBase 的 UGC 社区智能推荐系统架构
除了系统架构、开发改造层面的优势外,基于 OceanBase 的智能推荐系统也带来了三个关键技术优势。
1.原生向量类型支持。
OceanBase 原生支持向量类型,例如,可以直接将帖子内容 Embedding 后存储在帖子表即可,不需要单独再引入一套向量数据库。
plain
CREATE TABLE posts (
post_id BIGINT PRIMARY KEY,
title VARCHAR(255),
content TEXT,
-- 原生向量类型,无需额外存储系统
content_vector VECTOR(768),
view_count INT DEFAULT 0,
-- 向量索引,查询性能媲美专业向量数据库
VECTOR INDEX idx_content_vec(content_vector) WITH (distance=cosine, type=hnsw)
);2.事务一致性保证。
在同一个事务中,OceanBase可以同时更新结构化数据和向量数据,保证了事务一致性。而如果是使用传统数据库,则需要再引入一套向量数据库,会涉及两个库之间的数据同步问题,无法保证事务一致性。
plain
-- 在同一个事务中更新结构化数据和向量数据
BEGIN;
UPDATE posts SET view_count = view_count + 1 WHERE post_id = ?;
UPDATE users SET short_term_vector = ? WHERE user_id = ?;
COMMIT;3.一次查询,多路召回。
利用 OceanBase 的向量计算能力,可以用一条 SQL 完成所有的复杂推荐逻辑,包含短期向量和长期向量的融合、已看过内容的过滤、时间筛选等,不需要在业务侧执行复杂处理步骤,对业务开发很友好。
plain
-- 利用OceanBase的向量计算能力,一次SQL完成复杂推荐逻辑
WITH user_vectors AS (
SELECT short_term_vector, long_term_vector
FROM users WHERE user_id = ?
)
SELECT
p.post_id, p.title,
-- 融合双向量得分
0.7 * COSINE_SIMILARITY(p.content_vector, u.short_term_vector) +
0.3 * COSINE_SIMILARITY(p.content_vector, u.long_term_vector) AS score
FROM posts p, user_vectors u
WHERE p.created_at > DATE_SUB(NOW(), INTERVAL 7 DAY)
-- 过滤已看过内容
AND NOT EXISTS (SELECT 1 FROM user_actions WHERE user_id = ? AND post_id = p.post_id)
ORDER BY score DESC LIMIT 50;用户兴趣建模的双向量的创新
UGC 社区智能推荐系统实现了基于#用户兴趣 建模的双向量的创新,用于捕捉即时兴趣的短期向量和维护用户稳定偏好的长期向量。每个玩家都可以有两个向量表示短期和长期的兴趣爱好:长期代表固定的兴趣爱好;短期代表当下的关注点。将两个向量的查询结果基于一定权重分配进行动态融合后,即可生成向量化#个性化推荐。
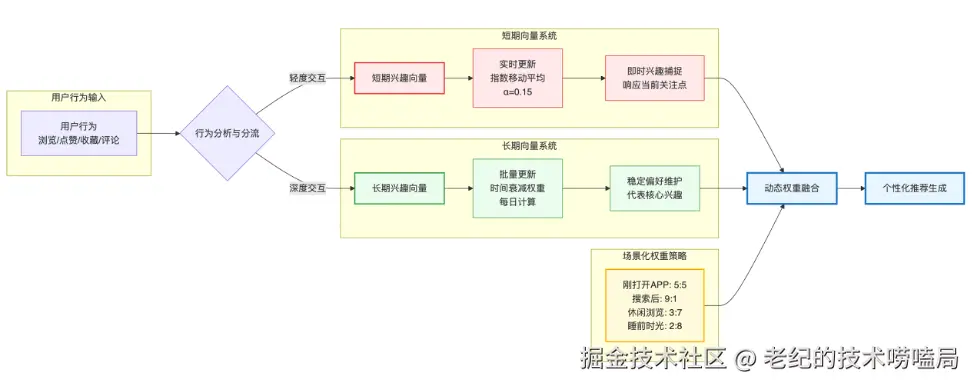
图7 基于用户兴趣建模的双向量创新
短期向量:捕捉即时兴趣
短期向量用于捕捉用户即时兴趣,所以当用户进行查询动作后,系统会实时更新该用户数据。短期向量的数据存储特点是响应快,可以捕捉用户最关注的核心点。
plain
def update_short_term_vector(user_id, post_vector, action_type):
# 行为权重:不同行为反映不同兴趣强度
weights = {'view': 0.1, 'like': 0.3, 'collect': 0.5}
# 指数移动平均:新兴趣逐渐替代旧兴趣
new_vector = 0.85 * current_vector + 0.15 * weights[action_type] * post_vector
# 实时更新,立即生效
execute_sql("UPDATE users SET short_term_vector = ? WHERE user_id = ?",
[new_vector, user_id])长期向量:维护稳定偏好
长期向量主要用于维护用户核心的兴趣爱好,一般每天批量计算更新一次,同时计算维度加入了该用户30天内的行为权重。
plain
-- 每日批量计算长期兴趣
UPDATE users u SET long_term_vector = (
SELECT VECTOR_NORMALIZE(
VECTOR_SUM(
-- 时间衰减:近期行为权重更高
VECTOR_MULTIPLY(p.content_vector,
EXP(-TIMESTAMPDIFF(DAY, ua.action_time, NOW()) / 30.0) *
-- 行为权重:深度互动权重更高
CASE ua.action_type WHEN 3 THEN 0.5 ELSE 0.1 END
)
)
)
FROM user_actions ua
JOIN posts p ON ua.post_id = p.post_id
WHERE ua.user_id = u.user_id
AND ua.action_time > DATE_SUB(NOW(), INTERVAL 30 DAY)
);双向量的好处
我们以一个例子来说明双向量的好处。有一个 RPG 游戏玩家小王,平时主要关注#剧情向的游戏,突然有一天显卡坏了,他需要去#电商平台 收显卡,此时如果只有一个向量表示,他的定位可能就变成了显卡硬件发烧友,但实际上小王买完显卡后可能又去#玩游戏 了。因此,基于用户建模的双向量既保留了小王长期稳定的 RPG 游戏数据,又保留了短期的即时兴趣数据,对用户画像的判定更准确。
一体化智能推荐系统的收益总结
如图8所示,我们在 UGC 社区智能推荐系统使用 OceanBase 后:推荐延迟从之前的200ms降低至50ms;存储空间节省了40%;运维复杂度由之前的运维4套系统到如今的运维1套系统,简化75%、此外,完全解决了使用传统架构时系统偶发数据不一致的问题。
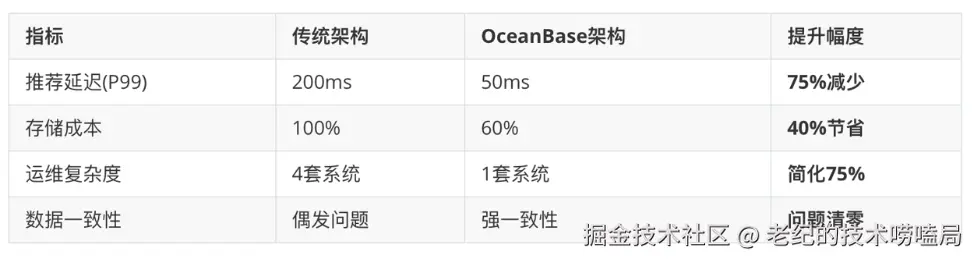
图8 UGC 社区智能推荐系统使用 OceanBase 的收益
以上就是我们公司对向量数据库的选型及应用经验,虽然公司业务围绕游戏,但客服与推荐系统场景较为普遍,希望我们的经验能给大家带来参考价值。
最后为大家推荐这个 OceanBase 开源负责人老纪的公众号「老纪的技术唠嗑局」,会持续更新和 #数据库 、#AI 、#技术架构 相关的各种技术内容。欢迎感兴趣的朋友们关注!
「老纪的技术唠嗑局」不仅希望能持续给大家带来有价值的技术分享,也希望能和大家一起为开源社区贡献一份力量。如果你对 OceanBase 开源社区认可,点亮一颗小星星✨吧!你的每一个Star,都是我们努力的动力。