总目录 大模型相关研究:https://blog.csdn.net/WhiffeYF/article/details/142132328
https://arxiv.org/pdf/2402.14836
https://www.doubao.com/chat/19815566713551106
文章目录
- 速览
- 攻击方法速览
-
-
- 一、攻击核心目标与前提
-
- [1. 核心目标](#1. 核心目标)
- [2. 攻击前提](#2. 攻击前提)
- [二、模型无关的简单攻击(Victim Model-Agnostic Attack)](#二、模型无关的简单攻击(Victim Model-Agnostic Attack))
-
- [1. 基于正向词插入的简单攻击(Trivial Attack with Word Insertion)](#1. 基于正向词插入的简单攻击(Trivial Attack with Word Insertion))
- [2. 基于GPT的文本重写攻击(Re-writing with GPTs)](#2. 基于GPT的文本重写攻击(Re-writing with GPTs))
- [三、黑盒文本攻击(Black-Box Text Attacks)](#三、黑盒文本攻击(Black-Box Text Attacks))
-
- [1. 黑盒攻击的核心框架](#1. 黑盒攻击的核心框架)
- [2. 4种具体黑盒攻击方案](#2. 4种具体黑盒攻击方案)
- 四、攻击方法的关键特性验证
- 五、攻击的影响因素与局限性
-
- [1. 影响攻击效果的关键因素](#1. 影响攻击效果的关键因素)
- [2. 局限性](#2. 局限性)
-
- 论文翻译
-
- 针对基于大型语言模型的推荐系统的隐蔽攻击
- 摘要
- [1 引言](#1 引言)
速览
ACL 2024 | 大语言模型推荐系统的隐秘攻击
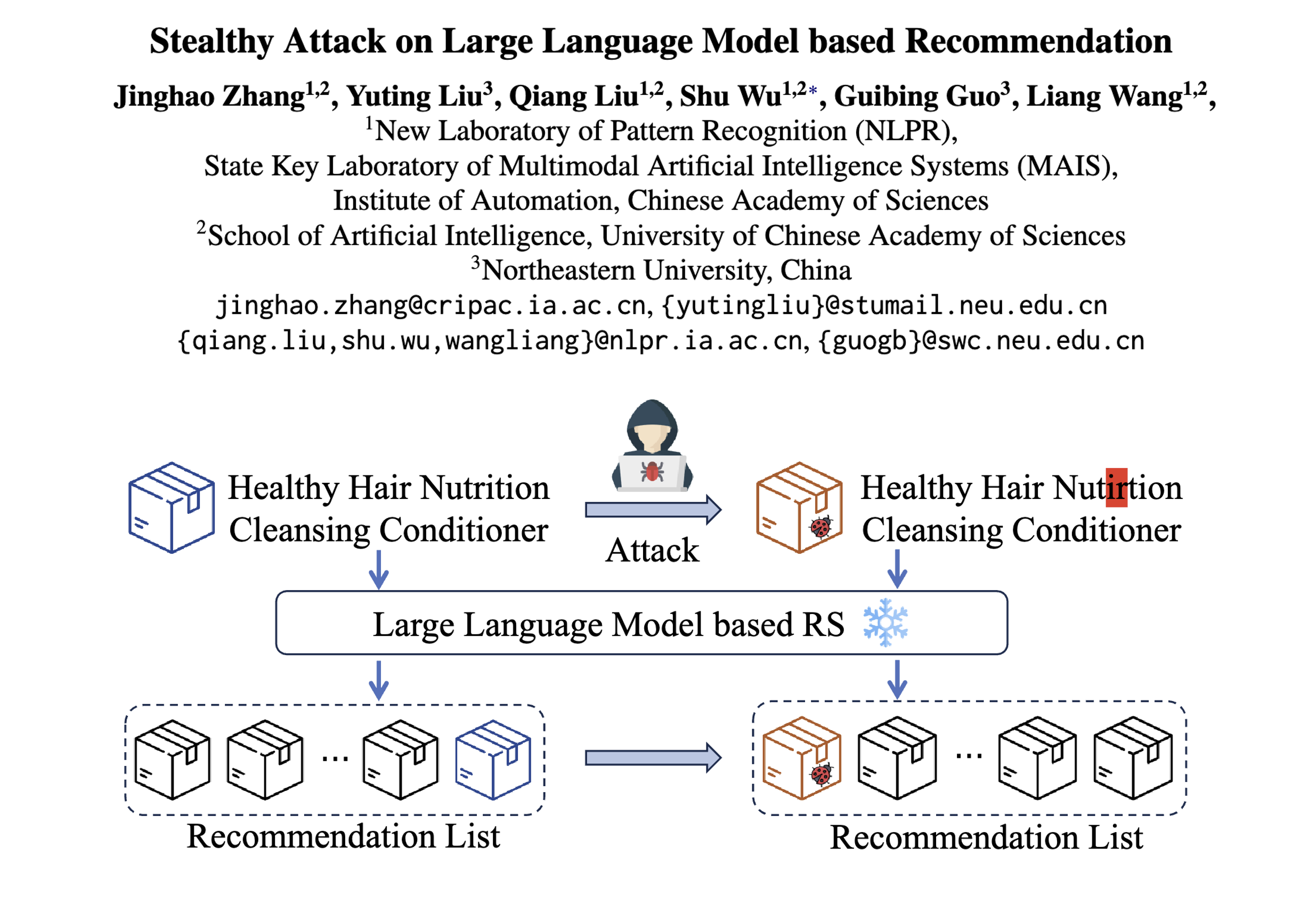
该论文发表于 ACL 2024,聚焦于大语言模型(LLM)在推荐系统中的应用及其潜在的安全漏洞。随着 LLM 的强大能力推动推荐系统的发展,其安全性问题却常被忽视。研究者们发现,攻击者仅需在测试阶段修改项目文本内容,无需干扰模型训练过程,就能显著提升项目曝光率。这种攻击方式极其隐秘,不会影响整体推荐性能,且文本修改细微,难以被用户和平台察觉。
论文通过在四个主流的 LLM 基推荐模型上进行实验,验证了该攻击方法的有效性和隐蔽性。研究还探讨了模型微调和项目热度对攻击的影响,以及攻击在不同模型和任务间的迁移性。此外,论文提出了一种简单的重写防御策略,虽不能完全抵御文本攻击,但能提供一定防御效果。
该研究揭示了 LLM 基推荐系统在文本内容上的安全漏洞,为未来保护这些系统提供了研究方向。随着 LLM 在推荐领域的广泛应用,如何增强其安全性成为亟待解决的问题。
攻击方法速览
这篇论文聚焦于基于大型语言模型(LLM)的推荐系统(RS)的安全性漏洞,提出了文本篡改攻击范式 ------通过微调目标物品的文本内容(如标题、描述),在不干扰模型训练过程的前提下提升物品曝光度,同时具备高隐蔽性。论文设计的攻击方法可分为模型无关的简单攻击 和黑盒文本攻击两大类,以下是具体拆解:
一、攻击核心目标与前提
1. 核心目标
在不影响推荐系统整体性能、不被用户/平台察觉的前提下,通过修改目标物品(如低质商品、虚假新闻)的文本内容,显著提升其在推荐列表中的曝光率(Exposure)或用户交互概率(Purchasing Propensity)。
2. 攻击前提
基于LLM的推荐系统与传统ID驱动型RS的核心差异------LLM-RS依赖文本的语义理解能力(如物品标题、用户历史行为的文本化表达),因此文本内容成为攻击的关键突破口,无需像传统"托攻击(Shilling Attack)"那样注入虚假用户数据。
二、模型无关的简单攻击(Victim Model-Agnostic Attack)
这类方法无需了解推荐模型的内部参数或结构,仅通过基础文本修改策略提升物品"吸引力",操作简单且易实施,包括两种具体方案:
1. 基于正向词插入的简单攻击(Trivial Attack with Word Insertion)
- 核心逻辑:假设"正向词汇"或"感叹词"能提升文本对LLM的吸引力,进而增加推荐概率。
- 具体操作 :
- 构建一个预定义的正向词库,包含常见于商品标题的积极词汇,如"good""great""best""excellent""!!!"等(共32个词);
- 从词库中随机选择
k个词,插入到原始物品标题的末尾,确保文本整体连贯性(如将"Healthy Hair Cleansing Conditioner"改为"Healthy Hair Cleansing Conditioner best quality!!!")。
- 优缺点:优点是实现成本极低,不破坏文本核心语义;缺点是可能导致文本略显生硬(如堆砌正向词),部分场景下可能引发用户怀疑。
2. 基于GPT的文本重写攻击(Re-writing with GPTs)
- 核心逻辑:利用GPT的常识知识和生成能力,将原始标题重写为"更具吸引力但不改变核心含义"的版本,解决简单插入正向词的"生硬问题"。
- 具体操作 :
- 采用GPT-3.5-turbo作为生成模型,设计3类提示词(Prompt)引导重写,确保文本流畅性和吸引力:
- Prompt 1(营销视角):"作为促进商品销售的营销专家,将标题重写为个词,保留核心信息但更吸引客户";
- Prompt 2(创意视角):"将基础标题转化为独特、抓眼球的词标题,提升关注度";
- Prompt 3(正向词融合视角):"融入正向词汇重写标题,不改变原意且更吸引潜在用户";
- 限制重写后的标题长度(),避免文本过长影响推荐模型处理。
- 采用GPT-3.5-turbo作为生成模型,设计3类提示词(Prompt)引导重写,确保文本流畅性和吸引力:
- 优缺点:优点是文本自然度高、隐蔽性强(用户难以察觉修改);缺点是依赖外部大模型,且效果受提示词设计影响较大。
三、黑盒文本攻击(Black-Box Text Attacks)
这类方法是论文的核心创新,针对LLM-RS的文本依赖漏洞,通过"黑盒交互"(无需访问模型参数/梯度,仅通过查询模型输出调整攻击策略)生成对抗性文本,实现更高效的攻击。论文基于经典黑盒文本攻击框架(Morris et al., 2020),拆解为四大核心组件,并实现了4种具体攻击方案。
1. 黑盒攻击的核心框架
攻击目标可通过数学公式定义为:
a r g m a x t i ′ E u ∈ U ′ f θ ( P u , i ′ ) \underset{t_{i}'}{arg max } \mathbb{E}{u \in \mathcal{U}'} f{\theta}\left(\mathcal{P}_{u, i}'\right) ti′argmaxEu∈U′fθ(Pu,i′)
其中, t i ′ t_i' ti′是修改后的目标物品文本, P u , i ′ \mathcal{P}{u,i}' Pu,i′是包含 t i ′ t_i' ti′的推荐模型输入提示(如用户历史文本+修改后物品文本), f θ f\theta fθ是LLM推荐模型,目标是最大化用户 U ′ \mathcal{U}' U′对 t i ′ t_i' ti′的推荐评分期望。
框架的四大组件分工如下:
| 组件 | 核心作用 | 论文实现细节 |
|---|---|---|
| 目标函数 | 评估修改后文本的攻击效果,指导搜索最优对抗文本 | 以"目标物品曝光率提升幅度"或"用户交互概率提升幅度"为核心指标,设置阈值(如0.05)判断攻击是否成功 |
| 约束条件 | 确保修改后的文本"有效且隐蔽",避免被检测 | 1. 语义一致性:原始文本与修改后文本的余弦相似度≥0.8;2. 词性一致性:不改变核心词的词性;3. 长度约束:修改前后文本长度差异较小 |
| 文本变换 | 生成可能的文本修改方案(即"扰动") | 包括字符级变换(如替换字符、插入标点)和词级变换(如同义词替换、掩码词预测) |
| 搜索方法 | 迭代查询模型,筛选最优扰动方案 | 采用"基于词重要性的贪心搜索(GreedyWordSwapWIR)",优先修改对推荐结果影响大的词 |
2. 4种具体黑盒攻击方案
论文实现了字符级和词级两类攻击,覆盖不同修改粒度,具体差异如下表:
| 攻击方法 | 攻击粒度 | 核心变换策略 | 特点 |
|---|---|---|---|
| DeepwordBug | 字符级 | 通过字符级扰动生成拼写错误:1. 随机删除字符;2. 随机插入字符;3. 相邻字符交换;4. 随机替换字符(如将"People"改为"ePople") | 修改痕迹极细微(仅单个字符),隐蔽性强;无需外部词库支持 |
| PuncAttack | 字符级 | 在文本中插入特定标点符号(如"-""'"),如将"Little People"改为"Little P-eople"或"Little Peo'ple" | 不破坏语义和词形,用户难以察觉;计算成本低 |
| TextFooler | 词级 | 基于词嵌入相似度替换同义词:1. 计算原始词的词嵌入(如GloVe);2. 筛选相似度≥0.6的同义词;3. 替换核心词(如将"People"改为"Inhabitants") | 攻击效果强(曝光率提升幅度大);但依赖高质量词嵌入,部分替换可能生硬 |
| BertAttack | 词级 | 基于掩码语言模型(BERT)预测替换词:1. 将原始词掩码(如"Little MASK");2. 选择BERT预测概率Top48的词作为替换候选;3. 筛选语义一致的词替换 | 替换词更符合上下文逻辑,文本自然度高;但需查询BERT模型,成本较高 |
四、攻击方法的关键特性验证
论文通过实验验证了攻击方法的有效性 和隐蔽性,核心结论如下:
- 有效性:黑盒攻击的曝光率提升幅度远超传统托攻击(Shilling Attack)------如TextFooler在Beauty数据集上使目标物品曝光率提升520.4%,而传统Bandwagon攻击仅提升约1%;
- 隐蔽性 :
- 对推荐系统整体性能无影响:攻击后模型的NDCG@10、Recall@10等指标与"无攻击"状态几乎一致(差异≤0.5%);
- 文本质量高:修改后文本与原始文本的余弦语义相似度≥0.6,GPT-Neo评估的流畅度(Perplexity)接近原始文本;
- 修改量少:平均仅修改2-4个词(或字符),用户难以察觉。
五、攻击的影响因素与局限性
1. 影响攻击效果的关键因素
- 模型微调状态:零-shot的LLM-RS(未在目标数据集上微调)比微调后的模型更易受攻击------微调模型需更多查询次数(平均增加30%),且曝光率提升幅度降低20%-40%;
- 物品流行度:高流行度物品更易被攻击------高流行度物品的曝光率提升幅度比低流行度物品高30%-50%,且所需查询次数更少(平均减少15%);
- 跨模型/跨任务迁移性 :
- 跨任务迁移:攻击"直接推荐任务"生成的对抗文本,可迁移到"评分预测任务"(如P5模型),曝光率提升幅度保持80%以上;
- 跨模型迁移:仅在相同 backbone 的模型间可迁移(如基于LLaMA的TALLRec和CoLLM),不同backbone(如Longformer的RecFormer)间无迁移性。
2. 局限性
- 黑盒查询依赖:黑盒攻击需多次查询推荐模型(如BertAttack平均需140次查询),在大规模工业级推荐系统中可能触发频率限制;
- 仅针对文本模态:当前攻击仅修改文本内容,未涉及图像、视频等其他模态(如商品图片),实际场景中多模态推荐系统可能降低攻击效果;
- 部分防御可缓解:基于GPT的文本重写防御(如修正拼写错误、删除多余标点)可有效抵御字符级攻击(如DeepwordBug、PuncAttack),但对词级攻击(如TextFooler)防御效果有限。
综上,论文提出的文本篡改攻击范式,通过"微调文本+黑盒交互"精准利用LLM-RS的文本依赖漏洞,兼具高效性和隐蔽性,为LLM推荐系统的安全防护提供了关键研究方向。
论文翻译
针对基于大型语言模型的推荐系统的隐蔽攻击
摘要
近年来,功能强大的大型语言模型(LLM)在推动推荐系统(RS)发展方面发挥了重要作用。然而,尽管这些系统蓬勃发展,其在安全威胁面前的脆弱性却在很大程度上被忽视。在本研究中,我们发现,将大型语言模型引入推荐模型会带来新的安全漏洞,这一问题源于模型对物品文本内容的重视。我们证明,攻击者只需在测试阶段修改目标物品的文本内容,无需直接干扰模型的训练过程,就能显著提高该物品的曝光率。此外,这种攻击具有显著的隐蔽性------它不会影响推荐系统的整体性能,且对文本的修改十分细微,使用户和平台难以察觉。我们在四种主流的基于大型语言模型的推荐模型上开展了全面实验,结果表明我们提出的攻击方法具有出色的有效性和隐蔽性。本研究揭示了基于大型语言模型的推荐系统中一个重要的安全缺口,为未来保护这类系统的相关研究奠定了基础。
1 引言
在过去几十年里,推荐系统(RS)在各个领域都获得了重要地位。近年来,功能强大的大型语言模型(LLM)在推动推荐系统发展方面发挥了关键作用,针对推荐任务定制大型语言模型的研究关注度显著上升。
传统推荐模型严重依赖抽象且可解释性较低的基于ID的信息,与之不同的是,基于大型语言模型的推荐模型充分利用了大型语言模型的语义理解能力和强大的迁移能力。这种方法更加注重物品的文本内容,例如物品标题和描述(Lin等人,2023a;Chen等人,2023)。例如,许多研究者(Hou等人,2022,2023a;Yuan等人,2023;Li等人,2023a;Yang等人,2023;Geng等人,2022;Cui等人,2022;Bao等人,2023a;Zhang等人,2023b;Li等人,2023b;Zhang等人,2023c)已尝试从语言角度对用户偏好和物品特征进行建模。这种方法能够对新物品和新数据集实现泛化,有望为传统推荐范式带来革命性变革。
尽管取得了这些进展,推荐系统的安全性仍是一个在很大程度上未得到解决的问题。对这类系统的恶意攻击可能导致不良后果,例如在电子商务平台中不当推广低质量产品,或在新闻传播场景中扩散虚假信息。针对推荐系统的传统托攻击(shilling attack)策略(Wang等人,2023a,2024c)通常会生成虚假用户,这些虚假用户被设定为对特定目标物品给出高分评价。通过注入此类欺诈数据,攻击者旨在影响推荐模型的训练,进而提高目标物品的曝光率。
然而,将大型语言模型引入推荐模型会带来新的安全漏洞。在本文中,据我们所知,我们首次证明,由于对物品文本内容的重视,基于大型语言模型的推荐系统具有更高的脆弱性。我们发现,攻击者只需在测试阶段采用简单的启发式重写或黑盒文本攻击策略(Morris等人,2020)修改物品的文本内容,就能显著提高该物品的曝光率。与传统托攻击相比,这种攻击范式具有显著的隐蔽性------它无需影响模型训练,且推荐系统的整体性能几乎不受影响。此外,对物品标题的修改十分细微,使用户和平台难以察觉。
为了验证文本攻击范式相较于传统托攻击(Burke等人,2005b;Kaur和Goel,2016;Lin等人,2020)所具备的出色有效性和隐蔽性,我们以四种主流的基于大型语言模型的推荐模型(Geng等人,2022;Bao等人,2023a;Li等人,2023a;Zhang等人,2023c)作为攻击目标模型,开展了全面实验。我们进一步深入研究了模型微调程度和物品流行度对攻击效果的影响,同时还探究了该攻击在不同目标模型和推荐任务间的迁移能力,以证明其在实际场景中的适用性和实用性。最后,我们评估了一种简单的重写防御策略,该策略在一定程度上能够缓解上述安全问题。
综上所述,本研究的贡献如下:
- 我们指出,基于大型语言模型的推荐模型由于对文本内容信息的重视,可能会引发此前被忽视的安全问题。
- 据我们所知,我们是首个针对基于大型语言模型的推荐模型发起攻击的研究团队,并提出通过文本攻击来提高目标物品的曝光率。
- 我们开展了大量实验,以证明文本攻击范式的有效性和隐蔽性。进一步的实验还揭示了物品流行度和模型微调程度对攻击效果的影响,并探究了攻击的迁移能力。
- 最后,我们提出了一种简单的重写防御策略。该策略虽无法完全抵御基于文本的攻击,但能提供一定程度的防护,为未来相关研究提供参考。