在数据库开发中,事务是保证数据一致性的核心机制。无论是电商下单、银行转账还是物流调度,都离不开事务的支撑。本文将从事务的基础概念出发,深入剖析其 ACID 特性的实现原理。
一.事物的特性:
事务的可靠性由四大特性(ACID)保证。
1. 原子性(Atomicity):
定义 :要么全成,要么全败,事务中的所有操作是一个不可分割的整体,一旦某一步执行失败,已执行的操作会全部回滚,数据库恢复到事务开始前的状态。
实现原理:Undo Log(回滚日志)
InnoDB 通过 Undo Log 实现原子性,它的核心作用是 "记录数据修改前的状态",以便回滚时恢复数据。
- 执行过程 :
当事务执行UPDATE/DELETE/INSERT时,InnoDB 会先将数据的 "旧值"(修改前的状态)写入 Undo Log,再执行实际的修改操作。
例如执行UPDATE account SET balance = 900 WHERE id=1(原 balance 为 1000),Undo Log 会记录 "id=1 的 balance 原本是 1000"。 - 回滚逻辑 :
若事务需要回滚(执行ROLLBACK),InnoDB 会读取 Undo Log 中的旧值,将数据恢复到修改前的状态。 - Undo Log 的额外作用:还用于实现 "MVCC 多版本并发控制"(后面隔离级别会讲到)。
2. 一致性(Consistency):
定义 :数据从一个一致态到另一个一致态,事务执行前后,数据库的数据必须满足预设的 "一致性规则"(如业务约束、数据完整性约束)。
例如转账场景中,"A 和 B 的余额总和" 就是一个一致性规则 ------ 事务执行前总和为A_balance + B_balance,执行后总和仍保持不变(即使中间步骤失败,回滚后也会恢复总和)。
实现原理:多特性协同保证
一致性是事务的 "最终目标",它不是由单一机制实现的,而是依赖于原子性、隔离性和持久性的协同作用:
- 原子性保证操作要么全成要么全败,避免中间态;
- 隔离性保证并发事务不相互干扰,避免脏数据影响;
- 持久性保证提交后数据不丢失,确保一致态的稳定。
此外,业务层的约束(如主键唯一、外键关联、CHECK 约束)也会辅助保证一致性。
3. 隔离性(Isolation):
定义 :并发事务互不干扰,多个事务并发执行时,每个事务的操作对其他事务是 "隔离" 的,不会出现相互干扰的情况。
MySQL 通过 "隔离级别" 控制隔离程度,隔离级别越低,并发性能越高,但数据一致性越弱;反之则并发性能越低,一致性越强。
(1)并发事务的4类问题
在讲解隔离级别前,先明确不控制隔离时可能出现的异常:
| 异常类型 | 含义说明 |
|---|---|
| 脏读(Dirty Read) | 事务 A 读取到事务 B 未提交的修改,若 B 回滚,A 读取的就是 "脏数据"。 |
| 不可重复读(Non-Repeatable Read) | 事务 A 多次读取同一数据,期间事务 B 修改并提交该数据,导致 A 前后读取结果不一致。 |
| 幻读(Phantom Read) | 事务 A 多次执行同一范围查询(如 WHERE id < 10),期间事务 B 插入 / 删除符合条件的数据,导致 A 前后查询的 "行数" 不一致。 |
| 丢失更新(Lost Update) | 事务 A 和 B 同时修改同一数据,后提交的事务覆盖先提交的修改。 |
(2)MySQL 的4种隔离级别
SQL 标准定义了 4 种隔离级别,InnoDB 对其做了优化实现:
| 隔离级别 | 脏读 | 不可重复读 | 幻读 | 并发性能 | 实现核心机制 |
|---|---|---|---|---|---|
| 读未提交(Read Uncommitted) | 可能 | 可能 | 可能 | 最高 | 无特殊机制,直接读取最新数据 |
| 读已提交(Read Committed) | 不可能 | 可能 | 可能 | 较高 | MVCC(多版本并发控制) |
| 可重复读(Repeatable Read) | 不可能 | 不可能 | 不可能(InnoDB 优化) | 中等 | MVCC + 间隙锁(Gap Lock) |
| 串行化(Serializable) | 不可能 | 不可能 | 不可能 | 最低 | 表级锁,强制事务串行执行 |
注意 :MySQL 默认隔离级别是 可重复读 (Repeatable Read),而 Oracle、SQL Server 默认是 "读已提交"。
(3)隔离级别的实现原理
隔离性的核心实现依赖 MVCC 和 锁机制,这里重点讲解最常用的 "读已提交" 和 "可重复读":
- MVCC(多版本并发控制):
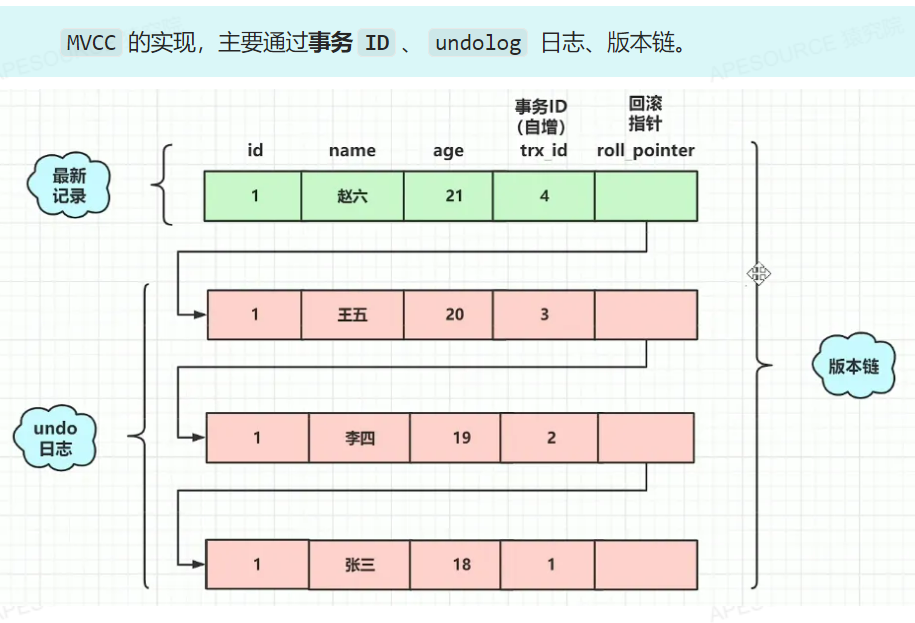
Read View事务在执行SQL时,会产生一个ReadView数据快照,用于判断当前事务可见哪个版本的数据。
ReadView中保存了四个重要字段:
●m_ids:通过一个List数据结构,保存未提交的活跃读写事务ID。
●min_limit_id:表示生成Read View时,活跃读写事务中最小的事务id,即m_ids中的最小值。
●max_limit_id:表示生成Read View时,系统中应该分配给下一个事务的id值。
●creator_trx_id: 创建当前Read View的事务ID。
可见性判断规则:
当事务查询数据时,会从版本链的最新版本开始,通过 Read View 判断该版本是否可见。若不可见,则沿DB_ROLL_PTR回溯到上一个版本,重复判断,直到找到可见版本或版本链结束(返回空)。
对于版本链中的某个版本( DB_TRX_ID 为trx_id),当前事务能否看到它,取决于:
1.若trx_id == creator_trx_id:该版本由当前事务修改,可见;
2.若trx_id < min_trx_id:修改该版本的事务在当前事务生成 Read View 前已提交,可见;
3.若trx_id > max_trx_id:修改该版本的事务在当前事务生成Read View 后才启动,不可见;
4.若min_trx_id ≤ trx_id ≤ max_trx_id:
○若trx_id在m_ids中(即修改事务仍活跃),不可见;
○若trx_id不在m_ids中(即修改事务已提交),可见
MVCC执行流程
- 获取事务的版本号,即事务ID
- 获取Read View
- 查询得到的数据,然后Read View中的事务版本号进行比较。
- 如果不符合Read View的可见性规则, 即就需要Undo log中历史快照;
- 最后返回符合规则的数据
- 所以,InnoDB 实现MVCC,是通过Read View+ Undo Log 实现的,Undo Log 保存了历史快照,Read View可见性规则帮助判断当前版本的数据是否可见
- 间隙锁(Gap Lock) :
InnoDB 在 "可重复读" 级别下通过间隙锁防止幻读。例如执行SELECT * FROM account WHERE id BETWEEN 1 AND 10 FOR UPDATE时,不仅会锁定 id=1~10 的行,还会锁定 "1~10 之间的间隙"(如 id=5 不存在,也会锁定该位置),防止其他事务插入 id 在 1~10 之间的数据。
4. 持久性(Durability):
定义 :提交后数据永久保存,事务一旦提交(COMMIT),其对数据的修改就会永久保存到数据库中,即使发生系统崩溃、断电等故障,数据也不会丢失。
实现原理:Redo Log(重做日志)
持久性依赖 Redo Log 和 刷盘机制,InnoDB 采用 "Write-Ahead Logging(WAL)" 策略:先写日志,再写磁盘。
- Redo Log 的作用 :记录数据 "修改后的状态",用于系统崩溃后恢复未刷盘的数据。
- 执行过程:
- 事务执行修改操作时,先将 "数据的新值" 写入 Redo Log Buffer(内存缓冲区);
- 事务提交时,将 Redo Log Buffer 中的内容刷新到 Redo Log File(磁盘文件)------ 这一步是 "持久性" 的关键;
- 后台线程会定期将内存中的数据页(Dirty Page)刷新到磁盘数据文件(.ibd)。
二.事务的基础操作:
1. 开启事务
有两种方式开启事务,效果完全一致:
sql
java
-- 方式 1:START TRANSACTION
START TRANSACTION;
-- 方式 2:BEGIN(简化写法)
BEGIN;2. 提交事务
事务执行成功后,通过COMMIT永久保存修改:
sql
java
COMMIT;提交后,Redo Log 会被标记为 "已完成",Undo Log 会被清理(或标记为可复用)。
3. 回滚事务
事务执行失败时,通过R撤销所有操作:
sql
java
ROLLBACK;回滚时,InnoDB 会读取 Undo Log 恢复数据到事务开始前的状态。
4. 保存点(Savepoint)
如果事务中包含多个步骤,可通过 "保存点" 实现 "部分回滚",无需回滚整个事务:
sql
java
-- 1. 开启事务
BEGIN;
-- 2. 执行操作 1:A 账户减 1000
UPDATE account SET balance = balance - 1000 WHERE id = 1;
-- 3. 设置保存点 sp1
SAVEPOINT sp1;
-- 4. 执行操作 2:B 账户加 1000(假设这里执行失败)
UPDATE account SET balance = balance + 1000 WHERE id = 2;
-- 5. 回滚到保存点 sp1(只撤销操作 2,保留操作 1)
ROLLBACK TO sp1;
-- 6. 检查数据无误后提交(此时仅操作 1 生效)
COMMIT;
-- 7. (可选)删除保存点
RELEASE SAVEPOINT sp1;5. 自动提交设置
MySQL 默认开启 "自动提交"( autocommit=1),即每条 SQL 语句都会被当作一个独立的事务自动提交。如果需要手动控制事务,建议先关闭自动提交:
sql
java
-- 查看当前自动提交状态(1=开启,0=关闭)
SELECT @@autocommit;
-- 关闭自动提交(仅当前会话有效)
SET autocommit = 0;