点一下关注吧!!!非常感谢!!持续更新!!!
🚀 AI篇持续更新中!(长期更新)
AI炼丹日志-31- 千呼万唤始出来 GPT-5 发布!"快的模型 + 深度思考模型 + 实时路由",持续打造实用AI工具指南!📐🤖
💻 Java篇正式开启!(300篇)
目前2025年09月08日更新到: Java-118 深入浅出 MySQL ShardingSphere 分片剖析:SQL 支持范围、限制与优化实践 MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解
章节内容
上节我们完成了如下的内容:
- SparkSQL 核心操作
- Action操作 详细解释+测试案例
- Transformation操作 详细解释+测试案例

SQL 语句详解
SparkSQL概述
SparkSQL是Apache Spark框架中的一个核心模块,专门用于处理结构化和半结构化数据。它提供了对数据进行查询、处理和分析的高级接口,既支持命令式编程风格,又支持声明式查询方式。
兼容性特点
总体而言:SparkSQL与HQL高度兼容,但在语法上比HQL更加简洁高效。这种兼容性主要体现在:
- 语法结构相似性达到90%以上
- 支持Hive的大部分UDF函数
- 可以直接读取Hive表数据
核心特性深入解析
1. DataFrame API
DataFrame是SparkSQL中的核心抽象,它本质上是一个分布式数据集,具有以下特点:
- 数据结构:以命名列的形式组织数据,类似于关系数据库中的表
- 数据源支持 :
- 关系型数据库:通过JDBC连接
- 文件系统:Parquet、JSON、CSV、ORC等格式
- Hive表:直接读取Hive元数据
- 其他:Avro、Cassandra等
使用示例:
python
# 创建DataFrame
df = spark.read.json("examples/src/main/resources/people.json")
# 显示数据
df.show()2. SQL查询能力
SparkSQL提供了完整的SQL支持,包括:
- 标准SQL语法:支持SELECT、JOIN、GROUP BY等常规操作
- 高级功能:窗口函数、子查询、CTE等
- 执行过程:SQL查询会被自动转换为逻辑计划,经过优化后生成物理执行计划,最终转换为RDD操作
查询示例:
sql
-- 注册临时视图
CREATE TEMPORARY VIEW people USING org.apache.spark.sql.json OPTIONS (path "people.json")
-- 执行SQL查询
SELECT name, age FROM people WHERE age > 203. Hive集成机制
SparkSQL与Hive的集成主要体现在:
- 元数据共享:可以直接读取Hive Metastore中的表定义
- 语法兼容:支持绝大多数HiveQL语法
- 数据互通:可以读写Hive表数据
集成配置步骤:
- 将hive-site.xml复制到Spark配置目录
- 设置Hive Metastore连接参数
- 启动SparkSession时启用Hive支持
4. 性能优化体系
SparkSQL的优化技术包括:
Catalyst优化器
- 逻辑优化:常量折叠、谓词下推、列裁剪等
- 物理优化:选择最优的连接算法、确定分区策略等
Tungsten执行引擎
- 内存管理:使用sun.misc.Unsafe直接操作堆外内存
- 代码生成:运行时生成优化后的字节码
- CPU缓存优化:改进数据布局以提升缓存命中率
典型应用场景
- 数据仓库分析:替代传统Hive进行ETL处理
- 交互式查询:通过JDBC/ODBC接口支持BI工具连接
- 流批一体处理:结合Structured Streaming实现实时分析
- 机器学习数据准备:为MLlib提供特征工程支持
与HiveQL的主要区别
| 特性 | SparkSQL | HiveQL |
|---|---|---|
| 执行引擎 | Spark核心 | MapReduce/Tez |
| 内存计算 | 支持 | 有限支持 |
| 延迟 | 毫秒级到秒级 | 分钟级 |
| 语法复杂度 | 更简洁 | 相对冗长 |
| 容错机制 | 基于RDD的血统 | 基于中间结果持久化 |
通过以上对比可以看出,SparkSQL在保留HQL兼容性的同时,通过内存计算和优化技术显著提升了查询性能。
数据样例
shell
// 数据
1 1,2,3
2 2,3
3 1,2
// 需要实现如下的效果
1 1
1 2
1 3
2 2
2 3
3 1
3 2编写代码
scala
package icu.wzk
case class Info(id: String, tags: String)
object SparkSql01 {
def main(args: Array[String]): Unit = {
val sparkSession = SparkSession
.builder()
.appName("SparkSQLDemo")
.master("local[*]")
.getOrCreate()
val sc = sparkSession.sparkContext
sc.setLogLevel("WARN")
val arr = Array("1 1,2,3", "2 2,3", "3 1,2")
val rdd: RDD[Info] = sc
.makeRDD(arr)
.map{
line => val fields: Array[String] = line.split("\\s+")
Info(fields(0), fields(1))
}
import sparkSession.implicits._
implicit val infoEncoder = Encoders.product[Info]
val ds: Dataset[Info] = sparkSession.createDataset(rdd)
ds.createOrReplaceTempView("t1")
sparkSession.sql(
"""
| select id, tag
| from t1
| lateral view explode(split(tags, ",")) t2 as tag
|""".stripMargin
).show
sparkSession.sql(
"""
| select id, explode(split(tags, ","))
| from t1
|""".stripMargin
).show
sparkSession.close()
}
}运行测试
控制台输出结果为:
scala
+---+---+
| id|tag|
+---+---+
| 1| 1|
| 1| 2|
| 1| 3|
| 2| 2|
| 2| 3|
| 3| 1|
| 3| 2|
+---+---+
+---+---+
| id|col|
+---+---+
| 1| 1|
| 1| 2|
| 1| 3|
| 2| 2|
| 2| 3|
| 3| 1|
| 3| 2|
+---+---+运行结果
运行结果如下图所示: 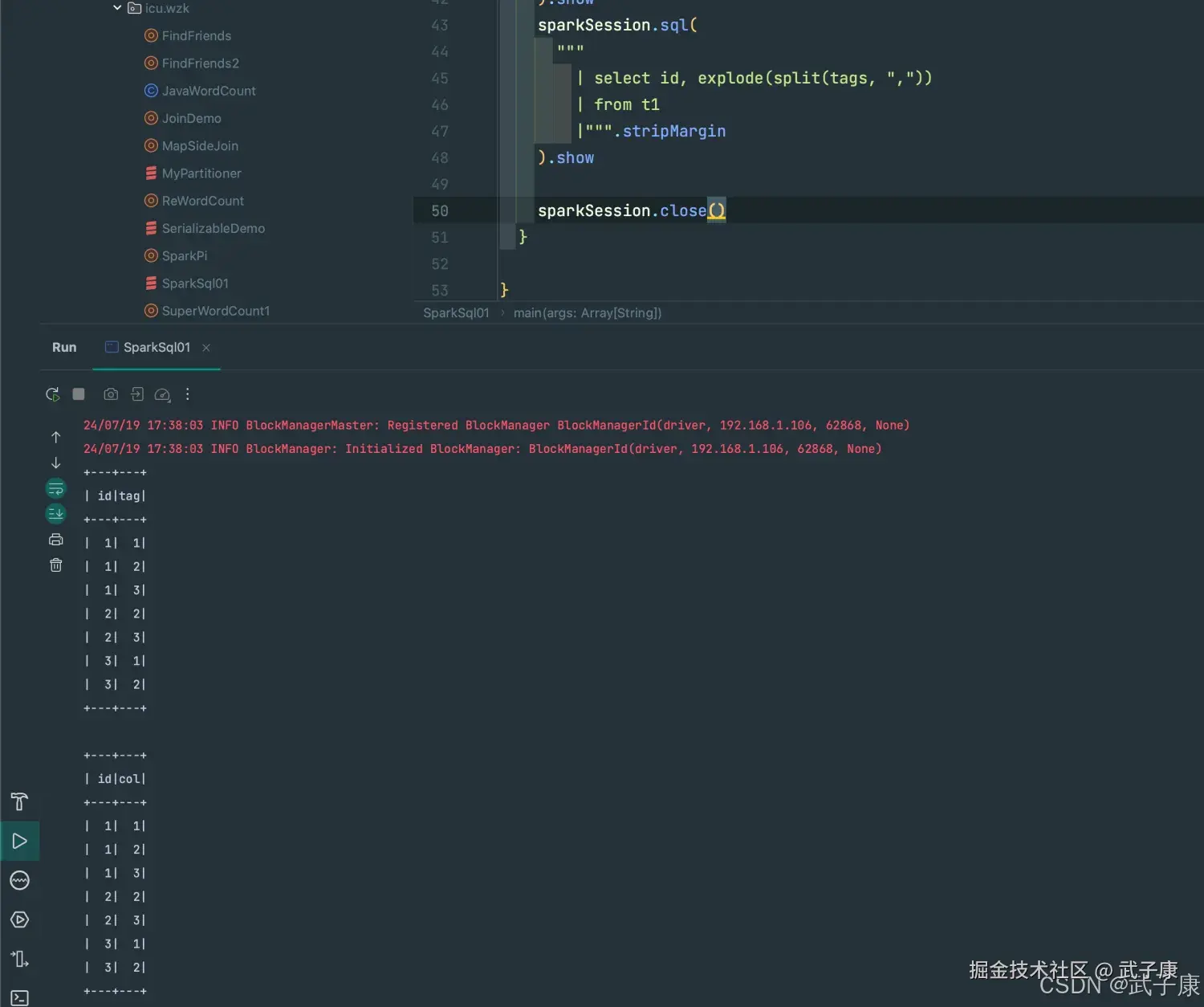
输入与输出
SparkSQL 内建支持的数据源包括:
- Parquet (默认数据源)
- JSON
- CSV
- Avro
- Images
- BinaryFiles(Spark 3.0)
简单介绍一下,Parquet 是一种列式存储格式,专门为大数据处理和分析而设计。
- 列式存储:Parquet 采用列式存储格式,这意味着同一列的数据存储在一起。这样可以极大地提高查询性能,尤其是当查询只涉及少量列时。
- 高效压缩:由于同一列的数据具有相似性,Parquet 能够更高效地进行压缩,节省存储空间。
- 支持复杂数据类型:Parquet 支持嵌套的数据结构,包括嵌套列表、映射和结构体,这使得它非常适合处理复杂的、半结构化的数据。
- 跨平台:Parquet 是一种开放标准,支持多种编程语言和数据处理引擎,包括 Apache Spark、Hadoop、Impala 等。

Parquet
特点:Parquet是一种列式存储格式,特别适合大规模数据的存储和处理。它支持压缩和嵌套数据结构,因此在存储效率和读取性能方面表现优异。
使用方式:spark.read.parquet("path/to/data") 读取Parquet文件;df.write.parquet("path/to/output") 将DataFrame保存为Parquet格式。
JSON
特点:JSON是一种轻量级的数据交换格式,广泛用于Web应用程序和NoSQL数据库中。SparkSQL能够解析和生成JSON格式的数据,并支持嵌套结构。
使用方式:spark.read.json("path/to/data") 读取JSON文件;df.write.json("path/to/output") 将DataFrame保存为JSON格式。
CSV
特点:CSV(逗号分隔值)是最常见的平面文本格式之一,简单易用,但不支持嵌套结构。SparkSQL支持读取和写入CSV文件,并提供了处理缺失值、指定分隔符等功能。
使用方式:spark.read.csv("path/to/data") 读取CSV文件;df.write.csv("path/to/output") 将DataFrame保存为CSV格式。
Avro
特点:Avro是一种行式存储格式,适合大规模数据的序列化。它支持丰富的数据结构和模式演化,通常用于Hadoop生态系统中的数据存储和传输。
使用方式:spark.read.format("avro").load("path/to/data") 读取Avro文件;df.write.format("avro").save("path/to/output") 将DataFrame保存为Avro格式。
ORC
特点:ORC(Optimized Row Columnar)是一种高效的列式存储格式,专为大数据处理而设计,支持高压缩率和快速读取性能。它在存储空间和I/O性能方面表现优越。
使用方式:spark.read.orc("path/to/data") 读取ORC文件;df.write.orc("path/to/output") 将DataFrame保存为ORC格式。
Hive Tables
特点:SparkSQL能够无缝集成Hive,直接访问Hive元数据,并对Hive表进行查询。它支持HiveQL语法,并能够利用Hive的存储格式和结构。
使用方式:通过spark.sql("SELECT * FROM hive_table")查询Hive表;也可以使用saveAsTable将DataFrame写入Hive表。
JDBC/ODBC
特点:SparkSQL支持通过JDBC/ODBC接口连接关系型数据库,如MySQL、PostgreSQL、Oracle等。它允许从数据库读取数据并将结果写回数据库。
使用方式:spark.read.format("jdbc").option("url", "jdbc:mysql://host/db").option("dbtable", "table").option("user", "username").option("password", "password").load() 读取数据库表;df.write.format("jdbc").option("url", "jdbc:mysql://host/db").option("dbtable", "table").option("user", "username").option("password", "password").save() 将DataFrame写入数据库。
Text Files
特点:SparkSQL可以处理简单的文本文件,每一行被读取为一个字符串。适合用于处理纯文本数据。
使用方式:spark.read.text("path/to/data") 读取文本文件;df.write.text("path/to/output") 将DataFrame保存为文本格式。
Delta Lake (外部插件)
特点:Delta Lake是一种开源存储层,构建在Parquet格式之上,支持ACID事务、可扩展元数据处理和流批一体的实时数据处理。尽管不是内建的数据源,但它在Spark生态系统中得到了广泛支持。
使用方式:spark.read.format("delta").load("path/to/delta-table") 读取Delta表;df.write.format("delta").save("path/to/delta-table") 将DataFrame保存为Delta格式。
测试案例
scala
val df1 =
spark.read.format("parquet").load("data/users.parquet")
// Use Parquet; you can omit format("parquet") if you wish as
it's the default
val df2 = spark.read.load("data/users.parquet")
// Use CSV
val df3 = spark.read.format("csv")
.option("inferSchema", "true")
.option("header", "true")
.load("data/people1.csv")
// Use JSON
val df4 = spark.read.format("json")
.load("data/emp.json")此外还支持 JDBC 的方式:
scala
val jdbcDF = sparkSession
.read
.format("jdbc")
.option("url", "jdbc:mysql://h122.wzk.icu/spark_test?useSSL=false")
.option("driver", "com.mysql.jdbc.Driver")
.option("user", "hive")
.option("password", "hive@wzk.icu")
.load()
jdbcDF.show()访问Hive

导入依赖
xml
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.12</artifactId>
<version>${spark.version}</version>
</dependency>hive-site
需要在项目的 Resource 目录下,新增一个 hive-site.xml 备注:最好使用 metastore service连接Hive,使用直接metastore的方式时,SparkSQL程序会修改Hive的版本信息
xml
<configuration>
<property>
<name>hive.metastore.uris</name>
<value>thrift://h122.wzk.icu:9083</value>
</property>
</configuration>编写代码
scala
object AccessHive {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder()
.appName("Demo1")
.master("local[*]")
.enableHiveSupport()
// 设为true时,Spark使用与Hive相同的约定来编写Parquet数据
.config("spark.sql.parquet.writeLegacyFormat", true)
.getOrCreate()
val sc = spark.sparkContext
sc.setLogLevel("warn")
spark.sql("show databases").show
spark.sql("select * from ods.ods_trade_product_info").show
val df: DataFrame = spark.table("ods.ods_trade_product_info")
df.show()
df.write.mode(SaveMode.Append).saveAsTable("ods.ods_trade_product_info_back")
spark.table("ods.ods_trade_product_info_back").show
spark.close()
}
}