1、I/O多路复用技术
| 特性维度 | Java NIO (Selector) | kqueue (FreeBSD/macOS) | epoll (Linux) | io_uring (Linux) |
|---|---|---|---|---|
| 操作系统支持 | 跨平台 (基于各平台原生API封装) | FreeBSD, macOS, iOS | Linux | Linux (内核5.1+) |
| 设计哲学 | 跨平台的抽象层 | 通用事件通知机制 | 高性能网络事件通知 | 真正的异步I/O,零拷贝 |
| 核心机制 | 基于 select/poll/epoll/kqueue 的封装 | 事件过滤器 (kevent) | 红黑树管理fd,就绪链表 | 双环形队列 (SQ, CQ),共享内存 |
| 最大连接数 | 受限于平台底层机制 | 非常高 | 非常高 | 非常高 |
| I/O效率 | 依赖底层实现 | 较高 | 高 | 极高 (批处理、减系统调用、减拷贝) |
| 代码复杂度 | 低 (Java API封装) | 中 | 中 | 高 (需管理内存、队列) |
| 典型应用场景 | 需要跨平台的Java高性能网络应用 | BSD系平台的高性能网络服务 | Linux高性能网络服务 (Nginx, Redis) | Linux极致性能场景 (数据库、存储) |
2、proactor、reactor
1、proactor模式
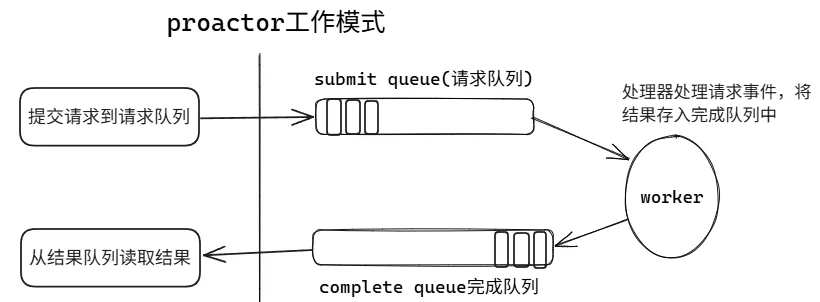
两个无锁的、单生产者单消费者的环形缓冲区 (Ring Buffer) ,分别用于提交请求和接收完成事件。用户态和内核态通过共享内存访问这两个环,极大地减少了系统调用的开销和上下文切换。
- 提交队列 (Submission Queue, SQ) :
- 一个环,用于应用程序 向内核提交异步 I/O 请求(如读、写、接受连接等)。
- 应用程序是生产者(将请求放入 SQ),内核是消费者(从 SQ 取走请求)。
- 完成队列 (Completion Queue, CQ) :
- 一个环,用于内核 向应用程序通知 I/O 操作的完成情况。
- 内核是生产者(将完成事件放入 CQ),应用程序是消费者(从 CQ 取走完成事件)。
linux io-uring
window iocp
2、reactor模式
单 Reactor 单线程:
- 所有步骤(事件循环、Acceptor、Handler 的业务处理)都在一个线程内完成。
- 优点: 简单,无锁,无并发问题。
- 缺点: Handler 中的业务处理会阻塞事件循环,影响其他连接的响应。
- 适用: 业务处理非常快的场景,如 Redis。
单 Reactor 多线程:
- Reactor(事件循环)运行在单独一个线程。
- 当有数据可读时,Reactor 将读取到的数据包(一个任务)派发 到一个线程池中进行业务处理。处理完成后,线程池将结果返回给 Handler,Handler 再向 Reactor 注册可写事件,由 Reactor 线程负责发送结果。
- 优点: 业务处理不阻塞事件循环。
- 缺点: Reactor 线程仍是瓶颈,数据进出需要线程间通信。
主从 Reactor 多线程:
- Main Reactor : 主线程,只负责监听和接受新连接,然后将新连接分发给 Sub Reactor。
- Sub Reactor : 有多个,每个都在自己的线程中运行独立的事件循环。Main Reactor 将新连接均衡地分配给一个 Sub Reactor。该连接的所有后续 I/O 事件都由这个 Sub Reactor 负责。
- 线程池: 负责处理非 I/O 的业务逻辑。
- 优点: 职责明确,性能与扩展性极佳。Main Reactor 快速接受连接,Sub Reactor 充分使用多核处理 I/O。
- 适用: 绝大多数高性能网络服务器,如 Netty、Nginx。
3、优化
1、SO_REUSEPORT 特性
它允许多个进程或线程绑定到完全相同的 IP 地址和端口组合,并由内核进行负载均衡,从而提升多核系统上网络服务器应用的性能
2、sendfile/mmap
java
sendfile 追求极致网络传输性能,发送静态大文件(如视频、下载文件)
mmap 需要对文件内容进行随机访问、读写、修改,或进行进程间共享内存通信
mmap 可用于实现共享内存,是高效的 IPC 方式之一。多个进程可以映射同一个文件或匿名内存区域,实现对共享数据的直接读写,速度远快于管道、消息队列等3、Network Interface Card
RSS (Receive Side Scaling):- 接收方扩展,硬件根据数据包哈希分发到不同RX队列。
RPS(Receive Packet Steering) - 接收数据包引导
RFS(Receive Flow Steering):-是RPS的功能扩展,其目标是提高CPU缓存命中率,减少网络延迟
XPS(Transmit Packet Steering)- 发送数据包引导,则根据当前处理软中断的CPU选择网卡发包队列,适合于多队列网卡,主要为了避免CPU由RX队列的中断进入到TX队列的中断时发生切换,导致CPU cache失效损失性能
- RX队列(Receive Queue, 接收队列):临时存放从网络上传来的数据包。
- TX队列(Transmit Queue, 发送队列):临时存放即将要发送到网络上的数据包。
LRO(Large Receive Offloading) 和 GRO(Generic Receive Offloading)是接收方向的包合并技术
TSO(TCP Segmentation Offload)和GSO(Generic Segmentation Offload)提升网络传输效率并降低CPU负载
4、TCP
- TCP Fast Open (TFO)
在 TCP 三次握手完成之前就开始传输数据,从而降低网络延迟。
- 拥塞控制算法
CUBIC
BBR(Bottleneck Bandwidth and Round-trip propagation time)
- 延迟策略
TCP_NODELAY 选项禁用Nagle算法,减少延迟但可能增加小包数量
TCP_CORK 与TCP_NODELAY相反,它尽可能多地合并数据包。
- 套接字缓冲区大小
java
sysctl -w net.ipv4.tcp_rmem='4096 131072 16777216' # 最小、默认、最大接收缓冲区
sysctl -w net.ipv4.tcp_wmem='4096 16384 16777216' # 发送缓冲区
sysctl -w net.core.rmem_max=16777216
sysctl -w net.core.wmem_max=16777216