前言
在AI浪潮席卷全球的今天,Java工程师如何守住后端主战场?模型部署正是Java工程师融入AI领域的方向。
为什么Java工程师必须掌握模型部署?
- 现实困境:Python训练模型,生产环境却需要低延迟、高并发的Java服务。
- 核心优势:JVM生态的并发处理、内存管理和工程化能力远超Python。
- 战略要地:模型服务化(serving)是AI落地最后一公里,正是Java的主场!
一、模型导出
ONNX(开放神经网络交换格式)是我们的核心桥梁。
ini
# PyTorch导出示例(TensorFlow类似)
import torch
import torchvision
# 1. 加载预训练模型
model = torchvision.models.resnet18(pretrained=True)
model.eval()
# 2. 创建示例输入
dummy_input = torch.randn(1, 3, 224, 224)
# 3. 导出ONNX模型(关键步骤!)
torch.onnx.export(
model,
dummy_input,
"resnet18.onnx",
export_params=True,
opset_version=11,
input_names=["input"],
output_names=["output"]
)
AI写代码python
运行
123456789101112131415161718192021注意事项:
- 验证输入/输出张量维度。
- 使用onnx.checker验证模型有效性。
- 复杂模型可能需要自定义OP(尽量避免)。
二、Java推理引擎选型
| 引擎 | 推荐指数 | 优势 | 局限 |
|---|---|---|---|
| ONNX Runtime | ⭐⭐⭐⭐⭐ | 微软官方支持,性能顶尖 | 需额外转换ONNX |
| DeepJavaLibrary | ⭐⭐⭐☆ | 直接加载PyTorch模型 | 社区生态较小 |
| TensorFlow Java | ⭐⭐☆ | 原生支持TF模型 | 依赖JNI,内存消耗大 |
ONNX Runtime Java示例:
ini
try (OrtEnvironment env = OrtEnvironment.getEnvironment();
OrtSession.SessionOptions options = new SessionOptions()) {
// 1. 加载模型
OrtSession session = env.createSession("resnet18.onnx", options);
// 2. 准备输入(需匹配训练时维度)
float[] inputData = loadImage("cat.jpg"); // 图像预处理
long[] shape = {1, 3, 224, 224};
OrtTensor inputTensor = OrtTensor.createTensor(env, FloatBuffer.wrap(inputData), shape);
// 3. 执行推理
try (OrtSession.Result results = session.run(Collections.singletonMap("input", inputTensor))) {
// 4. 解析输出
float[] output = ((float[][]) results.get(0).getValue())[0];
int label = argmax(output); // 取概率最大类别
}
}
AI写代码java
运行
12345678910111213141516171819三、Spring Boot实战
3.1 核心架构
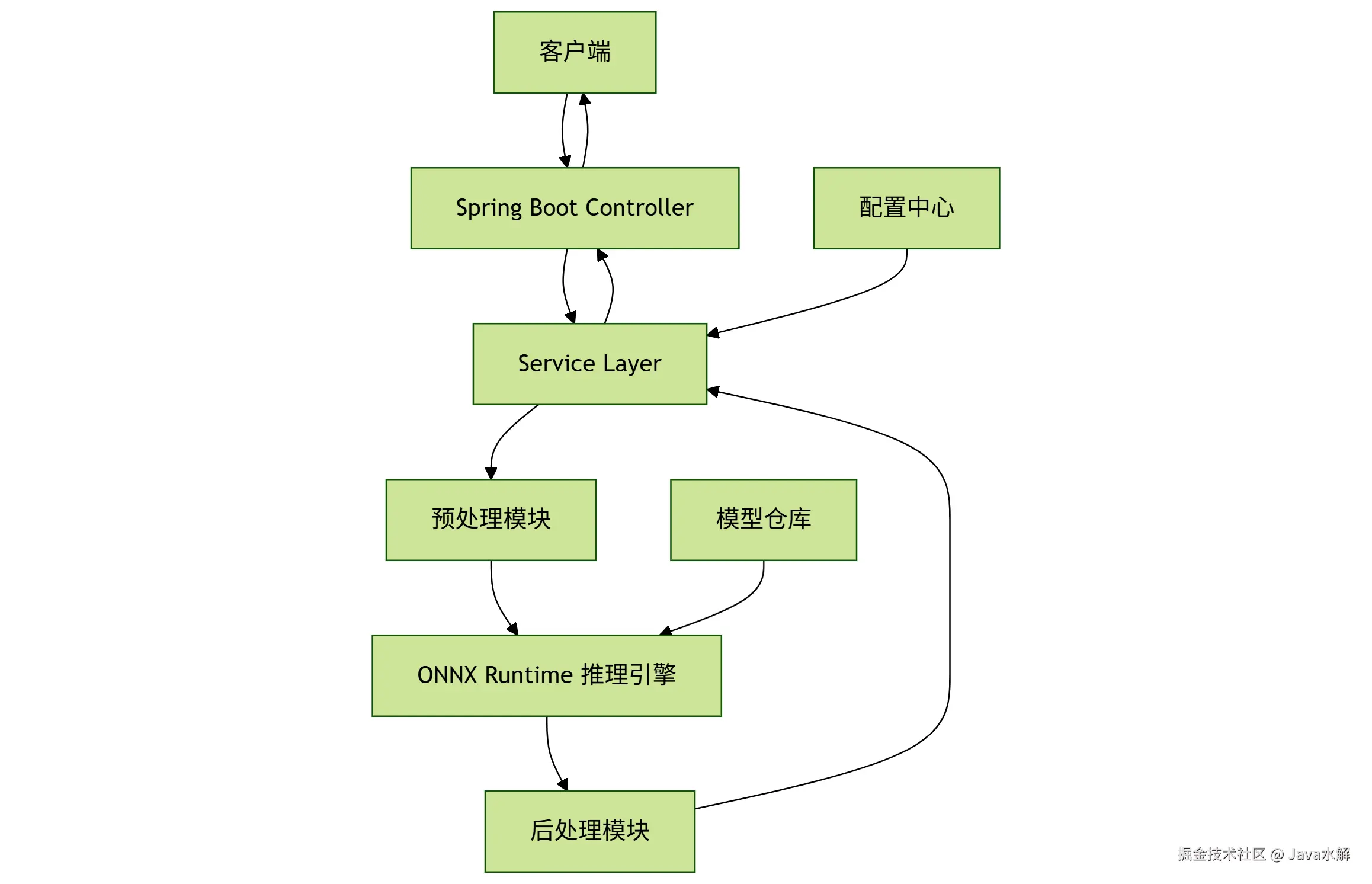
3.2 分层架构详细实现
1. Controller层 - 请求入口
less
@RestController
@RequestMapping("/api/v1/models")
public class ModelInferenceController {
private final InferenceOrchestrator orchestrator;
// 支持多模型版本管理
@PostMapping("/{modelName}/versions/{version}/predict")
public ResponseEntity<InferenceResponse> predict(
@PathVariable String modelName,
@PathVariable String version,
@RequestBody InferenceRequest request) {
// 参数校验
ValidationUtils.validateRequest(request);
// 异步处理
CompletableFuture<InferenceResult> future = orchestrator.executeAsync(
modelName,
version,
request.getData()
);
// 返回202 Accepted + 任务ID
String taskId = UUID.randomUUID().toString();
return ResponseEntity.accepted()
.header("Location", "/tasks/" + taskId)
.body(new InferenceResponse(taskId, "PROCESSING"));
}
// 任务状态查询端点
@GetMapping("/tasks/{taskId}")
public ResponseEntity<TaskStatus> getTaskStatus(
@PathVariable String taskId) {
// 实现状态查询逻辑
}
}
AI写代码java
运行
123456789101112131415161718192021222324252627282930313233343536372. Service层 - 核心业务流程
java
@Service
public class InferenceOrchestrator {
private final ModelLoader modelLoader;
private final Preprocessor preprocessor;
private final Postprocessor postprocessor;
private final InferenceExecutor executor;
@Async("inferenceThreadPool")
public CompletableFuture<InferenceResult> executeAsync(
String modelName,
String version,
byte[] inputData) {
// 1. 加载模型(带缓存机制)
OrtSession session = modelLoader.loadModel(modelName, version);
// 2. 数据预处理
OnnxTensor inputTensor = preprocessor.process(inputData, session);
// 3. 执行推理
OrtSession.Result output = executor.runInference(session, inputTensor);
// 4. 结果后处理
InferenceResult result = postprocessor.process(output);
return CompletableFuture.completedFuture(result);
}
}
AI写代码java
运行
12345678910111213141516171819202122232425262728293. 关键组件深度优化
- 模型加载器(带缓存和热更新)
java
@Component
public class ModelLoader {
private final Map<String, OrtSession> modelCache = new ConcurrentHashMap<>();
private final WatchService watchService; // 文件监听
public OrtSession loadModel(String modelName, String version) throws OrtException {
String cacheKey = modelName + ":" + version;
// 双重检查锁实现缓存
if (!modelCache.containsKey(cacheKey)) {
synchronized (this) {
if (!modelCache.containsKey(cacheKey)) {
// 从模型仓库加载
Path modelPath = modelRepository.resolveModelPath(modelName, version);
OrtSession session = createSession(modelPath);
modelCache.put(cacheKey, session);
// 注册热更新监听
registerModelWatcher(modelPath, cacheKey);
}
}
}
return modelCache.get(cacheKey);
}
private OrtSession createSession(Path modelPath) throws OrtException {
OrtEnvironment env = OrtEnvironment.getEnvironment();
SessionOptions options = new SessionOptions();
// GPU加速配置
if (useGPU) {
options.addCUDA(deviceId);
}
// 优化配置
options.setOptimizationLevel(OptimizationLevel.ALL_OPT)
.setMemoryPatternOptimization(true)
.setExecutionMode(ExecutionMode.SEQUENTIAL);
return env.createSession(modelPath.toString(), options);
}
}
AI写代码java
运行
123456789101112131415161718192021222324252627282930313233343536373839404142- 高性能推理执行器
kotlin
@Component
public class InferenceExecutor {
// 使用ThreadLocal确保线程安全
private ThreadLocal<OrtSession> threadLocalSession = new ThreadLocal<>();
public OrtSession.Result runInference(OrtSession session, OnnxTensor inputTensor) {
try {
// 设置线程级会话副本
if (threadLocalSession.get() == null) {
threadLocalSession.set(session);
}
// 批处理支持(自动合并请求)
if (inputTensor.getInfo().isBatchSupported()) {
return executeBatchInference(inputTensor);
}
// 单次推理
return threadLocalSession.get().run(Collections.singletonMap("input", inputTensor));
} finally {
// 重要:显式释放张量内存
inputTensor.close();
}
}
private OrtSession.Result executeBatchInference(OnnxTensor batchTensor) {
// 实现动态批处理逻辑
// ...
}
}
AI写代码java
运行
1234567891011121314151617181920212223242526272829303132四、云原生部署:Docker + Kubernetes
Dockerfile示例:
sql
FROM eclipse-temurin:17-jre
# 安装ONNX Runtime依赖
RUN apt-get update && apt-get install -y libgomp1
COPY target/model-serving.jar /app.jar
COPY src/main/resources/models /models
ENTRYPOINT ["java", "-Djava.library.path=/onnx_runtime", "-jar", "/app.jar"]
AI写代码dockerfile
123456789K8s部署关键配置:
yaml
apiVersion: apps/v1
kind: Deployment
spec:
template:
spec:
containers:
- name: model-server
image: registry.example.com/model-serving:v1
resources:
limits:
nvidia.com/gpu: 1 # GPU支持
requests:
memory: "4Gi"
volumeMounts:
- name: model-storage
mountPath: /models
---
apiVersion: v1
kind: Service
metadata:
name: model-service
spec:
type: LoadBalancer
ports:
- port: 8080
selector:
app: model-server
AI写代码yaml
123456789101112131415161718192021222324252627当你的Spring Boot服务成功响应第一个推理请求时,Python工程师的表情:😲 → 🤯 → 🫡