本文整理自 IvorySQL 2025 生态大会暨 PostgreSQL 高峰论坛的演讲分享,演讲嘉宾:高策,TensorChord CEO。
引言
本文主要分享如何在 PostgreSQL 上进行向量的搜索。
PostgreSQL 有非常多的 Extension,我们可以通过 Extension 的方式去扩展 PostgreSQL 能够支持的数据类型。这是 PostgreSQL 在全球流行的一个重要原因。
我们可以把向量理解为一个新的数据类型。PGVector 是目前非常流行的项目,支持在 PostgreSQL 中做向量搜索。但 PGVector 同样也存在很多问题。
为了解决社区里的一些问题,我们做了 VectorChord 这个基于 PostgreSQL 的向量搜索引擎,其前身是 pgvecto.rs。
背景
90% 的数据在过去的两年被生产
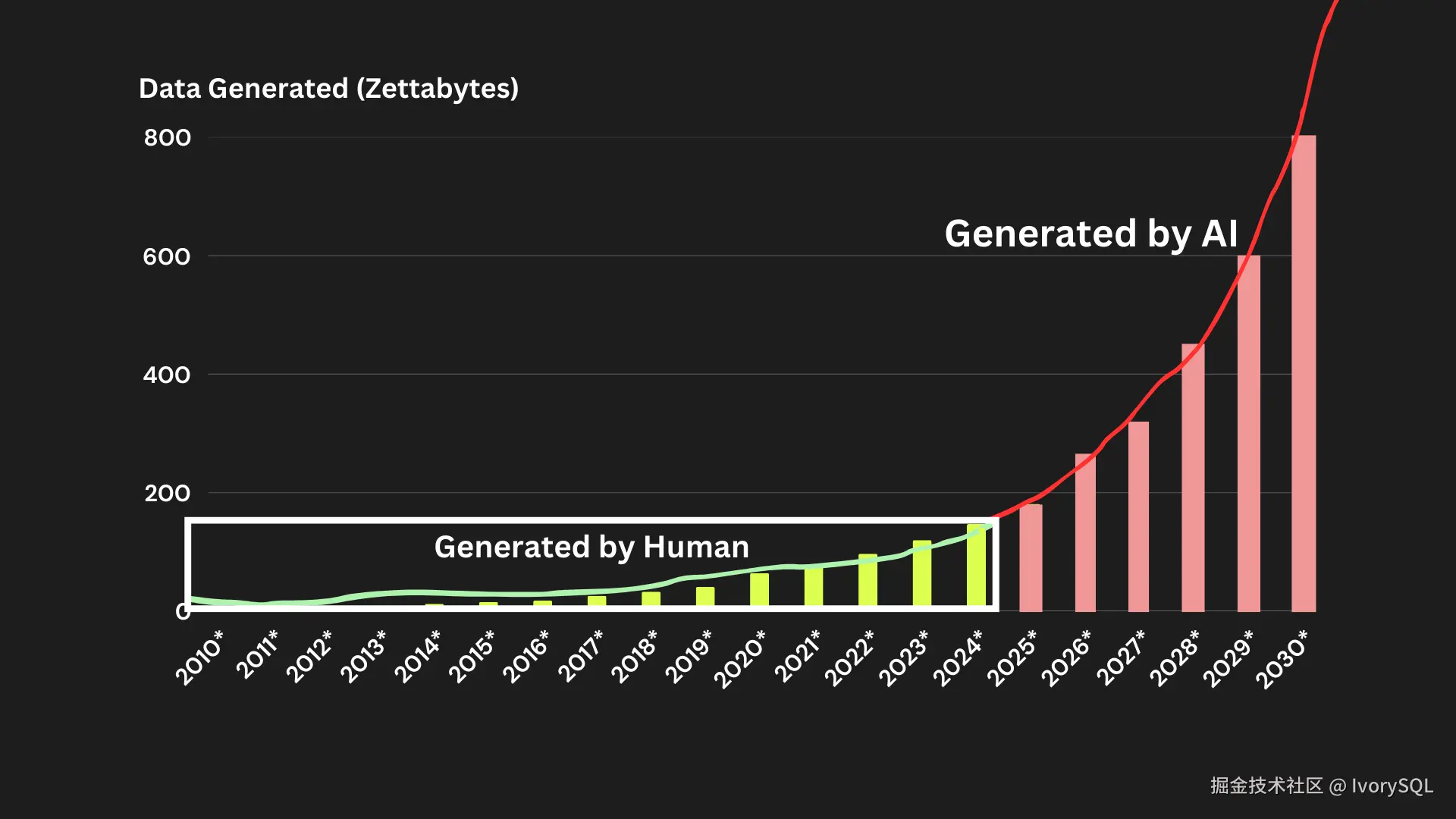
在数字化与智能化的浪潮下,全球数据正以前所未有的速度增长。
根据统计显示,全球 90% 的数据是在 2024 年和 2025 年两年间产生的,而 2023 年之前仅占 10%。
- 早期的数据主要由人类活动产生,增速相对平缓;
- 近两年随着生成式 AI 的广泛应用,数据曲线出现了陡峭的上升拐点。
- 未来几年,AI 生成数据将逐渐成为主流,占比持续攀升。
这一趋势不仅意味着数据量级的飞跃,也带来了数据利用方式的转变。传统的结构化数据已无法满足智能应用的需求,而大规模、多模态、语义化的数据将成为驱动 AI 应用和向量搜索的核心动力。
只有很少部分的数据被 LLM 使用
尽管 LLM(Large Language Model)正在快速发展,但目前真正被广泛利用的数据类型仍然十分有限,主要集中在文档和图像这类相对简单的模态。相比之下,更多高价值的数据类型,例如结构化业务数据、非结构化日志数据、甚至涉及隐私的敏感数据,尚未被有效挖掘。
事实上,像信用卡交易、游戏交互等数据都蕴含着巨大的潜在价值。如果要让 AI 真正理解并使用这些信息,必须先经过一个关键步骤:将原始数据转化为 Embedding(向量)表示,再通过向量搜索在海量数据中进行高效召回。这种转化不仅是 LLM 应用的前提,更是未来数据智能发展的必然趋势。随着数据规模和模态的不断扩展,对向量搜索的需求只会越来越迫切。

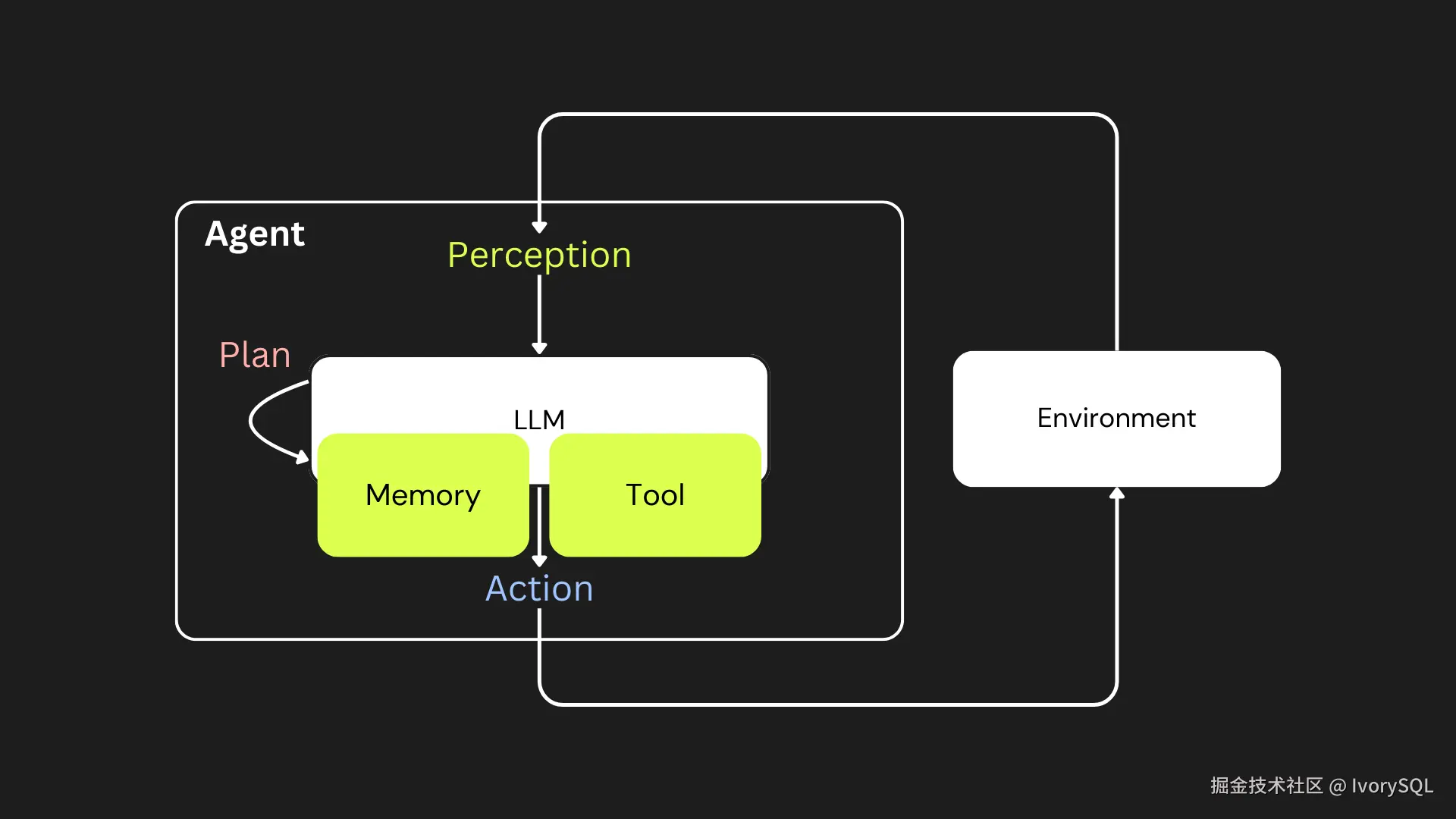
Agent 等新场景进一步扩展对向量搜索的需求
随着大模型应用的扩展,Agent 正逐渐成为热门探索方向。在这一类场景中,Agent 需要具备类似人类的记忆与学习能力,既要能够保留短期记忆,也要积累长期记忆。
在实现过程中,向量搜索发挥了核心作用:
- 通过将交互存储在矢量数据库中,实现了上下文保留和自适应学习,从而使人工智能代理能够回忆过去的经验并随着时间的推移改进。
- 矢量数据库处理文本、图像和音频的语义搜索,以实现长期记忆。
向量搜索
什么是向量搜索
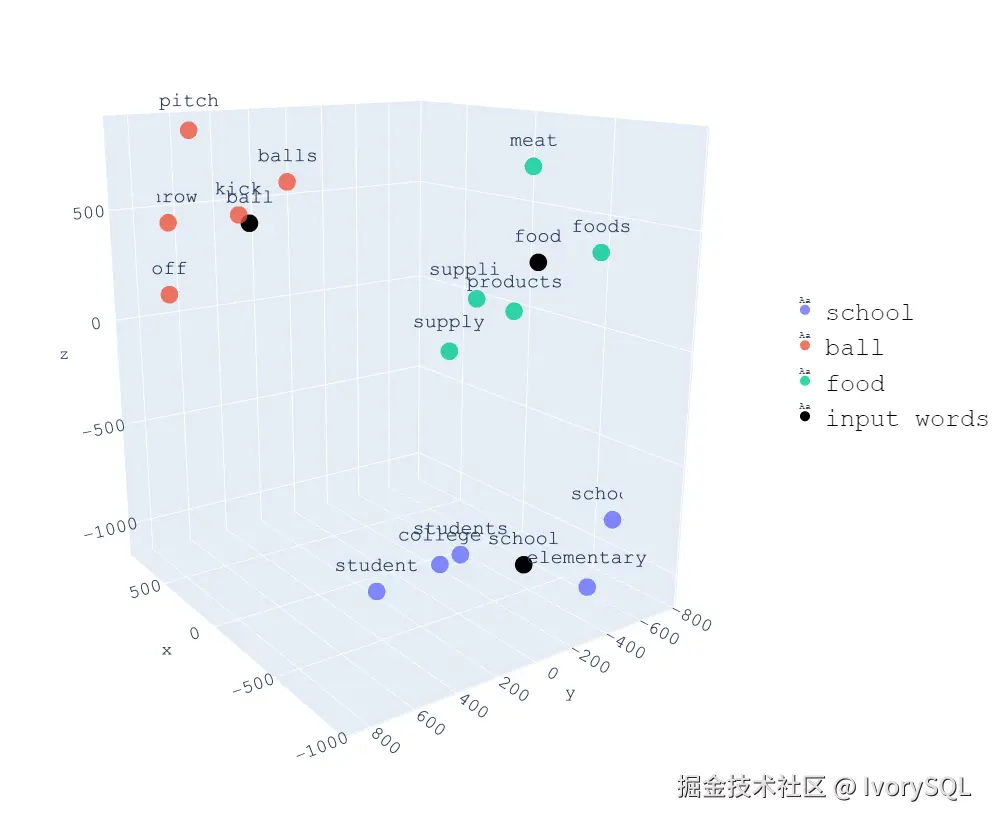
向量搜索的核心,是将文本、图像或音频等信息转化为向量化的数字表示,并在高维空间中通过计算"距离"来衡量相似度。
例如,当一句文本被模型转化为向量后,它可以被表示为一个点,落在三维或更高维的坐标空间中。类似语义的词语(如 student 和 school)会自然地分布在相互接近的位置,当输入一个新词(如 elementary),就可以通过计算向量间的距离,快速找到与之语义相似的词语。
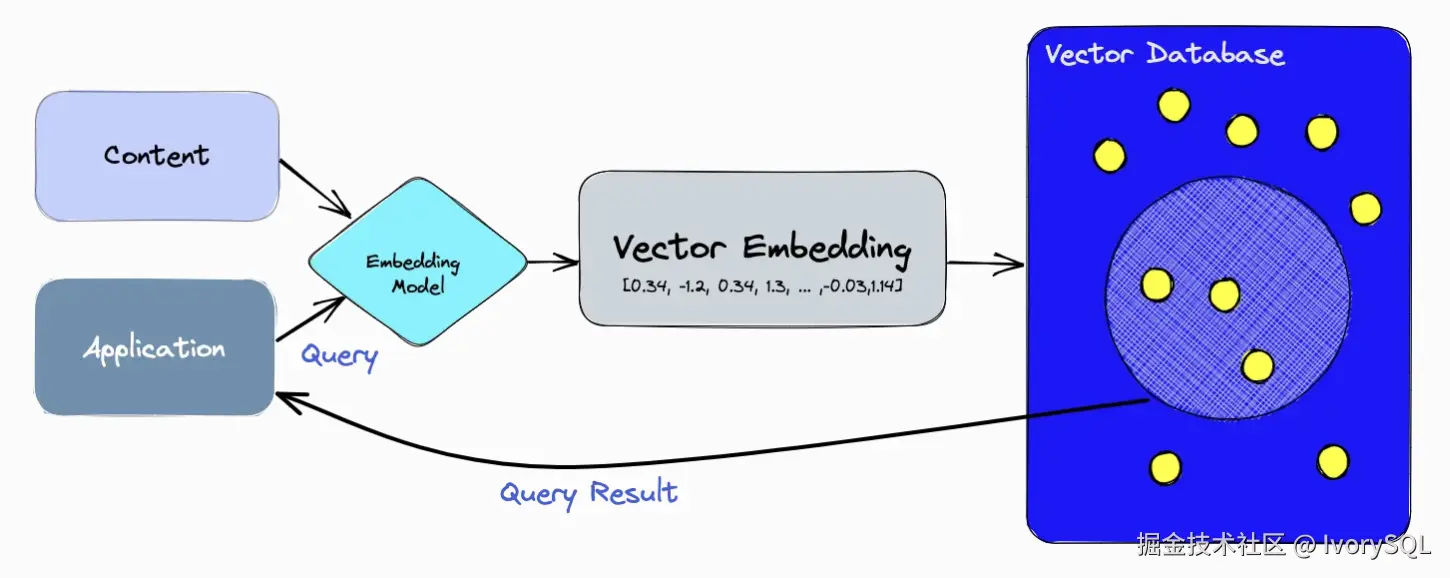
在实际应用中,向量搜索通常包括以下流程:
- 数据向量化:无论是文本还是查询请求,都会经过 Embedding Model 转化 Vector Embedding。
- 向量存储:业务相关的数据(如企业 HR 文档)被批量转化为向量,并存储在数据库中。
- 语义匹配与召回:当用户提出问题(如"公司年假有多少"),系统会将其转化为向量,并与数据库中的向量比对,快速找到语义最接近的答案。
- 结果生成:检索结果交由 LLM 进行加工,最终输出完整、自然的回答。
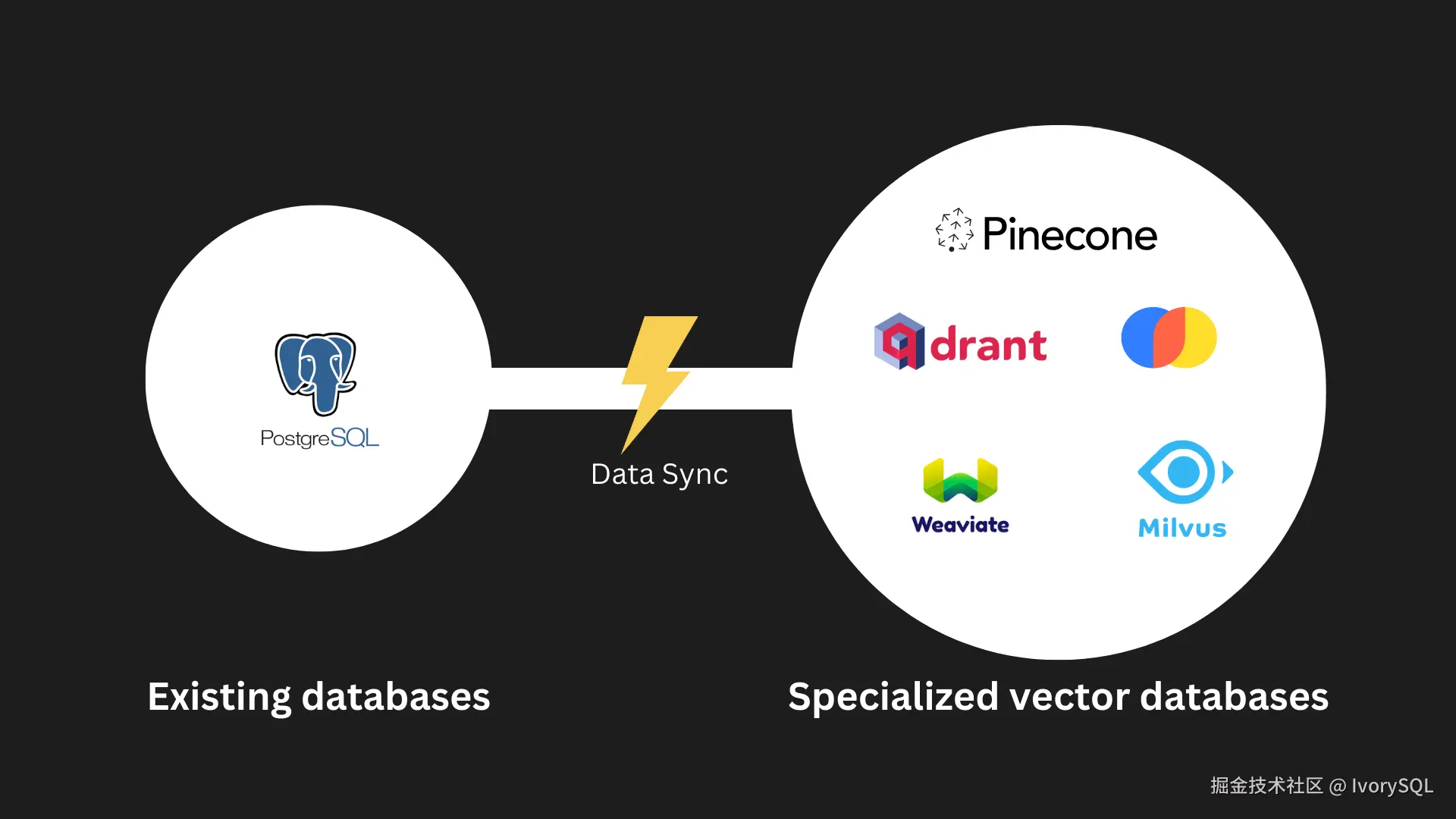
独立的向量数据库存在一致性的问题
在数据管理领域,独立的向量数据库正面临一致性挑战。许多企业已在 Postgres 中存储了核心数据,但为了支持向量搜索功能,往往需要额外维护一个独立的向量数据库。这意味着需要在两个数据库之间进行频繁的数据同步,以确保数据一致性。然而,这一过程引入了额外的复杂性,增加了维护成本和出错风险。
如果能在 Postgres 中直接实现向量搜索功能,这种一致性问题将迎刃而解,不仅能简化数据管理,还能提升系统的可维护性和应用性,为企业带来更高的效率和稳定性。
现有方案 pgvector 的问题
尽管 Postgres 中的 PGVector 是一个广受欢迎的向量搜索解决方案,但其在处理高维向量时存在显著局限性。
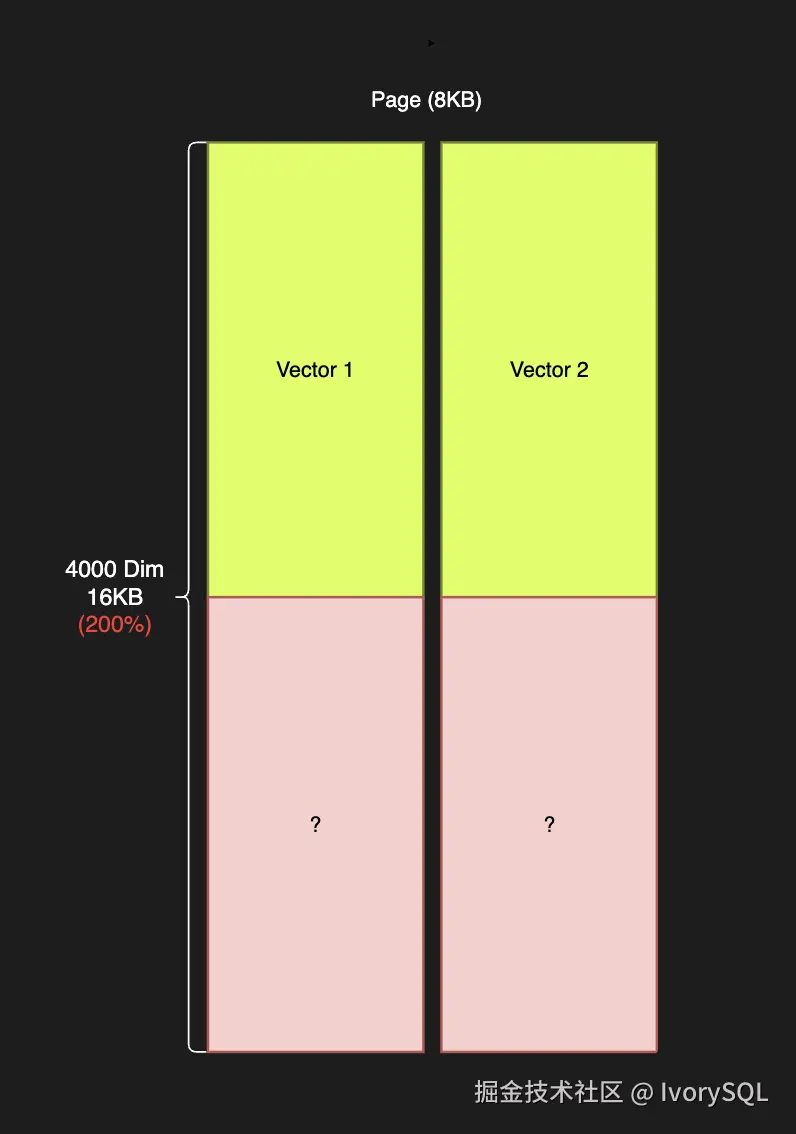
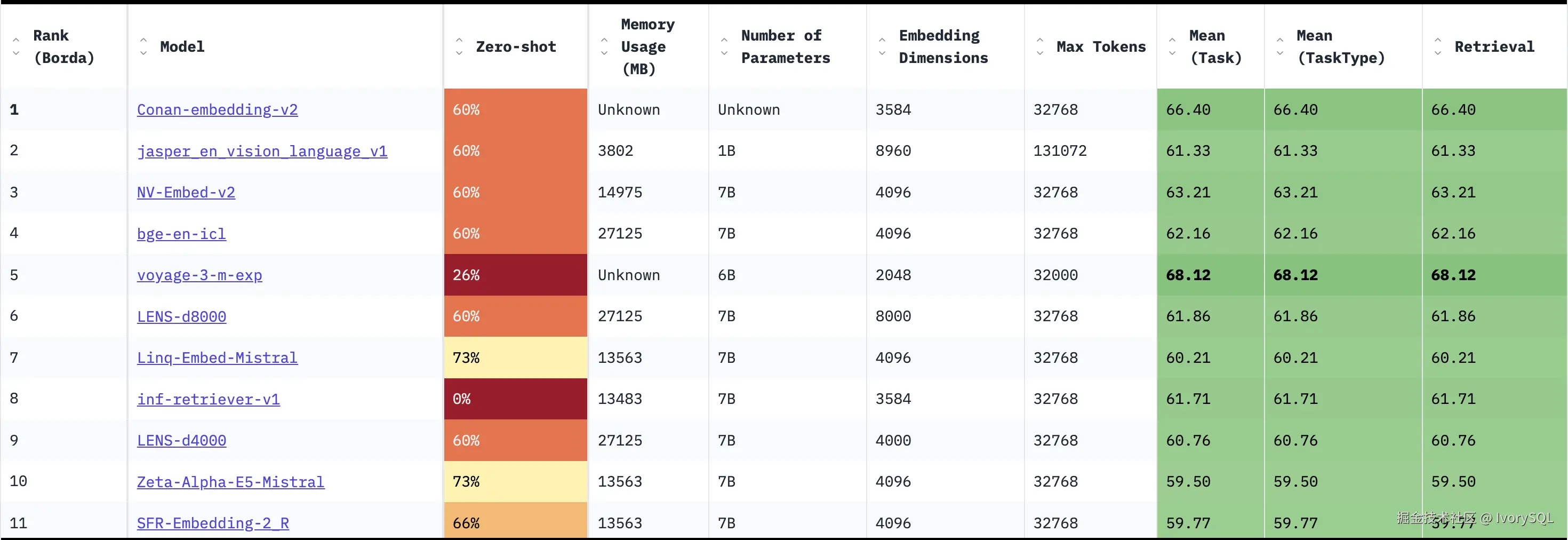
- 当前支持的最大向量维度为 2000(受限于 8kb 页面限制)但用户需要更高维度的向量支持以实现更好的召回效果。
- 各主流嵌入模型维度对比:
- OpenAl 嵌入:3072 维
- NV 嵌入:4096 维
- MTEB 榜单 Top10 的嵌入模型全部超过 2000 维
- 仅 1 个 Top20 模型(兼容 pgvector)低于 2000 维
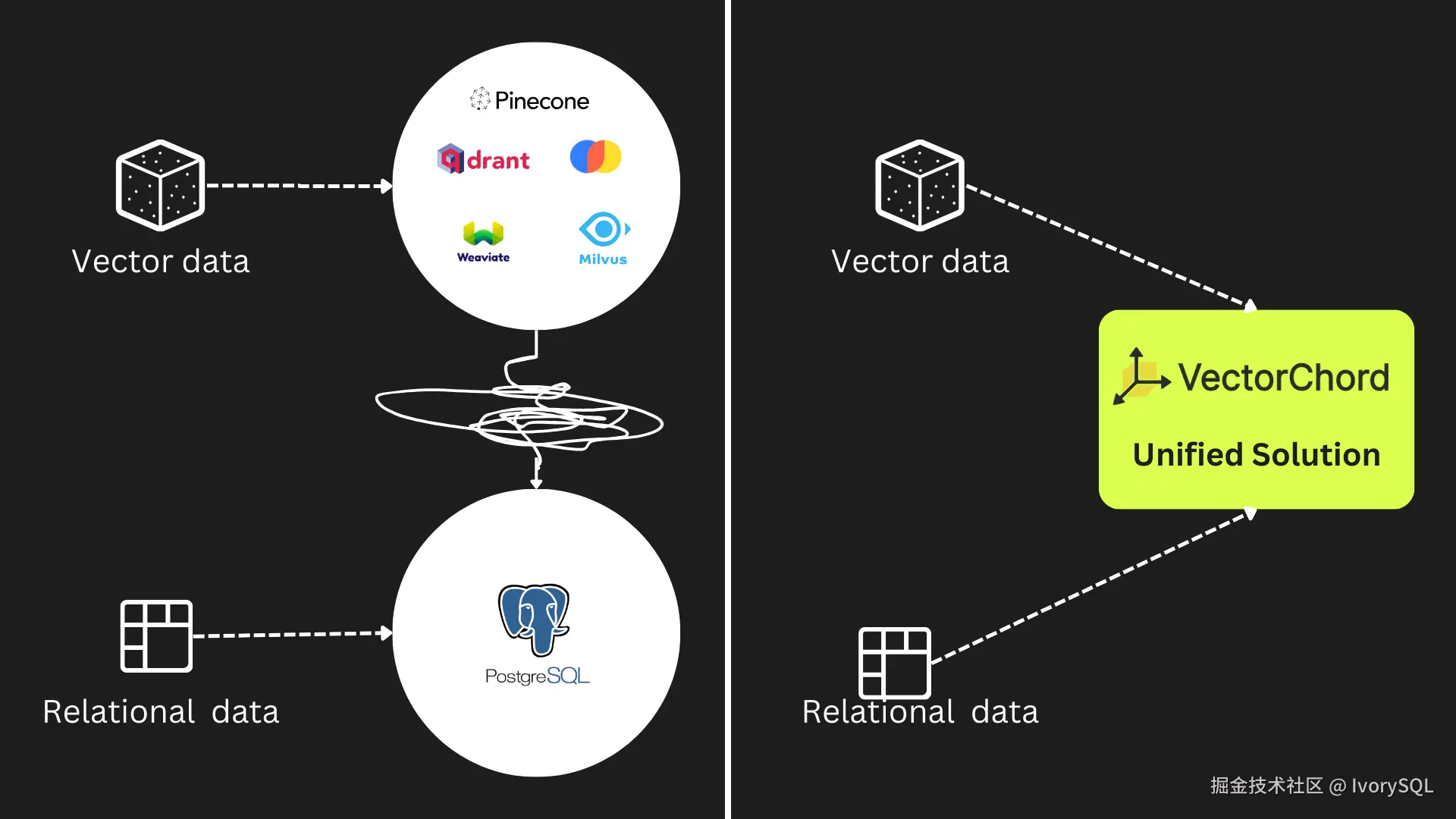
VectorChord
VectorChord 是基于 PostgreSQL 的向量解决方案,可解决数据一致性问题,且具备 PGVector 不具备的优势。
在技术指标上方面,VectorChord 与其他产品在相同检索精度下,其每秒请求数更优,高并发检索时响应更稳定。
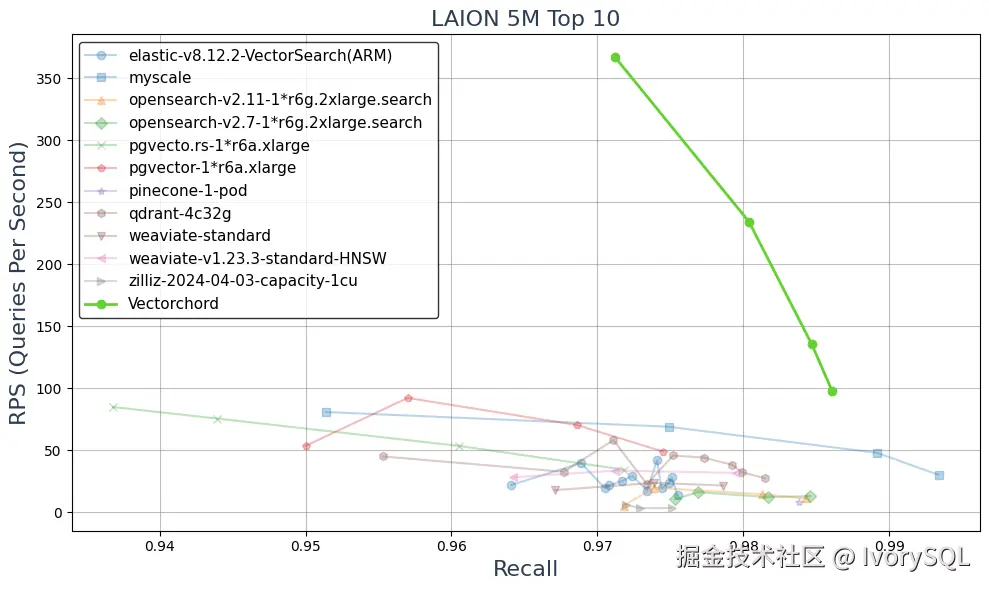
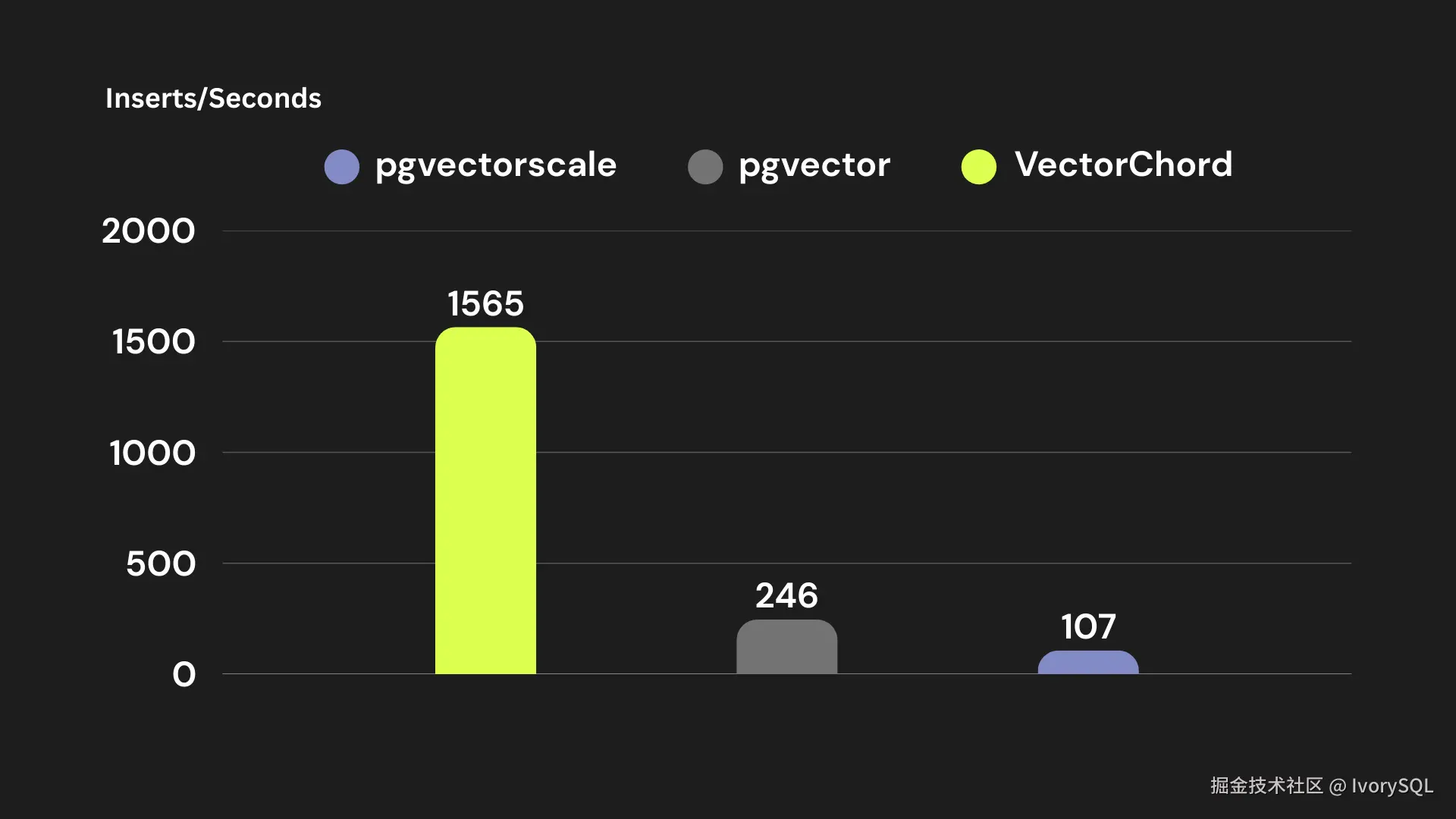
在插入性能方面,向量数据插入需重建索引,VectorChord 插入性能达 1500 操作 / 秒,显著优于 Timescale 出品的 PGVectorScale 与原生 PGVector,能满足实时推荐等需持续写入场景的需求。
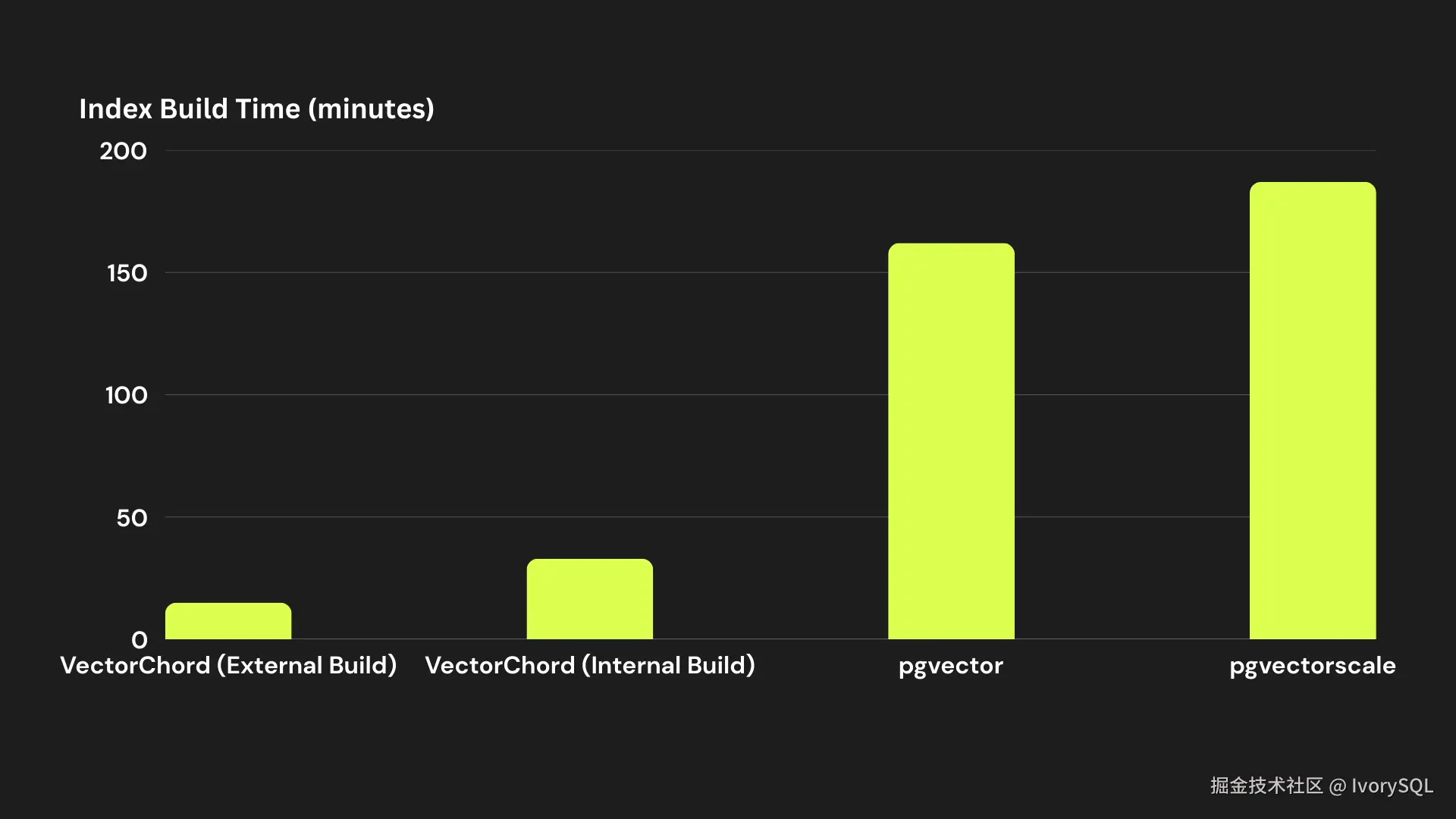
幕后技术:RabitQ + IVF + FastScan + Better Storage Layout
VectorChord 的高性能,由 RabitQ、IVF、FastScan、Better Storage Layout 四大技术协同支撑,该技术源自 2024 年 SIGCOMM 顶会论文,从算法到工程解决向量搜索的精度、性能与存储适配问题。
算法选型上,团队未用主流 HNSW(因图随机游走导致随机读写多,不适配磁盘),而是选 IVF------虽传统精度不足,但天生适配磁盘。同时叠加 FastScan(利用存储特性提高扫描效率)与 Better Storage Layout(减少数据访问耗时),补 IVF 短板。
其中 RabitQ 量化算法是最核心的一部分,解决了传统量化 "降精度" 痛点------传统量化压缩向量(如 bit 存维度)会丢精度,需扩大候选集补,而 RabitQ 靠数学证明控精度损失上下界,无需扩候选集。

Case Study
- Earth Index
- 该团队将地球划分为超过 32 亿个重叠的 10 公顷单元(每个单元约相当于中央公园面积的 3%),并运用前沿 AI 基础模型,将其编码为可搜索的地理空间数据库。
- GCP's vector search would cost$237K/month(!)
- Immich
- 挑战:
- 专用向量数据库和 SOL 数据库始终未能完美同步
- 带过滤条件的查询难以优化,性能往往达不到预期
- VectorChord 的优势:
- 更快的索引(支持更高质量参数)、更快的插入速度和更准确的结果
- 支持无缝的带过滤搜索,并提供无限滚动功能
欢迎关注我们的开源项目: