简报文档:大型语言模型语境学习中的演示位置偏置(DPP Bias)研究
目的
本简报旨在总结和分析大型语言模型(LLMs)在语境学习(ICL)中,演示(demos)在提示(prompt)中不同位置对模型性能、准确性和预测稳定性的影响。
主要发现
1. DPP 偏置的存在与显著性
- 新发现的偏置: 论文首次揭示并量化了一种新的位置偏置,称之为"演示在提示中的位置偏置"(DPP bias)。该偏置表明,即使演示内容保持不变,仅改变其在提示中的位置,模型的预测和准确性也会发生剧烈变化。"我们将这种偏置称为DEMOS' POSITION IN PROMPT bias (DPP bias)。"
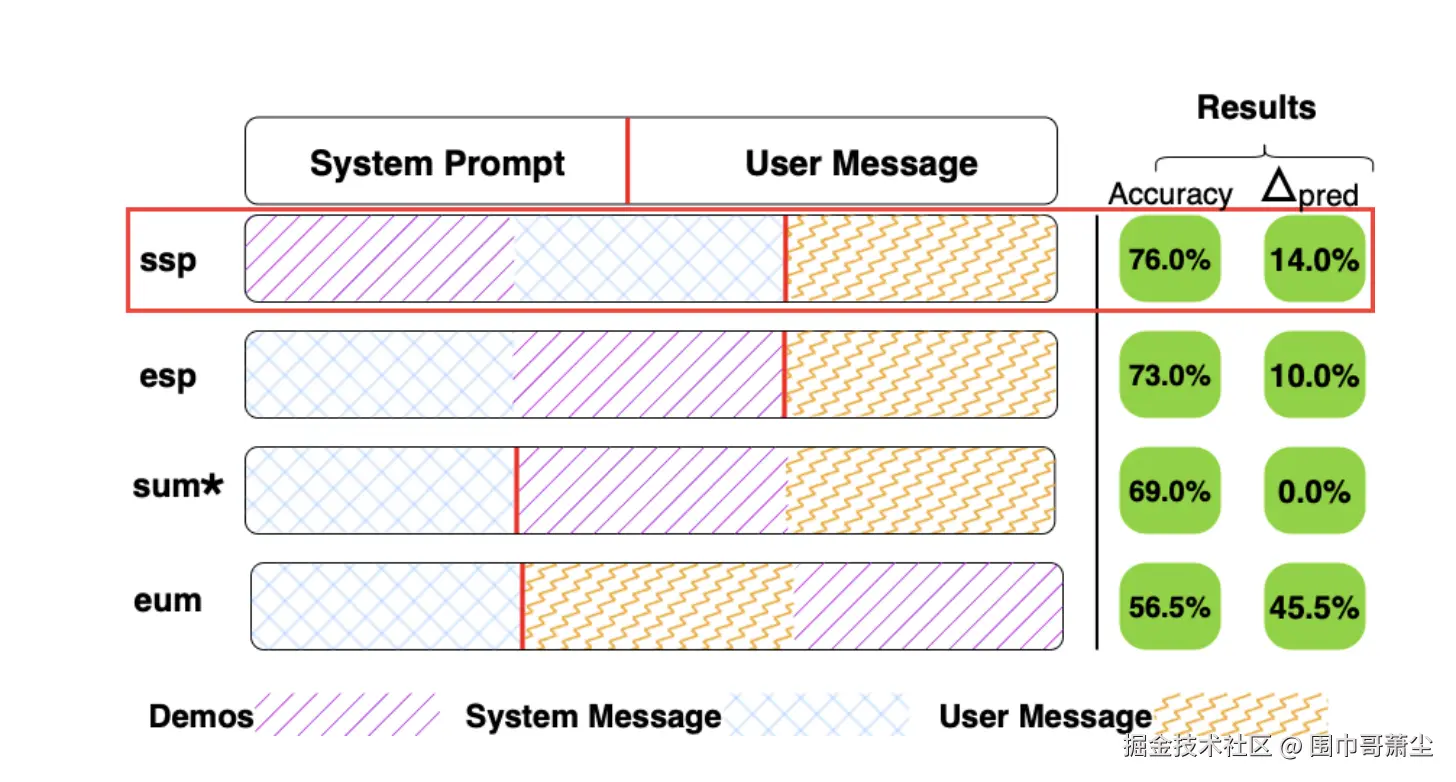
- 影响程度: DPP偏置对LLM的准确性和预测有显著影响。例如,在MMLU数据集上,将演示放置在提示开头(ssp)可使准确性相较于零样本学习提高高达18%,"MMLU shows a +18% gain in accuracy over the zero-shot baseline under ssp。"
- 预测波动: 将演示放置在用户消息末尾(eum)可能导致30%以上的预测翻转,且不会提高问答任务的正确性。"placing demos at the end of the user message flips over 30% of predictions without improving correctness in QA tasks." 在生成任务中,性能波动最为严重,例如在LLAMA3 3B模型上,XSUM任务中从ssp移到eum会导致预测改进率从82.5%降至27.5%。
2. 演示位置对性能的影响
- 最佳位置------提示开头: 普遍观察到,将演示放置在提示的开头(ssp - 系统提示开头 或 esp - 系统提示末尾)通常能获得最稳定和最准确的输出。"placing demos at the start of prompt yields the most stable and accurate outputs with gains of up to +6 points。" 这在分类和问答任务中尤为明显,例如在MNLI、AG NEWS、ARC和MMLU任务中,ssp通常能带来最一致的准确性提升。
- 最差位置------用户消息末尾: "将演示嵌入用户消息末尾会严重降低性能。"(eum) "embedding them at the end of the user message severely degrades performance。"这种放置方式导致模型决策不稳定性显著增加,尤其是在归纳偏差较弱或上下文建模能力较差的模型中。
- 对小模型影响最大: 小型模型对DPP偏置的敏感度最高,尽管大型模型在复杂任务上也会受到轻微影响。"Smaller models are most affected by this sensitivity, though even large models do remain marginally affected on complex tasks."
3. 模型的规模效应与任务特异性
- 规模与鲁棒性: 随着模型规模的增大,模型通常表现出更低的预测波动性和更高的性能稳定性。例如,在MNLI任务中,LLAMA3 70B的预测变化率低于10%,而LLAMA3 3B则超过20%。
- 任务依赖性: 鲁棒性的程度因任务而异,并非随着规模单调递增。例如,在GSM8K(算术推理)任务中,预测变化率在几乎所有模型和位置上都保持在90%以上,表明该任务对演示位置高度敏感,且LLAMA3 70B在ssp位置下表现出意外的性能下降。
- 无普适性最佳位置: 研究发现,没有一个单一的演示位置是普遍最优的,最佳位置会因模型架构和任务类型而异。"No Universally Best Position. Our results demonstrate that early positions dominate on average but exceptions emerge for arithmetic tasks. Instead, the optimal position varies by both model architecture and task category."
- 小型模型倾向前端: 像QWEN 1.5B这样的小型模型强烈偏好将演示放置在esp和ssp位置。
- 大型模型转向用户消息前端: 像LLAMA3 70B这样的大型模型则持续偏好将演示放置在sum位置(用户消息开头),可能因为它们能够更好地在较长的输入序列中保留相关上下文。
4. DPP偏置的潜在原因
- 架构原因: 因果解码器LLMs在训练时采用自回归掩码,导致早期token对后续预测的隐藏状态产生不成比例的影响。"earlier tokens exert disproportionate influence on the hidden state that conditions all subsequent predictions." 归纳头机制(induction heads)也显示注意力权重集中在早期token上。
- 数据原因: 指令调优语料库本身可能存在位置规律性(例如,演示通常在固定槽位),从而在模型中植入了一种分布先验。"Instruction-tuning corpora themselves exhibit positional regularities (e.g., demonstrations in fixed slots), thereby imprinting a distributional prior into the model."
5. 评估指标
- 准确性变化(Accuracy-Change) : 量化给定位置添加演示对模型总体任务性能的影响,相对于零样本学习。
- 预测变化(Prediction-Change) : 衡量演示位置导致的个体模型输出的波动性,即预测结果翻转的实例数量。这揭示了模型决策边界的稳定性。
实际应用与建议
- 明确评估演示位置: 建议LLM用户明确评估演示放置,而不是依赖默认或临时格式。"We recommend that users of instruction-tuned LLMs explicitly evaluate demonstration placement rather than relying on default or ad hoc formats."
- 模型和任务感知: 有效的提示设计必须同时考虑模型特性和任务类型。
- 未来研究方向:
- 测试时校准: 通过检索与未见实例最近邻的带标签最佳位置,进行多数投票来选择演示槽位,无需微调,可动态适应输入分布变化。
- 随机排列上下文进行后训练: 通过在训练时随机排列演示位置,训练出无偏置的语境学习语料库,以鼓励位置不变的表示。
- 深入可解释性研究: 探究特定位置为何被优先考虑,以及注意力初始化、解码器优先权、指令调优模板或训练语料库约定等因素的影响。
- 自动化演示位置优化: 开发能够同时优化演示内容和位置的自动化例程。
伦理考量与局限性
- 伦理: 增强对LLM行为的控制可能被用于生成欺骗性或有害内容。研究人员应整合内容过滤和审查框架。如果演示包含隐性偏见,将其置于提示前端可能会放大这些偏见。
- 局限性:
- 模型多样性有限: 仅评估了有限的模型规模和架构。
- 任务覆盖范围: 未深入探讨更复杂的任务,如多跳检索或对话语境。
- 仅限于英语: 结果主要基于英语数据,跨语言差异有待进一步研究。
- 自动化评估指标: 标准指标(准确性、F1、ROUGE)可能无法完美反映真实效用。
总结
这项研究系统地揭示了语境学习中一个此前被忽视的关键维度------演示在LLM提示中位置的影响 。研究强调,演示的位置并非仅仅是样式问题,而是具有功能性后果 的。将演示放置在提示前端(ssp, esp)通常能带来更高的准确性和预测稳定性,尤其对小型模型而言。然而,最佳位置并非普适,而是取决于模型规模和具体任务 。这些发现对LLM的提示工程实践具有重要指导意义,强调了在设计和优化提示时需要进行模型感知和任务敏感的调整。
在该研究案例中,提示词(prompt)结构化为系统指令(system prompt)和用户消息(user message)两部分,并探讨了在其中放置演示(demos)的四种不同位置。
具体来说,有以下四种典型的演示放置配置(DPP):
-
系统提示词开头 (ssp - Start of System Prompt) :
- 模板 :
<system> Use the demos below as examples on how to answer the question <DEMOS_PLACEHOLDER> <SYSTEM_PLACEHOLDER> <end_of_system> <user> <QUESTION_PLACEHOLDER> <end_of_user> - 说明:演示块被放置在系统消息的最开始,在任何指令内容之前。
- 模板 :
-
系统提示词结尾 (esp - End of System Prompt) :
- 模板 :
<system> <SYSTEM_PLACEHOLDER> Use the demos below as examples on how to answer the question <DEMOS_PLACEHOLDER> <end_of_system> <user> <QUESTION_PLACEHOLDER> <end_of_user> - 说明:演示块被放置在系统消息的末尾,在任何通用指令之后,但在用户查询之前。
- 模板 :
-
用户消息开头 (sum - Start of User Message) :
- 模板 :
<system> <SYSTEM_PLACEHOLDER> <end_of_system> <user> Use the demos below as examples on how to answer the question <DEMOS_PLACEHOLDER> <QUESTION_PLACEHOLDER> <end_of_user> - 说明:演示块被插入到用户消息的开头,在实际的查询文本之前。
- 模板 :
-
用户消息结尾 (eum - End of User Message) :
- 模板 :
<system> <SYSTEM_PLACEHOLDER> <end_of_system> <user> Answer this question <QUESTION_PLACEHOLDER> Use the demos below as examples on how to answer the question <DEMOS_PLACEHOLDER> <end_of_user> - 说明:演示块被附加在用户消息的最末尾,在查询之后。
- 模板 :
在这些模板中:
-
<DEMOS_PLACEHOLDER>代表用于上下文学习(in-context learning)的少量演示示例。 -
<SYSTEM_PLACEHOLDER>代表了针对特定任务的系统指令,例如:- AG News:"您是文本分类助手。您将收到一篇新闻文章,必须将其分类为以下类别之一:世界、体育、商业或科技/技术。只回复类别名称。不要在回复中提供任何解释。以键为'Answer'的json对象形式提供您的答案。"
- MNLI:"您是多类型自然语言推理系统。当给出两个句子(前提和假设)时,确定关系是蕴含、中立还是矛盾。处理包括小说、政府报告、电话语音等多种领域。不要在回复中提供任何解释。以键为'Answer'的json对象形式提供您的答案。"
- MMLU:"您是具有广泛跨学科知识的专家导师。您可以回答大学级别和高级中学级别的多项选择题,涵盖从数学和科学到人文和法律的众多科目。当给出问题和多个选项时,根据您的专业知识选择最佳选项。不要在回复中提供任何解释。以键为'Answer'的json对象形式提供您的答案。"
- SQuAD:"您是阅读理解助手。给定一段文字(上下文)和一个问题,您将从文字中找出最准确的答案。您只依赖提供的文本,避免添加无关信息。不要在回复中提供任何解释。以键为'Answer'的json对象形式提供您的答案。"
- GSM8K:"您是专门从事小学算术和代数应用题的数学导师。请逐步解释您的推理(如果要求)并提供最终的数字或简短答案。强调每一步的清晰性和正确性。以键为'Answer'的json对象形式提供您的答案。"
- 其他任务如ARC、CNN/DailyMail、XSUM也有类似的系统提示词。
-
<QUESTION_PLACEHOLDER>代表实际的用户查询文本。
这项研究通过保持提示词的内容(指令、演示示例和查询)不变,只改变演示块的结构位置来探究模型性能的变化,并将这种现象称为DPP偏置(DPP bias) 。