在性能分析中,常见的 Waiting for GPU completion 耗时问题主要有如下几类原因:
- HWC 未释放
这个得去看合成慢了还是release buffer 慢了 - 其他线程占用 GPU
这个得去看是什么线程,sf 合成还是其它的渲染任务,又或是什么后台算法线程等等 通常的优先级是合成 > 前台渲染 > 其它算法线程 - GPU 频率不足
这点很好确认,可以先确认下freq,低的话再echo 个数值高的测试下 - kgsl_dispathcer 线程状态异常
最常见就是卡D 态,因为adreno cmd 的分发是通过一把mutex 同步的
此外,还有一种是 GPU Ringbuffer 切换耗时过长 导致等待久,我们知道GPU 抢占的核心在于上下文切换,其中一个关键步骤是 Ringbuffer 的切换。

基于Adreno 722 抢占状态机
c
ADRENO_PREEMPT_NONE:没有抢占,空闲状态。
ADRENO_PREEMPT_START:抢占即将开始。
ADRENO_PREEMPT_TRIGGERED:已经触发硬件抢占。
ADRENO_PREEMPT_PENDING:等待硬件完成抢占。
ADRENO_PREEMPT_COMPLETE:抢占完成,切换到新的 ringbuffer。
ADRENO_PREEMPT_FAULTED:抢失败了**当前GPU 通过多rb 实现抢占,不同的prio 分布在不同的rb上
- SurfaceFlinger RenderEngine(prio=1) Ringbuffer0
- camera PostProcThread(prio=12) Ringbuffer3
- 前台RenderThread(prio=4) Ringbuffer1

下面通过trace 分析下这种场景
测试环境: qcom adreno 722 + Android W
测试步骤:拍照后退出卡顿
这个片段身处应用退出返回桌面过程中
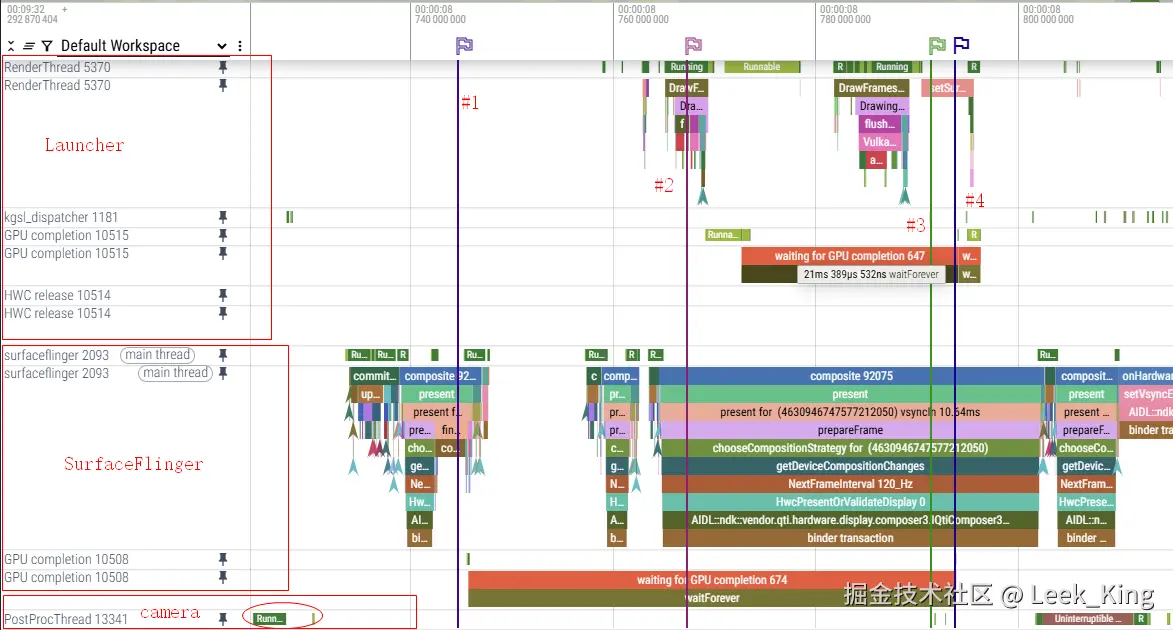
可以看到Sf 合成以及Launcher RenderThread 渲染都阻塞在gpu 侧较长时间
片段对应的时间线如下:
- 相机 PostProcThread (prio=12) 占用 GPU,运行在低优先级 Ringbuffer3。
- SurfaceFlinger 发起合成任务 (prio=1),需切到最高优先级 Ringbuffer0,触发抢占 (Ringbuffer3 → Ringbuffer0)。
- 切换过程中,Launcher 下发的两个渲染命令被阻塞等待。
下面接着看Ringbuffer 切换的耗时长,主要是GPU 在做上下文的切换

- 把状态切到 TRIGGERED,标记"抢占开始了"。
- 给 GMU 写个 QoS 值。
- 最关键:往 CP 控制寄存器里写指令,真正让硬件去做 context save/restore 和 Ringbuffer 切换。
简单说,就是 软件准备完 → 正式把接力棒交给硬件 的一步。
未完待续、、、、、、