crossNet
1、原理
这个网络结构最开始提出来是在推荐领域,其核心作用就是在不增加太多参数与内存的下显式实现特征交叉组合 .其公式如下: x l x_{l} xl是第l层的输出, x 0 x_{0} x0是原始输入,那么第 x l + 1 x_{l+1} xl+1层就等于原始输入乘以上一层输出实现交叉后加上上一层输出;这样一层就是 x 2 x^2 x2的交叉,两层就有 x 3 x^3 x3的交叉,依次类推,这样就确保实现高阶的特征交叉组合.且其参数是线性增长的.
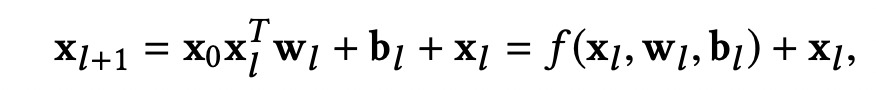
2、原理分析
- 首先从公式看其维度是不发生变化的,所以其高阶信息是压缩过的
- 注意到公式加上一层信息,因此不同层组合,展开其最后一层输出有保留低阶到高阶的的组合信息,但可能存在部分丢失问题
- 该结构适合在原始输入端使用,代替特征交叉组合的特征工程
- 该结构不建议过多层,容易导致过拟合,一般1~3层
- 该结构适合特征本身有交叉关系的场景使用
- 该结构使用稀疏与稠密的输入
3、实现
以torch 为例,当然实际应用通常希望加一点正则防止过拟合,此时可以通过优化器指定增加该部分结构的权重正则.
python
crossnet = CrossNet(...)
crossnet_params = []
othernet = OtherNet(...)
#获取crossnet参数
for name, param in model.named_parameters():
if "crossnet" in name:
crossnet_params.append(param)
optimizer = torch.optim.Adam([
{"params": crossnet.weights, "weight_decay":1e-4},
{"params": crossnet.biases, "weight_decay":0}
], lr=0.001)
python
class CrossNet(nn.Module):
def __init__(self, in_features, num_layers):
super(CrossNet, self).__init__()
self.num_layers = num_layers
self.in_features = in_features
self.weights = nn.ParameterList([
nn.Parameter(torch.randn(in_features, 1)) for _ in range(num_layers)
])
self.biases = nn.ParameterList([
nn.Parameter(torch.randn(in_features)) for _ in range(num_layers)
])
self.reset_parameters()
def forward(self, x0):
x = x0
for i in range(self.num_layers):
# x: (batch, in_features)
# x @ w: (batch, 1)
xw = torch.matmul(x, self.weights[i]) # (batch, 1)
# x0 * (x @ w) : broadcasting (batch, in_features)
cross = x0 * xw # broadcasting
x = cross + self.biases[i] + x # (batch, in_features)
return x
def reset_parameters(self):
# 用合理的初始化方法初始化 weights 和 biases
for w in self.weights:
nn.init.xavier_uniform_(w)
for b in self.biases:
nn.init.zeros_(b)