最近 OpenAI 发表了一篇文章《Why Language Models Hallucinate》,解释为什么会出现 "幻觉",周末我读了一下,总结这篇文章。
什么是"幻觉"?
幻觉是语言模型生成了似是而非的答案,即使很简单的问题,但是模型可能给出一些不符合事实的答案,比如:

css
问题:请用一句话回复,其中第三个词是 "dog"
回答:I have a dog. 词列表:I, have, dog, a. 以上就是一个 "幻觉" 错误,dog 并不是第三个词。
幻觉分类:
- 内在幻觉(Intrinsic Hallucinations):生成的内容与输入的源信息冲突,类似上面的这个问题。
- 外在幻觉(Extrinsic Hallucinations):生成了与源信息无关的内容,大部分情况是没有原始事实,会导致大模型开始 "胡说八道"。
为什么会出现 "幻觉"?
错误的奖励机制
"幻觉" 出现的一个原因源于目前的评估方法所设的错误奖励机制。
想像一下我们在做选择题的时候,对于不知道答案的情况下,我们会怎么选择?我们直接回答不知道,还是猜测一个答案?
大家应该更倾向猜测一个答案,毕竟有一定的概率猜中答案,这样就能获得分数,如果留空则没有奖励分数。
同样,如果只以准确度(即完全答对问题的百分比)来为模型评分,那就会鼓励模型猜测,而不是说"我不知道"。
所以根本原因是模型在训练过程中,并没有将弃权作为评估模型的一个指标,而是根据准确度来排列模型的先后次序。
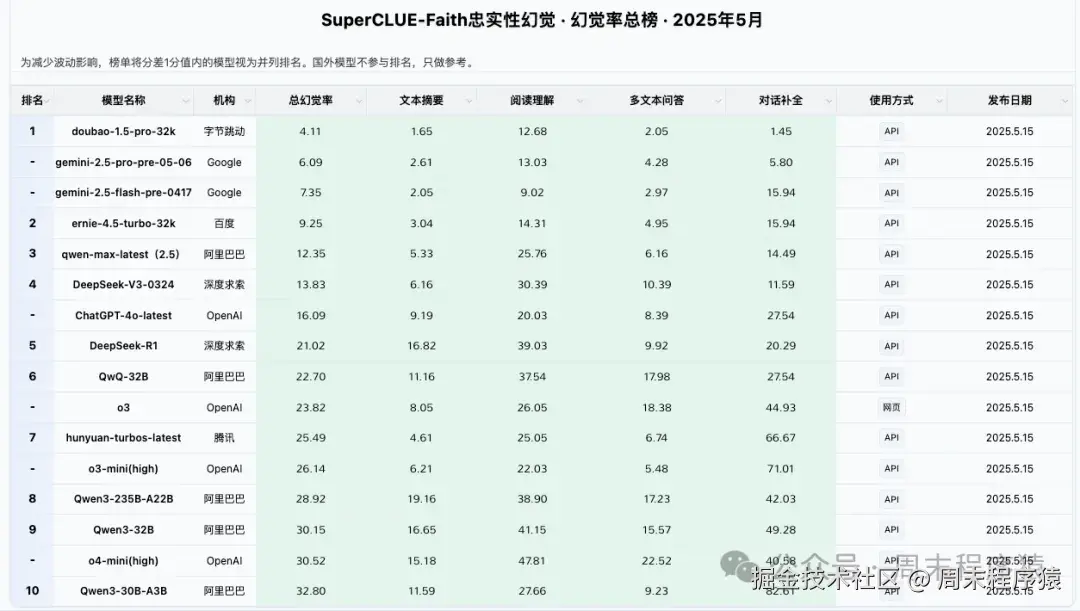
以上是大模型幻觉率的排行榜,可以看到 "幻觉" 并不是模型越大,"幻觉" 就越低,而是和本身的模型评分标准相关。
尽管知道错误的奖励机制会导致 "幻觉" 的出现,但衡量准确度的评分机制仍在排行榜和模型资料卡上占据主导地位,促使开发人员建立倾向猜测而非选择不作答的模型,这样就进一步加剧模型更加自信的提供错误答案。
预训练数据和微调问题
"幻觉" 出现的另一个原因就是预训练本身就是概率预测下一个词,这里必然存在一定概率出现非事实回答,这个时候有人可能会说:为啥拼写和符号等问题不会错?
这个是由于某些事实的数据量小,或者事实没有规律可言的情况下,模型只能按照概率选择下一个词,导致开始 "胡说八道",所以模型的学习目标(最小化交叉熵损失进行概率密度估计)在统计上必然会导致其生成错误。
同时,Gekhman等人在研究中讨论了一个问题:用新知识进行LLM微调是否会促使幻觉现象的发生。
发现 LLM 学习带有新知识的样本,要比学习与模型预先存在的知识样本,学得更慢,一旦学习了这些带有新知识的样本,模型产生幻觉的倾向就会增加。
如何减少 "幻觉"?
基于如上两个出现的原因,其对应方案如下。
完善的评分准则
对于模型训练过程中相对于表示不确定答案,向自信的错误答案施予更严重的惩罚,并对表示不确定的答案给予部分分数。
论文中认为只针对表示不确定的答案增设若干新测试尚不足够,更有必要更新以准确度为基础的热门评估机制,借此令评分标准不再鼓励猜测。
假如主要的评分机制持续奖励侥幸猜测,模型就会持续学习猜想答案,修定评分机制更有助扩大幻觉减少技术的采纳范围。
提升训练数据质量或者引入外部数据
分布偏移:当测试或用户提问的分布与训练数据分布不同时(OOD),模型更易出错。
垃圾进,垃圾出:训练数据本身包含的错误、半真半假的信息和偏见,会被模型学习并复制。
所以高质量的训练数据对于模型是非常重要的,对于模型不了解的知识,应选择类似 RAG 等外部数据源,补充一些事实的缺失问题。