目录
摘要
今天深入学习了决策树中如何选择分裂特征的关键技术------信息增益。通过猫分类的例子,我理解了信息增益是通过计算分裂前后熵的减少量来评估特征的重要性。熵衡量数据的不纯度,信息增益越大说明分裂后子集纯度提升越多。在根节点选择耳朵形状特征就是因为它带来了最大的信息增益(0.28),相比脸型(0.03)和胡须(0.12)更能有效区分猫和非猫
Abstract
Today's lesson focused on information gain for feature selection in decision trees. Using the cat classification example, I learned that information gain measures the reduction in entropy after splitting on a feature. Higher information gain indicates better feature for purifying subsets. The calculation involves comparing parent node entropy with weighted average entropy of child nodes. Ear shape feature was selected at root node due to its highest information gain (0.28) compared to face shape (0.03) and whiskers (0.12).
一、选择拆分信息增益
建立决策树时,我们将在节点上如何决定分裂特征的方法将基于哪种特征选择能够最大程度地减少熵最多,减少熵或者减少杂质在决策树模型中,熵的减少被称为是信息增益,让我来看看如何计算信息增益,从而选择在决策树的每个节点使用哪个特征进行分裂
让我们用刚才构建的决策树的根节点为例来决定使用哪个特征辨别是否为猫
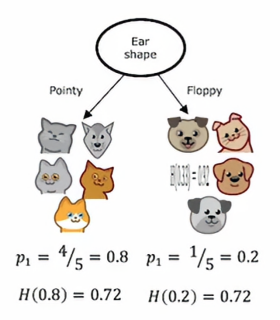
如果我们在根节点分裂时使用耳朵形状作为特征,左边有五个例子,右边有五个例子,在左边我们五个中有四个猫,所以p1=4/5,右边是五个中有一个是猫,所以p2=1/5,如果我们将昨天的熵公式应用到左边的数据子集以及右边的数据子集,我们发现左边的不纯度是0.8的熵,大约是0.72,而右边的熵也为0.72,所以如果我们在耳朵形状上分裂,这将是左右分支的熵
另一种选择是根据面部形状特征分裂
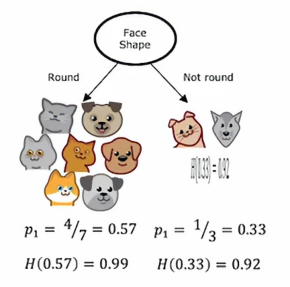
如果我们这样做,那么在左边,七个动物中有四个是猫,右边三分之一是猫,4/7和1/3的熵分别为0.99和0.92,所以左右的不纯度显得更高,直观上就是看着显得更乱
最后,作为根节点的第三个备选特征是胡须特征
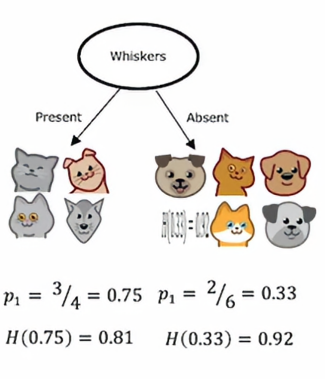
在这种情况下,我们根据是否有胡须来分裂,左边的p1 = 3/4 ,右边的p2 = 2/6=1/3,故它们的熵分别为0.81和0.92
所以,我们回到我们最初的问题,在这三个例子中,哪个是最佳选择,事实证明,与其比较这些熵数值,不如取它们的加权平均值来分析更有用,如果一个节点中很多示例,但它的熵很高,这似乎比一个只有少量示例但同样熵值很高的节点要差,因为如果数据集非常大且不纯,作为纯度测量的熵更差,相比之下,树的一个分支中只有少量示例时,即使非常不纯,其熵值也比较低,所以关键决策是,在这三个可用作根节点的特征中,我们通过加权平均来合并两个数字,因为低熵是多么重要,比如左子分支或右子分支也取决进入左子分支或右子分支的实例数量,因为如果在其中有很多实例,比如左子分支,那么确保左子分支的熵值较低就显得很重要了,在这个示例中,我们有十个示例,其中有五个示例进入了左子分支,所以我们可以计算加权平均值

因此,我们选择分裂的方法是计算这三个数字并选择最小的那个,因为那样会给我们带来平均加权熵值最低的左子分支和右子分支,在构建决策树的过程中,我们实际上会对这些公式进行一个改动,以符合决策树构建的惯例,就是我们不会计算加权平均熵值,而是计算没有分裂时相比的熵值减少量,所以我们到根节点,记住根节点上,我们一开始有根节点上的所有十个示例,有五只猫五只狗,所以在根节点上,我们有p1 = 0.5,H = 1,这是最大的不纯度,因为有五只猫和五只狗在同一层,所以我们实际用来选择分裂的公式不是左右两侧的加权熵值子分支,相反,它将是根节点的熵,即0.5的熵,然后减去这个公式,在这个例子中,如果我们计算一下数学公式,结果是0.28,对于脸型,我们计算为0.03,对于胡须,我们计算为0.12
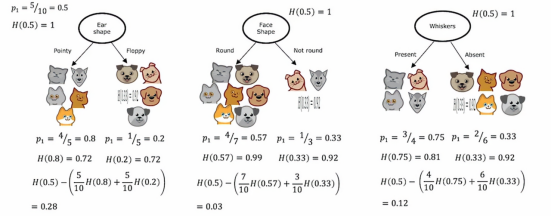
这些我们刚才计算的数字,我们称之为信息增益,它衡量的是我们在树中获得的熵减少,来自分裂所得到,因为根节点的熵原本是1,通过进行分裂,我们最终得到了更低的熵值,这两个值之间的差异就是熵的减少
那么为什么我们要计算熵的减少,而不是直接计算左右子分支的熵呢,事实证明,决定是否不再继续分裂的停止标准之一是看熵的减少程度,如果熵减少的太小,在这种情况下,我们可能会决定只是为了不必要地增加树的大小而冒着过拟合的风险并决定如果熵减少的太小,低于一个阈值,就不再分裂,在上面这个例子中,耳朵的减少量是最多的,所以我们可以选择耳朵形状来作为分类特征

上面这张图就是信息增益在数学上的定义,并且给定了具体的计算公式
所以总的来说,通过计算这些信息增益,我们可以判别几个特征中熵减少最多的特征,把它作为分类特征,这样我们可以得到最优的分类。
整合
信息增益标准让我们决定如何选择一个特征在一个节点进行分裂,让我们在决策树多个位置使用它,以确定如何构建一个大型的具有多个节点的决策树
这是构建决策树的总体过程,从树的根节点开始,包含所有训练示例,并计算所有的可能的信息增益特征,选择提供最高信息增益的特征进行分裂,当我们确定了分类的特征后,我们根据选定的特征把数据集分成两个子集,并创建左分支和右分支的树,并将训练示例发送到左分支和右分支,之后,我们继续重复在树上的左分支进行分裂,在右分支上的分裂,以此类推,一直这样做,直到满足标准,停止的标准是一个分类达到100%的纯度或者树的深度超过了我们设置的最大深度抑或是额外分裂的信息增益小于一个阈值,或者节点中示例数量低于阈值
我们来看一个实例操作
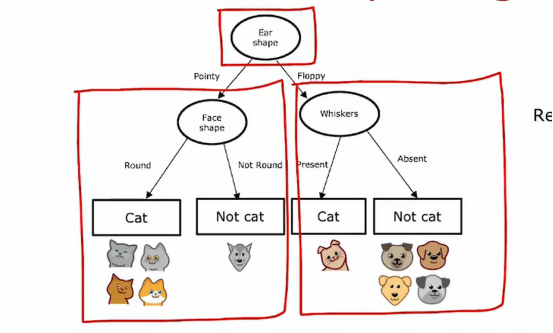
首先根节点上,我们发现耳朵形状是信息增益最好的情况,所以我们选择耳朵形状作为我们的分类特征,然后我们衍生出2个子树,我们先把眼光放到左子树上,通过计算,我们发现脸型的分类表现是最好的,所以我们选择脸型作为分类特征,然后我们发现,左边的猫纯度达到了100%,这达到了我们的停止条件,所以我们把左子树的两个叶节点划定为猫和非猫,然后我们将视角看到右子树,同样的,经过计算,我们将胡须作为我们的分类特征,经过分类之后,我们发现左边的猫特征纯度已经达到100%,右边非猫的纯度也达到了100%,所以我们判定这个分类过程结束,一个决策树就这样被建立起来了
总结
今天的学习让我掌握了决策树构建的核心机制------信息增益的计算和应用。通过具体的数值计算,我明白了为什么耳朵形状被选为根节点的分裂特征,因为它带来的熵减少最多。信息增益的计算公式虽然看起来复杂,但本质就是比较分裂前后不纯度的改善程度。这种量化的特征选择方法比凭直觉更科学可靠。我还了解了构建决策树的完整流程:从根节点开始,递归地在每个节点选择信息增益最大的特征进行分裂,直到满足停止条件。这些知识让我对决策树的工作原理有了更深入的理解,不再停留在表面认知上。